




Noch ein weiterer Cache, aber für ChatGPT
ChatGPT ist eine beeindruckende Technologie, die es Entwicklern ermöglicht, bahnbrechende Anwendungen zu erstellen. Allerdings sind die Leistung und die Kosten von Sprachmodell-Modellen (LLMs) erhebliche Probleme, die ihre breite Anwendung in verschiedenen Bereichen behindern. Als wir beispielsweise einen Chatbot https://osschat.io/ für die Open-Source-Community entwickelten, war ChatGPT ein großer Engpass, der verhinderte, dass unsere Anwendung so schnell wie erwartet reagierte. Die Kosten sind ebenfalls ein weiteres Hindernis, das uns daran hindert, mehr Open-Source-Communitys zu bedienen.
Bei einem Team-Mittagessen kam uns eine Idee: Warum nicht eine weitere Cache-Schicht für die von LLM generierten Antworten hinzufügen? Diese Caching-Schicht wäre ähnlich wie Redis und Memcache in der Vergangenheit entwickelt wurden, um den Zugriff auf Datenbanken zu beschleunigen und die Kosten zu senken. Mit diesem Cache können wir die Ausgaben für die Generierung von Inhalten verringern und schnellere Echtzeitantworten bereitstellen. Zusätzlich kann der Cache verwendet werden, um Antworten zu simulieren, was uns hilft, die Funktionen unserer Anwendung zu verifizieren, ohne zusätzliche Ausgaben für unsere Tests zu verursachen.
Traditionelle Caches rufen Daten nur ab, wenn der Schlüssel identisch ist. Diese Einschränkung stellt ein erhebliches Problem für AIGC-Anwendungen dar, die häufig mit natürlicher Sprache arbeiten und spezifischere Syntaxbeschränkungen oder zusätzliche Mechanismen zur Datenbereinigung benötigen. Um dieses Problem zu lösen, haben wir Yet Another Cache für AIGC-native Anwendungen entwickelt, den wir GPTCache (https://github.com/zilliztech/GPTCache) genannt haben, da er nativ entwickelt wurde, um ChatGPT zu beschleunigen, und für die semantische Suche optimiert ist.
Mit GPTCache können Sie Ihre LLM-Antworten mit nur wenigen Zeilen Codeänderungen zwischenspeichern und Ihre LLM-Anwendungen 100-mal schneller machen. In diesem Blogbeitrag beschreiben wir, wie wir den semantischen Cache aufgebaut haben und einige der Designentscheidungen, die wir getroffen haben.
Warum würde ein Cache bei unseren Anwendungsfällen helfen?
Unser Chatbot ermöglicht es Benutzern, allgemeine Fragen zu Open-Source-Projekten auf GitHub und detaillierte Fragen zu bestimmten GitHub-Repositories und den zugehörigen Dokumentationsseiten zu stellen. Mit der zunehmenden Beliebtheit unseres Dienstes steigen die Ausgaben im Zusammenhang mit dem Aufrufen der OpenAI-APIs. Wir haben beobachtet, dass bestimmte Arten von Inhalten, wie beliebte oder trendende Themen und beliebte GitHub-Repositories, häufiger aufgerufen werden. „Was ist“-Fragen werden am häufigsten aufgerufen, ebenso wie die Liste empfohlener Fragen auf der Startseite des Dienstes.
Wie bei traditionellen Anwendungen weist der Benutzerzugriff für AIGC-Anwendungen zeitliche und räumliche Lokalität auf. Wir können dies nutzen, indem wir ein Cache-System implementieren, das die Anzahl der ChatGPT-Aufrufe reduziert. Angesichts der langsamen Antwortzeit und der hohen Kosten der OpenAI-APIs ist dieses Cache-System unerlässlich, da diese typischerweise mehrere Dollar pro 1 Mio. Token berechnen und einige Sekunden für eine Antwort benötigen. Durch die Durchführung einer Vektorsuche unter Millionen von zwischengespeicherten Vektoren und das Abrufen des zwischengespeicherten Ergebnisses aus einer Datenbank können wir die durchschnittliche End-to-End-Antwortzeit unseres Dienstes erheblich reduzieren und die Kosten des OpenAI-Dienstes senken.
Warum funktioniert Redis in AIGC-Szenarien nicht?
Ich bin ein großer Fan von Redis wegen seiner Flexibilität und Leistung, die es für verschiedene Anwendungsfälle geeignet machen. Allerdings ist es nicht meine erste Wahl für den Aufbau eines Caches für ChatGPT. Redis verwendet ein Key-Value-Datenmodell und kann keine ungefähren Schlüssel abfragen.
Angenommen, ein Benutzer stellt Fragen wie „Was sind die Vor- und Nachteile aller Deep-Learning-Frameworks?“ oder „Erzähl mir von PyTorch vs. TensorFlow vs. JAX?“. In diesem Fall fragen sie nach derselben Sache. Redis trifft die Abfrage jedoch nicht, unabhängig davon, ob Sie die gesamte Frage zwischenspeichern oder nur die von einem Tokenizer generierten Schlüsselwörter zwischenspeichern. Dieser Fehlschlag liegt daran, dass verschiedene Wörter in natürlicher Sprache dieselbe Bedeutung haben können und Deep-Learning-Modelle diese Semantik besser offenlegen können als Regeln. Daher sollten wir die Vektorähnlichkeitssuche als Teil eines semantischen Caches einbeziehen.
Ein weiterer Grund, warum Redis möglicherweise nicht perfekt für AIGC-Caching geeignet ist, sind seine hohen Kosten. Die Schlüssel und Werte sind aufgrund des langen Kontexts groß, sodass das Speichern von allem in Redis schnell teuer werden kann. Caching mit einer festplattenbasierten Datenbank kann eine bessere Alternative sein, da chatGPT-Antworten langsam sind; daher spielt es keine Rolle, ob der Cache in Sub-Millisekunden oder in Dutzenden von Millisekunden antworten kann.
GPTCache von Grund auf erstellen
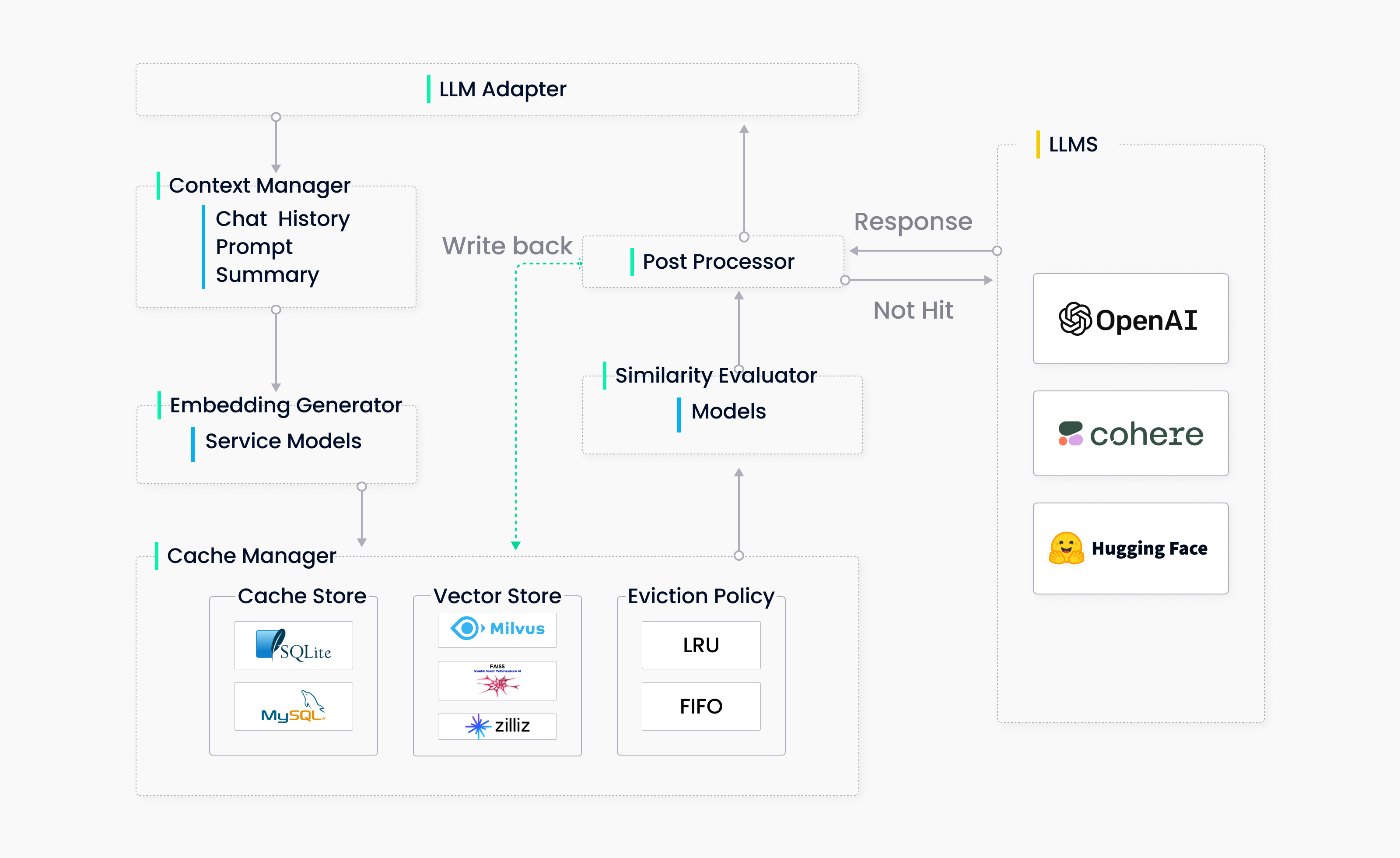
Wir sind von dieser Idee begeistert und haben sie über Nacht diskutiert. Als Ergebnis haben wir das unten gezeigte nützliche Architekturdiagramm entwickelt:
 GPTCache High Level Architecture | Zilliz
GPTCache High Level Architecture | Zilliz
Später beschlossen wir, die Implementierung zu vereinfachen, indem wir den Kontextmanager wegließen. Trotz dieser Änderungen besteht das System weiterhin aus fünf Hauptkomponenten. Wir haben die wichtigen Funktionalitäten für jede der Komponenten unten aufgeführt:
- LLM-Adapter: Adapter wandeln LLM-Anfragen in das Cache-Protokoll und die zwischengespeicherten Ergebnisse in LLM-Antworten um. Unser Ziel ist es, diesen Cache transparent zu machen, sodass kein zusätzlicher Aufwand erforderlich ist, um ihn in unser System oder ein anderes System zu integrieren, das von ChatGPT abhängt. Der Adapter sollte die einfache Integration aller LLMs erleichtern und für zukünftige multimodale Modelle erweiterbar sein. Anfangs haben wir OpenAI- und langchain-Adapter implementiert, weil unser System stark von ihnen abhängt. Mehrere Implementierungen stellten außerdem sicher, dass unsere Schnittstelle für alle LLM-APIs sinnvoll war, sodass wir den Adapter weiter erweitern konnten.
- Embedding-Generator: Der Embedding-Generator kodiert Abfragen in Embeddings und ermöglicht so Ähnlichkeitssuchen. Um den Bedürfnissen verschiedener Benutzer gerecht zu werden, unterstützen wir zwei Möglichkeiten zur Generierung von Embeddings. Die erste erfolgt über Cloud-Dienste wie OpenAI, Hugging Face und Cohere. Die zweite erfolgt über ein lokales Modell-Serving auf ONNX. Darüber hinaus planen wir, PyTorch-Embedding-Generatoren zu unterstützen und Bilder, Audiodateien sowie andere Arten unstrukturierter Daten zu kodieren.
- Cache-Manager: Der Cache-Manager ist die Kernkomponente von GPTCache und erfüllt drei Funktionen: Cache-Speicherung, die Benutzeranfragen und ihre LLM-Antworten speichert; Vektorspeicherung, die Vektor-Embeddings speichert und nach ähnlichen Ergebnissen sucht; und Eviction-Management, das die Cache-Kapazität steuert und abgelaufene Daten entfernt, wenn der Cache voll ist, wobei entweder die LRU- oder die FIFO-Richtlinie verwendet wird. Der Cache-Manager verwendet ein steckbares Design. Anfangs haben wir ihn mit SQLite und FAISS als Backend implementiert. Später haben wir ihn erweitert, um andere Implementierungen wie MySQL, PostgreSQL, Milvus und andere Vektordatenbanken einzubeziehen, wodurch er noch skalierbarer wurde. Der Eviction-Manager gibt Speicher frei, indem er alte, ungenutzte Daten aus GPTCache entfernt. Er entfernt bei Bedarf Einträge sowohl aus dem Cache als auch aus der Vektorspeicherung. Häufige Löschvorgänge in den meisten Vektorspeichersystemen können jedoch zu einem Leistungsabfall führen. GPTCache löst asynchrone Vorgänge wie Indexaufbau oder Kompaktierung aus, sobald der Löschschwellenwert erreicht ist, um dieses Problem zu entschärfen.
- Ähnlichkeitsbewerter: GPTCache ruft die top k ähnlichen Antworten aus seinem Cache ab und verwendet eine Ähnlichkeitsbewertungsfunktion, um zu bestimmen, ob eine zwischengespeicherte Antwort zur Eingabeabfrage passt. GPTCache unterstützt drei Bewertungsfunktionen: Exaktübereinstimmungsbewertung, Embedding-Distanzbewertung und ONNX-Modellbewertung. Das Ähnlichkeitsbewertungsmodul ist entscheidend für die Wirksamkeit von GPTCache. Nach einer Untersuchung haben wir eine feinabgestimmte Version des ALBERT-Modells verwendet. Es gibt jedoch immer Raum für Verbesserungen durch die Verwendung anderer feinabgestimmter Sprachmodelle oder anderer LLMs wie LLaMa-7b. Beiträge oder Vorschläge sind sehr willkommen.
- Postprozessoren: Der Postprozessor unterstützt bei der Vorbereitung der endgültigen Antwort an den Benutzer. Er kann die ähnlichste Antwort zurückgeben oder basierend auf der Anfrage-Temperatur Zufälligkeit hinzufügen. Wenn keine ähnliche Antwort im Cache gefunden werden kann, wird die Anfrage an LLMs delegiert, um eine neue Antwort zu generieren und zwischenzuspeichern.
Evaluierung
Um unsere Idee zu veranschaulichen, haben wir einen Datensatz entdeckt, der drei Satzpaare enthält: positive Beispiele mit identischer Semantik, negative Beispiele mit verwandter, aber nicht identischer Semantik, und Sätze zwischen positiven und negativen Beispielen mit vollständig unverwandter Semantik. Sie finden den Datensatz in unserem Repo.
Experiment 1
Um eine Baseline festzulegen, speichern wir zunächst die Schlüssel aller 30.000 positiven Beispiele im Cache. Als Nächstes wählen wir zufällig 1.000 Beispiele aus und verwenden deren Peer-Werte als Abfragen. Hier sind die Ergebnisse, die wir erhalten haben:
| Cache-Treffer | Cache-Fehlzugriff | Positiv | Negativ | Trefferlatenz |
|---|---|---|---|---|
| 876 | 124 | 837 | 39 | 0,20s |
Wir haben festgestellt, dass das Setzen des Ähnlichkeitsschwellenwerts von GPTCache auf 0.7 ein gutes Gleichgewicht zwischen der Trefferquote und der positiven Quote erzielt. Daher werden wir diese Einstellung für alle nachfolgenden Tests verwenden.
Um zu bestimmen, ob das zwischengespeicherte Ergebnis in Bezug auf die Anfrage positiv oder negativ ist, verwenden wir den von ChatGPT generierten Ähnlichkeitswert und setzen den positiven Schwellenwert auf 0.6. Wir generieren diesen Ähnlichkeitswert mit dem folgenden Prompt:
Bitte bewerten Sie die Ähnlichkeit der folgenden zwei Fragen auf einer Skala von 0 bis 1, wobei 0 bedeutet, dass sie nicht zusammenhängen, und 1 bedeutet, dass sie genau dieselbe Bedeutung haben.
Die Fragen "What are some good tips for self-study?" und "What are the smart tips for self-studying?" sind sehr ähnlich, mit einem Ähnlichkeitswert von 1.0.
Die Fragen "What are some essential things for wilderness survival?" und "What are the things you need for survival?" sind ziemlich ähnlich, mit einem Ähnlichkeitswert von 0.8.
Die Fragen "What advice would you give to 16-year-old you?" und "Where should I promote my business online?" sind völlig unterschiedlich, daher ist der Ähnlichkeitswert 0.
Also, Fragen "Which app lets you watch live football for free?" und "How can I watch a football live match on my phone?" Der Ähnlichkeitswert ist
Experiment 2
Wir haben Anfragen gestellt, die aus 50% positiven Stichproben und 50% negativen Stichproben (nicht verwandten Anfragen) bestanden. Als Ergebnis erhielten wir nach der Ausführung von 1160 Anfragen die folgenden Ergebnisse:
| Cache-Treffer | Cache-Fehlschlag | Positiv | Negativ | Trefferlatenz |
|---|---|---|---|---|
| 570 | 590 | 549 | 21 | 0.17s |
Die Trefferquote liegt bei fast 50%, und die negative Quote unter den Trefferergebnissen ist ähnlich wie in Experiment 1, was bedeutet, dass GPTCache hervorragende Arbeit dabei geleistet hat, verwandte und nicht verwandte Anfragen zu unterscheiden.
Experiment 3
Wir führten ein weiteres Experiment durch, bei dem wir alle negativen Stichproben in den Cache einfügten und ihre Peer-Werte als Anfragen verwendeten. Obwohl einige negative Stichprobenpaare einen hohen Ähnlichkeitswert hatten (größer als 0.9, laut ChatGPT), traf zu unserer Überraschung keines der negativen Beispiele den Cache. Dies liegt wahrscheinlich daran, dass das im Ähnlichkeitsbewerter verwendete Modell auf diesem Datensatz feinabgestimmt ist und fast alle Ähnlichkeitswerte für negative Stichproben unterbewertet wurden.
Zukünftige Evaluierung
Wir haben GPTCache in unsere OSSChat-Website integriert und arbeiten nun daran, Produktionsstatistiken zu sammeln. Bleiben Sie also gespannt auf die Veröffentlichung unseres nächsten Benchmarks, der reale Anwendungsfälle umfassen wird.
Es ist das Ende des Blogs, aber erst der Anfang für GPTCache
Wir freuen uns darüber, wie schnell wir in der Lage waren, ein so erstaunliches Stück Arbeit in weniger als zwei Wochen zu implementieren und als Open Source zu veröffentlichen. Bravo! Hoffentlich verstehen Sie jetzt die Idee von GPTCache, wie es implementiert wurde, vollständig und haben eine Fülle von Ideen, wie es in Ihr System integriert werden kann.
Lassen Sie uns einige der wichtigsten Punkte zu GPTCache kurz zusammenfassen:
- ChatGPT ist beeindruckend, kann aber mitunter teuer und langsam sein.
- Wie bei anderen Anwendungen können wir in AIGC-Anwendungsfällen Lokalität erkennen.
- Um diese Lokalität vollständig zu nutzen, benötigen Sie lediglich einen semantischen Cache.
- Um einen semantischen Cache zu erstellen, betten Sie Ihren Anfragekontext ein und speichern ihn in einer Vektordatenbank. Suchen Sie dann im Cache nach ähnlichen Anfragen, bevor Sie die Anfrage an LLMs senden.
- Denken Sie daran, die Kapazität des Caches zu verwalten!
Wir arbeiten derzeit daran, GPTCache mit weiteren LLMs und Vektordatenbanken zu integrieren. Bald werden wir das GPTCache Bootcamp veröffentlichen, das erklären wird, wie man GPTCache zusammen mit LangChain und Hugging Face verwendet, sowie weitere Ideen dazu, GPTCache multimodal zu machen. Wir freuen uns über Beiträge oder Vorschläge und ermutigen Sie, uns zu zeigen, wie GPTCache Ihnen in Ihrer Anwendung hilft!
Mehr über GPTCache erfahren

Weiterlesen

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.