




Webinar-Zusammenfassung: Verbessern Sie Ihr LLM mit privaten Daten mithilfe von LlamaIndex
Die Popularität von ChatGPT hat die Fähigkeiten großer Sprachmodelle (LLMs) bei der Generierung von Wissen und Schlussfolgerungen demonstriert. Allerdings wird ChatGPT mit öffentlich verfügbaren Daten vortrainiert, die möglicherweise keine spezifischen Antworten und Ergebnisse liefern, die für Ihr Unternehmen relevant sind. Wie können wir unsere LLMs also am besten mit privaten Daten erweitern? LlamaIndex ist eine der beliebtesten Lösungen. Es ist eine einfache, flexible, zentralisierte Schnittstelle, die Ihre externen Daten und LLMs verbindet.
In unserem jüngsten Webinar erklärte Jerry Liu, Mitgründer und CEO von LlamaIndex, wie LlamaIndex Ihre LLMs mit privaten Daten verbessern kann. Darüber hinaus teilte auch Frank Liu, Machine Learning Architect und Director of Operations bei Zilliz, seine Einblicke in LLMs. Begleiten Sie mich bei der Erkundung der wichtigsten Erkenntnisse aus diesem Webinar und bei der Beantwortung einiger unbeantworteter Fragen aus dem Publikum.
Fine-Tuning und In-Context-Learning
„Wie man LLMs mit privaten Daten erweitert“ ist eine Frage, die sich viele LLM-Entwickler stellen würden. Im Webinar erörterte Jerry zwei Methoden: Fine-Tuning und In-Context-Learning. Fine-Tuning erfordert ein erneutes Training des Netzwerks mit privaten Daten, kann jedoch kostspielig sein und es mangelt an Transparenz. Außerdem ist es möglicherweise nur in einigen Fällen wirksam. In-Context-Learning hingegen umfasst die Kombination eines vortrainierten Modells mit externem Wissen und einem Retrieval-Modell, um dem Eingabe-Prompt Kontext hinzuzufügen. Allerdings ergeben sich Herausforderungen bei der Kombination von Retrieval und Generierung, beim Abrufen des passenden Kontexts und beim Verwalten umfangreicher Quelldaten. LlamaIndex ist ein Toolkit, das dafür entwickelt wurde, die Herausforderungen des In-Context-Learnings zu bewältigen.
Was ist LlamaIndex?
LlamaIndex ist ein Open-Source-Tool, das die zentrale Datenverwaltungs- und Abfrageschnittstelle für Ihre LLM-Anwendungen bereitstellt. Sein Toolkit enthält drei Hauptkomponenten:
- Datenkonnektoren zum Erfassen von Daten aus verschiedenen Quellen.
- Datenindizes zur Strukturierung von Daten für verschiedene Anwendungsfälle.
- Eine Abfrageschnittstelle zum Eingeben von Prompts und Empfangen der wissensgestützten Ausgabe.
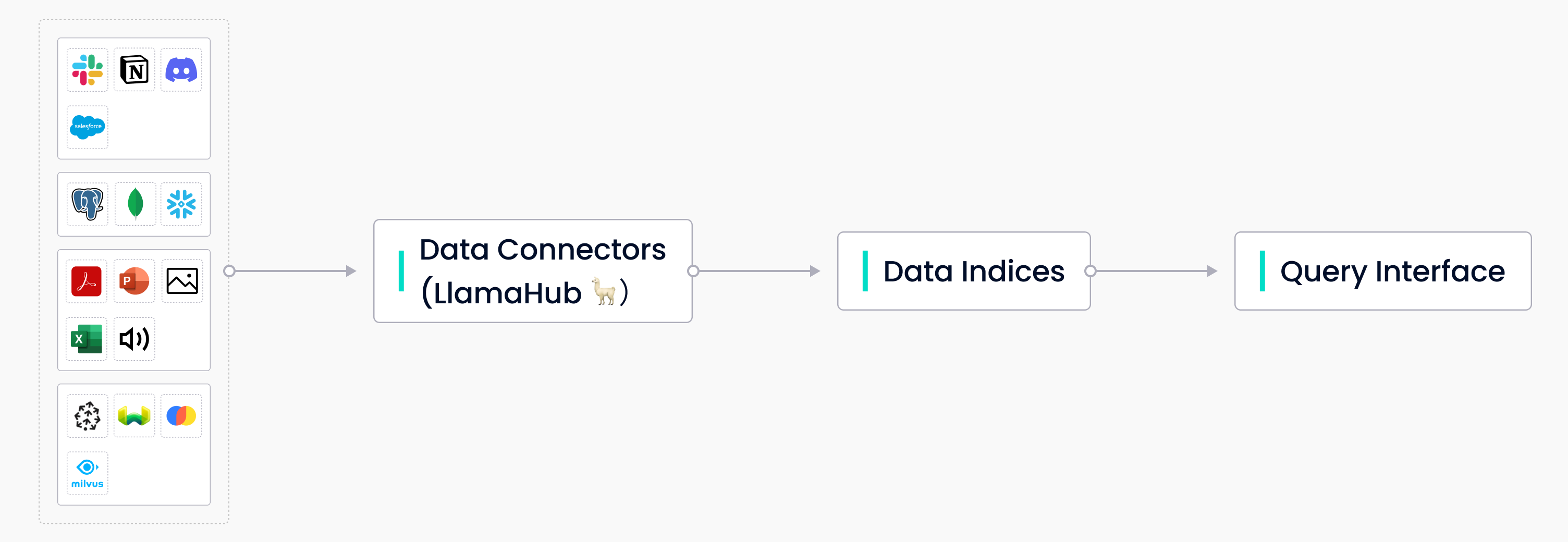 Drei Hauptkomponenten von LlamaIndex
Drei Hauptkomponenten von LlamaIndex
LlamaIndex ist auch ein wertvolles Tool für die Entwicklung von LLM-Anwendungen. Es funktioniert wie eine Blackbox, nimmt detaillierte Abfragebeschreibungen entgegen und liefert umfassende Antworten, die Referenzen und Aktionen enthalten. LlamaIndex verwaltet außerdem die Interaktionen zwischen dem Sprachmodell und privaten Daten, um genaue und gewünschte Ergebnisse bereitzustellen.
 LlamaIndex im Kontext
LlamaIndex im Kontext
Wie der Vector-Store-Index von LlamaIndex funktioniert
LlamaIndex verfügt über verschiedene Indizes, darunter den Listenindex, den Vector-Store-Index, den Baumindex und den Keyword-Index. Jerry verwendete im Webinar den Vector-Store-Index, um Ihnen zu zeigen, wie LlamaIndex-Indizes funktionieren.
Der Vector-Store-Index ist ein beliebter Modus für Retrieval und Synthese, der einen Vector Store mit einem Sprachmodell kombiniert. Eine Reihe von Quelldokumenten wird erfasst, in Textknoten aufgeteilt und im Vector Store gespeichert, wobei an jeden Knoten ein Embedding angehängt ist. Wenn Sie eine Abfrage stellen, durchsucht ein Abfrage-Embedding den Vector Store nach den top-k ähnlichsten Knoten; diese Knoten werden dann im Antwortsynthesemodul verwendet, um eine Antwort zu generieren.
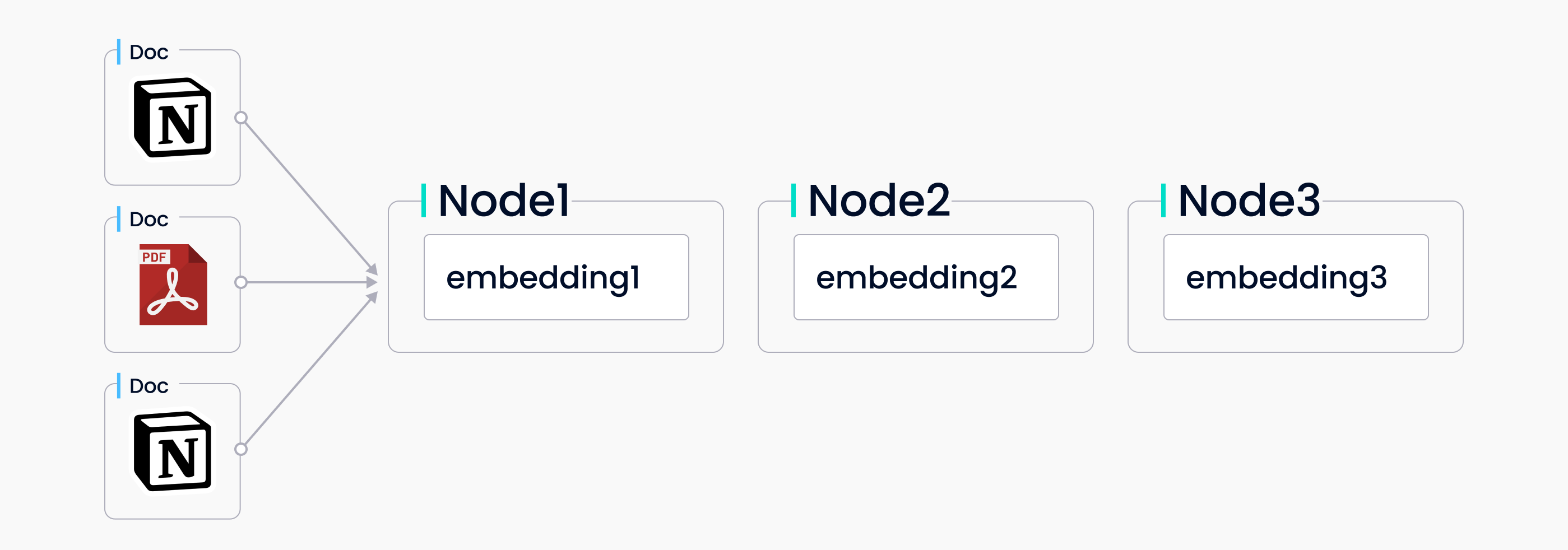 Datenaufnahme in LlamaIndex
Datenaufnahme in LlamaIndex
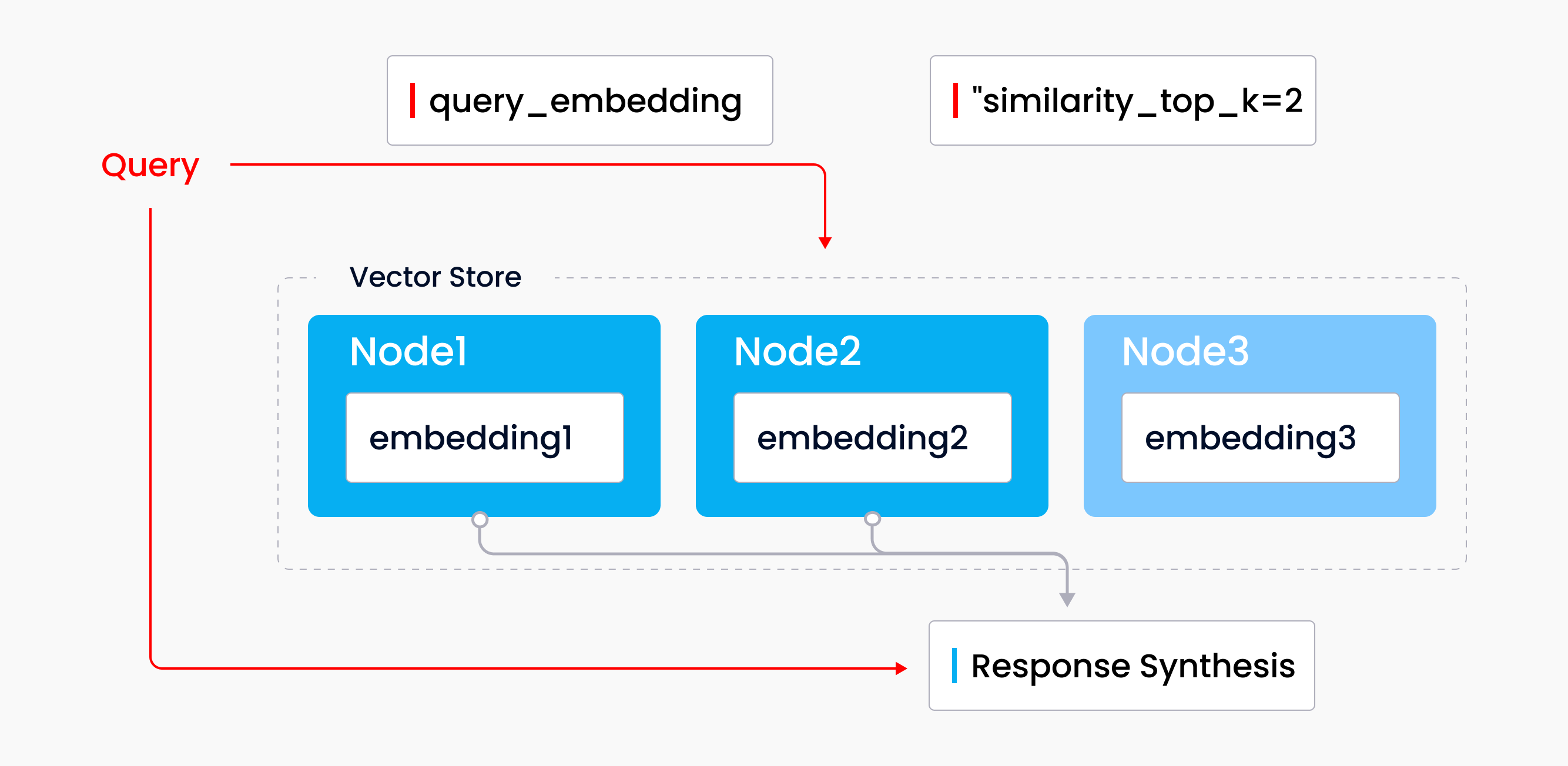 Abfrage über den Vector-Store-Index
Abfrage über den Vector-Store-Index
Die Verwendung eines Vektorspeicherindex ist der beste Ansatz, um Ähnlichkeit in deine LLM-Anwendung einzuführen. Dieser Indextyp ist ideal für Workflows, die Texte auf semantische Ähnlichkeit vergleichen. Beispielsweise wäre ein Vektorspeicherindex geeignet, um Fragen zu einer bestimmten Open-Source-Software zu stellen.
Die Integration von Milvus und LlamaIndex
LlamaIndex bietet zahlreiche Integrationen, die sowohl leistungsstark als auch leichtgewichtig sind. Im Webinar hob Jerry die Integration von Milvus und LlamaIndex hervor.
Milvus ist eine Vektordatenbank, die Open Source ist und in der Lage ist, riesige Datensätze zu verarbeiten, die Millionen, Milliarden oder sogar Billionen von Vektoren enthalten. Mit der Integration fungiert Milvus als Backend-Vektorspeicher für Embeddings und Text. Die Einrichtung der Integration ist einfach: mehrere Parameter eingeben, sie in einen Storage Context einbetten und sie dann in den Vektorspeicherindex einfügen. Die Abfrage des Index erfolgt über die Query Engine, und du erhältst die benötigten Antworten.
Zilliz Cloud ist ein vollständig verwalteter und Cloud-nativer Dienst für Milvus, und die Integration von LlamaIndex und Zilliz Cloud ist ebenfalls verfügbar.
Anwendungsfälle von LlamaIndex
Im Webinar stellte Jerry außerdem viele beliebte Anwendungsfälle von LlamaIndex vor, darunter:
- Semantische Suche
- Zusammenfassung
- Text zu SQL (strukturierte Daten)
- Synthese über heterogene Daten
- Vergleichs-/Kontrastabfragen
- Mehrstufige Abfragen
- Nutzung zeitlicher Beziehungen
- Aktualitätsfilterung / veraltete Knoten
Für detaillierte Beschreibungen und Informationen sieh dir die vollständige Webinar-Aufzeichnung an.
Fragen und Antworten
Während des Webinars erhielten wir viele Fragen aus unserem Publikum und schätzten dessen Engagement. Jerry beantwortete einige der Fragen während der Fragerunde, aber aus Zeitgründen blieben einige unbeantwortet. Unten haben wir eine Liste der am häufigsten gestellten Fragen und der unbeantworteten Fragen zusammen mit Jerrys Antworten zusammengestellt.
F: Was hältst du von OpenAIs Plugins, und wie würde LlamaIndex mit ihnen funktionieren?
Das ist eine gute Frage. Wir sehen uns auf beiden Seiten der Plugin-Landschaft. Einerseits sehen wir uns als ein wirklich gutes Plugin, das von jeder äußeren Agentenabstraktion aufgerufen werden kann (egal ob ChatGPT, LangChain oder mehr). Ein Client-Agent würde eine Eingabeanforderung an uns weitergeben, und wir würden herausfinden, wie wir diese Anforderung im Hintergrund am besten ausführen. Beispielsweise sind wir ein Plugin im chatgpt-retrieval-plugin repo. Auf der Client-Seite unterstützen wir die Integration mit allen Diensten, die das chatgpt-retrieval-plugin implementieren – eine „Vektorspeicher“-Abstraktion.
F: Du hast Kompromisse bei Leistung und Latenz erwähnt. Was sind einige Engpässe und Herausforderungen in diesem Bereich, denen du begegnest?
Größere Mengen an Kontext + größere Chunk-Größe = höhere Latenz. Es gibt eine Debatte darüber, ob größere Chunk-Größen immer zu besseren Ergebnissen führen (GPT-4 ist empirisch besser im Umgang mit umfangreicheren Kontextmengen als GPT-3). Dennoch gibt es hier im Allgemeinen eine positive Korrelation. Ein weiterer Kompromiss besteht darin, dass jedes „fortgeschrittene“ LLM-System, z. B. unter Einbeziehung von Agenten, verkettete LLM-Aufrufe erfordert. Verkettete LLM-Aufrufe dauern grundsätzlich länger in der Ausführung.
F: Ich verstehe, dass wir ein externes Modell verwenden, um die Abfragen auszuführen. Wie sicher sind die privaten Daten, die übertragen werden?
Das hängt vom API-Dienst ab. Beispielsweise verwendet OpenAI keine API-Daten, um seine Modelle zu trainieren/verbessern, aber es wird dennoch Bedenken von Unternehmen geben, sensible Daten an einen Drittanbieter zu senden. Wir haben kürzlich einige PII-Module hinzugefügt, um dies abzumildern. Eine weitere Alternative ist die Verwendung lokaler Modelle.
F: Was sind die Vor- und Nachteile der beiden Ansätze: (a) Nutzung einer Vektordatenbank wie Milvus für erweiterte Ähnlichkeitssuche und Graph-Optimierungen VOR dem Laden in LlamaIndex und der Indexierung dort sowie der Anbindung an ein LLM; (b) Verwendung nativer LlamaIndex-Integrationen mit Vektorspeichern?
Sie können beides tun. Wir planen, diese beiden Ansätze etwas stärker zusammenzuführen, bleiben Sie also dran. Auf einer sehr hohen Ebene ermöglicht Ihnen die Verwendung von Milvus zunächst als Daten-Loader, vorhandene Daten mit LlamaIndex zu verwenden. Wenn Sie hingegen unseren von Milvus unterstützten Vektorindex verwenden, definieren wir zusätzliche Strukturen auf diesen Daten. Der Vorteil des ersten Ansatzes ist, dass Sie vorhandene Daten nutzen können, und der Vorteil des zweiten ist, dass wir mehr Kontrolle bei der Definition von Metadaten haben.
F: Ich muss ungefähr 6.000 PDFs und PowerPoints lokal analysieren. Was würden Sie mir empfehlen, um die besten Ergebnisse zu erzielen, ohne OpenAI, LlamaIndex, mit llama65b zu verwenden?
Sie können versuchen, Llama zu verwenden, wenn die Lizenz für Sie in Ordnung ist. Sehen Sie sich die Open-Source-Modelle auf GitHub an.
Sehen Sie sich die vollständige Webinar-Aufzeichnung an!
Sehen Sie sich die Webinar-Aufzeichnung an, um weitere Informationen über LlamaIndex und die Diskussionen zwischen Jerry Liu und Frank Liu zu erhalten.

Weiterlesen

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.

Zilliz Cloud BYOC Upgrades: Bring Enterprise-Grade Security, Networking Isolation, and More
Discover how Zilliz Cloud BYOC brings enterprise-grade security, networking isolation, and infrastructure automation to vector database deployments in AWS