




Escalável e fiável: Um guia simples para a computação distribuída
Escalável e fiável: Um guia simples para a computação distribuída
A computação distribuída é a prática de executar tarefas ou processos em vários computadores ligados para aumentar o desempenho, a escalabilidade e a fiabilidade. Em vez de depender de uma máquina potente, a carga de trabalho é dividida entre vários nós, que podem lidar com conjuntos de dados e cálculos maiores de forma mais eficiente. Esta abordagem constitui a espinha dorsal de muitas aplicações modernas baseadas em dados, incluindo plataformas de comércio eletrónico, pipelines de aprendizagem automática, análises em tempo real, redes de sensores IoT e simulações de investigação de elevado desempenho.
 Computação distribuída
Computação distribuída
Figura: Computação distribuída
De Servidores Únicos a Sistemas Distribuídos: A Evolução
Durante muito tempo, muitas organizações confiaram em servidores grandes e centralizados - muitas vezes chamados de arquitecturas monolíticas - para executar as suas aplicações. No entanto, essa configuração tinha algumas desvantagens claras:
Escalabilidade limitada: Adicionar mais capacidade significava comprar servidores maiores, o que era caro e demorado.
Ponto único de falha**: Todo o sistema parava se o servidor principal fosse abaixo.
Actualizações complexas**: Fazer alterações ou actualizações era arriscado porque tudo estava alojado num único local.
Os clusters, que agrupam servidores mais pequenos, proporcionavam algum alívio, mas ainda não resolviam totalmente os problemas de escalonamento e fiabilidade. Foi aí que entrou em cena a computação distribuída. Ao dividir as tarefas e os dados por vários nós ligados, os sistemas distribuídos:
Escalam mais depressa e de forma mais económica**: É possível adicionar mais nós em vez de substituir um único servidor grande.
Melhoram a tolerância a falhas**: Se um nó falhar, os outros podem manter o sistema online.
Lidar com cargas de trabalho pesadas**: Vários nós a trabalhar em conjunto podem processar grandes volumes de dados de forma mais eficiente.
Soluções modernas como Milvus da Zilliz baseiam-se nestes princípios para gerir grandes quantidades de dados de elevada dimensão. O Milvus suporta pesquisas de semelhança em grande escala, distribuindo os dados por vários nós, e mantém um elevado desempenho, mesmo em condições exigentes.
Como é que a computação distribuída funciona?
A computação distribuída é um modelo em que várias máquinas (ou nós) trabalham em conjunto para realizar tarefas que seriam difíceis ou ineficientes de realizar numa única máquina. Cada nó de um sistema distribuído pode executar funções específicas, como armazenar dados ou processar cálculos, e o sistema coordena estas tarefas para funcionar como um todo unificado. Por conseguinte, esta abordagem conduz a um maior desempenho, a uma melhor [tolerância a falhas] (https://zilliz.com/ai-faq/how-do-distributed-databases-ensure-fault-tolerance) e a opções de escalonamento flexíveis.
Princípios básicos
Distribuição de tarefas: A ideia principal por detrás da computação distribuída é dividir grandes trabalhos em tarefas mais pequenas e atribuí-las a vários nós. Ao dividir as cargas de trabalho, cada nó pode trabalhar na sua parte em paralelo, o que acelera o processamento e evita que uma máquina fique sobrecarregada.
Data Partitioning: Os dados são divididos em segmentos (frequentemente designados por "shards"). Cada nó armazena um ou mais desses segmentos para leituras e gravações paralelas. Isto acelera o acesso aos dados e facilita o escalonamento: quando os dados crescem, adicionam-se mais nós e particionam-se ainda mais.
Sincronização e coordenação: Uma vez que as tarefas e os dados estão dispersos, torna-se fundamental que os nós se mantenham sincronizados para evitar actualizações contraditórias. Os sistemas distribuídos utilizam protocolos e algoritmos, tais como mecanismos de consenso, para garantir que cada nó mantém uma visão consistente dos dados. Estes métodos ajudam todas as partes do sistema a concordar com as alterações, mesmo quando estas ocorrem em simultâneo.
Componentes de sistemas distribuídos
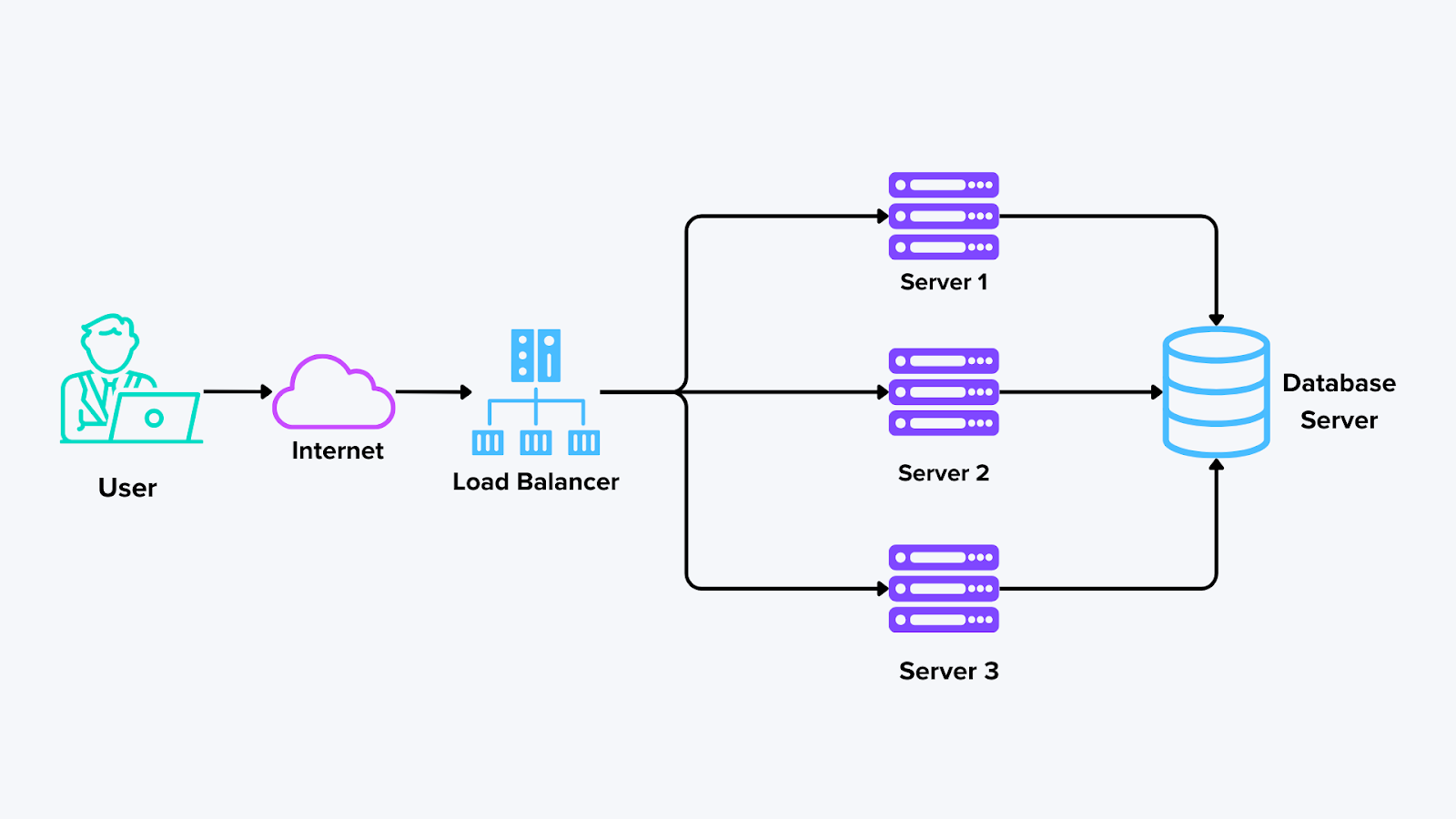 Componentes de sistemas distribuídos
Componentes de sistemas distribuídos
Figura: Componentes do sistema distribuído
Nós (ou Hosts)**: Cada nó executa tarefas ou armazena dados. Em muitos casos, os nós podem ser servidores físicos, máquinas virtuais ou contentores. Ao usar um sistema como o Milvus, cada nó pode conter um segmento do índice vetorial, permitindo pesquisas distribuídas em grandes conjuntos de dados sem sobrecarregar uma única máquina.
