




Riduzione della dimensionalità: Semplificare i dati complessi per facilitare l'analisi
TL;DR: La riduzione della dimensionalità è un processo utilizzato nella scienza dei dati e nell'apprendimento automatico per ridurre il numero di variabili, o "dimensioni", in un set di dati, conservando il maggior numero possibile di informazioni rilevanti. Questa riduzione semplifica l'analisi, la visualizzazione e l'elaborazione dei dati, soprattutto nel caso di insiemi di dati altamente dimensionali. Tecniche come la Principal Component Analysis (PCA) e la t-Distributed Stochastic Neighbor Embedding (t-SNE) identificano modelli e relazioni all'interno dei dati, proiettandoli su un numero inferiore di dimensioni. Scartando le caratteristiche meno significative, la riduzione della dimensionalità contribuisce a migliorare l'efficienza computazionale e a ridurre l'overfitting, rendendola essenziale per la gestione di dati complessi, in particolare in campi come l'analisi di immagini e testi.
Riduzione della dimensionalità: Semplificare i dati complessi per facilitare l'analisi
La Riduzione della dimensionalità semplifica un set di dati riducendo il numero di variabili o caratteristiche in ingresso, pur mantenendo le informazioni importanti. Svolge un ruolo fondamentale nella scienza dei dati e nell'apprendimento automatico. Rende più gestibile il lavoro con grandi insiemi di dati, migliora le prestazioni dei modelli e risparmia preziose risorse computazionali.
Immaginate di avere un foglio di calcolo grande e complesso, con molte colonne di dati. Se alcune di queste colonne non sono utili o devono essere chiarite per l'analisi, la riduzione della dimensionalità le riduce per facilitare il riconoscimento dei modelli.
La maledizione della dimensionalità
La maledizione della dimensionalità si riferisce ai problemi che sorgono quando si analizzano e organizzano i dati in spazi ad alta dimensionalità. Quando il numero di caratteristiche (o dimensioni) aumenta, il volume dello spazio si espande così rapidamente che i dati disponibili diventano scarsi. Questa scarsità rende difficile per gli algoritmi trovare modelli significativi, rendendo l'analisi dei dati inefficiente e inaffidabile.
Per capire l'impatto, immaginate di cercare di misurare la distanza tra punti in uno spazio unidimensionale, come una linea retta. I punti sono abbastanza vicini da poter essere misurati facilmente. Se si espande la misura a due dimensioni, come un foglio di carta piatto, i punti si estendono ulteriormente. Se si passa a tre dimensioni, come una stanza, i punti si allargano ancora di più. Con l'aumentare delle dimensioni, i punti diventano così distanti da sembrare quasi isolati e il calcolo della distanza diventa meno utile. Questo accade nei dati ad alta dimensionalità, dove le comuni tecniche di analisi dei dati possono non funzionare efficacemente perché le relazioni tra i punti di dati si diluiscono, come mostrato nella figura.
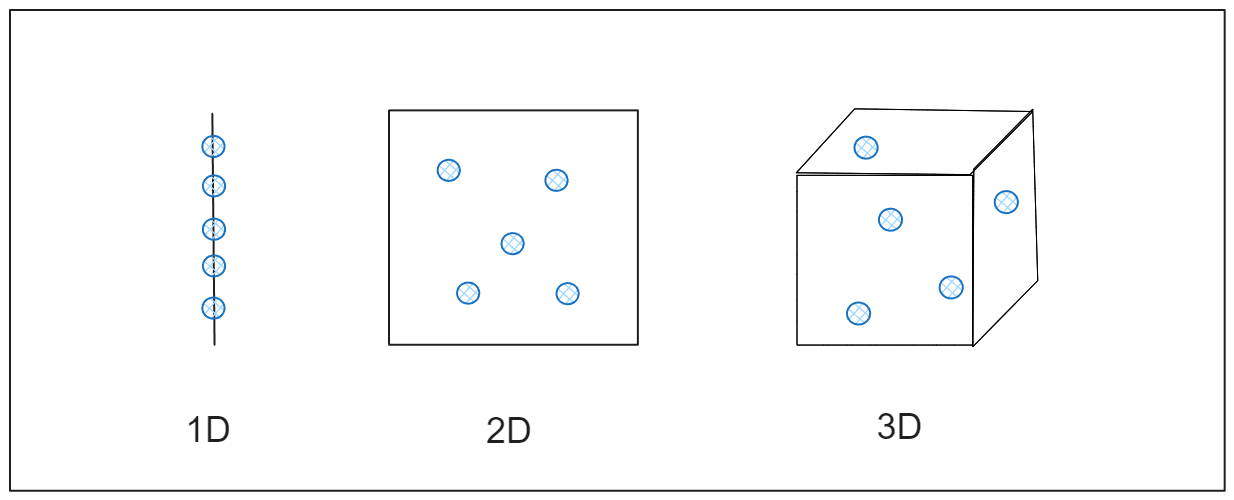 Figura- Come i dati si espandono attraverso le dimensioni.png
Figura- Come i dati si espandono attraverso le dimensioni.png
Figura: Come i dati si espandono attraverso le dimensioni
Una semplice analogia è la ricerca di amici in un parco. Se voi e i vostri amici siete sparsi in un piccolo parco, potete localizzarvi rapidamente. Ma immaginate che il parco cresca fino a raggiungere le dimensioni di un'enorme città. Ora, anche con lo stesso numero di amici, trovarne uno diventa difficile perché tutti sono troppo distanti. Allo stesso modo, negli spazi ad alta dimensionalità, i punti di dati si disperdono, rendendo difficile per gli algoritmi organizzarli o analizzarli in modo efficiente.
Tecniche chiave di riduzione della dimensionalità
Sebbene esistano diverse [strategie di riduzione della dimensionalità] (https://zilliz.com/learn/streamlining-data-strategies-for-reducing-dimensionality), esse possono essere classificate a grandi linee in due tipi principali: Selezione delle caratteristiche ed estrazione delle caratteristiche. Entrambi i metodi mirano a semplificare i dati, ma in modi diversi.
Selezione delle caratteristiche
La selezione delle caratteristiche riduce la dimensionalità selezionando un sottoinsieme delle caratteristiche più rilevanti dal set di dati originale. Invece di trasformare i dati, questo approccio mantiene le caratteristiche così come sono, ma elimina quelle che non contribuiscono in modo significativo all'analisi o alle prestazioni del modello. L'obiettivo è rimuovere le caratteristiche ridondanti o irrilevanti per rendere il dataset più semplice e facile da lavorare.
Esistono tre metodi comuni utilizzati per la selezione delle caratteristiche:
Metodi di filtro: Utilizzano test statistici per classificare le caratteristiche in base alla loro importanza. Tra gli esempi vi sono i punteggi di correlazione, il guadagno di informazioni e i test chi-quadro. Sono semplici e funzionano indipendentemente dal modello di apprendimento automatico.
Metodi Wrapper: Valutano diversi sottoinsiemi di caratteristiche e utilizzano le prestazioni del modello per determinare la combinazione migliore. Sebbene siano più accurati, possono essere computazionalmente costosi. Tecniche come l'eliminazione ricorsiva delle caratteristiche (RFE), la selezione in avanti e l'eliminazione all'indietro rientrano in questa categoria.
Metodi integrati**: Queste tecniche integrano la selezione delle caratteristiche nel processo di addestramento del modello. Modelli come gli alberi decisionali, la regressione Lasso e la regressione ridge identificano automaticamente le caratteristiche importanti come parte del loro addestramento.
Estrazione di caratteristiche
L'estrazione delle caratteristiche trasforma le caratteristiche originali in uno spazio meno dimensionale, creando nuove caratteristiche che catturano ancora le informazioni essenziali. Questo approccio è utile quando si vogliono comprimere i dati mantenendo le relazioni significative tra le caratteristiche. A differenza della selezione delle caratteristiche, l'estrazione delle caratteristiche crea rappresentazioni completamente nuove dei dati.
Le tecniche più diffuse sono l'Analisi delle componenti principali (PCA), l'Embedding stocastico dei vicini t-distribuito (t-SNE) e l'Analisi discriminante lineare (LDA). Discutiamole in dettaglio.
Analisi delle componenti principali (PCA)
L'analisi delle componenti principali (PCA) è una tecnica popolare utilizzata per la riduzione della dimensionalità. Il suo scopo principale è quello di semplificare un ampio insieme di variabili in un insieme più piccolo che catturi comunque la maggior parte delle informazioni presenti nei dati originali.
Per capire la PCA in modo semplice, si pensi a un set di dati come a un oggetto multidimensionale, come una nuvola di punti nello spazio. La PCA individua le direzioni (o assi) in cui i dati variano maggiormente e proietta i dati su questi nuovi assi. Il primo asse, chiamato componente principale, cattura la maggiore varianza (o diffusione) dei dati. Il secondo asse cattura la varianza successiva e così via. Concentrandosi solo sulle prime componenti, la PCA riduce il numero di dimensioni mantenendo intatta la struttura principale dei dati.
I diagrammi seguenti mostrano come la PCA agisce per semplificare i dati. A sinistra, c'è un grafico a dispersione di punti distribuiti in due direzioni. La PCA individua la direzione principale in cui i dati variano maggiormente, indicata dalla freccia nera. Il lato destro mostra l'appiattimento dei dati lungo questa direzione.
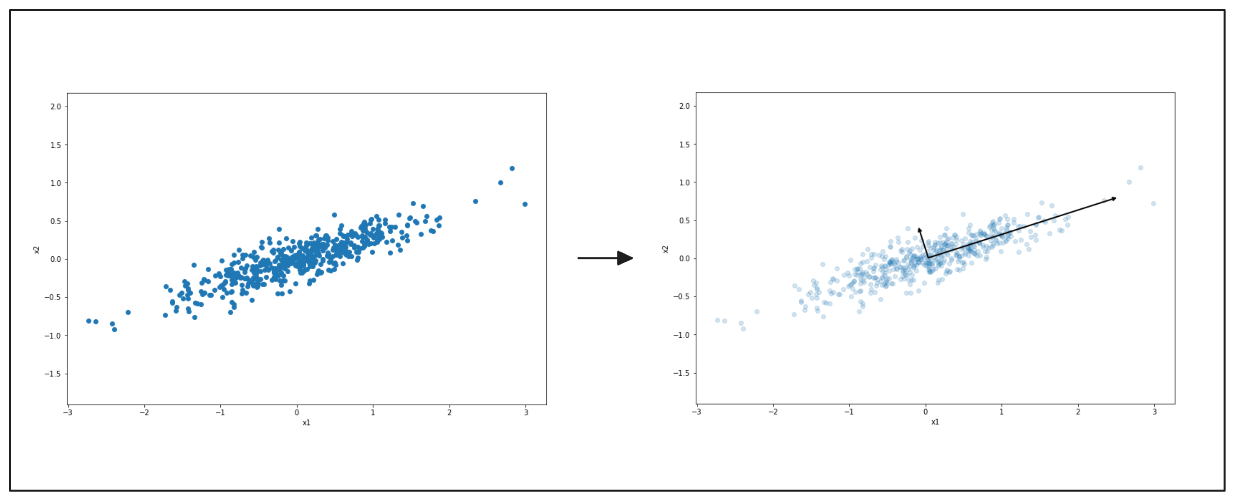 Figura- PCA che evidenzia la direzione principale della variazione dei dati..png
Figura- PCA che evidenzia la direzione principale della variazione dei dati..png
Figura: PCA che evidenzia la direzione principale della variazione dei dati.
Anche in questo caso, a sinistra, si vedono i dati distribuiti in due dimensioni. La freccia nera indica la direzione principale della variazione. A destra, i dati vengono compressi su questa linea, riducendoli a una forma più semplice. Questo processo rende i dati più facili da lavorare, pur mantenendo i modelli principali.
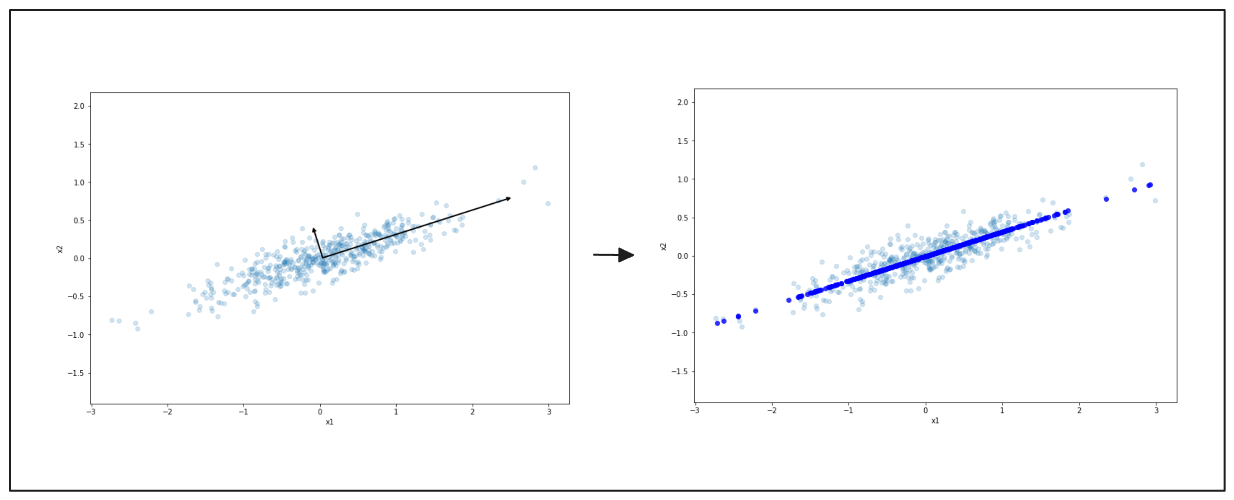 Figura- Rappresentazione semplificata dei dati con PCA.png
Figura- Rappresentazione semplificata dei dati con PCA.png
Figura: Rappresentazione semplificata dei dati con PCA
Pro dell'utilizzo della PCA
Riduzione della complessità: La semplificazione di insiemi di dati con molte variabili rende l'analisi più rapida ed efficiente.
Elimina il rumore**: La PCA filtra il rumore e le informazioni irrilevanti mantenendo le componenti con la maggiore varianza.
Migliora la visualizzazione**: La PCA aiuta a visualizzare i dati ad alta densità in due o tre dimensioni, rivelando modelli che altrimenti potrebbero essere nascosti.
I Cons dell'uso della PCA
Perdita di informazioni**: Alcuni dati possono essere persi durante la riduzione della dimensionalità, influenzando le prestazioni del modello.
Difficoltà di interpretazione: Le nuove caratteristiche create dalla PCA sono combinazioni delle caratteristiche originali, il che le rende difficili da interpretare in modo significativo.
Presuppone la linearità**: La PCA funziona meglio quando le relazioni tra le variabili sono lineari, il che potrebbe non essere sempre vero.
Applicazioni pratiche
Compressione di immagini: Riduce le dimensioni dei file di immagine mantenendo le caratteristiche visive principali.
Finanza**: Semplifica insiemi di dati complessi per identificare modelli nei movimenti dei prezzi delle azioni.
Genetica: Analizza grandi insiemi di dati genomici per scoprire strutture di dati significative.
Versatilità: Utile per semplificare e interpretare dati ad alta dimensionalità in vari campi.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
t-Distributed Stochastic Neighbor Embedding (t-SNE) visualizza i dati ad alta densità. Il t-SNE è ampiamente apprezzato per la sua capacità di mantenere le relazioni locali tra i punti di dati, che aiutano a rivelare la struttura sottostante del set di dati. Questo metodo è più adatto per i set di dati nello spazio 3D.
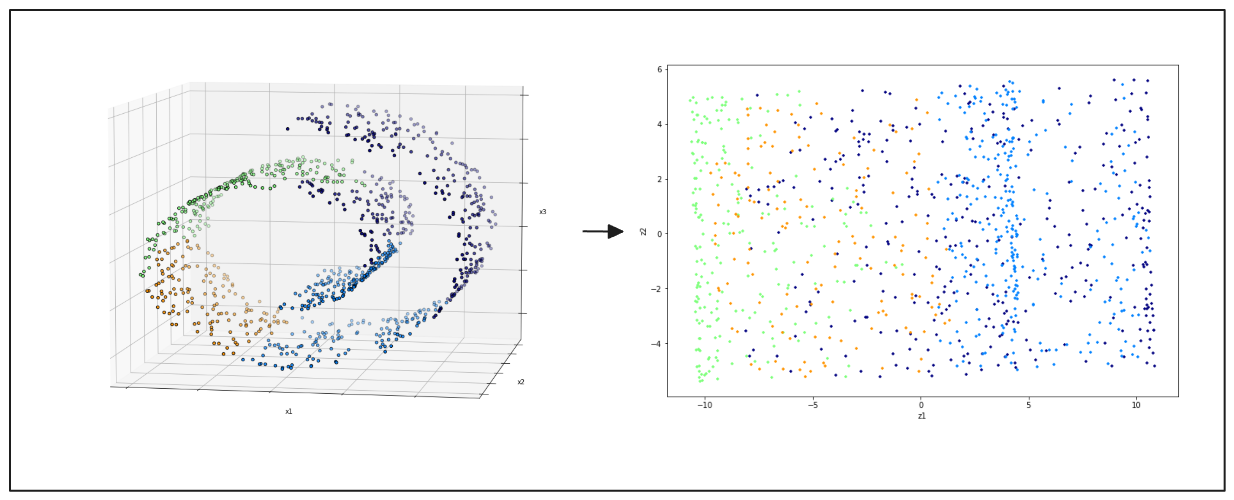 Figura- a sinistra- punti di dati swiss roll 3D, a destra- risultato della proiezione 2D da PCA.png
Figura- a sinistra- punti di dati swiss roll 3D, a destra- risultato della proiezione 2D da PCA.png
Figura: sinistra: punti di dati 3D di swiss roll, destra: risultato della proiezione 2D da PCA
Pro dell'uso di t-SNE
Preserva la struttura locale: t-SNE eccelle nel mantenere vicini i punti di dati nello spazio a bassa dimensione, rendendolo efficace per la visualizzazione dei cluster.
Utile per i dati complessi**: È particolarmente adatto a gestire relazioni non lineari e a esplorare modelli intricati nei dati.
Ottimo per la visualizzazione**: t-SNE produce diagrammi di dispersione visivamente intuitivi e accattivanti che aiutano a comprendere la disposizione dei dati.
I vantaggi dell'uso di t-SNE
Intensivo dal punto di vista computazionale: L'esecuzione di t-SNE può risultare lenta e dispendiosa in termini di risorse, soprattutto per grandi insiemi di dati.
Richiede la regolazione dei parametri**: Parametri come la perplessità e il tasso di apprendimento devono essere impostati con attenzione e i risultati possono variare significativamente in base a queste impostazioni.
Disturba la struttura globale**: Sebbene t-SNE preservi bene le relazioni locali, può distorcere la struttura globale dei dati e renderlo meno utile per comprendere le relazioni su larga scala.
Applicazioni pratiche
Visualizzazione di dati ad alta dimensione: Utile per esplorare le strutture dei cluster.
Riconoscimento delle immagini**: Visualizza la distribuzione delle caratteristiche dell'immagine.
Elaborazione del linguaggio naturale (NLP): Esplora le incorporazioni di parole.
Genomica: Identifica cluster di dati genetici significativi.
Popolarità: Ampiamente utilizzato dagli scienziati dei dati per ottenere approfondimenti visivi, nonostante le limitazioni.
Analisi discriminante lineare (LDA)
A differenza della PCA, la LDA mira a massimizzare la separazione tra le diverse classi nei dati. Lo fa proiettando i dati su uno spazio a bassa dimensione che separa al meglio le categorie in base alle loro etichette.
LDA è comunemente utilizzato in scenari in cui la [classificazione dei dati] (https://zilliz.com/glossary/classification) è l'obiettivo principale. È particolarmente utile quando si ha a che fare con insiemi di dati che hanno chiari confini di classe. Alcune applicazioni pratiche includono il riconoscimento dei volti, la diagnosi medica e la classificazione dei testi.
In che modo LDA si differenzia da PCA?
Obiettivo: LDA si concentra sulla massimizzazione della separabilità delle classi, mentre PCA mira a catturare la massima varianza dei dati senza considerare le etichette delle classi.
Supervisionata vs. non supervisionata: LDA è una tecnica supervisionata che utilizza le etichette di classe nei suoi calcoli. La PCA, invece, non è supervisionata e non utilizza alcuna informazione sulle etichette.
Varianza dei dati: LDA riduce le dimensioni trovando gli assi che massimizzano la distanza tra le medie delle diverse classi e riducono al minimo lo spread all'interno di ciascuna classe. La PCA non considera le informazioni sulle classi e il suo unico obiettivo è quello di ridurre la ridondanza dei dati.
Altre tecniche e metodi emergenti
Oltre alle tradizionali tecniche di riduzione della dimensionalità come PCA, t-SNE e LDA, diversi altri metodi e tendenze emergenti si stanno affermando nell'analisi dei dati.
Autoencoder
Gli autoencoder sono reti neurali utilizzate per l'apprendimento non supervisionato che hanno lo scopo di comprimere i dati in una rappresentazione a bassa dimensione e poi ricostruirli nella loro forma originale. La rete è composta da un codificatore che riduce la dimensionalità e da un decodificatore che ricostruisce l'input dalla rappresentazione compressa. Gli autoencoder sono utili per gestire relazioni non lineari nei dati e possono apprendere rappresentazioni complesse delle caratteristiche.
Analisi delle componenti indipendenti (ICA)
L'analisi delle componenti indipendenti (ICA) è una tecnica computazionale per separare un segnale multivariato in componenti additive e indipendenti. A differenza della PCA, che si concentra sulla varianza, l'ICA cerca fonti statisticamente indipendenti. Questo metodo è spesso utilizzato in applicazioni come la separazione cieca delle sorgenti, ad esempio per isolare le diverse sorgenti audio da una registrazione mista.
Approssimazione e proiezione uniformi del manifold (UMAP)
L'approssimazione e la proiezione uniformi del manifold (UMAP) è una tecnica relativamente nuova per la riduzione della dimensionalità che preserva le strutture locali e globali dei dati. Si basa sull'apprendimento dei manifold e mira a mantenere le relazioni tra i punti dei dati durante il processo di riduzione. UMAP è più veloce e spesso produce visualizzazioni migliori rispetto a t-SNE.
Vantaggi della riduzione della dimensionalità
La riduzione della dimensionalità offre diversi vantaggi chiave che migliorano l'analisi di insiemi di dati complessi:
Modelli semplificati: Un minor numero di caratteristiche porta a modelli più semplici, più facili da addestrare e analizzare, il che può essere cruciale per le applicazioni sensibili ai tempi.
Riduzione dei requisiti di archiviazione e calcolo: La gestione di dati meno dimensionali si traduce in una minore quantità di spazio di archiviazione e in tempi di elaborazione più rapidi, il che può ridurre i costi operativi, soprattutto nel caso di grandi insiemi di dati.
Migliora le prestazioni dei modelli**: Considerando le caratteristiche più significative, i modelli possono diventare più accurati e robusti, poiché è meno probabile che siano influenzati da dati irrilevanti.
Migliora l'interpretabilità**: La riduzione delle dimensioni può contribuire a evidenziare le relazioni essenziali nei dati che aiutano gli stakeholder a comprendere le decisioni del modello e i modelli sottostanti.
Facilita la visualizzazione dei dati**: La trasformazione di dati altamente dimensionali in due o tre dimensioni consente di ottenere rappresentazioni visive più chiare, aiutando a scoprire intuizioni che potrebbero non essere evidenti in dimensioni superiori.
Aiuta a ridurre il rumore**: Rimuovendo le dimensioni meno importanti, la riduzione della dimensionalità può ridurre la quantità di rumore, dando luogo a set di dati più puliti che contribuiscono ad analisi più affidabili.
Supporto per una migliore ingegnerizzazione delle caratteristiche**: Il processo può aiutare a identificare le caratteristiche di maggiore impatto, offrendo l'opportunità di creare caratteristiche migliorate che possono portare a migliori prestazioni del modello.
Consente una prototipazione più rapida**: Con un minor numero di dimensioni da considerare, i data scientist possono iterare rapidamente lo sviluppo del modello per testarlo e perfezionarlo rapidamente.
Sfide nella riduzione della dimensionalità
Le tecniche di riduzione della dimensionalità comportano diverse sfide che devono essere attentamente considerate:
Rischio di perdere informazioni importanti: La riduzione delle dimensioni può inavvertitamente scartare caratteristiche essenziali, il che può influire negativamente sulle prestazioni del modello e portare a un'interpretazione errata dei risultati.
Scegliere la tecnica giusta: L'efficacia dei metodi di riduzione della dimensionalità varia a seconda della natura del set di dati e degli obiettivi analitici specifici. Questa variabilità rende fondamentale la comprensione dei punti di forza e dei limiti di ciascuna tecnica per evitare risultati inefficaci.
Costo computazionale: Tecniche come t-SNE possono richiedere molte risorse e sono meno praticabili per grandi insiemi di dati. I requisiti di tempo e memoria possono limitare significativamente la loro applicabilità in scenari sensibili al fattore tempo.
Bilanciamento tra riduzione e accuratezza: Raggiungere il giusto livello di riduzione della dimensionalità, assicurando al contempo che il modello conservi informazioni sufficienti per ottenere previsioni accurate, è una sfida costante. Una riduzione eccessiva può semplificare troppo i dati, compromettendo la capacità del modello di catturare la complessità necessaria.
Applicazioni della riduzione della dimensionalità in vari settori industriali
Le tecniche di riduzione della dimensionalità trovano applicazione in diversi settori, per migliorare l'analisi dei dati e le prestazioni dei modelli. Ecco alcuni scenari pratici in cui questi metodi sono comunemente utilizzati:
Elaborazione delle immagini: In campi come la computer vision, la riduzione della dimensionalità aiuta a comprimere i dati delle immagini preservando le caratteristiche essenziali. Ad esempio, nel riconoscimento facciale, la PCA può ridurre migliaia di valori di pixel a caratteristiche più piccole, accelerando l'elaborazione senza perdere dettagli critici. Analogamente, nell'imaging medico, la riduzione della dimensionalità evidenzia le aree importanti nelle scansioni MRI per un'analisi più rapida.
Elaborazione del linguaggio naturale: La riduzione della dimensionalità viene utilizzata per semplificare i dati testuali ad alta dimensionalità, come ad esempio le incorporazioni di parole. Metodi come t-SNE aiutano a visualizzare le relazioni e i cluster di parole, favorendo l'analisi del sentiment e la modellazione dei temi.
Genomica: In bioinformatica, le tecniche di riduzione della dimensionalità sono essenziali per l'analisi dei dati genetici, dove il numero di variabili (geni) può essere estremamente elevato. La riduzione delle dimensioni aiuta a identificare i marcatori genetici chiave legati alle malattie.
Finanza: La riduzione della dimensionalità aiuta nella gestione del rischio e nell'ottimizzazione del portafoglio, semplificando grandi insiemi di dati di indicatori finanziari. Gli analisti possono scegliere le caratteristiche più rilevanti che influenzano il comportamento del mercato.
Sistemi di raccomandazione: Nel filtraggio collaborativo e basato sui contenuti, la riduzione della dimensionalità aiuta a creare algoritmi di raccomandazione più efficienti, identificando gli schemi sottostanti nelle preferenze degli utenti e nelle caratteristiche degli articoli.
Assistenza sanitaria**: L'analisi dei dati dei pazienti comporta spesso insiemi di dati ad alta densità. La riduzione della dimensionalità aiuta a identificare i fattori significativi che influenzano i risultati dei pazienti, migliorando la modellazione predittiva della progressione della malattia.
Analisi di marketing**: Nel marketing, la comprensione del comportamento dei clienti è fondamentale. La riduzione della dimensionalità consente alle aziende di segmentare facilmente i clienti riducendo la complessità dei dati dei clienti, con conseguenti strategie di marketing mirate.
Produzione e controllo qualità**: Nelle applicazioni industriali, la riduzione della dimensionalità aiuta ad analizzare i dati dei sensori delle macchine per identificare schemi e anomalie, migliorando il controllo della qualità e la manutenzione predittiva.
Come la riduzione della dimensionalità migliora le prestazioni dei database vettoriali?
La riduzione della dimensionalità migliora in modo significativo le prestazioni di database vettoriali come Milvus (creato dagli ingegneri di Zilliz), progettato per gestire dati non strutturati su larga scala e le loro rappresentazioni vettoriali ad alta densità. Ecco come sono interconnessi:
Memorizzazione efficiente dei dati: Milvus può memorizzare dati vettoriali ad alta dimensione generati da modelli di apprendimento automatico. L'applicazione di tecniche di riduzione della dimensionalità, come PCA o t-SNE, aiuta a comprimere questi vettori, riducendo i requisiti di archiviazione e migliorando la velocità di recupero.
Miglioramento delle prestazioni delle query: In un database vettoriale, la ricerca tra i dati ad alta densità può essere molto impegnativa dal punto di vista computazionale. La riduzione della dimensionalità minimizza la dimensionalità dei vettori, accelerando le [ricerche di similarità] (https://zilliz.com/blog/similarity-metrics-for-vector-search) e le [interrogazioni nearest-neighbor] (https://zilliz.com/glossary/anns).
Migliore visualizzazione dei dati: Quando si utilizzano Zilliz o Milvus per l'analisi dei dati, le tecniche di riduzione della dimensionalità possono facilitare la visualizzazione di insiemi di dati complessi. Ciò consente agli utenti di comprendere meglio le distribuzioni dei dati, le relazioni e i modelli all'interno dei dati ad alta dimensionalità memorizzati nel database.
Facilitazione dei flussi di lavoro di apprendimento automatico: Nelle pipeline di apprendimento automatico, la riduzione della dimensionalità può aiutare a semplificare la preelaborazione dei dati. La riduzione della complessità delle caratteristiche in ingresso migliora l'addestramento dei modelli di apprendimento automatico, con conseguente miglioramento delle prestazioni e dell'interpretabilità.
Conclusione
La riduzione della dimensionalità è una tecnica importante nella scienza dei dati e nell'apprendimento automatico che semplifica insiemi di dati complessi preservando le informazioni essenziali. La riduzione del numero di caratteristiche migliora le prestazioni del modello, facilita la visualizzazione e aiuta a semplificare l'analisi dei dati in vari campi. Nonostante le sue sfide, come il rischio di perdere informazioni importanti e la necessità di un'attenta selezione della tecnica, i vantaggi della riduzione della dimensionalità la rendono preziosa per scoprire intuizioni e migliorare l'efficienza dei processi analitici.
Domande frequenti sulla riduzione della dimensionalità
- Che cos'è la riduzione della dimensionalità?
La riduzione della dimensionalità è una tecnica utilizzata per ridurre il numero di caratteristiche o dimensioni in un set di dati, conservando il maggior numero possibile di informazioni rilevanti. Questa semplificazione facilita l'analisi, la visualizzazione e la modellazione di dati complessi.
- Perché la riduzione della dimensionalità è importante nella scienza dei dati?
Aiuta a migliorare le prestazioni dei modelli, riduce i requisiti di archiviazione e di calcolo, migliora la visualizzazione dei dati e semplifica l'interpretazione dei modelli, rendendola essenziale per un'analisi efficiente dei dati in varie applicazioni.
- Quali sono alcune tecniche comuni per la riduzione della dimensionalità?
Le tecniche più comuni includono l'analisi delle componenti principali (PCA), l'incorporazione t-distribuita dei vicini stocastici (t-SNE), l'analisi lineare discriminante (LDA), i metodi di selezione delle caratteristiche e le tecniche emergenti come gli autoencoder e l'UMAP.
- Quali sono le sfide associate alla riduzione della dimensionalità?
Le sfide includono il rischio di perdere informazioni importanti, la difficoltà di scegliere la tecnica giusta per specifici set di dati, i costi computazionali di alcuni metodi e il bilanciamento tra riduzione della dimensionalità e accuratezza del modello.
- In che modo la riduzione della dimensionalità avvantaggia i database vettoriali come Milvus?
La riduzione della dimensionalità migliora le prestazioni dei database vettoriali ottimizzando l'archiviazione dei dati, migliorando le prestazioni delle query, facilitando la visualizzazione dei dati e semplificando i flussi di lavoro dell'apprendimento automatico.
Risorse correlate
- La maledizione della dimensionalità
- Tecniche chiave di riduzione della dimensionalità
- Altre tecniche e metodi emergenti
- Vantaggi della riduzione della dimensionalità
- Sfide nella riduzione della dimensionalità
- Applicazioni della riduzione della dimensionalità in vari settori industriali
- Come la riduzione della dimensionalità migliora le prestazioni dei database vettoriali?
- Conclusione
- Domande frequenti sulla riduzione della dimensionalità
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente