




Avaliação RAG utilizando Ragas
*Este post foi escrito por Christy Bergman, Shahul Es e Jithin James.
A recuperação é um componente crucial dos sistemas de IA generativa, e seus desafios são particularmente evidentes na Retrieval Augmented Generation (RAG). A Retrieval Augmented Generation melhora os chatbots alimentados por IA, gerando respostas com base em dados extensivos em que foram treinados grandes modelos linguísticos (LLM). Apesar da sofisticação dos sistemas RAG, a exatidão da recuperação continua a ser um obstáculo significativo, tal como evidenciado pelas baixas pontuações de referências como WikiEval. Para ultrapassar estes desafios, é essencial estabelecer um quadro de avaliação abrangente e fazer experiências exaustivas para afinar os parâmetros dos RAG e obter um desempenho ótimo.
**No entanto, antes de poder fazer experiências com RAG, precisa de uma forma de avaliar que experiências tiveram os melhores resultados!
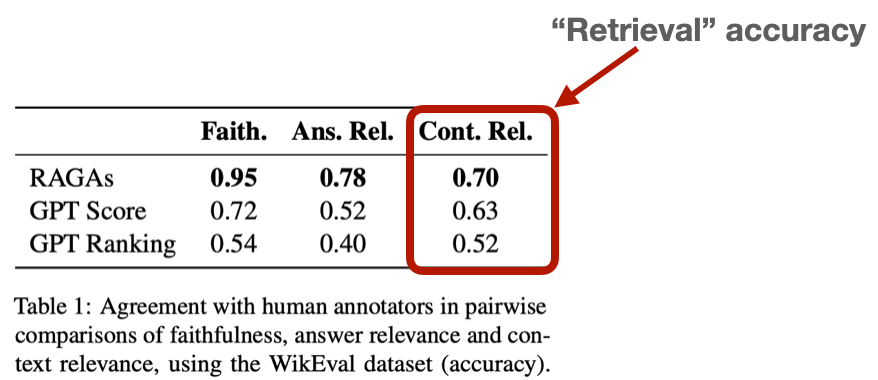
Fonte da imagem: https://arxiv.org/abs/2309.15217
O que são Ragas?
O Ragas é uma estrutura de avaliação especializada concebida para avaliar o desempenho dos sistemas Retrieval Augmented Generation (RAG). Fornece uma abordagem estruturada para avaliar a eficácia das implementações de RAG, utilizando Modelos de Linguagem Grandes (LLMs) avançados como juízes. O Ragas centra-se na automatização do processo de avaliação, oferecendo soluções escaláveis e económicas para avaliar as respostas geradas pela IA. A estrutura tem como objetivo abordar os enviesamentos e oferecer pontuações contínuas e explicáveis para resultados de linguagem natural. O Ragas simplifica a avaliação de sistemas RAG complexos, fornecendo métricas intuitivas e racionalizando o processo de avaliação da qualidade da recuperação.
Importância da avaliação dos sistemas RAG
A avaliação eficaz dos sistemas RAG é vital para refinar as respostas de IA. Uma estrutura de avaliação robusta garante que as experiências produzem resultados fiáveis e que a IA fornece respostas precisas e contextualmente adequadas. A automatização do processo de avaliação pode simplificar e acelerar esta tarefa, tornando-a mais económica e escalável.
Aproveitando os LLMs como juízes
A utilização de Modelos de Linguagem Grandes (LLMs) como o GPT-4 para avaliação tem ganho força devido à sua capacidade de avaliar vários aspectos da qualidade da recuperação, incluindo a relevância e a precisão. Embora possa parecer invulgar que um LLM avalie outro, a investigação indica que o GPT-4 se alinha com as avaliações humanas em cerca de 80% das vezes, o que corresponde ao "limite Bayesiano " da concordância humana. Este método automatiza o processo de avaliação, oferecendo escalabilidade e reduzindo custos em comparação com a rotulagem humana manual.
Abordagens à avaliação baseada em LLM
Existem duas abordagens principais para usar LLMs como juízes para avaliação RAG:
O MT-Bench usa um LLM para julgar apenas pares de pergunta-resposta que são verificados como verdade básica humana. Os humanos examinam inicialmente as perguntas e as respostas para garantir que as perguntas são suficientemente complexas para serem testadas antes de o LLM utilizar os 80 pares Q-A para avaliar diferentes descodificadores (componentes generativos de IA). Paper, Code, Leaderboard.
Ragas baseia-se na ideia de que os LLM podem avaliar eficazmente a produção de linguagem natural, formando paradigmas que ultrapassam os preconceitos da utilização direta dos LLM como juízes e fornecendo pontuações contínuas que são explicáveis e intuitivas de compreender). Paper, Code, Docs.
O resto deste blogue apresentará o Ragas, que enfatiza a automatização e a escalabilidade das avaliações RAG.
Dados de avaliação necessários para o Ragas
De acordo com a [documentação do Ragas] (https://docs.ragas.io/en/stable/howtos/applications/data_preparation.html), sua avaliação do pipeline do RAG precisará de quatro pontos de dados principais.
Pergunta: A pergunta feita.
Contextos: Partes de texto dos seus dados que melhor correspondem ao significado da pergunta.
Resposta: Resposta gerada pelo chatbot do RAG à pergunta.
Resposta verdadeira: Resposta esperada para a pergunta.
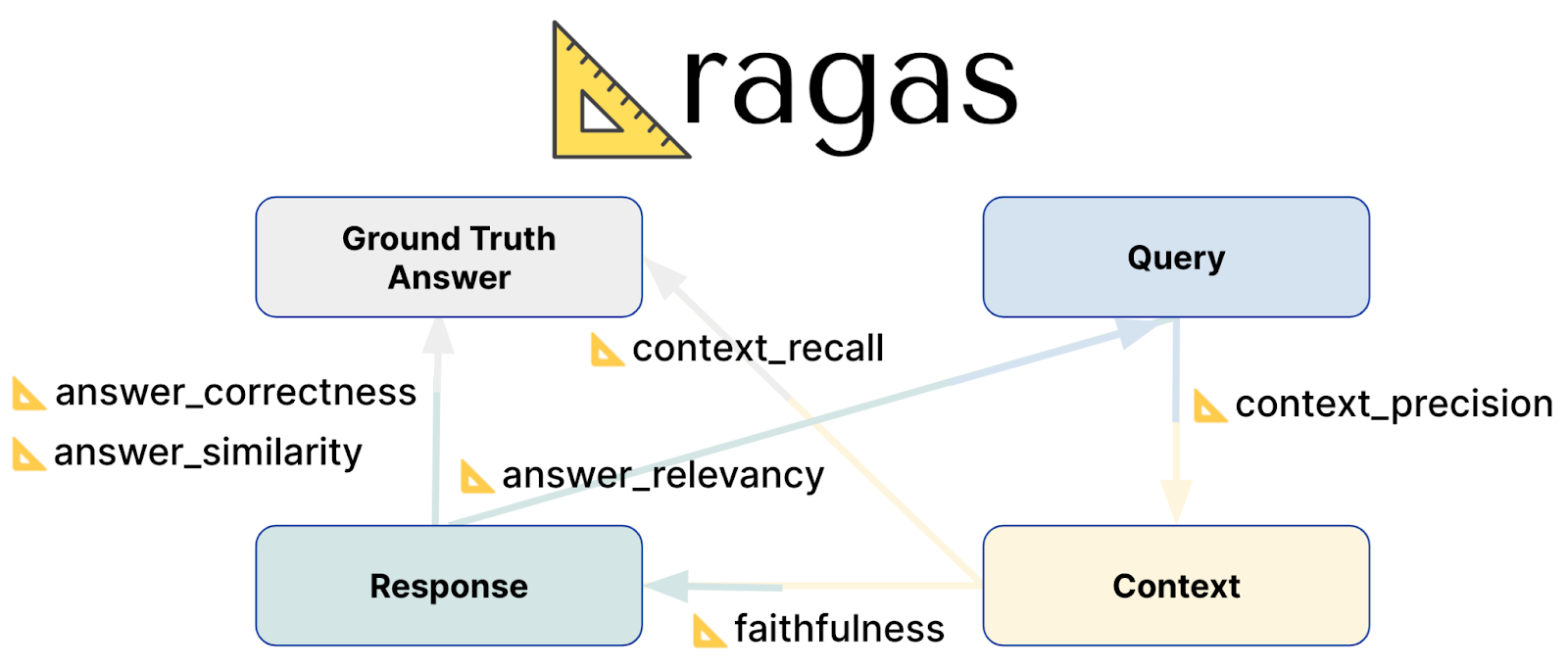 Métrica de avaliação das Ragas
Métrica de avaliação das Ragas
Principais métricas de avaliação
Pode encontrar explicações para cada métrica de avaliação, incluindo as suas fórmulas subjacentes, na documentação. Por exemplo, fidelidade. O Ragas fornece uma gama de pontuações de avaliação para medir a eficácia dos sistemas RAG:
Fidelidade: Esta pontuação avalia a precisão com que a resposta gerada reflecte a informação no contexto fornecido. Mede a exatidão factual da resposta, garantindo que está alinhada com o contexto do qual é derivada. As pontuações variam de 0 a 1, sendo que os valores mais elevados indicam maior exatidão e consistência.
Relevância da resposta**: Essa métrica de relevância da resposta avalia o quanto a resposta gerada responde ao prompt. Ela se concentra na integridade e na relevância da resposta, penalizando respostas incompletas ou redundantes. A pontuação de relevância é derivada da pergunta, do contexto e da resposta, com pontuações mais altas refletindo um melhor alinhamento com o prompt.
Recordação do contexto**: A Recuperação de contexto mede a eficácia com que o contexto recuperado corresponde à resposta verdadeira. Calcula a proporção de peças relevantes que foram recuperadas com sucesso em comparação com o que era esperado. As pontuações variam de 0 a 1, com valores mais altos a indicar que foi recuperada uma maior porção de contexto relevante.
Precisão do contexto**: Esta métrica avalia se os itens de contexto mais relevantes são classificados mais alto do que os menos relevantes. Verifica se todos os pedaços de contexto pertinentes aparecem no topo da lista. A precisão do contexto é determinada utilizando a pergunta, a verdade básica e os contextos, com pontuações mais elevadas a indicar uma melhor classificação das informações relevantes.
Relevância do contexto**: Esta pontuação de relevância do contexto avalia a relevância do contexto recuperado para a pergunta. Mede o grau em que o contexto corresponde à intenção da consulta. A métrica varia de 0 a 1, com valores mais altos mostrando que o contexto é mais pertinente para a pergunta.
Recuperação de entidade de contexto**: Esta métrica calcula a forma como o contexto recuperado capta as entidades mencionadas na verdade terrestre. Ele mede a proporção de entidades encontradas no contexto e na verdade básica em relação ao número total de entidades na verdade básica. Pontuações mais elevadas indicam uma melhor captura de entidades importantes no contexto.
Os pormenores sobre a forma como estas métricas são calculadas podem ser encontrados no seu [paper] (https://arxiv.org/abs/2309.15217).
Exemplo de código de avaliação RAG
Este código de avaliação assume que já tem uma demonstração do RAG. Para a minha demonstração, criei um chatbot RAG utilizando a Milvus Technical documentation e a base de dados de vectores Milvus para recuperação. O código completo da minha demonstração RAG notebook e Eval notebooks estão no GitHub.
Usando essa demonstração do RAG, fiz-lhe perguntas, obtive os contextos RAG do Milvus e gerei respostas de bot a partir de um LLM (ver as últimas 2 colunas abaixo). Além disso, forneço respostas "verdadeiras" para as mesmas perguntas (coluna "contextos" abaixo).
É necessário instalar o OpenAI, o conjunto de dados (HuggingFace), o ragas, o langchain e o pandas.
# ! pip install openai dataset ragas langchain pandas
importar pandas como pd
eval_df = pd.read_csv("data/milvus_ground_truth.csv")
display(eval_df.head())

Converta o dataframe do pandas para um conjunto de dados HuggingFace.
from datasets import Dataset
def assemble_ragas_dataset(input_df):
lista_de_perguntas, lista_de_verdades, lista_de_contextos = [], [], []
lista_de_perguntas = input_df.Question.to_list()
lista_verdade = eval_df.ground_truth_answer.to_list()
context_list = input_df.Custom_RAG_context.to_list()
lista_de_contextos = [[contexto] for context in lista_de_contextos]
rag_answer_list = input_df.Custom_RAG_answer.to_list()
# Criar um conjunto de dados HuggingFace a partir das listas de verdade terrestre.
ragas_ds = Dataset.from_dict({"question": lista_de_perguntas,
"contextos": lista_de_contextos,
"resposta": lista_de_respostas_de_ragas,
"verdade_fundamental": lista_verdade
})
return ragas_ds
# Crie um conjunto de dados Ragas HuggingFace a partir do pandas df.
ragas_input_ds = assemble_ragas_dataset(eval_df)
display(ragas_input_ds)

O modelo LLM padrão que o Ragas usa é o gpt-3.5-turbo-16k da OpenAI e o modelo de incorporação padrão é o text-embedding-ada-002. Pode alterar ambos os modelos para o que quiser.
Vou alterar o modelo LLM-as-judge para o modelo gpt-3.5-turbo, uma vez que o último blogue da OpenAI anunciou que este é o mais barato. Também alterei o modelo de incorporação para text-embedding-3-small, uma vez que o blogue referiu que estes novos embeddings suportam compression-mode.
No código abaixo, estou a utilizar apenas a métrica de avaliação RAG context para me concentrar na medição da qualidade da recuperação de documentos relevantes.
import os, openai, pprint
from openai import OpenAI
# Guardar a chave da api numa variável env.
openai_api_key=os.environ['OPENAI_API_KEY']
# Escolha as métricas que deseja ver.
from ragas.metrics import ( context_recall, context_precision, faithfulness, )
metrics = ['context_recall', 'context_precision', 'faithfulness']
# Altera o llm-as-critic.
from ragas.llms import llm_factory
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = llm_factory(model=LLM_NAME)
# Alterar também os embeddings.
from langchain_openai.embeddings import OpenAIEmbeddings
from ragas.embeddings import LangchainEmbeddingsWrapper
lc_embeddings = OpenAIEmbeddings( model="text-embedding-3-small", dimensions=512 )
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# Alterar os modelos predefinidos utilizados para cada métrica.
for metric in metrics:
globals()[métrica].llm = ragas_llm
globals()[métrica].embeddings = ragas_emb
# Avaliar o conjunto de dados.
from ragas import evaluate
ragas_result = evaluate( ragas_input_ds,
metrics=[ precisão_do_contexto, recuperação_do_contexto, fidelidade, ],
llm=ragas_llm,
)
# Ver as avaliações.
ragas_output_df = ragas_result.to_pandas()
ragas_output_df.head()

Pode ver o código completo da minha demonstração RAG notebook e Eval notebooks no GitHub.
Conclusão
Este blogue explorou os desafios actuais da recuperação em IA generativa, com particular ênfase nas técnicas de Retrieval Augmented Generation (RAG) para o avanço dos sistemas de IA de linguagem natural. A experimentação eficaz é essencial para otimizar os parâmetros RAG de modo a adaptarem-se a dados e casos de utilização específicos, garantindo o melhor desempenho. A avaliação dos sistemas RAG pode agora ser muito melhorada através da automatização, utilizando os LLM como avaliadores. Abordámos as principais métricas de avaliação de RAG e os seus métodos de cálculo, oferecendo uma perspetiva das suas aplicações práticas. Além disso, foi destacado um exemplo de implementação utilizando a base de dados de vectores Milvus juntamente com o pacote Ragas, demonstrando como estas ferramentas podem ser efetivamente utilizadas para melhorar e escalar as suas estruturas de avaliação RAG. Esta abordagem não só simplifica o processo de avaliação, como também aumenta a eficácia global da recuperação de contexto em soluções orientadas para a IA. Para uma exploração mais aprofundada, considere investigar aplicações do mundo real, abordar desafios, explorar direcções futuras, aderir às melhores práticas e aceder a recursos adicionais para aprofundar a sua compreensão da avaliação de sistemas RAG e aperfeiçoar o seu pipeline RAG.

Continue lendo

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.