




La tokenisation : Comprendre le texte en le décomposant

La tokenisation : Comprendre le texte en le décomposant
TL ; DR
La tokenisation est le processus de décomposition d'un texte en unités plus petites appelées tokens, telles que des mots, des phrases ou des sous-mots, afin de le préparer pour les modèles d'apprentissage automatique. Par exemple, la phrase "La tokenisation dans Milvus est puissante" peut être divisée en jetons comme ["Tokenization", "in", "Milvus", "is", "powerful"]. Ces jetons sont transformés en enregistrements numériques qui capturent leur signification pour des tâches telles que la recherche sémantique. Dans la base de données vectorielles [Milvus] (https://milvus.io/), la tokenisation est intégrée à des analyseurs qui traitent efficacement le texte pour l'indexer et le retrouver. Cette fonctionnalité simplifie les flux de travail, permettant aux développeurs de manipuler directement le texte brut et d'alimenter les applications de recherche avancée avec une précision et une évolutivité élevées.  ;
Introduction
Au cœur de nombreux systèmes d'intelligence artificielle (IA) et de [traitement du langage naturel (NLP)] (https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing) se trouve un processus qui transforme le texte brut en "données structurées" : la tokenisation. Mais qu'est-ce que la tokenisation exactement, et pourquoi est-il si important pour les machines de décomposer le texte en petits morceaux ?
La tokenisation est le processus de décomposition d'un texte en unités plus petites, ce qui permet aux machines d'analyser et de comprendre le langage de manière plus efficace. Cette étape essentielle permet aux ordinateurs de manipuler et de traiter le langage humain pour diverses tâches NLP, telles que l'analyse des sentiments, la traduction et la génération de textes.
 tokenization
tokenization
Qu'est-ce que la tokenisation ?
La tokenisation divise les textes, tels que les mots ou les caractères, en unités plus petites appelées [tokens] (https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models#:~:text=The%20above%20string,gram%20of%20tokens.). Il s'agit d'une étape fondamentale du [NLP] (https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing#What-is-NLP-used-for'), qui permet aux machines de traiter et de comprendre plus efficacement le langage humain.
Pourquoi avons-nous besoin de la tokenisation ?
La tokenisation est comparable à l'apprentissage d'une nouvelle langue : on commence par décomposer les phrases en unités plus petites pour en comprendre le sens et la structure. De la même manière, les ordinateurs divisent un bloc de texte en unités plus petites et plus faciles à gérer pour le traiter. La tokenisation apprend à l'ordinateur à identifier ces composants fondamentaux, comme les mots ou les sous-mots, ce qui lui permet de comprendre et d'analyser le texte.
Techniquement, la tokenisation convertit un texte non structuré en un format structuré qu'un ordinateur peut traiter. Par exemple, lorsque vous entrez une phrase dans un modèle NLP, le tokenizer la divise en tokens, auxquels sont ensuite attribuées des valeurs numériques. Ces valeurs permettent aux ordinateurs d'effectuer des opérations mathématiques, d'identifier des relations et d'extraire le sens des données. Sans la tokenisation, le texte resterait une chaîne de caractères incompréhensible pour la machine, ce qui rendrait toute analyse ultérieure impossible.
Concepts clés de la tokenisation
Nous allons ici explorer les concepts clés que vous devez comprendre au sujet de la tokenisation.
Token
Un jeton est une unité de base du texte considérée comme significative pour l'analyse. Les jetons peuvent être des caractères, des mots ou des sous-mots servant d'entrée primaire pour les tâches de traitement de texte ultérieures.
Tokenizer
Les tokenizers sont les outils fondamentaux qui permettent aux ordinateurs de disséquer et d'interpréter le langage humain en décomposant le texte en jetons. Il applique des règles spécifiques, telles que la division par des espaces ou l'utilisation de techniques au niveau des sous-mots, pour définir la granularité de la représentation du texte.
Analyseur
Un analyseur va au-delà de la simple tokenisation pour traiter et comprendre le texte en profondeur. Après la tokenisation, des filtres sont appliqués aux tokens pour les affiner davantage en appliquant un traitement supplémentaire, tel que la minuscule, le stemming, la lemmatisation ou la suppression des mots vides.
Vocabulaire
Le vocabulaire est l'ensemble des tokens uniques (mots, sous-mots ou caractères) qu'un modèle peut traiter. Il est construit à partir des jetons produits lors de la tokenisation. Le vocabulaire sert de référence au modèle pour comprendre le texte. Sa conception et sa taille influent sur la capacité du modèle à traiter le langage, en particulier les mots rares ou inédits.
Figure - Tokenizer et Analyzer dans Milvus](https://assets.zilliz.com/Figure_Tokenizer_and_Analyzer_in_Milvus_2f283b3046.png)
Figure : Tokéniseur et analyseur dans Milvus
Ce diagramme illustre le flux de traitement du texte, où le texte brut est tokenisé. Ensuite, un analyseur applique des filtres pour convertir les tokens en minuscules et supprimer les mots vides, ce qui permet d'obtenir une liste affinée de tokens significatifs.
Types de tokenisation
Les méthodes de tokenisation varient en fonction de la granularité de la décomposition du texte et des exigences spécifiques de la tâche à accomplir. Voici les types de tokenisation les plus courants :
1. Tokénisation des caractères: Elle décompose le texte en caractères individuels. Cette méthode peut s'avérer utile pour les langues présentant une morphologie complexe et pour des tâches telles que la correction orthographique ou le traitement de textes bruyants.
Figure - Tokénisation des caractères](https://assets.zilliz.com/Figure_Character_tokenization_c7c185282c.png)
Figure : La tokénisation des caractères
2. Tokénisation des mots: Il s'agit du type de tokénisation le plus courant, qui divise le texte en mots individuels. Il est utile pour la modélisation du langage, l'étiquetage des parties du discours et la reconnaissance des entités nommées, qui reposent sur l'analyse au niveau des mots.
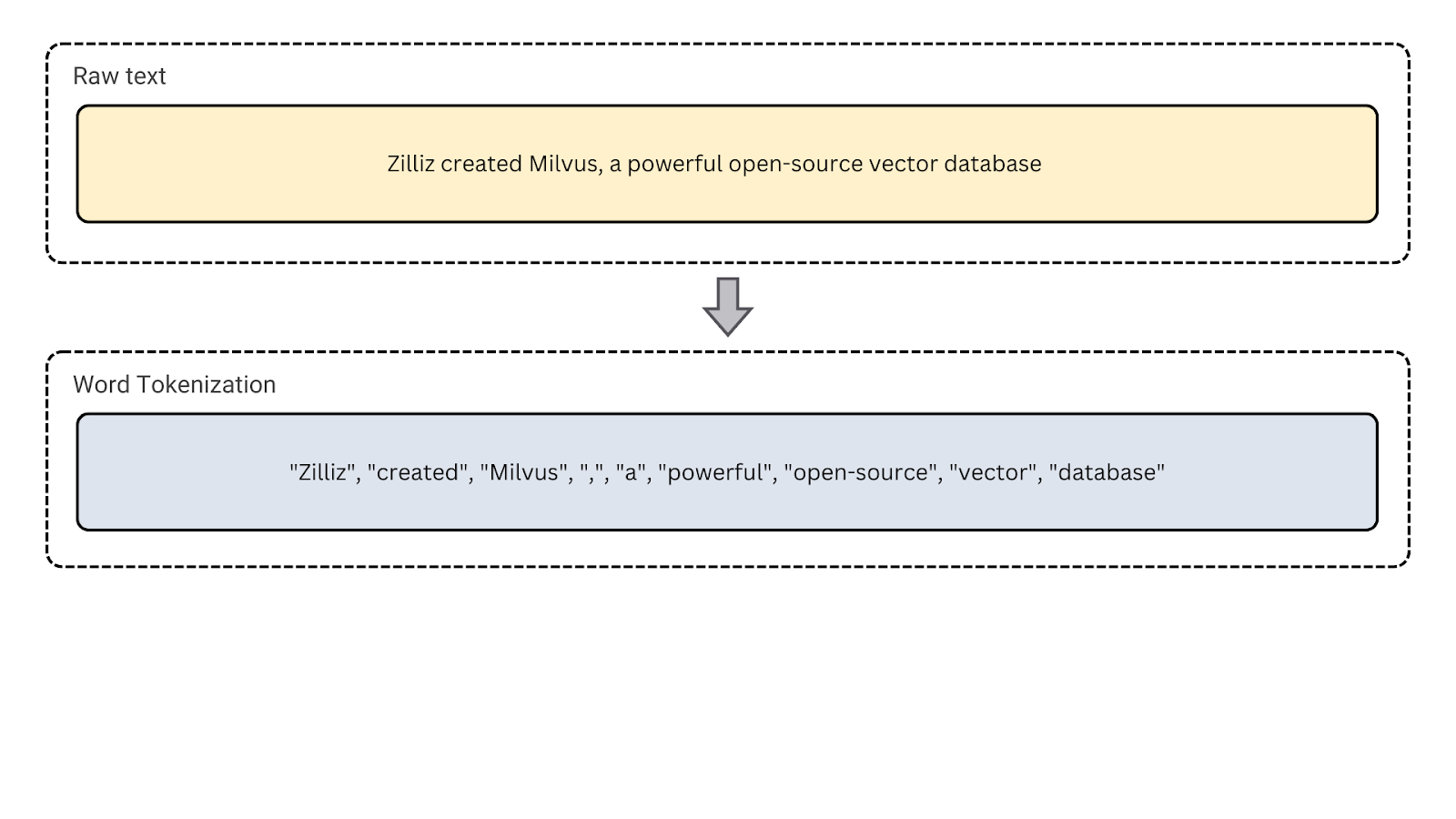 Figure- Bêta des mots
Figure- Bêta des mots
Figure : La tokenisation des mots.
3. Tokénisation des phrases: Ce type de tokenisation segmente le texte en phrases. Il sépare les paragraphes ou les longs blocs de texte en phrases distinctes. Ce type de tokenisation est utilisé pour des tâches telles que l'analyse des sentiments et le résumé de texte, où l'analyse de la structure au niveau de la phrase est nécessaire.
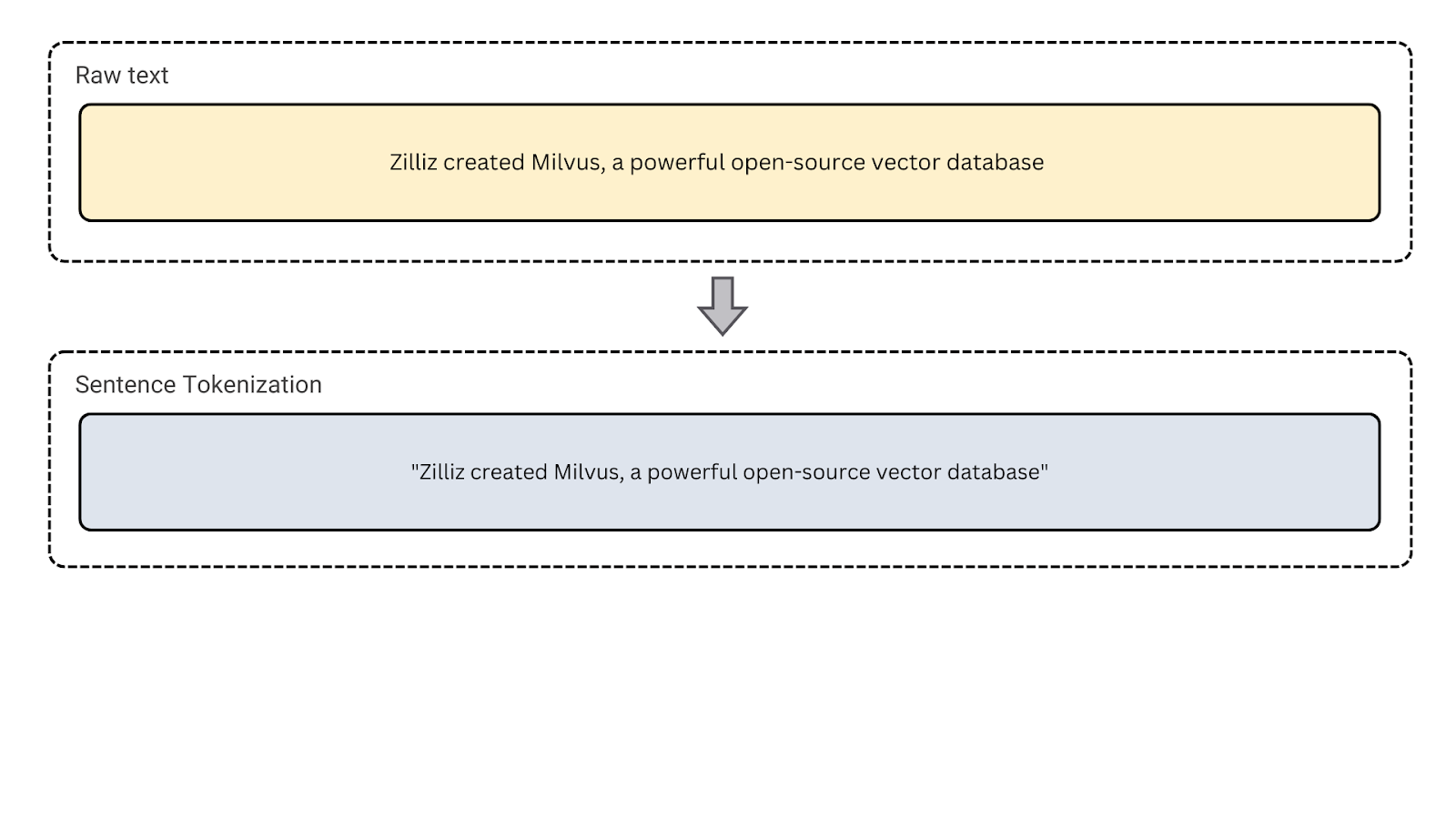 Figure- Tokénisation de phrases
Figure- Tokénisation de phrases
Figure : Bênage des phrases.
4. Tokénisation des sous-mots: Cette méthode divise les mots en unités plus petites et significatives (par exemple, les préfixes, les suffixes ou les tiges). Elle permet de réduire la taille du vocabulaire et est particulièrement utile pour des tâches telles que la génération de textes.
 Figure- Tokénisation des sous-mots
Figure- Tokénisation des sous-mots
Figure : La tokénisation des sous-mots
La tokenisation des sous-mots permet de diviser la phrase en sous-mots. Les mots rares comme "Zilliz" et "Milvus" sont divisés en unités plus petites. De même, "open-source" est divisé en ["open", "-", "source"], en traitant le trait d'union comme un jeton distinct.
Exemple de code
Voici un exemple Python utilisant le [BERT tokenizer] de Hugging Face (https://huggingface.co/docs/transformers/v4.47.1/en/model_doc/bert#transformers.BertTokenizer). Il montre comment la phrase est tokenisée en utilisant la tokenisation de sous-mots avec l'algorithme WordPiece :
from transformers import AutoTokenizer
# Chargement d'un tokenizer pré-entraîné
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Tokeniser une phrase
sentence = "Zilliz a créé Milvus, une puissante base de données vectorielle open-source"
tokens = tokenizer.tokenize(sentence)
print(tokens)
Sortie
['z', '##ill', '##iz', 'created', 'mil', '##vus', ',', 'a', 'powerful', 'open', '-', 'source', 'vector', 'database']
Comparaison entre la tokenisation et l'intégration de mots
La tokenisation et l'intégration de mots sont deux techniques fondamentales dans le traitement du langage naturel (NLP), mais elles ont des objectifs différents. La tokenisation divise le texte en unités plus petites, tandis que l'incorporation convertit ces unités sous forme numérique.
Figure - Relation sémantique entre les mots dans l'espace vectoriel] (https://assets.zilliz.com/Figure_Semantic_Relationship_Between_Words_in_Vector_Space_948e78f299.png)
Figure : Relation sémantique entre les mots dans l'espace vectoriel
Voici une comparaison entre la tokenisation et l'intégration de mots :
| La tokénisation et l'incorporation de mots sont des méthodes qui permettent d'améliorer la qualité de l'information et de la communication. | --------------- | ------------------------------------------------------------------------------- | -------------------------------------------------------------------------------- | | La tokenisation est une méthode qui consiste à diviser un texte en unités plus petites (tokens) et à représenter les tokens sous forme de vecteurs denses dans un espace vectoriel à haute dimension. | Le texte est divisé en unités qui peuvent être traitées. La signification sémantique et la relation entre les mots sont saisies dans la représentation vectorielle. Exemples | Phrase : "La tokenisation est cruciale "Tokens : ["Tokenization", "is", "crucial"] | Mot : "Milvus "Embedding : [0.23, 0.56, -0.12, ...] | | L'intégration : [0,23, 0,56, -0,12, ...] **Avantages ** Convertit un texte non structuré en un format structuré qu'un ordinateur peut traiter ** Saisit la sémantique des mots, les relations et le contexte | Il est nécessaire de disposer d'une grande puissance de calcul pour générer des embeddings.
Avantages et défis de la tokenisation
La tokenisation est essentielle dans le traitement des textes. Elle offre de nombreux avantages pour la modélisation et l'analyse du langage, mais présente également ses propres défis. Examinons ces deux aspects.
Avantages
Traitement de texte efficace:** La tokenisation est fondamentale dans la préparation des données textuelles pour les tâches NLP. Elle rend le texte plus adapté aux modèles d'apprentissage automatique.
Contrôle de la granularité:** La tokenisation permet de contrôler le niveau de granularité, ce qui permet au modèle de travailler avec des mots, des sous-mots ou même des caractères en fonction de la tâche à accomplir. Les exigences varient d'une tâche à l'autre et une granularité spécifique peut améliorer les performances.
Indépendance linguistique:** Les techniques de tokenisation peuvent s'adapter à différentes langues et à différents scripts pour convenir à différentes langues.
La tokenisation est cruciale pour la modélisation du langage. Elle définit les unités de base (tokens) que le modèle traite, ce qui permet une meilleure compréhension et une meilleure génération de texte.
Défis
Ambiguïté: La tokenisation est confrontée à des difficultés liées à l'ambiguïté de la langue. Par exemple, le mot "banque" peut désigner une institution financière ou le bord d'une rivière, selon le contexte. De même, des expressions telles que "high school" peuvent être tokenisées comme deux mots distincts ou comme une seule unité, ce qui affecte l'interprétation.
Certaines méthodes de tokenisation peuvent perdre des informations en divisant les mots en plus petits jetons, ce qui rend plus difficile pour les modèles de comprendre le contexte complet ou le sens du texte d'origine.
Gestion de la ponctuation:** La segmentation des tokens contenant de la ponctuation, comme les apostrophes ou les tirets, peut parfois s'avérer délicate pour les algorithmes de NLP.
Langues sans frontières claires:** La tokenisation peut être particulièrement difficile dans les langues sans frontières claires, comme le chinois ou le japonais, où les espaces ne séparent pas toujours les mots. Ces langues nécessitent des méthodes de tokenisation plus sophistiquées pour découper le texte avec précision.
Cas d'utilisation de la tokenisation
La tokenisation est largement utilisée dans diverses tâches de NLP, aidant les systèmes à traiter et à analyser les données textuelles. Voici quelques-uns des principaux cas d'utilisation de la tokenisation :
Moteurs de recherche: La tokenisation permet aux moteurs de recherche d'indexer et d'extraire rapidement des contenus pertinents en décomposant les termes de la requête et les documents en jetons, garantissant ainsi des résultats précis pour les requêtes des utilisateurs.
Traduction automatique:** La tokenisation est essentielle à la traduction automatique, car elle permet de décomposer les langues source et cible en jetons qu'un modèle peut cartographier et traduire efficacement d'une langue à l'autre.
Reconnaissance vocale:** La tokenisation aide à convertir la langue parlée en texte en segmentant l'entrée audio en jetons à traiter, ce qui permet aux systèmes de comprendre les mots parlés de manière structurée.
Analyse des sentiments:** La tokenisation est essentielle pour l'analyse des sentiments, où elle décompose le texte en tokens pour un traitement ultérieur afin de déterminer si le sentiment exprimé est positif, négatif ou neutre.
La tokenisation permet aux chatbots et aux assistants virtuels de comprendre et de traiter les requêtes des utilisateurs en divisant le texte en unités gérables. Cela leur permet de répondre de manière intelligente en fonction des données saisies.
Outils de tokenisation
Plusieurs outils sont couramment utilisés pour la tokenisation dans le cadre du NLP :
NLTK: Il s'agit d'une puissante bibliothèque Python pour le traitement du langage naturel, qui fournit des outils pour la tokenisation, le stemming, la lemmatisation, l'étiquetage POS, et plus encore.
SpaCy: Une bibliothèque NLP rapide avec un puissant tokenizer pour les mots et les phrases et une tokenisation personnalisable, ce qui en fait un outil de choix pour les applications industrielles.
Hugging Face Tokenizer: Il tokenise les modèles basés sur des transformateurs comme BERT et GPT avec une gestion des sous-mots.
Gensim](https://radimrehurek.com/gensim/):** Populaire pour la modélisation de sujets, il comprend des fonctions de prétraitement de texte et de tokenisation.
La tokenisation dans la base de données vectorielle Milvus
Une base de données vectorielle est conçue pour stocker, indexer et rechercher des données non structurées - telles que du texte, des images et des vidéos - à l'aide d'enchâssements vectoriels à haute dimension. Ces encastrements permettent une recherche rapide d'informations sémantiques et des recherches basées sur la similarité, ce qui rend les bases de données vectorielles essentielles pour des applications telles que les systèmes de recommandation, les moteurs de recherche et les flux de travail de l'intelligence artificielle.
La tokenisation est la première étape de ce processus. Elle décompose le texte brut en unités plus petites, telles que des mots, des phrases ou des sous-mots, qui sont ensuite convertis en représentations numériques (vector embeddings) par des [modèles d'apprentissage automatique] (https://zilliz.com/ai-models). Milvus, une base de données vectorielles open-source développée par Zilliz, stocke ces encastrements dans un espace à haute dimension où ils peuvent être efficacement interrogés pour rechercher des similitudes.
Tokénisation intégrée dans Milvus
Milvus simplifie la tokenisation grâce à ses [analyseurs intégrés] (https://milvus.io/docs/analyzer-overview.md), qui sont adaptés à différentes langues et à différents cas d'utilisation. Ces analyseurs intègrent des tokenizers et des filtres pour traiter les données textuelles en vue d'une indexation et d'une recherche efficaces :
Analyseur standard : L'analyseur par défaut pour le traitement de texte à usage général. Il effectue une tokenisation basée sur la grammaire, convertit les tokens en minuscules et prend en charge les recherches insensibles à la casse.
Analyseur anglais** : Conçu spécifiquement pour les textes en anglais. Il inclut le stemming (réduction des mots à leur forme racine) et la suppression des mots vides, en se concentrant sur les termes significatifs.
Analyseur chinois** : Optimisé pour le traitement des textes chinois, avec une tokenisation conçue pour gérer les structures linguistiques uniques.
Ces analyseurs intégrés permettent aux développeurs de saisir du texte brut directement dans Milvus sans avoir besoin d'un prétraitement externe, ce qui permet de rationaliser les flux de travail et de réduire la complexité.
Comment Milvus gère la tokenisation
À partir de Milvus 2.5, la base de données comprend des capacités intégrées recherche en texte intégral capacités, ce qui lui permet de traiter en interne les entrées de texte brut. Lorsque vous insérez des données textuelles, Milvus utilise l'analyseur spécifié pour transformer le texte en termes individuels pouvant faire l'objet d'une recherche. Ces termes sont ensuite convertis en représentations vectorielles éparses à l'aide d'algorithmes tels que BM25 et stockés en vue d'une récupération efficace.
Cette approche hybride permet à Milvus de traiter à la fois les vecteurs denses (enchâssements sémantiques) et les vecteurs épars (représentations basées sur les mots-clés). Par conséquent, Milvus prend en charge des scénarios de recherche hybride avancés qui combinent la compréhension sémantique et la précision des mots-clés, tout en gérant la symbolisation et la vectorisation de manière transparente au sein de la base de données.
Avantages de la tokenisation intégrée dans Milvus
Flux de travail simplifié** : Les analyseurs intégrés de Milvus éliminent la nécessité de recourir à des outils de tokenisation externes, ce qui facilite l'ingestion directe de données textuelles brutes.
Capacités de recherche améliorées** : En combinant la recherche en texte intégral avec la [recherche de similarité vectorielle] (https://zilliz.com/learn/vector-similarity-search), Milvus fournit des résultats très précis et pertinents pour diverses applications.
Évolutivité** : Le traitement interne de la tokenisation et de la vectorisation garantit que Milvus peut traiter efficacement des données textuelles à grande échelle dans une variété de cas d'utilisation.
Grâce à ces fonctionnalités, Milvus permet aux développeurs de créer plus facilement des applications de recherche et d'analyse intelligentes, en se concentrant sur l'innovation plutôt que sur les subtilités du prétraitement de texte. Que vous travailliez sur la recherche en langage naturel, les recommandations basées sur l'IA ou les systèmes de recherche hybrides, Milvus fournit une plateforme robuste et conviviale pour les développeurs afin d'alimenter vos applications.
FAQ sur la tokenisation
**01. Pourquoi la tokenisation est-elle importante pour le NLP ?
La tokenisation convertit les textes non structurés en unités gérables, ce qui permet aux ordinateurs de traiter le langage. Elle aide les modèles de NLP à attribuer des représentations numériques aux tokens, ce qui permet d'effectuer des opérations mathématiques et d'extraire des modèles significatifs.
**02. Quelle est la différence entre la tokenisation de mots et la tokenisation de caractères ?
La tokenisation des mots divise le texte en mots individuels, traitant chaque mot comme un jeton distinct. En revanche, la tokenisation des caractères décompose le texte en caractères individuels.
**03. Qu'est-ce que la lemmatisation et la tokenisation ?
La tokenisation divise le texte en unités plus petites, telles que des mots ou des phrases, ce qui facilite le traitement par les ordinateurs. La lemmatisation réduit les mots à leur forme de base, par exemple en convertissant "running" en "run", ce qui garantit la cohérence de la compréhension de la langue.
**04. Comment la tokenisation affecte-t-elle la performance du modèle ?
La tokenisation affecte la manière dont le texte est décomposé et compris par un modèle. Une bonne tokenisation peut améliorer les performances du modèle en capturant des relations précises entre les mots, tandis qu'une mauvaise tokenisation peut conduire à des interprétations erronées ou à une perte de sens.
**05. Quel rôle joue la tokenisation dans l'analyse des sentiments ou la classification des textes ?
Dans l'analyse des sentiments et la classification des textes, la tokenisation divise le texte en unités plus petites, comme des mots ou des phrases, qui peuvent être analysées pour en dégager des modèles ou des sentiments. Ce processus permet aux algorithmes de traiter les tokens individuels et de classer ou d'attribuer un sentiment au texte avec précision.
Ressources connexes
Qu'est-ce que Milvus ? Documentation Milvus](https://milvus.io/docs/overview.md)
[Notions de NLP : modèles de tokens, de N-grammes et de sacs de mots] (https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models)
[Les 10 techniques NLP les plus populaires pour les scientifiques des données] (https://zilliz.com/learn/top-10-nlp-techniques-every-data-scientist-should-know)
Guide du traitement du langage naturel pour les débutants ](https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing)
- TL ; DR
- Introduction
- Qu'est-ce que la tokenisation ?
- Pourquoi avons-nous besoin de la tokenisation ?
- Concepts clés de la tokenisation
- Types de tokenisation
- Comparaison entre la tokenisation et l'intégration de mots
- Avantages et défis de la tokenisation
- Cas d'utilisation de la tokenisation
- Outils de tokenisation
- La tokenisation dans la base de données vectorielle Milvus
- FAQ sur la tokenisation
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement