




Sfide infrastrutturali nella scalabilità di RAG con modelli di intelligenza artificiale personalizzati
I sistemi di Retrieval Augmented Generation (RAG) hanno migliorato in modo significativo le applicazioni di IA, fornendo risposte più accurate e contestualmente rilevanti. Tuttavia, la scalabilità e l'implementazione di questi sistemi in produzione hanno presentato sfide considerevoli, poiché sono diventati più sofisticati e incorporano modelli di IA personalizzati.
Durante un recente Unstructured Data Meetup ospitato da Zilliz, Chaoyu Yang, fondatore e CEO di BentoML, ha condiviso le sue intuizioni sugli ostacoli infrastrutturali che si incontrano quando si scalano i sistemi RAG con modelli AI personalizzati e ha evidenziato come strumenti come BentoML possano semplificare la distribuzione e la gestione di questi componenti. Questo post riassume i punti chiave di Chaoyu Yang ed esplora modelli di inferenza e tecniche di ottimizzazione avanzate. Queste strategie vi aiuteranno a costruire sistemi RAG non solo potenti, ma anche efficienti ed economici.
Guarda il replay dell'intervento di Chaoyu su Youtube
Come il RAG potenzia le applicazioni di IA
I sistemi RAG (Retrieval Augmented Generation) sono nati per affrontare il problema delle allucinazioni nelle applicazioni di IA. Integrando le capacità di recupero della somiglianza vettoriale di database vettoriali come Milvus e Zilliz Cloud con la potenza generativa di grandi modelli linguistici (LLMs, i sistemi RAG consentono ai modelli di IA di produrre risposte che sono:
Più accurate
Contestualmente rilevanti
Incredibilmente informativo
Senza allucinazioni
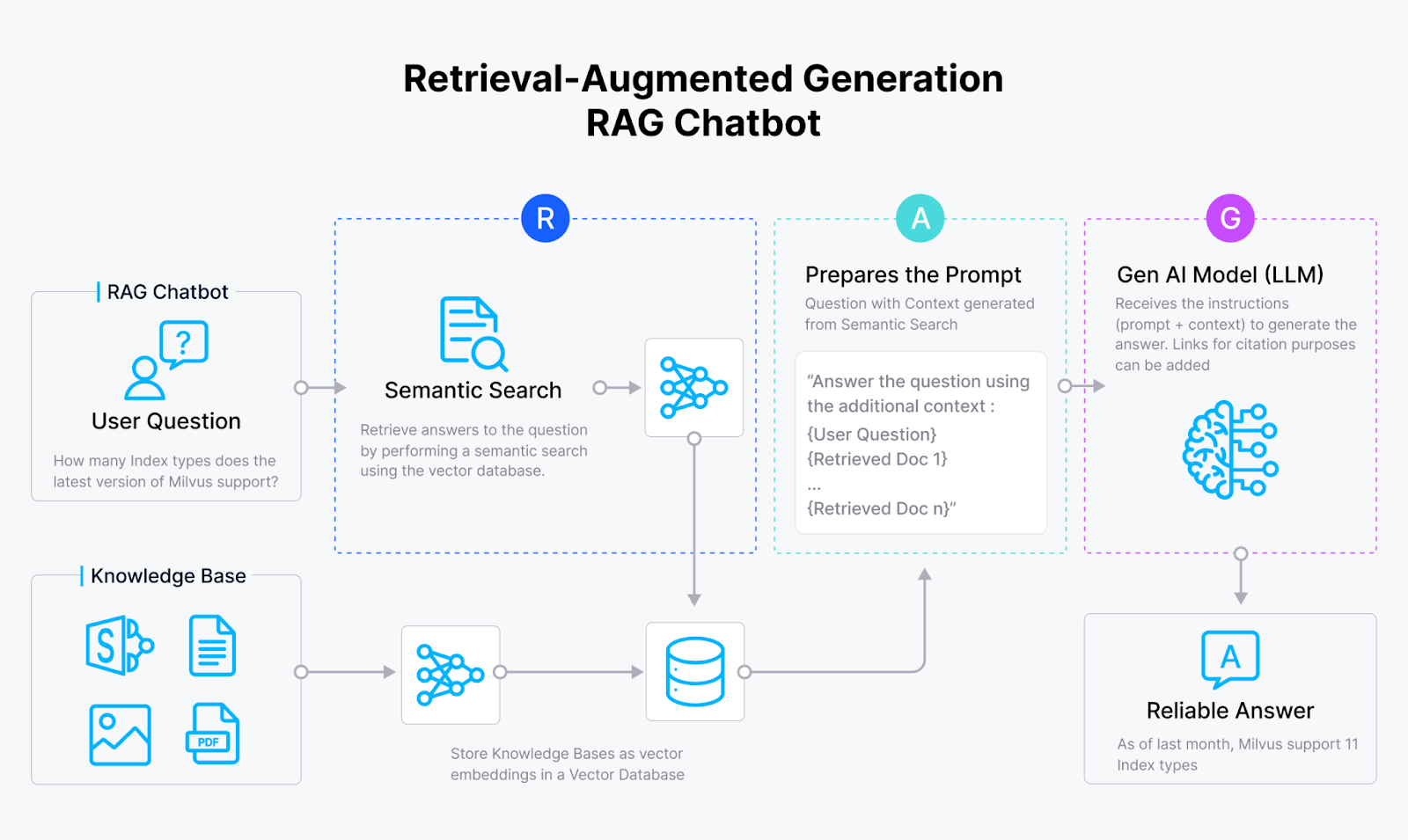
Come funziona un Chatbot RAG_
Questi sistemi hanno il potenziale per trasformare un'ampia gamma di settori, tra cui:
Risposte a domande
Riassunto di documenti
Generazione di contenuti personalizzati
E altro ancora.
I sistemi RAG raggiungono questo obiettivo attingendo alla vasta conoscenza nascosta nelle fonti esterne, come un bibliotecario AI!
Sfide nell'implementazione di sistemi RAG in produzione
I sistemi RAG hanno le loro sfide da superare prima di poter salvare la situazione negli ambienti di produzione. Uno degli ostacoli maggiori è garantire prestazioni di recupero di altissimo livello, il che comporta:
Ottimizzare il richiamo: Assicurarsi che vengano recuperate tutte le informazioni rilevanti.
Ottimizzare la precisione: ridurre al minimo la quantità di informazioni irrilevanti.
Per rendere le cose più interessanti, i sistemi RAG devono spesso gestire fonti di dati complesse e non strutturate. Immaginate di dare un senso a un PDF con più layout, tabelle e immagini di un fumetto! Questo problema richiede tecniche di elaborazione e comprensione dei documenti molto sofisticate.
Un'altra sfida che i sistemi RAG devono affrontare è la generazione di risposte accurate, contestualmente appropriate e in linea con l'intento dell'utente. È come scrivere una storia coerente usando solo frammenti di libri diversi!
Inoltre, è fondamentale garantire la sicurezza e l'affidabilità dei contenuti generati, soprattutto quando la posta in gioco è alta. Non vogliamo che i nostri sistemi di intelligenza artificiale si comportino in modo scorretto e diffondano informazioni errate!
I modelli di intelligenza artificiale personalizzati sono la spalla fidata di questa storia. Mettendo a punto e adattando i modelli di IA a domini e insiemi di dati specifici, gli sviluppatori possono dare ai loro sistemi RAG i superpoteri necessari per affrontare queste sfide.
Sfruttare i modelli di intelligenza artificiale personalizzati per ottenere prestazioni RAG più elevate
Per sfruttare appieno il potenziale dei sistemi RAG, è fondamentale utilizzare modelli di intelligenza artificiale personalizzati e adattati al nostro caso d'uso specifico. Grazie alla messa a punto e all'ottimizzazione di questi modelli, possiamo aumentarne significativamente le prestazioni. Esploriamo alcune aree chiave in cui i modelli AI personalizzati possono avere un impatto significativo.
Modelli di incorporazione del testo: La base del successo di RAG
I modelli di incorporazione del testo predefiniti, come "text-embedding-ada-002", spesso non riescono a cogliere le sfumature del nostro dominio specifico. Questo modello è al 57° posto nella classifica MTEB, il che indica un significativo margine di miglioramento.
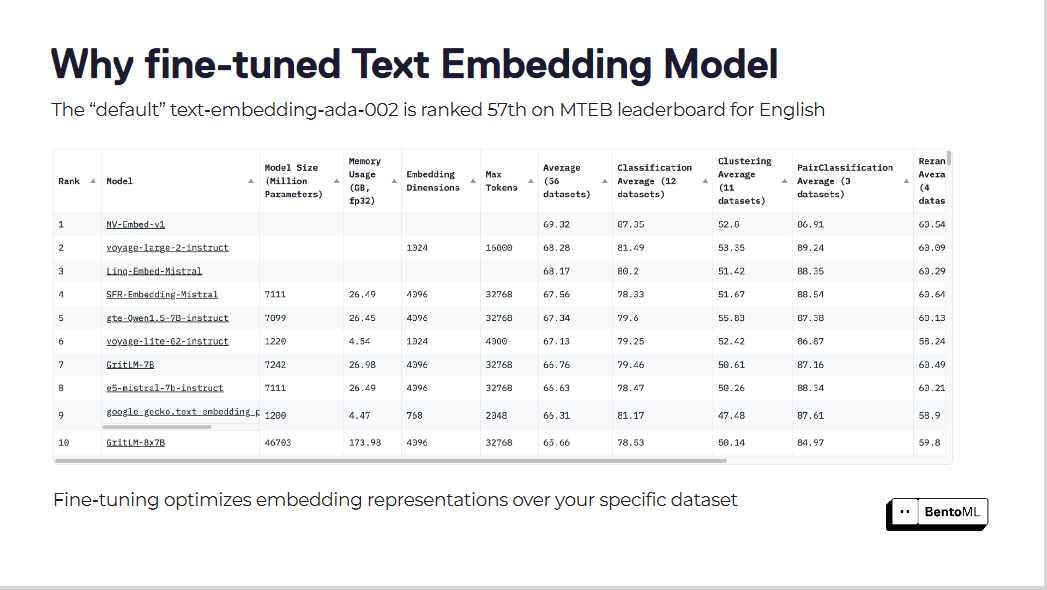
Il fine-tuning ottimizza le rappresentazioni di incorporamento per il vostro set di dati specifico
La messa a punto di questi modelli di embedding può portare a notevoli miglioramenti nei punteggi di recupero. Ottimizzando i modelli di embedding per i loro specifici set di dati, i sistemi RAG hanno registrato un sostanziale aumento delle prestazioni.
Ospitare i nostri LLM: Prendere il controllo
Gli LLM proprietari offrono convenienza, ma non sempre soddisfano le nostre esigenze o i nostri vincoli. Gli LLM open-source ci permettono di personalizzare e adattare i modelli alle nostre esigenze. Quando ospitiamo i nostri LLM, dobbiamo considerare i seguenti fattori chiave:
Sicurezza e privacy dei dati
Latenza e prestazioni
Capacità specifiche necessarie
Costo e scalabilità
Manutenzione e supporto
Elaborazione e comprensione dei documenti: Estrazione di informazioni da dati non strutturati
I sistemi RAG devono spesso elaborare e comprendere documenti complessi e non strutturati come PDF, immagini, ecc. L'integrazione di vari modelli e tecniche può aiutare a estrarre informazioni preziose. Ad esempio, possiamo condurre:
Analisi del layout con LayoutLM
Rilevamento delle tabelle con i trasformatori di tabelle TATR
OCR con EasyOCR o Tesseract
QA visiva dei documenti con LayoutLM v3 o Donut
La messa a punto di questi modelli per i vostri specifici tipi di documenti può migliorare notevolmente le loro prestazioni.
Tecniche avanzate per migliorare l'accuratezza di recupero
Per migliorare ulteriormente l'accuratezza del recupero, possiamo considerare l'implementazione delle seguenti tecniche:
Context-aware chunking e global concept-aware chunking: questi metodi aiutano a identificare le informazioni più rilevanti per il recupero, considerando il contesto e i concetti generali all'interno dei documenti.
Estrazione dei metadati:** L'estrazione dei metadati dai documenti può fornire un contesto aggiuntivo per migliorare il recupero e la sintesi delle risposte.
Modelli di re-ranker:** La messa a punto dei modelli di re-ranker su set di dati personalizzati può portare a prestazioni migliori del 10-30% rispetto ai modelli generici.
Sfruttando i modelli AI personalizzati in queste aree chiave, possiamo migliorare significativamente le prestazioni del nostro sistema RAG.
Tuttavia, distribuire e servire questi modelli in modo efficiente comporta una serie di sfide. Nella prossima sezione discuteremo alcune sfide infrastrutturali legate alla scalabilità di RAG con i modelli personalizzati.
Sfide infrastrutturali nella scalabilità di RAG con i modelli personalizzati
Man mano che i sistemi RAG diventano più complessi e incorporano più modelli personalizzati, le richieste di risorse computazionali e la necessità di una distribuzione e gestione efficiente aumentano in modo significativo. La scalabilità dei sistemi RAG (Retrieval Augmented Generation) con modelli AI personalizzati diventa un'esigenza urgente, ma comporta una serie di sfide infrastrutturali uniche.
Servizio efficiente di API per l'inferenza di modelli personalizzati
Una delle sfide principali è il servizio efficiente delle API di inferenza dei modelli personalizzati. I sistemi RAG spesso richiedono l'integrazione di più modelli, come:
Modelli di incorporazione del testo
Modelli linguistici di grandi dimensioni (LLM)
Modelli di elaborazione dei documenti
Ogni modello può avere requisiti computazionali e caratteristiche prestazionali diverse. La distribuzione di questi modelli come API di inferenza in grado di gestire le richieste in tempo reale e di scalare con la domanda è complessa.
Per affrontare questa sfida, è essenziale disporre di un'infrastruttura robusta e scalabile per servire le API di inferenza dei modelli. Questa infrastruttura deve essere in grado di gestire i requisiti specifici di ogni modello, come l'allocazione delle GPU, la gestione della memoria e i vincoli di latenza. Le tecnologie di containerizzazione come Docker possono aiutare a incapsulare le dipendenze dei modelli e a fornire un ambiente di runtime coerente tra i diversi sistemi.
Meccanismi di scalatura efficienti
Tuttavia, la semplice containerizzazione dei modelli non è sufficiente. L'infrastruttura deve anche supportare meccanismi di scalatura efficienti per gestire carichi di lavoro variabili. Questo requisito include la scalatura automatica del numero di istanze del modello in base al traffico di richieste in arrivo, garantendo un utilizzo ottimale delle risorse e riducendo al minimo i tempi di risposta.
Ottimizzazione del servizio dei modelli
Un'altra sfida cruciale è l'ottimizzazione del servizio dei modelli in termini di prestazioni ed efficienza economica. I modelli di intelligenza artificiale personalizzati, in particolare i modelli linguistici di grandi dimensioni, possono essere costosi dal punto di vista computazionale. Strategie di distribuzione ingenue possono portare a un utilizzo non ottimale delle risorse e a un aumento dei costi. Tecniche come il batching dinamico, in cui più richieste vengono raggruppate per sfruttare il parallelismo delle GPU, possono migliorare significativamente il throughput e ridurre i tempi di risposta.
Oltre al batching dinamico, è possibile applicare altre tecniche di ottimizzazione, come la quantizzazione, il pruning e la distillazione dei modelli, per ridurre l'ingombro di memoria e i requisiti computazionali dei modelli personalizzati. Tuttavia, l'implementazione di queste ottimizzazioni richiede un'attenta considerazione dei compromessi tra le prestazioni del modello e l'efficienza delle risorse.
Allocazione efficiente delle risorse e autoscaling
Anche l'allocazione efficiente delle risorse e l'autoscaling sono aspetti critici della scalabilità dei sistemi RAG con modelli personalizzati. L'infrastruttura deve essere in grado di allocare dinamicamente le risorse in base ai requisiti del carico di lavoro di ciascun modello. Questo approccio prevede il monitoraggio di metriche chiave come l'utilizzo della GPU, l'uso della memoria e la latenza delle richieste per prendere decisioni informate sul ridimensionamento. I meccanismi di autoscaling devono essere in grado di gestire picchi improvvisi di traffico e scalare le risorse di conseguenza per mantenere le prestazioni ottimali.
Composizione e orchestrazione di più modelli
Inoltre, l'infrastruttura deve supportare la composizione e l'orchestrazione di più modelli all'interno di un sistema RAG. I sistemi RAG spesso coinvolgono pipeline complesse in cui l'output di un modello serve come input di un altro. L'infrastruttura deve fornire strumenti e framework per definire e gestire queste pipeline, garantendo un flusso di dati continuo e un'esecuzione efficiente.
Monitoraggio e osservabilità
Il monitoraggio e l'osservabilità sono fondamentali per mantenere la salute e le prestazioni dei sistemi RAG con modelli personalizzati. L'infrastruttura deve fornire funzionalità di monitoraggio complete per tracciare le metriche chiave, i log e le tracce di tutti i componenti del sistema. Ciò consente di individuare e diagnosticare rapidamente i problemi e di ottimizzare e perfezionare il sistema in base ai dati sulle prestazioni reali.
Integrazione e distribuzione continue (CI/CD)
Infine, l'infrastruttura deve supportare l'integrazione e la distribuzione continua dei modelli personalizzati (CI/CD). Man mano che i modelli vengono aggiornati e perfezionati, è necessario stabilire un processo semplificato per il deploy delle nuove versioni senza interrompere il sistema complessivo. Ciò richiede solidi meccanismi di versioning, test e rollback per garantire la stabilità e l'affidabilità del sistema RAG.
Per affrontare queste sfide infrastrutturali è necessaria una combinazione di strumenti, framework e best practice. Nella prossima sezione analizzeremo come BentoML, una piattaforma per il servizio e la distribuzione di modelli di apprendimento automatico, possa aiutare ad affrontare queste sfide e a semplificare la scalabilità dei sistemi RAG con modelli AI personalizzati.
Creazione di API di inferenza per modelli personalizzati con BentoML
BentoML semplifica il processo di creazione e distribuzione delle API di inferenza per i modelli personalizzati nei sistemi RAG. Fornisce una transizione senza soluzione di continuità dallo sviluppo del modello alle API pronte per la produzione, consentendo un'iterazione più rapida e una più facile integrazione con i sistemi esistenti. Vediamo come può aiutarci a superare le sfide infrastrutturali per la scalabilità di RAG.
Dallo script di inferenza all'endpoint di servizio
Con poche righe di codice, si può facilmente convertire lo script di inferenza in un endpoint di servizio usando BentoML. Vediamo un esempio di creazione di un servizio BentoML per un modello di incorporamento del testo ottimizzato:
importare torch
da sentence_transformers import SentenceTransformer, models
classe SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
def encode(
self,
frasi: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
Questo frammento di codice definisce la classe SentenceTransformers'' per incapsulare il modello di incorporamento e i suoi metodi associati. Nel metodo ``` __init__, il modello SentenceTransformer`` viene inizializzato con un modello ottimizzato e impostato per funzionare sul dispositivo "cuda". Il metodo encode`` prende in input un elenco di frasi e restituisce i loro embeddings come array NumPy.
Per trasformarlo in un servizio BentoML, si possono aggiungere i decoratori @bentoml.service`` e @bentoml.api``:
importare bentoml
@bentoml.service
classe SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/my-fine-tuned-model",
device="cuda"
)
@bentoml.api
def encode(
self,
frasi: t.List[str],
) -> np.ndarray:
return self.model.encode(sentences)
Per servire il modello, si può usare la CLI di BentoML:
bentoml serve .
Questo comando avvia il server BentoML e serve il modello definito nella directory corrente. L'output della CLI mostra che il servizio è in ascolto su [http://localhost:3000](http://localhost:3000).
È quindi possibile effettuare richieste al modello servito utilizzando il client BentoML:
importare bentoml
con bentoml.SyncHTTPClient("http://localhost:3000") come client:
risultato: np.NDArray = client.encode(
sentences=["frase di input di esempio"],
)
Ottimizzazioni del servizio
BentoML offre diverse ottimizzazioni dei servizi già pronte. Una delle ottimizzazioni più potenti è il batching dinamico. Aggiungendo il parametro batchable=True alla definizione dell'API, BentoML esegue automaticamente il batching delle richieste in arrivo, ottimizzando l'utilizzo della GPU e migliorando il throughput del modello da servire.
@bentoml.api(batchable=True)
def encode(self, sentences: t.List[str]) -> np.ndarray:
return self.model.encode(sentences)
Il batching dinamico forma in modo intelligente piccoli batch raggruppando le richieste in arrivo, suddividendo i batch di grandi dimensioni e regolando automaticamente la dimensione dei batch. Questa ottimizzazione può portare a un tempo di risposta 3 volte più veloce e a un miglioramento di circa il 200% del throughput per l'embedding serving.
Infrastruttura di distribuzione e servizio
BentoML offre un'infrastruttura di distribuzione e di servizio flessibile e scalabile. Supporta diverse opzioni di distribuzione, tra cui la containerizzazione con Docker e l'orchestrazione con Kubernetes. È possibile specificare facilmente i requisiti delle risorse, come il numero e il tipo di GPU, e configurare le impostazioni del traffico come la concurrency e le code esterne.
importare bentoml
@bentoml.service(
risorse={
"gpu": 1,
"gpu_type": "nvidia-tesla-t4",
},
traffico={
"concurrency": 512,
"external_queue": Vero
}
)
classe SentenceTransformers:
def __init__(self):
...
@bentoml.api(batchable=True)
def encode(
...
):
...
Le funzionalità di micro-batching adattivo e di scalatura elastica di BentoML garantiscono l'utilizzo ottimale delle risorse e la scalatura automatica in base al traffico in entrata. Inoltre, fornisce un cruscotto di distribuzione facile da usare che offre informazioni sulla velocità delle richieste, sui tempi di risposta e sull'utilizzo delle risorse. Vediamo ora come scalare l'inferenza LLM con BentoML.
Scalare i servizi di inferenza LLM con BentoML
BentoML offre funzionalità e ottimizzazioni complete per aiutarvi a scalare i vostri servizi di inferenza LLM in modo efficiente.
Strategie di autoscalamento
L'autoscaling garantisce che i servizi di inferenza LLM possano gestire carichi di lavoro variabili e mantenere prestazioni ottimali. Tuttavia, le metriche di autoscaling tradizionali, come l'utilizzo delle GPU e le query al secondo (QPS), potrebbero non riflettere accuratamente il numero di repliche desiderato per i servizi LLM.
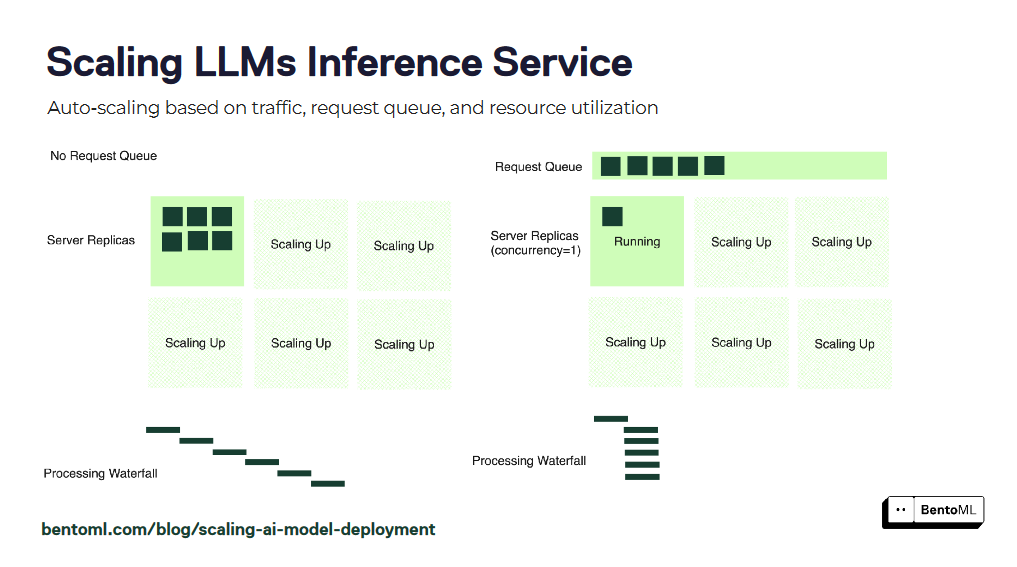
BentoML introduce l'autoscaling basato sulla concorrenza, un approccio più efficace per scalare i servizi di inferenza LLM. L'autoscaling basato sulla concorrenza considera il numero di richieste concorrenti che ogni replica del modello può gestire, fornendo una rappresentazione più accurata della capacità del servizio.
Ottimizzazione dell'avvio a freddo
L'avvio a freddo può essere una sfida significativa quando si scalano i servizi di inferenza LLM, specialmente con immagini container e file di modello di grandi dimensioni. BentoML offre diverse tecniche di ottimizzazione per mitigare la latenza dell'avvio a freddo.
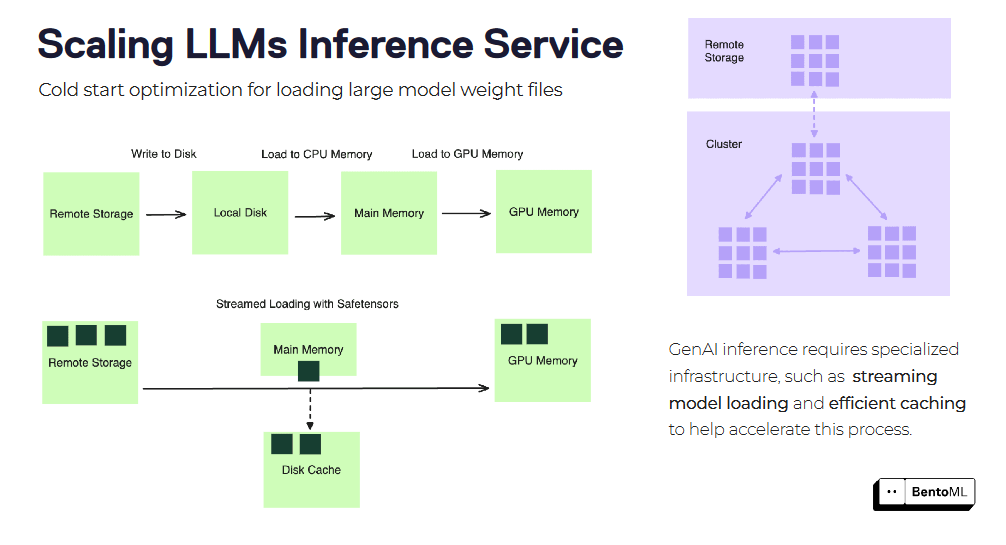
Una di queste tecniche è lo stream-loading delle immagini del contenitore. Invece di scaricare l'intera immagine del contenitore prima di avviare il servizio, BentoML può caricare in streaming l'immagine, recuperando solo i file necessari su richiesta. Questo può ridurre significativamente il tempo di avvio delle nuove repliche.
Un'altra ottimizzazione è il caricamento e la memorizzazione nella cache dei file del peso del modello. BentoML può memorizzare nella cache i pesi del modello caricato tra le repliche, riducendo il tempo necessario per caricare il modello per ogni nuova richiesta. Questo è particolarmente vantaggioso per i modelli linguistici di grandi dimensioni con file di pesi estesi.
Sfruttando le strategie di autoscaling di BentoML e le ottimizzazioni per l'avvio a freddo, potete scalare efficacemente i vostri servizi di inferenza LLM per gestire le richieste del vostro sistema RAG. BentoML elimina le complessità della gestione dell'infrastruttura, consentendovi di concentrarvi sullo sviluppo e sull'iterazione dei vostri modelli, garantendo al contempo prestazioni e scalabilità ottimali.
Modelli di inferenza avanzati per sistemi RAG
I sistemi RAG spesso richiedono modelli di inferenza avanzati per gestire flussi di lavoro complessi e ottimizzare le prestazioni. BentoML fornisce un framework flessibile ed estensibile per supportare questi pattern, consentendo la creazione di sofisticati sistemi RAG con facilità.
Le pipeline di elaborazione dei documenti possono essere costruite combinando più modelli e fasi di elaborazione, come l'analisi del layout, l'estrazione di tabelle e l'OCR.
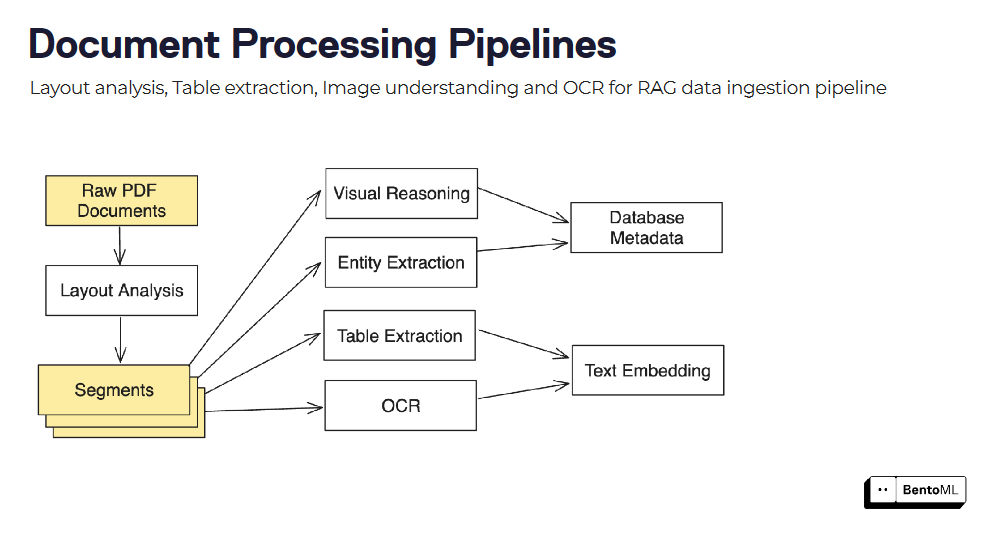
L'interfaccia di inferenza asincrona di BentoML gestisce in modo efficiente le attività di lunga durata, mentre il supporto per l'inferenza batch consente di elaborare grandi insiemi di dati sfruttando il parallelismo e le ottimizzazioni.
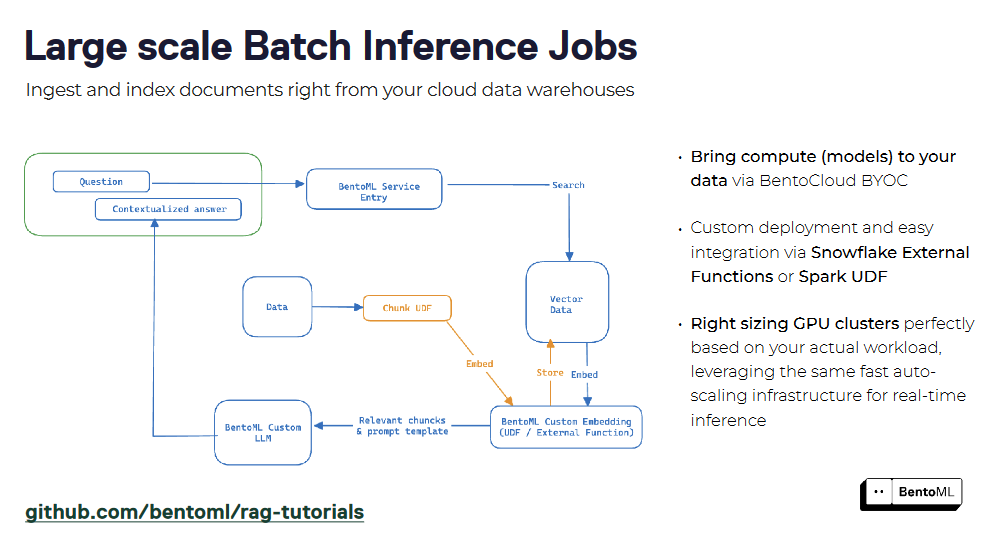
I sistemi RAG possono essere confezionati come servizi utilizzando BentoML, creando un'interfaccia unificata per l'interrogazione e l'interazione. Incapsulando i componenti retriever e generatori, è possibile distribuire facilmente un servizio RAG e integrarlo con altre applicazioni. Il supporto di BentoML per la containerizzazione e l'orchestrazione semplifica la scalabilità e la gestione dei servizi RAG negli ambienti di produzione.
Questi modelli di inferenza avanzati dimostrano la flessibilità e l'estensibilità di BentoML nella costruzione di servizi RAG potenti ed efficienti che gestiscono diversi compiti e carichi di lavoro.
Oltre all'infrastruttura per servire gli LLM, abbiamo bisogno anche di un robusto database vettoriale per memorizzare le nostre incorporazioni vettoriali ed eseguire una ricerca di similarità. È qui che ci viene in aiuto il database vettoriale Milvus. Nella prossima sezione vedremo come costruire una semplice applicazione RAG utilizzando BentoML e Milvus.
Integrazione di BentoML e del database vettoriale Milvus
Milvus è un database vettoriale open-source progettato per la ricerca di similarità ad alte prestazioni ed è un componente infrastrutturale fondamentale per la costruzione di Retrieval Augmented Generation (RAG).
Milvus si è integrato con BentoML, rendendo più facile la costruzione di applicazioni RAG scalabili. Questa sezione illustra la costruzione di un'applicazione RAG con BentoML e il database vettoriale Milvus. In questo esempio, utilizzeremo Milvus Lite, la versione leggera di Milvus, per una rapida prototipazione.
Il set di dati utilizzato può essere trovato qui: City data.
Fase 1: Impostazione dell'ambiente
Per prima cosa, installare le librerie necessarie, come mostrato di seguito:
# Installare le librerie necessarie
pip install -U pymilvus bentoml
Passo 2: Preparare i dati
Scarichiamo ed elaboriamo i dati della città.
importare os
importare le richieste
importare urllib.request
# Impostare l'origine dei dati
repo = "ytang07/bento_octo_milvus_RAG"
directory = "data"
save_dir = "./city_data"
api_url = f "https://api.github.com/repos/{repo}/contents/{directory}"
# Scaricare i file da GitHub
response = requests.get(api_url)
dati = response.json()
se non os.path.exists(save_dir):
os.makedirs(save_dir)
per item in data:
if item["type"] == "file":
file_url = item["download_url"]
file_path = os.path.join(save_dir, item["name"])
urllib.request.urlretrieve(file_url, file_path)
# Elaborare i dati scaricati
def chunk_text(filename):
con open(filename, "r") as f:
testo = f.read()
frasi = testo.split("\n")
return [s for s in sentences if len(s) > 7]
città = os.listdir("city_data")
city_chunks = []
per città in città:
chunked = chunk_text(f "city_data/{city}")
city_chunks.append({
"nome_città": city.split(".")[0],
"chunks": chunked
})
Fase 3: Configurare i client BentoML
Ora configureremo i client BentoML sia per il modello di incorporamento che per l'LLM, come mostrato di seguito.
importare bentoml
# Impostare gli endpoint e il token API
EMBEDDING_ENDPOINT = "IL TUO_EMBEDDING_MODEL_ENDPOINT"
LLM_ENDPOINT = "YOUR_LLM_ENDPOINT"
API_TOKEN = "IL TUO_API_TOKEN"
# Inizializza i client BentoML
embedding_client = bentoml.SyncHTTPClient(EMBEDDING_ENDPOINT, token=API_TOKEN)
llm_client = bentoml.SyncHTTPClient(LLM_ENDPOINT, token=API_TOKEN)
Sostituire gli endpoint e i token segnaposto con gli endpoint e i token API effettivi della distribuzione di BentoML. Questi client ci permetteranno di generare embeddings e di usare il modello linguistico per la generazione del testo.
Fase 4: Generare gli embeddings
Prima di generare gli embeddings, creiamo una funzione di embedding come mostrato di seguito:
Creare una funzione di incorporamento
def get_embeddings(testi):
# Gestisce grandi lotti di testi
se len(testi) > 25:
splits = [texts[x : x + 25] for x in range(0, len(texts), 25)]
embeddings = []
per split in split:
embedding_split = embedding_client.encode(sentences=split)
embeddings += embedding_split
restituire embeddings
# Gestire direttamente i piccoli lotti
return embedding_client.encode(frasi=testi)
Questa funzione gestisce il batching per grandi insiemi di testi, dato che il modello di embedding potrebbe avere dei limiti nella dimensione dell'input.
Genera le incorporazioni per tutti i chunks.
voci = []
per city_dict in city_chunks:
# Ottenere gli embeddings per i chunks di testo di ogni città
embedding_list = get_embeddings(city_dict["chunks"])
# Creare voci con embeddings e metadati
per i, embedding in enumerate(embedding_list):
voce = {
"embedding": embedding,
"sentence": city_dict["chunks"][i],
"città": city_dict["nome_città"],
}
entries.append(entry)
Qui stiamo creando un elenco di voci, ognuna delle quali contiene l'incorporamento, la frase originale e il nome della città. Questa struttura sarà utile quando si inseriranno i dati in Milvus.
Passo 5: Configurare Milvus
Ora inizializzeremo un database vettoriale usando Milvus per aggiungere gli embedding.
Inizializzare il client Milvus e creare lo schema
da pymilvus import MilvusClient, DataType
COLLECTION_NAME = "Bento_Milvus_RAG"
DIMENSION = 384 # Dovrebbe corrispondere alla dimensione di output del vostro modello di incorporazione.
# Inizializza il client Milvus
milvus_client = MilvusClient("milvus_demo.db")
# Creare lo schema
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=DIMENSION)
Stiamo usando Milvus lite, che è incorporato nell'applicazione. Lo schema definisce la nostra struttura di dati in Milvus, compreso un ID generato automaticamente e il vettore di incorporamento.
Preparare i parametri dell'indice e creare una collezione
# Preparare i parametri dell'indice
index_params = milvus_client.prepare_index_params()
index_params.add_index(
nome_campo="incorporazione",
index_type="AUTOINDEX",
metric_type="COSINE",
)
# Creare o ricreare la raccolta
se milvus_client.has_collection(nome_raccolta=nome_raccolta):
milvus_client.drop_collection(nome_collezione=NOME_COLLEZIONE)
milvus_client.create_collection(
nome_collezione=nome_collezione, schema=schema, parametri_indice=parametri_indice
)
Stiamo usando AUTOINDEX, che seleziona automaticamente il tipo di indice migliore in base ai dati. La [similarità del coseno] (https://zilliz.com/blog/similarity-metrics-for-vector-search#Cosine-Similarity) è usata come metrica di distanza per i confronti tra vettori.
Inserire i dati in Milvus
Ora inseriamo i dati in Milvus come mostrato di seguito
# Inserire i dati pre-elaborati in Milvus
milvus_client.insert(nome_collezione=nome_collezione, dati=entries)
Questo passo inserisce tutti i dati pre-elaborati (embeddings e metadati) nella collezione Milvus.
Fase 6: implementare RAG
Per implementare RAG in modo efficiente, creeremo tre funzioni per generare la risposta RAG, recuperare il contesto pertinente dalla raccolta e generare la risposta, come mostrato di seguito:
Creare una funzione per il LLM per generare le risposte
def generate_rag_response(question, context):
# Prepara il prompt per l'LLM
prompt = (
f "Sei un assistente utile. Rispondi alla domanda dell'utente basandoti solo sul contesto: {contesto}. \n"
f "La domanda dell'utente è {domanda}"
)
# Generare la risposta usando LLM
risultati = llm_client.generate(max_tokens=1024, prompt=prompt)
return "".join(risultati)
Questa funzione costruisce un prompt utilizzando il contesto recuperato e la domanda dell'utente e poi utilizza LLM per generare una risposta.
Creare una funzione per recuperare il contesto rilevante
def retrieve_context(question):
# Genera l'embedding per la domanda
embeddings = get_embeddings([domanda])
# Cerca vettori simili in Milvus
res = milvus_client.search(
nome_collezione=nome_collezione,
dati=embeddings,
anns_field="embedding",
limit=5,
output_fields=["sentence"],
)
# Estrarre e combinare le frasi rilevanti
sentences = [hit["entity"]["sentence"] for hits in res for hit in hits]
return ". ".join(frasi)
Questa funzione incorpora la domanda dell'utente, cerca vettori simili in Milvus e recupera i pezzi di testo corrispondenti per il contesto.
Combinare le funzioni precedenti per creare la pipeline RAG
def ask_question(question):
# Recupera il contesto rilevante
contesto = retrieve_context(domanda)
# Genera la risposta in base al contesto e alla domanda
return generate_rag_response(domanda, contesto)
Questa funzione collega tutto insieme, creando la nostra pipeline RAG.
Passo 7: utilizzare il sistema RAG
Ora possiamo usare il nostro sistema RAG per rispondere alle domande, come mostrato di seguito:
# Esempio di utilizzo
domanda = "In che stato si trova Cambridge?"
risposta = ask_question(domanda)
print(f "Domanda: {domanda}")
print(f "Risposta: {risposta}")
Questo esempio mostra come utilizzare il sistema RAG per rispondere a una domanda specifica su una città.
Note importanti:
Prima di eseguire questo codice, assicuratevi che i modelli di embedding e i modelli linguistici di grandi dimensioni siano correttamente distribuiti su BentoML.
La dimensione degli embeddings (384 in questo esempio) deve corrispondere all'output del modello di embedding.
Questa configurazione utilizza Milvus Lite, che è adatto per insiemi di dati più piccoli. Considerate l'utilizzo di una distribuzione completa di Milvus su Docker o K8s per applicazioni su larga scala.
L'efficacia del sistema RAG dipende dalla qualità e dalla copertura dei dati iniziali della città. Per ottenere i migliori risultati, assicurarsi che il set di dati sia completo e accurato.
L'integrazione di BentoML e Milvus crea un potente sistema RAG in grado di rispondere a domande basate sulle informazioni fornite sulla città. È possibile estendere questo sistema aggiungendo altri dati o perfezionandolo per casi d'uso specifici.
Conclusione
Costruire e scalare sistemi Retrieval Augmented Generation (RAG) con modelli AI personalizzati presenta sfide uniche. Gli sviluppatori possono creare sistemi RAG altamente performanti e scalabili sfruttando la potenza dei modelli personalizzati, ottimizzando l'infrastruttura di distribuzione e di servizio e adottando modelli di inferenza avanzati.
BentoML è uno strumento prezioso in questo percorso. Semplifica il processo di creazione e distribuzione delle API di inferenza, ottimizza le prestazioni del servizio e consente una scalabilità continua.
Integrando BentoML con il database vettoriale Milvus, le organizzazioni possono costruire sistemi RAG più potenti e scalabili. Questa combinazione consente di recuperare in modo efficiente le informazioni rilevanti e di generare risposte consapevoli del contesto, aprendo la strada ad applicazioni avanzate di intelligenza artificiale in vari settori e industrie.
Per ulteriori informazioni su BentoML e RAG, consultate le seguenti risorse
Continua a leggere

Will Amazon S3 Vectors Kill Vector Databases—or Save Them?
AWS S3 Vectors aims for 90% cost savings for vector storage. But will it kill vectordbs like Milvus? A deep dive into costs, limits, and the future of tiered storage.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.