




SuperGLUE: uma referência abrangente para avaliação avançada de PNL
SuperGLUE: uma referência abrangente para avaliação avançada de PNL
TL; DR
SuperGLUE (Super General Language Understanding Evaluation) é um benchmark concebido para avaliar o desempenho de modelos de compreensão de linguagem natural (NLU). Com base no seu antecessor, GLUE, introduz tarefas mais desafiantes para avaliar a capacidade de um modelo para lidar com raciocínios linguísticos complexos, tais como resposta a perguntas, resolução de coreferências e inferência. O SuperGLUE inclui um conjunto diversificado de conjuntos de dados e métricas, além de testar habilidades como compreensão contextual, recuperação de conhecimento e aprendizagem multitarefa. Desenvolvido para ultrapassar os limites da NLU, reflecte tarefas mais próximas do raciocínio humano. A obtenção de pontuações elevadas no SuperGLUE indica a robustez e a eficácia de um modelo na resolução de desafios linguísticos do mundo real.
Introdução
O processamento da linguagem natural (NLP) transformou a forma como as máquinas interagem com os seres humanos, desde os chatbots aos sistemas de recomendação. Modelos como o ELMo, BERT e GPT redefiniram o limiar da compreensão da linguagem, melhorando a modelação e a compreensão da linguagem humana. Estas transformações abriram caminho para a referência GLUE , um meio de avaliação sistemático que avalia a competência dos modelos linguísticos em várias tarefas.
No entanto, à medida que os modelos de PNL se tornam mais inteligentes, torna-se claro que enfrentamos um desafio mais difícil. É aqui que entra o ****[SuperGLUE] (https://super.gluebenchmark.com/) - com objectivos maiores e mais exigentes, apresenta um novo conjunto de tarefas baseadas no raciocínio, na compreensão do senso comum e na interpretação contextual diferenciada. O SuperGLUE testa a capacidade de qualquer modelo para resolver problemas linguísticos difíceis do mundo real, colocando assim um teste muito mais rigoroso aos modelos de PNL.
Neste artigo, vamos explorar as caraterísticas únicas do SuperGLUE, as tarefas que inclui e como está a impulsionar o desenvolvimento de modelos de PNL ainda mais sofisticados e fiáveis.
O que é o SuperGLUE?
O [SuperGLUE] (https://arxiv.org/abs/1905.00537), abreviação de Super General Language Understanding Evaluation, é um benchmark criado para testar a capacidade dos modelos de PNL de lidar com uma ampla gama de tarefas complexas de compreensão de linguagem. Trata-se essencialmente de uma versão actualizada do [GLUE] (https://arxiv.org/abs/1804.07461), concebida para elevar a fasquia. Enquanto o GLUE se concentra em tarefas mais simples, o SuperGLUE inclui desafios mais sofisticados que exigem um raciocínio mais profundo, conhecimento do senso comum e compreensão do contexto. Por exemplo, enquanto uma tarefa GLUE pode avaliar se duas frases são semanticamente semelhantes, uma tarefa SuperGLUE, como o Winograd Schema Challenge (WSC), exige a resolução de pronomes ambíguos usando o raciocínio do senso comum.
O SuperGLUE mantém duas das tarefas mais desafiantes do GLUE (RTE e WNLI) e introduz seis tarefas inteiramente novas, concebidas para levar os modelos para além da simples correspondência de padrões e para o conhecimento semântico e pragmático.
Quais são os objetivos do SuperGLUE?
Testando o raciocínio avançado:** O SuperGLUE vai além do processamento básico de linguagem - ele foi projetado para ver se os modelos podem raciocinar, fazer inferências e usar o conhecimento de senso comum em cenários complexos.
Incentivar o progresso da PNL:** Ao introduzir tarefas mais difíceis, a SuperGLUE motiva os pesquisadores a desenvolver técnicas de aprendizado de máquina mais avançadas e capazes.
Criando um benchmark completo:** Ao contrário do GLUE, que se concentra em desafios mais simples, o SuperGLUE fornece uma maneira mais realista e abrangente de testar o desempenho dos modelos com entradas complexas do mundo real.
Estabelecendo um padrão mais alto para a PNL:** O SuperGLUE foi criado com o futuro em mente - ele é desafiador o suficiente para que até mesmo os melhores modelos de hoje tenham muito espaço para melhorar, tornando-o uma ferramenta valiosa para acompanhar o progresso na PNL.
Como o SuperGLUE funciona
O SuperGLUE avalia os modelos de PNL desafiando suas habilidades lingüísticas. Essas tarefas exigem que os modelos façam mais do que apenas classificar frases ou prever palavras individuais - eles devem lidar com as complexidades do mundo real. Isso inclui resolução de coreferência (descobrir quais palavras ou frases se referem à mesma coisa), raciocínio (tirar conclusões lógicas do texto) e entender as relações entre entidades no contexto. Cada tarefa mede a forma como os modelos lidam com as exigências matizadas e sofisticadas da linguagem humana.
Uma visão geral detalhada das tarefas
O SuperGLUE é um superconjunto de muitas tarefas, que abordaremos nesta secção. Antes disso, veremos diferentes métricas de avaliação necessárias para classificar o desempenho do modelo.
Métricas de avaliação
O SuperGLUE emprega várias métricas de avaliação, dependendo da tarefa:
Correspondência exata (EM):** Usada para tarefas que avaliam se a resposta prevista corresponde exatamente à resposta esperada.
Pontuação F1:** Mede a precisão e a recuperação quando várias respostas corretas são possíveis.
Exatidão:** A proporção de exemplos previstos corretamente utilizada em tarefas de classificação mais simples, como BoolQ.
F1 macro-medido:** Uma média das pontuações F1 entre classes, garantindo uma avaliação equilibrada mesmo com desequilíbrio de classes.
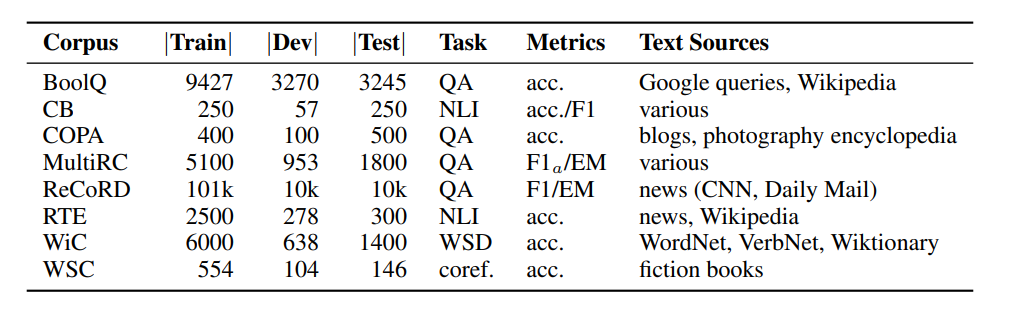 Figura- SuperGLUE Benchmark- Tabela de resumo das tarefas do SuperGLUE, incluindo tamanhos de corpus, métricas e fontes de texto para cada tarefa..png
Figura- SuperGLUE Benchmark- Tabela de resumo das tarefas do SuperGLUE, incluindo tamanhos de corpus, métricas e fontes de texto para cada tarefa..png
Figura: SuperGLUE Benchmark: Tabela de resumo das tarefas SuperGLUE, incluindo tamanhos de corpus, métricas e fontes de texto para cada tarefa.
Vamos explorar a visão geral detalhada das tarefas do SuperGLUE para compreender a profundidade e a variedade dos seus desafios.
- BoolQ (Perguntas booleanas)
[BoolQ] (https://paperswithcode.com/dataset/boolq) é uma tarefa de resposta a perguntas binárias em que o modelo determina se uma pergunta sim/não é verdadeira com base numa determinada passagem. Aqui estão a entrada, a saída e a métrica da tarefa:
| Input | Output | Metric |
|---|---|---|
| Uma passagem e uma pergunta de sim/não sobre a passagem. | Um valor booleano (Verdadeiro para sim, Falso para não). | Precisão |
Aqui está um exemplo:
Passagem: "Barq's é um refrigerante que contém cafeína e é engarrafado pela Coca-Cola."
Pergunta: "A cerveja Barq's contém cafeína?"
Output: True
- CB (CommitmentBank)
O CB consiste em avaliar se uma cláusula incorporada num texto é provavelmente verdadeira (implicação), falsa (contradição) ou indeterminada (neutra).
| Input | Output | Metric |
|---|---|---|
| Uma premissa e uma hipótese. | Um rótulo (implicação, neutro ou contradição). | Precisão e F1 macro-média. |
Aqui está um exemplo:
Premise: "Ela disse que talvez fosse à reunião."
Hipótese: "De certeza que ela vai à reunião."
Output: Contradição
- COPA (Escolha de Alternativas Plausíveis)
A COPA é uma tarefa de raciocínio causal em que o modelo determina a causa ou o efeito mais plausível de uma dada premissa a partir de duas alternativas.
| Input | Output | Metric |
|---|---|---|
| Uma premissa e duas alternativas (causa/efeito). | A alternativa mais plausível (1 ou 2). | Precisão |
Vejamos um exemplo:
Premissa: "A relva está molhada".
Alternativa 1: "Choveu ontem à noite."
Alternativa 2: "O sol estava a brilhar intensamente."
Output: 1
- MultiRC (Compreensão de Leitura de Várias Frases)
O [MultiRC] (https://paperswithcode.com/dataset/multirc) consiste em responder a perguntas baseadas numa passagem, em que cada pergunta pode ter várias respostas corretas.
| Input | Output | Metric | | | ----------------------------------------------------- | ----------------------------------------------- | ------------------- | | Uma passagem, uma pergunta e um conjunto de respostas possíveis. | Um rótulo binário (Verdadeiro ou Falso) para cada resposta. | F1 e correspondência exata. |
Aqui está um exemplo simples:
Passagem: "A Susana convidou os seus amigos para uma festa. Um dos seus amigos estava doente, mas depois foi à festa."
Pergunta: "O amigo doente foi à festa?"
Respostas: "Sim", "Não"
Output: Sim
- ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset)
O ReCoRD é uma tarefa de compreensão de leitura do tipo Cloze que requer raciocínio de senso comum para prever entidades mascaradas numa passagem.
| Input | Output | Metric | | | ------------------------------------------- | --------------------------------------------- | ---------- | | Uma passagem com entidades mascaradas e uma consulta. | A entidade correta de uma lista de candidatos. | F1 e EM. |
Aqui está um exemplo simples:
Passagem: "A Tesla foi fundada por
Query: "Quem fundou a Tesla?"
Candidatos: "Elon Musk", "Nikola Tesla", "Thomas Edison"
Resultado: Elon Musk
- RTE (Reconhecimento de detalhes textuais)
O RTE determina se uma hipótese é verdadeira, falsa ou indeterminada com base numa dada premissa.
| Input | Output | Metric |
|---|---|---|
| Uma premissa e uma hipótese. | Um rótulo (implicação, neutro ou contradição). | Precisão |
Aqui está um exemplo:
Premissa: "Dana Reeve, a viúva de Christopher Reeve, faleceu aos 44 anos."
Hipótese: "Dana Reeve tinha 44 anos quando morreu."
Output: Entailment
- WiC (Word-in-Context)
WiC testa a desambiguação do sentido da palavra, determinando se uma palavra é utilizada com o mesmo significado em dois contextos diferentes.
| Entrada | Saída | Métrica |
|---|---|---|
| Duas frases contendo a mesma palavra-alvo. | Um rótulo binário (Verdadeiro para o mesmo sentido, Falso para sentido diferente). | Precisão |
Vejamos um exemplo:
Sentença 1: "Ele pregou as tábuas na parede".
Sentença 2: "O tabuleiro de xadrez foi lindamente trabalhado."
Palavra alvo: "tabuleiro"
Output: Falso
- WSC (Desafio do esquema de Winograd)
O WSC é uma tarefa de resolução de coreferências em que o modelo identifica o referente correto de um pronome ambíguo utilizando o raciocínio do senso comum.
| Input | Output | Metric | | | ------------------------------------------- | --------------------- | ---------- | | Uma frase contendo um pronome ambíguo. | O referente correto. | Precisão
Aqui está um exemplo:
Sentença: "O Mark deu um livro ao Ted, mas ele não gostou."
Pronome: "ele"
Output: Ted
As tarefas acima em SuperGLUE desafiam os modelos de PNL para além da mera compreensão da linguagem, para a qual qualquer sistema é suposto construir um raciocínio matizado e resolver problemas do mundo real. Assim, a SuperGLUE avalia o modelo com base na compreensão, raciocínio e aplicação efectiva de conhecimentos de senso comum. Fornece um quadro de avaliação abrangente que capta tanto a precisão como a recuperação de modelos em diversos desafios de compreensão da linguagem.
Exemplo de implementação
Abaixo está um exemplo de carregamento e interação com a tarefa ReCoRD do SuperGLUE usando a biblioteca Hugging Face:
from datasets import load_dataset
# Carrega a tarefa ReCoRD do SuperGLUE
dataset = load_dataset("super_glue", "record", trust_remote_code = True
)
# Aceder aos dados de treino
dados_treino = conjunto de dados['treino']
# Ponto de dados de exemplo
exemplo = dados_treino[0]
print(f "Passagem: {example['passage']}")
print(f "Consulta com entidade mascarada: {example['query']}")
A função "load_dataset" carrega a tarefa ReCoRD. A entrada inclui uma passagem e uma consulta com uma entidade mascarada que precisa de ser resolvida. O modelo tem como objetivo prever corretamente a entidade mascarada, demonstrando a sua capacidade de compreender a passagem e aplicar o raciocínio de senso comum.
 Figura- Saída do exemplo implementado.png
Figura- Saída do exemplo implementado.png
Figura: Saída do exemplo implementado
SuperGLUE vs. GLUE: Principais diferenças
O SuperGLUE melhora o GLUE introduzindo tarefas significativamente mais desafiadoras que refletem a compreensão da linguagem do mundo real.
| Caraterísticas | GLUE | SuperGLUE | | | :------------------------: | :-------------------------------------------------: | :------------------------------------------------------: | | Complexidade da tarefa** | Tarefas linguísticas básicas (por exemplo, análise de sentimentos) | Tarefas complexas que exigem raciocínio e senso comum | | Saturação do conjunto de dados** | Desempenho próximo do nível humano | Ampla margem de manobra para melhorias do modelo | | Requisito de raciocínio** | Requisito mínimo de raciocínio | Raciocínio e inferência de alto nível são necessários | Diversidade de tarefas** | Principalmente classificação de frases e tarefas de similaridade | Inclui QA, coreferência e compreensão de leitura | Aplicação no mundo real** | Reflexão limitada no mundo real | Tarefas concebidas para emular desafios linguísticos do mundo real
Benefícios e desafios do SuperGLUE
A SuperGLUE substitui a forma como os modelos de PNL têm sido avaliados, mudando o foco para a sua capacidade de resolver tarefas do mundo real com nuances que exigem raciocínio e contexto avançado. Vamos discutir alguns benefícios concretos que a SuperGLUE confere à PNL e os desafios que os investigadores enfrentam ao utilizá-la em todo o seu potencial.
Benefícios
Testes de raciocínio e senso comum:** A SuperGLUE inclui tarefas que exigem que os modelos utilizem conhecimento de senso comum. Por exemplo, o Winograd Schema Challenge (WSC) testa a resolução de pronomes usando o senso comum, enquanto a tarefa COPA avalia o raciocínio causal escolhendo a causa ou o efeito mais plausível em um determinado cenário. Estas tarefas tornam-nos mais capazes em cenários do mundo real.
Ao incluir tarefas mais complexas, o SuperGLUE supera a saturação do GLUE, em que os modelos atingiam um desempenho quase humano em tarefas mais simples, tornando-o menos eficaz para distinguir os avanços.
Promove a explicabilidade do modelo:** As tarefas complexas do SuperGLUE incentivam o desenvolvimento de modelos com bom desempenho e fornecem resultados mais interpretáveis, ajudando os pesquisadores a entender como e por que os modelos fazem previsões específicas.
Reflete problemas do mundo real:** As tarefas da SuperGLUE são projetadas para refletir os problemas que os modelos encontram em aplicações como compreensão de leitura e sistemas de diálogo. Por exemplo, a tarefa ReCoRD testa o raciocínio de senso comum para inferir informações ausentes, enquanto a WSC avalia a resolução de pronomes ambíguos - recursos essenciais para assistentes virtuais e IA de conversação.
O SuperGLUE permite que os pesquisadores examinem como e onde os modelos falham, fornecendo tarefas diversas e desafiadoras que destacam pontos fracos específicos. Esta análise detalhada de erros ajuda a identificar áreas em que os modelos têm dificuldades, como o raciocínio, a compreensão do senso comum ou a compreensão contextual, permitindo melhorias direcionadas para tornar os modelos mais robustos e fiáveis.
Desafios
Altos custos computacionais:** O treinamento de modelos no SuperGLUE pode ser computacionalmente caro devido à complexidade das tarefas. A utilização de arquitecturas optimizadas e de infra-estruturas baseadas na nuvem pode ajudar a gerir eficazmente a procura de recursos.
Ajuste fino complexo:** Cada tarefa na SuperGLUE pode exigir diferentes estratégias de ajuste fino. Abordagens de aprendizado multitarefa e aprendizado por transferência podem ajudar a simplificar esse processo. O aprendizado multitarefa treina um modelo em tarefas relacionadas para melhorar a generalização, enquanto o aprendizado por transferência aplica o conhecimento de uma tarefa para melhorar o desempenho em outra, minimizando a necessidade de dados e treinamento extensivos.
Tamanhos pequenos de conjuntos de dados:** Algumas tarefas do SuperGLUE vêm com dados limitados, o que aumenta o risco de os modelos se ajustarem demais durante o treinamento. Este desafio pode ser resolvido empregando técnicas como aumento de dados para criar amostras de treinamento mais diversificadas e regularização para melhorar a generalização do modelo.
Ênfase excessiva nas tabelas de classificação:** Embora as classificações das tabelas de classificação mostrem o desempenho do modelo, concentrar-se apenas nestas pontuações pode diminuir o valor prático dos modelos. Mudar a atenção para aplicações do mundo real ajuda a garantir que os modelos sejam competitivos e tenham impacto em cenários práticos.
Dificuldade na comparação de resultados:** A variabilidade nas implementações, hardware e hiperparâmetros pode dificultar a comparação justa dos resultados entre grupos de investigação. A normalização dos protocolos de avaliação, a partilha de bases de código e a utilização de referências comuns permitem-nos obter comparações mais consistentes e justas.
Casos de uso do SuperGLUE
O SuperGLUE é um benchmark importante que ajuda a melhorar a PNL desafiando modelos com tarefas baseadas em complexidades do mundo real. Exemplos de tais usos podem variar desde a condução de melhores sistemas de IA e raciocínio de conversação até a pesquisa semântica.
O SuperGLUE tem inúmeras aplicações em PNL e além:
IA conversacional:** O SuperGLUE melhora o desenvolvimento de assistentes virtuais, fornecendo referências que testam a capacidade dos modelos de entender consultas com nuances com melhor raciocínio e senso comum.
Sistemas de Raciocínio Avançado:** SuperGLUE potencializa a criação de ferramentas de apoio à decisão, avaliando e melhorando as capacidades de inferência lógica dos modelos.
Compreensão de leitura:** O SuperGLUE permite que os modelos de PNL analisem e resumam documentos longos com precisão, desafiando-os com tarefas que exigem compreensão avançada e compreensão contextual, auxiliando a pesquisa e a educação.
Representação e inferência de conhecimento:** SuperGLUE auxilia na construção de gráficos de conhecimento mais robustos, testando a capacidade dos modelos de entender relacionamentos e aplicar raciocínio de senso comum, apoiando mecanismos de pesquisa e sistemas de recomendação.
Pesquisa semântica e bancos de dados vetoriais:** SuperGLUE melhora a precisão da pesquisa semântica, permitindo que os modelos lidem com tarefas complexas de recuperação de informações em grande escala de forma eficaz.
Ferramentas que suportam SuperGLUE
As tarefas avançadas e os benchmarks do SuperGLUE levaram ao desenvolvimento de outras ferramentas e plataformas projetadas para facilitar sua implementação e avaliação. Essas ferramentas ajudam pesquisadores e desenvolvedores a tomar melhores decisões sobre acesso a dados, treinamento de modelos e análise de resultados.
Vejamos as ferramentas que apoiam e melhoram a adoção e a interação com a SuperGLUE.
Ferramentas
Conjunto de dados de rosto: Fornece uma maneira fácil de carregar e interagir com as tarefas do SuperGLUE, agilizando o desenvolvimento e o teste de modelos.
Conjuntos de dados do TensorFlow: Oferece versões pré-formatadas das tarefas do SuperGLUE, integrando-se bem aos modelos baseados no TensorFlow.
AllenNLP:** Fornece módulos e componentes para tarefas de NLP, simplificando a experimentação com SuperGLUE.
Avaliando modelos de IA com SuperGLUE e aprimorando-os com RAG
Benchmarks como o SuperGLUE são essenciais para avaliar as capacidades de grandes modelos de linguagem (LLMs). Fornecem um quadro normalizado para medir o desempenho de um modelo em diversas tarefas e facilitam as comparações diretas entre modelos. Ao realçar os pontos fortes, como o raciocínio, e expor os pontos fracos, como as dificuldades com o raciocínio complexo ou tarefas específicas de um domínio, o SuperGLUE ajuda os investigadores a identificar as áreas a melhorar. Essas percepções permitem o ajuste fino, melhorando a compreensão de um modelo e as capacidades de geração de conteúdo.
No entanto, embora o SuperGLUE seja valioso para melhorar os LLMs, não é uma solução definitiva. Os LLMs têm limitações inerentes, independentemente do seu desempenho em benchmarks. São treinadas em conjuntos de dados estáticos e offline e não têm acesso a informação em tempo real ou específica do domínio. Isto pode levar a [alucinações] (https://zilliz.com/glossary/ai-hallucination), em que os modelos geram respostas inexactas ou fabricadas. Estas deficiências tornam-se ainda mais problemáticas quando se trata de consultas proprietárias ou altamente especializadas.
Apresentando o RAG: uma solução para melhorar as respostas de LLM
Para enfrentar estes desafios, Retrieval-Augmented Generation (RAG) oferece uma solução poderosa. O RAG melhora os modelos de linguagem de grande porte (LLMs) combinando as suas capacidades generativas com a capacidade de recuperar informações específicas do domínio a partir de bases de conhecimento externas armazenadas numa base de dados vetorial como Milvus ou Zilliz Cloud. Quando um utilizador faz uma pergunta, o sistema RAG procura informações relevantes na base de dados e utiliza essas informações para gerar uma resposta mais precisa. Vejamos como funciona o processo do RAG.
 Figura - Fluxo de trabalho do RAG.png
Figura - Fluxo de trabalho do RAG.png
Um sistema RAG é normalmente constituído por três componentes principais: um [modelo de incorporação] (https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data), uma [base de dados vetorial] (https://zilliz.com/learn/what-is-vetor-database) e um LLM.
O modelo de incorporação converte os documentos em vetor embeddings, que são armazenados numa base de dados vetorial como Milvus.
Quando um utilizador faz uma pergunta, o sistema transforma a consulta num vetor utilizando o mesmo modelo de incorporação.
A base de dados vetorial efectua então uma [pesquisa por semelhança] (https://zilliz.com/learn/vetor-similarity-search) para recuperar as informações mais relevantes. Esta informação recuperada é combinada com a pergunta original para formar uma "pergunta com contexto", que é então enviada para o LLM.
O LLM processa essa entrada enriquecida para gerar uma resposta mais precisa e contextualmente relevante.
Esta abordagem preenche a lacuna entre as LLM estáticas e as necessidades específicas de um domínio em tempo real.
FAQs do SuperGLUE
O que torna o SuperGLUE mais difícil do que o GLUE? O SuperGLUE baseia-se no GLUE introduzindo tarefas de raciocínio e senso comum que vão muito além das tarefas encontradas no GLUE.
Que modelos têm melhor desempenho na SuperGLUE? Os modelos baseados em transformadores destacam-se na SuperGLUE devido ao seu mecanismo de auto-atenção, que captura dependências de contexto e de longo alcance, pré-treinamento extensivo em grandes conjuntos de dados, escalabilidade e adaptabilidade através da aprendizagem por transferência.
**Quais são os requisitos computacionais para a SuperGLUE? O treino de modelos na SuperGLUE requer recursos computacionais significativos devido à complexidade das tarefas, que exigem um grande poder de processamento para afinação, raciocínio e tratamento eficaz de grandes conjuntos de dados.
**O SuperGLUE pode ser aplicado a tarefas específicas de um domínio? Embora se concentre na generalização, a personalização para domínios específicos é possível com um ajuste fino adicional com dados específicos do domínio.
Como é que o SuperGLUE é relevante para as aplicações modernas de IA? Estabelece um padrão para avaliar modelos em aplicações do mundo real, como a pesquisa semântica e a IA de conversação.
Recursos relacionados
Guia para iniciantes em processamento de linguagem natural](https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing)
20 conjuntos de dados abertos úteis para processamento de linguagem natural
- TL; DR
- Introdução
- O que é o SuperGLUE?
- Como o SuperGLUE funciona
- SuperGLUE vs. GLUE: Principais diferenças
- Benefícios e desafios do SuperGLUE
- Casos de uso do SuperGLUE
- Ferramentas que suportam SuperGLUE
- Avaliando modelos de IA com SuperGLUE e aprimorando-os com RAG
- FAQs do SuperGLUE
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis