




Zilliz Cloud On-Demand Compute: paga solo per ciò che usi
Nell'ultimo trimestre abbiamo lavorato su un caso di fatturazione con un cliente del settore della guida autonoma. Il loro team di analytics aveva bisogno della ricerca vettoriale su una collection da 1 miliardo di righe. L'abbiamo dimensionata su un cluster Dedicated: $7.000/mese. Abbiamo provato Serverless: $10.800. Il lavoro effettivo di analytics era di poche ore al mese.
Entrambe le fatture erano corrette. Entrambi i prodotti stavano facendo esattamente ciò per cui sono progettati. Il problema era che il workload di questo cliente — analytics sporadica che condivideva un dataset con altri due workload di produzione — non corrispondeva a ciò per cui uno dei due prodotti era stato progettato.
Quel caso è il motivo per cui abbiamo creato Zilliz Cloud On-Demand Search — una delle nuove funzionalità che abbiamo rilasciato con il lancio di Zilliz Vector Lakebase. Stesso workload, sotto i $500/mese. Di seguito spieghiamo cosa non funzionava, cosa abbiamo cambiato, dove On-Demand è lo strumento sbagliato e come alla fine si inserisce di nuovo in Vector Lakebase.
Il caso del cliente
La collection — circa 1 miliardo di record — era già utilizzata da due workload di produzione:
- Un servizio di retrieval online che gestisce traffico in tempo reale.
- Una pipeline di addestramento dei modelli che estrae dati di scenario per job di regressione (gestita da un team separato).
Analytics era un terzo workload aggiunto sopra gli stessi dati. Il pattern di accesso: gli analisti eseguivano ricerche solo quando avevano una domanda specifica, in brevi burst iterativi guidati dall'indagine in corso. Per il resto del tempo, nessuna query analitica raggiungeva il cluster.
Questo è un caso d'uso Zilliz abbastanza comune su una scala di dati abbastanza comune. Ciò che lo rendeva difficile era che tutti e tre i workload dovevano leggere dalla stessa collection sottostante, e ciascuno aveva una cadenza molto diversa.
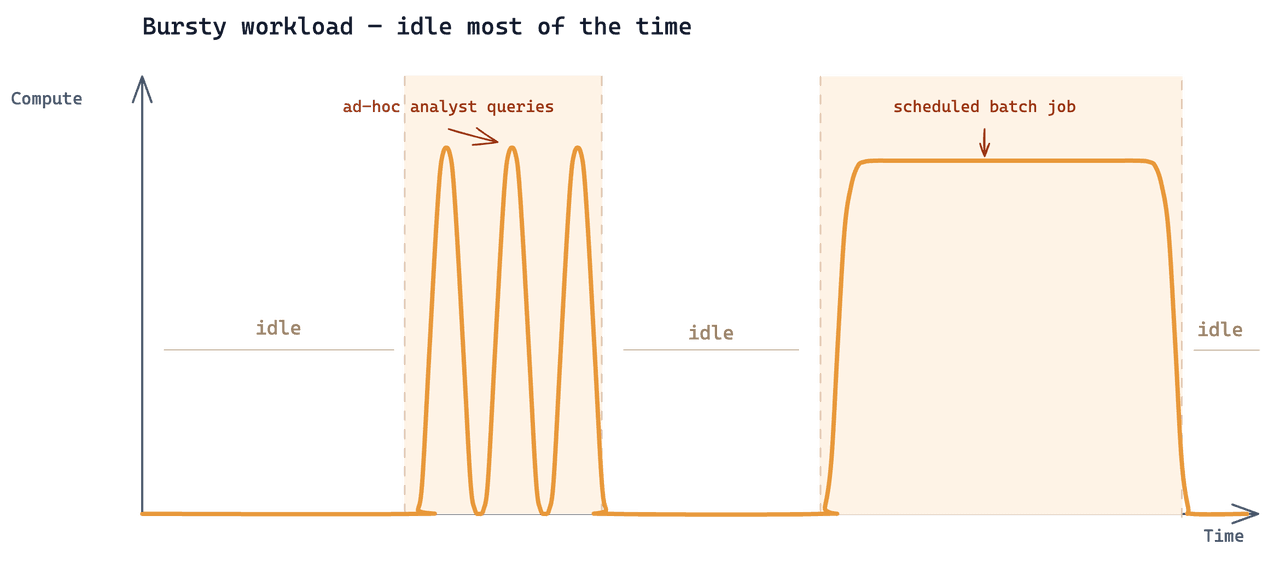
Perché il cluster Dedicated non era adatto
La configurazione esistente era un cluster Tiered di Zilliz Cloud a 24 CU. Aggiungere il workload di analytics lo portava a ~$7.000/mese. Il cluster viene fatturato per ogni ora in cui esiste: 24 × 30 = 720 ore/mese. Il lavoro reale di analytics consumava 2–3 ore. Le restanti 717 ore venivano fatturate per restare inattive — il 99,6% della spesa totale andava in capacità che nessuno utilizzava.
Puoi arrestare un cluster Dedicated tra una sessione e l'altra per evitare le ore inattive. Lo abbiamo preso in considerazione. Non funziona, per due motivi.
Primo, il cold start su Dedicated richiede oltre 10 minuti per query analitiche a freddo su un dataset di queste dimensioni. Il modello mentale di Dedicated è che tutti i dati richiesti debbano essere nella memoria locale prima che le query vengano eseguite, quindi precarica l'intero working set — in genere da decine a centinaia di volte i dati che una singola query a freddo tocca effettivamente. Lo stesso caricamento deve anche attivare lo stato per attività non di query supportate dal cluster, come DDL e delete. Questo overhead esiste indipendentemente dal fatto che la query successiva ne abbia bisogno o meno.
Secondo, la fatturazione viene arrotondata all'ora. Quindi, anche se l'analista fosse disposto ad aspettare oltre 10 minuti affinché il cluster si scaldi, la fattura per una singola query è comunque di un'ora più il caricamento. Con gli analisti che lavorano in brevi burst iterativi, il costo per query utile rimane alto, per quanto disciplinato sia l'avvio/arresto.
Perché il cluster Serverless non era adatto
Serverless è stata l'opzione successiva che abbiamo provato. Sulla carta ha la forma giusta per questo pattern di accesso: stateless, pay-per-query, nessun compute inattivo. Per il workload di analytics da solo, avrebbe potuto funzionare.
Il problema è che Serverless su questo dataset non prezza il workload di analytics in isolamento. Prezza tutto ciò che tocca la collection. Una volta inclusi i workload esistenti, tre voci hanno fatto saltare i conti:
- Query: ~$6.000/mese. La maggior parte proveniva dai job di regressione bisettimanali del team di addestramento dei modelli — 100 QPS per 3 ore, ogni due settimane. I prezzi unitari di Serverless incorporano un premio per le query a freddo che viene pagato su ogni query, anche quando la query è a caldo. Una volta che il volume di query non è banalmente basso, smette di tornare.
- Storage: $1.700/mese. Misurato separatamente perché Serverless non ha una tariffa per ora di compute in cui incorporare lo storage.
- Scritture: $3.000/mese. Stesso motivo — non c'è un'ora di compute in cui incorporarle.
Totale: $10.784/mese, più alto del cluster Dedicated da cui stavamo cercando di uscire.
Ciascuno di questi premi ha dietro una ragione strutturale.
Le query portano un premio per le query a freddo. Dal punto di vista dell'utente, Serverless è stateless. Dal punto di vista della piattaforma, i dati devono comunque essere caricati su macchine specifiche per l'esecuzione. Le query si dividono in calde (dati già sulla macchina) e fredde (prima serve un recupero dall'object storage). Le query calde costano poco; le query fredde sono costose. La piattaforma non può prevedere quali query saranno fredde per un determinato utente, quindi distribuisce il costo delle query a freddo sul prezzo unitario di ogni query. I workload con query per lo più calde finiscono per pagare quelle fredde di tutti gli altri.
Lo storage ha un prezzo superiore al costo marginale. In Dedicated, i costi di storage e scrittura viaggiano invisibilmente nella tariffa per ora di compute. Serverless non ha una tariffa per ora di compute dietro cui nascondere quei costi, quindi lo storage viene addebitato esplicitamente. Quel prezzo esplicito deve coprire dati che sono archiviati ma mai interrogati — la piattaforma non può spostarli in storage profondamente freddo perché i dati devono restare pronti per le query in qualsiasi momento. Mantenere questa prontezza richiede stato aggiuntivo, e il suo costo finisce ammortizzato sulla dimensione dello storage, che in realtà non corrisponde al consumo reale.
Anche le scritture hanno un prezzo superiore al costo marginale. Le scritture sono misurate separatamente per impedire agli utenti di emettere aggiornamenti ad alta frequenza che producono molti costi di scrittura senza far crescere il dataset (cosa che altrimenti lascerebbe la piattaforma ad assorbire il costo). Stessa dinamica dello storage: il costo dello stato di prontezza confluisce nel prezzo unitario per scrittura.
Il problema più profondo è che Serverless nasconde all'utente l'astrazione della "risorsa di compute". L'utente vede un'interfaccia stateless; la piattaforma deve comunque pagare per pattern di accesso imprevedibili dietro le quinte — dati caldi/freddi, traffico a burst, storage inattivo che deve restare pronto per le query. Questi costi non possono essere attribuiti con precisione a utenti specifici, quindi vengono ammortizzati nei prezzi unitari di query, storage e scritture. Ogni azione fatturabile finisce un gradino sopra il suo costo marginale reale.
Questo è un modello di "rischio condiviso": ogni voce di costo porta un sovrapprezzo per coprire le query a freddo, i burst o lo storage inattivo di qualcun altro. I workload meno responsabili di quella varianza — query a caldo stabili, ad alta frequenza e prevedibili — pagano la quota maggiore del premio. Più stabile è il tuo workload, più finisci per sovvenzionare.
Ciò di cui il cliente aveva effettivamente bisogno
Facendo un passo indietro, la richiesta del cliente non era esotica. Un dataset, più cadenze di accesso, con la fattura che segue solo il compute effettivamente usato da ciascuna cadenza.
- Retrieval online: continuo, a bassa latenza, prevedibile. Dedicated è adatto a questo.
- Addestramento dei modelli: a burst ma prevedibile — 3 ore ogni due settimane.
- Analytics: sporadico e imprevedibile — pochi minuti alla volta, con lunghi intervalli.
Dedicated non poteva offrire questo. Fattura la capacità provisionata, non il consumo. Neanche Serverless poteva: il suo prezzo unitario per query deve sovvenzionare query a freddo, storage inattivo e margine per i burst tra tutti gli utenti della piattaforma, quindi i workload stabili finiscono per pagare una varianza che non generano.
Quello di cui avevamo bisogno era un terzo modello di compute — uno che potesse collegarsi agli stessi dati di Dedicated, avviarsi abbastanza velocemente da rendere realistica la fatturazione per query, e fatturare solo quando è effettivamente in esecuzione.
Cosa abbiamo cambiato
On-Demand è un modello di calcolo separato su Zilliz Cloud che affianca Dedicated e Serverless. Cambia tre cose rispetto a entrambi:
- Avvio a freddo. Carica solo i chunk toccati dalla query corrente, non l'intero working set. Scende da oltre 10 minuti a pochi secondi.
- Fatturazione. Al minuto di effettivo tempo di attività del calcolo. Anche le scritture. Nessuna ora minima, nessun sovrapprezzo a freddo/caldo per query.
- Isolamento. Ogni workload si collega a una collection tramite il proprio gruppo di risorse di calcolo. Stessi dati, nessuna contesa.
Le prossime tre sezioni analizzano ciascun punto.
Caricare meno dati, più velocemente
L'avvio a freddo di 10 minuti su Dedicated esiste perché il cluster deve caricare l'intero working set nella memoria locale prima di servire le query. Su una collection da 1 miliardo di righe, sono da decine a centinaia di volte più dati di quanti ne servano effettivamente a una singola query. Ridurre l'avvio a freddo a pochi secondi significa abbandonare quell'assunzione: caricare solo ciò che la query corrente tocca.
Sembra una frase sola; in pratica ha richiesto di riprogettare tre livelli — cosa leggere, dove metterlo e come portarlo su.
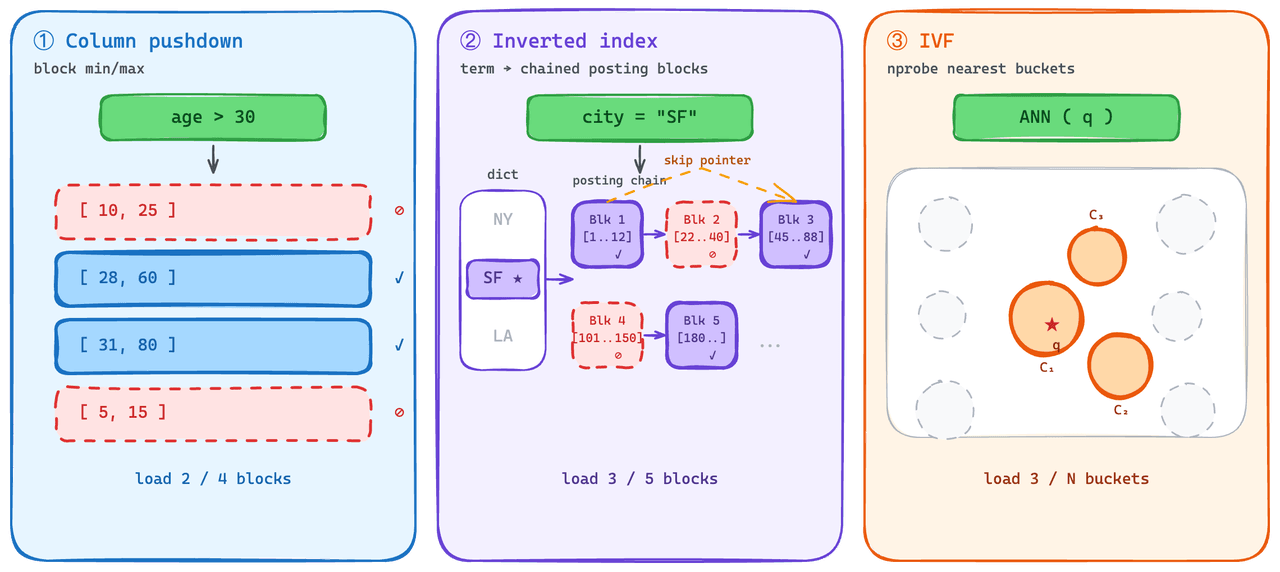
Indici che si caricano parzialmente.
Sul lato scalare, il predicate pushdown è una pratica standard. Il motore elimina i blocchi che non possono soddisfare il predicato e evita di recuperarli. Lo usiamo sugli indici invertiti: ogni posting list si carica come un blocco, e ogni lista contiene statistiche min/max che il motore può controllare prima del recupero.
La parte più difficile è stata dare al lato vettoriale una capacità comparabile di "leggere un sottoinsieme". Gli indici a grafo — l'opzione con prestazioni più elevate per il QPS a regime — non degradano gradualmente con il caricamento parziale: la struttura deve essere caricata per intero per essere utile, quindi il costo di caricamento a freddo è elevato.
On-Demand usa invece la famiglia IVF. IVF raggruppa i vettori in bucket al momento dell'indicizzazione, e al momento della query vengono recuperati solo i bucket più vicini alla query. Questo dà al lato vettoriale qualcosa di simile alla semantica del predicate pushdown: le query a freddo recuperano una piccola frazione dell'indice, non tutto l'indice.
È un compromesso deliberato. Perdiamo le prestazioni a regime degli indici a grafo, che è il motivo principale per cui On-Demand non è adatto al serving ad alto QPS (maggiori dettagli più avanti). Per workload sparsi e con picchi improvvisi, il compromesso vale la pena.
Un percorso dati a tre livelli.
Una volta che sappiamo cosa leggere, la domanda successiva è dove conservarlo. I chunk fluiscono liberamente tra S3, disco locale e memoria, e il ciclo di vita della cache è gestito per chunk tra le query: i chunk di cui la query corrente ha bisogno vengono portati su; i chunk che restano inattivi abbastanza a lungo vengono espulsi. Lo stesso dataset può essere interrogato a cadenze molto diverse, e nessuna di esse paga il costo di caricare dati che non tocca.
Ogni livello ha il proprio layout dei dati e la propria granularità, adattati alle caratteristiche di IO del supporto — l'allineamento che funziona per l'object storage non è l'allineamento che funziona per il disco locale, e nessuno dei due corrisponde a ciò contro cui il motore esegue in memoria.
IO asincrono end to end.
La catena di IO è completamente asincrona. Calcolo e IO sono in pipeline per tutto il percorso, quindi la CPU non resta in attesa di un recupero e la banda di IO non resta in attesa del calcolo.
Nel complesso, chunked + tiered + async riduce il payload delle query a freddo a meno dell'1–2% del dataset completo e il percorso a freddo end-to-end a pochi secondi.
Fatturazione al minuto
Con l'avvio a freddo a livello di secondi, "avviare il calcolo quando arriva una query, rilasciarlo quando finisce" funziona come un meccanismo di prodotto reale — non solo come un'aspirazione progettuale. Due componenti del piano di controllo fanno il grosso del lavoro.
Un pool di nodi in standby. I pull delle immagini aggiungono latenza all'avvio di un nodo nuovo. Manteniamo un piccolo pool di nodi con immagini già scaricate pronto, quindi lo spin-up attinge dal pool invece di partire da zero.
Rilascio basato su TTL. Ogni sessione ha un timeout di inattività configurabile. Le risorse di calcolo vengono rilasciate automaticamente quando scatta il timeout, il carico di query termina o la sessione viene chiusa. L'intero ciclo di vita è pianificato dalla piattaforma — niente modalità "ho dimenticato di fermare il mio cluster", niente operazioni manuali.
Poiché il ciclo di vita è granulare, la granularità della fatturazione si adegua. Il calcolo viene fatturato al minuto di uptime effettivo — nessuna ora minima, nessun addebito minimo per query. Le scritture sono misurate allo stesso modo: utilizzo effettivo delle risorse, al minuto.
La precisione dell'attribuzione dei costi è ciò che consente a On-Demand di evitare il sovrapprezzo sullo storage che Serverless deve applicare. Serverless prezza lo storage al di sopra del costo marginale perché il suo livello di calcolo non ha modo di assorbire costi non attribuiti — ogni dollaro speso dalla piattaforma deve finire da qualche parte in fattura, quindi storage e scritture diventano lo scarico per ciò che non può essere attribuito altrove. Quando On-Demand fattura ogni minuto di calcolo a una sessione specifica, non esiste un pool non attribuito. Lo storage su On-Demand segue i prezzi di Zilliz Cloud alle tariffe Dedicated — circa 1/10 dello storage Serverless tipico.
Isolamento dei carichi di lavoro su dati condivisi
Il terzo cambiamento consiste nel rendere esplicito il livello di calcolo. Su Dedicated, il livello di calcolo è il cluster — invisibile all'utente tranne che come singolo parametro di dimensionamento. Su Serverless, il livello di calcolo è completamente nascosto. On-Demand lo espone.
Ogni carico di lavoro si collega a una collection tramite un gruppo di risorse di calcolo. Nuovi gruppi vengono avviati — o quelli esistenti riutilizzati — tramite sessioni. I diversi gruppi sono isolati gli uni dagli altri, e la fattura di ciascun gruppo riflette solo il proprio consumo.
Nel caso della guida autonoma, è così che il carico di lavoro analitico ottiene il proprio collegamento ai dati: un gruppo di risorse On-Demand che si avvia per query ad hoc e viene rilasciato quando è inattivo, eseguendosi sulla stessa collection Milvus, sugli stessi indici e sugli stessi metadati dei carichi di lavoro esistenti di retrieval online e training del modello. La separazione storage-compute significa che nessuno di essi deve copiare o sincronizzare i dati per usarli. Nessuna sovvenzione incrociata, nessuna contesa di scheduling, nessun coordinamento operativo tra team sulla forma del cluster.
Questo è lo stesso pattern architetturale di un data lake, applicato alla ricerca vettoriale: lo storage è il substrato condiviso, e il calcolo si collega nella forma necessaria a ciascun carico di lavoro.
La fattura, dopo
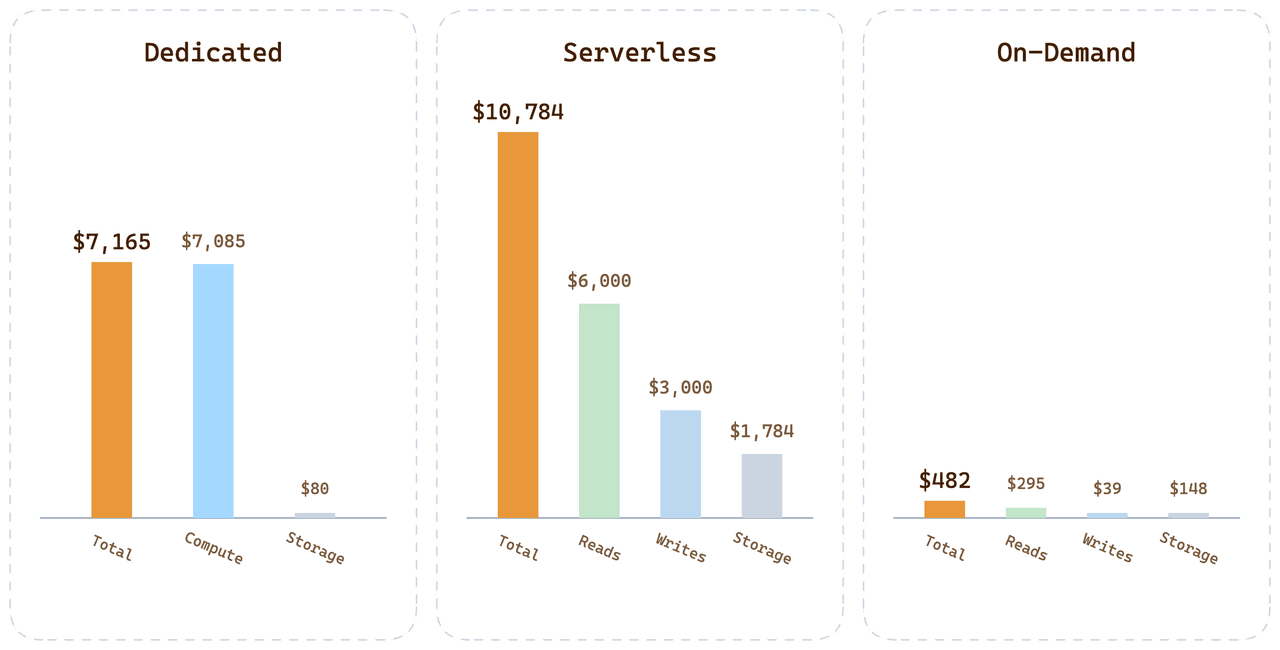
Per lo stesso carico di lavoro del cliente su tutte e tre le opzioni:
| Opzione | Fattura mensile | Dove vanno i soldi |
|---|---|---|
| Dedicated (24 CU Tiered) | $7,165 | 99,6% del calcolo pagato ma inattivo |
| Serverless | $10,784 | Premium per query + $1,700 storage + $3,000 scritture |
| On-Demand | < $500 | Calcolo al minuto + storage a tariffa Dedicated |
On-Demand per questo carico di lavoro arriva a meno di 1/20 della fattura Serverless. La differenza non è un trucco di prezzo; è la conseguenza diretta dell'attribuire i costi al consumo reale invece di ammortizzare la varianza di altri utenti in ogni prezzo unitario.
Dove On-Demand è lo strumento sbagliato
On-Demand non è un sostituto universale di Dedicated o Serverless. Le stesse scelte progettuali che lo rendono economico per carichi di lavoro radi e bursty lo rendono inadatto per altri. Il grafico seguente mostra il costo mensile rispetto alla pressione delle query per il carico di lavoro di questo cliente su tutte e tre le opzioni.
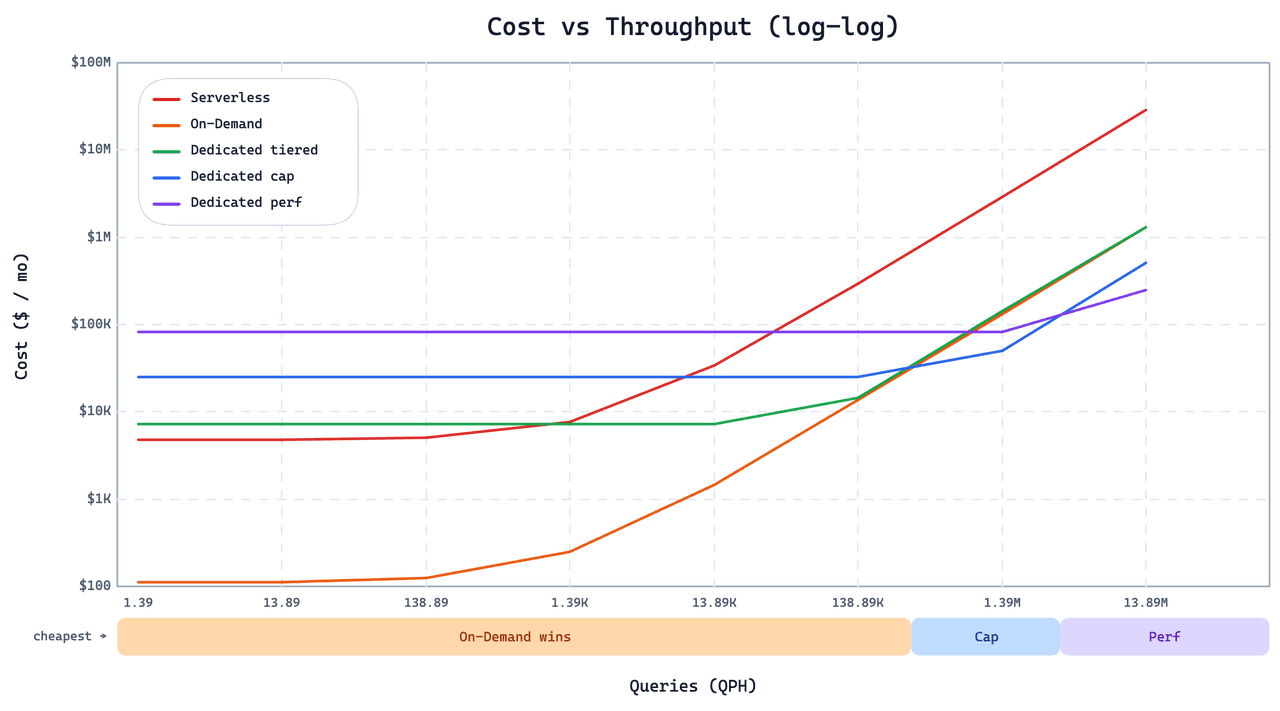
Sotto il punto di crossover, On-Demand è significativamente più economico. Una volta che il QPS entra nelle decine, le istanze Dedicated Cap or Perf diventano sia più economiche sia più veloci. Due decisioni progettuali spiegano il crossover:
Nessun indice a grafo. Per mantenere economico il caricamento delle query a freddo, On-Demand usa IVF invece degli indici a grafo. Gli indici a grafo offrono QPS più elevati in stato stazionario su larga scala, ma il loro costo di caricamento a freddo è alto. Al di sopra di qualche decina di QPS, il vantaggio in stato stazionario prevale nettamente. Per il serving ad alto QPS, usa Dedicated.
Latenza di coda più elevata sulle query a freddo. On-Demand non precarica i dati, quindi una query a freddo paga un fetch extra prima di poter essere eseguita. Le query calde sono veloci; quelle a freddo sono sensibilmente più lente, e la distribuzione della latenza di coda è più ampia rispetto a Dedicated o Serverless. Se la tua applicazione non può tollerare risposte occasionali nell’ordine dei secondi (o peggio, dei minuti), On-Demand non è la scelta giusta. Per quei carichi di lavoro, Smart Autoscaling on Dedicated riduce la capacità inattiva senza sacrificare la latenza in stato caldo.
Dove On-Demand è lo strumento giusto: accesso sparso, iterazione analitica e batch mining su grandi dataset — carichi di lavoro in cui elevata concorrenza e stretta coerenza della latenza non sono i requisiti principali.
Dove si inserisce in Zilliz Vector Lakebase
Il caso cliente in questo post è una parte di un pattern più ampio: lo stesso dataset, accessibile a cadenze diverse da carichi di lavoro diversi, dimensionato correttamente solo quando ogni carico di lavoro ottiene la forma di compute di cui ha effettivamente bisogno. On-Demand è una delle forme di compute. Zilliz Vector Lakebase è l’architettura che rende possibile il resto.
Un Vector Lakebase è una piattaforma dati lake-native per carichi di lavoro AI. I dati risiedono su S3, gli indici sono disaccoppiati dal compute e diverse forme di compute si collegano alla stessa collection tramite accesso zero-copy. Gestisce tre modalità di carico di lavoro come capacità di primo livello — retrieval in tempo reale, scoperta iterativa e analytics batch — ciascuna servita dalla forma di compute adatta al suo pattern di accesso. Il vector retrieval è sempre stato un carico di lavoro di primo livello su Zilliz Cloud; con il lancio di Vector Lakebase, le forme di compute per iterative-discovery e batch-analytics si uniscono ad esso sulla stessa base dati.
On-Demand è la forma di compute creata per carichi di lavoro analitici e bursty. Le altre quattro capacità coprono il resto delle modalità:
- Tiered Serving Solutions per il retrieval in tempo reale — Performance-Optimized (1000+ QPS, latenza in ms a singola cifra, tutto in memoria), Capacity-Optimized (100–500 QPS con latenza sotto i 100 ms su memoria + NVMe locale) e Tiered-Storage (10–50 QPS con latenza di ~100 ms tra memoria, NVMe e object store). Punti diversi sulla curva prestazioni/costo, stessa modalità di serving.
- External Data Lake Search per indicizzare e cercare dati già presenti in Lance, Iceberg o altri formati lake — senza copiarli in uno store separato.
- Full-Spectrum Search per vettori, testo, JSON e geospaziale su un unico piano di query, con retrieval ibrido, filtering e reranking su un modello dati wide-table.
- Unified Lake-Native Storage basato su Vortex, un formato colonnare aperto di nuova generazione con letture casuali più veloci rispetto a Lance o Parquet, più flessibilità di formato per colonna.
Zilliz Vector Lakebase è ora in public preview su Zilliz Cloud. Per l’architettura completa e il resto delle capacità, il Vector Lakebase deep-dive è la lettura canonica.
Per provare On-Demand sul tuo carico di lavoro, registrati su Zilliz Cloud e avvia un cluster On-Demand dalla console o dalla CLI. Se i numeri in questo post corrispondono a qualcosa che stai eseguendo, il team Zilliz sarà felice di esaminare il tuo carico di lavoro prima che tu inizi a costruire.

Continua a leggere

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.