




Capire lo sharding del database

Capire lo sharding del database
I siti web e le applicazioni moderne fanno molto affidamento sulle tecnologie dei database per gestire le richieste di lettura e scrittura da parte di più utenti. Tuttavia, quando la popolarità di un'applicazione aumenta, il numero di utenti cresce e diventa difficile fornire un'esperienza ottimale ai clienti a causa dei frequenti crash del database.
Quindi, come possono gli sviluppatori scalare i loro database per far fronte all'aumento della domanda? Anche se la risposta può variare a seconda del caso d'uso, lo sharding dei database è un metodo semplice ed economico. È facile da implementare e offre miglioramenti significativi delle prestazioni.
Nonostante la sua semplicità, lo sharding dei database può essere un concetto confuso. Questo post ne spiega il significato, le tecniche di implementazione, le alternative, i vantaggi e le sfide e i casi d'uso per aiutarvi a capire quando e come applicare il metodo di sharding più adatto.
Che cos'è lo sharding dei database?
Lo sharding dei database suddivide un ampio database in parti più piccole, chiamate shard, e le distribuisce su più macchine. Ogni macchina utilizza la stessa tecnologia, lavorando in parallelo per elaborare grandi volumi di dati.
È uno dei tanti metodi per accelerare l'elaborazione dei dati e garantire [l'alta disponibilità] (https://zilliz.com/learn/ensuring-high-availability-of-vector-databases). Se una singola macchina o un server di database si guasta a causa del sovraccarico di richieste, gli altri server possono comunque elaborare le richieste di lettura e scrittura, mantenendo un'esperienza utente fluida.
Tuttavia, lo sharding funziona solo finché i dati sono disponibili e accessibili. Permette agli sviluppatori di distribuire organicamente il carico di lavoro e di ridurre la latenza.
La replica e il partizionamento sono altre tecniche per prevenire i tempi di inattività. Questi metodi sono più appropriati per i database più piccoli. La replica comporta la copia di un intero database su più server, mentre il partizionamento scompone un database e lo archivia in un'unica macchina. Le sezioni successive illustreranno questi approcci in modo più dettagliato.
Come funziona lo sharding dei database?
Lo sharding è una forma di scalabilità orizzontale in cui gli sviluppatori installano nodi o server aggiuntivi per memorizzare più partizioni di dati. Ogni partizione diventa una tabella indipendente che condivide lo stesso schema del database originale. Tuttavia, le informazioni contenute in ogni shard sono uniche e gli sviluppatori memorizzano i singoli pezzi su più computer, chiamati nodi.
Ad esempio, la tabella seguente illustra un singolo database che rappresenta le informazioni sui clienti e sugli articoli che hanno acquistato.
| ID cliente | Nome | Articolo acquistato |
| 10001 | A | Camicia |
| 10002 | B | Berretto |
| 10003 | C | Camicia |
| 10004 | D | Scarpe |
Uno sviluppatore può usare lo sharding del database per dividere il database in partizioni più piccole, chiamate shard logici, su macchine separate o shard fisici.
Server 1
| Identità del cliente | Nome | Importo acquistato |
| 10001 | A | Camicia |
| 10002 | B | Berretto |
Server 2
| ID cliente | Nome | Articolo acquistato |
| 10003 | C | Camicia |
| 10004 | D | Scarpe |
Lo sharding funziona su un'architettura shared-nothing, in cui un singolo nodo di un cluster di computer elabora le richieste degli utenti in modo indipendente. Quando un utente cerca di accedere al database, solo lo shard che contiene le informazioni dell'utente si attiva ed elabora la richiesta in arrivo.
Gli sviluppatori dividono i dati in shard logici utilizzando una chiave di shard. Possono selezionare la chiave in base a una colonna che organizza i dati in gruppi o crearne una nuova. Le sezioni seguenti spiegano come funziona una chiave di shard e aiutano a sviluppare gruppi di dati per uno sharding efficiente.
Metodi di sharding
Gli sviluppatori possono implementare diverse tecniche di sharding in base al caso d'uso e alla natura dei dati da elaborare. I metodi più diffusi includono lo sharding basato su range, lo sharding con hashed, lo sharding di directory e il geo-sharding.
Sharding basato sull'intervallo
Lo sharding dinamico o basato sull'intervallo divide un database in shard in base a uno specifico intervallo di valori. Il diagramma seguente illustra come uno sviluppatore può dividere una tabella in shard utilizzando un intervallo di prezzi.
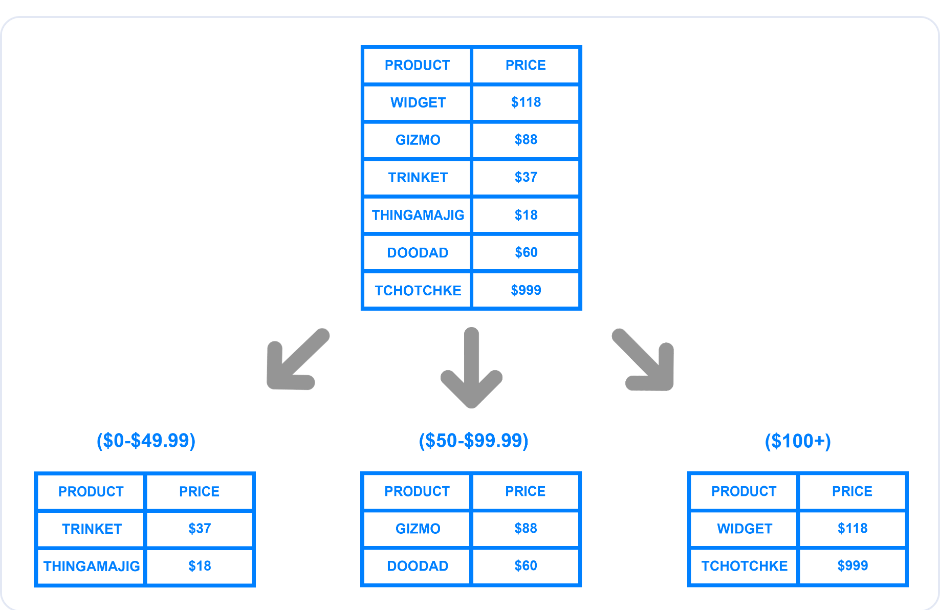 Sharding basato sul prezzo.png
Sharding basato sul prezzo.png
Sharding basato su un intervallo di prezzo
L'esempio mostra tre shard logici creati utilizzando gli intervalli di prezzo. Lo sviluppatore può assegnare a ciascun chunk una chiave di shard unica e memorizzarli su shard o macchine fisiche separate. Quando si scrive un record nel database, il sistema determina lo shard appropriato a cui appartengono i dati in base alla fascia di prezzo e lo aggiorna di conseguenza.
Sebbene l'implementazione dello sharding dinamico sia semplice, può sovraccaricare un particolare shard se contiene più record di altri. Nell'esempio precedente, se un maggior numero di clienti acquista articoli con un prezzo superiore a 100 dollari, il volume dei dati nel terzo shard sarà superiore a quello degli altri.
La distribuzione non uniforme può vanificare lo scopo dello sharding, poiché solo un singolo shard conterrà la maggior parte dei dati, causando un rallentamento del sistema. Inoltre, il metodo richiede una tabella di lookup che memorizza la chiave unica dello shard e gli intervalli corrispondenti.
Sharding con hash
Lo sharding Hashed assegna una chiave hash a ogni record in base a una colonna specifica. Gli sviluppatori generano le chiavi hash utilizzando una funzione hash che prende in input i valori della colonna. Possono dividere i dati determinando i record che appartengono a una chiave o a un valore hash corrispondente.
Ad esempio, gli sviluppatori possono selezionare una colonna e utilizzare i suoi valori per generare valori hash. Questi valori possono servire come chiave di shard per ogni chunk e gli sviluppatori possono memorizzarli su macchine diverse. Il diagramma seguente illustra il processo.
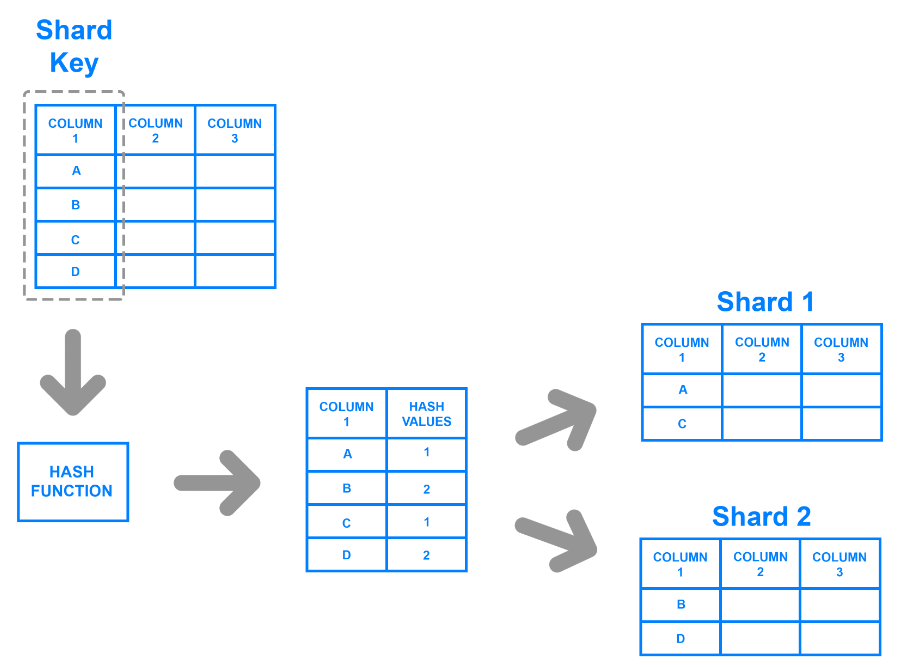 Hashed sharding.png
Hashed sharding.png
L'hashed sharding supera il problema della distribuzione non uniforme, poiché la funzione o l'algoritmo di hashing non ha bisogno di una chiave di shard definita dall'utente per partizionare i dati. Tuttavia, diventa difficile interrogare i dati dai singoli shard, poiché le chiavi non raggruppano i dati in base a criteri significativi. Un algoritmo genera casualmente i valori di hash e divide i dati in modo ad hoc.
Ad esempio, nello sharding basato sul range, le chiavi riflettono gli intervalli di un particolare valore nella tabella e si riferiscono alla struttura dei dati in modo più significativo. L'interrogazione di sharding basati su intervalli di valori è più rapida rispetto all'interrogazione di dati basati su chiavi hash.
Inoltre, l'aggiunta di altri shard o l'aggiornamento dei sistemi richiede allo sviluppatore di rieseguire l'intero algoritmo di hashing su tutti i record. Questo processo è necessario per bilanciare il volume dei dati tra le macchine, ma può comportare tempi di inattività e risorse di calcolo significativi.
Sharding delle directory
Lo sharding delle directory è più flessibile dei metodi discussi in precedenza. Divide i dati in base ai valori di una particolare colonna e utilizza una tabella di ricerca per determinare a quale shard appartiene un record.
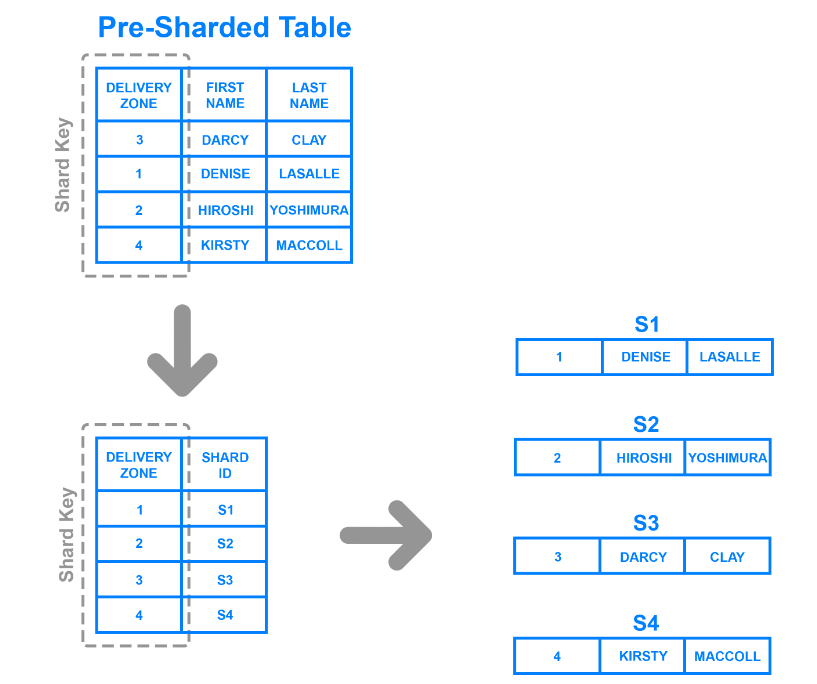 Sharding delle directory basato sulla zona di consegna.png
Sharding delle directory basato sulla zona di consegna.png
Directory sharding basato sulla zona di consegna
Ad esempio, l'illustrazione mostra come utilizzare la colonna Zona di consegna come chiave di sharding e suddividere i dati in base alle zone di appartenenza di un cliente. Il metodo crea quattro shard distinti, poiché la tabella ha quattro zone.
A differenza dello sharding basato su intervalli, le partizioni dei dati sono più versatili, poiché non devono aderire a intervalli di valori rigidi. Inoltre, consentono agli sviluppatori di aggiornare gli shard più rapidamente, poiché non devono generare algoritmicamente le chiavi per tutti i valori di una particolare colonna.
Tuttavia, questa tecnica richiede una tabella di ricerca per rispondere alle richieste in arrivo, rallentando la velocità di elaborazione. Inoltre, la selezione di una colonna che dà luogo a un numero elevato di shard può aumentare significativamente le dimensioni della tabella di ricerca e la latenza.
Selezione di una chiave shard
Uno sharding efficiente del database richiede agli sviluppatori di determinare una chiave di sharding appropriata per garantire una distribuzione equa dei dati tra gli shard. In una distribuzione non uniforme, shard specifici possono diventare hotspot di dati che contengono più dati di altri.
La chiave di shard deve anche semplificare il processo di interrogazione per aumentare la velocità di elaborazione e prevenire i tempi di inattività. Inoltre, la determinazione di una chiave shard appropriata si basa sulla selezione della colonna giusta.
L'elenco seguente evidenzia tre fattori significativi che gli sviluppatori possono prendere in considerazione quando scelgono la colonna più adatta per generare la chiave di shard.
- Cardinalità: ** La cardinalità specifica il numero massimo di shard che uno sviluppatore può creare in base a valori distinti in una colonna. Ad esempio, selezionando una colonna contenente tre valori distinti si otterranno tre shard. Lo sharding basato su directory è utile quando la cardinalità di una colonna è bassa.
- La frequenza si riferisce alla percentuale di dati appartenenti a una particolare chiave di shard. Ad esempio, nello sharding basato sui prezzi, intervalli di prezzo specifici possono contenere circa l'80% dei record totali, dando luogo a un hotspot di dati.
- Il volume dei dati negli shard dinamici cambia al variare della domanda di un'applicazione. Ad esempio, man mano che l'applicazione diventa popolare, i dati demografici degli utenti possono cambiare e le iscrizioni da parte di clienti di età compresa tra i 20 e i 25 anni possono aumentare. Lo sharding basato sull'età può dare origine a un hotspot di dati, poiché nello shard corrispondente alla fascia di età 20-25 anni saranno presenti più dati.
Per garantire un efficace sharding del database, gli sviluppatori devono considerare la cardinalità e la frequenza di una chiave di shard e determinare se essa darà luogo a shard dinamici.
Confronto con le alternative
Lo sharding dei database è uno dei metodi per scalare i database. Altri metodi includono il vertical scaling, la replica e il partizionamento. La comprensione delle differenze tra questi metodi e lo sharding aiuterà gli sviluppatori a utilizzare il metodo di scaling corretto per scenari specifici.
Scalatura verticale
Lo scaling verticale comporta l'aggiornamento della capacità di un server esistente. Gli sviluppatori possono installare CPU aggiuntive, dischi rigidi e altro software per migliorare le prestazioni.
Questo metodo è utile nei casi in cui una singola macchina è sufficiente per gestire le richieste degli utenti e sono necessari solo miglioramenti incrementali per aumentare le prestazioni.
Sebbene sia meno costoso dello sharding, aumenta la capacità del server solo in misura limitata, poiché solo una singola macchina è disponibile per elaborare le richieste degli utenti.
Replica
La replica avviene quando gli sviluppatori creano copie dello stesso database e le archiviano su più computer. Come lo sharding, questo metodo garantisce un'elevata disponibilità, poiché se un computer si guasta, gli altri rimangono attivi.
Sharding e replicazione sono simili in quanto distribuiscono l'elaborazione su più macchine. Tuttavia, lo sharding divide i dati in varie parti, mentre la replica copia l'intero database senza scomporlo.
Lo sharding è più appropriato per i database di grandi dimensioni, mentre la replica richiede server con un'elevata capacità di archiviazione. Il mantenimento e l'aggiornamento di ogni replica su macchine diverse è costoso e richiede tempo.
Partizionamento
Il partizionamento divide un database in più gruppi e li memorizza su un'unica macchina. Questo metodo è adatto quando si vogliono migliorare le prestazioni delle query e le dimensioni del database non sono tali da giustificare la memorizzazione delle partizioni su macchine diverse.
Può aiutare a ottimizzare l'archiviazione dei dati, consentendo agli sviluppatori di partizionare i dati in base alla data e all'ora. Possono spostare record specifici con data e ora più vecchie di una certa soglia in una tabella di archiviazione e utilizzare un'altra tabella per memorizzare i record più recenti.
Vantaggi dello sharding dei database
Lo sharding dei database è una strategia preziosa per una gestione efficiente dei dati. Le aziende che fanno affidamento su un'ampia quantità di dati per il funzionamento dei loro siti web, delle applicazioni e di altri software basati sui dati devono adottare lo sharding per massimizzare i benefici della loro tecnologia di database.
L'elenco che segue illustra in dettaglio alcuni vantaggi che lo sharding offre alle organizzazioni.
Scalabilità:** Suddividendo i dati su più macchine, lo sharding consente alle aziende di scalare i propri sistemi di database in modo più efficiente per supportare carichi di lavoro crescenti.
Minimi tempi di inattività:** Lo sharding garantisce un'elevata disponibilità operando su un'architettura shared-nothing. Questa strategia consente una migliore esperienza utente, poiché il guasto di una macchina non influisce sulle prestazioni delle altre.
Facilità di aggiornamento:** L'implementazione di aggiornamenti delle prestazioni è più efficiente, in quanto gli sviluppatori possono aggiornare separatamente le singole macchine senza spegnere l'intero sistema.
Sfide dello sharding dei database
Sebbene lo sharding offra vantaggi significativi, gli sviluppatori possono affrontare alcune sfide che aumentano la complessità dell'implementazione. L'elenco che segue evidenzia questi problemi con potenziali strategie di mitigazione.
L'incertezza sul volume e sulla varietà dei dati può causare la comparsa di hotspot. Nonostante una chiave shard efficace, la natura dei dati può cambiare, richiedendo agli sviluppatori di selezionare o creare una nuova chiave. Gli sviluppatori devono valutare attentamente l'idoneità dello sharding del database in scenari specifici. È possibile che la replica o lo scaling verticale siano più pratici dello sharding in situazioni diverse.
La gestione di più macchine è complessa, poiché gli sviluppatori devono monitorare costantemente lo stato di salute di ciascun nodo per identificare e risolvere rapidamente i problemi. Sistemi di monitoraggio robusti con meccanismi di allerta in tempo reale possono aiutare a mitigare questi problemi, avvisando i team competenti in caso di guasti ai server.
Costi di manutenzione:** La manutenzione di più server on-premises è costosa e richiede personale aggiuntivo con competenze specifiche per risolvere i problemi durante la manutenzione. Le organizzazioni possono migrare verso infrastruttura cloud per ospitare vari shard e far sì che il fornitore del cloud esegua controlli di manutenzione regolari dietro le quinte.
Casi d'uso dello sharding dei database
Sebbene le sezioni precedenti evidenzino brevemente i casi d'uso in cui lo sharding è vantaggioso, l'elenco seguente categorizza e spiega questi scenari in modo più dettagliato.
I siti di e-commerce con un'ampia base di utenti, le piattaforme di social media, le app di car-hailing e i siti di gioco sono i candidati ideali per lo sharding dei database. Lo sharding può aiutare gli amministratori di questi siti a bilanciare il carico in modo più efficace e a prevenire i tempi di inattività nelle ore di punta.
Per gli utenti che analizzano i big data, lo sharding può contribuire a migliorare la velocità di elaborazione distribuendo il carico su più server.
Un CDN è un gruppo di server distribuiti in diverse località per gestire le richieste degli utenti che si trovano in località geografiche vicine. Gli sviluppatori possono suddividere i database in base alla posizione degli utenti e distribuire i dati su questi server per ottenere tempi di risposta più rapidi.
Domande frequenti sullo sharding dei database
- **Qual è la differenza tra sharding e partizionamento?
Mentre lo sharding e il partizionamento dividono i dati in pezzi più piccoli, lo sharding distribuisce ogni pezzo su diverse macchine o nodi. Al contrario, il partizionamento memorizza ogni chunk all'interno di una singola macchina.
- **Qual è la differenza tra sharding e replica?
La replica copia l'intero database e lo memorizza su macchine diverse. Rispetto allo sharding, che suddivide il database in righe e memorizza ogni pezzo su più server, la replica offre una maggiore disponibilità ma richiede più risorse di calcolo e capacità di archiviazione.
- **Come si sceglie la chiave di sharding corretta?
La scelta di una chiave di shard appropriata richiede agli sviluppatori di determinare la colonna corretta per dividere i dati. Una chiave shard deve avere una cardinalità bassa e una frequenza uguale.
La cardinalità si riferisce al numero massimo di shard possibili in base ai valori delle colonne. Ad esempio, selezionando una colonna che contiene quattro valori distinti si otterranno quattro shard. La frequenza si riferisce alla proporzione di dati che ogni shard contiene.
Inoltre, selezionare o creare shard che rimangano statici durante il ciclo di vita dell'applicazione. Gli shard il cui volume di dati è destinato a cambiare possono dare origine a hotspot, con alcuni shard che ricevono più volume di altri.
- **Quali sono le principali sfide dello sharding dei database?
Lo sharding dei database aumenta l'overhead delle query, poiché gli sviluppatori devono scrivere query per accedere ai dati da più macchine per eseguire l'analisi.
Aumenta anche i costi dell'infrastruttura, poiché le organizzazioni devono mantenere più server e monitorarne lo stato di salute per evitare interruzioni.
Inoltre, l'aggiornamento e il ribilanciamento degli shard è complesso se il volume e la varietà dei dati aumentano. Una tecnica di sharding adatta a una situazione può non essere più pratica in altre.
- **Lo sharding dei database è adatto alle piccole applicazioni?
Sebbene lo sharding dei database sia una tecnica preziosa per migliorare la velocità di elaborazione e il throughput, è inadeguato per le piccole applicazioni. È pratico da implementare solo quando il volume dei dati raggiunge un punto in cui diventa insostenibile mantenere un singolo database su un singolo server.
Risorse correlate
Sebbene gli sviluppatori applichino solitamente lo sharding a insiemi di dati strutturati, le seguenti risorse vi aiuteranno a comprendere il concetto nel contesto di dati non strutturati e database vettoriali:
Sharding, Partitioning e Segmenti - Ottenere il massimo dal database
Distribuzione di database vettoriali in ambienti multi-cloud
Anatomia di un sistema di gestione di database vettoriali nativo per il cloud
Hub delle risorse di intelligenza artificiale generativa | Zilliz
Modelli di intelligenza artificiale più performanti per le vostre applicazioni GenAI
- Che cos'è lo sharding dei database?
- Come funziona lo sharding dei database?
- Metodi di sharding
- Selezione di una chiave shard
- Confronto con le alternative
- Vantaggi dello sharding dei database
- Sfide dello sharding dei database
- Casi d'uso dello sharding dei database
- Domande frequenti sullo sharding dei database
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente