




Come scegliere il miglior modello di embedding per RAG nel 2026: 10 modelli confrontati
TL;DR: Abbiamo testato 10 modelli di embedding in quattro scenari di produzione che i benchmark pubblici non coprono: recupero cross-modale, recupero cross-linguale, recupero di informazioni chiave e compressione delle dimensioni. Nessun singolo modello vince su tutto. Gemini Embedding 2 è il migliore tuttofare. Qwen3-VL-2B open-source supera le API closed-source nei task cross-modali. Se devi comprimere le dimensioni per risparmiare spazio di archiviazione, scegli Voyage Multimodal 3.5 o Jina Embeddings v4.
Perché MTEB non basta per scegliere un modello di embedding
La maggior parte dei prototipi RAG parte da text-embedding-3-small di OpenAI. È economico, facile da integrare e, per il recupero di testo in inglese, funziona abbastanza bene. Ma il RAG in produzione lo supera rapidamente. La tua pipeline acquisisce immagini, PDF, documenti multilingue — e un modello di embedding solo testuale smette di essere sufficiente.
La classifica MTEB ti dice che esistono opzioni migliori. Il problema? MTEB testa solo il recupero di testo in una singola lingua. Non copre il recupero cross-modale (query testuali su raccolte di immagini), la ricerca cross-linguale (una query in cinese che trova un documento in inglese), l'accuratezza su documenti lunghi, né quanta qualità perdi quando tronchi le dimensioni degli embedding per risparmiare spazio di archiviazione nel tuo database vettoriale.
Quindi quale modello di embedding dovresti usare? Dipende dai tipi di dati, dalle lingue, dalla lunghezza dei documenti e dal fatto che tu abbia bisogno o meno della compressione delle dimensioni. Abbiamo creato un benchmark chiamato CCKM e testato 10 modelli rilasciati tra il 2025 e il 2026 esattamente su queste dimensioni.
Che cos'è il benchmark CCKM?
CCKM (Cross-modal, Cross-lingual, Key information, MRL) testa quattro capacità che i benchmark standard non coprono:
| Dimensione | Cosa testa | Perché è importante |
|---|---|---|
| Recupero cross-modale | Abbina descrizioni testuali all'immagine corretta quando sono presenti distrattori quasi identici | Le pipeline RAG multimodali hanno bisogno di embedding di testo e immagini nello stesso spazio vettoriale |
| Recupero cross-linguale | Trova il documento inglese corretto a partire da una query in cinese, e viceversa | Le basi di conoscenza in produzione sono spesso multilingue |
| Recupero di informazioni chiave | Individua un fatto specifico nascosto in un documento da 4K–32K caratteri (ago nel pagliaio) | I sistemi RAG elaborano frequentemente documenti lunghi come contratti e articoli di ricerca |
| Compressione dimensionale MRL | Misura quanta qualità perde il modello quando tronchi gli embedding a 256 dimensioni | Meno dimensioni = costo di archiviazione inferiore nel tuo database vettoriale, ma a quale costo in termini di qualità? |
MTEB non copre nulla di tutto questo. MMEB aggiunge il multimodale ma salta i negativi difficili, quindi i modelli ottengono punteggi elevati senza dimostrare di gestire distinzioni sottili. CCKM è progettato per coprire ciò che questi non coprono.
Quali modelli di embedding abbiamo testato? Gemini Embedding 2, Jina Embeddings v4 e altri
Abbiamo testato 10 modelli che coprono sia servizi API sia opzioni open-source, più CLIP ViT-L-14 come baseline del 2021.
| Modello | Fonte | Parametri | Dimensioni | Modalità | Caratteristica principale |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Non divulgati | 3072 | Testo / immagine / video / audio / PDF | Tutte le modalità, copertura più ampia | |
| Jina Embeddings v4 | Jina AI | 3.8B | 2048 | Testo / immagine / PDF | MRL + adattatori LoRA |
| Voyage Multimodal 3.5 | Voyage AI (MongoDB) | Non divulgati | 1024 | Testo / immagine / video | Bilanciato tra le attività |
| Qwen3-VL-Embedding-2B | Alibaba Qwen | 2B | 2048 | Testo / immagine / video | Open-source, multimodale leggero |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | Testo / immagine | Architettura CLIP modernizzata |
| Cohere Embed v4 | Cohere | Non divulgati | Fisse | Testo | Recupero enterprise |
| OpenAI text-embedding-3-large | OpenAI | Non divulgati | 3072 | Testo | Il più usato |
| BGE-M3 | BAAI | 568M | 1024 | Testo | Open-source, oltre 100 lingue |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | Testo | Leggero, focalizzato sull'inglese |
| nomic-embed-text | Nomic AI | 137M | 768 | Testo | Ultralleggero |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | Testo / immagine | Baseline |
Recupero cross-modale: quali modelli gestiscono la ricerca da testo a immagine?
Se la tua pipeline RAG gestisce immagini insieme al testo, il modello di embedding deve collocare entrambe le modalità nello stesso spazio vettoriale. Pensa alla ricerca di immagini nell'e-commerce, a basi di conoscenza miste immagine-testo o a qualsiasi sistema in cui una query testuale deve trovare l'immagine giusta.
Metodo
Abbiamo preso 200 coppie immagine-testo da COCO val2017. Per ogni immagine, GPT-4o-mini ha generato una descrizione dettagliata. Poi abbiamo scritto 3 negativi difficili per immagine — descrizioni che differiscono da quella corretta per solo uno o due dettagli. Il modello deve trovare la corrispondenza giusta in un pool di 200 immagini e 600 distrattori.
Un esempio dal dataset:
 Valigie vintage in pelle marrone con adesivi di viaggio tra cui California e Cuba, posizionate su un portabagagli metallico contro un cielo blu — usate come immagine di test nel benchmark di recupero cross-modale
Valigie vintage in pelle marrone con adesivi di viaggio tra cui California e Cuba, posizionate su un portabagagli metallico contro un cielo blu — usate come immagine di test nel benchmark di recupero cross-modale
Descrizione corretta: "L'immagine mostra valigie vintage in pelle marrone con vari adesivi di viaggio tra cui 'California', 'Cuba' e 'New York', posizionate su un portabagagli metallico contro un cielo azzurro limpido."
Negativo difficile: Stessa frase, ma "California" diventa "Florida" e "cielo blu" diventa "cielo coperto." Il modello deve comprendere davvero i dettagli dell'immagine per distinguerli.
Valutazione:
- Genera embedding per tutte le immagini e tutto il testo (200 descrizioni corrette + 600 negativi difficili).
- Testo-a-immagine (t2i): Ogni descrizione cerca tra 200 immagini la corrispondenza più vicina. Assegna un punto se il risultato principale è corretto.
- Immagine-a-testo (i2t): Ogni immagine cerca tra tutti gli 800 testi la corrispondenza più vicina. Assegna un punto solo se il risultato principale è la descrizione corretta, non un negativo difficile.
- Punteggio finale: hard_avg_R@1 = (accuratezza t2i + accuratezza i2t) / 2
Risultati
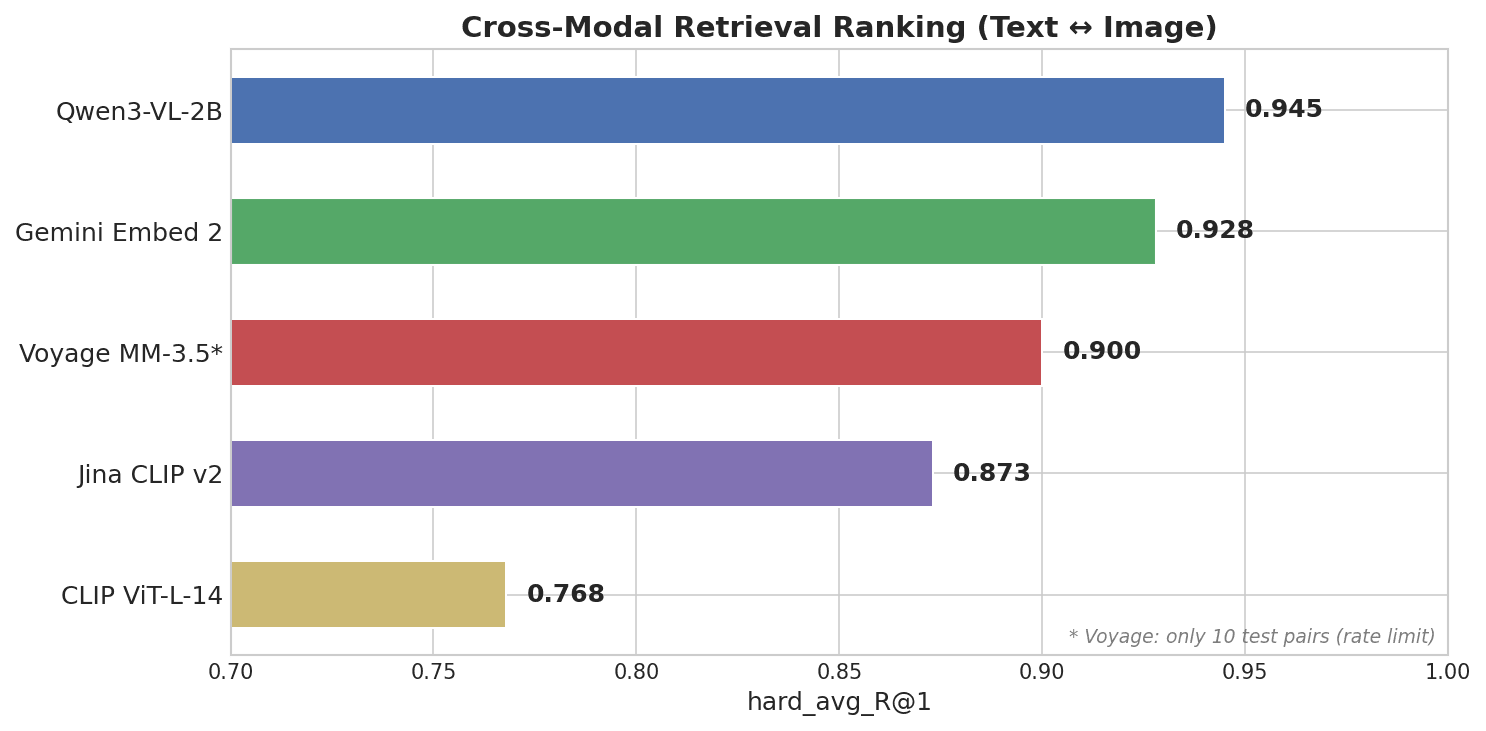 Grafico a barre orizzontali che mostra la classifica del recupero cross-modale: Qwen3-VL-2B guida con 0,945, seguito da Gemini Embed 2 con 0,928, Voyage MM-3.5 con 0,900, Jina CLIP v2 con 0,873 e CLIP ViT-L-14 con 0,768
Grafico a barre orizzontali che mostra la classifica del recupero cross-modale: Qwen3-VL-2B guida con 0,945, seguito da Gemini Embed 2 con 0,928, Voyage MM-3.5 con 0,900, Jina CLIP v2 con 0,873 e CLIP ViT-L-14 con 0,768
Qwen3-VL-2B, un modello open-source da 2B parametri del team Qwen di Alibaba, si è classificato primo — davanti a ogni API closed-source.
Il divario di modalità spiega la maggior parte della differenza. I modelli di embedding mappano testo e immagini nello stesso spazio vettoriale, ma in pratica le due modalità tendono a raggrupparsi in regioni diverse. Il divario di modalità misura la distanza L2 tra questi due cluster. Divario più piccolo = recupero cross-modale più facile.
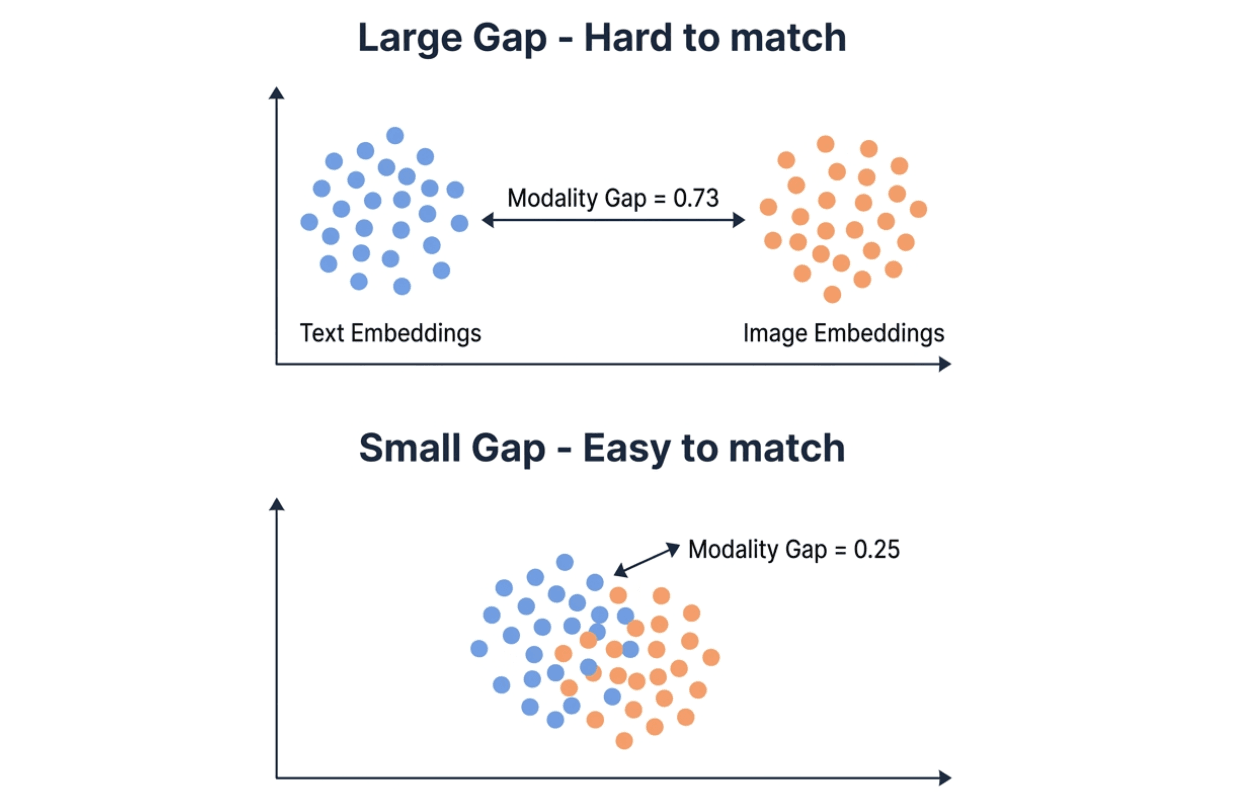 Visualizzazione che confronta un ampio gap di modalità (0,73, cluster di embedding di testo e immagini molto distanti) rispetto a un piccolo gap di modalità (0,25, cluster sovrapposti) — un gap più piccolo rende più facile il matching cross-modale
Visualizzazione che confronta un ampio gap di modalità (0,73, cluster di embedding di testo e immagini molto distanti) rispetto a un piccolo gap di modalità (0,25, cluster sovrapposti) — un gap più piccolo rende più facile il matching cross-modale
| Modello | Punteggio (R@1) | Gap di modalità | Parametri |
|---|---|---|---|
| Qwen3-VL-2B | 0.945 | 0.25 | 2B (open source) |
| Gemini Embedding 2 | 0.928 | 0.73 | Sconosciuti (chiuso) |
| Voyage Multimodal 3.5 | 0.900 | 0.59 | Sconosciuti (chiuso) |
| Jina CLIP v2 | 0.873 | 0.87 | ~1B |
| CLIP ViT-L-14 | 0.768 | 0.83 | 428M |
Il gap di modalità di Qwen è 0,25 — circa un terzo dello 0,73 di Gemini. In un database vettoriale come Milvus, un piccolo gap di modalità significa che puoi memorizzare embedding di testo e immagini nella stessa raccolta e cercare direttamente in entrambi. Un gap ampio può rendere meno affidabile la ricerca di similarità cross-modale, e potresti aver bisogno di un passaggio di ri-ranking per compensare.
Retrieval cross-lingue: quali modelli allineano il significato tra le lingue?
Le basi di conoscenza multilingue sono comuni in produzione. Un utente pone una domanda in cinese, ma la risposta si trova in un documento inglese — o viceversa. Il modello di embedding deve allineare il significato tra le lingue, non solo all'interno di una sola.
Metodo
Abbiamo costruito 166 coppie di frasi parallele in cinese e inglese su tre livelli di difficoltà:
 Livelli di difficoltà cross-lingue: il livello Facile mappa traduzioni letterali come 我爱你 a I love you; il livello Medio mappa frasi parafrasate come 这道菜太咸了 a This dish is too salty con hard negative; il livello Difficile mappa idiomi cinesi come 画蛇添足 a gilding the lily con hard negative semanticamente diversi
Livelli di difficoltà cross-lingue: il livello Facile mappa traduzioni letterali come 我爱你 a I love you; il livello Medio mappa frasi parafrasate come 这道菜太咸了 a This dish is too salty con hard negative; il livello Difficile mappa idiomi cinesi come 画蛇添足 a gilding the lily con hard negative semanticamente diversi
Ogni lingua riceve anche 152 distrattori hard negative.
Punteggio:
- Genera embedding per tutto il testo cinese (166 corretti + 152 distrattori) e tutto il testo inglese (166 corretti + 152 distrattori).
- Cinese → Inglese: Ogni frase cinese cerca tra 318 testi inglesi la sua traduzione corretta.
- Inglese → Cinese: Lo stesso al contrario.
- Punteggio finale: hard_avg_R@1 = (accuratezza zh→en + accuratezza en→zh) / 2
Risultati
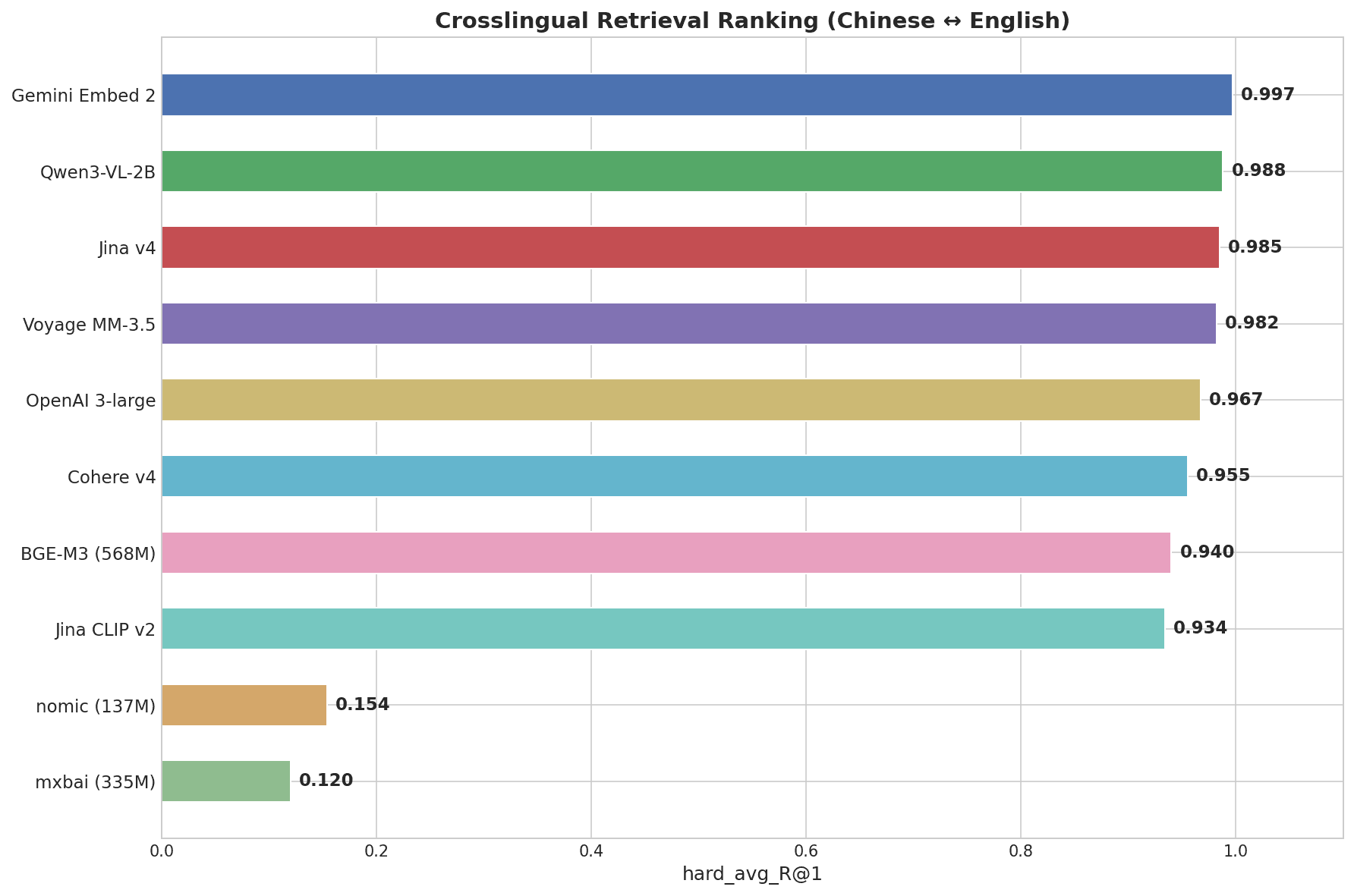 Grafico a barre orizzontali che mostra il ranking del retrieval cross-lingue: Gemini Embed 2 in testa con 0,997, seguito da Qwen3-VL-2B con 0,988, Jina v4 con 0,985, Voyage MM-3.5 con 0,982, fino a mxbai con 0,120
Grafico a barre orizzontali che mostra il ranking del retrieval cross-lingue: Gemini Embed 2 in testa con 0,997, seguito da Qwen3-VL-2B con 0,988, Jina v4 con 0,985, Voyage MM-3.5 con 0,982, fino a mxbai con 0,120
Gemini Embedding 2 ha ottenuto 0,997 — il valore più alto di qualsiasi modello testato. È stato l'unico modello a ottenere un perfetto 1,000 nel livello Difficile, dove coppie come "画蛇添足" → "gilding the lily" richiedono una reale comprensione semantica tra lingue, non pattern matching.
| Modello | Punteggio (R@1) | Facile | Medio | Difficile (idiomi) |
|---|---|---|---|---|
| Gemini Embedding 2 | 0.997 | 1.000 | 1.000 | 1.000 |
| Qwen3-VL-2B | 0.988 | 1.000 | 1.000 | 0.969 |
| Jina Embeddings v4 | 0.985 | 1.000 | 1.000 | 0.969 |
| Voyage Multimodal 3.5 | 0.982 | 1.000 | 1.000 | 0.938 |
| OpenAI 3-large | 0.967 | 1.000 | 1.000 | 0.906 |
| Cohere Embed v4 | 0.955 | 1.000 | 0.980 | 0.875 |
| BGE-M3 (568M) | 0.940 | 1.000 | 0.960 | 0.844 |
| nomic-embed-text (137M) | 0.154 | 0.300 | 0.120 | 0.031 |
| mxbai-embed-large (335M) | 0.120 | 0.220 | 0.080 | 0.031 |
I primi 7 modelli superano tutti 0,93 nel punteggio complessivo — la vera differenziazione avviene nel livello Difficile (idiomi cinesi). nomic-embed-text e mxbai-embed-large, entrambi modelli leggeri focalizzati sull'inglese, ottengono punteggi vicini allo zero nei task cross-lingue.
Retrieval di informazioni chiave: i modelli riescono a trovare un ago in un documento da 32K token?
I sistemi RAG elaborano spesso documenti lunghi — contratti legali, articoli di ricerca, report interni contenenti dati non strutturati. La domanda è se un modello di embedding riesca ancora a trovare un fatto specifico sepolto tra migliaia di caratteri di testo circostante.
Metodo
Abbiamo preso articoli di Wikipedia di lunghezze variabili (da 4K a 32K caratteri) come pagliaio e inserito un singolo fatto fabbricato — l'ago — in posizioni diverse: inizio, 25%, 50%, 75% e fine. Il modello deve determinare, in base a un embedding della query, quale versione del documento contiene l'ago.
Esempio:
- Ago: "The Meridian Corporation reported quarterly revenue of $847.3 million in Q3 2025."
- Query: "What was Meridian Corporation's quarterly revenue?"
- Pagliaio: Un articolo di Wikipedia di 32.000 caratteri sulla fotosintesi, con l'ago nascosto da qualche parte al suo interno.
Punteggio:
- Generare embedding per la query, il documento con l'ago e il documento senza.
- Se la query è più simile al documento che contiene l'ago, contarlo come un risultato positivo.
- Calcolare l'accuratezza media su tutte le lunghezze dei documenti e le posizioni dell'ago.
- Metriche finali: overall_accuracy e degradation_rate (quanto cala l'accuratezza dal documento più corto a quello più lungo).
Risultati
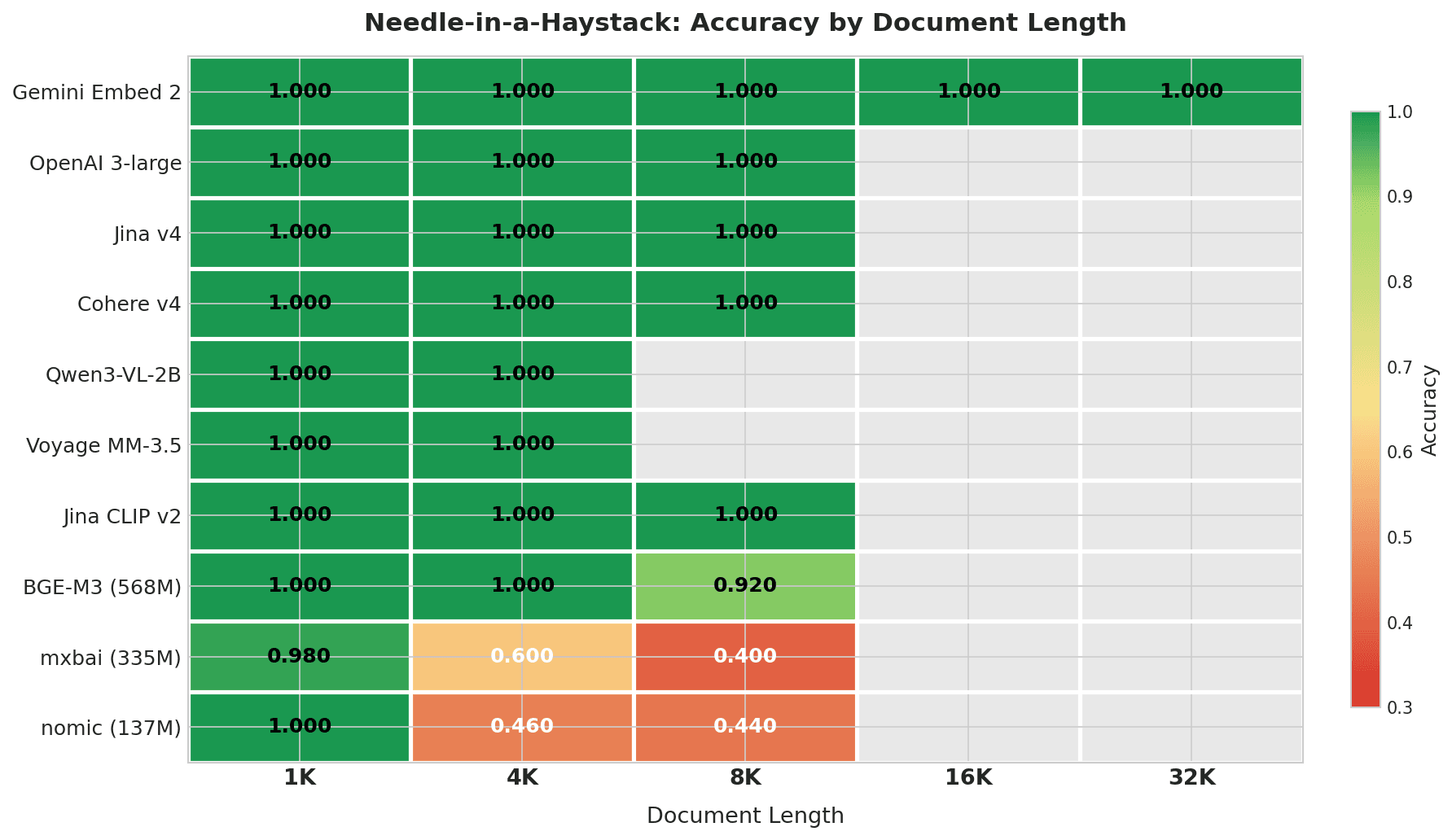 Heatmap che mostra l'accuratezza Needle-in-a-Haystack per lunghezza del documento: Gemini Embed 2 ottiene 1.000 su tutte le lunghezze fino a 32K; i 7 modelli migliori ottengono punteggi perfetti entro le rispettive finestre di contesto; mxbai e nomic degradano bruscamente a 4K+
Heatmap che mostra l'accuratezza Needle-in-a-Haystack per lunghezza del documento: Gemini Embed 2 ottiene 1.000 su tutte le lunghezze fino a 32K; i 7 modelli migliori ottengono punteggi perfetti entro le rispettive finestre di contesto; mxbai e nomic degradano bruscamente a 4K+
Gemini Embedding 2 è l'unico modello testato sull'intero intervallo 4K–32K e ha ottenuto un punteggio perfetto a ogni lunghezza. Nessun altro modello in questo test ha una finestra di contesto che raggiunge 32K.
| Modello | 1K | 4K | 8K | 16K | 32K | Complessivo | Degrado |
|---|---|---|---|---|---|---|---|
| Gemini Embedding 2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0% |
| OpenAI 3-large | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Jina Embeddings v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Cohere Embed v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Qwen3-VL-2B | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Voyage Multimodal 3.5 | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Jina CLIP v2 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| BGE-M3 (568M) | 1.000 | 1.000 | 0.920 | — | — | 0.973 | 8% |
| mxbai-embed-large (335M) | 0.980 | 0.600 | 0.400 | — | — | 0.660 | 58% |
| nomic-embed-text (137M) | 1.000 | 0.460 | 0.440 | — | — | 0.633 | 56% |
"—" significa che la lunghezza del documento supera la finestra di contesto del modello.
I 7 modelli migliori ottengono punteggi perfetti entro le rispettive finestre di contesto. BGE-M3 inizia a perdere terreno a 8K (0.920). I modelli leggeri (mxbai e nomic) scendono a 0.4–0.6 già a 4K caratteri — circa 1.000 token. Per mxbai, questo calo riflette in parte la sua finestra di contesto da 512 token che tronca la maggior parte del documento.
Compressione dimensionale MRL: quanta qualità si perde a 256 dimensioni?
Matryoshka Representation Learning (MRL) è una tecnica di addestramento che rende le prime N dimensioni di un vettore significative da sole. Prendi un vettore da 3072 dimensioni, troncato a 256, e conserva comunque gran parte della sua qualità semantica. Meno dimensioni significano costi di storage e memoria inferiori nel tuo database vettoriale — passare da 3072 a 256 dimensioni corrisponde a una riduzione dello storage di 12 volte.
 Illustrazione che mostra il troncamento dimensionale MRL: 3072 dimensioni a qualità piena, 1024 al 95%, 512 al 90%, 256 all'85% — con risparmi di storage di 12 volte a 256 dimensioni
Illustrazione che mostra il troncamento dimensionale MRL: 3072 dimensioni a qualità piena, 1024 al 95%, 512 al 90%, 256 all'85% — con risparmi di storage di 12 volte a 256 dimensioni
Metodo
Abbiamo utilizzato 150 coppie di frasi dal benchmark STS-B, ciascuna con un punteggio di similarità annotato da esseri umani (0–5). Per ogni modello, abbiamo generato embedding a dimensioni complete, poi li abbiamo troncati a 1024, 512 e 256.
 Esempi di dati STS-B che mostrano coppie di frasi con punteggi di similarità umani: A girl is styling her hair vs A girl is brushing her hair punteggio 2.5; A group of men play soccer on the beach vs A group of boys are playing soccer on the beach punteggio 3.6
Esempi di dati STS-B che mostrano coppie di frasi con punteggi di similarità umani: A girl is styling her hair vs A girl is brushing her hair punteggio 2.5; A group of men play soccer on the beach vs A group of boys are playing soccer on the beach punteggio 3.6
Punteggio:
- A ogni livello di dimensione, calcola la similarità coseno tra gli embedding di ciascuna coppia di frasi.
- Confronta il ranking di similarità del modello con il ranking umano usando ρ di Spearman (correlazione di rango).
Che cos'è ρ di Spearman? Misura quanto due ranking concordano. Se gli esseri umani classificano la coppia A come la più simile, B seconda, C meno simile — e le similarità coseno del modello producono lo stesso ordine A > B > C — allora ρ si avvicina a 1.0. Un ρ di 1.0 significa accordo perfetto. Un ρ di 0 significa nessuna correlazione.
Metriche finali: spearman_rho (più alto è meglio) e min_viable_dim (la dimensione più piccola in cui la qualità rimane entro il 5% delle prestazioni a dimensione completa).
Risultati
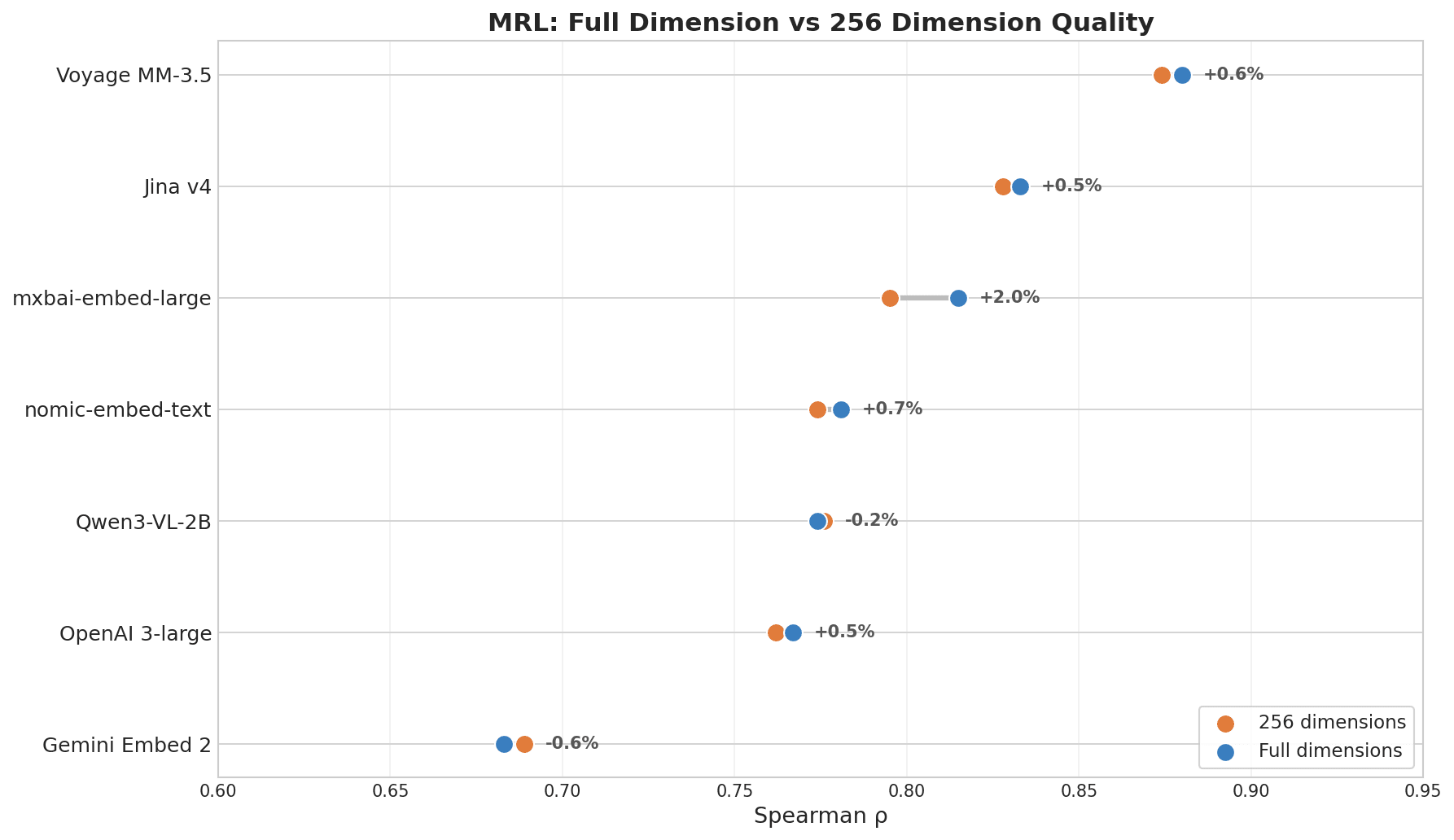 Grafico a punti che mostra la qualità MRL a dimensione completa vs a 256 dimensioni: Voyage MM-3.5 è in testa con una variazione del +0.6%, Jina v4 +0.5%, mentre Gemini Embed 2 mostra -0.6% in fondo
Grafico a punti che mostra la qualità MRL a dimensione completa vs a 256 dimensioni: Voyage MM-3.5 è in testa con una variazione del +0.6%, Jina v4 +0.5%, mentre Gemini Embed 2 mostra -0.6% in fondo
Se stai pianificando di ridurre i costi di archiviazione in Milvus o in un altro database vettoriale troncando le dimensioni, questo risultato è importante.
| Modello | ρ (dim completa) | ρ (256 dim) | Decadimento |
|---|---|---|---|
| Voyage Multimodal 3.5 | 0.880 | 0.874 | 0.7% |
| Jina Embeddings v4 | 0.833 | 0.828 | 0.6% |
| mxbai-embed-large (335M) | 0.815 | 0.795 | 2.5% |
| nomic-embed-text (137M) | 0.781 | 0.774 | 0.8% |
| OpenAI 3-large | 0.767 | 0.762 | 0.6% |
| Gemini Embedding 2 | 0.683 | 0.689 | -0.8% |
Voyage e Jina v4 sono in testa perché entrambi sono stati addestrati esplicitamente con MRL come obiettivo. La compressione delle dimensioni ha poco a che fare con la dimensione del modello — ciò che conta è se il modello è stato addestrato per farlo.
Una nota sul punteggio di Gemini: il ranking MRL riflette quanto bene un modello preserva la qualità dopo il troncamento, non quanto sia buona la sua retrieval a dimensione completa. La retrieval a dimensione completa di Gemini è forte — i risultati cross-lingual e sulle informazioni chiave lo hanno già dimostrato. Semplicemente non è stato ottimizzato per la riduzione. Se non hai bisogno della compressione delle dimensioni, questa metrica non si applica a te.
Quale modello di embedding dovresti usare?
Nessun singolo modello vince in tutto. Ecco la scorecard completa:
| Modello | Params | Cross-Modal | Cross-Lingual | Informazioni chiave | ρ MRL |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Undisclosed | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage Multimodal 3.5 | Undisclosed | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina Embeddings v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| OpenAI 3-large | Undisclosed | — | 0.967 | 1.000 | 0.760 |
| Cohere Embed v4 | Undisclosed | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
"—" significa che il modello non supporta quella modalità o capacità. CLIP è un baseline del 2021 come riferimento.
Ecco cosa emerge:
- Cross-modale: Qwen3-VL-2B (0,945) primo, Gemini (0,928) secondo, Voyage (0,900) terzo. Un modello open-source da 2B ha battuto ogni API closed-source. Il fattore decisivo è stato il divario di modalità, non il numero di parametri.
- Cross-linguale: Gemini (0,997) è in testa — l’unico modello a ottenere un punteggio perfetto nell’allineamento a livello di espressioni idiomatiche. I primi 8 modelli superano tutti 0,93. I modelli leggeri solo in inglese ottengono punteggi vicini allo zero.
- Informazioni chiave: le API e i grandi modelli open-source ottengono punteggi perfetti fino a 8K. I modelli sotto i 335M iniziano a degradare a 4K. Gemini è l’unico modello che gestisce 32K con un punteggio perfetto.
- Compressione dimensionale MRL: Voyage (0,880) e Jina v4 (0,833) sono in testa, perdendo meno dell’1% a 256 dimensioni. Gemini (0,668) arriva ultimo — forte a piena dimensione, non ottimizzato per il troncamento.
Come scegliere: un diagramma di flusso decisionale
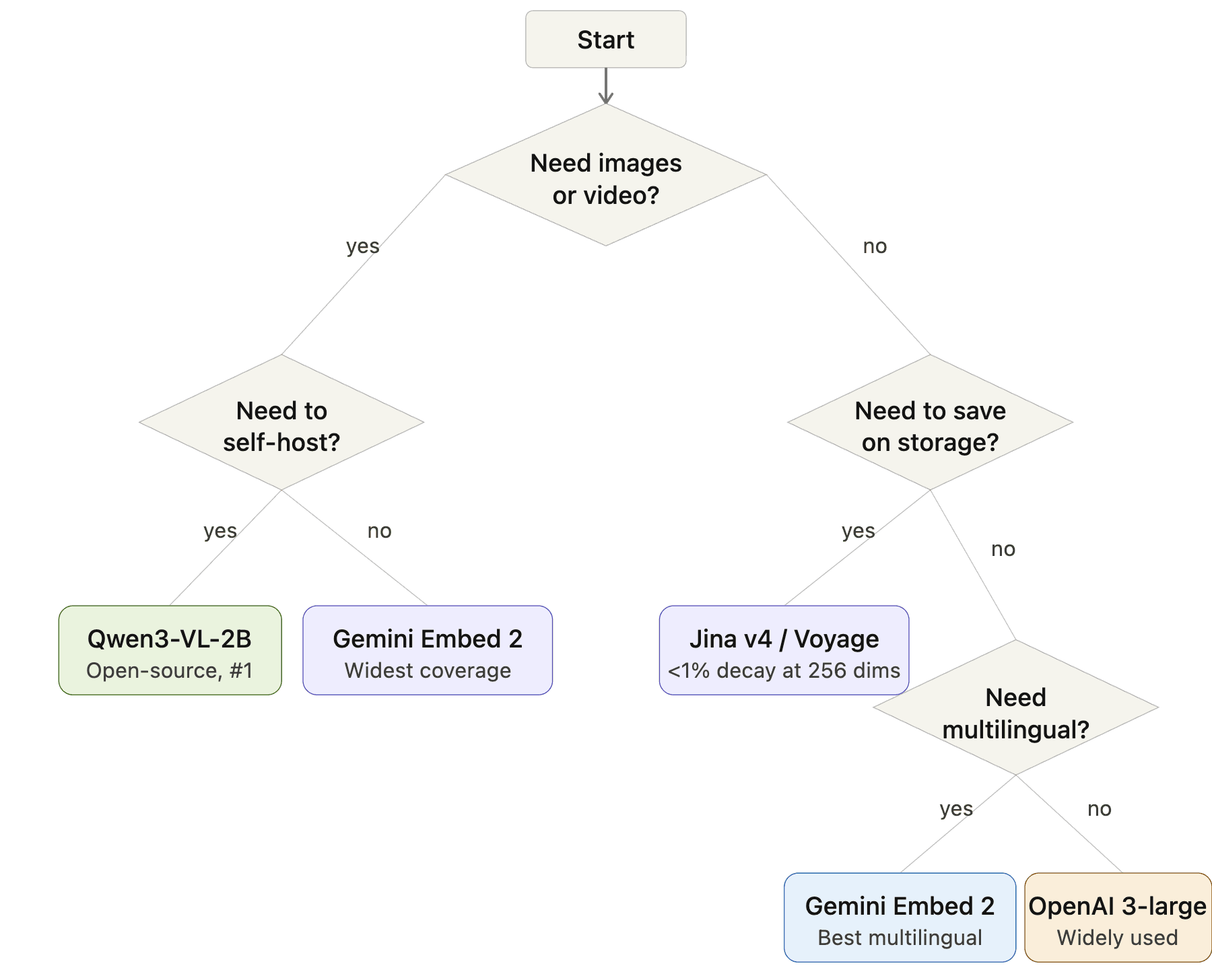 Diagramma di flusso per la selezione del modello di embedding: Inizio → Servono immagini o video? → Sì: Devi fare self-hosting? → Sì: Qwen3-VL-2B, No: Gemini Embedding 2. Niente immagini → Devi risparmiare spazio di archiviazione? → Sì: Jina v4 o Voyage, No: Serve il multilingue? → Sì: Gemini Embedding 2, No: OpenAI 3-large
Diagramma di flusso per la selezione del modello di embedding: Inizio → Servono immagini o video? → Sì: Devi fare self-hosting? → Sì: Qwen3-VL-2B, No: Gemini Embedding 2. Niente immagini → Devi risparmiare spazio di archiviazione? → Sì: Jina v4 o Voyage, No: Serve il multilingue? → Sì: Gemini Embedding 2, No: OpenAI 3-large
Il miglior tuttofare: Gemini Embedding 2
Nel complesso, Gemini Embedding 2 è il modello complessivamente più forte in questo benchmark.
Punti di forza: primo nel cross-linguale (0,997) e nel recupero di informazioni chiave (1,000 su tutte le lunghezze fino a 32K). Secondo nel cross-modale (0,928). La copertura di modalità più ampia — cinque modalità (testo, immagine, video, audio, PDF), mentre la maggior parte dei modelli si ferma a tre.
Punti deboli: ultimo nella compressione MRL (ρ = 0,668). Superato nel cross-modale dall’open-source Qwen3-VL-2B.
Se non hai bisogno di compressione dimensionale, Gemini non ha veri concorrenti nella combinazione di recupero cross-linguale + documenti lunghi. Ma per la precisione cross-modale o l’ottimizzazione dello storage, i modelli specializzati fanno meglio.
Limitazioni
- Non abbiamo incluso tutti i modelli che vale la pena considerare — NV-Embed-v2 di NVIDIA e v5-text di Jina erano nella lista, ma non sono rientrati in questo round.
- Ci siamo concentrati sulle modalità testo e immagine; embedding di video, audio e PDF (nonostante alcuni modelli dichiarino il supporto) non sono stati coperti.
- Il recupero di codice e altri scenari specifici di dominio erano fuori ambito.
- Le dimensioni dei campioni erano relativamente piccole, quindi differenze di ranking ristrette tra i modelli possono rientrare nel rumore statistico.
I risultati di questo articolo saranno obsoleti entro un anno. Nuovi modelli vengono rilasciati costantemente, e la classifica si rimescola a ogni release. L’investimento più duraturo è costruire la tua pipeline di valutazione — definisci i tuoi tipi di dati, i tuoi pattern di query, le lunghezze dei tuoi documenti e sottoponi i nuovi modelli ai tuoi test quando escono. I benchmark pubblici come MTEB, MMTEB e MMEB valgono la pena di essere monitorati, ma la decisione finale dovrebbe sempre venire dai tuoi dati.
Il nostro codice di benchmark è open-source su GitHub — fai un fork e adattalo al tuo caso d’uso.
Una volta scelto il tuo modello di embedding, hai bisogno di un posto dove archiviare e cercare quei vettori su larga scala. Milvus è il database vettoriale open-source più adottato al mondo, con 43K+ stelle su GitHub, costruito esattamente per questo — supporta dimensioni troncate con MRL, raccolte multimodali miste, ricerca ibrida che combina vettori densi e sparsi, e scala da un laptop a miliardi di vettori.
- Inizia con la guida Quickstart di Milvus, oppure installa con
pip install pymilvus. - Unisciti a Milvus Slack o Milvus Discord per fare domande sull’integrazione dei modelli di embedding, sulle strategie di indicizzazione vettoriale o sulla scalabilità in produzione.
- Prenota una sessione gratuita di Milvus Office Hours per esaminare la tua architettura RAG — possiamo aiutarti con la selezione del modello, la progettazione dello schema delle collection e l’ottimizzazione delle prestazioni.
- Se preferisci saltare il lavoro sull’infrastruttura, Zilliz Cloud (Milvus gestito) offre un piano gratuito per iniziare.
Alcune domande che emergono quando gli ingegneri scelgono un modello di embedding per RAG in produzione:
D: Dovrei usare un modello di embedding multimodale anche se al momento ho solo dati testuali?
Dipende dalla tua roadmap. Se la tua pipeline probabilmente aggiungerà immagini, PDF o altre modalità entro i prossimi 6–12 mesi, iniziare con un modello multimodale come Gemini Embedding 2 o Voyage Multimodal 3.5 evita una migrazione dolorosa in seguito — non dovrai ricreare gli embedding dell’intero dataset. Se sei sicuro che resterà solo testuale per il futuro prevedibile, un modello focalizzato sul testo come OpenAI 3-large o Cohere Embed v4 ti offrirà un miglior rapporto prezzo/prestazioni.
D: Quanto spazio di archiviazione fa effettivamente risparmiare la compressione dimensionale MRL in un database vettoriale?
Passare da 3072 dimensioni a 256 dimensioni comporta una riduzione di 12 volte dello spazio di archiviazione per vettore. Per una collection Milvus con 100 milioni di vettori in float32, ciò equivale circa a 1,14 TB → 95 GB. Il punto chiave è che non tutti i modelli gestiscono bene il troncamento — Voyage Multimodal 3.5 e Jina Embeddings v4 perdono meno dell’1% di qualità a 256 dimensioni, mentre altri degradano in modo significativo.
D: Qwen3-VL-2B è davvero migliore di Gemini Embedding 2 per la ricerca cross-modale?
Nel nostro benchmark, sì — Qwen3-VL-2B ha ottenuto 0,945 contro lo 0,928 di Gemini nel recupero cross-modale difficile con distrattori quasi identici. Il motivo principale è il gap di modalità molto più piccolo di Qwen (0,25 vs 0,73), il che significa che testo e immagine embeddings si raggruppano più vicini nello spazio vettoriale. Detto questo, Gemini copre cinque modalità mentre Qwen ne copre tre, quindi se hai bisogno di embedding per audio o PDF, Gemini è l’unica opzione.
D: Posso usare questi modelli di embedding direttamente con Milvus?
Sì. Tutti questi modelli producono vettori float standard, che puoi inserire in Milvus e cercare con similarità coseno, distanza L2 o prodotto interno. PyMilvus funziona con qualsiasi modello di embedding — genera i tuoi vettori con l’SDK del modello, poi archiviali e cercali in Milvus. Per i vettori troncati con MRL, imposta semplicemente la dimensione della collection sul tuo target (ad es., 256) quando crei la collection.

Continua a leggere

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.