




RAG local agêntico com LangGraph e Llama 3.2
*Atualizado a 25 de setembro de 2024 com Llama 3.2
Neste post, vamos demonstrar como construir agentes que podem chamar ferramentas de forma inteligente para executar tarefas específicas usando LangGraph e Llama 3, enquanto também aproveitam Milvus Lite para armazenamento eficiente de dados. Estes agentes reúnem várias capacidades importantes, incluindo o planeamento, a memória e a chamada de ferramentas para melhorar o desempenho dos sistemas de geração aumentada por recuperação (RAG).
Introdução ao LangGraph e ao Llama 3
O LangGraph é uma extensão do LangChain, concebido para construir aplicações multi-ator robustas e com estado com modelos de linguagem grandes (LLMs). Enquanto o LangChain oferece uma estrutura para integrar LLMs em vários fluxos de trabalho, o LangGraph avança ao modelar tarefas como nós e arestas numa estrutura gráfica. Isto permite fluxos de controlo mais complexos, permitindo que as LLMs planeiem, aprendam e se adaptem à tarefa em questão. O LangGraph oferece a flexibilidade necessária para implementar sistemas em que os agentes usam raciocínio em várias etapas, selecionando dinamicamente as ferramentas certas para cada etapa. Além disso, o LangGraph pode ser utilizado para construir agentes RAG fiáveis que seguem um fluxo de controlo definido pelo utilizador sempre que são executados, garantindo consistência e previsibilidade nas suas respostas.
O LangGraph também permite comportamentos mais complexos, semelhantes aos dos agentes, permitindo a incorporação de ciclos nos fluxos de trabalho. Estes ciclos permitem que os agentes regressem a passos anteriores, se necessário, permitindo ajustes dinâmicos às acções que tomam com base em novas informações ou reflexões. Isto resulta em agentes mais inteligentes, capazes de aperfeiçoar o seu raciocínio ao longo do tempo, criando sistemas RAG mais robustos e adaptáveis.
O Llama 3, um modelo de linguagem de grande dimensão de código aberto, funciona como o motor de raciocínio central da memória do agente. Quando combinado com o LangGraph, o Llama 3 pode analisar a entrada, decidir quais as acções a tomar e invocar as ferramentas necessárias. Em vez de apenas gerar texto, o Llama 3 - alimentado pelo LangGraph - permite que os agentes planeiem, executem e reflictam sobre as suas acções, tornando-os mais inteligentes e capazes.
Neste post, mostraremos como criar um sistema langgraph agentic rag usando LangGraph com Llama 3 e Milvus Lite. Esta configuração permite-lhe executar tudo localmente sem necessitar de servidores externos, tornando-o ideal para utilizadores preocupados com a privacidade e ambientes offline.
Construindo um agente de chamadas de ferramentas com LangGraph
O fluxo de trabalho do LangGraph é construído em torno do conceito de nós, onde cada nó representa uma tarefa ou ferramenta específica. Estas tarefas podem incluir a chamada de LLMs, a [recuperação de informação] (https://zilliz.com/learn/what-is-information-retrieval), ou a invocação de ferramentas personalizadas. Num agente de chamada de ferramentas, estão em jogo dois componentes-chave:
Nó LLM: Este nó decide qual a ferramenta a utilizar com base na entrada do utilizador. Analisa a consulta e apresenta o nome da ferramenta e os argumentos relevantes.
Nó Ferramenta: Este nó recebe o nome da ferramenta e os argumentos do nó LLM, invoca a ferramenta apropriada e devolve o resultado ao LLM.
Ao estruturar as tarefas (como a pesquisa na Web) como nós e arestas, o LangGraph permite a criação de fluxos de trabalho inteligentes e de várias etapas, em que os LLMs podem raciocinar sobre as perguntas dos utilizadores sobre as acções a tomar, as ferramentas a utilizar, as respostas às perguntas e a forma de refinar as suas respostas. O Milvus Lite desempenha um papel fundamental aqui, fornecendo armazenamento e recuperação eficientes de [dados vectorizados] (https://zilliz.com/learn/an-ultimate-guide-to-vectorizing-structured-data) localmente.
Como o Milvus Lite melhora os agentes locais de chamadas de ferramentas
Milvus Lite é uma versão local e leve do Milvus que não requer Docker ou Kubernetes para operar. Isso facilita a execução do Milvus no seu laptop, notebook Jupyter ou até mesmo no Google Colab. A implementação local do Milvus Lite permite-lhe armazenar vectores gerados a partir de diferentes fontes web ou documentos sem ter de recorrer a [bases de dados] externas (https://zilliz.com/glossary/ai-database). Integra-se perfeitamente com o LangGraph para lidar com pesquisas vectoriais, tornando-o uma solução ideal para sistemas RAG locais.
Por exemplo, o Milvus Lite pode ser utilizado para armazenar documentos indexados que são recuperados pelo agente durante uma pesquisa na Web. Quando o agente procura informação, a base de dados vetorial permite a recuperação rápida e precisa de documentos relevantes.
Criação de um sistema RAG local com LangGraph e Llama 3
Usamos o LangGraph para criar um agente RAG local personalizado com Llama 3.2 que usa diferentes abordagens:
Implementamos cada abordagem como um fluxo de controlo em LangGraph:
Roteamento (RAG adaptativo) - Permite ao agente encaminhar de forma inteligente as consultas dos utilizadores para o método de recuperação mais adequado, com base na própria pergunta. O nó LLM analisa a consulta e, com base nas palavras-chave ou na estrutura da pergunta, pode encaminhá-la para nós de recuperação específicos.
Exemplo 1: As perguntas que requerem respostas factuais podem ser encaminhadas para um nó de recuperação de documentos que pesquisa uma base de conhecimentos pré-indexada (alimentada por Milvus).
Exemplo 2: As perguntas abertas e criativas podem ser direcionadas para o LLM para tarefas de geração.
Retorno (RAG Corretivo)** - Garante que o agente tem um plano de reserva se os seus métodos de recuperação iniciais não fornecerem resultados relevantes. Suponhamos que os nós de recuperação iniciais (por exemplo, recuperação de documentos da base de conhecimentos) não fornecem respostas satisfatórias (com base na pontuação de relevância ou nos limiares de confiança). Nesse caso, o agente recorre a um nó de pesquisa na Web.
- O nó de pesquisa na Web pode utilizar APIs de pesquisa externas.
Auto-correção (Self-RAG)** - Permite ao agente identificar e corrigir os seus próprios erros ou resultados enganadores. O nó LLM gera uma resposta, que é depois encaminhada para outro nó para avaliação. Este nó de avaliação pode utilizar várias técnicas:
Reflexão: O agente pode verificar a sua resposta em relação à consulta original para ver se aborda todos os aspectos.
Análise da pontuação de confiança: O LLM pode atribuir uma pontuação de confiança à sua resposta. Se a pontuação for inferior a um determinado limiar, a resposta é reencaminhada para o LLM para revisão.
Ideias gerais para Agentes
Reflexão-** O mecanismo de auto-correção é uma forma de reflexão em que o agente LangGraph reflecte sobre a sua recuperação e gerações. Ele retorna as informações para avaliação e permite que o agente exiba uma forma de reflexão rudimentar, melhorando sua qualidade de saída ao longo do tempo.
O fluxo de controlo apresentado no gráfico é uma forma de planeamento: o agente não reage apenas à consulta; estabelece um processo passo a passo para obter ou gerar a melhor resposta.
Utilização de ferramentas-** O fluxo de controlo do agente LangGraph incorpora nós específicos para várias ferramentas. Estes podem incluir nós de recuperação para a base de conhecimentos (por exemplo, Milvus), demonstrando a sua capacidade de aceder a um vasto conjunto de informações, e nós de pesquisa na Web para informações externas.
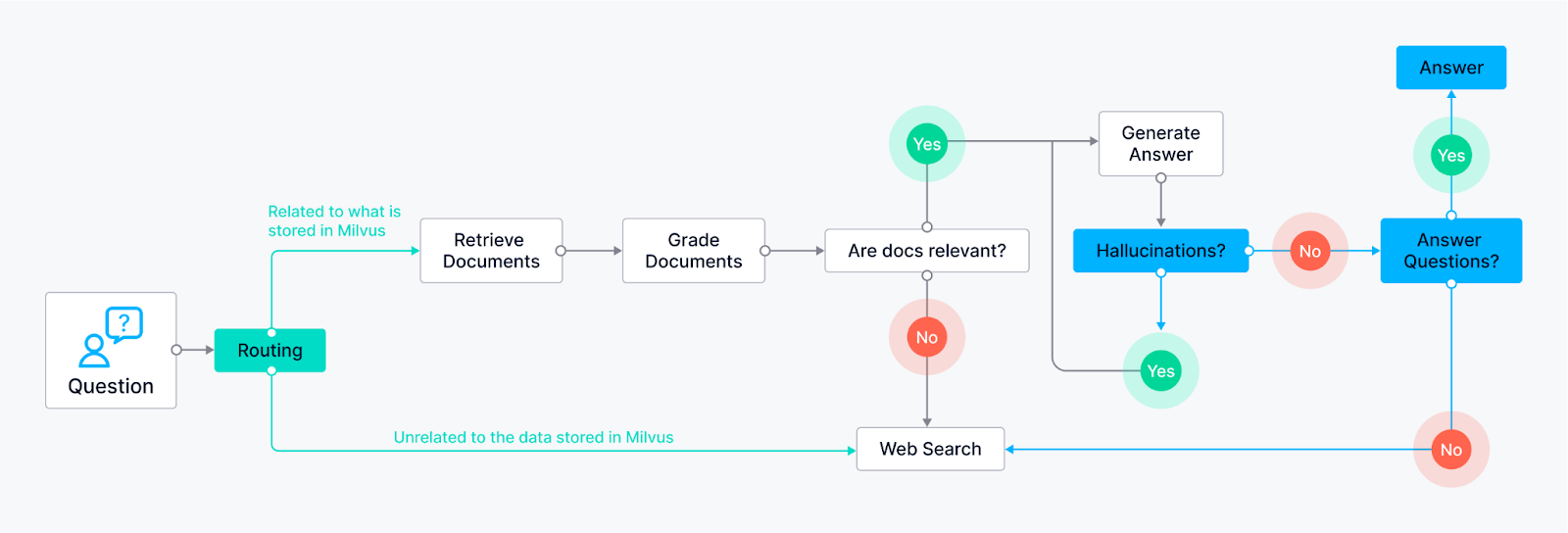
Exemplos de agentes
Para mostrar as capacidades dos nossos agentes LLM, vamos analisar dois componentes chave: o Classificador de Alucinações e o Classificador de Respostas. Embora o código completo esteja disponível no final deste post, esses trechos fornecerão uma melhor compreensão de como esses agentes funcionam dentro da estrutura LangChain.
Avaliador de Alucinação
O classificador de alucinações tenta resolver um desafio comum dos LLMs: alucinações, em que o modelo gera respostas que parecem plausíveis mas não têm fundamento factual. Este agente actua como um verificador de factos, avaliando se a resposta do LLM está de acordo com um conjunto de documentos obtidos a partir do Milvus.
### Classificador de alucinações
## LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template="""Você é um avaliador que avalia se
uma resposta é fundamentada/apoiada por um conjunto de factos. Atribui uma pontuação binária "sim" ou "não" para indicar
se a resposta é fundamentada/apoiada por um conjunto de factos. Forneça a pontuação binária como um JSON com uma
única chave "pontuação" e sem preâmbulo ou explicação.
Aqui estão os factos:
{documentos}
Aqui está a resposta:
{geração}
""",
input_variables=["generation", "documents"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents": docs, "generation": generation})
Avaliador de respostas
Após o Classificador de Alucinações, outro agente entra em cena. Este agente verifica outro aspeto crucial: garantir que a resposta do LLM aborda diretamente a pergunta original do utilizador. Utiliza o mesmo LLM, mas com uma pergunta diferente, especificamente concebida para avaliar a relevância da resposta para a pergunta.
def grau_geracao_v_documentos_e_pergunta(estado):
"""
Determina se a geração é fundamentada no documento e responde a perguntas.
Args:
state (dict): O estado atual do gráfico
Retorna:
str: Decisão para o próximo nó a ser chamado
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documentos = estado["documentos"]
generation = state["generation"]
pontuação = hallucination_grader.invoke({"documents": documents, "generation": generation})
nota = pontuação['pontuação']
# Verificar a alucinação
se a classificação == "sim":
print("---DECISÃO: GERAÇÃO ESTÁ FUNDAMENTADA EM DOCUMENTOS---")
# Verificar a resposta a perguntas
print("---GERAÇÃO DE GRAU vs PERGUNTA---")
pontuação = answer_grader.invoke({"pergunta": pergunta, "geração": geração})
nota = nota['nota']
se nota == "sim":
print("---DECISÃO: GERAÇÃO ABORDA A PERGUNTA---")
devolver "útil"
else:
print("---DECISÃO: A GERAÇÃO NÃO RESPONDE À PERGUNTA---")
devolver "não útil"
senão:
pprint("---DECISÃO: A GERAÇÃO NÃO ESTÁ BASEADA EM DOCUMENTOS, TENTAR DE NOVO---")
devolver "não suportado"
Pode ver no código acima que estamos a verificar as previsões do LLM que utilizamos como classificador.
Compilando o gráfico LangGraph
Isto irá compilar todos os agentes que definimos e possibilitará a utilização de diferentes ferramentas para o seu sistema RAG.
# Compilar
app = workflow.compile()
# Teste
from pprint import pprint
inputs = {"question": "O que é engenharia de prontidão?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f "Terminou a execução: {chave}:")
pprint(valor["geração"])
'Terminou a execução: gerar:'
('A engenharia de prompts é o processo de comunicação com os Modelos de Linguagem Grande '
'Modelos (LLMs) para direcionar o seu comportamento para os resultados desejados sem '
'sem atualizar os pesos do modelo. Centra-se no alinhamento e na capacidade de direção do modelo, '
' 'exigindo experimentação e heurística devido a efeitos variáveis entre '
'modelos. O objetivo é melhorar a geração de texto controlável, optimizando '
' 'optimizando os avisos para aplicações específicas.')
Conclusão
Nesta publicação do blogue, mostrámos como construir um sistema RAG usando agentes com LangChain/LangGraph, Llama 3.2 e Milvus. Estes agentes permitem que os LLMs tenham capacidades de planeamento, memória e utilização de diferentes ferramentas, o que pode levar a respostas mais robustas e informativas.
Próximos passos para a melhoria
Embora a implementação atual do sistema agentic RAG seja eficaz para fluxos de trabalho locais de um único agente, existem várias direcções interessantes para a melhoria e inovação.
Coordenação multi-agente: Atualmente, o LangGraph é utilizado para conceber sistemas de agente único que operam dentro de um fluxo de controlo predefinido, como uma pesquisa na Web. No entanto, uma progressão natural seria alargar este sistema para suportar múltiplos agentes a trabalhar em paralelo ou em coordenação. Em cenários em que uma tarefa requer conhecimentos especializados ou múltiplas fontes de recuperação, os agentes podem processar, de forma colaborativa, diferentes partes da tarefa. Por exemplo, um agente pode concentrar-se na recuperação de informações factuais, enquanto outro se ocupa de tarefas criativas ou da interação com o utilizador e um terceiro avalia a qualidade global do resultado. Estes sistemas multiagentes permitiriam operações mais complexas, conduzindo a uma maior eficiência e precisão no tratamento de diversas consultas.
Dados em tempo real** Actualizações:** Outra melhoria potencial poderia ser permitir que os agentes actualizassem as suas fontes de dados em tempo real. Atualmente, o Milvus Lite serve como uma base de conhecimentos estática; no entanto, em domínios dinâmicos, a informação pode ficar rapidamente desactualizada. Os agentes poderiam ser concebidos para monitorizar e atualizar continuamente o seu armazenamento vetorial local com dados frescos da Web ou de outras APIs, assegurando que os resultados do sistema permanecem relevantes e actualizados. Por exemplo, se um agente for questionado sobre os últimos preços das acções ou notícias de última hora, pode ir buscar automaticamente os dados mais recentes, tornando o sistema muito mais adaptável e útil em ambientes de ritmo acelerado.
Reflexão e auto-aperfeiçoamento melhorados: Embora o atual mecanismo de reflexão seja útil, há espaço para melhorias em termos de auto-correção. As futuras versões do agente poderiam incorporar técnicas mais avançadas, como a aprendizagem por reforço ou mecanismos de aprendizagem contínua, permitindo que o agente aprenda com as suas experiências e erros passados ao longo do tempo. Ao permitir que o trabalho de memória do agente melhore a sua qualidade de resposta de forma iterativa, poderíamos conseguir um sistema que não só recuperasse e gerasse respostas de alta qualidade, mas também aperfeiçoasse os seus processos com base no feedback.
Ao incorporar estes próximos passos, podemos melhorar significativamente as capacidades dos sistemas RAG agênticos, tornando-os mais flexíveis, adaptáveis e eficazes na resolução de tarefas complexas numa variedade de indústrias.
Não hesite em consultar o código disponível no [repositório Milvus Bootcamp] (https://github.com/milvus-io/bootcamp/tree/master/bootcamp/RAG/advanced_rag).
Se gostou desta publicação do blogue que mostra como construir um RAG agêntico langgraph, considere dar-nos uma estrela no , e partilhe as suas experiências com a comunidade juntando-se ao nosso
Inspirado no Repositório Github da Meta com receitas para usar o Llama 3

Continue lendo

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.