




La chaîne de la pensée : Guider l'IA pour qu'elle réfléchisse étape par étape
La chaîne de la pensée : Guider l'IA pour qu'elle réfléchisse étape par étape
Qu'est-ce que l'incitation à la réflexion en chaîne ?
La chaîne de pensée (CoT) est une technique de prompt engineering qui aide les grands Large Language Models (LLMs) à décomposer les problèmes complexes en étapes plus petites et plus faciles. Au lieu de donner une réponse directe, le modèle propose une séquence de pensées ou de raisonnements, comme une personne qui résoudrait un problème étape par étape.
Comment fonctionne l'incitation à la réflexion en chaîne ?
L'incitation à la réflexion en chaîne fonctionne en guidant les [modèles d'IA] (https://zilliz.com/glossary/foundation-models) pour qu'ils s'attaquent à des problèmes complexes étape par étape. Cette méthode repose sur un raisonnement séquentiel ; chaque étape s'appuie sur la précédente. Par exemple, supposons qu'un problème mathématique difficile soit posé au modèle. Au lieu d'essayer de donner la réponse finale tout de suite, il procède d'abord à des calculs plus petits ou à des étapes logiques, ce qui lui permet d'obtenir un résultat final plus précis. Ce processus de décomposition du problème aide le modèle à obtenir la bonne réponse et à comprendre comment il y est parvenu, ce qui améliore la qualité globale de la réponse.
Exemple pratique : Avant et après l'incitation à la réflexion en chaîne
Comprenons le fonctionnement de la CoT à l'aide d'un exemple concret. Les deux invites montrent l'impact de la chaîne de pensée sur la réponse du modèle d'IA.
1. Invitation avant CoT
Classer les avis d'utilisateurs suivants dans les catégories "positif", "négatif" ou "neutre":________________.
Le produit est arrivé en retard mais fonctionne bien.
"Un service et une qualité absolument fantastiques !" "Un service et une qualité absolument fantastiques !""Un service et une qualité absolument fantastiques !
Je n'aimais pas la couleur, mais le service clientèle m'a aidé.
Je n'ai pas aimé la couleur, mais le service clientèle m'a aidé"_"Terrible expérience. Je ne le recommanderais pas".
"C'est bien, ça fait l'affaire." "C'est bien, ça fait l'affaire." "C'est bien, ça fait l'affaire.
Réponse:
 Prompt sans COT.png
Prompt sans COT.png
Figure : Invite sans CoT
Analyse:
Dans l'invite naïve, le modèle fournit un résultat de base dans lequel chaque avis est simplement classé sans expliquer comment il est parvenu à chaque décision. Il ne montre pas à l'utilisateur le raisonnement qui sous-tend la catégorisation et ne lui indique pas quels mots ou phrases spécifiques ont été considérés comme positifs ou négatifs. Le résultat est correct mais manque de profondeur et de transparence.
2. Invite après la CdT
- Veuillez classer les commentaires d'utilisateurs suivants comme "positifs", "négatifs" ou "neutres". Pour chaque commentaire, suivez les étapes suivantes
Lisez attentivement l'avis.
Identifiez les mots ou les phrases positives.
_Identifiez les mots ou phrases négatifs.
Évaluer le sentiment général sur la base des éléments positifs et négatifs.
Attribuer la catégorie appropriée.
En sortie, présentez toutes les informations dans un tableau.
Procéder à l'examen de chaque dossier : ________________________________________________________________________________.
Le produit est arrivé en retard mais fonctionne très bien.
"Un service et une qualité absolument fantastiques !" "Un service et une qualité absolument fantastiques !""Un service et une qualité absolument fantastiques !
Je n'aimais pas la couleur, mais le service clientèle m'a aidé.
Je n'ai pas aimé la couleur, mais le service clientèle m'a aidé"_"Terrible expérience. Je ne le recommanderais pas".
_"C'est bien, ça fait l'affaire." _ "C'est bien, ça fait l'affaire." _ "C'est bien".
Réponse:
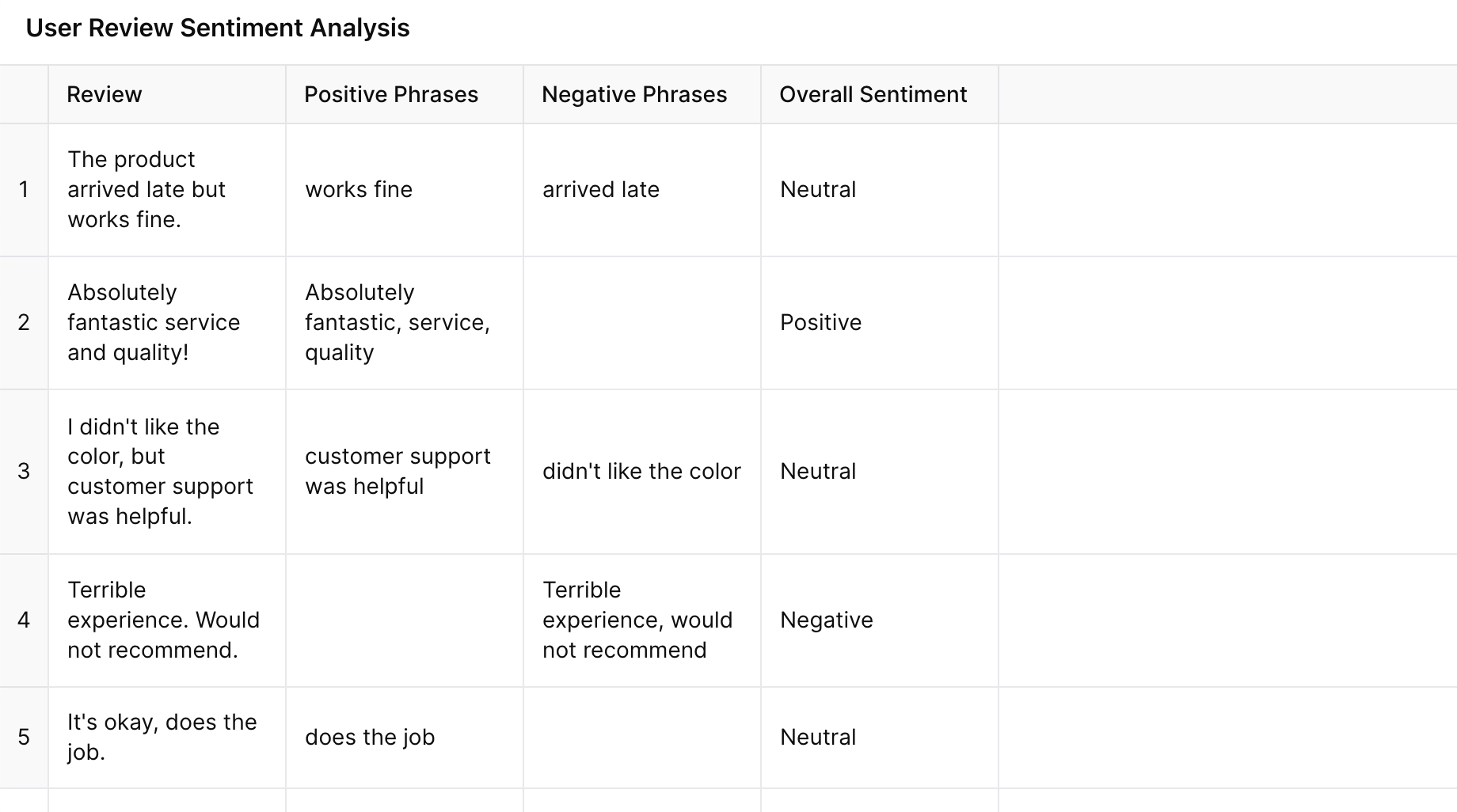 Invitation avec CoT
Invitation avec CoT
Figure : Invite avec CoT
Analyse:
Le modèle explique son raisonnement en identifiant les phrases positives et négatives dans chaque avis, ce qui permet à l'utilisateur de comprendre clairement la décision.
Un tableau est généré, qui non seulement énumère la catégorie finale, mais montre également les phrases clés de chaque avis, ce qui rend le résultat plus structuré et plus transparent.
Variantes de la chaîne de pensée avec des exemples d'invites
Voici différents types d'incitation à l'enchaînement de la pensée, accompagnés d'exemples pratiques pour chacun d'entre eux :
1. Incitation à la chaîne de pensée standard
Ce type de chaîne de pensée demande au modèle de réfléchir à chaque partie du problème, étape par étape.
Exemple d'incitation:
Un train roulant à 60 miles par heure doit parcourir 180 miles. Combien de temps lui faudra-t-il pour effectuer ce trajet ? Voyons cela étape par étape.
Réponse attendue du modèle:
"Le train roule à 60 miles par heure.
"La distance à parcourir est de 180 miles.
"Pour trouver le temps, il faut diviser la distance par la vitesse : 180 ÷ 60 = 3.
"Il faudra donc 3 heures pour atteindre la destination."
2. Incitation à l'enchaînement de quelques pensées
Dans une chaîne de pensée à quelques reprises, le modèle reçoit quelques exemples avant d'être invité à résoudre un nouveau problème.
Exemple d'incitation:
Voici un exemple : Quelle est la vitesse d'une voiture qui parcourt 100 miles en 2 heures ? La vitesse est de 100 ÷ 2 = 50 miles par heure. Voici un autre exemple : Si un avion parcourt 600 miles en 3 heures, sa vitesse est de 600 ÷ 3 = 200 miles par heure. Maintenant, en suivant les mêmes étapes, si un cycliste parcourt 90 miles en 3 heures, quelle est sa vitesse ?".
Réponse attendue du modèle:
"La distance est de 90 miles et le temps est de 3 heures.
"Pour trouver la vitesse, nous divisons 90 par 3.
"90 ÷ 3 = 30 miles par heure".
3. Cohérence personnelle Chaîne de pensée
Le modèle génère plusieurs voies de raisonnement et choisit la réponse la plus cohérente.
Exemple de l'énoncé:
Si une personne achète 6 pommes pour 12 $, combien coûte chaque pomme ? Essayons de résoudre ce problème de différentes manières et comparons les réponses."_ _Réponse attendue du modèle:** _Réponse attendue du modèle:** _Réponse attendue du modèle Réponse attendue du modèle:
Voie 1 :
- "Le coût total est de 12 $ et il y a 6 pommes.
- "12 $ ÷ 6 = 2 $ par pomme". Piste 2 :
- "Si 6 pommes coûtent 12 $, chaque pomme coûte 2 $ car 12 $ divisés par 6 sont égaux à 2 $. Réponse finale: "Les deux méthodes aboutissent au même résultat, le coût par pomme est donc de 2 $.
4. Chaîne de pensée interactive
Dans cette variante, le modèle demande des clarifications ou des informations supplémentaires lorsque cela est nécessaire. Exemple de message: Vous avez un total de 50 dollars et vous voulez acheter des livres. Chaque livre coûte 7 dollars. Combien de livres pouvez-vous acheter et combien d'argent vous restera-t-il ? Si vous avez besoin de plus d'informations, n'hésitez pas à demander avant de résoudre la question. Réponse attendue du modèle: 1. "Les taxes sont-elles incluses dans le prix du livre, ou s'agit-il simplement de 7 dollars par livre ?" (Si l'utilisateur confirme qu'il s'agit de 7 $ par livre sans les taxes) 2. "D'accord, sans les taxes, \N50$ divisé par \N7$ donne environ 7 livres. Puisque 7 × 7 égalent 49." 3. "Il vous restera 1 $ après avoir acheté 7 livres."
5. Chaîne de pensée multi-agents
Dans ce cas, plusieurs agents d'intelligence artificielle collaborent pour résoudre le problème en s'attaquant à différentes parties. Exemple d'introduction: Il y a 45 étudiants et 9 enseignants qui partent en voyage. Si chaque bus peut contenir 15 personnes, combien de bus sont nécessaires ? Demandons à un agent de calculer le nombre total de personnes, à un autre agent de calculer la division et à un troisième agent de vérifier la solution". Réponse attendue du modèle: Agent 1: "Le nombre total de personnes est de 45 élèves + 9 professeurs = 54 personnes. Agent 2: "Nous divisons 54 personnes par 15 par bus : 54 ÷ 15 = 3,6, ce qui signifie que nous avons besoin de 4 bus". Agent 3: "Le nombre total de personnes et le calcul sont exacts." Nous avons besoin de 4 bus.
6. Chaîne de pensée récursive
Le modèle vérifie son propre raisonnement et révise les étapes si nécessaire. Exemple de l'énoncé: "_Avec 120 $ en main, vous dépensez 45 $ pour les courses, 30 $ pour l'essence et 20 $ pour les loisirs. Combien d'argent vous reste-t-il ? Veuillez vérifier vos calculs au fur et à mesure". Réponse attendue du modèle:
- "En commençant par 120 $."
- "$120 - $45 = $75."
- "$75 - $30 = $45."
- "$45 - $20 = $25."
- "Vérification : \N120 - \N45 = \N75, puis \N75 - \N30 = \N45, et enfin \N45 - \N20 = \N25. La réponse est \N25$".
Quand utiliser l'incitation à la chaîne de pensée ?
L'incitation à l'enchaînement des pensées convient aux tâches qui nécessitent un raisonnement en plusieurs étapes, une réflexion logique ou une analyse minutieuse. Voici quelques scénarios dans lesquels la chaîne de pensée peut s'avérer utile :
Problèmes mathématiques ou calculs: Lorsque la tâche implique plusieurs opérations ou calculs, la CoT guide le modèle à travers chaque étape. Par exemple, pour résoudre des problèmes de mots ou des opérations arithmétiques complexes, il faut décomposer l'information en éléments plus petits et plus faciles à gérer avant d'effectuer les calculs.
Raisonnement logique et déduction: CoT est idéal pour les tâches où le modèle doit analyser des informations étape par étape, qu'il s'agisse de prendre une décision basée sur plusieurs facteurs ou de résoudre une énigme impliquant des étapes logiques.
Résolution de problèmes en plusieurs étapes: Des tâches comme équilibrer un budget, suivre une recette ou résoudre un problème technique nécessitent souvent plusieurs étapes. La CdT aide le modèle à suivre ces étapes dans le bon ordre.
Réponse à des questions complexes: CoT peut guider le modèle à travers le raisonnement nécessaire pour donner une réponse plus précise et plus détaillée lorsqu'on lui pose des questions complexes en science, en droit ou en philosophie. Au lieu de deviner, il analyse les faits et la logique nécessaires à l'élaboration d'une réponse solide.
Améliorer encore l'incitation à la réflexion en chaîne
Pour améliorer encore l'efficacité de l'invite, d'autres techniques peuvent être combinées pour traiter le raisonnement. Par exemple :
Fournir des invites claires et structurées: La qualité de l'invite a un impact significatif sur le raisonnement. Les messages-guides doivent être conçus de manière à améliorer la confiance en soi et à décomposer les problèmes en étapes logiques. Plus l'invite est structurée et détaillée, mieux le modèle suivra le processus de raisonnement.
**L'apprentissage par petites touches, dans lequel le modèle donne quelques exemples de raisonnement à partir de problèmes, peut améliorer la confiance en soi. En montrant au modèle plusieurs cas similaires où le raisonnement étape par étape a été utilisé, il peut mieux comprendre comment aborder de nouvelles tâches.
Auto-réflexion et vérification: L'un des moyens d'améliorer la confiance en soi consiste à inviter le modèle à vérifier son propre raisonnement. Après avoir généré une réponse, le modèle peut être invité à revoir ses étapes pour s'assurer qu'elles sont logiques. Cela permet de détecter les erreurs logiques ou les lacunes avant de donner la réponse finale.
Intégration de l'autoconsistance: L'autoconsistance est une méthode par laquelle le modèle génère plusieurs chemins de raisonnement et les compare ensuite pour voir s'ils mènent à la même conclusion. Si plusieurs chemins concordent, le modèle est plus susceptible d'être parvenu à la bonne réponse. Par exemple, on peut demander au modèle de résoudre un problème de deux manières différentes, puis sélectionner la réponse la plus cohérente entre les différentes approches.
Limites de l'incitation à la chaîne de pensée
Bien que l'incitation par chaîne de pensée soit une approche puissante pour améliorer le raisonnement de l'IA, elle présente certaines limites qui peuvent avoir un impact sur son efficacité dans certains scénarios.
1. Susceptibilité aux erreurs de raisonnement: La chaîne de pensée repose sur le fait que le modèle suit un processus logique, étape par étape. Cependant, si le modèle commet une erreur dans une étape, cette erreur peut se répercuter sur la réponse finale.
2. Frais généraux en temps et en ressources: Le CoT nécessite plus de ressources informatiques car le modèle doit réfléchir à chaque étape au lieu de fournir une réponse directe. Cela peut rendre le processus plus lent et plus gourmand en ressources, en particulier pour les problèmes complexes ou à plusieurs étapes. Dans les situations où la rapidité est une priorité, la méthode CoT n'est peut-être pas idéale.
4. Dépendance à l'égard de messages-guides bien conçus: L'efficacité du CoT dépend fortement de la qualité des messages-guides fournis. Si l'invite n'est pas claire ou bien structurée, le modèle risque d'avoir du mal à résoudre le problème. L'élaboration de ces messages-guides requiert des efforts et de l'expertise.
5. Généralisation limitée à des tâches inconnues: CoT est très efficace pour les tâches qu'il a déjà vues ou qui ressemblent étroitement à des tâches antérieures. Cependant, lorsqu'il est confronté à des problèmes ou à des tâches qui ne lui sont pas familiers et qui ne font pas partie de ses données d'apprentissage, le modèle peut avoir du mal à appliquer efficacement la CoT, car il s'appuie sur des schémas de raisonnement appris.
6. Risque d'adaptation excessive à la structure de l'invite: Avec le temps, un modèle formé à l'utilisation de la CoT pourrait devenir trop dépendant d'invites spécifiques, ce qui limiterait sa flexibilité. Le modèle Overfitting pourrait s'attendre à ce que les problèmes soient toujours présentés dans un format particulier, ce qui rendrait plus difficile l'adaptation du modèle à des tâches nouvelles ou formulées différemment.
Cas d'utilisation de la chaîne de pensée dans le monde réel
L'incitation à la réflexion en chaîne a un large éventail d'applications pratiques dans divers domaines. Voici quelques cas d'utilisation clés dans le monde réel où la chaîne de pensée peut s'avérer très bénéfique :
1. Résolution de problèmes mathématiques
La CdT est extrêmement utile dans l'enseignement des mathématiques et les plates-formes de tutorat. Les étudiants peuvent comprendre le processus en décomposant les problèmes mathématiques en étapes plus petites et logiques au lieu d'obtenir simplement la réponse finale. Il est également utile pour les calculs avancés dans des domaines tels que l'algèbre, le calcul et les statistiques.
2. Raisonnement juridique et analyse des contrats
Dans les systèmes juridiques, le CoT aide les systèmes d'IA à évaluer les documents juridiques, à analyser les clauses et à générer des conseils juridiques en passant systématiquement en revue chaque point d'un contrat ou d'une affaire. Il peut également expliquer le [raisonnement juridique] étape par étape (https://zilliz.com/blog/simplifying-legal-research-with-rag-milvus-ollama), ce qui rend l'IA plus transparente et plus fiable dans les processus juridiques.
3. Assistance à la clientèle et dépannage
Le CoT aide les chatbots ou les systèmes d'assistance pilotés par l'IA à guider les utilisateurs à travers des processus de dépannage étape par étape. C'est utile pour les questions techniques, lorsque l'utilisateur doit suivre des instructions ou des étapes de diagnostic pour résoudre un problème.
4. Diagnostic médical et aide à la décision
La CdT peut aider les médecins ou les professionnels de la santé à analyser les symptômes, les résultats des tests et les antécédents médicaux afin de suggérer des diagnostics ou des traitements possibles, en expliquant comment chaque conclusion a été tirée.
5. Réponse aux questions complexes
La CoT est très efficace pour répondre à des questions complexes qui nécessitent plus qu'une simple recherche de faits. Pour les questions portant sur des domaines tels que l'histoire, les sciences ou le droit, la CoT peut aider les systèmes d'IA à fournir des réponses détaillées, en plusieurs étapes, expliquant le raisonnement de la réponse.
6. Stratégie de jeu et résolution d'énigmes
Dans les jeux, les stratégies sont générées par la prise en compte de plusieurs étapes dans une séquence. CoT décompose les stratégies complexes dans les scénarios de jeu ou de résolution d'énigmes en mouvements plus petits et plus réfléchis qui conduisent à une meilleure prise de décision et à un meilleur jeu pour des jeux comme les échecs, le Go ou les jeux d'énigmes.
Comment Milvus peut-il améliorer l'efficacité de l'incitation à la chaîne de pensée ?
Milvus, une base de données vectorielle open-source développée par Zilliz, est conçue pour stocker et récupérer efficacement des données non structurées telles que des images, du texte et des vidéos. Alors que l'incitation à la chaîne de pensée se concentre sur l'amélioration des capacités de raisonnement des modèles d'IA, Milvus améliore la façon dont ces modèles gèrent et traitent les données vectorielles à grande échelle.
- Efficient Data Retrieval for Complex Reasoning: CoT repose sur l'accès des modèles d'IA à des informations pertinentes pour un raisonnement étape par étape. Milvus est un backend efficace, qui stocke de grandes quantités de données vectorielles (telles que les text embeddings) et permet une récupération rapide. Cela permet aux modèles d'IA d'accéder sans délai aux données dont ils ont besoin à chaque étape du processus de raisonnement.
Appui aux applications à grande échelle: Dans de nombreux cas réels, les messages-guides CoT nécessitent la manipulation de vastes ensembles de données pour un raisonnement en plusieurs étapes. L'utilisation de Milvus dans de nombreux cas réels permet aux modèles d'IA de travailler avec de grands ensembles de données sans compromettre la vitesse ou les performances.
Recherches de similarité optimisées: Milvus est conçu pour des [recherches sémantiques] (https://zilliz.com/glossary/semantic-search) et des [recherches de similarité] (https://zilliz.com/learn/vector-similarity-search) rapides, ce qui améliore le CoT en permettant à l'IA d'accéder rapidement à des données sémantiquement liées. Cela accélère le processus de raisonnement, car le modèle peut extraire des informations pertinentes de manière plus précise et plus efficace lorsqu'il s'agit de résoudre des problèmes à plusieurs étapes.
Conclusion
En résumé, l'invitation à la chaîne de pensée aide les modèles d'IA à résoudre des problèmes complexes en les divisant en étapes logiques, ce qui améliore la précision et la clarté. Milvus améliore ce processus en permettant un accès rapide à de grandes quantités de données non structurées, de sorte que l'IA puisse extraire des informations pertinentes à chaque étape. CoT et Milvus offrent des solutions pratiques pour traiter des tâches complexes dans des domaines tels que la recherche, l'assistance à la clientèle et l'analyse financière, rendant l'IA plus efficace et plus fiable dans les applications du monde réel.
FAQ sur l'incitation à la chaîne de pensée
Comment l'invitation à la chaîne de pensée améliore-t-elle le raisonnement de l'IA?
L'incitation par chaîne de pensée améliore le raisonnement de l'IA en guidant le modèle pas à pas dans la résolution des problèmes. Cette méthode encourage le modèle à décomposer les tâches complexes en éléments plus petits et plus faciles à gérer, ce qui permet de réduire les erreurs et d'améliorer la précision.
Quand utiliser le guidage par chaîne de pensée?
La CoT est utilisée de préférence pour les tâches qui nécessitent un raisonnement en plusieurs étapes, une analyse logique approfondie ou la résolution de problèmes complexes. Les exemples incluent les problèmes mathématiques, les déductions logiques, le dépannage technique et les processus de prise de décision à multiples facettes.
- Quels sont les principaux avantages de l'incitation à la réflexion en chaîne ?
Les principaux avantages de la chaîne de pensée sont l'amélioration de la précision, une meilleure gestion des problèmes complexes, la réduction des erreurs, l'amélioration de la transparence du modèle et une approche structurée qui rend le raisonnement de l'IA plus compréhensible et plus fiable.
- Comment Milvus améliore-t-il l'efficacité de l'invitation à la réflexion en chaîne ?
Milvus améliore l'incitation à la chaîne de pensée en stockant et en récupérant efficacement des données non structurées à grande échelle, telles que du texte et des images. Il permet aux modèles d'IA d'accéder rapidement aux données pertinentes à chaque étape du raisonnement pour des performances fluides et rapides dans les tâches complexes à plusieurs étapes.
Qu'est-ce qui différencie l'invitation à la chaîne de pensée des réponses traditionnelles de l'IA?
Les réponses traditionnelles de l'IA tentent souvent de fournir une réponse directe sans détailler le processus de raisonnement. En revanche, l'invitation à suivre une chaîne de pensée guide le modèle dans l'explication de son raisonnement étape par étape, offre de la transparence et suit une progression logique vers la solution.
Ressources connexes
- Qu'est-ce que l'incitation à la réflexion en chaîne ?
- Comment fonctionne l'incitation à la réflexion en chaîne ?
- Variantes de la chaîne de pensée avec des exemples d'invites
- Quand utiliser l'incitation à la chaîne de pensée ?
- Améliorer encore l'incitation à la réflexion en chaîne
- Limites de l'incitation à la chaîne de pensée
- Cas d'utilisation de la chaîne de pensée dans le monde réel
- Comment Milvus peut-il améliorer l'efficacité de l'incitation à la chaîne de pensée ?
- Conclusion
- FAQ sur l'incitation à la chaîne de pensée
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement