




WhyHow
Build more controlled retrieval workflows within your RAG pipeline with WhyHow and Milvus or Zilliz Cloud
이 통합 기능을 무료로 사용하세요.WhyHow란 무엇인가요?
WhyHow는 개발자에게 복잡한 검색 증강 생성(RAG을 수행하기 위해 비정형 데이터를 구성, 문맥화 및 안정적으로 검색할 수 있는 빌딩 블록을 제공하는 플랫폼입니다.) 규칙 기반 검색 패키지](https://github.com/whyhow-ai/rule-based-retrieval)는 개발자가 고급 필터링 기능을 추가하여 RAG 내에서 보다 정확한 검색 워크플로우를 구축할 수 있도록 도와주는 WhyHow에서 개발한 Python 패키지입니다. 이 패키지는 텍스트 생성을 위한 OpenAI와 효율적인 벡터 저장 및 유사도 검색을 위한 Milvus 및 Zilliz Cloud(완전 관리형 Milvus)와 통합됩니다.
왜 와이하우와 밀버스/질리즈를 통합해야 하나요?
검색 증강 생성(RAG)은 보다 정확한 답변을 위해 문맥에 맞는 쿼리 정보를 제공함으로써 대규모 언어 모델(LLM)을 향상시키는 고급 기술입니다. 그러나 단순한 RAG 파이프라인은 때때로 올바른 데이터 청크를 일관되게 검색하지 못할 수 있습니다. 이 문제는 검색 및 LLM 응답 생성의 블랙박스 특성, 벡터 데이터베이스에서 차선의 결과를 산출하는 잘못된 문구의 사용자 쿼리, 또는 문맥상 관련이 있지만 의미상 서로 다른 데이터를 응답에 포함해야 하는 경우 등으로 인해 발생할 수 있습니다.
이러한 문제를 극복하기 위해서는 원시 데이터 청크의 검색을 보다 효과적으로 제어할 수 있어야 합니다. WhyHow와 Milvus/Zilliz를 통합하면 규칙 기반 검색 솔루션을 구축할 수 있습니다. 이 접근 방식을 사용하면 유사성 검색을 수행하기 전에 특정 규칙을 정의하고 관련 데이터 청크에 매핑하여 검색 워크플로우에 대한 제어를 강화할 수 있습니다. 이러한 규칙을 구현하면 쿼리 범위를 보다 타겟팅된 청크로 좁혀서 정확한 응답을 생성할 수 있는 관련 데이터를 검색할 가능성이 높아집니다. 프롬프트 및 쿼리 튜닝을 추가하면 출력 품질을 지속적으로 개선할 수 있습니다.
와이하우와 밀버스/질리즈 통합의 작동 방식
WhyHow 및 Milvus/Zilliz로 구축된 규칙 기반 검색 솔루션은 다음과 같은 작업을 수행합니다:
벡터 저장소 생성:** 이 통합은 청크 임베딩을 저장할 Milvus 컬렉션을 생성합니다.
분할, 청크 및 임베딩: 문서를 업로드하면, 통합은 문서를 Milvus 또는 Zilliz Cloud로 수집하기 전에 자동으로 분할, 청크, 임베딩을 생성합니다. 이 규칙 기반 검색 패키지는 현재 PDF 처리, 메타데이터 추출, 청킹을 위해 LangChain의 PyPDFLoader와 RecursiveCharacterTextSplitter를 지원합니다. 임베딩의 경우, OpenAI text-embedding-3-small model을 지원합니다.
데이터 삽입: 임베딩과 메타데이터를 밀버스 또는 질리즈 클라우드에 업로드합니다.
자동 필터링: 사용자 정의 규칙을 사용하여 통합이 자동으로 메타데이터 필터를 구축하여 벡터 스토어에 대한 쿼리 범위를 좁힙니다.
이 통합의 워크플로는 다음과 같습니다:
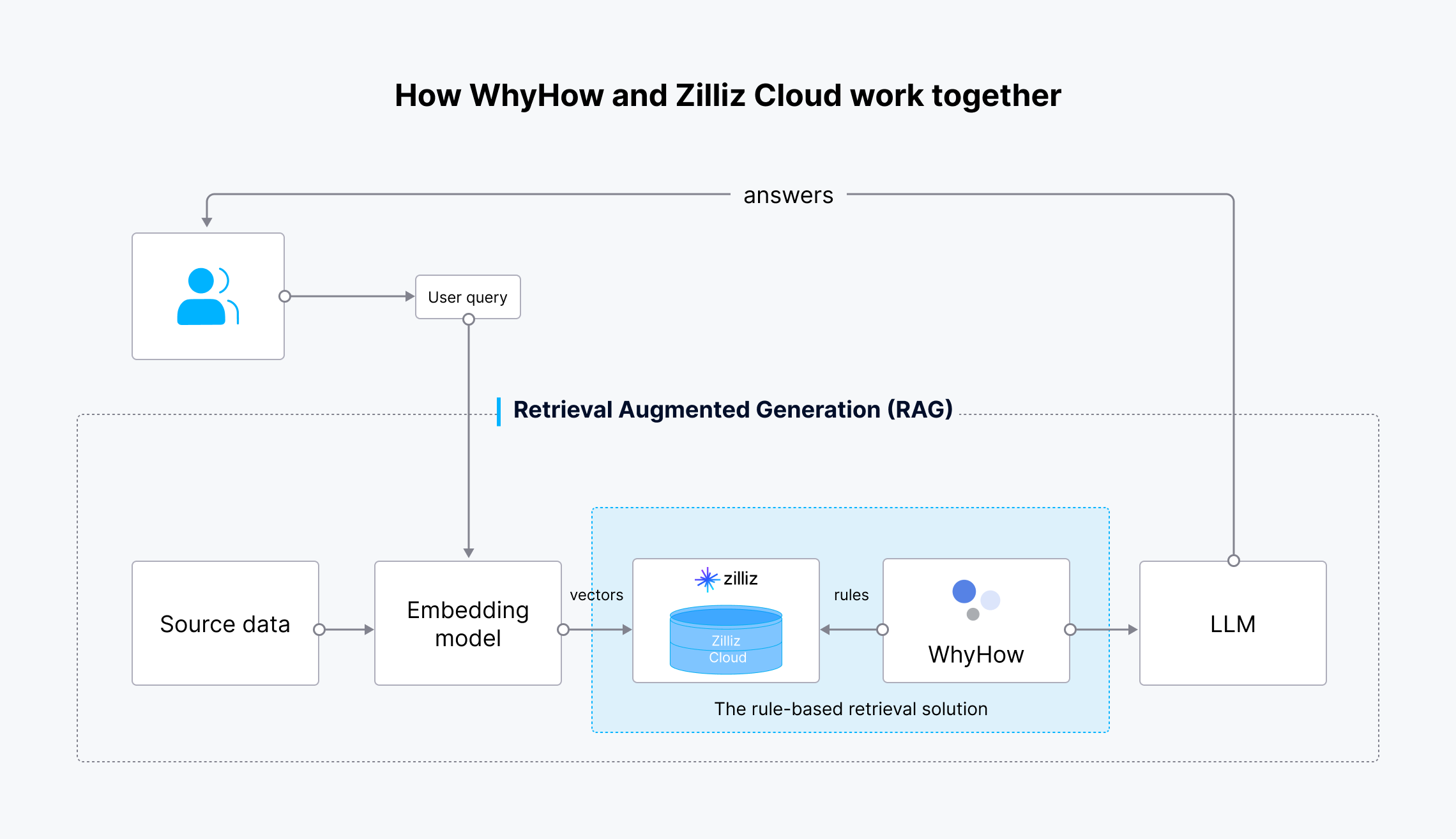 와이하우와 질리즈 클라우드의 연동 방법.png
와이하우와 질리즈 클라우드의 연동 방법.png
- 소스 데이터는 OpenAI의 임베딩 모델을 사용하여 벡터 임베딩으로 변환됩니다.
- 벡터 임베딩은 저장 및 검색을 위해 밀버스 또는 질리즈 클라우드에 수집됩니다.
- 사용자 쿼리도 벡터 임베딩으로 변환되어 가장 연관성이 높은 결과를 검색하기 위해 Milvus 또는 Zilliz Cloud로 전송됩니다.
- WhyHow는 규칙을 설정하고 벡터 검색에 필터를 추가합니다.
- 검색된 결과와 원래 사용자 쿼리는 LLM으로 전송됩니다.
- LLM은 보다 정확한 결과를 생성하여 사용자에게 전송합니다.
와이하우와 밀버스/질리즈 클라우드 사용 방법