




4 Schritte zum Aufbau eines Videosuchsystems
Wie der Name schon sagt, ist die Suche nach Videos per Bild der Prozess, aus dem Repository Videos abzurufen, die ähnliche Frames wie das Eingabebild enthalten. Einer der wichtigsten Schritte besteht darin, Videos in Embeddings umzuwandeln, das heißt, die Keyframes zu extrahieren und ihre Merkmale in Vektoren umzuwandeln. Nun fragen sich einige neugierige Leser vielleicht, worin der Unterschied zwischen der Suche nach einem Video per Bild und der Suche nach einem Bild per Bild besteht? Tatsächlich entspricht die Suche nach den Keyframes in Videos der Suche nach einem Bild per Bild.
Bei Interesse können Sie unseren vorherigen Artikel Milvus x VGG: Aufbau eines inhaltsbasierten Bildabrufsystems lesen.
Systemübersicht2
Das folgende Diagramm veranschaulicht den typischen Workflow eines solchen Videosuchsystems.
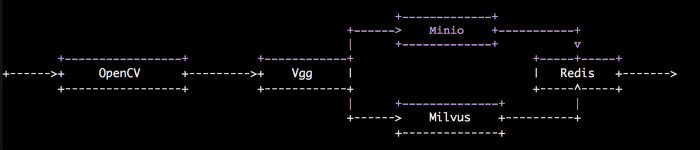 Workflow des Videosuchsystems.
Workflow des Videosuchsystems.
Beim Importieren von Videos verwenden wir die OpenCV-Bibliothek, um jedes Video in Frames zu zerlegen, Vektoren der Keyframes mithilfe des Bildmerkmalsextraktionsmodells VGG zu extrahieren und anschließend die extrahierten Vektoren (Embeddings) in Milvus einzufügen. Wir verwenden Minio zum Speichern der Originalvideos und Redis zum Speichern von Korrelationen zwischen Videos und Vektoren.
Bei der Suche nach Videos verwenden wir dasselbe VGG-Modell, um das Eingabebild in einen Merkmalsvektor umzuwandeln und ihn in Milvus einzufügen, um die Vektoren mit der größten Ähnlichkeit zu finden. Anschließend ruft das System entsprechend den Korrelationen in Redis die entsprechenden Videos aus Minio auf seiner Schnittstelle ab.
Datenvorbereitung
In diesem Artikel verwenden wir etwa 100.000 GIF-Dateien von Tumblr als Beispieldatensatz für den Aufbau einer End-to-End-Lösung zur Suche nach Videos. Sie können Ihre eigenen Video-Repositories verwenden.
Bereitstellung
Der Code zum Aufbau des Videoabrufsystems in diesem Artikel befindet sich auf GitHub.
Schritt 1: Docker-Images erstellen.
Das Videoabrufsystem benötigt Milvus v0.7.1 docker, Redis docker, Minio docker, den Docker für die Front-End-Schnittstelle und den Docker für die Back-End-API. Sie müssen den Docker für die Front-End-Schnittstelle und den Docker für die Back-End-API selbst erstellen, während Sie die anderen drei Docker direkt von Docker Hub abrufen können.
# Get the video search code
$ git clone -b 0.10.0 https://github.com/JackLCL/search-video-demo.git
# Build front-end interface docker and api docker images
$ cd search-video-demo & make all
Schritt 2: Umgebung konfigurieren.
Hier verwenden wir docker-compose.yml, um die oben genannten fünf Container zu verwalten. In der folgenden Tabelle finden Sie die Konfiguration von docker-compose.yml:
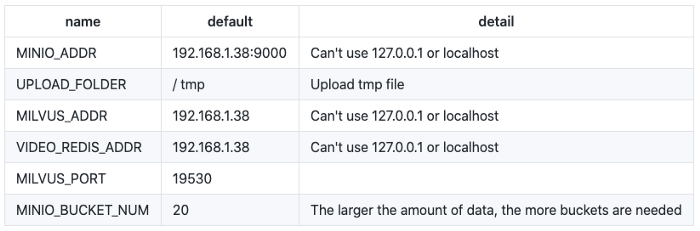 Docker Compose konfigurieren.
Docker Compose konfigurieren.
Die IP-Adresse 192.168.1.38 in der obigen Tabelle ist die Serveradresse speziell für den Aufbau des Videoabrufsystems in diesem Artikel. Sie müssen sie auf Ihre Serveradresse aktualisieren.
Sie müssen die Speicherverzeichnisse für Milvus, Redis und Minio manuell erstellen und dann die entsprechenden Pfade in docker-compose.yml hinzufügen. In diesem Beispiel haben wir die folgenden Verzeichnisse erstellt:
/mnt/redis/data /mnt/minio/data /mnt/milvus/db
Sie können Milvus, Redis und Minio in docker-compose.yml wie folgt konfigurieren:
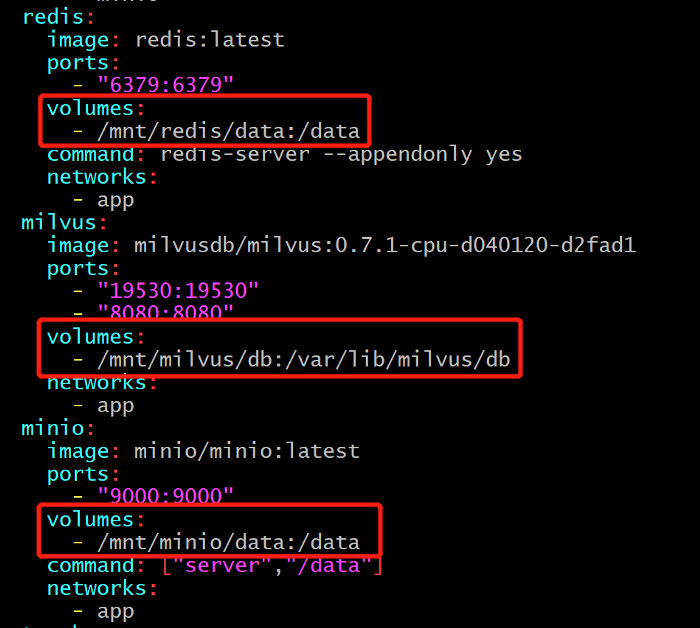 Milvus, Redis, MinIO, Docker-compose konfigurieren.
Milvus, Redis, MinIO, Docker-compose konfigurieren.
Schritt 3: System starten.
Verwenden Sie die geänderte docker-compose.yml, um die fünf Docker-Container zu starten, die im Videoabrufsystem verwendet werden sollen:
$ docker-compose up -d
Dann können Sie docker-compose ps ausführen, um zu überprüfen, ob die fünf Docker-Container ordnungsgemäß gestartet wurden. Der folgende Screenshot zeigt eine typische Oberfläche nach einem erfolgreichen Start.
 Erfolgreiche Einrichtung.
Erfolgreiche Einrichtung.
Jetzt haben Sie erfolgreich ein Videosuchsystem aufgebaut, auch wenn die Datenbank noch keine Videos enthält.
Schritt 4: Videos importieren.
Im Verzeichnis deploy des System-Repositorys befindet sich import_data.py, ein Skript zum Importieren von Videos. Sie müssen nur den Pfad zu den Videodateien und das Importintervall aktualisieren, um das Skript auszuführen.
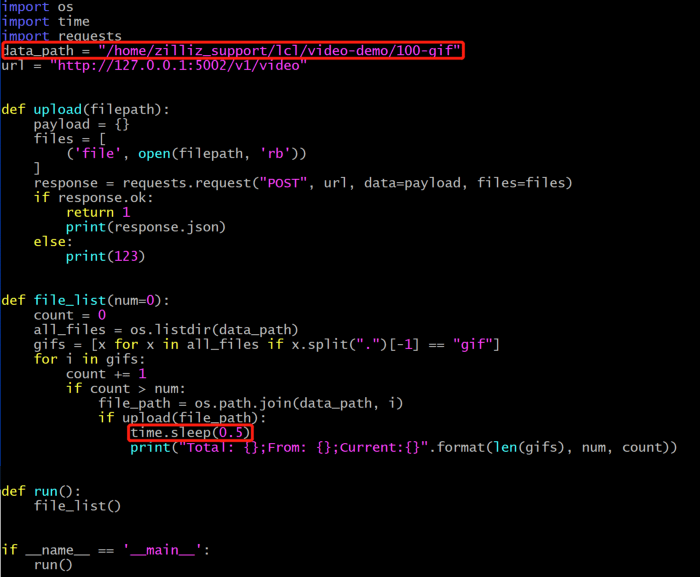 Videopfad aktualisieren.
Videopfad aktualisieren.
data_path: Der Pfad zu den zu importierenden Videos.
time.sleep(0.5): Das Intervall, in dem das System Videos importiert. Der Server, den wir zum Aufbau des Videosuchsystems verwenden, verfügt über 96 CPU-Kerne. Daher wird empfohlen, das Intervall auf 0,5 Sekunden zu setzen. Setzen Sie das Intervall auf einen höheren Wert, wenn Ihr Server weniger CPU-Kerne hat. Andernfalls belastet der Importvorgang die CPU und erzeugt Zombie-Prozesse.
Führen Sie import_data.py aus, um Videos zu importieren.
$ cd deploy
$ python3 import_data.py
Sobald die Videos importiert sind, ist Ihr eigenes Videosuchsystem einsatzbereit!
Anzeige der Benutzeroberfläche
Öffnen Sie Ihren Browser und geben Sie 192.168.1.38:8001 ein, um die Oberfläche des Videosuchsystems wie unten gezeigt anzuzeigen.
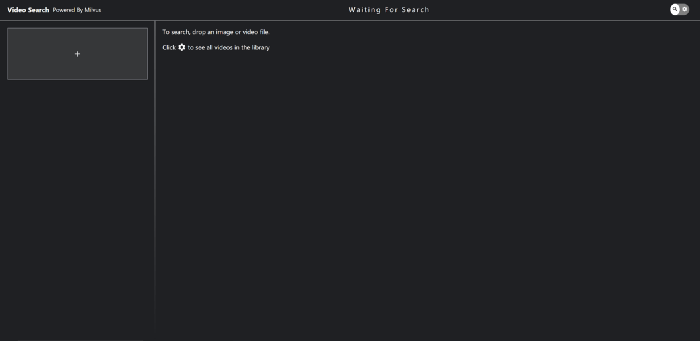 Videosuchoberfläche.
Videosuchoberfläche.
Schalten Sie den Zahnrad-Schalter oben rechts um, um alle Videos im Repository anzuzeigen.
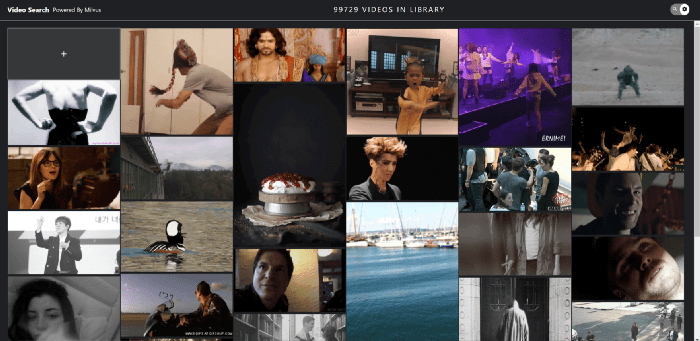 Alle Videos anzeigen.
Alle Videos anzeigen.
Klicken Sie auf das Upload-Feld oben links, um ein Zielbild einzugeben. Wie unten gezeigt, gibt das System Videos zurück, die die ähnlichsten Frames enthalten.
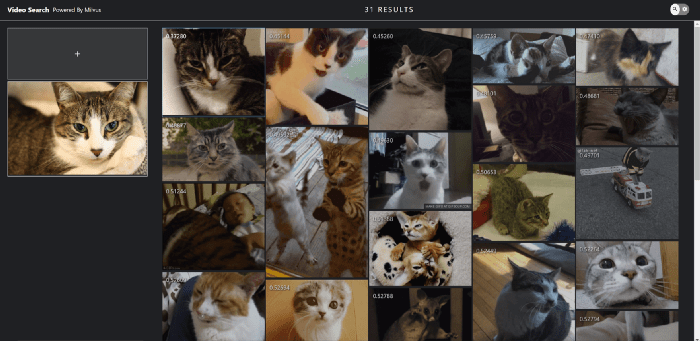 Ein Katzen-Empfehlungssystem genießen.
Ein Katzen-Empfehlungssystem genießen.
Viel Spaß als Nächstes mit unserem Videosuchsystem!
Erstellen Sie Ihr eigenes
In diesem Artikel haben wir Milvus verwendet, um ein System zur Suche nach Videos anhand von Bildern zu erstellen. Dies veranschaulicht die Anwendung von Milvus in der Verarbeitung unstrukturierter Daten.
Milvus ist mit mehreren Deep-Learning-Frameworks kompatibel und ermöglicht Suchen im Millisekundenbereich für Vektoren im Milliardenmaßstab. Nehmen Sie Milvus gerne mit in weitere KI-Szenarien: https://github.com/milvus-io/milvus.
Seien Sie kein Fremder, folgen Sie uns auf Twitter oder treten Sie uns auf Slack!👇🏻
Weiterlesen

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Introducing Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud
We're announcing the general availability of Customer-Managed Encryption Keys (CMEK) on Zilliz Cloud.

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.