




Le 10 principali tecniche di Context Engineering che dovresti conoscere per RAG in produzione
Quando costruiamo per la prima volta una demo RAG o di un agente, di solito le cose funzionano bene. Con un dataset piccolo, alcuni prompt e un retrieval semplice, spesso possiamo avere un prototipo funzionante in poche ore.
La vera sfida appare quando proviamo a eseguire il sistema in produzione. Man mano che l’utilizzo cresce, i problemi emergono rapidamente. Il retrieval diventa più lento, le risposte diventano meno affidabili, la latenza aumenta e i costi crescono. Ciò che funzionava in una piccola demo spesso si rompe quando sono coinvolti dati reali, utenti reali e contesti più lunghi.
A questo punto, di solito ci rendiamo conto che il problema non è solo il modello. Riguarda anche il modo in cui il contesto viene preparato e passato al modello. È qui che entra in gioco il context engineering. Si concentra sul recupero, l’organizzazione, il perfezionamento e la gestione delle informazioni che un modello linguistico usa per generare risposte.
In questo articolo, spieghiamo come funziona il context engineering nella pratica. Esaminiamo approcci recenti per costruire il contesto, elaborarlo in modo efficiente e gestirlo nel tempo. Queste tecniche aiutano a trasformare semplici demo in sistemi che possono funzionare in modo affidabile in produzione.
Nota: Questo articolo si basa principalmente sul paper https://arxiv.org/html/2507.13334v1.
Che cos’è il Context Engineering?
Il context engineering si concentra sull’assemblaggio delle informazioni di cui un modello linguistico di grandi dimensioni ha bisogno per rispondere bene a una domanda. Queste informazioni non si limitano al prompt. Includono anche la query dell’utente, i documenti recuperati, la cronologia della conversazione e altri dati rilevanti. L’obiettivo è migliorare l’accuratezza, ridurre il tempo di risposta e controllare i costi.
Questo lavoro viene svolto per lo più automaticamente tramite algoritmi. Il context engineering combina prompt engineering, retrieval-augmented generation (RAG) e tecniche multi-agente in un unico sistema, invece di usarle separatamente.
Nella pratica, una configurazione di context engineering ha due parti. La prima consiste in componenti fondamentali che gestiscono il recupero, l’elaborazione e l’orchestrazione dei dati. Il secondo livello è costituito da sistemi complessi più complessi che combinano questi componenti in applicazioni complete. I team possono combinare e riutilizzare queste parti per adattarle a diversi scenari di produzione.
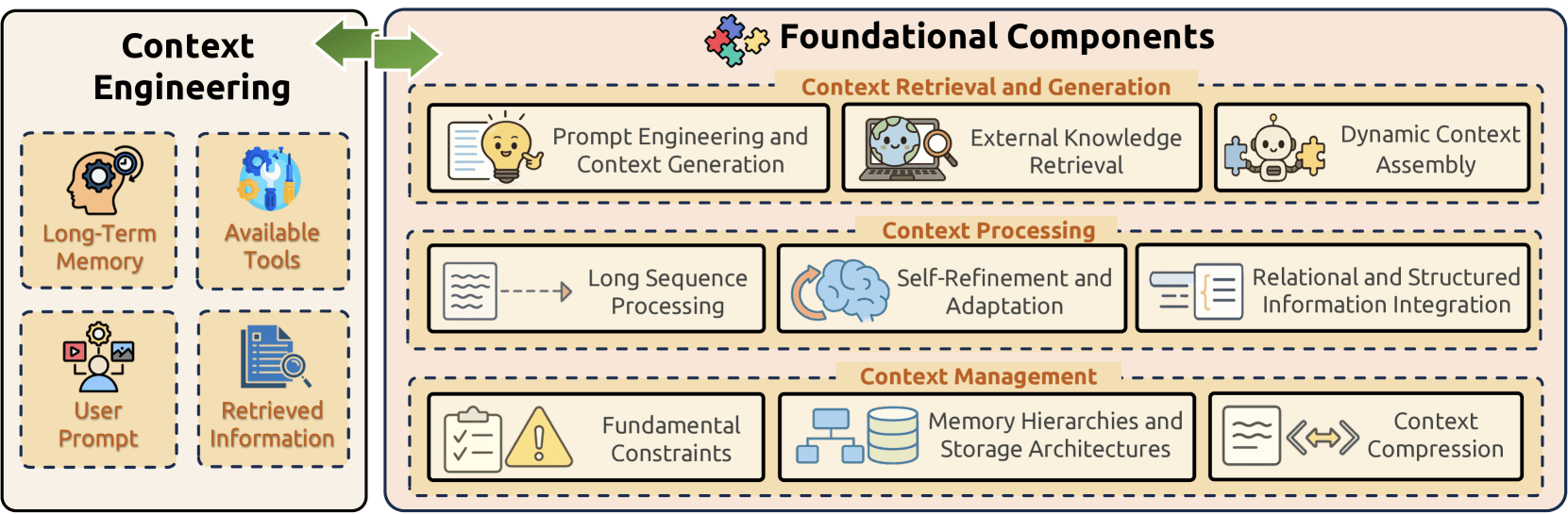
Componenti fondamentali
Il Context Engineering si basa su tre componenti fondamentali che, insieme, affrontano le principali sfide della gestione delle informazioni nei modelli linguistici di grandi dimensioni:
- Recupero e generazione del contesto reperisce informazioni contestuali appropriate attraverso il prompt engineering, il recupero di conoscenza esterna e l’assemblaggio dinamico del contesto;
- Elaborazione del contesto trasforma e ottimizza le informazioni acquisite attraverso l’elaborazione di sequenze lunghe, meccanismi di auto-perfezionamento e integrazione di dati strutturati;
- Gestione del contesto affronta l’organizzazione e l’utilizzo efficienti delle informazioni contestuali risolvendo vincoli fondamentali, implementando gerarchie di memoria sofisticate e sviluppando tecniche di compressione.
Sistemi complessi nella pratica
Al di sopra di questi componenti fondamentali, il context engineering viene applicato attraverso diversi tipi comuni di sistemi complessi.
Retrieval-augmented generation (RAG) consente a un modello di cercare informazioni in una knowledge base prima di rispondere a una domanda. Questo aiuta a garantire che la risposta si basi su dati reali e aggiornati invece che su supposizioni del modello. Nella pratica, RAG può essere costruito come semplici pipeline modulari, guidato da agenti che controllano il retrieval, oppure combinato con knowledge graph per un contesto più ricco.
I sistemi di memoria consentono ai modelli di tenere traccia delle informazioni attraverso le interazioni. La memoria a breve termine conserva i dettagli della conversazione corrente, mentre la memoria a lungo termine archivia le conversazioni passate e la conoscenza appresa. Questo rende le conversazioni multi-turno più coerenti e aiuta il sistema a migliorare nel tempo.
Il ragionamento integrato con strumenti consente ai modelli di utilizzare strumenti esterni come calcolatrici, motori di ricerca o API invece di basarsi solo sul ragionamento testuale. Una parte importante di questa configurazione consiste nel reinserire i risultati degli strumenti nel contesto al momento giusto, affinché il modello possa usarli in modo efficace.
I sistemi multi-agente utilizzano più modelli che lavorano insieme per gestire compiti complessi. Ogni agente ha un ruolo specifico e il sistema coordina il modo in cui comunicano, condividono informazioni e rimangono sincronizzati per produrre un risultato coerente.
Elaborazione del contesto
In precedenza, abbiamo introdotto le tre parti principali dell’ingegneria del contesto: recupero e generazione del contesto, elaborazione del contesto e gestione del contesto. Queste costituiscono i componenti di base di un sistema di contesto pratico.
L’elaborazione del contesto è particolarmente importante. Prende le informazioni grezze recuperate e le pulisce, le rimodella e le organizza affinché il modello possa comprenderle e utilizzarle in modo più efficiente.
In questa sezione, esaminiamo come viene svolta l’elaborazione del contesto nei sistemi reali e quali approcci vengono comunemente utilizzati.
Elaborazione di contesti lunghi
Elaborare contesti molto lunghi è costoso perché i modelli transformer usano la self-attention, che scala male al crescere della lunghezza dell’input. Man mano che la sequenza diventa più lunga, il calcolo e l’uso della memoria aumentano rapidamente, creando veri colli di bottiglia nei sistemi di produzione.
Ad esempio, espandere la lunghezza dell’input di Mistral-7B da 4K a 128K token aumenta il costo computazionale di circa 122×. Anche l’uso della memoria cresce bruscamente sia durante il prefilling sia durante il decoding. In pratica, modelli come Llama 3.1 8B possono richiedere fino a 16 GB di memoria per una singola richiesta da 128K token.
Per aggirare questi limiti, i ricercatori usano principalmente tre approcci.
Uno è costruire nuove architetture di modello, come Mamba, che siano più economiche da eseguire per progettazione. Un altro è usare tecniche come l’interpolazione posizionale per consentire ai modelli esistenti di gestire input molto più lunghi. Il terzo approccio migliora il modo in cui viene eseguito il calcolo, evitando lavoro ridondante e usando la memoria in modo più efficiente, così che l’elaborazione di contesti lunghi sia più veloce e usi meno risorse.
(1) Innovazioni architetturali per contesti lunghi
Per affrontare il costo quadratico dei Transformer, i ricercatori hanno sviluppato nuove architetture di modello che rendono l’elaborazione di sequenze lunghe meno costosa e più efficiente.
- I State Space Models (SSMs) mantengono una complessità computazionale lineare e requisiti di memoria costanti tramite stati nascosti di dimensione fissa, con modelli come Mamba che offrono meccanismi efficienti di calcolo ricorrente che scalano in modo più efficace rispetto ai transformer tradizionali.
- Gli approcci di dilated attention come LongNet impiegano campi attentivi che si espandono esponenzialmente all’aumentare della distanza tra token, ottenendo una complessità computazionale lineare pur mantenendo una dipendenza logaritmica tra token, rendendo possibile elaborare sequenze più lunghe di un miliardo di token.
- Le Toeplitz Neural Networks (TNNs) modellano le sequenze con matrici di Toeplitz a posizione relativa codificata, riducendo la complessità spazio-temporale a log-lineare e consentendo l’estrapolazione da 512 token di addestramento a 14.000 token di inferenza.
- I meccanismi di linear attention riducono la complessità da O(N²) a O(N) esprimendo la self-attention come prodotti scalari lineari di mappe di caratteristiche kernel, ottenendo uno speedup fino a 4000× durante l’elaborazione di sequenze molto lunghe.
Approcci alternativi come gli LLM senza attention superano le barriere quadratiche impiegando recursive memory transformers e altre innovazioni architetturali.
(2) Interpolazione posizionale ed estensione del contesto
Le tecniche di interpolazione posizionale consentono ai modelli di elaborare sequenze oltre i limiti della finestra di contesto originale riscalando in modo intelligente gli indici di posizione invece di estrapolare a posizioni non viste.
- Gli approcci basati su Neural Tangent Kernel (NTK) forniscono framework matematicamente fondati per l’estensione del contesto, con YaRN (Yet another RoPE-based Interpolation method) che combina l’interpolazione NTK con l’interpolazione lineare e la correzione della distribuzione dell’attenzione.
- Approcci a due stadi: LongRoPE raggiunge finestre di contesto da 2048K token attraverso approcci a due stadi: prima il fine-tuning dei modelli fino a una lunghezza di 256K, poi l’esecuzione dell’interpolazione posizionale per raggiungere la lunghezza massima del contesto.
- Position Sequence Tuning (PoSE) dimostra impressionanti estensioni della lunghezza della sequenza fino a 128K token combinando molteplici strategie di interpolazione posizionale.
- Le tecniche Self-Extend consentono agli LLM di elaborare contesti lunghi senza fine-tuning impiegando strategie di attenzione a due livelli—attenzione raggruppata e attenzione di vicinato—per catturare dipendenze tra token distanti e adiacenti.
(3) Tecniche di ottimizzazione per un’elaborazione efficiente
Senza modificare l’architettura centrale del modello, i ricercatori hanno anche sviluppato una gamma di tecniche di ottimizzazione per rendere più efficiente l’elaborazione di contesti lunghi.
Grouped-Query Attention (GQA) suddivide le teste di query in gruppi che condividono teste di chiave e valore, raggiungendo un equilibrio tra multi-query attention e multi-head attention e riducendo al contempo i requisiti di memoria durante la decodifica.
FlashAttention sfrutta la gerarchia asimmetrica della memoria GPU per ottenere uno scaling lineare della memoria invece di requisiti quadratici, con FlashAttention-2 che fornisce circa il doppio della velocità attraverso la riduzione delle operazioni non di moltiplicazione matriciale e una distribuzione del lavoro ottimizzata.
Ring Attention con Blockwise Transformers consente di gestire sequenze estremamente lunghe distribuendo il calcolo su più dispositivi, sfruttando il calcolo a blocchi e sovrapponendo la comunicazione al calcolo dell’attenzione.
Le tecniche di sparse attention includono Shifted sparse attention (S²-Attn) in LongLoRA e SinkLoRA con SF-Attn, che raggiungono il 92% del miglioramento della perplessità della full attention con significativi risparmi computazionali.
Gestione della memoria e compressione del contesto riducono il costo degli input lunghi. Rolling Buffer Cache limita la finestra di attenzione per ridurre la memoria della KV cache, mentre StreamingLLM supporta sequenze lunghe mantenendo solo i token chiave e il contesto recente. Altri metodi come Infini-attention e H2O migliorano l’efficienza attraverso memoria compressiva e un’eliminazione dalla cache più intelligente.
Auto-raffinamento e adattamento contestuali
L’auto-raffinamento consente agli LLM di migliorare gli output attraverso meccanismi di feedback ciclici che rispecchiano i processi di revisione umani, sfruttando l’autovalutazione tramite auto-interazione conversazionale mediante prompt engineering distinto dagli approcci di reinforcement learning.
L’idea è semplice: per compiti complessi, è più facile scrivere una prima versione e poi correggerla che ottenere tutto corretto al primo tentativo. Quando i modelli imparano a controllare il proprio lavoro e a migliorarlo passo dopo passo, ottengono prestazioni migliori nel ragionamento, nella scrittura di codice e nei compiti creativi, e si adattano più facilmente a nuove situazioni.
(1) Framework fondamentali di auto-raffinamento
- Il framework Self-Refine usa lo stesso modello come generatore, fornitore di feedback e raffinatore, dimostrando che identificare e correggere errori è spesso più facile che produrre soluzioni iniziali perfette.
- Reflexion mantiene testo riflessivo in buffer di memoria episodica per il processo decisionale futuro attraverso feedback linguistico, mentre una guida strutturata si dimostra essenziale poiché prompting semplicistici spesso non riescono a consentire un’auto-correzione affidabile.
- Il framework N-CRITICS implementa una valutazione basata su ensemble in cui gli output iniziali sono valutati sia dagli LLM generatori sia da altri modelli, con feedback compilato che guida il raffinamento finché non vengono soddisfatti criteri di arresto specifici del compito.
(2) Meta-learning ed evoluzione autonoma
In una fase più avanzata, l’auto-raffinamento del contesto si concentra sul meta-apprendimento e sul miglioramento autonomo. L’obiettivo è aiutare il modello non solo a risolvere compiti, ma anche a imparare come imparare meglio nel tempo.
SELF insegna agli LLM meta-competenze (auto-feedback, auto-raffinamento) con esempi limitati, poi fa sì che il modello si auto-evolva continuamente generando e filtrando i propri dati di addestramento. I meccanismi di auto-ricompensa consentono ai modelli di migliorare autonomamente tramite un auto-giudizio iterativo, in cui un singolo modello assume il doppio ruolo di esecutore e giudice, massimizzando le ricompense che assegna a se stesso.
Il framework Creator estende questo paradigma consentendo agli LLM di creare e utilizzare i propri strumenti attraverso un processo a quattro moduli che comprende creazione, processo decisionale, esecuzione e riconoscimento.
Il framework Self-Developing rappresenta l’approccio più autonomo, consentendo agli LLM di scoprire, implementare e perfezionare i propri algoritmi di miglioramento attraverso cicli iterativi che generano candidati algoritmici come codice eseguibile.
Contesto multimodale
I modelli linguistici di grandi dimensioni multimodali (MLLM) vanno oltre il testo lavorando con input come immagini, audio e dati 3D. Combinano questi diversi tipi di informazioni in un unico contesto su cui il modello può ragionare.
Questo rende possibili applicazioni più avanzate, ma comporta anche nuove sfide, come integrare diverse modalità, ragionare tra di esse e gestire input lunghi e complessi.
(1) Integrazione del contesto multimodale
L’integrazione del contesto è il nucleo dell’elaborazione del contesto multimodale. Mira a combinare informazioni provenienti da diverse modalità, come immagini, testo e audio, in un’unica rappresentazione con cui un modello può ragionare.
Un approccio di base trasforma le immagini in token utilizzando encoder come CLIP e poi le aggiunge ai token di testo prima di inviare tutto al modello linguistico. Questo è facile da implementare, ma le diverse modalità spesso rimangono collegate in modo lasco.
Metodi più avanzati migliorano l’integrazione. L’attenzione cross-modale consente al modello di apprendere relazioni dirette tra token visivi e testuali all’interno del modello, il che è importante per compiti come l’editing di immagini e il ragionamento visivo.
Per scalare a input lunghi o complessi, i design gerarchici elaborano ciascuna modalità per fasi. Alcuni sistemi uniscono anche informazioni provenienti da più immagini o input prima di passarle al modello, invece di gestirle separatamente una per una.
Altri lavori evitano del tutto di adattare modelli solo testuali addestrando fin dall’inizio su dati multimodali e testo insieme. Il ragionamento cross-modale si basa su questo, richiedendo al modello di comprendere non solo ciascuna modalità singolarmente, ma anche il significato che emerge quando vengono combinate, come il sarcasmo espresso attraverso sia un’immagine sia un testo.
(2) Encoder multimodali esterni e moduli di allineamento
L’integrazione del contesto multimodale si basa su due parti principali: encoder multimodali esterni e i moduli di allineamento che li collegano al modello linguistico.
Nella maggior parte dei sistemi attuali, ogni tipo di dato è gestito da un encoder dedicato. Per esempio, le immagini sono elaborate da modelli come CLIP, e l’audio è gestito da modelli come CLAP. Questi encoder trasformano input grezzi, come pixel o onde sonore, in vettori di caratteristiche.
I moduli di allineamento convertono poi queste caratteristiche nello spazio di embedding del modello linguistico, in modo che possano lavorare insieme ai token di testo. Alcuni sistemi usano mappature semplici come gli MLP, mentre altri usano Q-Former, che seleziona le caratteristiche visive più rilevanti per il testo utilizzando token di query apprendibili.
Questa configurazione modulare rende i sistemi più facili da mantenere. Gli encoder possono essere aggiornati o sostituiti senza riaddestrare l’intero modello linguistico, il che è importante per la distribuzione nel mondo reale.
Contesto relazionale e strutturato
I modelli linguistici di grandi dimensioni affrontano vincoli fondamentali nell’elaborazione di dati relazionali e strutturati, inclusi tabelle, database e grafi di conoscenza, a causa dei requisiti di input basati sul testo e delle limitazioni dell’architettura sequenziale.
La linearizzazione spesso non riesce a preservare relazioni complesse e proprietà strutturali, con prestazioni che peggiorano quando le informazioni sono disperse nei contesti.
Per risolvere questo problema, i ricercatori hanno cercato modi per rappresentare i dati strutturati in una forma utilizzabile dai modelli linguistici. L’obiettivo è aiutare i modelli a ottenere risultati migliori in compiti che coinvolgono ragionamento complesso e verifica dei fatti.
(1) Embedding di Knowledge Graph e integrazione neurale
Le strategie avanzate di codifica affrontano le limitazioni strutturali attraverso embedding di knowledge graph che trasformano entità e relazioni in vettori numerici, consentendo un’elaborazione efficiente all’interno delle architetture dei modelli linguistici.
Le reti neurali su grafi catturano relazioni complesse tra entità, facilitando il ragionamento multi-hop attraverso strutture di knowledge graph mediante architetture specializzate come GraphFormers, che annidano componenti GNN accanto a blocchi transformer.
(2) Verbalizzazione
Un approccio comune consiste nel trasformare dati strutturati—come knowledge graph, tabelle o record di database—in testo in linguaggio naturale, in modo che possano essere usati direttamente dai modelli linguistici esistenti senza modificarne l’architettura. Altri metodi riorganizzano il testo di input in livelli strutturati basati su relazioni linguistiche, oppure estraggono informazioni chiave e le rappresentano esplicitamente come grafi, tabelle o schemi relazionali.
In alcuni casi, rappresentare dati strutturati usando linguaggi di programmazione funziona meglio del linguaggio naturale. Ad esempio, usare codice Python per i knowledge graph o SQL per i database porta spesso a prestazioni migliori nei compiti di ragionamento complesso, perché questi formati preservano la struttura in modo più chiaro. Esistono anche approcci efficienti in termini di risorse che usano rappresentazioni matriciali compatte per gestire dati strutturati con meno parametri mantenendo al contempo buone prestazioni.
(3) Architetture ibride
Per gestire dati strutturati con relazioni complesse, come tabelle e knowledge graph, i ricercatori hanno esplorato architetture ibride che combinano grandi modelli linguistici con componenti progettati per dati strutturati a grafo, come le reti neurali su grafi.
Vengono usati diversi approcci pratici. GraphToken rende esplicite le relazioni aggiungendo token speciali, il che aiuta i modelli a ragionare sui grafi. Heterformer elabora testo e struttura del grafo insieme in un unico framework, mantenendo le informazioni sulle relazioni e controllando al contempo il costo computazionale.
Altri metodi integrano la conoscenza in modi diversi. K-BERT aggiunge informazioni del knowledge graph durante l’addestramento, in modo che il modello apprenda queste relazioni in anticipo. KAPING recupera conoscenza rilevante al momento dell’inferenza, senza riaddestramento. Progettazioni più avanzate usano adapter e attention per fondere le informazioni del grafo direttamente nel modello, portando a un’integrazione più stretta.
Conclusione
Il context engineering offre un modo utile per comprendere come funzionano i sistemi LLM in produzione. In generale, comprende tre processi principali: recupero e generazione del contesto, elaborazione del contesto e gestione del contesto. Insieme, questi passaggi determinano come le informazioni vengono raccolte, preparate e passate al modello.
Tra questi, l’elaborazione del contesto è particolarmente importante perché decide come le informazioni recuperate vengono ripulite, organizzate e compresse prima di raggiungere il modello. A causa dei limiti di spazio, questo articolo si è concentrato principalmente su questa parte e ha esaminato diversi approcci usati nei sistemi reali. Anche il recupero e la gestione del contesto sono aree importanti e possono essere approfondite in discussioni future.
Se stai costruendo sistemi RAG o agent e riscontri problemi in produzione legati a contesto, costi o latenza, unisciti al nostro canale Slack per discutere di context engineering con altri ingegneri. Puoi anche prenotare una breve sessione individuale per ricevere indicazioni pratiche su come passare dalle demo a sistemi pronti per la produzione tramite Milvus Office Hours.
Continua a leggere

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.

Cosmos World Foundation Model Platform for Physical AI
NVIDIA's Cosmos platform enables safe, digital twin training of GenAI models for physical applications, overcoming data scarcity and safety challenges.