




O que é uma Rede Neural Convolucional? Um guia para engenheiros**

O que é uma Rede Neural Convolucional? Um guia para engenheiros**
Uma Rede Neural Convolucional (CNN) é um modelo de aprendizagem profunda adaptado a dados visuais como imagens, vídeos e, por vezes, até ficheiros de áudio.
As CNN transformaram domínios como a visão por computador, a análise de imagens e processamento, a deteção de objectos e até o processamento de linguagem natural (PNL).
As redes neuronais tradicionais, como MLP (Multi-Layer Perceptron) ou Fully Connected Networks, tratam os dados de imagem como [vectores] planos(https://zilliz.com/learn/what-is-vetor-database), o que pode ser limitativo quando se lida com a informação espacial presente nos dados visuais. Este facto pode levar a uma fraca precisão devido a pressupostos errados (inductive bias).
As CNNs resolvem estes problemas preservando a estrutura da imagem, como a conetividade local e o conteúdo dos pixéis dos dados da imagem, tornando-as eficientes no reconhecimento de padrões.
Este post destaca as vantagens das CNN, explica a sua arquitetura e dá um exemplo simples de conceção de um modelo CNN.
Principais razões para utilizar uma CNN
As CNNs são excelentes na extração de caraterísticas significativas de dados visuais em bruto, superando as redes neurais tradicionais. As razões para usar uma CNN incluem:
Partilha de parâmetros-A CNN partilha o mesmo conjunto de parâmetros em diferentes regiões de entrada, o que é útil para identificar eficazmente os padrões ocultos em dados de elevada dimensão.
Número reduzido de parâmetros** - As CNN utilizam a técnica de pooling e convolução, o que reduz significativamente o número de parâmetros em comparação com as redes totalmente ligadas.
Aprendizagem hierárquica de caraterísticas**-A CNN imita a estrutura hierárquica do sistema visual humano.
Desempenho topo de gama** - As CNN superam consistentemente as redes neuronais tradicionais em tarefas como a deteção de objectos, o processamento de imagens, o reconhecimento de voz e a segmentação de imagens. Note-se que os recentes avanços na visão computacional introduziram também [Transformadores] convolucionais e não convolucionais (https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)).
Vantagens e desvantagens da rede neural convolucional
Embora as CNNs tenham mudado o jogo da visão computacional, precisamos conhecer os prós e os contras. Vamos mergulhar nas vantagens e desvantagens das CNNs:
Vantagens da rede neural convolucional:
- Deteção de padrões e caraterísticas: As CNNs são óptimas na deteção de padrões e caraterísticas em imagens, vídeos e sinais de áudio. A sua estrutura hierárquica permite-lhes aprender caraterísticas complexas a partir de dados brutos.
- Invariância às transformações: As CNNs são invariantes em termos de translação, rotação e escala. O que significa que podem reconhecer objectos mesmo que estes se encontrem em diferentes posições, orientações ou tamanhos numa imagem.
- Extração automática de caraterísticas: As CNNs permitem uma formação de ponta a ponta, sem necessidade de extração manual de caraterísticas. A rede aprende a encontrar caraterísticas relevantes diretamente a partir dos dados brutos de entrada.
- Escalabilidade e precisão: As CNNs podem lidar com grandes quantidades de dados e são exactas em tarefas complexas. À medida que são fornecidos mais dados, o seu desempenho melhora normalmente.
Desvantagens da rede neural convolucional:
Custo computacional: O treinamento de CNNs é computacionalmente caro e requer muita memória. Isto pode ser um desafio para implementar sem hardware especializado como GPUs.
Sobreajuste: Se não forem fornecidos dados suficientes ou [técnicas de regularização] adequadas (https://zilliz.com/learn/understanding-regularization-in-nueral-networks), as CNNs podem ter um ajuste excessivo. Isso significa que elas terão um bom desempenho em dados de treinamento, mas não conseguirão generalizar para novos dados não vistos.
Requisitos de dados: As CNNs requerem grandes quantidades de dados rotulados para o treino. Em domínios em que os dados rotulados são escassos ou dispendiosos de obter, isto pode ser uma grande limitação.
Interpretabilidade: É difícil interpretar o que uma CNN aprendeu. A natureza de "caixa negra" dos modelos de aprendizagem profunda torna difícil compreender o raciocínio subjacente às suas previsões, o que pode ser um problema em aplicações sensíveis.
Compreender estas vantagens e desvantagens é crucial para decidir se se deve utilizar as CNN para uma determinada tarefa e para conceber e implementar soluções baseadas em CNN.
Técnicas de regularização comuns em CNNs
Como mencionámos nas desvantagens, as CNNs podem ser propensas a sobreajustes, especialmente quando trabalham com dados limitados. As técnicas de regularização são usadas para evitar que as CNNs se ajustem demais aos dados de treinamento, para que o modelo possa generalizar melhor para dados não vistos. Aqui estão algumas técnicas de regularização comuns usadas em CNNs:
Dropout: Esta técnica "retira" aleatoriamente (ou seja, define como zero) alguns recursos de saída da camada durante o treinamento. O abandono força a rede a aprender caraterísticas mais robustas que não dependem de um único neurónio. Ao fazer isso, a rede torna-se menos sensível aos pesos específicos dos neurónios e, por sua vez, resulta numa melhor generalização. Durante o teste, todos os neurónios são utilizados, mas as suas saídas são reduzidas para compensar os neurónios em falta durante o treino.
Regularização L1: Também conhecida como regularização Lasso, a regularização L1 adiciona um termo de penalização à função de perda que é proporcional ao valor absoluto dos pesos. Essa técnica incentiva a esparsidade no modelo, levando alguns pesos a zero. A regularização L1 é útil quando se pretende criar um modelo mais simples, removendo caraterísticas menos importantes.
Regularização L2: Também conhecida como Ridge Regularization, a regularização L2 adiciona um termo de penalidade à função de perda que é proporcional ao quadrado dos pesos. Esta técnica desencoraja pesos grandes e distribui os valores dos pesos de forma mais uniforme. A regularização L2 não resulta em modelos esparsos como o L1, mas pode ajudar a reduzir o impacto de caraterísticas menos relevantes.
Tanto L1 quanto L2 podem reduzir o número de pesos e tornar a rede mais eficiente. A escolha entre L1 e L2 (ou uma combinação de ambas, conhecida como regularização Elastic Net) depende do problema e do conjunto de dados.
Essas técnicas de regularização, quando usadas corretamente, resolvem um dos maiores problemas do aprendizado profundo e de máquina atualmente.
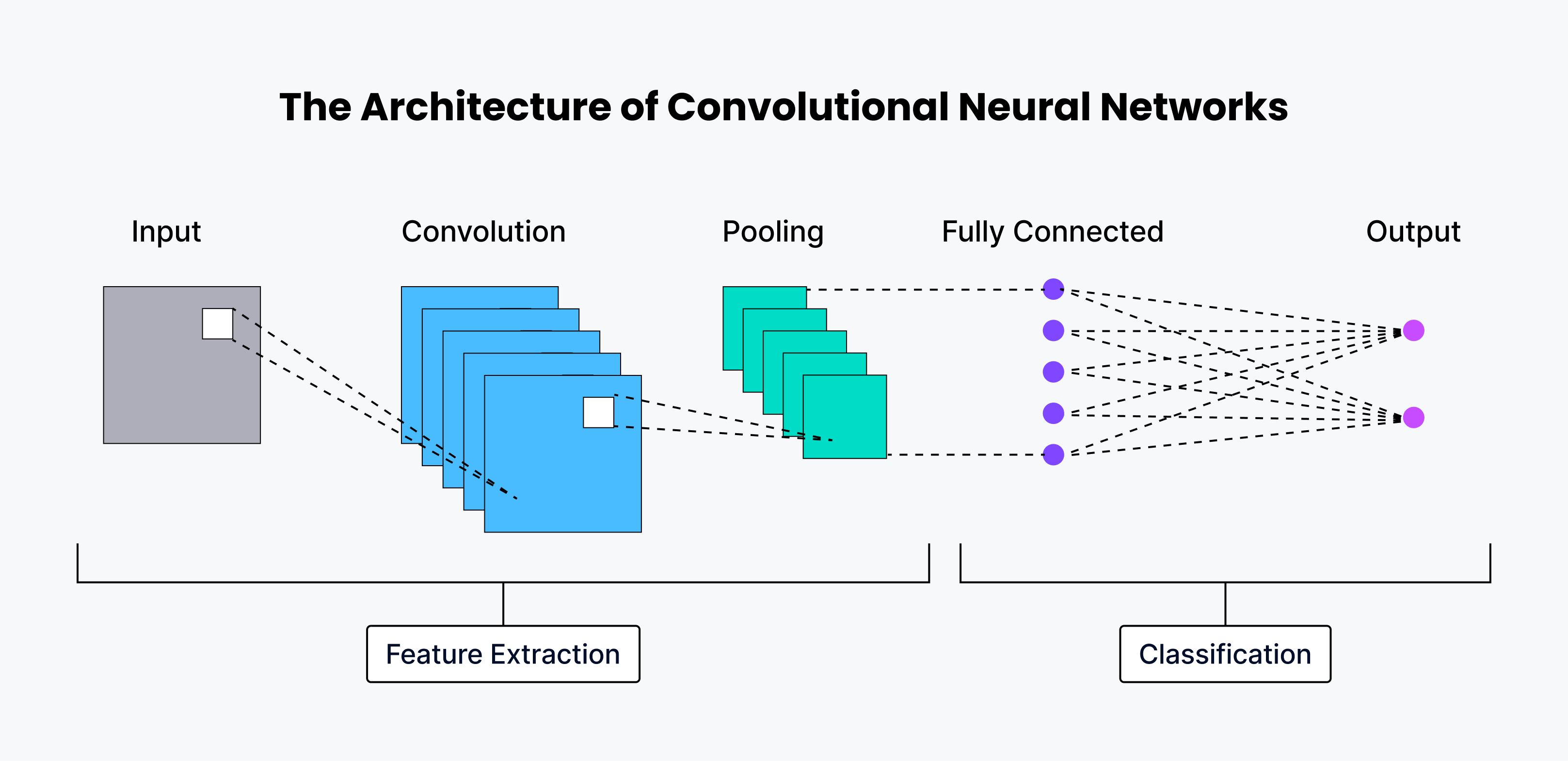
Arquitetura CNN e como funciona
Uma CNN tem grandes capacidades, o que permite a estas redes encontrar padrões ocultos e decifrar dados visuais com uma precisão excecional.
O sistema neural humano tem várias camadas, e cada uma é responsável por executar uma função única. As CNN têm uma arquitetura semelhante, com cada camada a extrair caraterísticas diferentes da imagem de entrada. Segue-se uma explicação detalhada de todas as camadas envolvidas na arquitetura das CNN.
As primeiras camadas são camadas de convolução, que são responsáveis pela extração das caraterísticas básicas da imagem, como arestas e forma.
As camadas seguintes são camadas de pooling, que são a camada de saída responsável pela redução do tamanho dos [mapas de caraterísticas] (https://www.baeldung.com/cs/cnn-feature-map).
Finalmente, a última camada é a camada totalmente ligada (FC), que é responsável pela classificação da imagem numa das categorias dadas.
Quase todas as arquitecturas convolucionais puras modernas têm apenas uma camada de pooling global no final, seguida de uma camada totalmente ligada.
Camada de convolução
A camada de convolução é o núcleo de uma CNN, concebida para encontrar padrões distintos nos dados de entrada. Pega na imagem de entrada e aplica um conjunto de filtros para produzir uma saída chamada mapa de caraterísticas. Os filtros são pequenas matrizes de pesos que analisam a imagem de entrada para identificar diferentes padrões. À medida que o filtro se desloca pela imagem, fá-lo em passos definidos pelo stride - o número de pixéis que o filtro desloca em cada passo. Por vezes, o preenchimento é utilizado para controlar o tamanho da saída, adicionando pixels extra à volta da entrada. Existem diferentes tipos de preenchimento, incluindo preenchimento válido, preenchimento zero (sem preenchimento), preenchimento igual (o tamanho da saída é igual ao tamanho da entrada) e preenchimento total (que aumenta o tamanho da saída). Após a operação de convolução, é aplicada uma função de ativação não linear, normalmente ReLU (Rectified Linear Unit), para introduzir a não linearidade no modelo.
Mais camadas convolucionais
Como mencionamos anteriormente, outra camada convolucional pode vir após a primeira camada convolucional. Quando isso acontece, a CNN torna-se hierárquica, pois as camadas posteriores podem ver os pixels dentro dos campos receptivos das camadas anteriores. Esta estrutura hierárquica permite que a camada oculta da rede aprenda caraterísticas mais complexas à medida que os dados fluem através das camadas.
Digamos que queremos reconhecer um rosto humano numa imagem. Pode pensar-se num rosto como uma composição de várias caraterísticas. São os olhos, o nariz, a boca, as sobrancelhas e assim por diante. Cada caraterística individual do rosto é um padrão de nível inferior na rede neuronal e a combinação destas caraterísticas é um padrão de nível superior, uma hierarquia de caraterísticas no córtex visual da CNN.
Na primeira camada convolucional, a rede pode aprender a detetar caraterísticas simples como arestas, curvas e formas básicas. Estas podem ser o contorno das caraterísticas faciais ou o contraste entre diferentes partes do rosto.
A classificação de imagens da segunda camada pode combinar estas caraterísticas básicas para reconhecer formas mais complexas. Por exemplo, pode detetar formas circulares (possivelmente olhos) ou linhas curvas (talvez o contorno da boca ou das sobrancelhas).
Nas camadas seguintes, a rede pode começar a reconhecer caraterísticas faciais completas, combinando os padrões das camadas anteriores. Um neurónio pode disparar quando detecta uma estrutura semelhante a um olho, outro quando detecta um padrão semelhante a um nariz.
Nas camadas finais, a CNN combinaria todas estas caraterísticas faciais para reconhecer um rosto completo. Nesta fase, a rede não está apenas a detetar caraterísticas individuais, mas a compreender como estas caraterísticas se relacionam entre si no contexto de um rosto.
Finalmente, as camadas convolucionais convertem a imagem em valores numéricos para que a rede neural possa interpretar as imagens de entrada e extrair padrões a vários níveis de abstração. Esta aprendizagem hierárquica de caraterísticas é um dos principais pontos fortes das CNN em tarefas de reconhecimento de imagens, para compreender objectos complexos e multicomponentes como os rostos.
Camada de agrupamento
A seguir à camada de convolução, encontramos frequentemente uma camada de pooling. O objetivo desta camada de agrupamento (downsamples) é reduzir o tamanho dos mapas de caraterísticas, preservando as caraterísticas mais importantes. Isto ajuda a reduzir a complexidade computacional e a controlar o sobreajuste. Existem duas técnicas comuns de agrupamento: o agrupamento máximo, que retira o valor máximo de uma pequena região do mapa de caraterísticas, e o agrupamento médio, que retira o valor médio de uma pequena região.
Camada totalmente conectada (FC)
A camada final de uma CNN é tipicamente uma camada totalmente conectada que classifica a saída da CNN. Esta camada é semelhante a uma camada de rede neural tradicional, ligando-se a todos os neurónios da camada anterior. Utiliza as caraterísticas de alto nível aprendidas pelas camadas convolucionais para efetuar a classificação final ou a tarefa de regressão.
 The-Architecture-of-Convolutional-Neural-Networks.png
The-Architecture-of-Convolutional-Neural-Networks.png
Terminologia essencial
Ao trabalhar com CNNs, é importante compreender alguma terminologia essencial. Uma época refere-se a uma passagem completa por todo o conjunto de dados de treinamento. Dropout é uma técnica utilizada para evitar o sobreajuste, eliminando aleatoriamente os neurónios durante o processo de treino. A profundidade estocástica é outro método que encurta a rede durante o treinamento, eliminando aleatoriamente blocos residuais.
Passos - É o tamanho do passo que o filtro dá durante a operação de convolução.
Padding-Padding na CNN é a adição de zeros à volta dos limites da imagem para preservar a sua dimensão espacial após a convolução. É feito para evitar que a imagem encolha e para evitar a perda de informação após cada operação de convolução.
Época-Uma passagem completa por todo o conjunto de dados de treino.
Dropout (regularização)-Técnica para evitar o sobreajuste, eliminando aleatoriamente neurónios durante o treino, o que força a rede a aprender em vez de depender de mais neurónios.
Profundidade Estocástica- Encurta a rede durante o treino, eliminando aleatoriamente os blocos residuais e contornando as suas transformações através de ligações de salto. Entretanto, na altura do teste, toda a rede é utilizada para fazer previsões. Isto resulta numa melhoria do erro de teste e numa redução significativa do tempo de formação.
Tipos de redes neurais convolucionais
A história e o desenvolvimento das redes neuronais convolucionais remontam a várias décadas e muitos investigadores contribuíram para o seu desenvolvimento. Compreender esta história ajudá-lo-á a compreender o estado atual das CNN.
Base histórica
Kunihiko Fukushima lançou os alicerces das CNN em 1980 com o seu trabalho sobre o "Neocognitron", uma rede neural artificial hierárquica com várias camadas. Este modelo inicial podia aprender um reconhecimento robusto de padrões visuais.
Yann LeCun deu outro contributo importante em 1989 com o seu artigo "Backpropagation Applied to Handwritten Zip Code Recognition". LeCun aplicou a retropropagação para treinar redes neuronais para reconhecer padrões em códigos postais manuscritos. Este foi um grande passo para as aplicações práticas das redes neuronais.
LeNet-5: A arquitetura original da CNN
LeCun e a sua equipa continuaram a trabalhar nela durante a década de 1990 e finalmente criaram a LeNet-5 em 1998. A LeNet-5 aplicou os princípios de trabalhos anteriores ao reconhecimento de documentos. É considerada a arquitetura original da CNN e a base para todos os trabalhos futuros.
Evolução das arquitecturas CNN
Desde o LeNet-5, foram desenvolvidas muitas variantes de arquitecturas CNN. Novos conjuntos de dados, como o MNIST e o CIFAR-10, e concursos como o [ImageNet] (https://zilliz.com/glossary/imagenet) Large Scale Visual Recognition Challenge (ILSVRC) impulsionaram a maior parte desta inovação. Algumas das arquitecturas CNN notáveis que foram desenvolvidas são:
AlexNet: Desenvolvida por Alex Krizhevsky, Ilya Sutskever e Geoffrey Hinton, a AlexNet venceu o ILSVRC 2012. Era mais profunda e mais larga do que as CNNs anteriores, utilizava activações ReLU e dropout para regularização.
VGGNet: Desenvolvida pelo Visual Geometry Group em Oxford, a VGGNet é conhecida pela sua simplicidade e profundidade. Utiliza pequenos filtros convolucionais 3x3 em toda a rede.
GoogLeNet (Inception): Desenvolvida pela Google, introduziu o módulo "Inception" que permite uma computação mais eficiente e redes mais profundas.
ResNet: Desenvolvida pela Microsoft Research, a ResNet introduziu as ligações por saltos e permitiu o treino de redes muito mais profundas (até 152 camadas no documento original).
ZFNet: Uma melhoria em relação à AlexNet, a ZFNet (nomeada em homenagem aos seus criadores Zeiler e Fergus) venceu o ILSVRC 2013 ao ajustar os hiperparâmetros da arquitetura.
Cada uma destas arquitecturas trouxe inovações que ultrapassaram os limites do que era possível com as CNN, melhorando o desempenho em várias tarefas de visão computacional.
Como conceber uma rede neural de convolução
Ao projetar uma CNN, há várias decisões importantes a serem tomadas. Estas incluem a escolha do tamanho da entrada, a determinação do número de camadas de convolução, a seleção do tamanho e do número de filtros por camada de entrada, a escolha do método de agrupamento, a decisão sobre o número de camadas totalmente ligadas e a seleção das funções de ativação. Cada uma dessas escolhas pode afetar significativamente o desempenho e a eficiência da rede.
Escolher o tamanho da entrada-O tamanho da entrada representa o tamanho de uma imagem sobre a qual a CNN será treinada. O tamanho da entrada deve ser suficientemente grande para que a rede seja capaz de extrair as caraterísticas de um objeto que pretende classificar.
Escolher o número de camadas de convolução - Isto determina quantas caraterísticas a rede será capaz de aprender. Mais camadas de convolução permitem-lhe aprender caraterísticas mais complexas, mas o tempo de computação aumenta.
Escolha a dimensão do filtro - A dimensão do filtro, juntamente com o passo da convolução, determina a dimensão das caraterísticas que serão extraídas das imagens. Um filtro de maior dimensão extrairá um maior número de caraterísticas.
Escolher o número de filtros por camada- Isto determina o número de caraterísticas diferentes que podem ser extraídas de uma imagem.
Escolha o método de agrupamento - As duas técnicas de agrupamento mais comuns são o agrupamento máximo e o agrupamento médio. O agrupamento máximo obtém o valor máximo de uma pequena região do mapa de caraterísticas, enquanto o agrupamento médio obtém o valor médio de uma pequena região do mapa de caraterísticas.
Escolha o número de camadas totalmente conectadas - Isso determina o número de classes que a rede pode classificar.
Escolha a função de ativação - A [função de ativação] (https://zilliz.com/learn/class-activation-mapping-CAM) permite a aprendizagem de padrões mais complexos a partir do conjunto de dados de imagens. Para a classificação binária, é normal utilizar a função sigmoide. Numa declaração de problema de classificação multi-classe, a camada FC utiliza a função de ativação softmax. Atualmente, para introduzir a não linearidade nos dados, utilizam-se sobretudo as [funções de ativação] GeLU ou Swish(https://zilliz.com/glossary/activation-functions).
Abaixo está um exemplo simples de implementação de CNN com Python que classifica sinais de trânsito. Encontre o conjunto de dados no site do Kaggle.
Implementação simples de CNN com PyTorch
Para implementar um modelo CNN em Python, use frameworks como PyTorch, TensorFlow, Keras, etc. Estas estruturas fornecem a implementação de todas as camadas necessárias para uma CNN.
O processo começa com a importação dos módulos necessários, como se segue:
# dependências para computação
import pandas as pd
import numpy as np
# dependências para leitura e visualização de imagens
from cv2 import resize
from skimage.io import imread
import matplotlib.pyplot as plt
%matplotlib em linha
# dependência para criar o conjunto de validação
from sklearn.model_selection import train_test_split
# dependência para avaliar o modelo
from sklearn.metrics import accuracy_score
from tqdm import tqdm
# bibliotecas e módulos PyTorch
importar torch
from torch.autograd import Variable
from torch.nn import (Linear, ReLU, CrossEntropyLoss,
Sequencial, Conv2d, MaxPool2d, Module,
Softmax, BatchNorm2d, Dropout)
from torch.optim import Adam, SGD
Uma vez feito isso, carregue o conjunto de dados e as imagens com o seguinte código:
# Carregando o conjunto de dados
treino = pd.read_csv('Dados/treino.csv')
# carregar imagens de treino
imagens_treino = []
for img_name in tqdm(train['Path']):
# definir o caminho da imagem
caminho_da_imagem = 'Dados/' + str(nome_da_imagem)
# ler a imagem
img = imread(image_path, as_gray=True)
# redimensionar a imagem
img = resize(img, (28, 28))
# normalização dos valores de pixéis
img /= 255.0
# converter o tipo de pixel para float 32
img = img.astype('float32')
# introduzir a imagem na lista
train_img.append(img)
# converter a lista numa matriz numérica
train_x = np.array(train_img)
# Definir o objetivo
train_y = train['ClassId'].values
train_x.shape
Depois que os dados de treinamento forem carregados, será necessário criar um conjunto de dados de treinamento e validação usando o método train_test_split() do sklearn.
# criar conjunto de validação
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size = 0.1)
# Verificar as formas dos conjuntos de treino e validação
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)
Também será necessário remodelar os dados para o modelo Torch da seguinte forma:
# Conversão das imagens de treino para o formato Torch
train_x = train_x.reshape(-1, 1, 28, 28)
train_x = torch.from_numpy(train_x)
# Conversão do alvo para o formato torch
train_y = train_y.astype(int);
train_y = torch.from_numpy(train_y)
# Conversão das imagens de validação para o formato torch
val_x = val_x.reshape(-1, 1, 28, 28)
val_x = torch.from_numpy(val_x)
# Conversão do alvo para o formato torch
val_y = val_y.astype(int);
val_y = torch.from_numpy(val_y)
Em seguida, defina as diferentes camadas de uma CNN da seguinte forma:
classe Net(Module):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequencial(
# Definindo uma camada de convolução 2D
Conv2d(1, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# Definição de outra camada de convolução 2D
Conv2d(4, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
)
# camada densa final para previsão
self.linear_layers = Sequencial(
Linear(4 * 7 * 7, 43)
)
# Definição da passagem para a frente
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
return x
A rede CNN acima tem duas camadas de convolução seguidas de uma camada de pooling máximo com dimensões espaciais de 2 por 2.
Uma camada de achatamento pode ajudar a classificar as camadas ocultas na imagem do sinal nas respectivas classes.
Em seguida, vamos decidir sobre o optimizador e a função de perda e definir o procedimento de formação.
# definindo o modelo
modelo = Net()
# definição do optimizador
optimizador = Adam(model.parameters(), lr=0.07)
# definição da função de perda
critério = CrossEntropyLoss()
# Verificar se a GPU está disponível
se torch.cuda.is_available():
model = model.cuda()
critério = criterion.cuda()
print(modelo)
def train(epoch):
model.train()
tr_loss = 0
# obter o conjunto de treino
x_treino, y_treino = Variável(treino_x), Variável(treino_y)
# obter o conjunto de validação
x_val, y_val = Variable(val_x), Variable(val_y)
# converter os dados para o formato GPU
if torch.cuda.is_available():
x_train = x_train.cuda()
y_train = y_train.cuda()
x_val = x_val.cuda()
y_val = y_val.cuda()
# Limpar os gradientes dos parâmetros do modelo
optimizador.zero_grad()
# Previsão para o conjunto de treino e validação
output_train = model(x_train)
output_val = model(x_val)
# Calcular a perda do conjunto de treino e validação
loss_train = critério(output_train, y_train)
loss_val = criterion(output_val, y_val)
perdas_treino.append(perda_treino)
val_losses.append(perda_val)
# retropropagação e atualização dos parâmetros do modelo
perda_treino.retrocesso()
optimizador.step()
tr_loss = loss_train.item()
se epoch%2 == 0:
# imprimir a perda de validação
print('Época : ',época+1, '\t', 'perda :', perda_val)
Finalmente, treine o modelo para 25 épocas nos dados de treino da seguinte forma:
# definir o número de épocas
n_epochs = 25
# lista vazia para armazenar as perdas de treino
perdas_treino = []
# lista vazia para armazenar as perdas de validação
val_losses = []
# treinar o modelo
for epoch in range(n_epochs):
train(epoch)
No final, cada modelo estará lá para fazer previsões sobre os dados de teste. Para saber mais detalhes, consulte este blog para como escrever CNNs do zero no PyTorch.
FAQs
Qual é a diferença entre CNN e Deep Neural Networks?
Uma CNN é um tipo de rede neural que pode processar dados visuais como imagens, voz, vídeo, etc., enquanto as redes neurais profundas (DNNs) são um tipo de rede neural artificial que pode aprender padrões complexos a partir de dados.
Seguem-se as principais diferenças entre as CNN e as DNN.
Uma CNN tem uma arquitetura específica para o processamento de imagens. Por outro lado, uma DNN não tem qualquer arquitetura específica e pode funcionar para uma variedade de tarefas.
Uma CNN aprende caraterísticas de imagens utilizando camadas de convolução, enquanto uma DNN aprende caraterísticas com a ajuda de diferentes [tipos de camadas] (https://www.geeksforgeeks.org/deep-neural-network-with-l-layers/).
Uma CNN é mais difícil de treinar, requer mais dados e é computacionalmente dispendiosa em comparação com uma DNN.
Quais são as três camadas de uma CNN?
As três camadas de uma CNN são a camada de ativação, a camada de convolução, a camada de pooling e a camada totalmente conectada.
- Camada de convolução**-Esta camada é responsável pela extração de caraterísticas das imagens. Funciona através da digitalização de imagens com um filtro, que é uma pequena matriz de pesos. O filtro desloca-se pela imagem e os pesos são multiplicados pelos valores dos pixéis na imagem. Por fim, produz um mapa de caraterísticas que contém as caraterísticas extraídas.
Camada de pooling-A camada de pooling reduz o tamanho dos mapas de caraterísticas. Para o efeito, duas técnicas de agrupamento comuns são o agrupamento máximo e o agrupamento médio.
- Camada totalmente ligada** - É o mesmo que as redes neuronais tradicionais que classificam a saída da CNN. Os neurónios nas camadas totalmente ligadas classificam então a imagem num conjunto de classes.
O que é uma Rede Neural Convolucional no aprendizado profundo?
Uma rede neural convolucional é um tipo de rede neural profunda que processa imagens, discursos e vídeos para que possa usá-los para fazer previsões do mundo real em dados estruturados/não estruturados no crescente mundo digital.
Uma CNN ajuda a prever emoções humanas, comportamentos, interesses, gostos, desgostos, etc., de forma fácil e eficiente.
- Principais razões para utilizar uma CNN
- Vantagens e desvantagens da rede neural convolucional
- Técnicas de regularização comuns em CNNs
- **Arquitetura CNN e como funciona**
- Tipos de redes neurais convolucionais
- Como conceber uma rede neural de convolução
- **Implementação simples de CNN com PyTorch**
- **FAQs**
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis