




**Che cos'è una rete neurale convoluzionale? Una guida per ingegneri**

Che cos'è una rete neurale convoluzionale? Una guida per ingegneri
Una Rete neurale convoluzionale (CNN) è un modello di apprendimento profondo adatto a dati visivi come immagini, video e talvolta anche file audio.
Le CNN hanno trasformato campi come la computer vision, l'analisi e l'elaborazione delle immagini](https://www.v7labs.com/blog/image-processing-guide), il rilevamento di oggetti e persino l'elaborazione del linguaggio naturale (NLP).
Le reti neurali tradizionali, come MLP (Multi-Layer Perceptron) o Fully Connected Networks, trattano i dati delle immagini come vettori piatti, il che può essere limitante quando si tratta delle informazioni spaziali presenti nei dati visivi. Ciò può portare a una scarsa accuratezza a causa di ipotesi errate (bias induttivi).
Le CNN risolvono questi problemi preservando la struttura dell'immagine, come la connettività locale e il contenuto dei pixel dei dati dell'immagine, rendendole efficienti nel riconoscimento dei modelli.
Questo post evidenzia i vantaggi delle CNN, ne spiega l'architettura e fornisce un semplice esempio di progettazione di un modello CNN.
Ragioni principali per l'utilizzo di una CNN
Le CNN eccellono nell'estrazione di caratteristiche significative da dati visivi grezzi, superando le reti neurali tradizionali. I motivi per utilizzare una CNN sono:
Condivisione dei parametri Una CNN condivide lo stesso set di parametri in diverse regioni di input, il che è utile per identificare in modo efficiente i modelli nascosti nei dati ad alta dimensionalità.
Le CNN utilizzano la tecnica del pooling e della convoluzione, che riduce significativamente il numero di parametri rispetto alle reti completamente connesse.
Apprendimento gerarchico delle caratteristiche**-Le CNN imitano la struttura gerarchica del sistema visivo umano.
Prestazioni all'avanguardia**-Le CNN superano costantemente le reti neurali tradizionali in compiti quali il rilevamento di oggetti, l'elaborazione di immagini, il riconoscimento vocale e la segmentazione di immagini. Si noti che i recenti progressi nella computer vision hanno introdotto anche [Transformers] convoluzionali e non convoluzionali (https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)).
Vantaggi e svantaggi delle reti neurali convoluzionali
Sebbene le CNN abbiano cambiato il gioco della computer vision, è necessario conoscerne i pro e i contro. Vediamo i vantaggi e gli svantaggi delle CNN:
Rete neurale convoluzionale Vantaggi:
- Rilevamento di modelli e caratteristiche: Le CNN sono ottime per rilevare modelli e caratteristiche in immagini, video e segnali audio. La loro struttura gerarchica consente di apprendere caratteristiche complesse dai dati grezzi.
- Invarianza alle trasformazioni: Le CNN sono invarianti alla traslazione, alla rotazione e alla scalatura. Ciò significa che sono in grado di riconoscere gli oggetti anche se si trovano in posizioni, orientamenti o dimensioni diverse all'interno di un'immagine.
- Estrazione automatica delle caratteristiche: Le CNN consentono un addestramento end-to-end, senza necessità di estrazione manuale delle caratteristiche. La rete impara a trovare le caratteristiche rilevanti direttamente dai dati di input grezzi.
- Scalabilità e precisione: Le CNN sono in grado di gestire grandi quantità di dati e sono precise in compiti complessi. Quando vengono forniti più dati, le loro prestazioni di solito migliorano.
Svantaggi delle reti neurali convoluzionali:
Costo computazionale: L'addestramento delle CNN è computazionalmente costoso e richiede molta memoria. Questo può essere un problema da implementare senza hardware specializzato come le GPU.
Overfitting: Se non vengono forniti dati sufficienti o adeguate [tecniche di regolarizzazione] (https://zilliz.com/learn/understanding-regularization-in-nueral-networks), le CNN possono andare in overfit. In altre parole, ottengono buone prestazioni sui dati di addestramento, ma non riescono a generalizzare a nuovi dati non visti.
Requisiti dei dati: Le CNN richiedono grandi quantità di dati etichettati per l'addestramento. Nei domini in cui i dati etichettati sono scarsi o costosi da ottenere, questo può essere un grosso limite.
Interpretabilità: È difficile interpretare ciò che una CNN ha imparato. La natura di "scatola nera" dei modelli di apprendimento profondo rende difficile comprendere il ragionamento alla base delle loro previsioni, il che può essere un problema nelle applicazioni sensibili.
La comprensione di questi vantaggi e svantaggi è fondamentale per decidere se utilizzare le CNN per un determinato compito e per progettare e implementare soluzioni basate sulle CNN.
Tecniche di regolarizzazione comuni nelle CNN
Come abbiamo detto negli svantaggi, le CNN possono essere inclini all'overfitting, soprattutto quando lavorano con dati limitati. Le tecniche di regolarizzazione vengono utilizzate per evitare che le CNN si adattino eccessivamente ai dati di addestramento, in modo che il modello possa generalizzarsi meglio ai dati non visti. Ecco alcune tecniche di regolarizzazione comunemente utilizzate nelle CNN:
Dropout: Questa tecnica "elimina" in modo casuale (cioè azzera) alcune caratteristiche di uscita dello strato durante l'addestramento. L'abbandono costringe la rete ad apprendere caratteristiche più robuste che non dipendono da un singolo neurone. In questo modo, la rete diventa meno sensibile ai pesi specifici dei neuroni, ottenendo una migliore generalizzazione. Durante il test vengono utilizzati tutti i neuroni, ma le loro uscite vengono ridimensionate per compensare i neuroni mancanti durante l'addestramento.
Regolarizzazione L1: Conosciuta anche come regolarizzazione Lasso, la regolarizzazione L1 aggiunge un termine di penalità alla funzione di perdita che è proporzionale al valore assoluto dei pesi. Questa tecnica incoraggia la sparsità del modello spingendo alcuni pesi a zero. La regolarizzazione L1 è utile quando si vuole creare un modello più semplice rimuovendo le caratteristiche meno importanti.
Regolarizzazione L2: Conosciuta anche come Ridge Regularization, la regolarizzazione L2 aggiunge un termine di penalizzazione alla funzione di perdita che è proporzionale al quadrato dei pesi. Questa tecnica scoraggia i pesi grandi e distribuisce i valori dei pesi in modo più uniforme. La regolarizzazione L2 non produce modelli sparsi come L1, ma può aiutare a ridurre l'impatto delle caratteristiche meno rilevanti.
Sia L1 che L2 possono ridurre il numero di pesi e rendere la rete più efficiente. La scelta tra L1 e L2 (o una combinazione di entrambe, nota come regolarizzazione Elastic Net) dipende dal problema e dal set di dati.
Queste tecniche di regolarizzazione, se utilizzate correttamente, risolvono uno dei maggiori problemi dell'apprendimento profondo e automatico.
Architettura delle CNN e funzionamento
Una CNN ha grandi capacità, che le consentono di trovare schemi nascosti e decifrare i dati visivi con una precisione eccezionale.
Il sistema neurale umano ha diversi strati, ognuno dei quali è responsabile dell'esecuzione di una funzione unica. Le CNN hanno un'architettura simile, con ogni strato che estrae caratteristiche diverse dall'immagine in ingresso. Di seguito viene fornita una spiegazione dettagliata di tutti gli strati coinvolti nell'architettura delle CNN.
I primi strati sono strati di rivoluzione, responsabili dell'estrazione delle caratteristiche di base dell'immagine, come i bordi e la forma.
I livelli successivi sono strati di raggruppamento, che sono lo strato di uscita responsabile della riduzione delle dimensioni delle [mappe di caratteristiche] (https://www.baeldung.com/cs/cnn-feature-map).
Infine, l'ultimo strato è il livello pienamente connesso (FC), che è responsabile della classificazione dell'immagine in una delle categorie indicate.
