




Implementazione di un sistema RAG multimodale con vLLM e Milvus
Immaginate di aver trascorso mesi a mettere a punto la vostra applicazione di intelligenza artificiale su uno specifico LLM attraverso un fornitore di API. Poi, di punto in bianco, ricevete un'e-mail: "Stiamo deprecando il modello che state utilizzando a favore della nostra nuova versione". Vi suona familiare? Sebbene i fornitori di API nel cloud offrano la comodità di potenti funzionalità di intelligenza artificiale pronte all'uso, affidarsi esclusivamente a loro introduce anche diversi rischi significativi:
- Mancanza di controllo: Non avete alcun controllo sulle versioni o sugli aggiornamenti dei modelli.
- Imprevedibilità: Potreste trovarvi di fronte a cambiamenti improvvisi nel comportamento o nelle capacità del modello.
- Intuizione limitata: La visibilità sulle prestazioni e sui modelli di utilizzo è spesso limitata.
- Problemi di privacy**: La privacy dei dati può essere un problema critico, soprattutto quando si gestiscono informazioni sensibili.
Qual è la soluzione? Come si può riprendere il controllo? Come mitigare questi rischi e al tempo stesso migliorare le capacità del vostro sistema? La risposta sta nel costruire un sistema più robusto e indipendente utilizzando soluzioni open-source.
Questo blog vi guiderà nella creazione di un RAG multimodale con Milvus e vLLM. Sfruttando la potenza di un [database vettoriale] (https://zilliz.com/learn/what-is-vector-database) open-source combinato con l'inferenza LLM open-source, è possibile progettare un sistema in grado di elaborare e comprendere [più tipi di dati] (https://zilliz.com/learn/introduction-to-unstructured-data) - testo, immagini, audio e persino video. Questo approccio non solo vi permette di avere il controllo completo della tecnologia, ma garantisce anche un sistema potente e versatile, che supera le soluzioni tradizionali basate sul testo.
Cosa realizzeremo: un RAG multimodale completamente sotto il vostro controllo
Costruiremo un sistema Multimodal RAG utilizzando Milvus e vLLM, illustrando come sia possibile auto-ospitare il proprio LLM e ottenere il pieno controllo delle proprie applicazioni AI. Il nostro tutorial vi guiderà nella creazione di un'applicazione Streamlit che dimostra la potenza dell'integrazione di più tipi di dati. Ecco cosa tratteremo:
Elaborare un input video estraendo i fotogrammi e trascrivendo l'audio
Memorizzare e indicizzare in modo efficiente i dati multimodali utilizzando Milvus
- Utilizziamo OpenAI CLIP per codificare le immagini in embeddings che possono essere ricercati con Milvus.
- Utilizziamo il modello Mistral Embedding per codificare il testo in embeddings.
Recuperare il contesto pertinente in base alle query dell'utente utilizzando Milvus.
Generare risposte utilizzando Pixtral in esecuzione con vLLM, sfruttando la comprensione visiva e testuale.
Alla fine di questo tutorial, avrete sviluppato un sistema flessibile e scalabile interamente sotto il vostro controllo, senza più preoccuparvi di deprecazioni delle API o di modifiche inaspettate.
Che cos'è Milvus?
Milvus è un database vettoriale open-source, ad alte prestazioni e altamente scalabile, in grado di memorizzare, indicizzare e ricercare dati non strutturati su scala miliardaria attraverso embeddings vettoriali ad alta dimensionalità. È perfetto per la realizzazione di moderne applicazioni di intelligenza artificiale come la retrieval augmented generation (RAG), la ricerca semantica, la ricerca multimodale e i sistemi di raccomandazione. Milvus funziona in modo efficiente in vari ambienti, dai computer portatili ai sistemi distribuiti su larga scala.
Che cos'è vLLM?
L'idea centrale di vLLM (Virtual Large Language Model) è quella di ottimizzare il servizio e l'esecuzione di LLM utilizzando tecniche efficienti di gestione della memoria. Ecco gli aspetti principali:
- Gestione ottimizzata della memoria: vLLM implementa tecniche avanzate di allocazione e gestione della memoria per sfruttare appieno le risorse hardware disponibili. Questa ottimizzazione consente di eseguire modelli linguistici di grandi dimensioni in modo efficiente, evitando colli di bottiglia nella memoria che possono ostacolare le prestazioni.
- Batching dinamico: vLLM adatta le dimensioni e le sequenze dei batch in base alle capacità di memoria e di calcolo dell'hardware sottostante. Questa regolazione dinamica migliora la velocità di elaborazione e riduce al minimo la latenza durante l'inferenza del modello.
- Design modulare: L'architettura di vLLM è modulare e facilita l'integrazione con diversi acceleratori hardware. Questa modularità consente inoltre di scalare facilmente su più dispositivi o cluster, rendendolo altamente adattabile a diversi scenari di implementazione.
- Utilizzo efficiente delle risorse: vLLM ottimizza l'uso di risorse critiche come CPU, GPU e memoria. Questa efficienza consente al sistema di supportare modelli più grandi e di gestire un numero maggiore di richieste simultanee, il che è essenziale negli ambienti di produzione dove scalabilità e prestazioni sono fondamentali.
- Integrazione senza soluzione di continuità**: Progettato per integrarsi senza problemi con i framework e le librerie di apprendimento automatico esistenti, vLLM offre un'interfaccia di facile utilizzo. Ciò garantisce agli sviluppatori la possibilità di distribuire e gestire facilmente modelli linguistici di grandi dimensioni in una serie di applicazioni, senza dover ricorrere a una riconfigurazione approfondita.
Componenti principali del nostro RAG multimodale
L'applicazione RAG multimodale che stiamo costruendo comprende i seguenti componenti chiave:
- vLLM è la libreria di inferenza che utilizzeremo per l'inferenza e il servizio del modello multimodale Pixtral.
- Koyeb fornisce il livello di infrastruttura per la nostra distribuzione, offrendo una piattaforma serverless specializzata per i carichi di lavoro AI. Grazie all'integrazione nativa di vLLM e alla gestione automatizzata delle risorse GPU, semplifica l'implementazione di LLM mantenendo prestazioni e scalabilità di livello produttivo.
- Pixtral di Mistral AI funge da cervello multimodale, combinando un codificatore di visione da 400M parametri con un decodificatore multimodale da 12B parametri. Questa architettura gli consente di elaborare sia le immagini che il testo all'interno della stessa [finestra di contesto] (https://zilliz.com/glossary/context-window).
- Milvus fornisce la base di memorizzazione dei vettori, gestendo in modo efficiente le incorporazioni provenienti da diverse modalità. La sua capacità di gestire più tipi di vettori e di eseguire una rapida ricerca di similarità lo rende perfetto per le applicazioni multimodali.
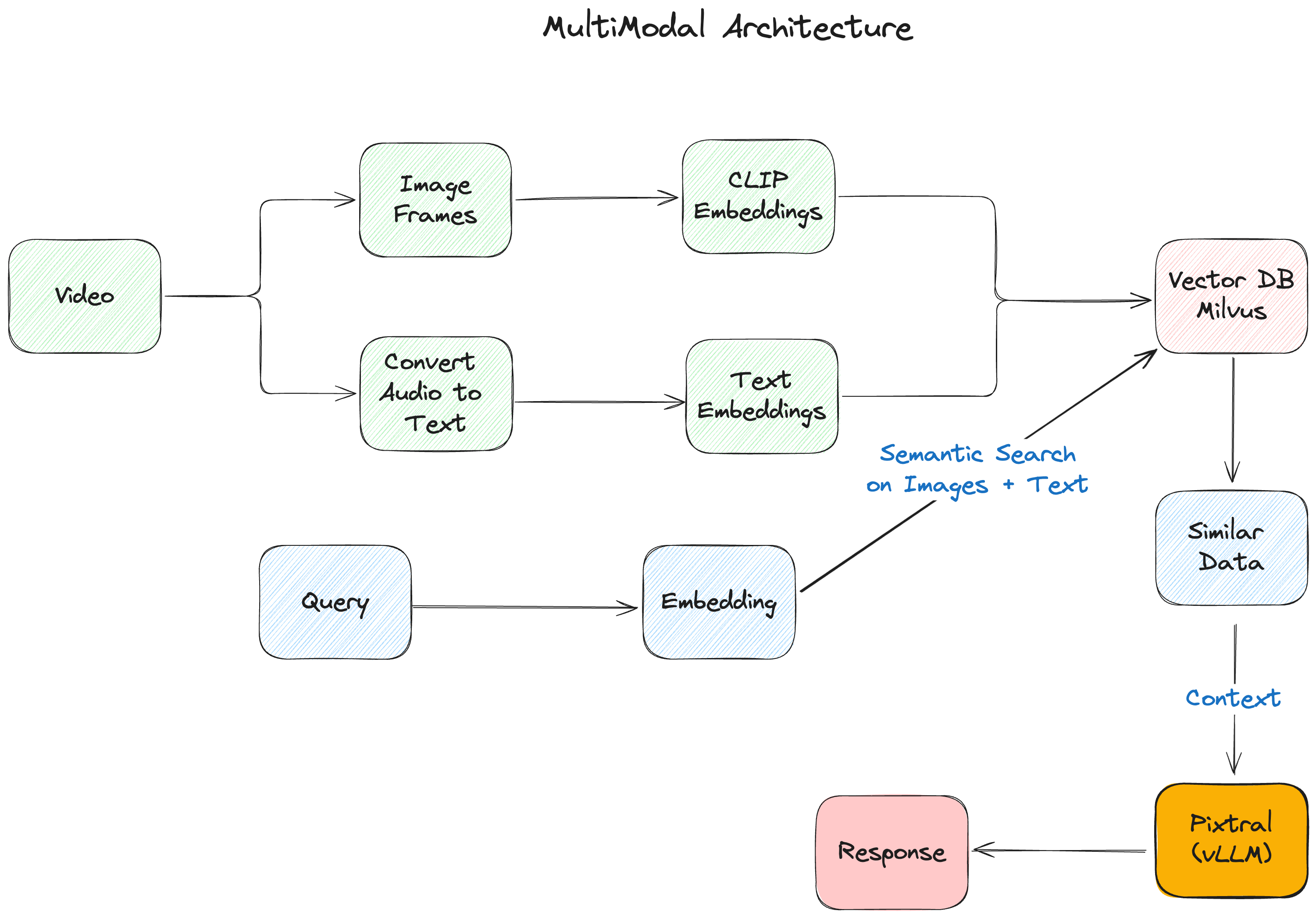 Figura- L'architettura multimodale di RAG.png
Figura- L'architettura multimodale di RAG.png
Figura: L'architettura multimodale RAG
Iniziare
Per prima cosa, installiamo le nostre dipendenze:
#Pacchetti del nucleo di LlamaIndex
pip install -U llama-index-vector-stores-milvus llama-index-multi-modal-llms-mistralai llama-index-embeddings-mistralai llama-index-multi-modal-llms-openai llama-index-embeddings-clip llama_index
# Elaborazione video e audio
pip install moviepy pytube pydub SpeechRecognition openai-whisper ffmpeg-python soundfile
# Elaborazione e visualizzazione di immagini
pip installare torch torchvision matplotlib scikit-image git+https://github.com/openai/CLIP.git
# Utilità e infrastrutture
pip install pymilvus streamlit ftfy regex tqdm
Impostazione dell'ambiente
Inizieremo configurando il nostro ambiente e importando le librerie necessarie:
``Python importare os importare base64 importare json da pathlib import Path da dotenv import load_dotenv da llama_index.core import Impostazioni da llama_index.embeddings.mistralai import MistralAIEmbedding
Carica le variabili d'ambiente
load_dotenv()
Configurare il modello di incorporamento predefinito
Settings.embed_model = MistralAIEmbedding( "mistral-embed", api_key=os.getenv("MISTRAL_API_KEY") )
## Pipeline di elaborazione video
Il cuore del nostro sistema è la pipeline di elaborazione video, che trasforma i contenuti video grezzi in dati che il nostro sistema RAG può comprendere ed elaborare in modo efficiente.
``Python
def process_video(video_path: str, output_folder: str, output_audio_path: str) -> dict:
# Crea la directory di output se non esiste
Path(output_folder).mkdir(parents=True, exist_ok=True)
# Estrarre i fotogrammi dal video
video_to_images(percorso_video, cartella_uscita)
# Estrarre e trascrivere l'audio
video_a_audio(percorso_video, percorso_audio_uscita)
text_data = audio_to_text(output_audio_path)
# Salvare la trascrizione
con open(os.path.join(output_folder, "output_text.txt"), "w") come file:
file.write(text_data)
os.remove(percorso_uscita_audio)
return {"Autore": "Autore di esempio", "Titolo": "Titolo di esempio", "Visualizzazioni": "1000000"}
Questa pipeline suddivide i video in:
- fotogrammi di immagine (estratti a 0,2 FPS)
- Trascrizione audio con Whisper
- Metadati sul video
Costruzione dell'indice vettoriale
Utilizziamo Milvus per memorizzare le nostre incorporazioni multimodali. Ecco come creare il nostro indice:
def create_index(output_folder: str):
# Crea collezioni diverse per testo e immagini
text_store = MilvusVectorStore(
uri="milvus_local.db",
collection_name="text_collection",
overwrite=True,
dim=1024
)
image_store = MilvusVectorStore(
uri="milvus_local.db",
collection_name="image_collection",
overwrite=True,
dim=512
)
storage_context = StorageContext.from_defaults(
vector_store=text_store,
image_store=image_store
)
# Caricare e indicizzare i documenti
documents = SimpleDirectoryReader(output_folder).load_data()
restituire MultiModalVectorStoreIndex.from_documents(
documenti,
storage_context=storage_context
)
Elaborazione delle query con Pixtral
Quando un utente pone una domanda, abbiamo bisogno di:
- Recuperare il contesto pertinente dal nostro archivio vettoriale
- Elaborare la domanda con Pixtral utilizzando sia il testo che le immagini.
Ecco la nostra funzione di elaborazione delle query:
def process_query_with_image(query_str, context_str, metadata_str, image_document):
client = OpenAI(
base_url=os.getenv("KOYEB_ENDPOINT"),
api_key=os.getenv("KOYEB_TOKEN")
)
con open(image_document.image_path, "rb") come image_file:
image_base64 = base64.b64encode(image_file.read()).decode("utf-8")
qa_tmpl_str = """
Date le informazioni fornite, comprese le immagini rilevanti e il contesto recuperato
dal video, rispondere in modo accurato e preciso alla domanda senza alcuna
conoscenze preliminari aggiuntive.
---------------------
Contesto: {context_str}
Metadati: {metadata_str}
---------------------
Domanda: {query_str}
Risposta: """
# Preparare i messaggi per Pixtral
messaggi = [
{
"role": "user",
"contenuto": [
{
"tipo": "text",
"text": qa_tmpl_str.format(
context_str=context_str,
query_str=query_str,
metadata_str=metadata_str
)
},
{
"tipo": "image_url",
"image_url": {
"url": f "data:image/jpeg;base64,{image_base64}"
}
},
],
}
]
completion = client.chat.completions.create(
model="mistralai/Pixtral-12B-2409",
messaggi=messaggi,
max_tokens=300
)
return completion.choices[0].message.content
Costruire l'interfaccia Streamlit
Infine, creiamo un'interfaccia intuitiva con Streamlit:
``Python def main(): st.title("RAG multimodale con Pixtral e Milvus")
# Inizializza lo stato della sessione
se 'index' non è in st.session_state:
st.session_state.index = None
st.session_state.retriever_engine = Nessuno
st.session_state.metadata = Nessuno
# Ingresso video
video_path = st.text_input("Inserire percorso video:")
se video_path e non st.session_state.index:
con st.spinner("Elaborazione video..."):
# Elabora il video e crea l'indice
[... codice di elaborazione...]
if st.session_state.index:
st.subheader("Chatta con il video")
query = st.text_input("Fai una domanda sul video:")
se query:
with st.spinner("Generazione della risposta..."):
# Genera e visualizza la risposta
[... codice di elaborazione della query...]
if name == "main": main()
### Esecuzione dell'applicazione
Prima di avviare l'applicazione, assicurarsi di avere:
1. Impostare le variabili d'ambiente in `.env`.
2. Installato tutte le dipendenze necessarie
Quindi lanciare l'applicazione:
```Bash
streamlit run app.py
Verrà visualizzata la homepage dove è possibile:
- Caricare video da elaborare
- porre domande sul contenuto del video
- leggere le risposte di Pixtral con i fotogrammi video pertinenti
 Figura- L'interfaccia della vostra applicazione RAG multimodale costruita con Milvus e Pixtral.png
Figura- L'interfaccia della vostra applicazione RAG multimodale costruita con Milvus e Pixtral.png
Figura: L'interfaccia dell'applicazione RAG multimodale costruita con Milvus e Pixtral
D'ora in poi, è possibile interagire con il video e, ad esempio, imparare di più sulla distribuzione gaussiana.
 Figura- Esecuzione della ricerca multimodale.png
Figura- Esecuzione della ricerca multimodale.png
Figura: Esecuzione della ricerca multimodale
Conclusione
In questo post abbiamo dimostrato come costruire un potente sistema RAG multimodale utilizzando Milvus, Pixtral e vLLM. Grazie alla combinazione delle efficienti capacità di archiviazione vettoriale di Milvus e dell'avanzata comprensione multimodale di Pixtral, abbiamo creato un sistema in grado di elaborare, comprendere e rispondere alle query sui contenuti video. E questo sistema è completamente sotto il vostro controllo.
Ci piacerebbe sapere cosa ne pensate!
Se vi piace questo post, prendete in considerazione:
- ⭐ Darci una stella su GitHub
- 💬 Unisciti alla nostra comunità Milvus Discord per condividere le tue esperienze
- 🔍 Esplorare il nostro repository Bootcamp per ulteriori esempi di applicazioni multimodali con Milvus

Continua a leggere

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.