




CLIP 및 Llama3를 사용한 로컬 멀티모달 RAG
최근 GPT-4o와 Gemini가 출시되면서 멀티모달이 화두가 되고 있습니다. 지난 1년간 주목받았던 또 다른 기술은 검색 증강 생성(RAG)이지만, 대부분 텍스트에 집중되어 있었습니다. 이 튜토리얼에서는 멀티모달 RAG 시스템을 구축하는 방법을 보여드리겠습니다.
멀티모달 RAG를 사용하면 텍스트만 사용할 필요 없이 이미지, 오디오, 동영상, 텍스트 등 다양한 유형의 데이터를 사용할 수 있습니다. 또한 다양한 종류의 데이터를 반환할 수도 있습니다. RAG 시스템의 입력으로 텍스트를 사용한다고 해서 반드시 텍스트를 출력으로 반환해야 하는 것은 아닙니다. 이 튜토리얼에서 그 방법을 보여드리겠습니다.
전제 조건
튜토리얼의 다양한 구성 요소 설정을 시작하기 전에 시스템에 다음 사항이 있는지 확인하세요:
Docker 및 Docker-Compose-시스템에 Docker 및 Docker-Compose가 설치되어 있는지 확인합니다.
밀버스 스탠드얼론 - 여기서는 Docker Compose를 통해 쉽게 관리할 수 있는 효율적인 밀버스 스탠드얼론을 사용하며, 설치 안내 문서를 참조하세요.
올라마**-시스템에 올라마를 설치합니다. 이렇게 하면 노트북에서 Llama3를 사용할 수 있습니다. 최신 설치 가이드는 웹사이트를 참조하세요.
OpenAI 클립
CLIP](https://zilliz.com/learn/exploring-openai-clip-the-future-of-multimodal-ai-learning)(대비 언어-이미지 사전 학습) 모델의 핵심 아이디어는 그림과 텍스트 사이의 연관성을 이해하는 것입니다. 이 모델은 텍스트-이미지 쌍으로 훈련된 기본 AI 모델입니다. 그런 다음 텍스트와 이미지 모두에 대해 벡터 공간에 점을 생성하는 방법을 학습합니다. 이 공간에서 유사한 텍스트 설명은 관련 이미지에 가까워지고 그 반대의 경우도 마찬가지입니다.
CLIP은 다음과 같은 다양한 애플리케이션에 사용할 수 있습니다:
이미지 검색**: 텍스트 설명을 사용하여 이미지를 검색하거나 이미지에 어울리는 완벽한 캡션을 찾는다고 상상해 보세요.
멀티모달 학습: 텍스트와 이미지를 연결하는 CLIP의 강점은 다양한 형식의 정보를 다루는 멀티모달 RAG와 같은 시스템을 위한 완벽한 빌딩 블록입니다.
이를 통해 RAG 시스템은 텍스트와 이미지가 모두 포함될 수 있는 쿼리를 이해하고 응답할 수 있습니다.
그림1: OpenAI CLIP의 아키텍처](https://assets.zilliz.com/Architecture_of_Open_AI_CLIP_765f6f1fc0.png)
멀티모달 임베딩 ## 멀티모달 임베딩
**임베딩이란 무엇인가요? 간단히 말해서 임베딩은 데이터를 압축한 표현입니다. CLIP은 이미지나 텍스트를 입력으로 받아 주요 특징을 캡처하는 숫자 코드로 변환합니다.
CLIP의 장점은 텍스트와 이미지 모두에서 작동한다는 것입니다. 이미지를 제공하면 시각적 콘텐츠를 캡처하는 임베딩이 생성됩니다. 그러나 텍스트를 입력할 수도 있으며, CLIP은 텍스트의 의미를 반영하는 임베딩을 생성합니다.
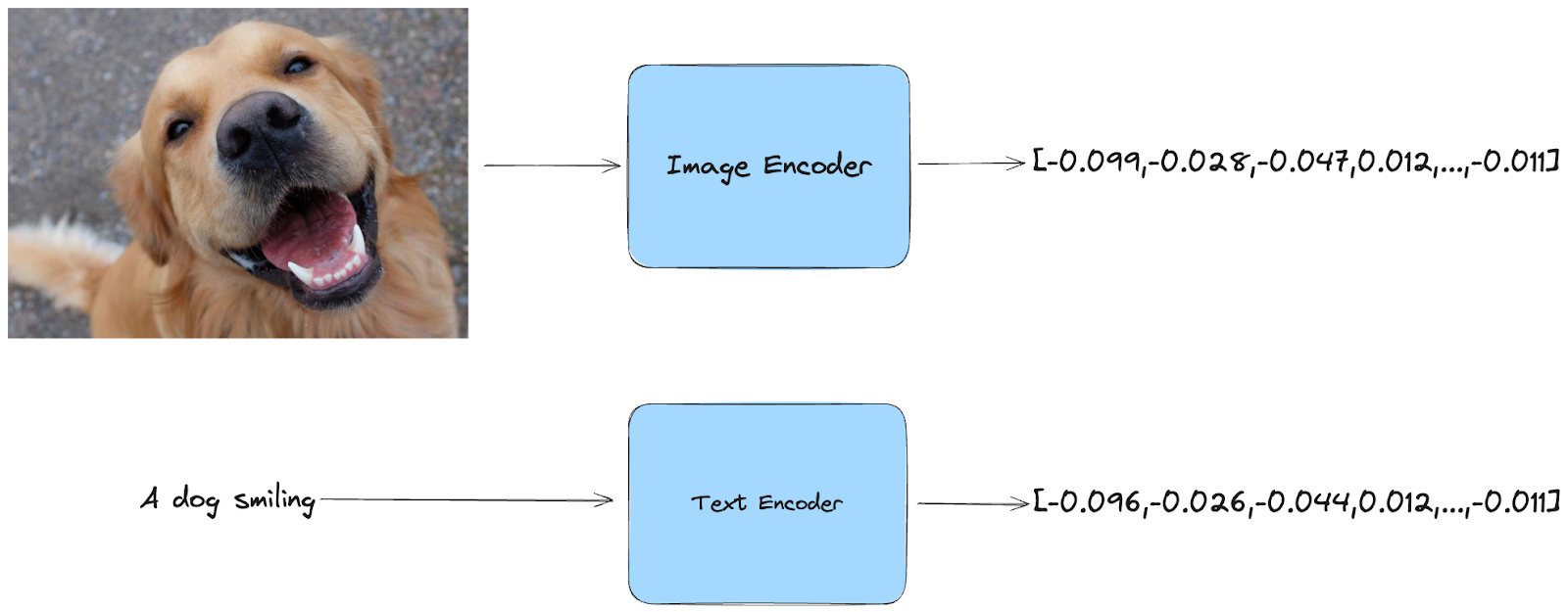 멀티모달 임베딩
멀티모달 임베딩
벡터 공간에 투영을 상상해 보면 비슷한 의미를 가진 임베딩이 서로 가깝게 배치되어 있을 것입니다. 예를 들어 "미소를 짓고 있는 개"라는 텍스트와 웃고 있는 것처럼 보이는 개 그림은 서로 가까이 있습니다.
그림2. 벡터 공간에서의 표현](https://assets.zilliz.com/Representation_in_a_Vector_Space_e47a5a4373.png)
멀티모달 RAG 구축하기
위키피디아에서 데이터를 사용하고, 자세히 알아보고자 하는 내용과 관련된 텍스트 데이터를 다운로드하고, 이미지로 동일한 작업을 수행합니다.
CLIP ViT-B/32 모델로 임베딩을 생성하고 LLM으로 Llama3를 사용하겠습니다.
임베딩은 대규모 임베딩을 관리하도록 설계된 Milvus에 저장하여 빠르고 효율적인 검색을 수행할 수 있도록 합니다.
LlamaIndex를 쿼리 엔진으로, Milvus를 벡터 저장소로 사용합니다.
위키백과를 검색하고 텍스트와 이미지를 처리한 다음 RAG 애플리케이션을 만들어야 하기 때문에 전체 코드가 상당히 길어집니다. 하지만 Github에서 전체 코드를 확인할 수 있으니 꼭 확인해보세요!
일단 작동이 시작되면 다음과 유사한 쿼리를 실행할 수 있을 것입니다:
# https://en.wikipedia.org/wiki/Helsinki
query2 = "헬싱키에서 인기 있는 관광 명소는 무엇인가요?"
# 이미지 검색 결과 생성
image_query(query2)
# 텍스트 검색 결과 생성
text_retrieval_results = text_query_engine.query(query2)
print("텍스트 검색 결과: \n" + str(text_retrieval_results))
다음과 비슷한 내용이 출력되어야 합니다.
헬싱키의 인기 관광 명소로는 풍부한 역사를 간직한 요새 섬인 수오멘린나(스베아보르그)와 헬싱키의 주요 섬 중 하나에 위치한 코르케아사리 동물원 등이 있습니다. 또한 헬싱키에서 가장 큰 자연 보호 구역인 반한까우풍인셀카(Vanhankaupunginselkä)를 비롯한 많은 자연 보호 구역이 있습니다.

이렇게 하면 이미지나 텍스트를 처리할 수 있고 이미지나 텍스트를 반환할 수도 있는 멀티모달 RAG 애플리케이션을 갖게 됩니다.
깃허브](https://github.com/stephen37/Milvus_demo/tree/main/multimodal_milvus_clip)에서 코드에 액세스하고, 디스코드에서 자유롭게 질문하고, 깃허브에서 별을 주시면 됩니다.

계속 읽기

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.