Rede**: A rede é a cola que conecta todos os nós. Transporta dados e mensagens entre máquinas para partilhar resultados e atualizar-se mutuamente. As ligações de rede fiáveis e rápidas são vitais para uma comunicação sem falhas.
Balanceadores de carga**: Quando vários nós estão prontos para aceitar pedidos de entrada, os [balanceadores de carga] (https://zilliz.com/ai-faq/how-do-distributed-databases-perform-load-balancing) distribuem o tráfego uniformemente. Isto evita que qualquer nó trate demasiados pedidos de uma só vez. Ao distribuir a carga, o sistema pode lidar com picos de tráfego e manter um desempenho estável.
Servidor de base de dados**: Um servidor de base de dados é responsável pelo armazenamento, gestão e recuperação de dados estruturados ou não estruturados em vários nós. Numa arquitetura distribuída, as bases de dados podem ser fragmentadas (dividindo os dados em partes mais pequenas em vários nós) ou replicadas (mantendo cópias dos dados nos nós para tolerância a falhas).
Filas de mensagens e serviços de coordenação**: Os sistemas distribuídos geralmente dependem de ferramentas de mensagens (como Apache Kafka ou NATS) ou serviços de coordenação (como o ZooKeeper) para gerenciar a comunicação entre os nós. Essas ferramentas ajudam a agendar tarefas, acompanhar o progresso e garantir que dois nós não estejam executando o mesmo trabalho simultaneamente. Elas também lidam com anúncios de todo o sistema - como quando um nó fica on-line ou off-line, para que o resto do sistema possa se adaptar.
Tipos de arquitecturas de computação distribuída
A computação distribuída pode assumir muitas formas, dependendo de como os nós interagem e compartilham responsabilidades. Abaixo estão algumas arquiteturas comuns, juntamente com exemplos de como elas funcionam em diferentes cenários, incluindo o banco de dados Milvus. A escolha da arquitetura distribuída correta depende da dimensão da carga de trabalho, dos requisitos de latência e das restrições de custos.
Tipos de computação distribuída](https://assets.zilliz.com/Types_of_Distributed_Computing_524a467d73.png)
Figura: Tipos de computação distribuída
1. Modelo cliente-servidor
No modelo cliente-servidor, um ou mais servidores centrais tratam os pedidos de vários dispositivos clientes. Cada servidor é normalmente mais potente do que um cliente individual e aloja a lógica comercial principal ou o armazenamento de dados. Os clientes enviam pedidos (como buscar dados ou executar cálculos) e os servidores respondem com as informações ou resultados solicitados.
Prós**: Separação clara de funções, controlo centralizado e gestão de segurança simplificada.
Contras**: Os clientes podem perder o acesso ao serviço se um servidor ficar inoperante. O escalonamento também pode ser um desafio se os pedidos excederem a capacidade do servidor.
2. Redes peer-to-peer (P2P)
As arquitecturas peer-to-peer tratam todos os nós como iguais. Cada nó pode atuar tanto como cliente como servidor, partilhando recursos ou ficheiros sem depender de um servidor central. Nesta arquitetura, os nós ligam-se diretamente uns aos outros. Em vez de solicitar dados a um único servidor autorizado, os pares trocam dados entre si.
Prós**: Não existe um ponto único de falha e o escalonamento através da adição de mais pares pode ser mais fácil.
Contras**: Gerir a consistência dos dados e a qualidade do serviço pode ser difícil em ambientes totalmente descentralizados.
3. Computação em cluster
Um cluster é um grupo de servidores que trabalham juntos de forma tão próxima que parecem ser um único sistema. As tarefas podem ser divididas entre os nós para processamento paralelo, tornando a computação em cluster popular para cargas de trabalho de alto desempenho. Os servidores de um cluster partilham frequentemente o armazenamento e as tarefas são divididas entre eles por um sistema de agendamento ou equilibrador de carga. Se um servidor falhar, os outros podem continuar a funcionar.
Arquitetura Milvus: Milvus utiliza nós agrupados para gerir grandes volumes de dados vectoriais. A distribuição de índices vectoriais por várias máquinas pode tratar eficazmente milhares de milhões de vectores de elevada dimensão. Esta abordagem de clustering aumenta o desempenho e a resiliência, especialmente quando se lida com pesquisas massivas ou cargas de trabalho de recomendação.
Prós**: Ótimo para processamento paralelo e tolerância a falhas.