Quasi tutte le moderne architetture convoluzionali pure hanno solo uno strato di pooling globale alla fine, seguito da uno strato completamente connesso.
Strato di convoluzione
Lo strato di convoluzione è il cuore di una CNN, progettato per trovare modelli distintivi nei dati di ingresso. Prende l'immagine di ingresso e applica una serie di filtri per produrre un risultato chiamato mappa di caratteristiche. I filtri sono piccole matrici di pesi che analizzano l'immagine di ingresso per identificare diversi modelli. Quando il filtro si sposta sull'immagine, lo fa in passi definiti dallo stride, ossia il numero di pixel che il filtro sposta in ogni passo. A volte si usa il padding per controllare le dimensioni dell'output, aggiungendo altri pixel intorno all'input. Esistono diversi tipi di padding, tra cui il padding valido, il padding zero (nessun padding), il padding uguale (la dimensione dell'uscita è uguale a quella dell'ingresso) e il padding completo (che aumenta la dimensione dell'uscita). Dopo l'operazione di convoluzione, viene applicata una funzione di attivazione non lineare, in genere ReLU (Rectified Linear Unit), per introdurre la non linearità nel modello.
Altri strati convoluzionali
Come abbiamo detto in precedenza, un altro strato convoluzionale può venire dopo il primo strato convoluzionale. Quando ciò accade, la CNN diventa gerarchica, poiché gli strati successivi possono vedere i pixel all'interno dei campi ricettivi degli strati precedenti. Questa struttura gerarchica consente agli strati nascosti della rete di apprendere caratteristiche più complesse man mano che i dati scorrono attraverso gli strati.
Supponiamo di voler riconoscere un volto umano in un'immagine. Si può pensare a un volto come a una composizione di varie caratteristiche. Occhi, naso, bocca, sopracciglia e così via. Ogni singola caratteristica del volto è un modello di livello inferiore nella rete neurale e la combinazione di queste caratteristiche è un modello di livello superiore, una gerarchia di caratteristiche nella corteccia visiva della CNN.
Nel primo strato convoluzionale, la rete potrebbe imparare a rilevare caratteristiche semplici come bordi, curve e forme di base. Queste potrebbero essere il contorno dei tratti del viso o il contrasto tra le diverse parti del volto.
Il secondo livello di classificazione delle immagini potrebbe combinare queste caratteristiche di base per riconoscere forme più complesse. Ad esempio, potrebbe rilevare forme circolari (forse gli occhi) o linee curve (forse il contorno della bocca o delle sopracciglia).
Nei livelli successivi la rete potrebbe iniziare a riconoscere interi tratti del viso combinando i modelli dei livelli precedenti. Un neurone potrebbe attivarsi quando rileva una struttura simile agli occhi, un altro quando rileva un modello simile al naso.
Negli strati finali la CNN combinerebbe tutte queste caratteristiche facciali per riconoscere un volto completo. In questa fase la rete non si limita a rilevare le singole caratteristiche, ma capisce come queste si relazionano tra loro nel contesto di un volto.
Infine, gli strati convoluzionali convertono l'immagine in valori numerici, in modo che la rete neurale possa interpretare le immagini in ingresso ed estrarre modelli a vari livelli di astrazione. Questo apprendimento gerarchico delle caratteristiche è uno dei punti di forza delle CNN nei compiti di riconoscimento delle immagini, per comprendere oggetti complessi e multicomponenti come i volti.
Strato di accumulo
Dopo il livello di convoluzione, si trova spesso un livello di pooling. Lo scopo di questo strato di pooling (downsamples) è quello di ridurre le dimensioni delle mappe di caratteristiche preservando le caratteristiche più importanti. Questo aiuta a ridurre la complessità computazionale e a controllare l'overfitting. Esistono due tecniche comuni di pooling: il pooling massimo, che prende il valore massimo da una piccola regione della mappa di caratteristiche, e il pooling medio, che prende il valore medio da una piccola regione.
Strato completamente connesso (FC)
Lo strato finale di una CNN è in genere uno strato completamente connesso che classifica l'output della CNN. Questo livello è simile a quello di una rete neurale tradizionale e si collega a tutti i neuroni del livello precedente. Utilizza le caratteristiche di alto livello apprese dagli strati convoluzionali per eseguire la classificazione o la regressione finale.
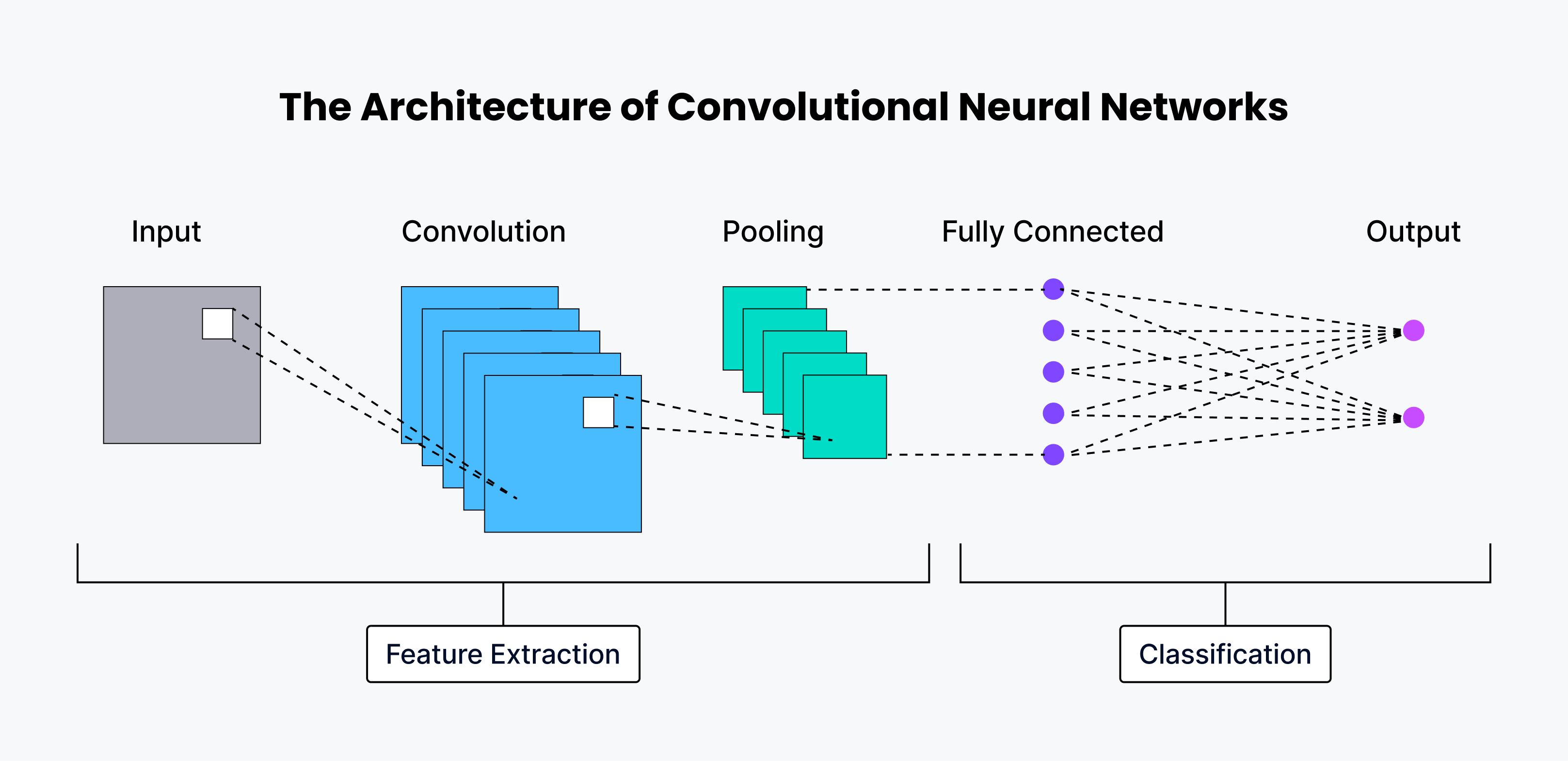 L'architettura delle reti neurali convoluzionali.png
L'architettura delle reti neurali convoluzionali.png
Terminologia essenziale
Quando si lavora con le CNN, è importante comprendere una terminologia essenziale. Un'epoca si riferisce a un passaggio completo dell'intero set di dati di addestramento. Il dropout è una tecnica utilizzata per prevenire l'overfitting, eliminando casualmente i neuroni durante il processo di addestramento. La profondità stocastica è un altro metodo che accorcia la rete durante l'addestramento, eliminando casualmente i blocchi residui.
Strides: è la dimensione del passo che il filtro compie durante l'operazione di convoluzione.
Il Padding - Il padding nelle CNN consiste nell'aggiunta di zeri intorno ai bordi dell'immagine per preservarne la dimensione spaziale dopo la convoluzione. Viene fatto per evitare che l'immagine si rimpicciolisca e per prevenire la perdita di informazioni dopo ogni operazione di convoluzione.
Epoch-Un passaggio completo attraverso l'intero set di dati di addestramento.
Dropout (regolarizzazione)-Tecnica per prevenire l'overfitting mediante l'eliminazione casuale di neuroni durante l'addestramento, che costringe la rete ad apprendere piuttosto che affidarsi ad altri neuroni.
Profondità stocastica-Accorcia la rete durante l'addestramento, eliminando i blocchi residui in modo casuale e bypassando le loro trasformazioni attraverso connessioni saltate. Nel frattempo, al momento del test, l'intera rete viene utilizzata per fare previsioni. In questo modo si ottiene un miglioramento dell'errore di test e una riduzione significativa del tempo di addestramento.
Tipi di reti neurali convoluzionali
La storia e lo sviluppo delle reti neurali convoluzionali risalgono a diversi decenni fa e molti ricercatori vi hanno contribuito. La comprensione di questa storia aiuterà a capire lo stato attuale delle CNN.
Basi storiche
Kunihiko Fukushima ha gettato le basi delle CNN nel 1980 con il suo lavoro sul "Neocognitron", una rete neurale artificiale gerarchica a più livelli. Questo primo modello era in grado di apprendere un robusto riconoscimento di modelli visivi.
Yann LeCun ha dato un altro importante contributo nel 1989 con il suo lavoro "Backpropagation Applied to Handwritten Zip Code Recognition". LeCun applicò la backpropagation per addestrare le reti neurali a riconoscere i modelli dei codici postali scritti a mano. Questo fu un grande passo avanti verso le applicazioni pratiche delle reti neurali.
LeNet-5: l'architettura originale della CNN
LeCun e il suo team continuarono a lavorarci per tutti gli anni Novanta e infine arrivarono a LeNet-5 nel 1998. LeNet-5 ha applicato i principi del lavoro precedente al riconoscimento dei documenti. È considerata l'architettura CNN originale e la base per tutti i lavori futuri.
Evoluzione delle architetture CNN
Da LeNet-5 sono state sviluppate molte architetture CNN diverse. Nuovi dataset come MNIST e CIFAR-10 e concorsi come ImageNet Large Scale Visual Recognition Challenge (ILSVRC) hanno guidato la maggior parte di questa innovazione. Alcune delle architetture CNN più importanti che sono state sviluppate sono:
AlexNet: Sviluppata da Alex Krizhevsky, Ilya Sutskever e Geoffrey Hinton, AlexNet ha vinto l'ILSVRC 2012. Era più profonda e più ampia delle CNN precedenti, utilizzava attivazioni ReLU e dropout per la regolarizzazione.
VGGNet: Sviluppata dal Visual Geometry Group di Oxford, VGGNet è nota per la sua semplicità e profondità. Utilizza piccoli filtri convoluzionali 3x3 in tutta la rete.
GoogLeNet (Inception): Sviluppato da Google, ha introdotto il modulo "Inception" che consente un calcolo più efficiente e reti più profonde.
ResNet: Sviluppato da Microsoft Research, ResNet ha introdotto il salto delle connessioni e ha permesso l'addestramento di reti molto più profonde (fino a 152 strati nel documento originale).
ZFNet: Un miglioramento di AlexNet, ZFNet (dal nome dei suoi creatori Zeiler e Fergus) ha vinto l'ILSVRC 2013 grazie alla messa a punto degli iperparametri dell'architettura.
Ciascuna di queste architetture ha apportato innovazioni che hanno spinto i confini di ciò che era possibile fare con le CNN, migliorando le prestazioni in vari compiti di computer vision.
Come progettare una rete neurale a convoluzione
Quando si progetta una CNN, si devono prendere diverse decisioni chiave. Tra queste, la scelta della dimensione dell'ingresso, la determinazione del numero di strati di convoluzione, la selezione della dimensione e del numero di filtri per strato di ingresso, la scelta del metodo di pooling, la decisione sul numero di strati completamente connessi e la selezione delle funzioni di attivazione. Ognuna di queste scelte può avere un impatto significativo sulle prestazioni e sull'efficienza della rete.
Scegliere la dimensione dell'ingresso-La dimensione dell'ingresso rappresenta la dimensione dell'immagine su cui la CNN verrà addestrata. La dimensione dell'ingresso deve essere sufficientemente grande da consentire alla rete di estrarre le caratteristiche dell'oggetto che intende classificare.
Scegliere il numero di strati di convoluzione: determina il numero di caratteristiche che la rete sarà in grado di apprendere. Un numero maggiore di livelli di convoluzione consente di apprendere caratteristiche più complesse, ma il tempo di calcolo aumenta.
Scegliere la dimensione del filtro-La dimensione del filtro, insieme allo stride della convoluzione, determina la dimensione delle caratteristiche che verranno estratte dalle immagini. Un filtro di dimensioni maggiori estrarrà un numero maggiore di caratteristiche.
Scegliere il numero di filtri per livello: questo determina il numero di caratteristiche diverse che possono essere estratte da un'immagine.
**Le due tecniche di pooling più comuni sono il max pooling e il average pooling. Il max pooling prende il valore massimo da una piccola regione della mappa delle caratteristiche, mentre il average pooling prende il valore medio da una piccola regione della mappa delle caratteristiche.
Scegliere il numero di livelli completamente connessi: questo determina il numero di classi che la rete può classificare.
Scegliere la funzione di attivazione-La [funzione di attivazione] (https://zilliz.com/learn/class-activation-mapping-CAM) consente di apprendere modelli più complessi dal set di dati dell'immagine. Per la classificazione binaria, è normale utilizzare la funzione sigmoide. In un problema di classificazione multiclasse, lo strato FC utilizza la funzione di attivazione softmax. Per introdurre la non linearità nei dati, oggi si utilizzano soprattutto le [funzioni di attivazione] GeLU o Swish(https://zilliz.com/glossary/activation-functions).
Di seguito è riportato un semplice esempio di implementazione di CNN con Python per classificare i segnali stradali. Trovate il set di dati sul sito web di Kaggle.
Semplice implementazione di CNN con PyTorch
Per implementare un modello CNN in Python, si possono usare framework come PyTorch, TensorFlow, Keras, ecc. Questi framework forniscono l'implementazione di tutti gli strati necessari per una CNN.
