




Aufbau eines intelligenten QA-Systems mit NLP und Milvus
Milvus-Projekt:github.com/milvus-io/milvus
Das Frage-Antwort-System wird häufig im Bereich der Verarbeitung natürlicher Sprache eingesetzt. Es dient dazu, Fragen in natürlicher Sprache zu beantworten, und hat ein breites Anwendungsspektrum. Typische Anwendungen umfassen: intelligente Sprachinteraktion, Online-Kundendienst, Wissenserwerb, personalisierte emotionale Chats und mehr. Die meisten Frage-Antwort-Systeme lassen sich klassifizieren als: generative und Retrieval-Frage-Antwort-Systeme, Single-Round-Frage-Antwort- und Multi-Round-Frage-Antwort-Systeme, offene Frage-Antwort-Systeme und spezifische Frage-Antwort-Systeme.
Dieser Artikel befasst sich hauptsächlich mit einem QA-System, das für ein bestimmtes Fachgebiet entwickelt wurde und üblicherweise als intelligenter Kundendienst-Roboter bezeichnet wird. In der Vergangenheit erforderte der Aufbau eines Kundendienst-Roboters in der Regel die Umwandlung des Domänenwissens in eine Reihe von Regeln und Wissensgraphen. Der Konstruktionsprozess stützte sich stark auf „menschliche“ Intelligenz. Sobald sich die Szenarien änderten, war viel repetitive Arbeit erforderlich. Mit der Anwendung von Deep Learning in der Verarbeitung natürlicher Sprache (NLP) kann maschinelles Lesen automatisch Antworten auf passende Fragen direkt aus Dokumenten finden. Das Deep-Learning-Sprachmodell wandelt die Fragen und Dokumente in semantische Vektoren um, um die passende Antwort zu finden.
Dieser Artikel verwendet Googles Open-Source-BERT-Modell und Milvus, eine Open-Source-Vektorsuchmaschine, um schnell einen Q&A-Bot auf Basis semantischen Verständnisses zu erstellen.
Gesamtarchitektur
Dieser Artikel implementiert ein Frage-Antwort-System durch semantisches Ähnlichkeitsmatching. Der allgemeine Aufbauprozess ist wie folgt:
- Eine große Anzahl von Fragen mit Antworten in einem bestimmten Fachgebiet erhalten (ein Standard-Fragenset).
- Das BERT-Modell verwenden, um diese Fragen in Merkmalsvektoren umzuwandeln und sie in Milvus zu speichern. Und Milvus weist gleichzeitig jedem Merkmalsvektor eine Vektor-ID zu.
- Diese repräsentativen Frage-IDs und ihre entsprechenden Antworten in PostgreSQL speichern.
Wenn ein Benutzer eine Frage stellt:
- Das BERT-Modell wandelt sie in einen Merkmalsvektor um.
- Milvus führt eine Ähnlichkeitssuche durch und ruft die ID ab, die der Frage am ähnlichsten ist.
- PostgreSQL gibt die entsprechende Antwort zurück.
Das Systemarchitekturdiagramm ist wie folgt (die blauen Linien stellen den Importprozess dar und die gelben Linien stellen den Abfrageprozess dar):
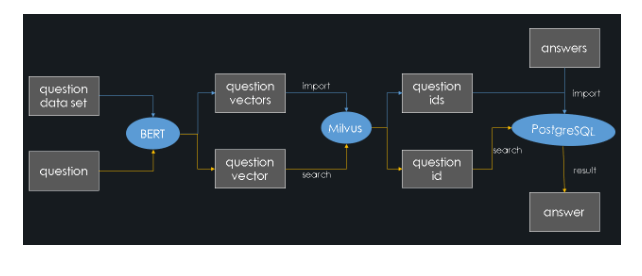 Figure 1.
Figure 1.
Als Nächstes zeigen wir Ihnen Schritt für Schritt, wie Sie ein Online-Q&A-System erstellen.
Schritte zum Aufbau des Q&A-Systems
Bevor Sie beginnen, müssen Sie Milvus und PostgreSQL installieren. Die spezifischen Installationsschritte finden Sie auf der offiziellen Milvus-Website.
1. Datenvorbereitung
Die experimentellen Daten in diesem Artikel stammen von: https://github.com/chatopera/insuranceqa-corpus-zh
Der Datensatz enthält Frage- und Antwortdatenpaare im Zusammenhang mit der Versicherungsbranche. In diesem Artikel extrahieren wir daraus 20.000 Frage-Antwort-Paare. Mithilfe dieses Frage- und Antwortdatensatzes können Sie schnell einen Kundendienst-Roboter für die Versicherungsbranche erstellen.
2. Merkmalsvektoren generieren
Dieses System verwendet ein Modell, das BERT vortrainiert hat. Laden Sie es über den untenstehenden Link herunter, bevor Sie einen Dienst starten: https://storage.googleapis.com/bert_models/2018_10_18/cased_L-24_H-1024_A-16.zip
Verwenden Sie dieses Modell, um die Fragendatenbank in Merkmalsvektoren für die zukünftige Ähnlichkeitssuche umzuwandeln. Weitere Informationen zum BERT-Dienst finden Sie unter https://github.com/hanxiao/bert-as-service.
 Figure 2.
Figure 2.
3. In Milvus und PostgreSQL importieren
Normalisieren und importieren Sie die generierten Merkmalsvektoren in Milvus und importieren Sie anschließend die von Milvus zurückgegebenen IDs und die entsprechenden Antworten in PostgreSQL. Im Folgenden wird die Tabellenstruktur in PostgreSQL gezeigt:
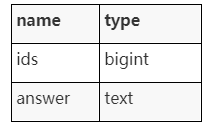 Figure 3.
Figure 3.
 Abbildung 4.
Abbildung 4.
4. Antworten abrufen
Der Benutzer gibt eine Frage ein, und nachdem der Merkmalsvektor durch BERT generiert wurde, kann er die ähnlichste Frage in der Milvus-Bibliothek finden. Dieser Artikel verwendet die Kosinusdistanz, um die Ähnlichkeit zwischen zwei Sätzen darzustellen. Da alle Vektoren normalisiert sind, gilt: Je näher die Kosinusdistanz der beiden Merkmalsvektoren bei 1 liegt, desto höher ist die Ähnlichkeit.
In der Praxis enthält Ihr System möglicherweise keine perfekt passenden Fragen in der Bibliothek. Dann können Sie einen Schwellenwert von 0,9 festlegen. Wenn die größte abgerufene Ähnlichkeitsdistanz unter diesem Schwellenwert liegt, meldet das System, dass es keine verwandten Fragen enthält.
 Abbildung 5.
Abbildung 5.
Systemdemonstration
Im Folgenden wird eine Beispieloberfläche des Systems gezeigt:
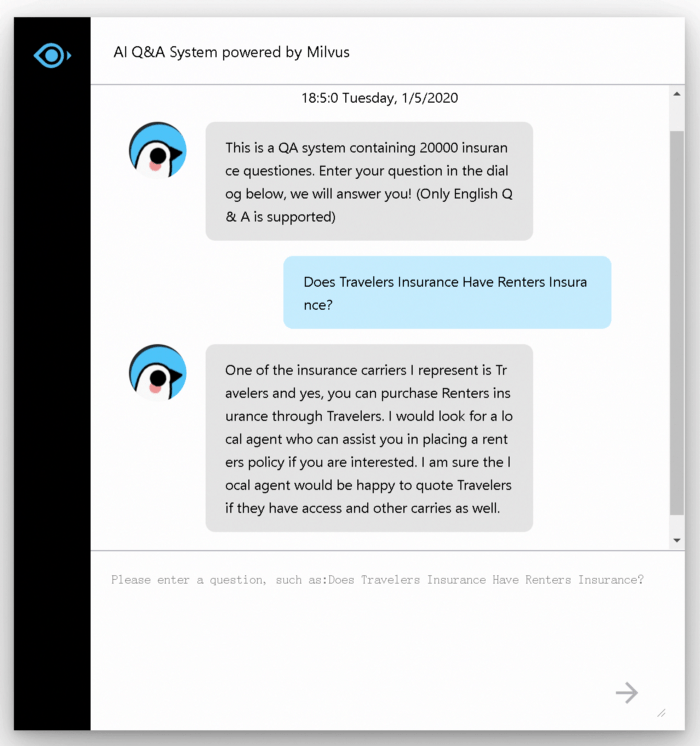 Abbildung 6.
Abbildung 6.
Geben Sie Ihre Frage in das Dialogfeld ein und Sie erhalten eine entsprechende Antwort:
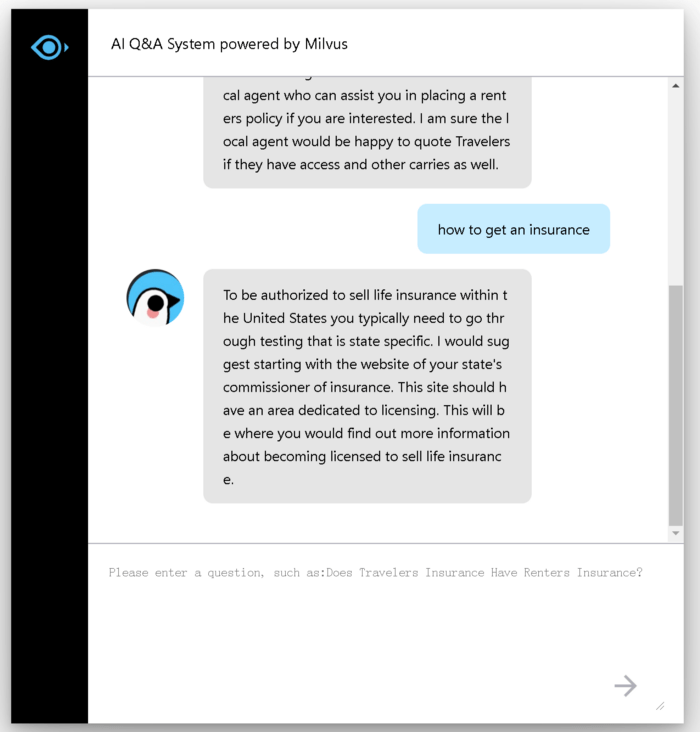 Abbildung 7.
Abbildung 7.
Zusammenfassung
Nach der Lektüre dieses Artikels hoffen wir, dass Sie es einfach finden, Ihr eigenes Q&A-System zu erstellen.
Mit dem BERT-Modell müssen Sie die Textkorpora nicht mehr im Voraus sortieren und organisieren. Gleichzeitig kann Ihr QA-System dank der hohen Leistung und hohen Skalierbarkeit der Open-Source-Vektorsuchmaschine Milvus ein Korpus von bis zu Hunderten Millionen Texten unterstützen.
Milvus ist offiziell der Linux AI (LF AI) Foundation zur Inkubation beigetreten. Sie sind herzlich eingeladen, der Milvus-Community beizutreten und mit uns daran zu arbeiten, die Anwendung von KI-Technologien zu beschleunigen!
=> Testen Sie hier unsere Online-Demo: https://www.milvus.io/scenarios
Weiterlesen

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.