




Computação sob demanda do Zilliz Cloud: pague apenas pelo que usar
No último trimestre, trabalhamos em um caso de cobrança com um cliente de direção autônoma. A equipe de analytics dele precisava de busca vetorial em uma coleção de 1B de linhas. Dimensionamos isso em um cluster Dedicated: $7.000/mês. Testamos o Serverless: $10.800. O trabalho real de analytics era de algumas horas por mês.
Ambas as faturas estavam corretas. Ambos os produtos estavam fazendo exatamente aquilo para que foram projetados. O problema era que a carga de trabalho desse cliente — analytics esparso compartilhando um dataset com duas outras cargas de trabalho de produção — não correspondia ao que qualquer um dos produtos foi projetado para atender.
Foi para esse caso que criamos o Zilliz Cloud On-Demand Search — um dos novos recursos que lançamos com o lançamento do Zilliz Vector Lakebase. Mesma carga de trabalho, por menos de $500/mês. Abaixo está o que não se encaixou, o que mudamos, onde o On-Demand é a ferramenta errada e como ele se encaixa novamente no Vector Lakebase no final.
O caso do cliente
A coleção — cerca de 1 bilhão de registros — já estava em uso por duas cargas de trabalho de produção:
- Um serviço de recuperação online atendendo tráfego em tempo real.
- Um pipeline de treinamento de modelo que busca dados de cenários para jobs de regressão (executado por uma equipe separada).
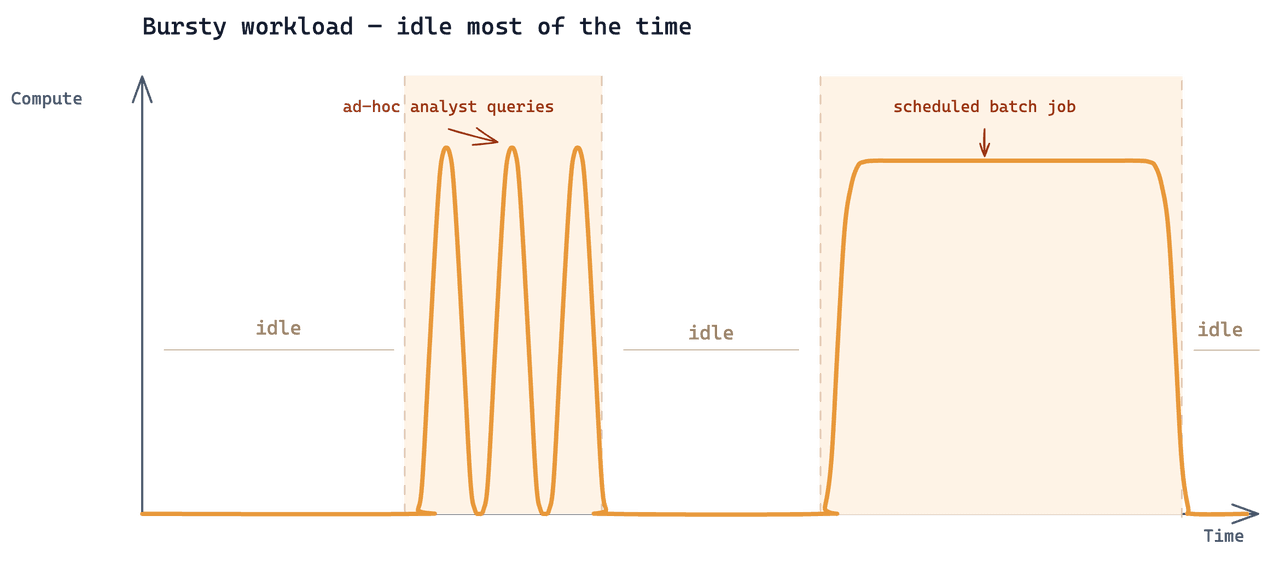
Analytics era uma terceira carga de trabalho sendo adicionada sobre os mesmos dados. O padrão de acesso: os analistas só executavam buscas quando tinham uma pergunta específica, em curtos ciclos iterativos guiados pela investigação atual. No restante do tempo, nenhuma consulta analítica atingia o cluster.
Este é um caso de uso bastante comum da Zilliz em uma escala de dados bastante comum. O que o tornava difícil era que todas as três cargas de trabalho precisavam ler da mesma coleção subjacente, e cada uma tinha uma cadência muito diferente.
Por que o cluster Dedicated não se encaixava
A configuração existente era um cluster Tiered do Zilliz Cloud com 24 CU. Adicionar a carga de trabalho de analytics a ele custava ~$7.000/mês. O cluster é cobrado por cada hora em que existe: 24 × 30 = 720 horas/mês. O trabalho real de analytics consumia 2–3 horas. As 717 horas restantes eram cobradas enquanto ficava ocioso — 99,6% do gasto total ia para capacidade que ninguém usava.
Você pode parar um cluster Dedicated entre sessões para evitar as horas ociosas. Consideramos isso. Não funciona, por dois motivos.
Primeiro, a inicialização a frio no Dedicated leva mais de 10 minutos para consultas analíticas frias em um dataset desse tamanho. O modelo mental do Dedicated é que todos os dados necessários precisam estar na memória local antes que as consultas sejam executadas, então ele pré-carrega todo o conjunto de trabalho — normalmente dezenas a centenas de vezes os dados que uma única consulta fria realmente acessa. O mesmo carregamento também precisa trazer o estado para trabalhos não relacionados a consultas que o cluster suporta, como DDL e exclusões. Essa sobrecarga existe quer a próxima consulta precise dela ou não.
Segundo, a cobrança arredonda para a hora. Então, mesmo que o analista estivesse disposto a esperar mais de 10 minutos para o cluster aquecer, a fatura por uma única consulta ainda é de uma hora mais o carregamento. Com analistas executando em curtos ciclos iterativos, o custo por consulta útil permanece alto, não importa quão diligente seja a disciplina de iniciar/parar.
Por que o cluster Serverless não se encaixava
Serverless foi a próxima opção que testamos. No papel, ele tem o formato certo para esse padrão de acesso: sem estado, pagamento por consulta, sem computação ociosa. Para a carga de trabalho de analytics por si só, poderia ter funcionado.
O problema é que o Serverless nesse dataset não precifica a carga de trabalho de analytics isoladamente. Ele precifica tudo o que toca a coleção. Depois que incluímos as cargas de trabalho existentes, três itens quebraram a conta:
- Consultas: ~$6.000/mês. A maior parte vinha dos jobs de regressão quinzenais da equipe de treinamento de modelos — 100 QPS por 3 horas, a cada duas semanas. Os preços unitários do Serverless incorporam um prêmio de consulta fria que é pago em cada consulta, mesmo quando a consulta está quente. Quando o volume de consultas deixa de ser trivialmente baixo, a conta deixa de fechar.
- Armazenamento: $1.700/mês. Medido separadamente porque o Serverless não tem taxa por hora de computação na qual incorporar o armazenamento.
- Gravações: $3.000/mês. Mesmo motivo — não há hora de computação na qual incorporar.
Total: $10.784/mês, mais alto do que o cluster Dedicated do qual estávamos tentando escapar.
Cada um desses prêmios tem uma razão estrutural por trás.
As consultas carregam um prêmio de consulta fria. Do lado do usuário, o Serverless é sem estado. Do lado da plataforma, os dados ainda precisam ser carregados em máquinas específicas para execução. As consultas se dividem em quentes (dados já na máquina) e frias (busca no armazenamento de objetos primeiro). Consultas quentes são baratas; consultas frias são caras. A plataforma não consegue prever quais consultas serão frias para qualquer usuário específico, então distribui o custo de consulta fria pelo preço unitário de cada consulta. Workloads com consultas majoritariamente quentes acabam pagando pelas consultas frias de todos.
O armazenamento é precificado acima do custo marginal. No Dedicated, os custos de armazenamento e gravação entram invisivelmente na taxa por hora de computação. O Serverless não tem taxa por hora de computação para esses custos se esconderem atrás, então o armazenamento é cobrado explicitamente. Esse preço explícito precisa cobrir dados que são armazenados, mas nunca consultados — a plataforma não pode movê-los para armazenamento profundamente frio porque os dados precisam permanecer prontos para consulta a qualquer momento. Manter essa prontidão exige estado adicional, e seu custo acaba amortizado no tamanho do armazenamento, que não corresponde de fato ao consumo real.
As gravações também são precificadas acima do custo marginal. As gravações são medidas separadamente para impedir que usuários emitam atualizações de alta frequência que gerem muito custo de gravação sem aumentar o dataset (o que, de outra forma, deixaria a plataforma absorvendo o custo). Mesma dinâmica do armazenamento: o custo do estado de prontidão entra no preço unitário por gravação.
O problema mais profundo é que o Serverless oculta a abstração de "recurso de computação" do usuário. O usuário vê uma interface sem estado; a plataforma ainda precisa pagar por padrões de acesso imprevisíveis por trás dela — dados quentes/frios, tráfego em rajadas, armazenamento ocioso que precisa permanecer pronto para consulta. Esses custos não podem ser atribuídos com precisão a usuários específicos, então são amortizados nos preços unitários de consultas, armazenamento e gravações. Toda ação faturável acaba ficando um pouco acima de seu custo marginal real.
Este é um modelo de "risco compartilhado": cada item de linha carrega uma sobretaxa para cobrir as consultas frias, rajadas ou armazenamento ocioso de outra pessoa. Os workloads menos responsáveis por essa variância — consultas quentes estáveis, de alta frequência e previsíveis — pagam a maior parcela do prêmio. Quanto mais estável for o seu workload, mais você acaba subsidiando.
O que o cliente realmente precisava
Dando um passo atrás, o pedido do cliente não era exótico. Um dataset, múltiplas cadências de acesso, com a conta seguindo apenas a computação que cada cadência realmente usava.
- Recuperação online: contínua, de baixa latência, previsível. Dedicated é certo para isso.
- Treinamento de modelos: em rajadas, mas previsível — 3 horas a cada duas semanas.
- Analytics: esparso e imprevisível — alguns minutos por vez, com longos intervalos.
O Dedicated não conseguia entregar isso. Ele cobra pela capacidade provisionada, não pelo consumo. O Serverless também não: seu preço unitário por consulta precisa subsidiar consultas frias, armazenamento ocioso e folga para rajadas em todos os usuários da plataforma, então workloads estáveis acabam pagando pela variância que não geram.
O que precisávamos era de um terceiro modelo de computação — um que pudesse se anexar aos mesmos dados que o Dedicated, subir rápido o suficiente para tornar realista a cobrança por consulta e cobrar apenas quando estivesse realmente em execução.
O que mudamos
On-Demand é um modelo de computação separado no Zilliz Cloud que existe ao lado de Dedicated e Serverless. Ele muda três coisas em comparação com qualquer um deles:
- Inicialização a frio. Carrega apenas os chunks que a consulta atual acessa, não todo o conjunto de trabalho. Cai de mais de 10 minutos para segundos.
- Cobrança. Por minuto de tempo real de computação em execução. Escritas também. Sem hora mínima, sem prêmio por consulta fria/quente.
- Isolamento. Cada workload se conecta a uma coleção por meio do seu próprio grupo de recursos de computação. Mesmos dados, sem contenção.
As próximas três seções percorrem cada uma delas.
Carregando menos dados, mais rápido
A inicialização a frio de 10 minutos no Dedicated existe porque o cluster precisa trazer todo o conjunto de trabalho para a memória local antes de servir consultas. Em uma coleção de 1B de linhas, isso é dezenas a centenas de vezes mais dados do que qualquer consulta individual realmente precisa. Comprimir a inicialização a frio para segundos significa abandonar essa suposição: carregar apenas o que a consulta atual acessa.
Isso parece uma frase; na prática, exigiu redesenhar três camadas — o que ler, onde colocar e como inicializar.
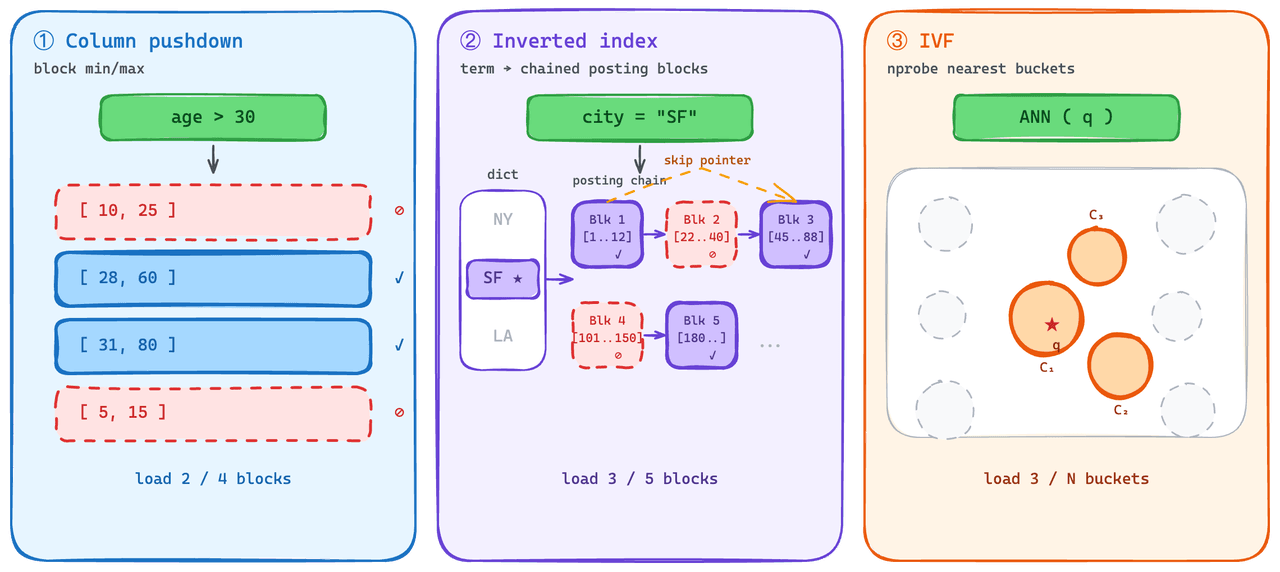
Índices que carregam parcialmente.
No lado escalar, predicate pushdown é prática padrão. O mecanismo elimina blocos que não podem corresponder ao predicado e evita buscá-los. Usamos isso em índices invertidos: cada posting list carrega como um bloco, e cada lista traz estatísticas de min/max que o mecanismo pode verificar antes de buscar.
A parte mais difícil foi dar ao lado vetorial uma capacidade comparável de "ler um subconjunto". Índices de grafos — a opção de maior desempenho para QPS em estado estável — não degradam suavemente sob carregamento parcial: a estrutura precisa ser carregada por completo para ser útil, então o custo de carregamento a frio é alto.
On-Demand usa a família IVF em vez disso. IVF agrupa vetores em buckets no momento da indexação e, no momento da consulta, apenas os buckets mais próximos da consulta são buscados. Isso dá ao lado vetorial algo próximo da semântica de predicate-pushdown: consultas frias puxam uma pequena fração do índice, não ele inteiro.
Esta é uma troca deliberada. Perdemos o desempenho em estado estável dos índices de grafos, que é o principal motivo pelo qual On-Demand não é adequado para servir em alto QPS (mais sobre isso abaixo). Para workloads esparsos e em rajadas, a troca vale a pena.
Um caminho de dados em três camadas.
Depois que sabemos o que ler, a próxima pergunta é onde mantê-lo. Chunks fluem livremente entre S3, disco local e memória, e o ciclo de vida do cache é gerenciado por chunk entre consultas: chunks de que a consulta atual precisa são trazidos para cima; chunks que permanecem ociosos por tempo suficiente são evictados. O mesmo dataset pode ser consultado em cadências muito diferentes, e nenhum deles paga o custo de carregar dados que não acessa.
Cada camada tem seu próprio layout de dados e granularidade, adaptados às características de IO do meio — o alinhamento que funciona para armazenamento de objetos não é o alinhamento que funciona para disco local, e nenhum deles corresponde ao que o mecanismo executa na memória.
IO assíncrono de ponta a ponta.
A cadeia de IO é totalmente assíncrona. Computação e IO são executados em pipeline por todo o caminho, então a CPU não fica parada esperando uma busca e a largura de banda de IO não fica parada esperando a computação.
No agregado, chunked + tiered + async reduz o payload da consulta fria para menos de 1–2% do dataset completo e o caminho frio de ponta a ponta para segundos.
Cobrança por minuto
Com a inicialização a frio no nível de segundos, "acionar computação quando uma consulta chega, liberá-la quando termina" funciona como um mecanismo real de produto — não apenas uma aspiração de design. Duas partes do plano de controle fazem o trabalho pesado.
Um pool de nós em standby. Pulls de imagem adicionam latência para inicializar um nó novo. Mantemos um pequeno pool de nós pré-carregados pronto, então a inicialização usa o pool em vez de começar do zero.
Liberação baseada em TTL. Cada sessão tem um tempo limite de ociosidade configurável. Os recursos de computação são liberados automaticamente quando o tempo limite expira, a carga de trabalho de consultas termina ou a sessão é encerrada. Todo o ciclo de vida é agendado pela plataforma — sem modo "esqueci de parar meu cluster", sem operações manuais.
Como o ciclo de vida é granular, a granularidade de cobrança cai para acompanhar. A computação é cobrada por minuto de tempo de atividade real — sem hora mínima, sem cobrança mínima por consulta. As gravações são medidas da mesma forma: uso real de recursos, por minuto.
A precisão da atribuição de custos é o que permite que o On-Demand evite o prêmio de armazenamento que o Serverless precisa cobrar. O Serverless precifica o armazenamento acima do custo marginal porque sua camada de computação não tem como absorver custos não atribuídos — cada dólar que a plataforma gasta precisa aparecer em algum lugar da conta, então armazenamento e gravações se tornam o destino para o que não pode ser atribuído em outro lugar. Quando o On-Demand cobra cada minuto de computação de uma sessão específica, não há pool não atribuído. O armazenamento no On-Demand segue a precificação do Zilliz Cloud nas tarifas do Dedicated — cerca de 1/10 do armazenamento Serverless típico.
Isolamento de cargas de trabalho em dados compartilhados
A terceira mudança é tornar a camada de computação explícita. No Dedicated, a camada de computação é o cluster — invisível para o usuário, exceto como um único parâmetro de dimensionamento. No Serverless, a camada de computação fica totalmente oculta. O On-Demand a expõe.
Cada carga de trabalho se conecta a uma coleção por meio de um grupo de recursos de computação. Novos grupos são inicializados — ou grupos existentes são reutilizados — por meio de sessões. Diferentes grupos são isolados entre si, e a conta de cada grupo reflete apenas seu próprio consumo.
No caso de direção autônoma, é assim que a carga de trabalho de analytics obtém sua própria conexão aos dados: um grupo de recursos On-Demand que é inicializado para consultas ad hoc e liberado quando fica ocioso, executando na mesma coleção Milvus, nos mesmos índices e nos mesmos metadados que as cargas de trabalho existentes de recuperação online e treinamento de modelos. A separação entre armazenamento e computação significa que nenhuma delas precisa copiar ou sincronizar dados para usá-los. Sem subsídio cruzado, sem disputa de agendamento, sem coordenação operacional entre equipes sobre o formato do cluster.
Este é o mesmo padrão arquitetural de um data lake, aplicado à busca vetorial: o armazenamento é o substrato compartilhado, e a computação se conecta no formato que cada carga de trabalho precisa.
A conta, depois
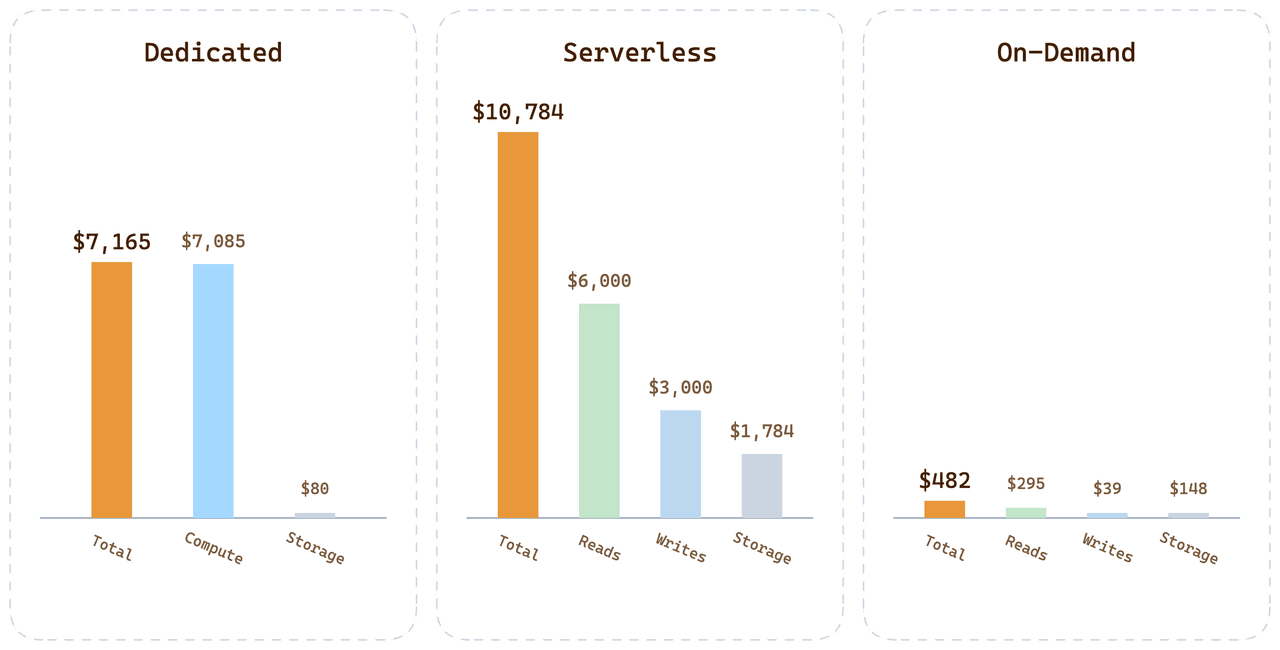
Para a mesma carga de trabalho do cliente nas três opções:
| Opção | Conta mensal | Para onde vai o dinheiro |
|---|---|---|
| Dedicated (24 CU Tiered) | $7,165 | 99,6% da computação paga, mas ociosa |
| Serverless | $10,784 | Prêmio de consulta + $1,700 de armazenamento + $3,000 de gravações |
| On-Demand | < $500 | Computação por minuto + armazenamento com tarifa de Dedicated |
O On-Demand para esta carga de trabalho fica abaixo de 1/20 da conta do Serverless. A diferença não é um truque de precificação; é a consequência direta de atribuir custos ao consumo real em vez de amortizar a variação de outros usuários em cada preço unitário.
Onde o On-Demand é a ferramenta errada
O On-Demand não é um substituto universal para Dedicated ou Serverless. As mesmas escolhas de design que o tornam barato para cargas de trabalho esparsas e em rajadas fazem dele a opção errada para outras. O gráfico abaixo plota o custo mensal em relação à pressão de consultas para a carga de trabalho deste cliente nas três opções.
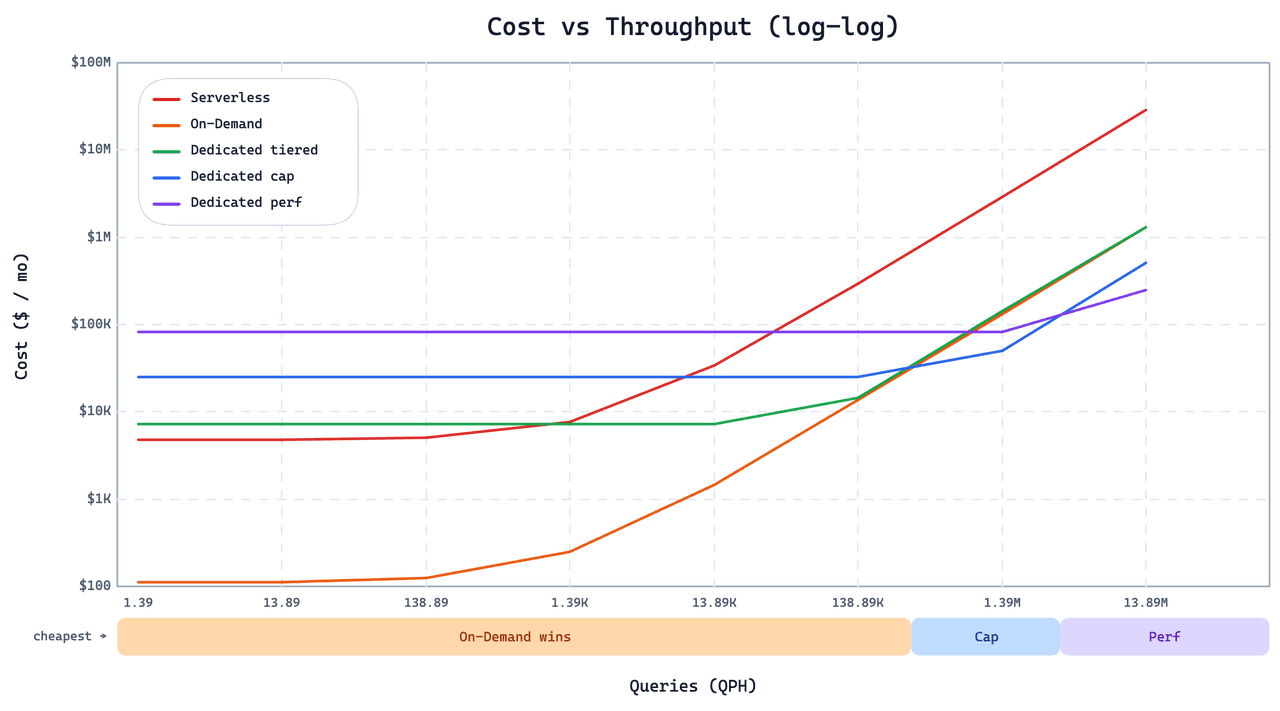
Abaixo do ponto de cruzamento, o On-Demand é significativamente mais barato. Quando o QPS entra na casa das dezenas, as instâncias Dedicated Cap ou Perf se tornam mais baratas e mais rápidas. Duas decisões de design explicam o ponto de cruzamento:
Sem índice de grafo. Para manter o carregamento de consultas frias barato, o On-Demand usa IVF em vez de índices de grafo. Índices de grafo entregam QPS em estado estável mais alto em escala, mas seu custo de carregamento frio é alto. Acima de algumas dezenas de QPS, a vantagem em estado estável vence decisivamente. Para atendimento de alto QPS, use Dedicated.
Maior latência de cauda em consultas frias. O On-Demand não pré-carrega dados, então uma consulta fria paga uma busca extra antes de poder executar. Consultas aquecidas são rápidas; as frias são perceptivelmente mais lentas, e a distribuição de latência de cauda é mais ampla do que em Dedicated ou Serverless. Se sua aplicação não consegue tolerar respostas ocasionais em nível de segundos (ou pior, em nível de minutos), o On-Demand não é a escolha certa. Para essas cargas de trabalho, o Smart Autoscaling on Dedicated reduz a capacidade ociosa sem sacrificar a latência em estado aquecido.
Onde o On-Demand é a ferramenta certa: acesso esparso, iteração analítica e mineração em lote em grandes conjuntos de dados — cargas de trabalho em que alta simultaneidade e consistência rigorosa de latência não são os requisitos principais.
Onde isso se encaixa no Zilliz Vector Lakebase
O caso do cliente neste post é uma fatia de um padrão maior: o mesmo conjunto de dados, acessado em diferentes cadências por diferentes cargas de trabalho, dimensionado corretamente apenas quando cada carga de trabalho recebe o formato de computação de que realmente precisa. O On-Demand é um desses formatos de computação. Zilliz Vector Lakebase é a arquitetura que torna possível o restante.
Um Vector Lakebase é uma plataforma de dados nativa de lake para cargas de trabalho de IA. Os dados ficam no S3, os índices são desacoplados da computação, e diferentes formatos de computação se conectam à mesma coleção por meio de acesso zero-copy. Ele lida com três modos de carga de trabalho como capacidades de primeira classe — recuperação em tempo real, descoberta iterativa e analytics em lote — cada um atendido pelo formato de computação que se ajusta ao seu padrão de acesso. A recuperação vetorial sempre foi uma carga de trabalho de primeira classe no Zilliz Cloud; com o lançamento do Vector Lakebase, os formatos de computação de descoberta iterativa e analytics em lote se juntam a ela sobre a mesma base de dados.
O On-Demand é o formato de computação criado para cargas de trabalho analíticas e com picos. As outras quatro capacidades cobrem o restante dos modos:
- Tiered Serving Solutions para recuperação em tempo real — Performance-Optimized (1000+ QPS, latência de ms de um dígito, tudo em memória), Capacity-Optimized (100–500 QPS com latência abaixo de 100 ms em memória + NVMe local) e Tiered-Storage (10–50 QPS com latência de ~100 ms em memória, NVMe e armazenamento de objetos). Diferentes pontos na curva de desempenho/custo, mesmo modo de atendimento.
- External Data Lake Search para indexar e pesquisar dados que já estão em Lance, Iceberg ou outros formatos de lake — sem copiá-los para um armazenamento separado.
- Full-Spectrum Search para vetores, texto, JSON e geoespacial em um único plano de consulta, com recuperação híbrida, filtragem e reranking em um modelo de dados de tabela ampla.
- Unified Lake-Native Storage construído sobre Vortex, um formato colunar aberto de próxima geração com leituras aleatórias mais rápidas que Lance ou Parquet, além de flexibilidade de formato por coluna.
O Zilliz Vector Lakebase está agora em preview público no Zilliz Cloud. Para a arquitetura completa e o restante das capacidades, o aprofundamento do Vector Lakebase é a leitura canônica.
Para testar o On-Demand na sua própria carga de trabalho, inscreva-se no Zilliz Cloud e crie um cluster On-Demand pelo console ou pela CLI. Se os números deste post corresponderem a algo que você está executando, a equipe da Zilliz terá prazer em analisar sua carga de trabalho com você antes de você criar.

Continue lendo

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.