




VIPSHOP, Milvus를 사용해 10배 더 빠른 개인화 추천 시스템 구축

10배 더 빠른 쿼리 속도
이전 Elasticsearch 솔루션보다
<30ms 응답 시간
수백만 개의 벡터를 검색하기 위한
최적화된 사용자 경험
사용자의 구매 행동을 기반으로 한 더욱 정확한 추천
Milvus-powered vector search has been running steadily in our recommendation systems, providing high performance and allowing us more flexibility in selecting models and algorithms.
VIPSHOP Search Service Team
VIPSHOP 소개
VIPSHOP은 중국에 본사를 둔 저명한 NYSE 상장 온라인 소매업체로, 인기 브랜드 제품을 소비자에게 상당한 할인율로 제공하는 데 특화되어 있습니다. 다양한 제품군에는 패션, 의류, 액세서리, 뷰티 제품, 생활용품, 전자제품이 포함됩니다. 5,200만 명이 넘는 압도적인 고객 기반을 보유하고 연간 거의 2억 7천만 건의 주문을 처리하는 VIPSHOP은 Fortune의 권위 있는 China 500 목록에서 115위에 이름을 올렸습니다.
과제: Elasticsearch 사용으로 인한 높은 지연 시간과 급증하는 유지 관리 비용
비즈니스가 빠르게 성장함에 따라 VIPSHOP은 일반적인 딜레마에 직면했습니다. 제품 포트폴리오가 확장될수록 사용자가 찾고 있는 것을 발견하도록 돕는 일의 복잡성도 커졌습니다. 이 문제를 해결하기 위해 VIPSHOP은 사용자 쿼리 키워드와 사용자의 구매 행동을 기반으로 한 개인화 추천 시스템을 만들었습니다.
이전에 VIPSHOP 팀은 추천 시스템을 구동하기 위해 Elasticsearch의 Cosine Similarity(7.x) 기능을 활용했습니다. 그러나 이 접근 방식은 두 가지 이유로 비효율적이었습니다.
벡터 검색의 높은 지연 시간: 수백만 개의 벡터에서 Top-K 결과를 검색하는 데 평균 약 300 ms가 걸려, 시스템의 전체 응답 시간이 수 초에 달했습니다.
Elasticsearch 인덱스 유지 관리의 높은 비용: 제품, 소비자의 구매 행동 및 기타 모든 데이터에서 파생된 벡터가 동일한 인덱스 세트를 공유하여 인덱스 구축, 운영 및 유지 관리를 훨씬 더 복잡하게 만들었습니다.
VIPSHOP은 locality sensitive hashing 플러그인을 개발하여 Elasticsearch의 성능을 향상하려고 시도했습니다. 그러나 이는 처리량만 개선했을 뿐 벡터 검색 시간을 100 ms 미만으로 줄이지는 못했습니다. 따라서 팀은 여전히 시스템 성능을 개선하기 위한 새로운 벡터 검색 스택이 절실히 필요했습니다.
Milvus 솔루션
광범위한 조사 끝에 VIPSHOP 팀은 수십억 개의 벡터 임베딩을 처리하고 초고속 응답을 제공할 수 있는 오픈 소스 벡터 데이터베이스인 Milvus를 선택했습니다. Milvus는 또한 분산 배포, 다국어 SDK, 읽기/쓰기 분리와 같은 풍부한 기능을 제공하여 Elasticsearch 및 FAISS와 같은 다른 많은 벡터 검색 솔루션보다 우수한 선택지가 되었습니다.
Milvus를 사용한 VIPSHOP 추천 시스템의 아키텍처
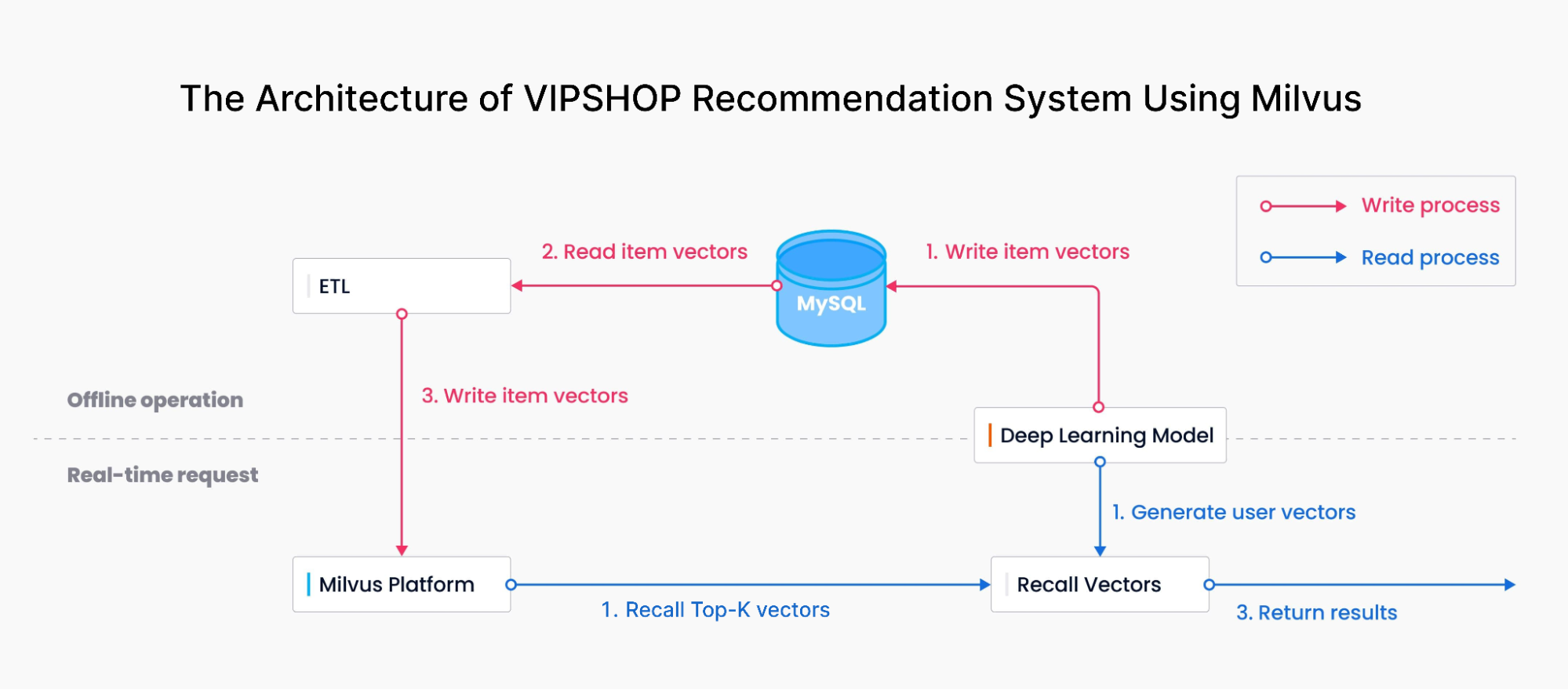
위 다이어그램은 Milvus를 사용한 VIPSHOP의 추천 시스템 아키텍처를 보여줍니다. 이는 두 가지 핵심 부분으로 구성됩니다.
쓰기 프로세스: VIPSHOP 팀은 딥러닝 모델을 사용하여 각 제품의 특징을 벡터 임베딩으로 변환한 다음 MySQL과 ETL 도구를 통해 Milvus로 가져왔습니다.
읽기 프로세스: 팀은 딥러닝 모델을 사용하여 소비자의 쿼리와 구매 행동을 벡터로 변환한 다음 Milvus에서 유사한 결과를 검색했습니다. Milvus는 유사도 검색을 수행하고 가장 관련성이 높은 Top-K 결과를 소비자에게 반환했습니다.
Milvus 구현 세부 사항: 데이터 업데이트 및 리콜
데이터 업데이트와 리콜은 Milvus 기반 추천 시스템에서 가장 필수적인 프로세스입니다.
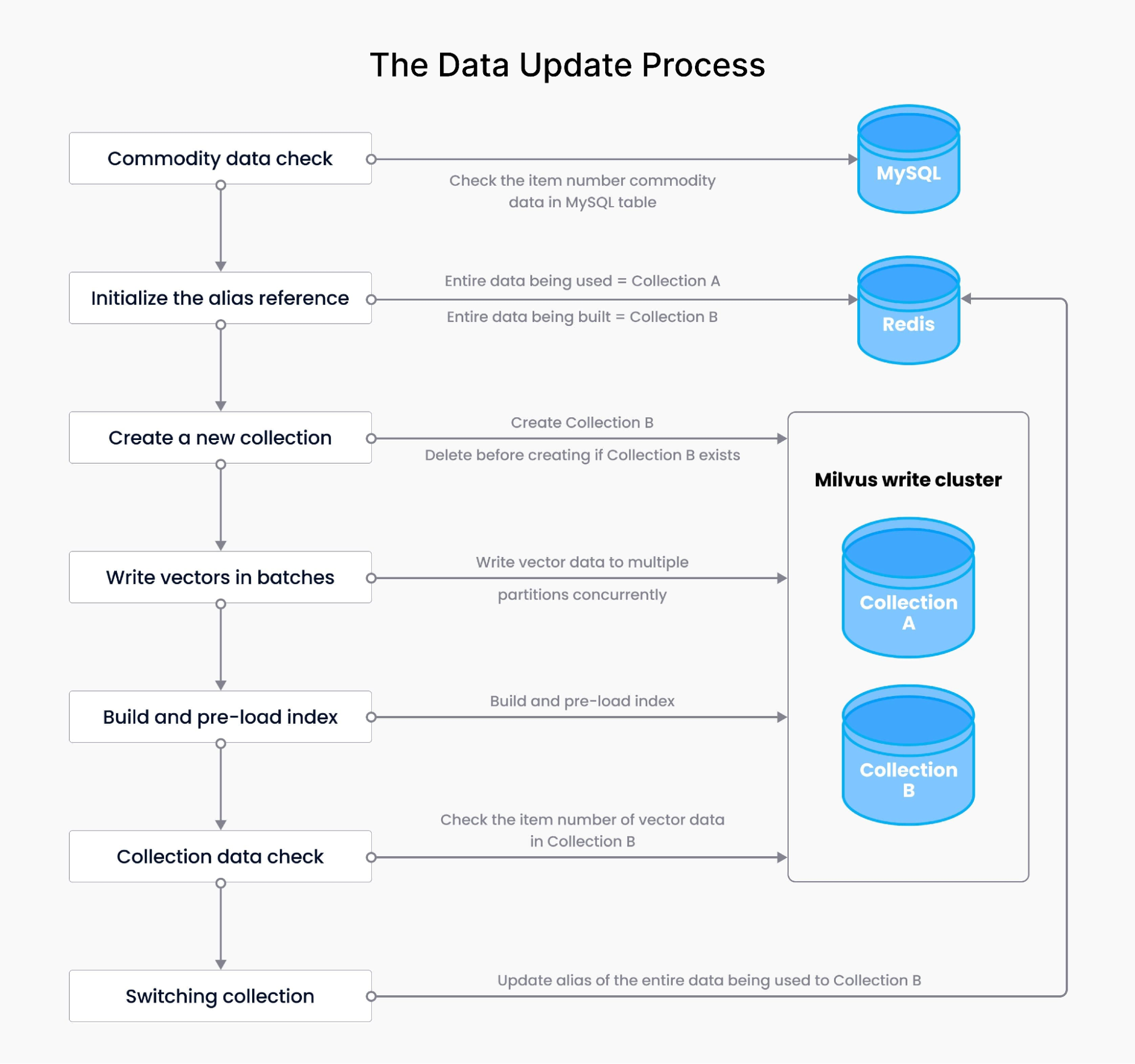
데이터 업데이트 절차는 데이터 동기화를 보장하며, 벡터 데이터 쓰기, 벡터 데이터 볼륨 감지, 인덱스 구축, 인덱스 사전 로딩, 별칭 관리와 같은 작업을 포함합니다. 이는 상품 데이터 검사로 시작하여 MySQL의 수량이 기존 데이터와 일치하는지 확인합니다. 이어서 Redis에서 별칭 초기화, 새 컬렉션 생성, 벡터 일괄 쓰기, Milvus에서 인덱스 사전 로딩을 포함한 전체 데이터 구축 프로세스가 진행됩니다. 새 컬렉션의 데이터를 검증한 후, 시스템은 여러 데이터 컬렉션 간에 별칭을 원활하게 전환합니다.
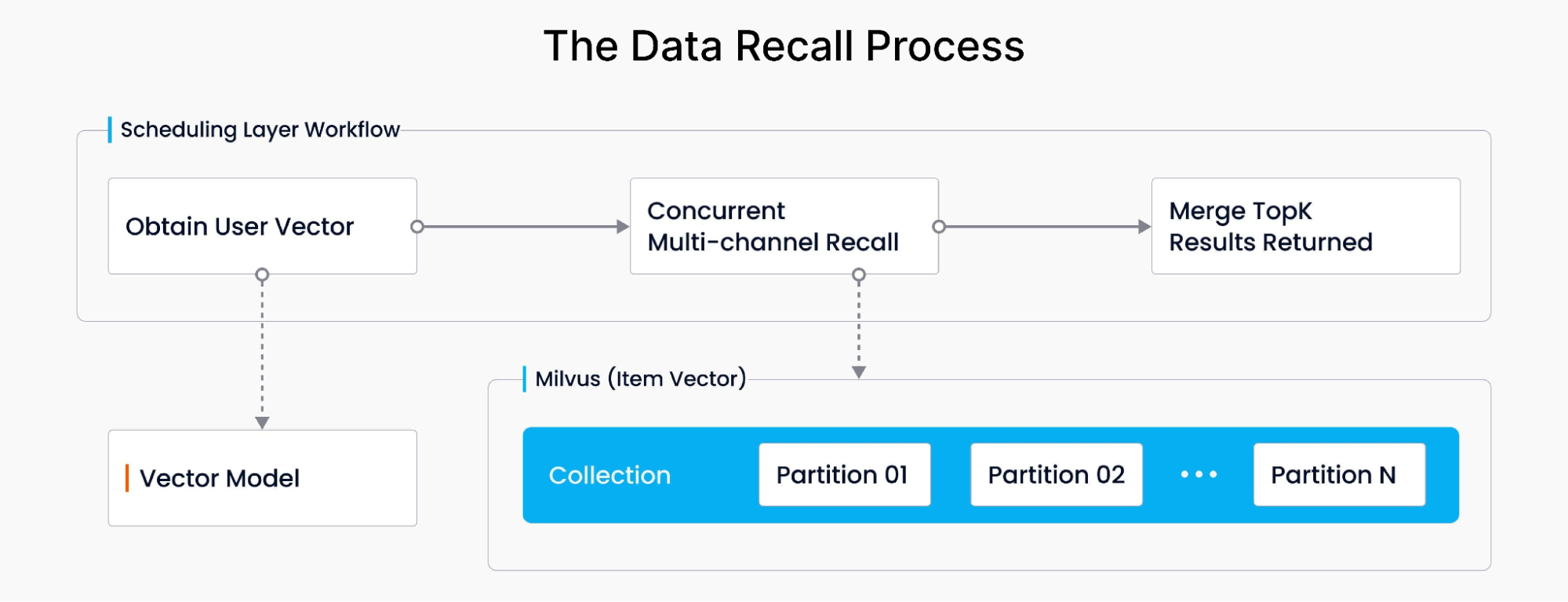
상품 추천에 핵심적인 리콜 프로세스는 소비자의 쿼리 및 구매 행동과 관련된 벡터를 획득하고, 그 거리를 계산하며, 결과를 병합하는 과정을 포함합니다. Milvus를 활용하여 시스템은 서로 다른 Milvus 파티션에서 데이터를 동시에 비동기적으로 검색하고, 벡터 유사도를 계산하며, 유사도 거리를 기반으로 상위 결과의 순위를 매깁니다. 그런 다음 Milvus 파티션 데이터에 여러 차례 호출한 후, 최종 추천 결과를 사용자에게 제시합니다. 전체 워크플로는 다음과 같습니다:
다음 표는 세 가지 주요 Milvus 서비스의 성능을 보여줍니다. 표에서 보듯이 Top-K 결과를 리콜하는 평균 지연 시간은 약 10ms입니다.
| 서비스 | 역할 | 입력 매개변수 | 출력 매개변수 | 응답 지연 시간 |
|---|---|---|---|---|
| 사용자 벡터 획득 | 사용자 벡터 획득 | user info + query | 사용자 벡터 | 10 ms |
| Milvus Search | 벡터 유사도를 계산하고 Top-K 결과 반환 | 사용자 벡터 | 아이템 벡터 | 10 ms |
| 스케줄링 로직 | 동시 결과 리콜 및 병합 | 다중 채널에서 리콜된 아이템 벡터와 유사도 점수 | Top-K 아이템 | 10 ms |
결과: 더 나은 시스템 성능과 최적의 사용자 경험
VIPSHOP의 추천 시스템에 Milvus를 도입함으로써 전반적인 시스템 성능이 크게 향상되었으며, 여기에는 다음이 포함됩니다:
10배 더 빠른 쿼리 속도
Milvus를 사용하여 시스템 쿼리 및 응답 시간이 30ms 미만으로 줄어들었으며, 이는 이전 Elasticsearch 솔루션보다 10배 빠릅니다.
향상된 시스템 확장성
Milvus의 분산 배포와 수평 확장 지원을 통해 추천 시스템은 성능 저하 없이 빠르게 증가하는 데이터 규모와 사용자 쿼리를 손쉽게 처리할 수 있습니다.
향상된 사용자 경험
Milvus는 추천 프로세스를 최적화하여 사용자 선호도와 검색 의도에 기반한 맞춤형 상품 제안을 제공함으로써 사용자 만족도와 참여도를 향상시킵니다.
유지보수 비용 절감
Milvus는 벡터 데이터를 효율적으로 처리하고 쿼리 메커니즘을 간소화하여 추천 시스템의 전체 유지보수 비용을 줄입니다.
배운 교훈과 권장 사례
Milvus를 사용하는 과정에서 VIPSHOP 팀은 몇 가지 교훈을 얻었고, 최적의 시스템 성능과 사용자 경험을 위한 여러 중요한 인사이트를 확보했습니다:
읽기 작업이 우선시되는 상황에서는 읽기-쓰기 분리 배포 전략을 채택하면 전체 시스템 성능을 향상시킬 수 있습니다.
Milvus Java client는 리콜 서비스의 인메모리 상주 특성으로 인해 내장된 재연결 메커니즘이 없습니다. VIPSHOP 팀은 하트비트 테스트를 통해 Java client와 서버 간의 일관된 연결성을 보장하기 위해 자체 커넥션 풀을 구축했습니다.
새 컬렉션의 워밍업이 충분하지 않아 Milvus에서 가끔 느린 쿼리가 발생합니다. 이 문제를 해결하기 위해 VIPSHOP 팀은 새 컬렉션에 대한 쿼리를 시뮬레이션했습니다.
검색 성능과 정확도 사이의 적절한 균형을 맞추기 위해, VIPSHOP 팀은 특정 비즈니스 시나리오에 맞춘 엄격한 부하 테스트 실험을 수행하고 이러한 매개변수를 최적화할 수 있는 합리적인 임계값을 설정할 것을 권장합니다.
정적 데이터가 포함된 시나리오에서는 먼저 모든 데이터를 컬렉션으로 가져온 뒤 나중에 인덱스를 구축하는 것이 더 효율적입니다.