Il processo inizia con l'importazione dei moduli necessari, come segue:
# dipendenze per il calcolo
importare pandas come pd
importare numpy come np
# dipendenze per la lettura e la visualizzazione delle immagini
da cv2 import resize
da skimage.io import imread
importare matplotlib.pyplot come plt
%matplotlib inline
# dipendenza per creare l'insieme di validazione
da sklearn.model_selection import train_test_split
# dipendenza per valutare il modello
da sklearn.metrics import accuracy_score
da tqdm import tqdm
# librerie e moduli PyTorch
importare torch
da torch.autograd importare Variabile
da torch.nn import (Lineare, ReLU, CrossEntropyLoss,
Sequenziale, Conv2d, MaxPool2d, Modulo,
Softmax, BatchNorm2d, Dropout)
da torch.optim importare Adam, SGD
Una volta fatto ciò, caricare il set di dati e le immagini con il seguente codice:
# caricamento del set di dati
train = pd.read_csv('Data/train.csv')
# caricamento delle immagini di addestramento
train_img = []
per nome_immagine in tqdm(train['Path']):
# definizione del percorso dell'immagine
image_path = 'Data/' + str(img_name)
# lettura dell'immagine
img = imread(percorso_immagine, as_gray=True)
# ridimensionare l'immagine
img = resize(img, (28, 28))
# normalizzazione dei valori dei pixel
img /= 255,0
# conversione del tipo di pixel in float 32
img = img.astype('float32')
# inserire l'immagine nell'elenco
train_img.append(img)
# Conversione dell'elenco in array numpy
train_x = np.array(train_img)
# definire il target
train_y = train['ClassId'].values
train_x.shape
Una volta caricati i dati di addestramento, è necessario creare un set di dati di addestramento e uno di validazione utilizzando il metodo train_test_split() di sklearn.
# creare l'insieme di validazione
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size = 0,1)
# Controllare le forme degli insiemi di addestramento e di validazione
(train_x.shape, train_y.shape), (val_x.shape, val_y.shape)
È inoltre necessario rimodellare i dati per il modello Torch come segue:
# conversione delle immagini di addestramento in formato Torch
train_x = train_x.reshape(-1, 1, 28, 28)
train_x = torch.from_numpy(train_x)
# Conversione del target in formato torch
train_y = train_y.astype(int);
train_y = torch.from_numpy(train_y)
# Conversione delle immagini di validazione in formato torch
val_x = val_x.reshape(-1, 1, 28, 28)
val_x = torch.from_numpy(val_x)
# conversione del target in formato torch
val_y = val_y.astype(int);
val_y = torch.from_numpy(val_y)
Definire quindi i diversi livelli di una CNN come segue:
classe Net(Modulo):
def __init__(self):
super(Net, self).__init__()
self.cnn_layers = Sequential(
# Definizione di uno strato di convoluzione 2D
Conv2d(1, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
# Definizione di un altro livello di convoluzione 2D
Conv2d(4, 4, kernel_size=3, stride=1, padding=1),
BatchNorm2d(4),
ReLU(inplace=True),
MaxPool2d(kernel_size=2, stride=2),
)
# strato denso finale per la predizione
self.linear_layers = Sequential(
Lineare(4 * 7 * 7, 43)
)
# Definizione del passaggio in avanti
def forward(self, x):
x = self.cnn_layers(x)
x = x.view(x.size(0), -1)
x = self.linear_layers(x)
restituire x
La rete CNN di cui sopra ha due livelli di convoluzione seguiti da un livello di pooling massimo con dimensioni spaziali di 2 per 2.
Uno strato di appiattimento può aiutare a classificare gli strati nascosti nell'immagine del segno nelle rispettive classi.
Quindi, decidiamo l'ottimizzatore e la funzione di perdita e definiamo la procedura di addestramento.
# Definizione del modello
modello = Net()
# Definizione dell'ottimizzatore
ottimizzatore = Adam(model.parameters(), lr=0.07)
# Definizione della funzione di perdita
criterio = CrossEntropyLoss()
# verifica se la GPU è disponibile
se torch.cuda.is_available():
model = model.cuda()
criterio = criterion.cuda()
print(modello)
def train(epoch):
model.train()
tr_loss = 0
# ottenere l'insieme di allenamento
x_train, y_train = Variabile(train_x), Variabile(train_y)
# ottenere l'insieme di validazione
x_val, y_val = Variabile(val_x), Variabile(val_y)
# convertire i dati in formato GPU
se torch.cuda.is_available():
x_train = x_train.cuda()
y_train = y_train.cuda()
x_val = x_val.cuda()
y_val = y_val.cuda()
# Azzeramento dei gradienti dei parametri del modello
optimizer.zero_grad()
# predizione per i set di addestramento e di validazione
output_train = model(x_train)
output_val = modello(x_val)
# Calcolo della perdita per l'addestramento e la validazione
loss_train = criterio(output_train, y_train)
loss_val = criterio(output_val, y_val)
train_losses.append(loss_train)
val_losses.append(loss_val)
# Retropropagazione e aggiornamento dei parametri del modello
loss_train.backward()
ottimizzatore.step()
tr_loss = loss_train.item()
se epoch%2 == 0:
# stampa della perdita di validazione
print('Epoch : ',epoch+1, '\t', 'loss :', loss_val)
Infine, allenare il modello per 25 epoche sui dati di allenamento come segue:
# definizione del numero di epoche
n_epoche = 25
# lista vuota per memorizzare le perdite dell'allenamento
train_losses = []
# Elenco vuoto per memorizzare le perdite di validazione
val_losses = []
# addestramento del modello
per epoch in range(n_epochs):
train(epoch)
Alla fine, ogni modello sarà in grado di fare previsioni sui dati di test. Per maggiori dettagli, consultare questo blog [come scrivere CNN da zero in PyTorch] (https://blog.paperspace.com/writing-cnns-from-scratch-in-pytorch/).
FAQs
Qual è la differenza tra CNN e Reti neurali profonde?
Una CNN è un tipo di rete neurale in grado di elaborare dati visivi come immagini, parlato, video e così via, mentre le reti neurali profonde (DNN) sono un tipo di rete neurale artificiale in grado di apprendere modelli complessi dai dati.
Di seguito sono riportate le principali differenze tra le CNN e le DNN.
Una CNN ha un'architettura specifica per l'elaborazione delle immagini. Una DNN, invece, non ha un'architettura specifica e può essere utilizzata per una varietà di compiti.
Una CNN apprende le caratteristiche dalle immagini utilizzando strati di convoluzione, mentre una DNN apprende le caratteristiche con l'aiuto di diversi [tipi di strati] (https://www.geeksforgeeks.org/deep-neural-network-with-l-layers/).
Una CNN è più difficile da addestrare, richiede più dati ed è computazionalmente costosa rispetto a una DNN.
**Quali sono i tre strati di una CNN?
I tre livelli di una CNN sono il livello di attivazione, il livello di convoluzione, il livello di pooling e il livello completamente connesso.
Questo strato è responsabile dell'estrazione delle caratteristiche dalle immagini. Funziona scansionando le immagini con un filtro, che è una piccola matrice di pesi. Il filtro si sposta sull'immagine e i pesi vengono moltiplicati per i valori dei pixel nell'immagine. Infine, produce una mappa di caratteristiche che contiene le caratteristiche estratte.
Il livello di pooling riduce le dimensioni delle mappe di caratteristiche. A tale scopo, due tecniche comuni di pooling sono il max pooling e il average pooling.
Strato completamente connesso**: è lo stesso delle reti neurali tradizionali che classificano l'output della CNN. I neuroni degli strati completamente connessi classificano l'immagine in un insieme di classi.
**Che cos'è una rete neurale convoluzionale nell'apprendimento profondo?
Una rete neurale convoluzionale è un tipo di rete neurale profonda che elabora immagini, discorsi e video in modo da poterli utilizzare per fare previsioni reali su dati strutturati/non strutturati nel crescente mondo digitale.
Una CNN aiuta a prevedere in modo semplice ed efficiente le emozioni, i comportamenti, gli interessi, le simpatie, le antipatie e così via.
- **Ragioni principali per l'utilizzo di una CNN**
- Vantaggi e svantaggi delle reti neurali convoluzionali
- Tecniche di regolarizzazione comuni nelle CNN
- **Architettura delle CNN e funzionamento**
- Tipi di reti neurali convoluzionali
- **Come progettare una rete neurale a convoluzione**
- **Semplice implementazione di CNN con PyTorch**
- **FAQs**
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente