




Plaud Powers Billion-Scale Agent Memory with Zilliz Cloud

< 200 ms
Average recall latency
10B+
Vector chunks per region, with room to grow
In days
Billion-scale historical data backfill, no service interruption
Zero downtime
Schema changes and cluster upgrades on an always-on app
AI is moving from answering one-off questions to agents that remember, which makes AI memory the heart of consumer AI products. Zilliz Cloud gives us a solid foundation we can trust for agentic memory retrieval at a massive scale, so our team can put its energy into product innovation and user experience, not the plumbing beneath it.
Charles Liu
About Plaud
Plaud is the world's No.1 AI note-taking brand. Its hardware — the credit-card-sized AI notetakers Plaud Note, Plaud Note Pro, and the wearable Plaud NotePin S — works with Plaud Intelligence (available on app, web, desktop) to turn everyday conversations into summaries, to-do items, and business value. In less than three years, Plaud has become one of the defining companies in consumer AI hardware: it has shipped more than 2 million devices across 170+ countries and has scaled from $1M to over $100M in annual recurring revenue in roughly two years.

Behind that experience is a harder task than it looks. Every recording becomes long-lived, personal memory a user expects to search and ask across instantly — multiplied by a fast-growing global user base. Storing and retrieving that memory at scale is the job Plaud entrusts to Zilliz Cloud.
The Challenge
Consumer-scale AI memory is one of the most demanding retrieval workloads in production. Plaud first built its retrieval on OpenSearch, which handled search and logs well. But as the workload shifted toward billion-scale semantic and hybrid search, OpenSearch's retrieval performance and cost at that scale could no longer keep up. Replacing that foundation meant solving for three forces at once.
- Explosive, consumer-scale data growth. As adoption accelerated worldwide, Plaud's vectorized memory grew from hundreds of millions to billions of chunks per region, approaching tens of billions. Each recording also generates rich scalar metadata used for filtering and ranking, and a consumer product produces enormous long-tail "cold" memory — data a user may ignore for months, then suddenly need — that must stay inexpensive to retain without slowing active queries.
- A semantic, agentic workload — not just keyword search. Plaud's core use case is Agentic RAG and memory: retrieval driven by meaning, at a billion-scale, feeding Ask Plaud and its agents. This requires genuine high-performance vector search combined with conditional scalar filtering, and heavy continuous writes running alongside low-latency reads without interference. Relevance must also respect content type and recency — a summary should outweigh a raw transcript, and recent memory should surface first.
- Global, always-on, and built for sensitive personal data. A global user base makes multi-region deployment and data residency hard requirements. Because recordings are deeply personal, the platform needs customer-controlled encryption and a model in which no plaintext ever leaves Plaud. And because the product ships continuously, the retrieval layer itself must evolve — new fields, new indexes, version upgrades — with zero downtime.
Why Zilliz Cloud
Plaud chose Zilliz Cloud as the foundation for this workload for three reasons.
Proven performance and stability at a billion-scale. Plaud needed an engine that stays fast and stable as data grows into the billions in live production — not in a benchmark. Zilliz Cloud's distributed architecture sustains high-performance search and high-throughput writes at scale, with reads and writes isolated to keep latency predictable as the workload grows.
A privacy model that keeps user content with Plaud. Plaud sends Zilliz Cloud only what retrieval needs — semantic vectors and the scalar fields used for filtering, such as timestamps. No transcripts, audio, or plaintext ever leave Plaud. Paired with customer-managed encryption keys (CMEK), this gives Plaud strong, verifiable control over user privacy.
A managed foundation that leaves Plaud in control of relevance. Zilliz Cloud handles the hard part — distributed vector storage and retrieval at scale — while Plaud keeps the parts that differentiate its product: how it builds sparse and dense vectors, runs multi-way recall, and fuses and ranks results.
The Solution
Within Plaud, Zilliz Cloud is the retrieval layer powering ContextOS, the system that turns raw recordings into usable memory. The path from voice to answer runs in four stages:
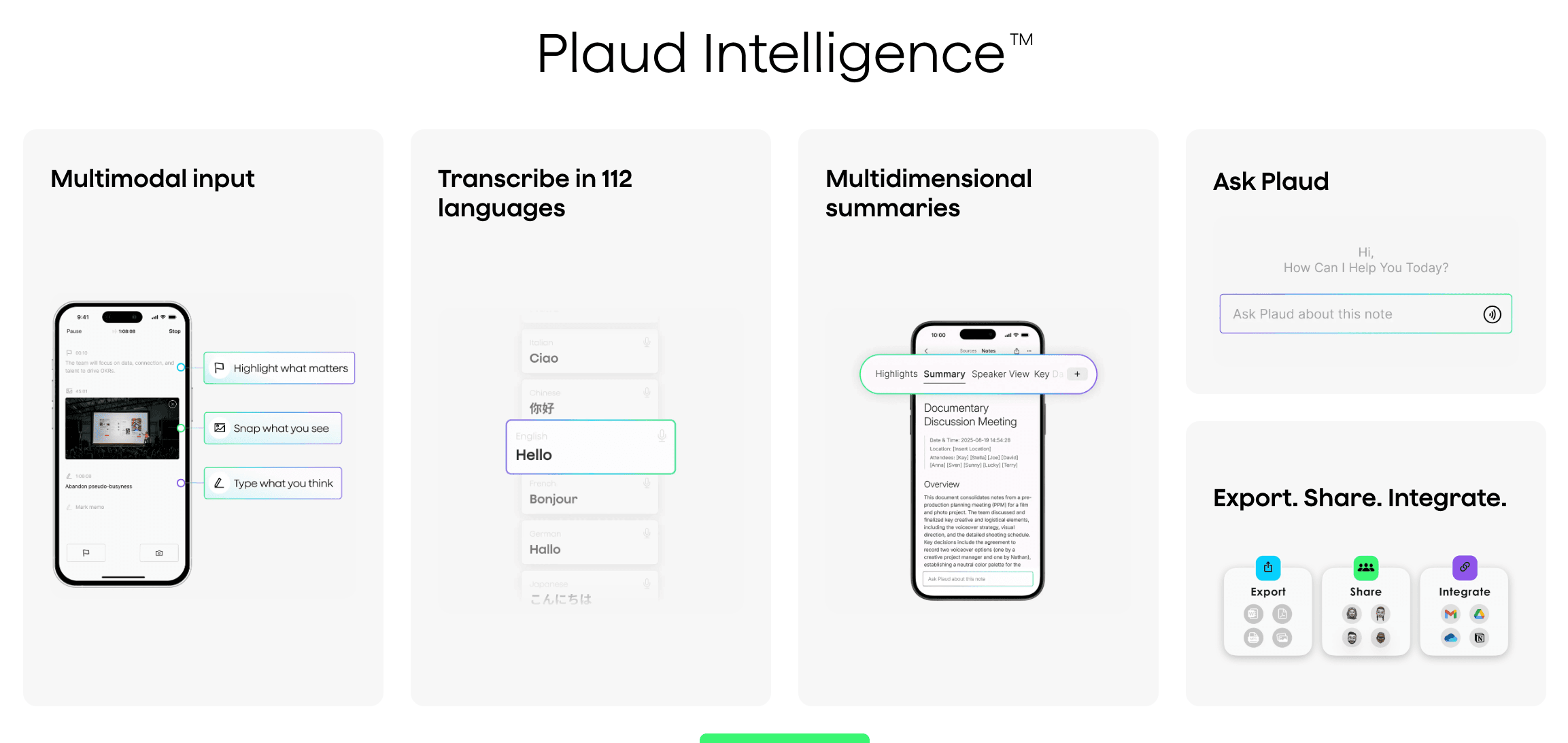
- Capture & preprocess — A user finishes a recording; the file enters Plaud's filesystem and is preprocessed as needed (for example, speech-to-text and text-to-embeddings using AI models).
- Understand & store — ContextOS processes the content and writes it to Zilliz Cloud as semantic vectors plus scalar filter fields — never raw text.
- Retrieve-on-intent — When the user searches or asks Plaud something, an agent interprets the intent, encodes it into vectors, and retrieves the most relevant context from ContextOS, backed by Zilliz Cloud.
- Generate — That retrieved context grounds the agent's answer.
On this foundation, Zilliz Cloud powers three product scenarios:
- Search across a user's own recordings;
- Ask Plaud (RAG), answers grounded in transcripts and summaries;
- MAG (Memory-Augmented Generation), answers grounded in long-term personal memory.
Engineering deep dive: built for agent memory
Agent memory is not classic RAG over a static document set. It is living, per-user context that grows continuously and must stay fresh, filterable, and private. Meeting that bar took specific engineering — these are the capabilities the Plaud team highlights.
Billion-scale historical data backfill, with the service still live
Growing a memory product means constantly loading and reshaping large volumes of historical data — without taking the search offline for users who depend on it. With Zilliz Cloud, Plaud runs billion-scale historical backfills as offline batch jobs that complete in days while the live service stays fully readable. Massive memory sets are deployed to production without a maintenance window.
Zero-downtime schema evolution and upgrades
A fast-moving consumer app changes constantly: new memory attributes to store, new fields to filter and search on, new index and engine versions to adopt. Zilliz Cloud lets Plaud add dynamic columns, enable keyword (BM25) search on new text fields, and roll out index and cluster upgrades — all with zero downtime. Plaud keeps shipping while a global app stays always-on.
Global multi-region with data residency
Plaud's users span North America, Europe, and Asia-Pacific and expect their data both fast and kept in-region. Zilliz Cloud's native multi-region support lets Plaud place each user's memory in the right region for residency and low latency. Cross-cluster primary-key uniqueness makes this safe at scale — users and their data can move between regional clusters while keys stay globally unique — and zero-downtime replication keeps the migration invisible to users.
Memory-aware hybrid retrieval
In personal memory, the best match isn't always the most semantically similar one: a recent note usually matters more than an old one, and a summary is often more useful than a raw transcript. Zilliz Cloud's hybrid search combines semantic and keyword retrieval with decay ranking and document-type weighting, so Ask Plaud and its agents surface memory that is not just relevant, but timely and the right kind.
Beyond these headline efforts, Plaud's workload leans on a set of foundational capabilities that any production-grade agent-memory system needs:
| Capability | Why it matters for Plaud |
|---|---|
| Conditional scalar filtering with vector search | Personal memory is always scoped to a user and metadata, so filtering has to run together with semantic search at full speed |
| Read–write isolation | Continuous, high-volume ingestion runs alongside low-latency queries without either degrading the other |
| Customer-managed encryption (CMEK) | Plaud and its users hold the keys; revoke a key and the data can no longer be decrypted |
| Cold/hot tiering | Long-tail "cold" memory stays inexpensive to retain and re-warms automatically on access |
| Managed backup & recovery | Full-dataset backups run with negligible impact on live query performance |
| Elastic capacity scaling | Capacity grows with the user base without re-architecting the system |
Results & Benefits
- Low-latency retrieval at scale — Recall returns in under 200ms on average and under 800ms at P99, giving the end-to-end Ask AI pipeline room to stay responsive even as data grows into the billions.
- Billions of vectors without re-architecture — Plaud has grown from hundreds of millions to billions of chunks per region, with a clear path to tens of billions, all on the same foundation and without retrieval becoming the bottleneck.
- Faster data operations, zero downtime — Billion-scale historical backfills complete in days, and schema and cluster upgrades run with zero downtime, so the team ships continuously on an always-on, global app.
- Global compliance and performance — Native multi-region deployment keeps each user's data in-region, satisfying data-residency requirements while delivering low latency to users worldwide.
- Lower operational overhead — A fully managed service removes the hidden cost of self-run clusters (setup, tuning, scaling, and on-call), so engineering focuses on product, not plumbing.
The clearest benefit is strategic: a reliable, scalable foundation lets Plaud's engineers shift attention from "will the infrastructure hold?" back to "how good can the product be?" — enabling a larger semantic memory, more sophisticated recall strategies, and faster feature iteration.
Plaud's advice for teams building consumer AI systems
Having lived the full growth curve, Plaud's team offers four lessons for others building AI recording, personal AI memory, or other consumer AI products:
- Choose infra for your end-state scale. The moment a consumer product takes off, data jumps from hundreds of millions to billions of chunks. Pick a purpose-built engine that scales smoothly, and avoid one expensive migration later.
- Test scalar filtering and semantic search together. Conditional filtering combined with semantic retrieval is the most realistic — and most demanding — test of a vector engine for real AI applications.
- Put operational cost on the books. Self-managed sharding, scaling, and on-call are hidden, high costs. A fully managed option zeroes them out so the team can focus on the product.
- Plan for global reach and compliance early. For a global user base, data residency and multi-region low-latency become hard requirements sooner than you expect.
What's next
Plaud plans to expand its use of Zilliz Cloud from Agentic RAG and agent memory today to a central role in its agent context engineering, as its memory layer scales to tens of billions of vectors and beyond.
"Plaud is exactly the kind of company redefining what consumer AI can be — and doing it profitably, at remarkable speed. We're proud that Zilliz Cloud is the retrieval foundation behind Plaud's success, and we're excited to keep building together as they scale toward what's next in agentic AI."
— James Luan, CTO of Zilliz
Try Zilliz Cloud for Free
Zilliz Cloud is a fully managed Vector Database and Vector Lakebase for enterprise AI, compatible with Milvus APIs. It delivers a hundred-billion-scale vector search with high performance, enterprise-grade security, and zero-maintenance operations. Now extended with the openness, scalability, and economics of multimodal data lakes, it gives enterprises a single platform to search, analyze, and govern unstructured data for production AI.
Whether you're scaling RAG or building agent memory, Zilliz Cloud provides the same retrieval foundation that powers Plaud. Get started with Zilliz Cloud for free now or talk to our team.
Pick for the scale you'll end up at, not the one you have. Consumer data grows faster than anyone plans for, and a migration at that size is painful. Hand the retrieval infrastructure to specialists, and spend your own people on the product
The engineering team, Plaud