




Comprendre le profilage continu, ses cas d’utilisation, ses avantages et ses défis

Comprendre le profilage continu, ses cas d’utilisation, ses avantages et ses défis
 continuous profiling.jpg
continuous profiling.jpg
Pourquoi certaines applications sont-elles plus performantes que d’autres ? La réponse réside souvent dans des techniques de surveillance qui évaluent constamment les performances d’une application. À mesure que la demande d’une expérience utilisateur améliorée augmente, le besoin de tels systèmes de surveillance s’accroît. Les organisations doivent mettre en place des cadres robustes pour résoudre rapidement les problèmes de performance et fidéliser les clients.
Les entreprises peuvent adopter le profilage continu pour rationaliser les flux de travail de leurs applications et corriger les problèmes dès qu’ils apparaissent. Cette méthode permet aux ingénieurs et aux développeurs d’effectuer des ajustements en temps réel afin de garantir que l’application reste rapide, fiable et économe en ressources.
Cet article expliquera le profilage continu, ses avantages et ses défis, ainsi que quelques cas d’utilisation et outils de profilage. Ces informations vous aideront à mettre en œuvre un pipeline de profilage continu efficace pour surveiller les performances des applications.
Qu’est-ce que le profilage continu ?
Le profilage continu est une méthode de surveillance qui collecte et analyse des métriques pertinentes concernant les opérations d’un système ou d’un programme. Par exemple, le profilage peut informer les ingénieurs sur l’utilisation du CPU, l’utilisation de la mémoire, la fréquence et la durée des appels de fonctions, ainsi que l’activité d’E/S.
Cette méthode recueille des données provenant de l’environnement de production et utilise des pipelines automatisés pour détecter les anomalies et les incohérences en temps réel. C’est une technique populaire pour gérer les centres de données, où plusieurs serveurs sont profilés 24 h/24 et 7 j/7 afin d’analyser la répartition de la charge de travail, la latence et le débit.
Grâce au profilage continu, les administrateurs système et les développeurs peuvent rapidement identifier la cause profonde d’un problème et stocker des données de profil étendues pour une analyse ultérieure.
Comment fonctionne le profilage continu ?
Le profilage est un processus itératif qui doit se concentrer sur les événements dans l’environnement de production afin d’identifier de nouveaux problèmes qui peuvent ne pas apparaître dans des configurations locales hors ligne.
Les professionnels utilisent des profileurs légers qui collectent constamment des données en temps réel sur plusieurs métriques. Ces profileurs surveillent les applications avec un impact minimal sur les ressources existantes. Ils aident également à visualiser les données sur des tableaux de bord afin d’identifier les tendances, les modèles et les incohérences.
Il existe deux types de profileurs : l’échantillonnage et l’instrumentation. Les sections suivantes expliquent comment ils vous aident à comprendre leurs cas d’utilisation.
Profileur par échantillonnage
Un profileur par échantillonnage ou statistique collecte des données de performance à différents moments afin d’analyser le temps passé sur des appels de fonctions particuliers. Il fonctionne en interrogeant périodiquement une application et en surveillant l’exécution du code afin de déterminer les goulots d’étranglement potentiels.
La méthode consiste à capturer les données d’utilisation des ressources à intervalles fixes appelés instantanés. L’utilisateur agrège ces instantanés au moyen de techniques statistiques afin de représenter la façon dont l’application utilise les ressources du système et exécute les appels de fonctions. Les outils de visualisation peuvent aider à résumer les informations au sein de ces agrégations pour aider l’utilisateur à comprendre le chemin d’exécution du code d’une application.
Comme les profileurs par échantillonnage collectent des données à différentes périodes, le processus présente une surcharge minimale et donne aux développeurs une vue globale des performances de l’application. Il leur permet également d’identifier des tendances à long terme, telles que les fuites de mémoire, en analysant les données sur plusieurs intervalles de temps.
Profileur par instrumentation
Le profilage par instrumentation effectue une surveillance plus détaillée et génère des données de retour approfondies pour capturer les performances d’une application. La technique enregistre la durée des appels de fonctions, les procédures standard et les séquences d’événements.
La méthode nécessite de modifier le code source pour inclure le profileur à différents points de contrôle. Les techniques pour intégrer le profileur incluent :
Instrumentation du code
Accrochage à l’exécution
Échantillonnage
Le profileur collecte des données sur les métriques pertinentes aux points de contrôle spécifiés et permet aux développeurs d’effectuer des analyses détaillées impliquant des approches de machine learning (ML) et statistiques.
Bien que le profilage par instrumentation fournisse une grande profondeur d’information, il peut introduire une surcharge d’exécution importante pendant l’exécution du code. De plus, la manipulation du code pour instrumenter le profileur peut provoquer des erreurs et entraîner des bogues de performance supplémentaires.
Visualisation des données
La visualisation des données est cruciale dans les processus de profilage, car elle offre aux développeurs une vue intuitive des métriques de performance. Les graphes de flamme sont populaires pour visualiser les données de profilage. Ils affichent les traces de pile afin de mettre en évidence les chemins de code et le temps d’exécution.
 flame graph.png
flame graph.png
{kind=link}
Ils comportent des barres horizontales codées par couleur représentant le temps passé dans les appels de fonction, l’utilisation de la mémoire, l’utilisation du CPU et d’autres métriques. Chaque barre représente une étape, comme une fonction, une requête ou un appel d’API dans un bloc de code.
La barre la plus haute, le span parent, représente la première requête d’exécution, et les barres situées en dessous illustrent toutes les étapes suivantes, ou spans enfants, déclenchées le long du chemin de code. Chaque barre enfant peut créer un autre span parent si le chemin de code entre dans un autre service ou lance une nouvelle requête d’appel.
L’axe x représente la durée de chaque span, ce qui signifie que des spans plus larges indiquent que l’appel de fonction a mis longtemps à se terminer. L’axe y montre la profondeur d’une pile ou le nombre de sous-requêtes résultant d’un appel de fonction particulier.
Les outils de profilage peuvent générer ces graphes et permettre aux utilisateurs de cliquer sur une barre spécifique pour voir le temps d’exécution et les erreurs. Ils peuvent également consulter les métriques associées, les journaux et les statistiques de télémétrie afin de mieux comprendre le flux d’exécution.
Profilage traditionnel vs profilage continu
Un concept lié au profilage continu est le profilage traditionnel, qui effectue un suivi détaillé en temps réel des performances d’une application. Il instrumente chaque appel de fonction et chaque événement afin de fournir des informations détaillées sur le chemin d’exécution du code d’une application.
Bien que le profilage traditionnel et le profilage continu aident à surveiller les performances d’une application, ils présentent quelques différences essentielles. La liste suivante résume ces différences pour vous aider à distinguer les deux.
Cas d’utilisation : Le profilage traditionnel convient aux tests à la demande et aux environnements hors ligne. En revanche, le profilage continu offre une surveillance constante afin d’identifier rapidement les problèmes dans les applications sensibles au temps.
Portée : Les développeurs peuvent mettre en œuvre le profilage traditionnel pour tester des fonctions ou des modules particuliers, tandis que le profilage continu peut surveiller un système entier.
Automatisation : Étant donné que les développeurs effectuent le profilage traditionnel de manière ponctuelle, il nécessite une configuration manuelle, tandis que les pipelines de profilage continu s’exécutent automatiquement pour enregistrer les données d’exécution du code.
Avantages et défis du profilage continu
Le profilage continu est un outil efficace pour déterminer l’efficacité de votre application et la répartition de la charge de travail. Cependant, la mise en œuvre du profilage continu est difficile, car les développeurs doivent trouver un équilibre entre la couverture des données et une surcharge élevée.
Les sections suivantes expliquent plus en détail les avantages de la surveillance continue afin de vous aider à comprendre les forces et les faiblesses de la méthode.
Avantages
Surveillance en temps réel : Les développeurs peuvent obtenir en continu des informations en temps réel sur les performances de leur application dans l’environnement de production.
Surcharge minimale : Les outils de profilage continu ajoutent une surcharge minimale aux opérations existantes. Bien que l’instrumentation puisse causer des problèmes de performance, une gestion habile de la manipulation du code peut atténuer ces problèmes.
Meilleur débogage : Grâce à des données de performance étendues pour différentes périodes et différents points de contrôle, le profilage continu aide les développeurs à identifier la cause racine et à déboguer les problèmes plus efficacement.
Optimisation : À mesure que les développeurs identifient les problèmes, ils peuvent rapidement corriger et améliorer la base de code d’une application afin d’optimiser les performances sans provoquer de temps d’arrêt.
Analyse des données : Le profilage continu peut générer de riches données de performance que les développeurs peuvent stocker et analyser à l’aide de techniques avancées de ML. Cette approche peut révéler davantage d’informations sur le fonctionnement du code et aider à développer des cas de test plus robustes.
Défis
Surcharge de données : Bien que le profilage continu effectue une surveillance en temps réel, il peut générer des données considérables qui peuvent devenir difficiles à analyser. Les outils d’agrégation et de visualisation peuvent atténuer ces problèmes en permettant aux développeurs de se concentrer sur les indicateurs de performance critiques. De plus, le filtrage des données selon les critères souhaités peut aider à supprimer les données non pertinentes.
Complexité de l’intégration : L’intégration d’outils de profilage dans le code source est complexe et devient plus difficile dans les architectures distribuées. Les développeurs peuvent résoudre ces problèmes en mettant en œuvre des pipelines de profilage automatisés pour chaque composant et en utilisant un tableau de bord centralisé pour analyser les données à l’échelle du système.
Coût : Les outils de profilage et la mise à l’échelle peuvent être coûteux pour les systèmes d’entreprise étendus. Identifier les zones clés à surveiller et définir des objectifs clairs peut aider les organisations à réduire la granularité et la portée du profilage, permettant une mise à l’échelle plus efficace et réduisant les coûts de collecte et de stockage des données.
Outils de profilage
Les développeurs peuvent utiliser des outils de profilage de pointe pour rationaliser les flux de travail de surveillance. Vous trouverez ci-dessous une liste des meilleurs outils de profilage continu qui offrent des fonctionnalités variées et prennent en charge plusieurs frameworks.
Datadog Continuous Profiler
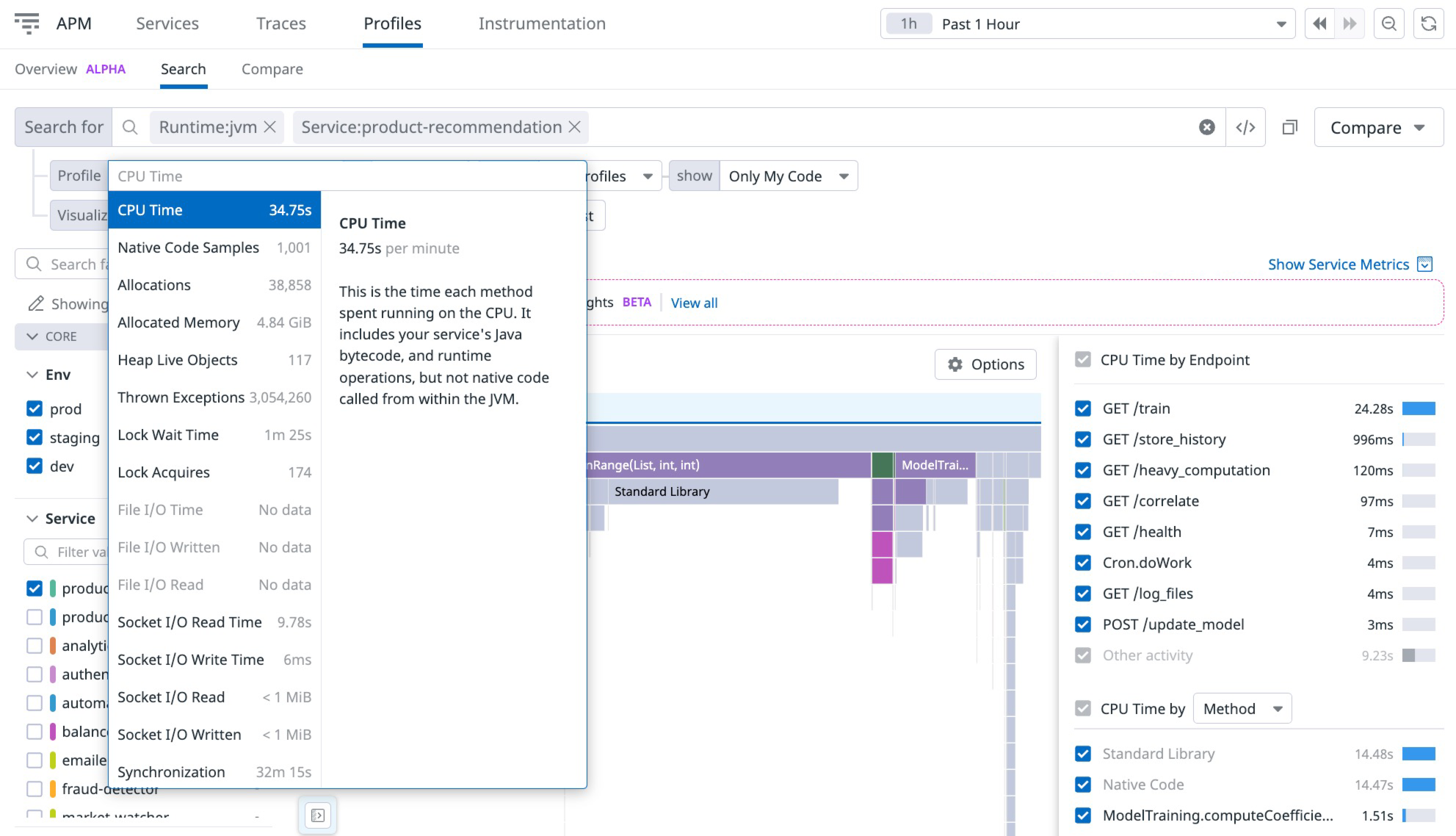
Datadog propose un profileur continu de haute qualité qui collecte et analyse les données de performance de votre base de code. Il fonctionne dans n’importe quel environnement et vous aide à résoudre les problèmes de production grâce à des insights basés sur l’IA.
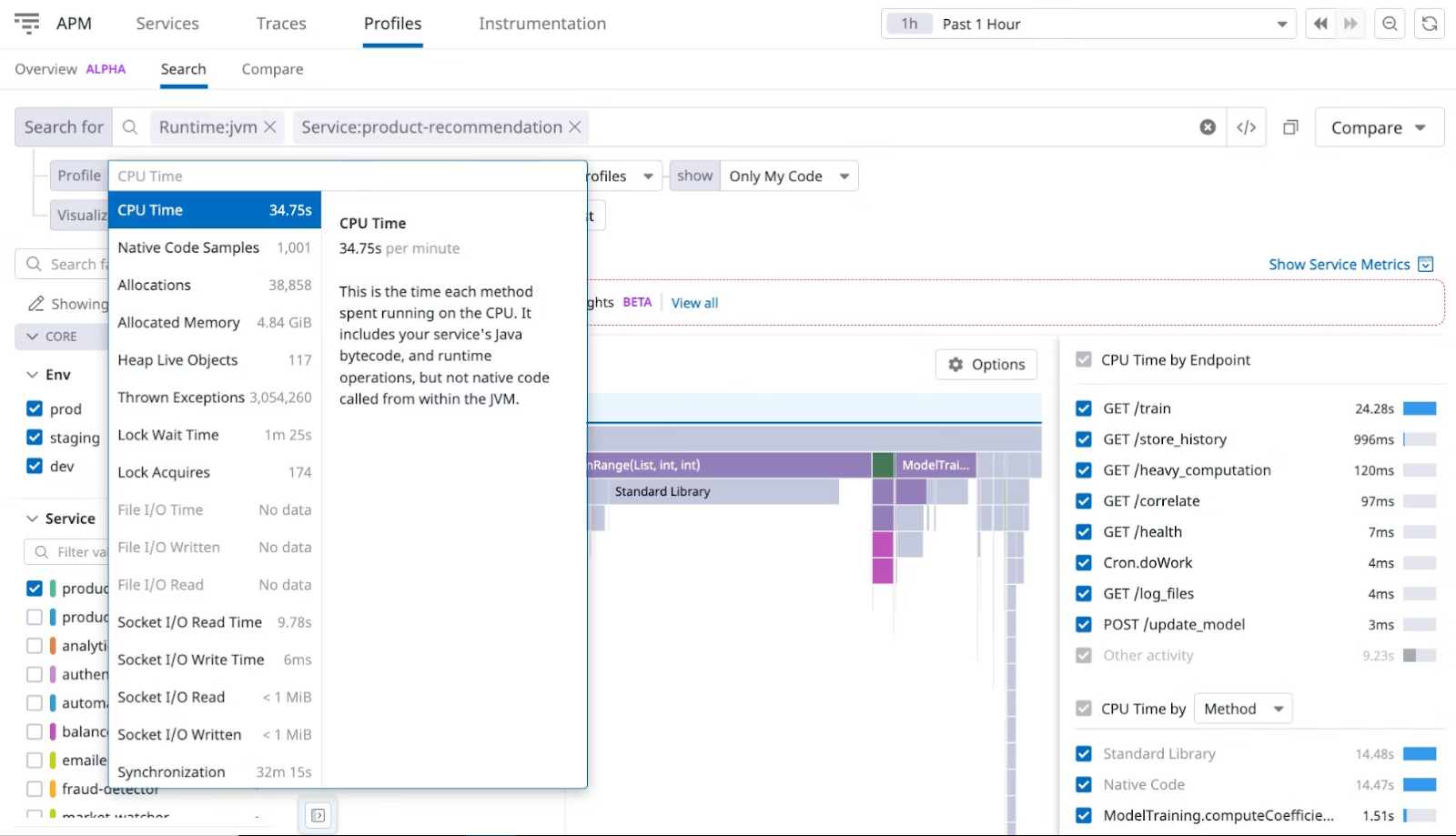 Datadog Continuous Profiler.png
Datadog Continuous Profiler.png
Figure : Datadog Continuous Profiler
{kind=link}
L’outil surveille chaque ligne de code sur l’ensemble des systèmes, conteneurs et hôtes, en mettant en évidence les blocs dont les performances sont inefficaces avec différentes charges de production. Il offre également une visibilité au niveau des threads qui vous permet de corréler les spans et d’identifier la cause racine des requêtes lentes.
Amazon CodeGuru Profiler
Amazon CodeGuru Profiler permet aux développeurs d’identifier les vulnérabilités, anomalies et inefficacités à l’exécution grâce à des techniques de ML et de raisonnement automatisé. L’outil prend en charge les applications Python et Java.
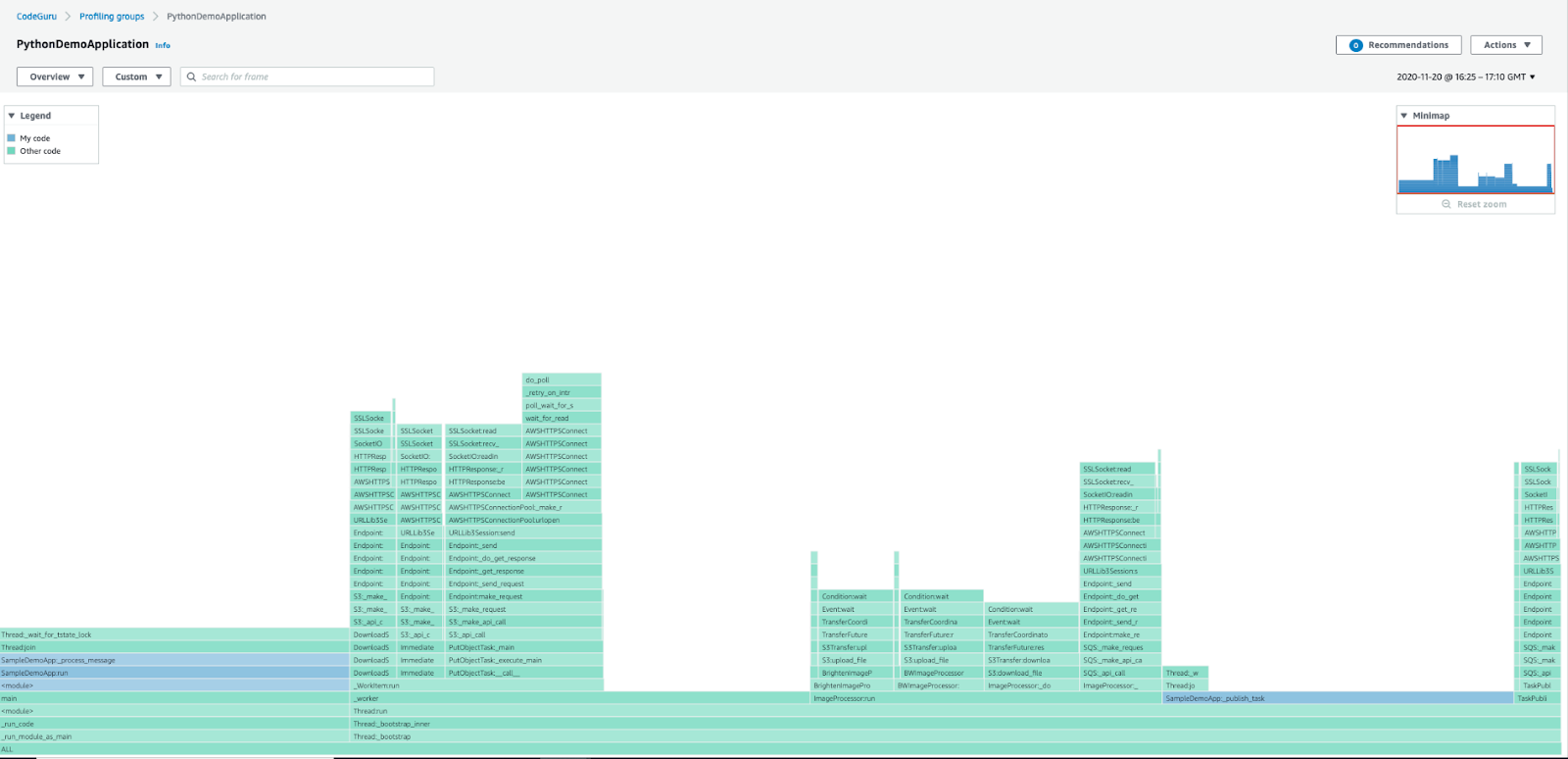 Amazon CodeGuru Profiler.png
Amazon CodeGuru Profiler.png
Figure : Amazon CodeGuru Profiler
{kind=link}
Il offre un suivi automatisé des bugs et des suggestions pour corriger le code afin d’accélérer le débogage. Les flame graphs interactifs et les résumés de heap vous aident à visualiser les chemins de code et l’allocation des objets grâce à l’analyse de l’utilisation du heap.
Google Cloud Profiler
Google Cloud Profiler est un outil de profilage continu léger permettant de surveiller les données d’utilisation du CPU et de la mémoire dans les applications de production. Il fonctionne avec les frameworks Python, Node.js, Go et Java.
 Google Cloud Profiler.png
Google Cloud Profiler.png
Figure : Google Cloud Profiler
{kind=link}
L’outil relie les données d’utilisation au code source pour vous aider à identifier l’origine d’un problème spécifique. Il dispose également d’une interface intuitive avec de multiples fonctionnalités pour contrôler la visualisation. Par exemple, vous pouvez filtrer les données de performance en fonction des types de profileurs, des zones et de la période.
Monitoring & Observability de Zilliz Cloud
Zilliz Cloud est un service de base de données vectorielle entièrement géré, propulsé par Milvus. Il vous permet d’exploiter tout le potentiel des données non structurées pour vos applications d’IA. Il est également idéal pour de nombreux cas d’utilisation populaires, tels que la génération augmentée par récupération (RAG), le traitement du langage naturel (NLP), la recherche sémantique, la recherche d’images, les systèmes de recommandation et les chatbots d’IA.
Les bases de données vectorielles comme Zilliz Cloud jouant un rôle crucial dans les applications d’IA modernes, il est essentiel d’évaluer leurs performances en temps réel. Zilliz Cloud a récemment introduit une fonctionnalité de monitoring complète pour suivre les performances et l’état du système en temps réel. Ces améliorations fournissent des alertes personnalisables et surveillent une série de métriques clés, notamment l’utilisation du CPU, la latence, les requêtes par seconde, les vecteurs par seconde et la consommation de stockage. Le système suit également le nombre d’entités chargées ainsi que le nombre d’entités et de collections, assurant une visibilité complète sur les opérations de la base de données.
 Zilliz Cloud monitoring.png
Zilliz Cloud monitoring.png
Figure : monitoring de Zilliz Cloud
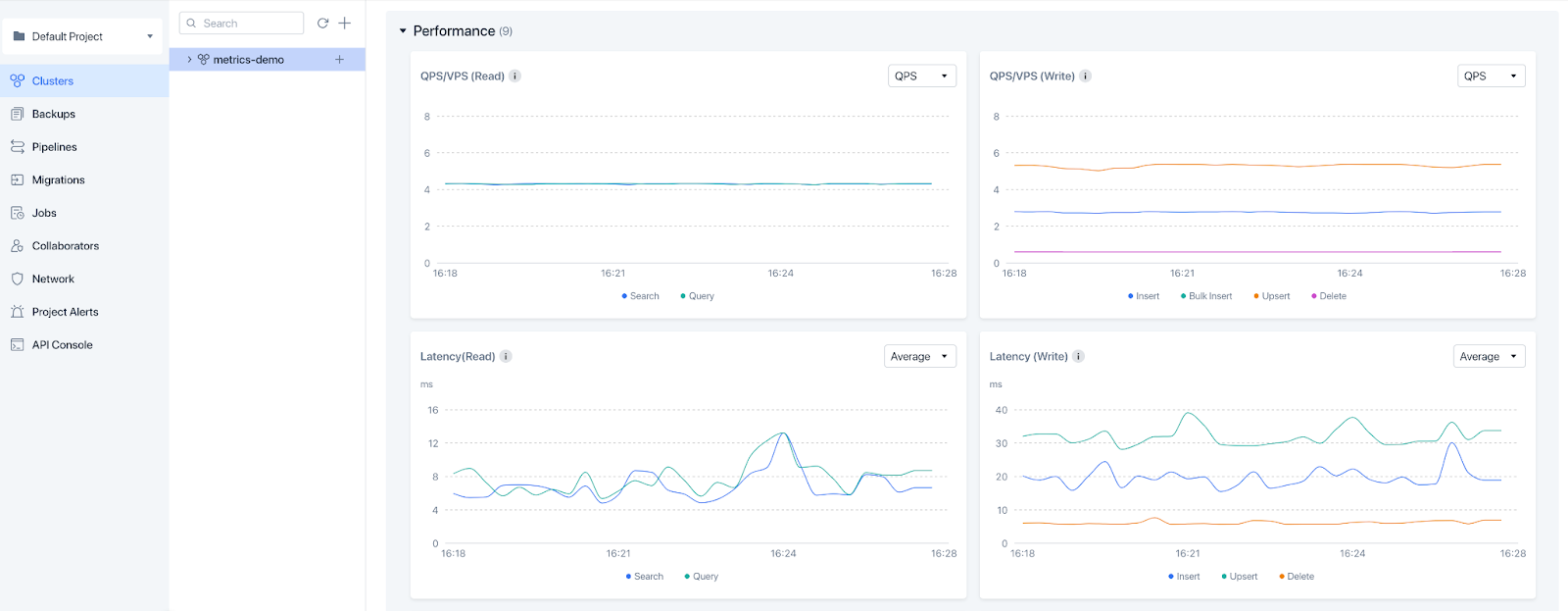{kind=link}
Vous pouvez également intégrer des alertes avec des seuils et des niveaux de gravité prédéfinis, ainsi que plusieurs canaux de notification, afin de ne jamais manquer un événement important.
Comment choisir un outil de profilage ?
Bien que la liste ci-dessus propose quelques options adaptées, vous devez choisir un outil qui correspond à votre cas d’utilisation et à vos objectifs spécifiques. Les points ci-dessous mettent en évidence quelques éléments à prendre en compte lorsque vous investissez dans un outil de profilage.
Faible surcharge : Lors de la collecte des données de performance, l’outil doit avoir un impact minimal sur vos opérations et votre infrastructure existantes.
Prise en charge des langages et des plateformes : L’outil doit être compatible avec le langage de programmation et le framework de votre application.
Visualisation des données : Recherchez des fonctionnalités de visualisation qui peuvent vous aider à vous concentrer sur les métriques critiques grâce à des tableaux de bord intuitifs et des fonctionnalités interactives.
Scalabilité : Assurez-vous que l’outil est facile à faire évoluer dans des environnements distribués, en soutenant la croissance sans compromettre les performances.
FAQ sur le profilage continu
- Le profilage continu est-il gourmand en ressources ?
Le profilage continu utilise des profileurs légers pour collecter des données avec une surcharge minimale afin d’enregistrer les statistiques pertinentes dans les environnements de production.
- Le profilage continu peut-il détecter les fuites de mémoire ?
Oui. Le profilage continu peut identifier les fuites en surveillant les modèles d’utilisation de la mémoire au fil du temps.
- En quoi le profilage continu est-il différent de la journalisation ?
La journalisation enregistre des séquences d’événements spécifiques, tandis que le profilage continu enregistre des données de performance plus étendues concernant l’utilisation des ressources, telles que la consommation du CPU, l’utilisation de la mémoire et les opérations d’E/S.
- Quels types de métriques de performance le profilage continu suit-il ?
Le profilage continu suit l’utilisation du CPU, l’utilisation de la mémoire, les opérations d’E/S et les statistiques de latence.
- Quels sont les types de profilage continu ?
Le profilage par échantillonnage et le profilage par instrumentation sont les deux méthodes de surveillance des métriques de performance. Un profileur par échantillonnage enregistre les données à intervalles réguliers, tandis que l’instrumentation profile le code à différents points de contrôle.
Ressources connexes
Bien que le profilage continu concerne la surveillance des performances pour tous les systèmes, les ressources ci-dessous vous aideront à comprendre le fonctionnement de cette méthode pour les bases de données vectorielles.
- Qu’est-ce que le profilage continu ?
- Comment fonctionne le profilage continu ?
- Visualisation des données
- Profilage traditionnel vs profilage continu
- Avantages et défis du profilage continu
- Outils de profilage
- Monitoring & Observability de Zilliz Cloud
- Comment choisir un outil de profilage ?
- FAQ sur le profilage continu
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement