




So migrieren Sie Ihre Daten nahtlos zu Milvus: Ein umfassender Leitfaden
Milvus ist eine robuste Open-Source-Vektordatenbank für die Ähnlichkeitssuche, die Milliarden und sogar Billionen von Vektordaten mit minimaler Latenz speichern, verarbeiten und abrufen kann. Sie ist außerdem hoch skalierbar, zuverlässig, cloud-nativ und funktionsreich. Die neueste Version von Milvus führt noch mehr spannende Funktionen und Verbesserungen ein, darunter GPU-Unterstützung für eine über 10-mal schnellere Leistung und MMap für eine größere Speicherkapazität auf einer einzelnen Maschine.
Stand September 2023 hat Milvus fast 23.000 Sterne auf GitHub erhalten und hat Zehntausende von Nutzern aus verschiedenen Branchen mit unterschiedlichen Anforderungen. Es wird noch beliebter, da Generative-AI-Technologie wie ChatGPT immer stärker verbreitet ist. Es ist eine wesentliche Komponente verschiedener AI-Stacks, insbesondere des retrieval augmented generation-Frameworks, das das Halluzinationsproblem großer Sprachmodelle angeht.
Um der wachsenden Nachfrage neuer Nutzer gerecht zu werden, die zu Milvus migrieren möchten, sowie bestehender Nutzer, die auf die neuesten Milvus-Versionen aktualisieren möchten, haben wir Milvus Migration entwickelt. In diesem Blog untersuchen wir die Funktionen von Milvus Migration und führen Sie durch die schnelle Übertragung Ihrer Daten von Milvus 1.x, FAISS und Elasticsearch 7.0 und darüber hinaus zu Milvus.
Milvus Migration, ein leistungsstarkes Datenmigrationstool
Milvus Migration ist ein in Go geschriebenes Datenmigrationstool. Es ermöglicht Nutzern, ihre Daten nahtlos von älteren Versionen von Milvus (1.x), FAISS und Elasticsearch 7.0 und darüber hinaus zu Milvus-2.x-Versionen zu verschieben.
Das folgende Diagramm zeigt, wie wir Milvus Migration entwickelt haben und wie es funktioniert.
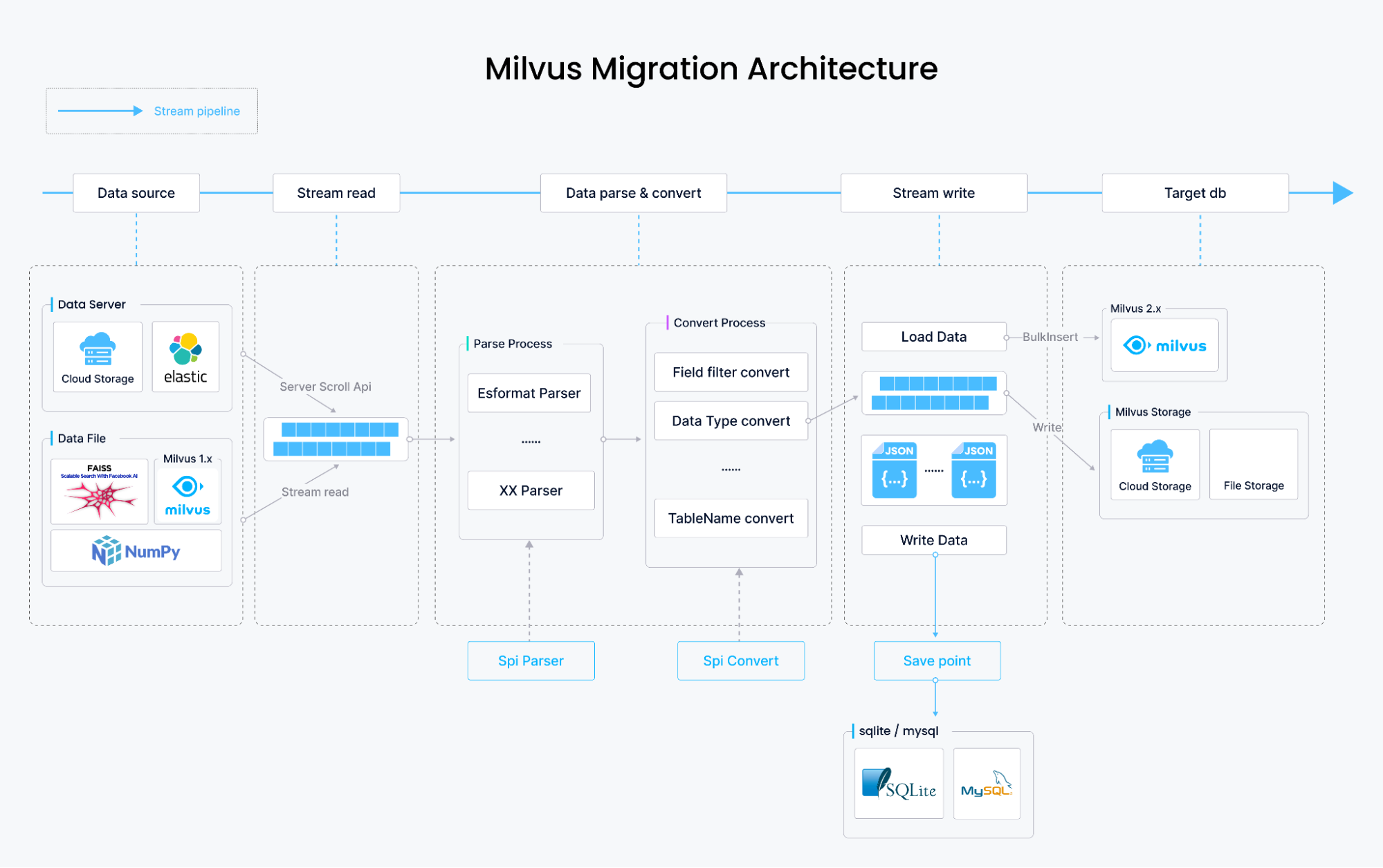
Wie Milvus Migration Daten migriert
Von Milvus 1.x und FAISS zu Milvus 2.x
Die Datenmigration von Milvus 1.x und FAISS umfasst das Parsen des Inhalts der ursprünglichen Datendateien, ihre Umwandlung in das Datenspeicherformat von Milvus 2.x und das Schreiben der Daten mithilfe von bulkInsert des Milvus SDK. Dieser gesamte Prozess ist streambasiert, theoretisch nur durch den Speicherplatz begrenzt, und speichert Datendateien auf Ihrer lokalen Festplatte, S3, OSS, GCP oder Minio.
Von Elasticsearch zu Milvus 2.x
Bei der Elasticsearch-Datenmigration unterscheidet sich der Datenabruf. Daten werden nicht aus Dateien bezogen, sondern sequenziell mithilfe der Scroll API von Elasticsearch abgerufen. Die Daten werden anschließend geparst und in das Speicherformat von Milvus 2.x umgewandelt, gefolgt vom Schreiben mithilfe von bulkInsert. Neben der Migration von in Elasticsearch gespeicherten Vektoren des Typs dense_vector unterstützt Milvus Migration auch die Migration anderer Feldtypen, darunter long, integer, short, boolean, keyword, text und double.
Funktionsumfang von Milvus Migration
Milvus Migration vereinfacht den Migrationsprozess durch seinen robusten Funktionsumfang:
Unterstützte Datenquellen:
Milvus 1.x zu Milvus 2.x
Elasticsearch 7.0 und darüber hinaus zu Milvus 2.x
FAISS zu Milvus 2.x
Mehrere Interaktionsmodi:
Befehlszeilenschnittstelle (CLI) unter Verwendung des Cobra-Frameworks
Restful API mit integrierter Swagger UI
Integration als Go-Modul in andere Tools
Vielseitige Unterstützung von Dateiformaten:
Lokale Dateien
Amazon S3
Object Storage Service (OSS)
Google Cloud Platform (GCP)
Flexible Elasticsearch-Integration:
Migration von Vektoren des Typs
dense_vectoraus ElasticsearchUnterstützung für die Migration anderer Feldtypen wie long, integer, short, boolean, keyword, text und double
Schnittstellendefinitionen
Milvus Migration stellt die folgenden wichtigen Schnittstellen bereit:
/start: Initiiert einen Migrationsauftrag (entspricht einer Kombination aus dump und load, unterstützt derzeit nur ES-Migration)./dump: Initiiert einen Dump-Auftrag (schreibt Quelldaten in das Ziel-Speichermedium)./load: Initiiert einen Ladeauftrag (schreibt Daten aus dem Ziel-Speichermedium in Milvus 2.x)./get_job: Ermöglicht Benutzern, die Ausführungsergebnisse von Aufträgen einzusehen. (Weitere Details finden Sie in server.go des Projekts)
Als Nächstes verwenden wir in diesem Abschnitt einige Beispieldaten, um zu erkunden, wie Milvus Migration verwendet wird. Sie finden diese Beispiele hier auf GitHub.
Migration von Elasticsearch zu Milvus 2.x
- Elasticsearch-Daten vorbereiten
Um Elasticsearch-Daten zu migrieren, sollten Sie bereits Ihren eigenen Elasticsearch-Server eingerichtet haben. Sie sollten Vektordaten im Feld dense_vector speichern und sie zusammen mit anderen Feldern indizieren. Die Index-Mappings sind unten dargestellt.

- Kompilieren und Build erstellen
Laden Sie zunächst den Quellcode von Milvus Migration von GitHub herunter. Führen Sie dann die folgenden Befehle aus, um ihn zu kompilieren.
go get
go build
Dieser Schritt erzeugt eine ausführbare Datei namens milvus-migration.
migration.yamlkonfigurieren
Bevor Sie die Migration starten, müssen Sie eine Konfigurationsdatei namens migration.yaml vorbereiten, die Informationen zur Datenquelle, zum Ziel und zu anderen relevanten Einstellungen enthält. Hier ist eine Beispielkonfiguration:
# Configuration for Elasticsearch to Milvus 2.x migration
dumper:
worker:
workMode: Elasticsearch
reader:
bufferSize: 2500
meta:
mode: config
index: test_index
fields:
- name: id
pk: true
type: long
- name: other_field
maxLen: 60
type: keyword
- name: data
type: dense_vector
dims: 512
milvus:
collection: "rename_index_test"
closeDynamicField: false
consistencyLevel: Eventually
shardNum: 1
source:
es:
urls:
- http://localhost:9200
username: xxx
password: xxx
target:
mode: remote
remote:
outputDir: outputPath/migration/test1
cloud: aws
region: us-west-2
bucket: xxx
useIAM: true
checkBucket: false
milvus2x:
endpoint: {yourMilvusAddress}:{port}
username: ******
password: ******
Eine ausführlichere Erklärung der Konfigurationsdatei finden Sie auf dieser Seite auf GitHub.
- Den Migrationsauftrag ausführen
Nachdem Sie Ihre Datei migration.yaml konfiguriert haben, können Sie die Migrationsaufgabe starten, indem Sie den folgenden Befehl ausführen:
./milvus-migration start --config=/{YourConfigFilePath}/migration.yaml
Beobachten Sie die Log-Ausgabe. Wenn Sie Logs sehen, die den folgenden ähneln, bedeutet dies, dass die Migration erfolgreich war.
[task/load_base_task.go:94] ["[LoadTasker] Dec Task Processing-------------->"] [Count=0] [fileName=testfiles/output/zwh/migration/test_mul_field4/data_1_1.json] [taskId=442665677354739304][task/load_base_task.go:76] ["[LoadTasker] Progress Task --------------->"] [fileName=testfiles/output/zwh/migration/test_mul_field4/data_1_1.json] [taskId=442665677354739304][dbclient/cus_field_milvus2x.go:86] ["[Milvus2x] begin to ShowCollectionRows"][loader/cus_milvus2x_loader.go:66] ["[Loader] Static: "] [collection=test_mul_field4_rename1] [beforeCount=50000] [afterCount=100000] [increase=50000][loader/cus_milvus2x_loader.go:66] ["[Loader] Static Total"] ["Total Collections"=1] [beforeTotalCount=50000] [afterTotalCount=100000] [totalIncrease=50000][migration/es_starter.go:25] ["[Starter] migration ES to Milvus finish!!!"] [Cost=80.009174459][starter/starter.go:106] ["[Starter] Migration Success!"] [Cost=80.00928425][cleaner/remote_cleaner.go:27] ["[Remote Cleaner] Begin to clean files"] [bucket=a-bucket] [rootPath=testfiles/output/zwh/migration][cmd/start.go:32] ["[Cleaner] clean file success!"]
Zusätzlich zum Befehlszeilenansatz unterstützt Milvus Migration auch die Migration über die Restful API.
Um die Restful API zu verwenden, starten Sie den API-Server mit dem folgenden Befehl:
./milvus-migration server run -p 8080
Sobald der Dienst läuft, können Sie die Migration durch Aufrufen der API starten.
curl -XPOST http://localhost:8080/api/v1/start
Wenn die Migration abgeschlossen ist, können Sie Attu, ein All-in-one-Verwaltungstool für Vektordatenbanken, verwenden, um die Gesamtzahl der erfolgreich migrierten Zeilen anzuzeigen und andere sammlungsbezogene Vorgänge auszuführen.
 Die Attu-Oberfläche
Die Attu-Oberfläche
Migration von Milvus 1.x zu Milvus 2.x
- Milvus 1.x-Daten vorbereiten
Damit Sie den Migrationsprozess schnell ausprobieren können, haben wir 10.000 Milvus 1.x-Testdaten-Datensätze in den Quellcode von Milvus Migration aufgenommen. In realen Fällen müssen Sie jedoch Ihre eigene meta.json-Datei aus Ihrer Milvus 1.x-Instanz exportieren, bevor Sie den Migrationsprozess starten.
- Sie können die Daten mit dem folgenden Befehl exportieren.
./milvus-migration export -m "user:password@tcp(adderss)/milvus?charset=utf8mb4&parseTime=True&loc=Local" -o outputDir
Stellen Sie sicher, dass Sie:
Die Platzhalter durch Ihre tatsächlichen MySQL-Anmeldedaten ersetzen.
Den Milvus 1.x-Server stoppen oder Datenschreibvorgänge anhalten, bevor Sie diesen Export durchführen.
Den Milvus-Ordner
tablesund die Dateimeta.jsonin dasselbe Verzeichnis kopieren.
Hinweis: Wenn Sie Milvus 2.x auf Zilliz Cloud (dem vollständig verwalteten Dienst von Milvus) verwenden, können Sie die Migration über die Cloud Console starten.
- Kompilieren und erstellen
Laden Sie zunächst den Quellcode von Milvus Migration von GitHub herunter. Führen Sie dann die folgenden Befehle aus, um ihn zu kompilieren.
go get
go build
Dieser Schritt generiert eine ausführbare Datei namens milvus-migration.
migration.yamlkonfigurieren
Bereiten Sie eine migration.yaml-Konfigurationsdatei vor, in der Details zur Quelle, zum Ziel und zu anderen relevanten Einstellungen angegeben werden. Hier ist eine Beispielkonfiguration:
# Configuration for Milvus 1.x to Milvus 2.x migration
dumper:
worker:
limit: 2
workMode: milvus1x
reader:
bufferSize: 1024
writer:
bufferSize: 1024
loader:
worker:
limit: 16
meta:
mode: local
localFile: /outputDir/test/meta.json
source:
mode: local
local:
tablesDir: /db/tables/
target:
mode: remote
remote:
outputDir: "migration/test/xx"
ak: xxxx
sk: xxxx
cloud: aws
endpoint: 0.0.0.0:9000
region: ap-southeast-1
bucket: a-bucket
useIAM: false
useSSL: false
checkBucket: true
milvus2x:
endpoint: localhost:19530
username: xxxxx
password: xxxxx
Eine ausführlichere Erklärung der Konfigurationsdatei finden Sie auf dieser Seite auf GitHub.
- Migrationsauftrag ausführen
Sie müssen die Befehle dump und load separat ausführen, um die Migration abzuschließen. Diese Befehle konvertieren die Daten und importieren sie in Milvus 2.x.
Hinweis: Wir werden diesen Schritt in Kürze vereinfachen und Benutzern ermöglichen, die Migration mit nur einem Befehl abzuschließen. Bleiben Sie dran.
Dump-Befehl:
./milvus-migration dump --config=/{YourConfigFilePath}/migration.yaml
Load-Befehl:
./milvus-migration load --config=/{YourConfigFilePath}/migration.yaml
Nach der Migration enthält die generierte Collection in Milvus 2.x zwei Felder: id und data. Weitere Details können Sie mit Attu anzeigen, einem All-in-one-Administrationstool für Vektordatenbanken.
Migration von FAISS zu Milvus 2.x
- FAISS-Daten vorbereiten
Um Elasticsearch-Daten zu migrieren, sollten Sie Ihre eigenen FAISS-Daten bereithalten. Damit Sie den Migrationsprozess schnell ausprobieren können, haben wir einige FAISS-Testdaten im Quellcode von Milvus Migration bereitgestellt.
- Kompilieren und erstellen
Laden Sie zunächst den Quellcode von Milvus Migration von GitHub herunter. Führen Sie dann die folgenden Befehle aus, um ihn zu kompilieren.
go get
go build
Dieser Schritt erzeugt eine ausführbare Datei namens milvus-migration.
migration.yamlkonfigurieren
Bereiten Sie eine migration.yaml-Konfigurationsdatei für die FAISS-Migration vor, in der Details zur Quelle, zum Ziel und zu anderen relevanten Einstellungen angegeben werden. Hier ist eine Beispielkonfiguration:
# Configuration for FAISS to Milvus 2.x migration
dumper:
worker:
limit: 2
workMode: FAISS
reader:
bufferSize: 1024
writer:
bufferSize: 1024
loader:
worker:
limit: 2
source:
mode: local
local:
FAISSFile: ./testfiles/FAISS/FAISS_ivf_flat.index
target:
create:
collection:
name: test1w
shardsNums: 2
dim: 256
metricType: L2
mode: remote
remote:
outputDir: testfiles/output/
cloud: aws
endpoint: 0.0.0.0:9000
region: ap-southeast-1
bucket: a-bucket
ak: minioadmin
sk: minioadmin
useIAM: false
useSSL: false
checkBucket: true
milvus2x:
endpoint: localhost:19530
username: xxxxx
password: xxxxx
Eine ausführlichere Erklärung der Konfigurationsdatei finden Sie auf dieser Seite auf GitHub.
- Migrationsauftrag ausführen
Wie bei der Migration von Milvus 1.x zu Milvus 2.x erfordert die FAISS-Migration die Ausführung sowohl des Befehls dump als auch des Befehls load. Diese Befehle konvertieren die Daten und importieren sie in Milvus 2.x.
Hinweis: Wir werden diesen Schritt in Kürze vereinfachen und Benutzern ermöglichen, die Migration mit nur einem Befehl abzuschließen. Bleiben Sie dran.
Dump-Befehl:
./milvus-migration dump --config=/{YourConfigFilePath}/migration.yaml
Load-Befehl:
./milvus-migration load --config=/{YourConfigFilePath}/migration.yaml
Weitere Details können Sie mit Attu anzeigen, einem All-in-one-Administrationstool für Vektordatenbanken.
Bleiben Sie gespannt auf zukünftige Migrationspläne
In Zukunft werden wir die Migration aus weiteren Datenquellen unterstützen und weitere Migrationsfunktionen hinzufügen, darunter:
Unterstützung der Migration von Redis zu Milvus.
Unterstützung der Migration von MongoDB zu Milvus.
Unterstützung fortsetzbarer Migrationen.
Vereinfachung der Migrationsbefehle durch Zusammenführen der Dump- und Load-Prozesse in einen einzigen.
Unterstützung der Migration aus anderen gängigen Datenquellen zu Milvus.
Fazit
Milvus 2.3, die neueste Version von Milvus, bringt spannende neue Funktionen und Leistungsverbesserungen, die den wachsenden Anforderungen des Datenmanagements gerecht werden. Die Migration Ihrer Daten zu Milvus 2.x kann diese Vorteile freisetzen, und das Milvus Migration-Projekt macht den Migrationsprozess optimiert und einfach. Probieren Sie es aus, und Sie werden nicht enttäuscht sein.
Hinweis: Die Informationen in diesem Blog basieren auf dem Stand der Milvus- und Milvus Migration-Projekte im September 2023. Die aktuellsten Informationen und Anweisungen finden Sie in der offiziellen Milvus-Dokumentation.

Weiterlesen

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.