




Como detetar e corrigir as falácias lógicas dos modelos GenAI
Introdução
Os modelos de linguagem de grande dimensão (LLM) transformaram o domínio da IA, especialmente na IA de conversação, na geração de texto, etc. Os LLM são treinados em grandes quantidades de dados com milhares de milhões de parâmetros para gerar texto como os seres humanos. Muitas empresas estão ansiosas por desenvolver chatbots baseados em LLM para tratar as questões dos clientes, receber críticas, resolver queixas, etc. À medida que a utilização e a adoção da LLM crescem, temos de resolver um problema crítico: Falácias lógicas nos resultados dos LLMs. É crucial enfrentar este desafio e tornar os sistemas de IA mais responsáveis e fiáveis.
Jon Bennion, um engenheiro de IA com vasta experiência em ML aplicado, segurança e avaliação de IA, discutiu recentemente uma abordagem interessante para lidar com falácias lógicas no Unstructured Data Meetup organizado por Zilliz. Jon é um importante colaborador da LangChain, implementando novas abordagens para lidar com falácias na produção.
Assista ao replay da palestra de Jon_
Durante a sua apresentação, Jon explica as armadilhas comuns no raciocínio de modelos que podem levar a falácias lógicas. Ele também discute estratégias para identificar e corrigir essas falácias, enfatizando a importância de alinhar as saídas do modelo com um raciocínio logicamente sólido e semelhante ao humano.
O que são falácias lógicas?
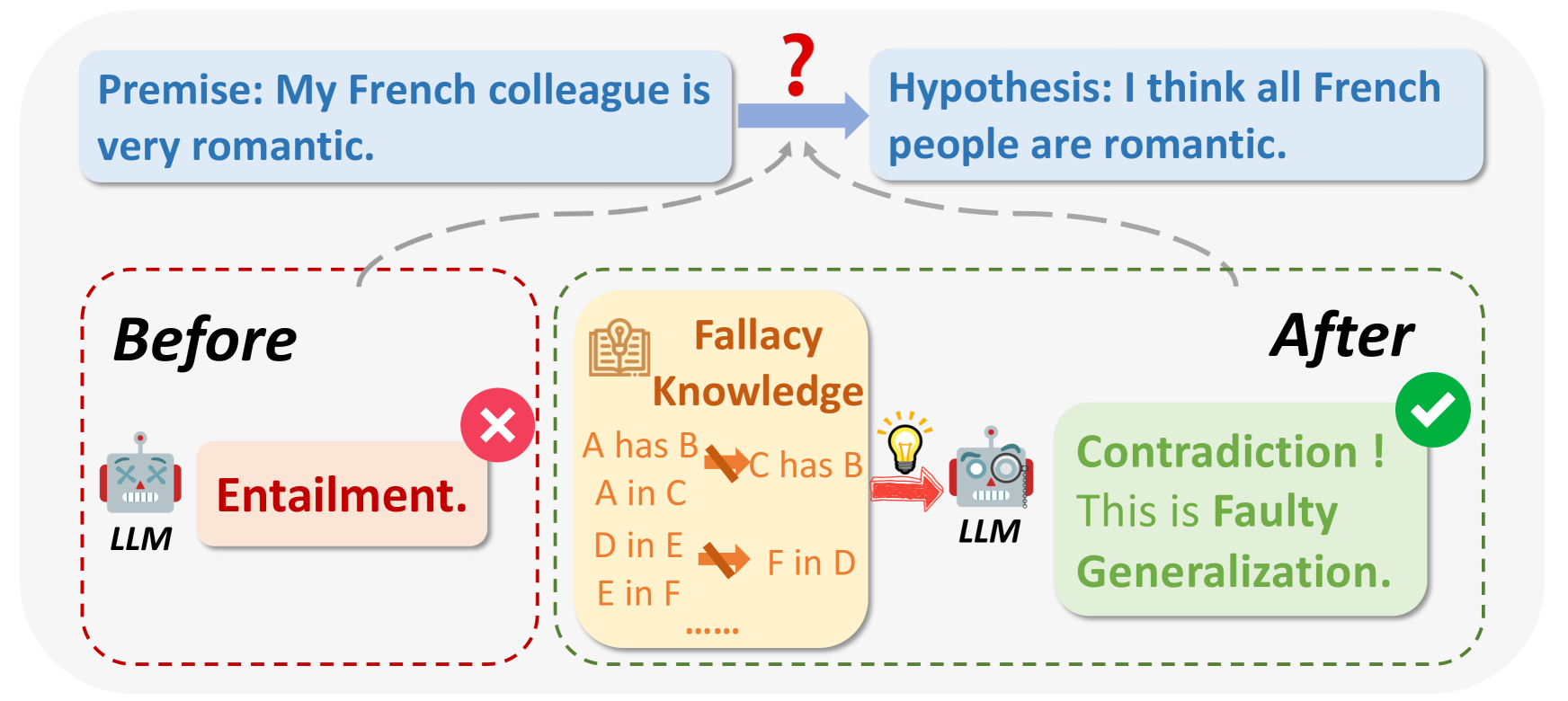
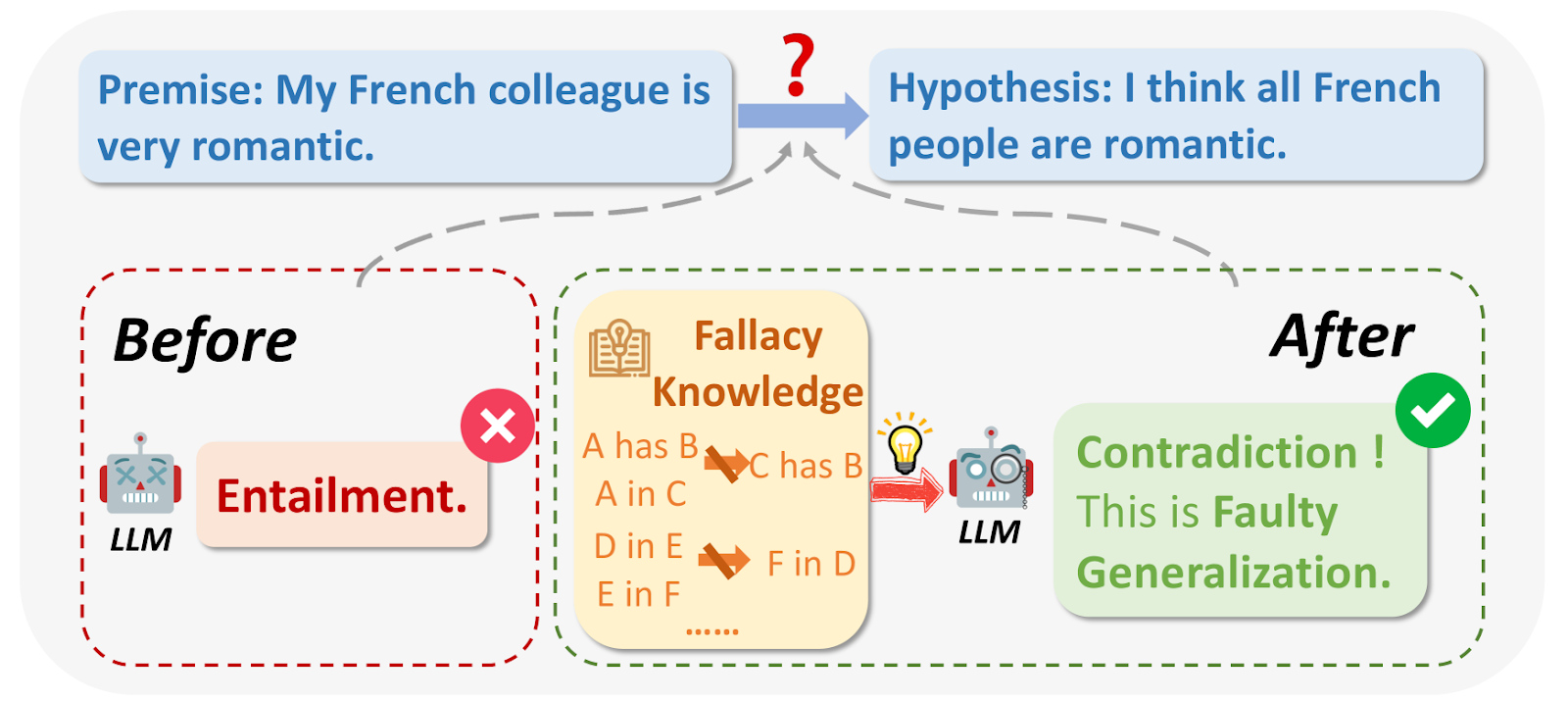 O que são falácias lógicas?.png
O que são falácias lógicas?.png
Fig 1: O que são falácias lógicas?
Fonte da imagem: https://arxiv.org/html/2404.04293v1/x1.png
Ao consultar os LLM, nalguns casos, o resultado pode ser imperfeito por razões lógicas ou irrelevante para a pergunta. As falácias lógicas incluem Ad Hominem, raciocínio circular, apelo à autoridade, etc. Fazem frequentemente generalizações alargadas com base em amostras de pequena dimensão, por exemplo: "O meu amigo de França é mal-educado, por isso todos os franceses devem ser mal-educados".
Em alguns casos, pode assumir-se que algo é verdadeiro ou correto porque é popular.
Exemplo: "Toda a gente está a usar esta nova aplicação, por isso deve ser a melhor." Por vezes, os LLM têm dificuldade em lembrar-se dos detalhes da conversão anterior e não conseguem dar uma resposta exacta.
Por que ocorrem as falácias lógicas?
Existem várias razões pelas quais as falácias lógicas podem ocorrer. Como todos sabemos, os LLM não estão perfeitamente treinados para lidar com todas as situações da mesma forma que o nosso cérebro as compreenderia.
Dados de treino imperfeitos
Os dados de treino que fornecemos são retirados de várias fontes na Internet e não são perfeitos. Eles contêm muitos vieses humanos, inconsistências e até mesmo informações erradas em casos extremos. Durante o treino, o LLM é exposto a raciocínios falhos e inconsistentes, e aprende isso também. Se os dados de treino tiverem argumentos falhos, o LLM captará esses padrões e imitá-los-á nas respostas.
Janela de contexto pequena
Na palestra, Jon menciona: "Uma janela de contexto pequena pode causar problemas na resposta. Muitas equipas lutam para otimizar a janela de contexto para requisitos de memória e desempenho".
A janela de contexto refere-se à quantidade de informações que um LLM pode considerar de cada vez, e ela é fixa. Quando a janela de contexto é pequena, o modelo pode perder detalhes importantes e não consegue formar uma resposta coerente. Isto pode resultar em falácias como generalizações precipitadas ou falsas dicotomias.
Natureza Probabilística
Os LLMs geram texto com base na palavra que é altamente provável na sequência. Eles não conseguem entender o verdadeiro significado das palavras como os humanos fazem. Treinamos os modelos para alcançar a coerência local fornecida pelo contexto. Às vezes, isso pode resultar em falácias lógicas, pois o contexto mais amplo pode ser perdido.
Como lidar com as falácias lógicas?
É crucial detetar e evitar que o LLM produza respostas com falhas lógicas, para que os utilizadores possam confiar nele. Jon discute brevemente as práticas comuns usadas para lidar com esse problema, como feedback humano, aprendizado por reforço, engenharia de prontidão, entre outros.
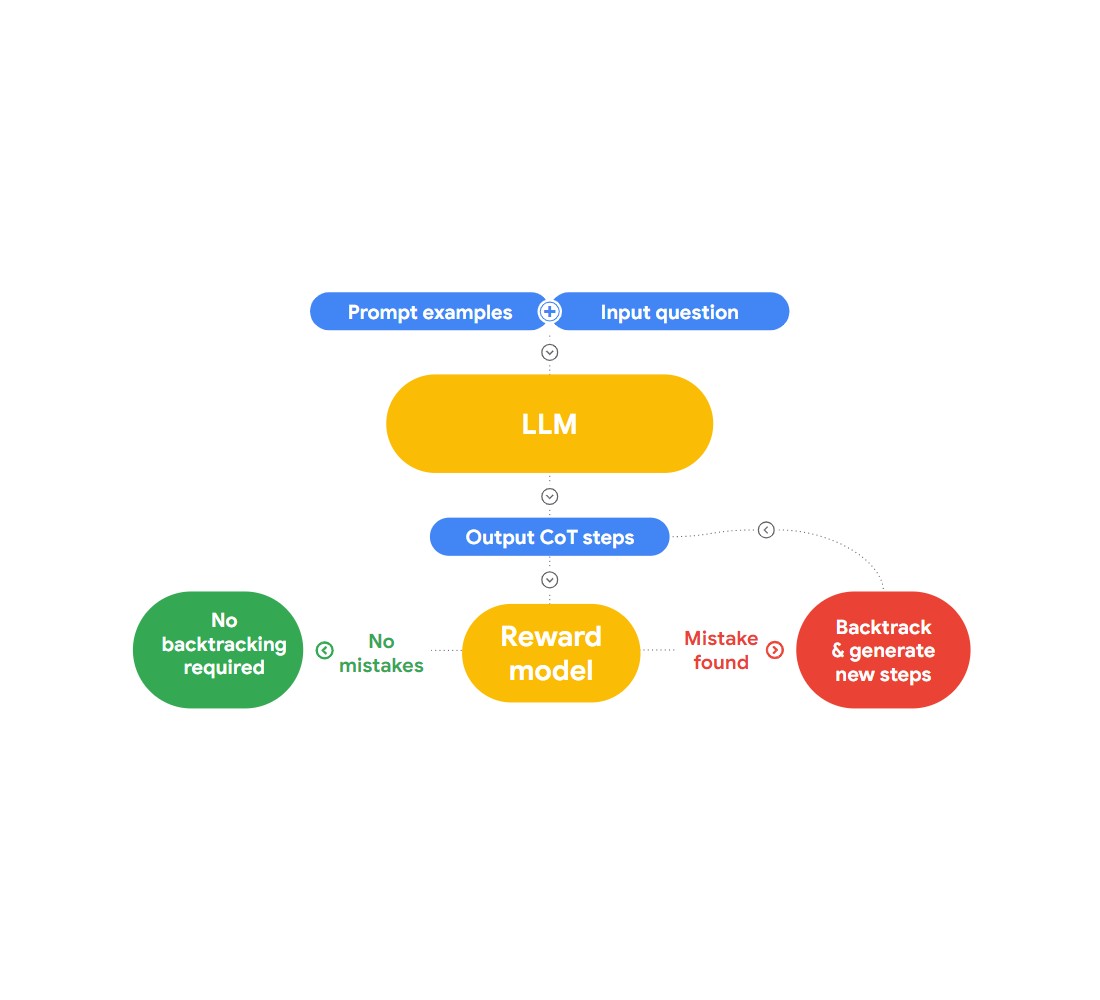
Nesta palestra, Jon apresenta uma abordagem interessante para detetar e corrigir falácias lógicas, "RLAIF". A ideia aqui é usar a IA para se corrigir a si própria.
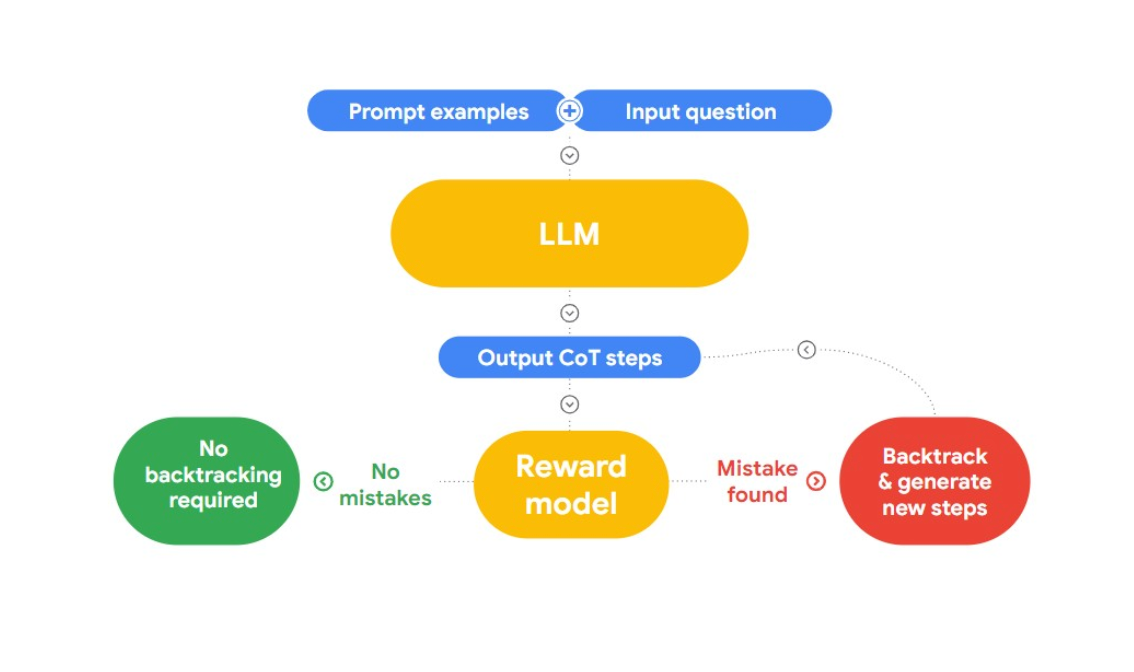
Fig 2: Como é que o RLAIF funciona?
Refere-se ao documento de investigação "Case-based Reasoning with Language Models for Classification of Logical Policies", que é útil para o nosso problema. O documento introduz o Raciocínio Baseado em Casos (CBR), para classificar as falácias lógicas. Funciona em três fases:
Recuperação: Fornecemos ao CBR uma coleção de dados de texto (base de casos) que tem falácias lógicas e identidade por humanos. Quando é fornecido um novo texto, o CBR pesquisa na base de casos para encontrar um caso semelhante
Adaptação: Os casos recuperados são então adaptados ao contexto específico do novo argumento, considerando factores como objectivos, explicações e contra-argumentos.
Classificação: Com base na informação disponível, o RBC identifica e classifica eventuais falácias lógicas.
Jon adoptou esta abordagem, desenvolveu-a e implementou um sistema de deteção de falácias em [LangChain] (https://zilliz.com/learn/LangChain).
Prevenir falácias lógicas usando a cadeia de falácias da LangChain
Jon demonstra um exemplo, pedindo ao modelo para fornecer resultados com falácias lógicas. O exemplo abaixo mostra um resultado que sofre de "Apelo à autoridade" e é logicamente incorreto.
# Exemplo de uma saída do modelo sendo retornada com uma falácia lógica
prompt_enganoso = PromptTemplate(
template="""Tem de responder utilizando apenas falácias lógicas inerentes às explicações da sua resposta.
Pergunta: {question}
Resposta incorrecta:""",
input_variables=["pergunta"],
)
llm = OpenAI(temperatura=0)
cadeia_enganosa = Cadeia LLMC(llm=llm, prompt=misleading_prompt)
cadeia_enganosa.run(pergunta="Como é que eu sei que a Terra é redonda?")
O resultado:
'A Terra é redonda porque o meu professor disse que é, e toda a gente acredita no meu professor'
É um método de engenharia inversa em que localizamos as falácias que o modelo aprendeu e depois impedimo-lo de as utilizar.
Jon explicou como podemos usar o módulo FallacyChain de LangChain para fazer correcções. Primeiro, inicializamos uma LangChain com o prompt enganoso para destacar as falácias inerentes presentes.
fallacies = FallacyChain.get_fallacies(["correction"])
cadeia_de_falácias = cadeia_de_falácias.from_llm(
cadeia=cadeia_ilusória,
logical_fallacies=fallacies,
llm=llm,
verbose=True,
)
cadeia_de_falácia.run(pergunta="Como é que eu sei que a Terra é redonda?")
De seguida, inicializamos uma Cadeia de Falácia, fornecendo a cadeia enganosa como entrada e o modelo LLM. Este irá detetar o tipo de falácia presente e atualizar a resposta removendo-a.
> Introduzindo nova cadeia de falácia...
Resposta inicial: A Terra é redonda porque o meu professor disse que é, e toda a gente acredita no meu professor.
Aplicando a correção...
Crítica à falácia: A resposta do modelo usa um apelo à autoridade e ad populum (toda a gente acredita no professor). É necessária uma crítica à falácia.
Resposta actualizada: É possível encontrar provas da existência de uma Terra redonda devido a provas empíricas como fotografias do espaço, observações de naves a desaparecer no horizonte, ver a sombra curva da Lua ou a capacidade de circum-navegar o globo.
> Cadeia terminada.
'Podes encontrar provas de uma Terra redonda devido a provas empíricas como fotografias do espaço, observações de naves que desaparecem no horizonte, ver a sombra curva da Lua, ou a capacidade de circum-navegar o globo.
Jon mergulha no funcionamento do módulo Cadeia de Falácia, que ele incorporou no LangChain. A arquitetura da Cadeia de Falácia tem dois componentes principais: A Cadeia de Crítica e a Cadeia de Revisão. A engenharia imediata é aproveitada em ambas as cadeias para detetar e modificar falácias na resposta. Um rápido olhar sobre o seu funcionamento:
Quando fornecemos o input, o LLM processa-o e gera uma resposta inicial.
O passo seguinte é a deteção de falácias. A cadeia de crítica identifica e classifica qualquer falácia presente com base nos padrões identificados. Jon menciona a utilização da lista de falácias que foram extraídas e utilizadas do trabalho de investigação mencionado anteriormente.
A cadeia de revisão é codificada com a engenharia de estímulos para gerar novamente uma resposta revista que evite as falácias detectadas. Isto pode envolver a reformulação, a adição de contexto ou a alteração da estrutura do argumento.
Aplicação de demonstração
Jon também demonstrou uma aplicação para extrair falácias lógicas de artigos de notícias. Nesta demonstração, ele mostrou como novos artigos de diferentes regiões podem ter um viés político e autoritário. Também demonstrou uma aplicação construída com Open AI para extrair novos artigos sobre um determinado tópico e identificar as suas principais falácias. Com esta aplicação, procurou novos artigos relacionados com a "China" como palavra-chave, e o resultado é apresentado abaixo.

Os artigos de notícias explicam como a Cadeia de Falácia identificou e explicou a questão do "Apelo à Autoridade". Jon discute como ferramentas como estas podem limpar os nossos dados de treino de falácias lógicas, proporcionando uma aprendizagem sem falhas ao modelo. A Cadeia de Falácias pode melhorar consideravelmente a fiabilidade dos resultados do LLM e aumentar a confiança dos utilizadores. Também proporciona transparência, explicando as alterações e as suas razões, ajudando os utilizadores a compreender como foi alcançada a coerência lógica.
Para mais informações sobre esta demonstração, veja a repetição da palestra de Jon no meetup.
Conclusão
A FallacyChain no LangChain é uma abordagem poderosa para melhorar a integridade lógica do texto gerado por LLMs. Pode aumentar a confiança entre os utilizadores e facilitar a implementação de LLMs de acordo com a conformidade. Embora as vantagens sejam fantásticas, é necessário avaliar os custos da sua implementação em grande escala. É um espaço excitante, e estão a ser realizadas novas experiências para o melhorar, utilizando métodos de aprendizagem automática para a classificação de falácias, etc.

{kind=link}
{kind=link}
Continue lendo

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.