




LlamaIndex
LlamaIndex Integration | Build Retrieval-Augmented Generation applications with Zilliz Cloud and Milvus Vector Database
이 통합을 무료로 사용하세요라마인덱스 통합, 질리즈 클라우드로 검색 증강 세대 애플리케이션 구축
LlamaIndex(이전의 GPT Index)는 대규모 언어 모델(LLM) 애플리케이션을 위해 맞춤화된 데이터 프레임워크로, 개인 또는 도메인별 데이터의 수집, 구조화 및 액세스를 용이하게 해줍니다. LLM의 핵심은 인간의 언어와 추론된 데이터(정형 및 비정형 데이터 모두) 사이의 가교 역할을 하는 것입니다. 널리 이용 가능한 LLM은 공개적으로 사용 가능한 광범위한 데이터 세트에 대해 사전 학습된 상태로 제공되지만, 중요한 데이터가 누락되는 경우가 많기 때문에 LLM에서 오답이 생성되거나 잘못된 답변이 도출되는 경우가 많습니다.
라마인덱스는 벡터 데이터베이스와 통합됩니다:
- 내부 인덱스 사용: LlamaIndex는 벡터 저장소를 사용하여 인덱스로 작동할 수 있습니다. 기존 인덱스와 마찬가지로 이 LlamaIndex 기반 인덱스는 문서를 저장하고 쿼리에 효과적으로 응답할 수 있습니다.
- 외부 데이터 통합: LlamaIndex는 벡터 저장소에서 데이터를 검색할 수 있으며, 기존 데이터 커넥터처럼 작동합니다. 일단 검색된 데이터는 추가 처리 및 활용을 위해 LlamaIndex의 데이터 구조에 원활하게 통합될 수 있습니다. 이를 흔히 검색 증강 생성 또는 RAG라고 합니다.
라마인덱스와 질리즈 클라우드의 통합 작동 방식
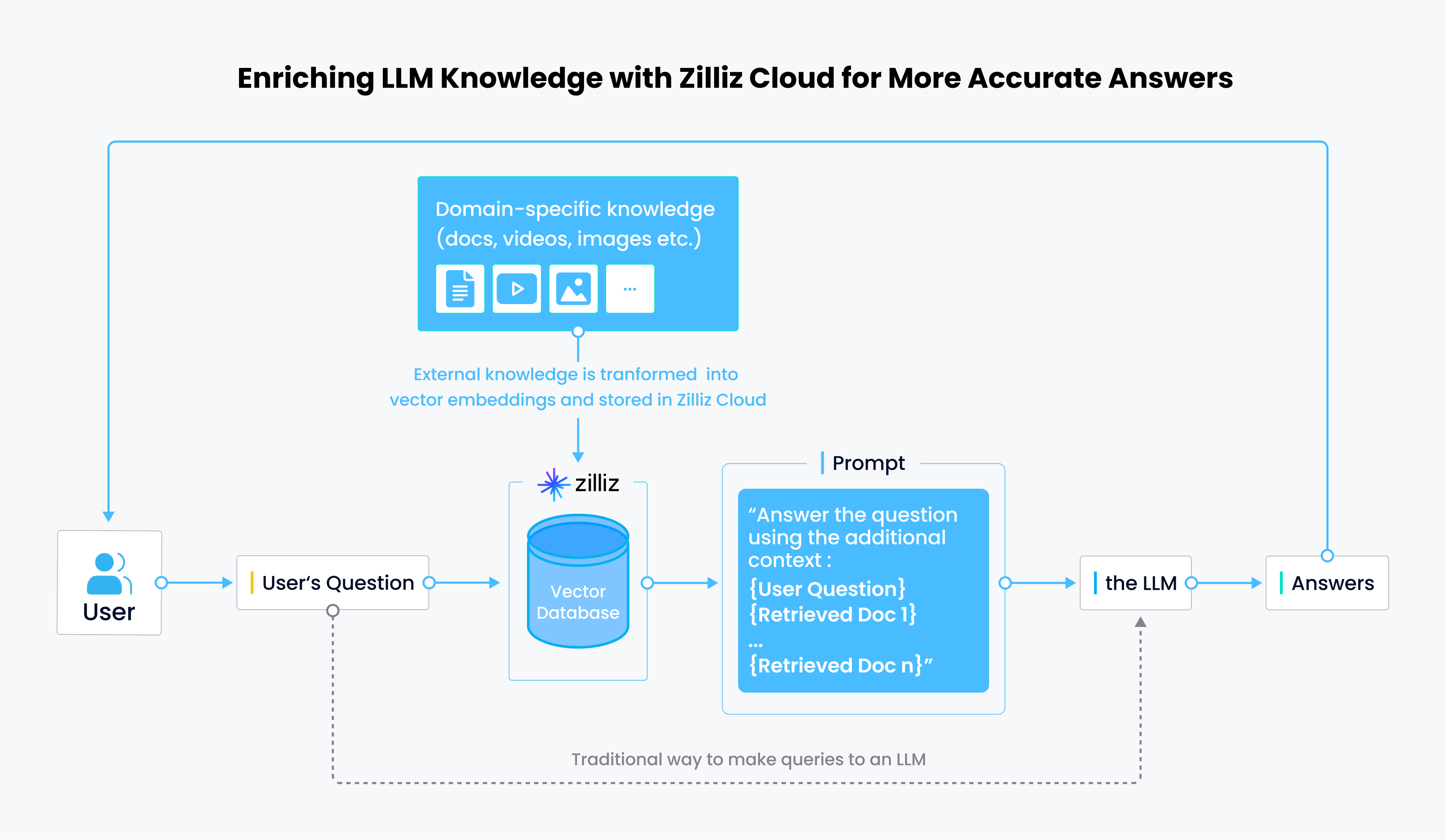
라마 사용 방법에 대해 자세히 알아보기