Contras**: Pode ser complexo de gerir e exigir maiores investimentos em hardware.
4. Computação em nuvem e de borda
A computação em nuvem fornece recursos sob demanda (como máquinas virtuais, armazenamento e serviços) pela Internet. A computação de borda coloca o processamento e o armazenamento de dados mais próximos da fonte de dados (por exemplo, dispositivos IoT) para reduzir a latência. Na computação em nuvem, as organizações executam aplicações em servidores remotos mantidos por fornecedores de nuvem. A capacidade é normalmente escalável num curto espaço de tempo. Na computação periférica, os dados gerados pelos dispositivos são processados localmente ou em centros de dados periféricos próximos, reduzindo a necessidade de enviar tudo para uma nuvem central.
Vantagens**: Escalonamento elástico, flexibilidade e custos operacionais potencialmente mais baixos. As configurações de ponta também melhoram a capacidade de resposta para tarefas sensíveis ao tempo.
Contras**: Requer ligações de rede estáveis (no caso da computação em nuvem) e os dispositivos de extremidade podem ter recursos limitados.
5. Microsserviços
Os Microsserviços dividem uma aplicação em serviços mais pequenos, fracamente acoplados, que comunicam através de uma rede. Cada serviço trata de uma função específica, como a autenticação do utilizador ou a indexação de dados. Os serviços podem ser executados em máquinas separadas ou contentores. Expõem APIs para comunicação e podem ser escalados de forma independente para corresponder à sua carga de trabalho específica.
Prós**: Simplifica as actualizações, uma vez que cada serviço pode ser alterado sem afetar todo o sistema. Também permite o dimensionamento especializado, em que apenas os serviços mais utilizados recebem nós adicionais.
Os contras são**: adiciona complexidade ao gerenciamento de muitos serviços, garantindo o funcionamento sem problemas. A monitorização, o registo e a implementação de actualizações requerem um planeamento cuidadoso.
Casos de utilização de computação distribuída
A computação distribuída tem uma ampla gama de soluções modernas. Abaixo estão alguns dos cenários mais comuns em que as organizações se beneficiam da divisão de cargas de trabalho e dados entre nós interconectados:
Análise de grandes dados e processamento em tempo real: As organizações executam grandes conjuntos de dados em paralelo em vários nós para acelerar a análise. Os dados continuam a fluir e as actualizações acontecem quase instantaneamente. Isto é crucial nos sectores financeiro, dos cuidados de saúde e do comércio eletrónico, onde as decisões são tomadas com base em informações rápidas.
Aprendizado de máquina e treinamento de modelos de IA:** Modelos complexos são treinados mais rapidamente quando os cálculos são executados em várias máquinas simultaneamente. Esta configuração lida eficazmente com grandes conjuntos de caraterísticas e reduz o tempo total de formação. É comum no reconhecimento de imagens, PNL e recomendações personalizadas.
Aplicações Web de elevado tráfego e comércio eletrónico:** Os pedidos são distribuídos por vários servidores, pelo que nenhuma máquina fica sobrecarregada. Se um servidor falhar, os restantes continuam a funcionar para evitar grandes períodos de inatividade. Com o escalonamento flexível, é mais fácil lidar com picos repentinos, como as vendas de fim de ano.
Internet das Coisas (IoT) e Redes de Sensores:** Numerosos sensores alimentam dados em nós distribuídos, que os processam perto da fonte para respostas mais rápidas. Esta abordagem localizada melhora a monitorização e ajuda com alertas em tempo real. É amplamente adoptada em cidades inteligentes, fabrico e veículos conectados.
Investigação científica e computação de alto desempenho (HPC):** Tarefas pesadas, como simulações climáticas, são divididas em trabalhos mais pequenos que são executados em paralelo. Isto reduz drasticamente os tempos de cálculo e apoia as colaborações científicas globais. Os investigadores podem aperfeiçoar modelos mais rapidamente e fazer avançar a inovação.
Redes de distribuição de conteúdos (CDN):** Armazenar ficheiros e conteúdos multimédia em servidores de todo o mundo, permitindo aos utilizadores aceder aos conteúdos a partir do nó mais próximo. Esta configuração reduz os tempos de carregamento e os atrasos na rede, tornando-a vital para serviços de streaming, descarregamentos de ficheiros de grandes dimensões e sítios Web de elevado tráfego.
Benefícios dos sistemas distribuídos
As organizações recorrem a sistemas distribuídos para lidar com dados e tarefas computacionais em constante crescimento. Abaixo estão algumas das principais vantagens que ajudam as equipas a escalar, a manter a resiliência e a trabalhar de forma mais eficiente:
Escalabilidade e partilha de recursos: As arquitecturas distribuídas permitem que as organizações adicionem mais máquinas à medida que as cargas de trabalho crescem, em vez de dependerem de um servidor grande. O sistema evita estrangulamentos e melhora o rendimento, dividindo dados e tarefas em vários nós.
Tolerância a falhas e redundância:** Quando os dados e tarefas críticos são replicados em vários nós, o sistema pode continuar a funcionar mesmo que um nó falhe. Esta conceção reduz o tempo de inatividade e preserva o acesso dos utilizadores.
Design flexível e modular:** Os sistemas distribuídos dividem frequentemente as tarefas em módulos mais pequenos e independentes. Cada nó lida com tarefas específicas, facilitando a atualização ou substituição de componentes sem perturbar todo o ambiente.
Equilíbrio entre consistência e disponibilidade (CAP Theorem): É difícil para os sistemas distribuídos serem totalmente consistentes e estarem sempre disponíveis ao mesmo tempo, especialmente quando ocorrem problemas de rede. O equilíbrio exato depende do grau de importância da consistência imediata para cada caso de utilização.
Desempenho e rendimento melhorados:** Ao executar tarefas em paralelo, os sistemas distribuídos podem processar mais operações em menos tempo. Isto é essencial para a análise de grandes volumes de dados ou para pesquisas vectoriais em tempo real.
Desafios e considerações
Embora os sistemas distribuídos ofereçam muitas vantagens, também introduzem complexidades únicas. Abaixo estão alguns obstáculos e factores comuns a ter em conta ao criar e manter infra-estruturas distribuídas:
Latência da rede e limites de largura de banda: As tarefas que abrangem servidores distantes podem ficar mais lentas se as conexões de rede forem fracas ou estiverem sobrecarregadas. Quando a largura de banda é limitada, as grandes transferências de dados podem enfrentar estrangulamentos. Colocar nós mais próximos dos utilizadores ou armazenar dados em cache pode ajudar a reduzir a [latência] (https://zilliz.com/ai-faq/what-is-the-role-of-network-latency-in-distributed-databases).
Consistência de dados e tolerância a partições:** Manter tudo sincronizado pode ser um desafio quando os dados são armazenados em vários nós. Falhas de rede ou interrupções de nós introduzem conflitos que exigem um tratamento cuidadoso. Alguns sistemas favorecem actualizações rápidas, enquanto outros dão prioridade a uma precisão rigorosa.
Segurança e privacidade dos dados:** Os dados deslocam-se entre máquinas, aumentando o risco de fugas ou de acesso não autorizado. A encriptação e os controlos de acesso rigorosos ajudam a proteger as informações sensíveis. Auditorias regulares e verificações de conformidade garantem que os dados do utilizador permanecem protegidos.
Gerenciando transações distribuídas:** Uma única transação pode envolver vários serviços ou nós, complicando a coordenação. Protocolos como a confirmação em duas fases ou [gestores de transacções] (https://zilliz.com/ai-faq/what-is-the-role-of-a-distributed-transaction-manager) acompanham estes passos. Estratégias de reversão cuidadosas evitam que falhas parciais corrompam os dados.
Apresentando Milvus: um banco de dados vetorial distribuído e nativo da nuvem
O Milvus foi projetado desde o início como um sistema distribuído nativo da nuvem para gerenciar dados vetoriais de alta dimensão. Ao dividir os dados e o processamento em vários nós, o Milvus oferece os principais benefícios da computação distribuída - escalabilidade, tolerância a falhas e execução paralela - tornando-o adequado para o treinamento de modelos de IA, sistemas de recomendação em tempo real e análises complexas.
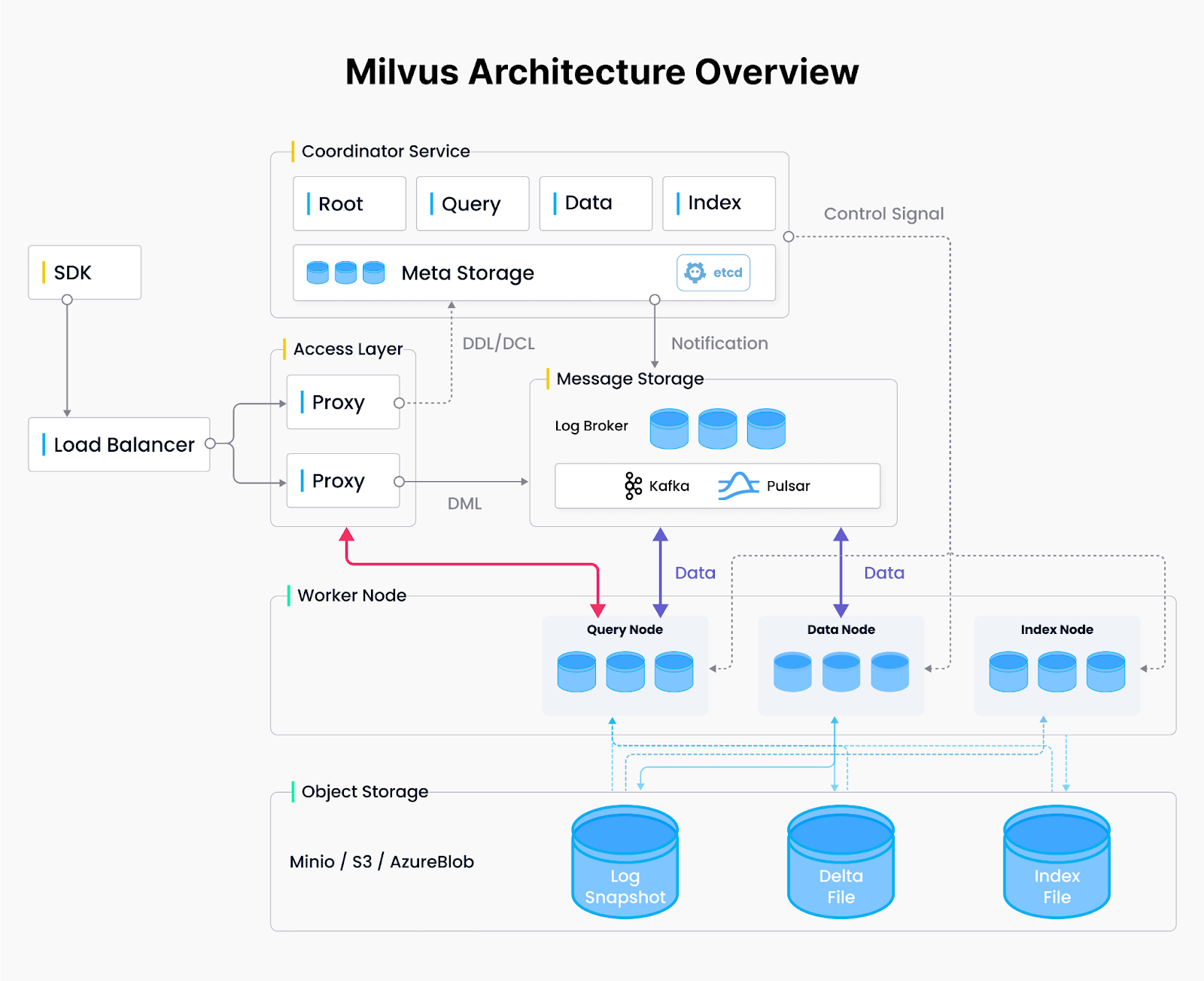 Milvus Architecture.png
Milvus Architecture.png
Figura: Arquitetura Milvus
Arquitetura distribuída Milvus: Design de quatro camadas
O Milvus é uma [base de dados vetorial] amplamente utilizada (https://zilliz.com/learn/what-is-vetor-database) que adopta uma arquitetura de sistema distribuída composta por quatro camadas para atribuir dinamicamente recursos onde quer que sejam mais necessários - quer se trate de mais potência de computação para indexação em grande escala ou memória adicional para tratar consultas complexas em paralelo.
Camada de acesso:** Os nós de acesso sem estado tratam dos pedidos recebidos, actuando como ponto de entrada para o sistema.
Camada de coordenação: coordena as atribuições de nós e o gerenciamento de recursos, ativando ou desativando os workers conforme necessário.
Camada de trabalho: executa as principais tarefas de consulta, ingestão de dados e criação de índices em nós escaláveis e sem estado.
Camada de armazenamento: mantém dados vetoriais e metadados do sistema para tolerância a falhas e persistência do nó.
Escalabilidade e consistência na arquitetura distribuída Milvus
O Milvus aplica princípios de computação distribuída para lidar com conjuntos de dados vectoriais maciços, mantendo a consistência dos dados. Abaixo estão os principais recursos de design que o ajudam a escalar horizontalmente, minimizar gargalos e oferecer níveis de consistência ajustáveis:
Escalonamento horizontal: Milvus segmenta grandes conjuntos de dados em partes gerenciáveis. Cada segmento é indexado independentemente, portanto, à medida que seus dados crescem, é possível adicionar mais nós sem revisar a infraestrutura existente.
Nós independentes para consulta, dados e índice:** Para escalar funções específicas, consultas, ingestão de dados e indexação são executados independentemente em tipos de nós separados. Essa separação ajuda a evitar gargalos e garante que o sistema possa lidar com bilhões de vetores.
Consistência ajustável e** Sharding: Os dados são fragmentados em vários nós para gravações simultâneas, enquanto os níveis de consistência ajustáveis do Milvus permitem-lhe equilibrar o desempenho e a precisão com base nas necessidades da sua aplicação.
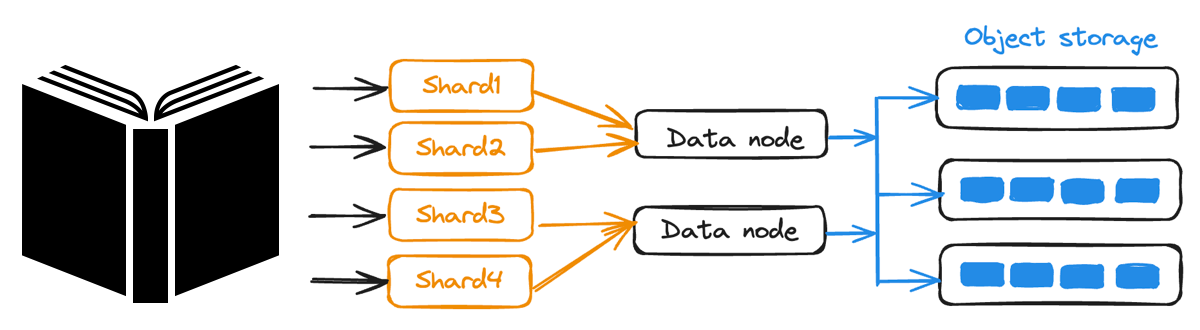 Fragmentação de dados em Milvus
Fragmentação de dados em Milvus
Figura: Fragmentação de dados em Milvus
Múltiplos modos de implantação para diferentes necessidades
Milvus oferece várias [opções de implantação] (https://milvus.io/docs/install-overview.md) para acomodar diferentes escalas de dados e requisitos de desempenho. Seja testando em uma única máquina ou executando um sistema de produção em larga escala, esses modos permitem que você combine recursos e complexidade com as necessidades do seu projeto. Abaixo está uma ilustração do nível de escalonamento de dados para cada banco de dados vetorial. Pode ver que o Milvus distributed foi concebido para lidar com escalas de dados de dezenas de milhões e mais.
Modos de implantação do Milvus](https://assets.zilliz.com/Milvus_Deployment_Modes_63d691a4d6.png)
Figura: Modos de implantação do Milvus
Milvus Lite: Uma biblioteca Python leve que fornece as funcionalidades principais do Milvus sem precisar de um processo de servidor separado. É ideal para experiências de pequena escala, prototipagem rápida ou demonstrações rápidas em ambientes locais. O Milvus Lite permite-lhe começar rapidamente com uma configuração mínima se estiver a construir uma prova de conceito ou a testar novas funcionalidades num notebook.
Milvus Distributed:** Uma arquitetura totalmente multi-nó concebida para exigências à escala empresarial. Ao separar as tarefas entre nós de acesso, coordenadores, trabalhadores e camadas de armazenamento, ele lida com bilhões (ou até dezenas de bilhões) de vetores com alta disponibilidade e tolerância a falhas. Esse modelo é a escolha ideal para organizações que esperam que seus dados cresçam rapidamente, exigem desempenho robusto em consultas simultâneas e desejam a flexibilidade de adicionar ou remover nós com base na carga de trabalho.
Milvus Standalone:** Uma implantação de nó único que agrupa todos os componentes do Milvus em um ambiente, geralmente distribuído por meio de uma imagem do Docker. Isso torna a instalação e a manutenção simples e fornece capacidade suficiente para volumes de dados moderados. As equipas que procuram executar cargas de trabalho de produção que não requerem escalabilidade maciça ou mecanismos de failover complexos encontrarão esta opção económica e fiável.
Para saber mais sobre a implementação do Milvus, leia o nosso guia: [Como escolher o modo de implantação Milvus certo para seus aplicativos de IA] (https://zilliz.com/blog/choose-the-right-milvus-deployment-mode-ai-applications).
Conclusão
A computação distribuída reformulou a forma como as organizações lidam com dados e escalam as suas aplicações, afastando-se dos servidores monolíticos para clusters flexíveis e tolerantes a falhas de nós interligados. Ao dividir tarefas e dados por várias máquinas, as equipas conseguem um processamento mais rápido, uma maior disponibilidade e uma utilização mais eficiente dos recursos. As soluções modernas, como o Zilliz, aplicam estes princípios para fornecer uma base de dados de vectores nativa da nuvem que pode processar milhares de milhões de vectores em paralelo. À medida que os volumes de dados continuam a aumentar e os casos de utilização se tornam mais complexos, a adoção de uma abordagem distribuída - seja para análise, aprendizagem automática ou recomendações em tempo real - continua a ser uma estratégia fundamental para se manter competitivo no atual mundo orientado para os dados.
FAQs sobre computação distribuída
Porquê escolher um sistema distribuído em vez de um servidor único e potente? Com um sistema distribuído, pode adicionar mais máquinas à medida que as cargas de trabalho aumentam, em vez de atualizar um único servidor. Esta flexibilidade aumenta o desempenho, reduz os custos e diminui o impacto de qualquer ponto único de falha.
Como é que os dados se mantêm consistentes num ambiente distribuído?**Os sistemas distribuídos utilizam protocolos e algoritmos (como mecanismos de consenso) para manter os dados sincronizados em vários nós. A abordagem exacta varia consoante o sistema, mas o objetivo é garantir que as actualizações não entram em conflito e que cada nó tem a visualização correta dos dados.
É difícil manter infra-estruturas distribuídas?** Embora os sistemas distribuídos apresentem mais partes móveis - como comunicação de rede, coordenação de nós e replicação - as ferramentas adequadas e as melhores práticas podem atenuar a complexidade. Ferramentas como Kubernetes e plataformas de monitoramento simplificam a orquestração e a observabilidade.
Onde é que o Milvus se enquadra na computação distribuída? O Milvus é uma base de dados vetorial distribuída, nativa da nuvem, concebida para pesquisas de semelhanças em grande escala. Ao dividir os dados em segmentos e aproveitar a indexação paralela, o Milvus pode lidar com milhares de milhões de vectores em vários nós sem sacrificar a velocidade ou a fiabilidade.
E se meus dados precisarem ser coletados ou se o tráfego aumentar repentinamente? Os sistemas distribuídos são ideais para lidar com mudanças repentinas na demanda. Pode ativar nós ou recursos adicionais rapidamente, evitando a sobrecarga em qualquer máquina e mantendo um desempenho consistente mesmo durante os períodos de pico de utilização.
Recursos relacionados
Modelos de IA com melhor desempenho para seus aplicativos GenAI | Zilliz](https://zilliz.com/ai-models)
Captura de dados de alterações: manter os seus sistemas sincronizados em tempo real
Processamento de dados não estruturados da nuvem para a borda
Otimizando a comunicação de dados: Milvus adota o NATS Messaging
Introduzindo Monitoramento Abrangente e Observabilidade no Zilliz Cloud
- De Servidores Únicos a Sistemas Distribuídos: A Evolução
- Como é que a computação distribuída funciona?
- Tipos de arquitecturas de computação distribuída
- Casos de utilização de computação distribuída
- Benefícios dos sistemas distribuídos
- Desafios e considerações
- Apresentando Milvus: um banco de dados vetorial distribuído e nativo da nuvem
- Conclusão
- FAQs sobre computação distribuída
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis