




프로덕션 RAG를 위해 알아야 할 상위 10가지 컨텍스트 엔지니어링 기법
처음 RAG나 에이전트 데모를 만들 때는 보통 잘 작동합니다. 작은 데이터셋, 몇 개의 프롬프트, 단순한 검색만으로도 몇 시간 안에 프로토타입을 실행할 수 있는 경우가 많습니다.
진짜 문제는 시스템을 프로덕션에서 실행하려고 할 때 나타납니다. 사용량이 증가하면 문제가 빠르게 드러납니다. 검색은 느려지고, 답변의 신뢰도는 낮아지며, 지연 시간은 증가하고, 비용은 올라갑니다. 작은 데모에서 작동하던 것이 실제 데이터, 실제 사용자, 더 긴 컨텍스트가 관련되면 종종 깨집니다.
이 시점에서 우리는 보통 문제가 단지 모델만의 문제가 아니라는 것을 깨닫습니다. 모델에 컨텍스트가 어떻게 준비되고 전달되는지도 중요합니다. 바로 여기서 컨텍스트 엔지니어링이 등장합니다. 이는 언어 모델이 답변을 생성하는 데 사용하는 정보를 검색하고, 구성하고, 정제하고, 관리하는 데 중점을 둡니다.
이 글에서는 컨텍스트 엔지니어링이 실제로 어떻게 작동하는지 설명합니다. 컨텍스트를 구축하고, 효율적으로 처리하며, 시간이 지나도 관리하기 위한 최신 접근 방식을 살펴봅니다. 이러한 기법은 단순한 데모를 프로덕션에서 안정적으로 실행할 수 있는 시스템으로 전환하는 데 도움이 됩니다.
참고: 이 글은 주로 논문 https://arxiv.org/html/2507.13334v1에 기반합니다.
컨텍스트 엔지니어링이란 무엇인가?
컨텍스트 엔지니어링은 대규모 언어 모델이 질문에 잘 답변하는 데 필요한 정보를 조합하는 데 중점을 둡니다. 이 정보는 프롬프트에만 국한되지 않습니다. 사용자의 쿼리, 검색된 문서, 대화 기록, 기타 관련 데이터도 포함됩니다. 목표는 정확도를 높이고, 응답 시간을 줄이며, 비용을 제어하는 것입니다.
이 작업은 대부분 알고리즘을 통해 자동으로 수행됩니다. 컨텍스트 엔지니어링은 프롬프트 엔지니어링, 검색 증강 생성(RAG), 멀티 에이전트 기법을 별도로 사용하는 대신 하나의 시스템으로 결합합니다.
실제로 컨텍스트 엔지니어링 구성은 두 부분으로 이루어집니다. 첫 번째는 데이터 검색, 처리, 오케스트레이션을 담당하는 기반 구성 요소로 이루어져 있습니다. 두 번째 계층은 이러한 구성 요소를 완전한 애플리케이션으로 결합하는 더 복잡한 시스템으로 구성됩니다. 팀은 다양한 프로덕션 시나리오에 맞게 이러한 부분을 조합하고 재사용할 수 있습니다.
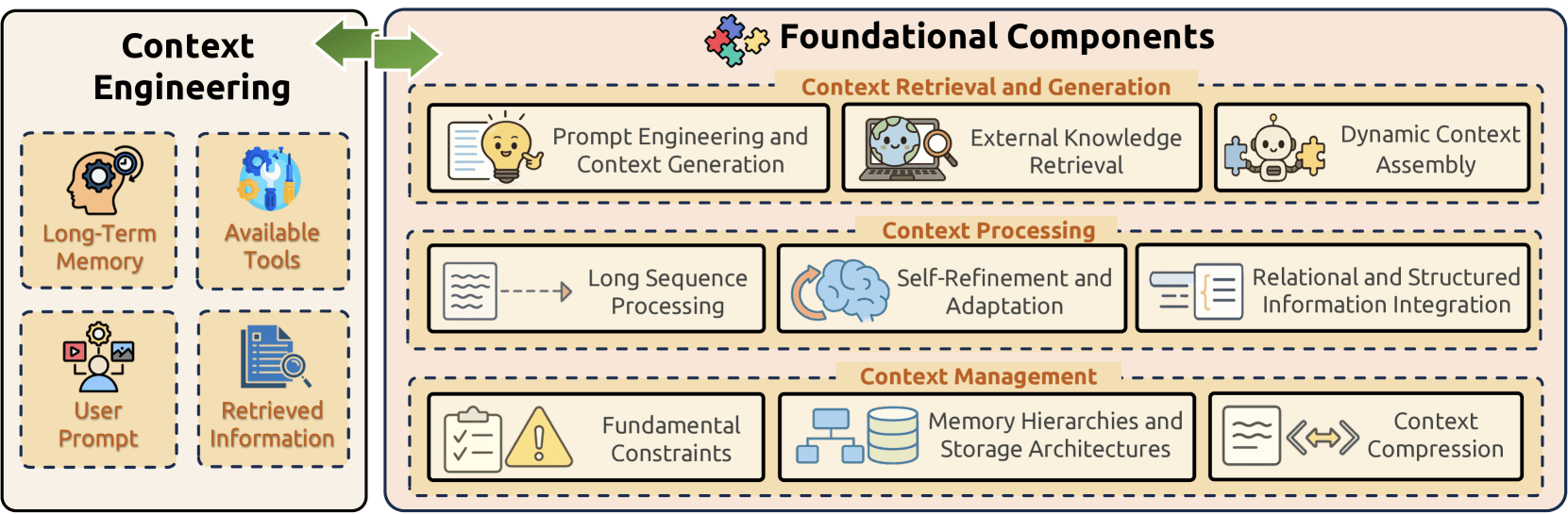
기반 구성 요소
컨텍스트 엔지니어링은 대규모 언어 모델에서 정보 관리의 핵심 과제를 함께 해결하는 세 가지 기본 구성 요소를 기반으로 합니다:
- 컨텍스트 검색 및 생성은 프롬프트 엔지니어링, 외부 지식 검색, 동적 컨텍스트 조립을 통해 적절한 컨텍스트 정보를 가져옵니다;
- 컨텍스트 처리는 긴 시퀀스 처리, 자기 정제 메커니즘, 구조화된 데이터 통합을 통해 획득한 정보를 변환하고 최적화합니다;
- 컨텍스트 관리는 근본적인 제약을 해결하고, 정교한 메모리 계층을 구현하며, 압축 기법을 개발함으로써 컨텍스트 정보의 효율적인 구성과 활용을 다룹니다.
실제 복잡한 시스템
이러한 기반 구성 요소 위에서 컨텍스트 엔지니어링은 몇 가지 일반적인 유형의 복잡한 시스템을 통해 적용됩니다.
검색 증강 생성(RAG)은 모델이 질문에 답하기 전에 지식 베이스에서 정보를 찾아볼 수 있게 합니다. 이는 답변이 모델의 추측이 아니라 실제 최신 데이터를 기반으로 하도록 보장하는 데 도움이 됩니다. 실제로 RAG는 단순한 모듈식 파이프라인으로 구축될 수도 있고, 검색을 제어하는 에이전트에 의해 구동될 수도 있으며, 더 풍부한 컨텍스트를 위해 지식 그래프와 결합될 수도 있습니다.
메모리 시스템은 모델이 상호작용 전반에 걸쳐 정보를 추적할 수 있게 합니다. 단기 메모리는 현재 대화의 세부 정보를 보관하고, 장기 메모리는 과거 대화와 학습된 지식을 저장합니다. 이는 멀티턴 대화를 더 일관되게 만들고 시스템이 시간이 지나며 개선되도록 돕습니다.
도구 통합 추론은 모델이 텍스트 추론에만 의존하는 대신 계산기, 검색 엔진 또는 API와 같은 외부 도구를 사용할 수 있게 합니다. 이 설정에서 중요한 부분은 모델이 도구 결과를 효과적으로 사용할 수 있도록 적절한 순간에 도구 결과를 다시 컨텍스트에 삽입하는 것입니다.
멀티 에이전트 시스템은 복잡한 작업을 처리하기 위해 함께 작동하는 여러 모델을 사용합니다. 각 에이전트는 특정 역할을 가지며, 시스템은 일관된 결과를 생성하기 위해 이들이 어떻게 소통하고, 정보를 공유하며, 동기화 상태를 유지할지 조율합니다.
컨텍스트 처리
앞서 우리는 컨텍스트 엔지니어링의 세 가지 주요 부분인 컨텍스트 검색 및 생성, 컨텍스트 처리, 컨텍스트 관리를 소개했습니다. 이들은 실용적인 컨텍스트 시스템의 기본 구성 요소를 이룹니다.
컨텍스트 처리는 특히 중요합니다. 이는 원시 검색 정보를 가져와 정리하고, 재구성하며, 조직화하여 모델이 더 효율적으로 이해하고 사용할 수 있게 합니다.
이 섹션에서는 실제 시스템에서 컨텍스트 처리가 어떻게 이루어지는지와 어떤 접근 방식이 일반적으로 사용되는지 살펴봅니다.
긴 컨텍스트 처리
매우 긴 컨텍스트를 처리하는 것은 비용이 많이 듭니다. transformer 모델은 self-attention을 사용하며, 이는 입력 길이가 증가할수록 확장성이 좋지 않기 때문입니다. 시퀀스가 길어질수록 계산량과 메모리 사용량이 빠르게 증가하여 프로덕션 시스템에서 실제 병목 현상을 만듭니다.
예를 들어, Mistral-7B의 입력 길이를 4K에서 128K 토큰으로 확장하면 계산 비용이 약 122배 증가합니다. 메모리 사용량도 prefilling과 decoding 중에 모두 급격히 증가합니다. 실제로 Llama 3.1 8B와 같은 모델은 단일 128K 토큰 요청에 최대 16 GB의 메모리를 필요로 할 수 있습니다.
이러한 한계를 극복하기 위해 연구자들은 주로 세 가지 접근 방식을 사용합니다.
하나는 Mamba와 같이 설계상 실행 비용이 더 저렴한 새로운 모델 아키텍처를 구축하는 것입니다. 또 다른 방법은 positional interpolation과 같은 기법을 사용하여 기존 모델이 훨씬 더 긴 입력을 처리할 수 있게 하는 것입니다. 세 번째 접근 방식은 중복 작업을 피하고 메모리를 더 효율적으로 사용하여 계산이 수행되는 방식을 개선함으로써 긴 컨텍스트 처리를 더 빠르게 하고 더 적은 리소스를 사용하게 합니다.
(1) 긴 컨텍스트를 위한 아키텍처 혁신
Transformers의 제곱 비용을 해결하기 위해 연구자들은 긴 시퀀스 처리를 더 저렴하고 효율적으로 만드는 새로운 모델 아키텍처를 개발해 왔습니다.
- State Space Models (SSMs)는 고정 크기 hidden state를 통해 선형 계산 복잡도와 일정한 메모리 요구 사항을 유지하며, Mamba와 같은 모델은 기존 transformers보다 더 효과적으로 확장되는 효율적인 recurrent computation 메커니즘을 제공합니다.
- Dilated attention 접근 방식인 LongNet은 토큰 거리가 증가함에 따라 지수적으로 확장되는 attentive field를 사용하여, 토큰 간 로그 의존성을 유지하면서 선형 계산 복잡도를 달성하고, 10억 개 이상의 토큰으로 이루어진 시퀀스를 처리할 수 있게 합니다.
- Toeplitz Neural Networks (TNNs)는 상대 위치가 인코딩된 Toeplitz 행렬로 시퀀스를 모델링하여 시공간 복잡도를 로그-선형으로 줄이고, 512개의 학습 토큰에서 14,000개의 추론 토큰으로 외삽할 수 있게 합니다.
- Linear attention 메커니즘은 self-attention을 kernel feature map의 선형 dot-product로 표현함으로써 복잡도를 O(N²)에서 O(N)으로 줄이며, 매우 긴 시퀀스를 처리할 때 최대 4000배의 속도 향상을 달성합니다.
non-attention LLMs와 같은 대안적 접근 방식은 recursive memory transformers 및 기타 아키텍처 혁신을 사용하여 제곱 장벽을 깨뜨립니다.
(2) 위치 보간 및 컨텍스트 확장
위치 보간 기법은 보지 못한 위치로 외삽하는 대신 위치 인덱스를 지능적으로 재조정함으로써, 모델이 원래 컨텍스트 창의 한계를 넘어서는 시퀀스를 처리할 수 있게 합니다.
- 신경 접선 커널(NTK) 접근법은 맥락 확장을 위한 수학적으로 기반이 탄탄한 프레임워크를 제공하며, YaRN(Yet another RoPE-based Interpolation method)은 NTK 보간을 선형 보간 및 어텐션 분포 보정과 결합합니다.
- 2단계 접근법: LongRoPE는 2단계 접근법을 통해 2048K 토큰 맥락 창을 달성합니다. 먼저 모델을 256K 길이로 파인튜닝한 다음, 최대 맥락 길이에 도달하기 위해 위치 보간을 수행합니다.
- 위치 시퀀스 튜닝(PoSE) 은 여러 위치 보간 전략을 결합하여 최대 128K 토큰까지 인상적인 시퀀스 길이 확장을 보여줍니다.
- Self-Extend 기법은 그룹화된 어텐션과 이웃 어텐션이라는 이중 수준 어텐션 전략을 사용하여 먼 토큰과 인접한 토큰 간의 의존성을 포착함으로써, 파인튜닝 없이 LLM이 긴 맥락을 처리할 수 있게 합니다.
(3) 효율적 처리를 위한 최적화 기법
핵심 모델 아키텍처를 변경하지 않고도, 연구자들은 긴 맥락 처리를 더 효율적으로 만들기 위한 다양한 최적화 기법도 개발해 왔습니다.
그룹화된 쿼리 어텐션(GQA) 은 쿼리 헤드를 키 및 값 헤드를 공유하는 그룹으로 분할하여, 디코딩 중 메모리 요구량을 줄이면서 다중 쿼리 어텐션과 다중 헤드 어텐션 사이의 균형을 이룹니다.
FlashAttention 은 비대칭 GPU 메모리 계층 구조를 활용하여 2차 요구량 대신 선형 메모리 스케일링을 달성하며, FlashAttention-2는 비행렬 곱셈 연산 감소와 최적화된 작업 분배를 통해 약 두 배의 속도를 제공합니다.
Ring Attention 은 Blockwise Transformers와 함께 블록 단위 계산을 활용하고 통신을 어텐션 계산과 중첩시키면서 계산을 여러 장치에 분산하여 매우 긴 시퀀스를 처리할 수 있게 합니다.
희소 어텐션 기법에는 LongLoRA의 Shifted sparse attention(S²-Attn)과 SF-Attn을 사용하는 SinkLoRA가 포함되며, 이들은 상당한 계산 절감과 함께 전체 어텐션 대비 92%의 퍼플렉서티 개선을 달성합니다.
메모리 관리 및 맥락 압축 은 긴 입력의 비용을 줄입니다. Rolling Buffer Cache는 KV 캐시 메모리를 줄이기 위해 어텐션 창을 제한하는 반면, StreamingLLM은 핵심 토큰과 최근 맥락만 유지하여 긴 시퀀스를 지원합니다. Infini-attention 및 H2O와 같은 다른 방법은 압축 메모리와 더 스마트한 캐시 축출을 통해 효율성을 개선합니다.
맥락적 자기 정제 및 적응
자기 정제는 강화학습 접근법과 구별되는 프롬프트 엔지니어링을 통한 대화형 자기 상호작용을 통해 자기 평가를 활용하면서, 인간의 수정 과정을 반영하는 순환적 피드백 메커니즘을 통해 LLM이 출력을 개선할 수 있게 합니다.
아이디어는 단순합니다. 복잡한 작업에서는 모든 것을 한 번에 맞히는 것보다 첫 번째 버전을 작성한 뒤 고치는 것이 더 쉽습니다. 모델이 자신의 작업을 점검하고 단계별로 개선하는 법을 배우면, 추론, 코드 작성, 창의적 작업에서 더 나은 성능을 보이고 새로운 상황에 더 쉽게 적응합니다.
(1) 기초 자기 정제 프레임워크
- Self-Refine 프레임워크는 동일한 모델을 생성기, 피드백 제공자, 정제기로 사용하며, 오류를 식별하고 수정하는 것이 완벽한 초기 해답을 생성하는 것보다 종종 더 쉽다는 점을 보여줍니다.
- Reflexion 은 언어적 피드백을 통해 향후 의사결정을 위해 에피소드 기억 버퍼에 성찰적 텍스트를 유지하는 반면, 단순한 프롬프팅은 신뢰할 수 있는 자기 수정을 가능하게 하는 데 종종 실패하므로 구조화된 지침이 필수적임을 보여줍니다.
- N-CRITICS 프레임워크는 초기 출력이 생성 LLM과 다른 모델 모두에 의해 평가되는 앙상블 기반 평가를 구현하며, 컴파일된 피드백은 작업별 중단 기준이 충족될 때까지 정제를 안내합니다.
(2) 메타러닝 및 자율적 진화
더 발전된 단계에서, 컨텍스트 자기 정제는 메타러닝과 자율적 개선에 초점을 맞춥니다. 목표는 모델이 작업을 해결하는 것뿐만 아니라 시간이 지남에 따라 더 잘 학습하는 방법도 배우도록 돕는 것입니다.
SELF 는 제한된 예시로 LLM에 메타 기술(자기 피드백, 자기 정제)을 가르친 다음, 모델이 자체 학습 데이터를 생성하고 필터링함으로써 지속적으로 자기 진화하도록 합니다. 자기 보상 메커니즘은 단일 모델이 수행자와 심판이라는 이중 역할을 맡아 자신에게 부여하는 보상을 극대화하는 반복적 자기 판단을 통해 모델이 자율적으로 개선되도록 합니다.
Creator 프레임워크는 LLM이 생성, 의사결정, 실행, 인식을 아우르는 4개 모듈 프로세스를 통해 자체 도구를 만들고 사용할 수 있게 함으로써 이 패러다임을 확장합니다.
Self-Developing 프레임워크는 가장 자율적인 접근 방식을 나타내며, LLM이 실행 가능한 코드로 알고리즘 후보를 생성하는 반복 주기를 통해 자체 개선 알고리즘을 발견, 구현, 정제할 수 있게 합니다.
멀티모달 컨텍스트
멀티모달 대규모 언어 모델(MLLM)은 이미지, 오디오, 3D 데이터와 같은 입력을 다룸으로써 텍스트를 넘어섭니다. 이들은 이러한 다양한 유형의 정보를 모델이 추론할 수 있는 단일 컨텍스트로 결합합니다.
이는 더 발전된 애플리케이션을 가능하게 하지만, 서로 다른 모달리티를 통합하고, 모달리티 간에 추론하며, 길고 복잡한 입력을 처리하는 것과 같은 새로운 과제도 가져옵니다.
(1) 멀티모달 컨텍스트 통합
컨텍스트 통합은 멀티모달 컨텍스트 처리의 핵심입니다. 이는 이미지, 텍스트, 오디오와 같은 서로 다른 모달리티의 정보를 모델이 추론할 수 있는 단일 표현으로 결합하는 것을 목표로 합니다.
기본적인 접근 방식은 CLIP과 같은 인코더를 사용해 이미지를 토큰으로 변환한 다음, 모든 것을 언어 모델에 보내기 전에 이를 텍스트 토큰에 덧붙입니다. 이는 구현하기 쉽지만, 서로 다른 모달리티는 종종 느슨하게 연결된 상태로 남아 있습니다.
더 발전된 방법은 통합을 개선합니다. 교차 모달 어텐션은 모델 내부에서 시각 토큰과 텍스트 토큰 간의 직접적인 관계를 학습할 수 있게 하며, 이는 이미지 편집 및 시각 추론과 같은 작업에 중요합니다.
길거나 복잡한 입력으로 확장하기 위해, 계층적 설계는 각 모달리티를 단계적으로 처리합니다. 일부 시스템은 각각을 별도로 처리하는 대신, 모델에 전달하기 전에 여러 이미지나 입력의 정보를 병합하기도 합니다.
다른 연구는 처음부터 멀티모달 데이터와 텍스트를 함께 학습함으로써 텍스트 전용 모델을 조정하는 것을 아예 피합니다. 교차 모달 추론은 이를 기반으로 하며, 모델이 각 모달리티 자체만이 아니라 이미지와 텍스트를 통해 표현되는 풍자처럼 이들이 결합될 때 나타나는 의미도 이해할 것을 요구합니다.
(2) 외부 멀티모달 인코더와 정렬 모듈
멀티모달 컨텍스트 통합은 두 가지 주요 부분, 즉 외부 멀티모달 인코더 와 이를 언어 모델에 연결하는 정렬 모듈 을 기반으로 합니다.
대부분의 현재 시스템에서는 각 데이터 유형이 전용 인코더에 의해 처리됩니다. 예를 들어, 이미지는 CLIP과 같은 모델로 처리되고, 오디오는 CLAP과 같은 모델로 처리됩니다. 이러한 인코더는 픽셀이나 음파와 같은 원시 입력을 특징 벡터로 변환합니다.
그런 다음 정렬 모듈은 이러한 특징을 언어 모델의 임베딩 공간으로 변환하여 텍스트 토큰과 함께 작동할 수 있게 합니다. 일부 시스템은 MLP와 같은 단순한 매핑을 사용하는 반면, 다른 시스템은 학습 가능한 쿼리 토큰을 사용해 텍스트와 가장 관련 있는 시각 특징을 선택하는 Q-Former를 사용합니다.
이러한 모듈식 설정은 시스템을 더 쉽게 유지관리할 수 있게 합니다. 전체 언어 모델을 다시 학습하지 않고도 인코더를 업데이트하거나 교체할 수 있으며, 이는 실제 배포에 중요합니다.
관계형 및 구조화된 컨텍스트
대규모 언어 모델은 텍스트 기반 입력 요구사항과 순차적 아키텍처의 한계로 인해 표, 데이터베이스, 지식 그래프를 포함한 관계형 및 구조화된 데이터를 처리하는 데 근본적인 제약에 직면합니다.
선형화는 복잡한 관계와 구조적 속성을 보존하는 데 실패하는 경우가 많으며, 정보가 컨텍스트 전반에 분산되어 있을 때 성능이 저하됩니다.
이 문제를 해결하기 위해 연구자들은 구조화된 데이터를 언어 모델이 사용할 수 있는 형태로 표현하는 방법을 모색해 왔습니다. 목표는 모델이 복잡한 추론과 사실 확인이 포함된 작업에서 더 나은 성능을 내도록 돕는 것입니다.
(1) 지식 그래프 임베딩과 신경망 통합
고급 인코딩 전략은 엔터티와 관계를 수치 벡터로 변환하는 지식 그래프 임베딩을 통해 구조적 한계를 해결하며, 이를 통해 언어 모델 아키텍처 내에서 효율적인 처리가 가능해집니다.
그래프 신경망은 엔터티 간의 복잡한 관계를 포착하여, transformer 블록과 함께 GNN 구성 요소를 중첩하는 GraphFormers와 같은 특수 아키텍처를 통해 지식 그래프 구조 전반의 multi-hop 추론을 가능하게 합니다.
(2) 언어화
일반적인 접근 방식 중 하나는 지식 그래프, 테이블, 데이터베이스 레코드와 같은 구조화된 데이터를 자연어 텍스트로 변환하여, 아키텍처를 변경하지 않고도 기존 언어 모델이 직접 사용할 수 있게 하는 것입니다. 다른 방법들은 언어적 관계를 기반으로 입력 텍스트를 구조화된 계층으로 재구성하거나, 핵심 정보를 추출해 그래프, 테이블, 관계형 스키마로 명시적으로 표현합니다.
일부 경우에는 프로그래밍 언어를 사용해 구조화된 데이터를 표현하는 것이 자연어보다 더 효과적입니다. 예를 들어, 지식 그래프에는 Python 코드를, 데이터베이스에는 SQL을 사용하는 것이 복잡한 추론 작업에서 더 강력한 성능으로 이어지는 경우가 많습니다. 이러한 형식이 구조를 더 명확하게 보존하기 때문입니다. 또한 좋은 성능을 유지하면서 더 적은 매개변수로 구조화된 데이터를 처리하기 위해 compact matrix 표현을 사용하는 자원 효율적인 접근 방식도 있습니다.
(3) 하이브리드 아키텍처
테이블과 지식 그래프처럼 복잡한 관계를 가진 구조화된 데이터를 처리하기 위해, 연구자들은 대규모 언어 모델을 그래프 신경망과 같은 그래프 구조 데이터용 구성 요소와 결합하는 하이브리드 아키텍처를 탐구해 왔습니다.
여러 실용적인 접근 방식이 사용됩니다. GraphToken은 특수 토큰을 추가해 관계를 명시적으로 만들며, 이는 모델이 그래프에 대해 추론하는 데 도움을 줍니다. Heterformer는 하나의 프레임워크 안에서 텍스트와 그래프 구조를 함께 처리하여, 계산 비용을 제어하면서 관계 정보를 유지합니다.
다른 방법들은 서로 다른 방식으로 지식을 통합합니다. K-BERT는 학습 중 지식 그래프 정보를 추가하여 모델이 이러한 관계를 미리 학습하도록 합니다. KAPING은 재학습 없이 추론 시점에 관련 지식을 검색합니다. 더 발전된 설계는 adapter와 attention을 사용해 그래프 정보를 모델에 직접 혼합하여, 더 긴밀한 통합을 이끌어냅니다.
결론
컨텍스트 엔지니어링은 LLM 시스템이 프로덕션 환경에서 어떻게 작동하는지 이해하는 데 유용한 방법을 제공합니다. 일반적으로 이는 세 가지 주요 과정, 즉 컨텍스트 검색 및 생성, 컨텍스트 처리, 컨텍스트 관리를 포함합니다. 이 단계들은 함께 정보가 어떻게 수집되고, 준비되며, 모델에 전달되는지를 결정합니다.
그중에서도 컨텍스트 처리는 검색된 정보가 모델에 도달하기 전에 어떻게 정제되고, 구성되며, 압축되는지를 결정하기 때문에 특히 중요합니다. 분량의 한계로 인해 이 글은 주로 이 부분에 초점을 맞추고 실제 시스템에서 사용되는 여러 접근 방식을 검토했습니다. 검색과 컨텍스트 관리 역시 중요한 영역이며, 향후 논의에서 더 깊이 탐구할 수 있습니다.
RAG 또는 에이전트 시스템을 구축하면서 컨텍스트, 비용 또는 지연 시간과 관련된 프로덕션 이슈를 겪고 있다면, 다른 엔지니어들과 컨텍스트 엔지니어링을 논의할 수 있는 Slack Channel에 참여하세요. 또한 Milvus Office Hours를 통해 데모에서 프로덕션 준비가 된 시스템으로 전환하는 데 필요한 실질적인 지침을 얻기 위한 짧은 일대일 세션을 예약할 수도 있습니다.
계속 읽기

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.