




Calcul à la demande de Zilliz Cloud : ne payez que ce que vous utilisez
Le trimestre dernier, nous avons travaillé sur un cas de facturation avec un client spécialisé dans la conduite autonome. Son équipe d’analytique avait besoin d’une recherche vectorielle sur une collection de 1 milliard de lignes. Nous l’avons dimensionnée sur un cluster Dedicated : 7 000 $ par mois. Nous avons essayé Serverless : 10 800 $. Le travail analytique réel représentait quelques heures par mois.
Les deux factures étaient correctes. Les deux produits faisaient exactement ce pour quoi ils ont été conçus. Le problème était que la charge de travail de ce client — des analyses sporadiques partageant un jeu de données avec deux autres charges de travail de production — ne correspondait pas à ce pour quoi l’un ou l’autre produit avait été conçu.
C’est pour ce cas que nous avons créé Zilliz Cloud On-Demand Search — l’une des nouvelles fonctionnalités que nous avons livrées avec le lancement de Zilliz Vector Lakebase. Même charge de travail, moins de 500 $ par mois. Voici ce qui ne convenait pas, ce que nous avons changé, les cas où On-Demand n’est pas le bon outil, et comment il s’intègre de nouveau dans Vector Lakebase à la fin.
Le cas client
La collection — environ 1 milliard d’enregistrements — était déjà utilisée par deux charges de travail de production :
- Un service de récupération en ligne servant du trafic en temps réel.
- Un pipeline d’entraînement de modèles qui extrait des données de scénarios pour des tâches de régression (exécuté par une équipe distincte).
L’analytique était une troisième charge de travail ajoutée par-dessus les mêmes données. Le schéma d’accès : les analystes ne lançaient des recherches que lorsqu’ils avaient une question précise, par courtes itérations dictées par l’enquête en cours. Le reste du temps, aucune requête analytique n’atteignait le cluster.
C’est un cas d’utilisation Zilliz assez courant, à une échelle de données assez courante. Ce qui le rendait difficile, c’est que les trois charges de travail devaient lire la même collection sous-jacente, et que chacune avait une cadence très différente.
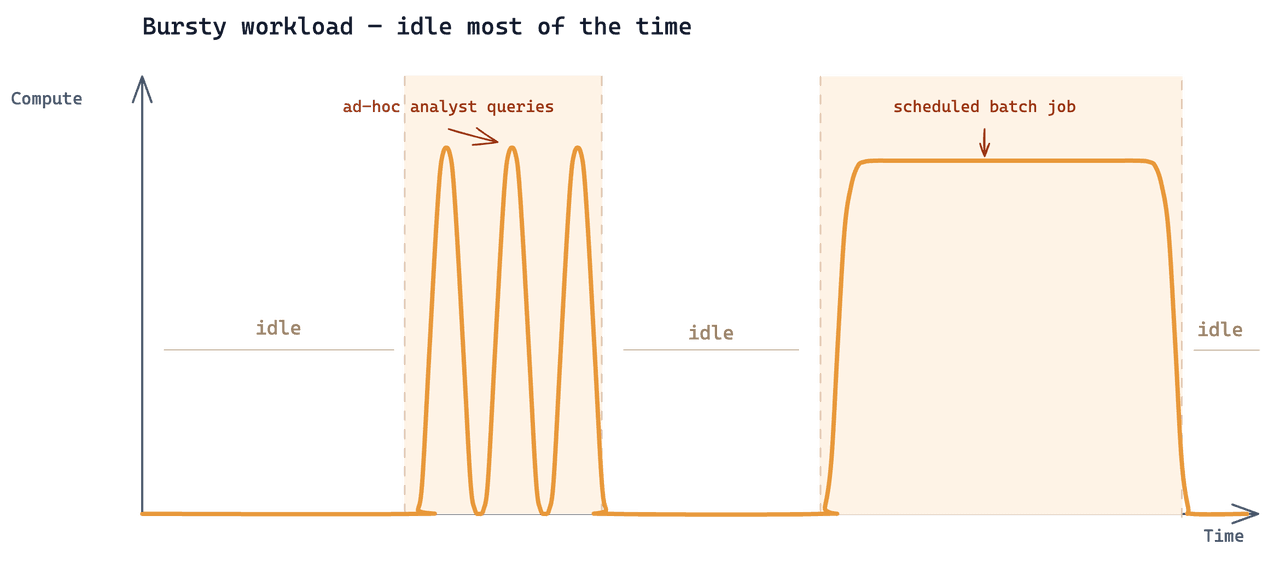
Pourquoi le cluster Dedicated ne convenait pas
La configuration existante était un cluster à paliers Zilliz Cloud de 24 CU. L’ajout de la charge de travail analytique à celui-ci revenait à environ 7 000 $ par mois. Le cluster est facturé pour chaque heure d’existence : 24 × 30 = 720 heures par mois. Le travail analytique réel consommait 2 à 3 heures. Les 717 heures restantes étaient facturées alors que le cluster restait inactif — 99,6 % de la dépense totale allait à une capacité que personne n’utilisait.
Vous pouvez arrêter un cluster Dedicated entre deux sessions pour éviter les heures d’inactivité. Nous l’avons envisagé. Cela ne fonctionne pas, pour deux raisons.
Premièrement, le démarrage à froid sur Dedicated prend plus de 10 minutes pour des requêtes analytiques à froid sur un jeu de données de cette taille. Le modèle mental de Dedicated est que toutes les données requises doivent être en mémoire locale avant l’exécution des requêtes, il précharge donc l’ensemble de travail complet — généralement des dizaines à des centaines de fois plus de données que ce qu’une seule requête à froid touche réellement. Le même chargement doit aussi mettre en place l’état nécessaire aux tâches hors requête prises en charge par le cluster, comme le DDL et les suppressions. Cette surcharge existe, que la requête suivante en ait besoin ou non.
Deuxièmement, la facturation est arrondie à l’heure. Ainsi, même si l’analyste acceptait d’attendre plus de 10 minutes que le cluster chauffe, la facture pour une seule requête reste d’une heure plus le chargement. Comme les analystes travaillent par courtes itérations, le coût par requête utile reste élevé, quelle que soit la rigueur de la discipline de démarrage/arrêt.
Pourquoi le cluster Serverless ne convenait pas
Serverless était l’option suivante que nous avons essayée. Sur le papier, elle a la bonne forme pour ce schéma d’accès : sans état, paiement à la requête, pas de calcul inactif. Pour la charge de travail analytique seule, cela aurait pu fonctionner.
Le problème est que Serverless sur ce jeu de données ne tarifie pas la charge de travail analytique isolément. Il tarifie tout ce qui touche la collection. Une fois les charges de travail existantes incluses, trois postes ont rendu le calcul défavorable :
- Requêtes : ~6 000 $/mois. La majeure partie provenait des jobs de régression bimensuels de l’équipe d’entraînement des modèles — 100 QPS pendant 3 heures, toutes les deux semaines. Les prix unitaires du Serverless intègrent une prime de requête à froid qui est payée sur chaque requête, même lorsque la requête est chaude. Dès que le volume de requêtes n’est plus trivialement bas, le calcul ne tient plus.
- Stockage : 1 700 $/mois. Mesuré séparément parce que Serverless n’a pas de frais d’heure de calcul dans lesquels intégrer le stockage.
- Écritures : 3 000 $/mois. Même raison — pas d’heure de calcul dans laquelle les intégrer.
Total : 10 784 $/mois, plus élevé que le cluster Dedicated auquel nous essayions d’échapper.
Chacune de ces primes a une raison structurelle derrière elle.
Les requêtes portent une prime de requête à froid. Du côté utilisateur, Serverless est sans état. Du côté plateforme, les données doivent tout de même être chargées sur des machines spécifiques pour être exécutées. Les requêtes se répartissent entre chaudes (données déjà sur la machine) et froides (récupération depuis le stockage objet d’abord). Les requêtes chaudes sont peu coûteuses ; les requêtes froides sont coûteuses. La plateforme ne peut pas prédire quelles requêtes seront froides pour un utilisateur donné, elle répartit donc le coût des requêtes à froid sur le prix unitaire de chaque requête. Les charges de travail avec des requêtes majoritairement chaudes finissent par payer pour les requêtes froides de tout le monde.
Le stockage est tarifé au-dessus du coût marginal. En Dedicated, les coûts de stockage et d’écriture sont intégrés invisiblement aux frais d’heure de calcul. Serverless n’a pas de frais d’heure de calcul derrière lesquels cacher ces coûts, donc le stockage est facturé explicitement. Ce prix explicite doit couvrir les données stockées mais jamais interrogées — la plateforme ne peut pas les déplacer vers un stockage profondément froid, car les données doivent rester prêtes à être interrogées à tout moment. Maintenir cette disponibilité exige un état supplémentaire, et son coût finit amorti sur la taille du stockage, qui ne correspond pas réellement à la consommation réelle.
Les écritures sont également tarifées au-dessus du coût marginal. Les écritures sont mesurées séparément pour empêcher les utilisateurs d’émettre des mises à jour haute fréquence qui génèrent beaucoup de coûts d’écriture sans faire croître le jeu de données (ce qui laisserait sinon la plateforme absorber le coût). Même dynamique que pour le stockage : le coût de l’état de disponibilité se répercute dans le prix unitaire par écriture.
Le problème plus profond est que Serverless cache l’abstraction de « ressource de calcul » à l’utilisateur. L’utilisateur voit une interface sans état ; la plateforme doit toujours payer pour les schémas d’accès imprévisibles en arrière-plan — données chaudes/froides, trafic en rafales, stockage inactif qui doit rester prêt à être interrogé. Ces coûts ne peuvent pas être attribués précisément à des utilisateurs spécifiques, ils sont donc amortis dans les prix unitaires des requêtes, du stockage et des écritures. Chaque action facturable finit légèrement au-dessus de son coût marginal réel.
C’est un modèle de « risque partagé » : chaque poste porte une majoration pour couvrir les requêtes froides, les rafales ou le stockage inactif de quelqu’un d’autre. Les charges de travail les moins responsables de cette variance — requêtes chaudes stables, haute fréquence et prévisibles — paient la plus grande part de prime. Plus votre charge de travail est stable, plus vous finissez par subventionner.
Ce dont le client avait réellement besoin
Avec du recul, la demande du client n’avait rien d’exotique. Un jeu de données, plusieurs cadences d’accès, avec une facture ne suivant que le calcul réellement utilisé par chaque cadence.
- Récupération en ligne : continue, faible latence, prévisible. Dedicated est adapté à cela.
- Entraînement de modèles : en rafales mais prévisible — 3 heures toutes les deux semaines.
- Analytique : rare et imprévisible — quelques minutes à la fois, avec de longs intervalles.
Dedicated ne pouvait pas offrir cela. Il facture la capacité provisionnée, pas la consommation. Serverless ne le pouvait pas non plus : son prix unitaire par requête doit subventionner les requêtes à froid, le stockage inactif et la capacité de rafale pour tous les utilisateurs de la plateforme, si bien que les charges de travail stables finissent par payer pour une variance qu’elles ne génèrent pas.
Ce dont nous avions besoin, c’était d’un troisième modèle de calcul — capable de s’attacher aux mêmes données que Dedicated, de démarrer assez vite pour rendre réaliste la facturation par requête, et de facturer uniquement lorsqu’il est réellement en cours d’exécution.
Ce que nous avons changé
À la demande est un modèle de calcul distinct sur Zilliz Cloud qui coexiste avec Dedicated et Serverless. Il change trois choses par rapport aux deux :
- Démarrage à froid. Charger uniquement les fragments que la requête actuelle touche, et non l’ensemble de travail complet. Passe de plus de 10 minutes à quelques secondes.
- Facturation. À la minute de temps de fonctionnement réel du calcul. Les écritures aussi. Pas d’heure minimale, pas de prime par requête froide/chaude.
- Isolation. Chaque charge de travail se rattache à une collection via son propre groupe de ressources de calcul. Mêmes données, aucune contention.
Les trois sections suivantes détaillent chacune d’elles.
Charger moins de données, plus rapidement
Le démarrage à froid de 10 minutes sur Dedicated existe parce que le cluster doit charger l’ensemble de travail complet en mémoire locale avant de servir les requêtes. Sur une collection de 1 milliard de lignes, cela représente des dizaines à des centaines de fois plus de données que ce dont une seule requête a réellement besoin. Réduire le démarrage à froid à quelques secondes signifie abandonner cette hypothèse : charger uniquement ce que la requête actuelle touche.
Cela tient en une phrase ; en pratique, cela a nécessité de repenser trois couches — quoi lire, où le placer, et comment le monter.
Index qui se chargent partiellement.
Côté scalaire, le predicate pushdown est une pratique standard. Le moteur élimine les blocs qui ne peuvent pas correspondre au prédicat et évite de les récupérer. Nous l’utilisons sur les index inversés : chaque liste de publications se charge comme un bloc, et chaque liste porte des statistiques min/max que le moteur peut vérifier avant la récupération.
La partie la plus difficile a été de donner au côté vectoriel une capacité comparable de « lire un sous-ensemble ». Les index en graphe — l’option la plus performante pour le QPS en régime stable — ne se dégradent pas harmonieusement en cas de chargement partiel : la structure doit être chargée entièrement pour être utile, donc le coût de chargement à froid est élevé.
On-Demand utilise plutôt la famille IVF. IVF regroupe les vecteurs en compartiments au moment de l’indexation, et au moment de la requête, seuls les compartiments les plus proches de la requête sont récupérés. Cela donne au côté vectoriel quelque chose de proche de la sémantique du predicate-pushdown : les requêtes à froid chargent une petite fraction de l’index, pas l’ensemble.
C’est un compromis délibéré. Nous perdons les performances en régime stable des index en graphe, ce qui est la principale raison pour laquelle On-Demand n’est pas adapté au service à QPS élevé (nous y reviendrons plus bas). Pour les charges de travail clairsemées et en rafales, ce compromis en vaut la peine.
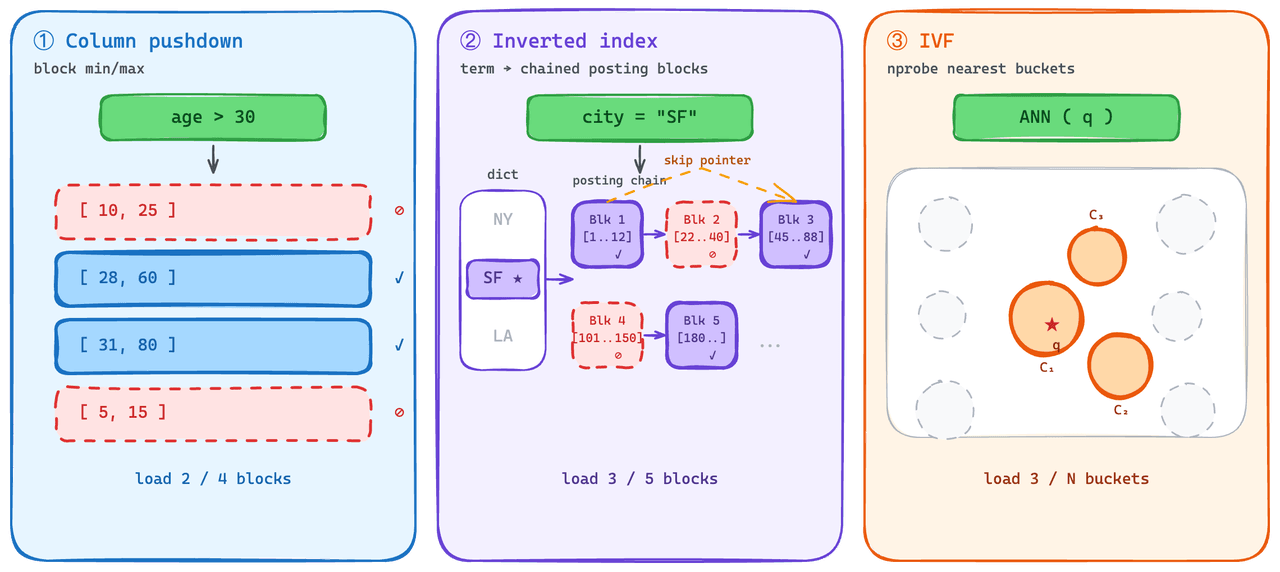
Un chemin de données à trois niveaux.
Une fois que nous savons quoi lire, la question suivante est où le conserver. Les fragments circulent librement entre S3, le disque local et la mémoire, et le cycle de vie du cache est géré par fragment entre les requêtes : les fragments dont la requête actuelle a besoin sont remontés ; les fragments qui restent inactifs suffisamment longtemps sont évincés. Le même jeu de données peut être interrogé à des cadences très différentes, et aucun ne paie le coût du chargement de données qu’il ne touche pas.
Chaque niveau possède sa propre disposition des données et sa propre granularité, adaptées aux caractéristiques d’E/S du support — l’alignement qui fonctionne pour le stockage objet n’est pas celui qui fonctionne pour le disque local, et aucun des deux ne correspond à ce contre quoi le moteur s’exécute en mémoire.
E/S asynchrones de bout en bout.
La chaîne d’E/S est entièrement asynchrone. Calcul et E/S sont pipelinés tout au long du processus, de sorte que le CPU ne reste pas à attendre une récupération et que la bande passante d’E/S ne reste pas à attendre le calcul.
Au total, le découpage en fragments + la hiérarchisation + l’asynchronisme réduisent la charge utile des requêtes à froid à moins de 1 à 2 % du jeu de données complet et le chemin à froid de bout en bout à quelques secondes.
Facturation à la minute
Avec un démarrage à froid au niveau de la seconde, « lancer le calcul lorsqu’une requête arrive, le libérer lorsqu’elle se termine » fonctionne comme un véritable mécanisme produit — pas seulement comme une aspiration de conception. Deux éléments du plan de contrôle font le gros du travail.
Un pool de nœuds en attente. Les extractions d’images ajoutent de la latence au démarrage d’un nouveau nœud. Nous maintenons prêt un petit pool de nœuds préchargés, de sorte que la montée en charge puise dans le pool au lieu de partir de zéro.
Libération basée sur le TTL. Chaque session dispose d’un délai d’inactivité configurable. Les ressources de calcul sont libérées automatiquement lorsque le délai expire, que la charge de requêtes se termine ou que la session est fermée. L’ensemble du cycle de vie est planifié par la plateforme — pas de mode « j’ai oublié d’arrêter mon cluster », pas d’opérations manuelles.
Comme le cycle de vie est à granularité fine, la granularité de facturation s’aligne. Le calcul est facturé à la minute d’activité réelle — pas de minimum d’une heure, pas de frais minimum par requête. Les écritures sont mesurées de la même manière : utilisation réelle des ressources, par minute.
C’est la précision de l’attribution des coûts qui permet à On-Demand d’éviter la prime de stockage que Serverless doit facturer. Serverless facture le stockage au-dessus du coût marginal parce que sa couche de calcul n’a aucun moyen d’absorber les coûts non attribués — chaque dollar dépensé par la plateforme doit se retrouver quelque part sur la facture, si bien que le stockage et les écritures deviennent le réceptacle de ce qui ne peut pas être attribué ailleurs. Quand On-Demand facture chaque minute de calcul à une session précise, il n’y a pas de réserve non attribuée. Le stockage sur On-Demand suit la tarification Zilliz Cloud aux tarifs Dedicated — environ 1/10 du stockage Serverless typique.
Isolation des charges de travail sur des données partagées
Le troisième changement consiste à rendre la couche de calcul explicite. Sur Dedicated, la couche de calcul est le cluster — invisible pour l’utilisateur, sauf sous la forme d’un paramètre unique de dimensionnement. Sur Serverless, la couche de calcul est entièrement masquée. On-Demand l’expose.
Chaque charge de travail s’attache à une collection via un groupe de ressources de calcul. De nouveaux groupes sont lancés — ou des groupes existants réutilisés — via des sessions. Les différents groupes sont isolés les uns des autres, et la facture de chaque groupe ne reflète que sa propre consommation.
Dans le cas de la conduite autonome, c’est ainsi que la charge de travail analytique obtient sa propre attache aux données : un groupe de ressources On-Demand qui démarre pour les requêtes ad hoc et se libère en cas d’inactivité, en s’exécutant sur la même collection Milvus, les mêmes index et les mêmes métadonnées que les charges de travail existantes de recherche en ligne et d’entraînement de modèles. La séparation stockage-calcul signifie qu’aucune d’elles n’a besoin de copier ou de synchroniser des données pour les utiliser. Pas de subvention croisée, pas de conflit de planification, pas de coordination opérationnelle entre les équipes concernant la forme du cluster.
C’est le même modèle architectural qu’un lac de données, appliqué à la recherche vectorielle : le stockage est le substrat partagé, et le calcul s’y attache sous la forme dont chaque charge de travail a besoin.
La facture, après
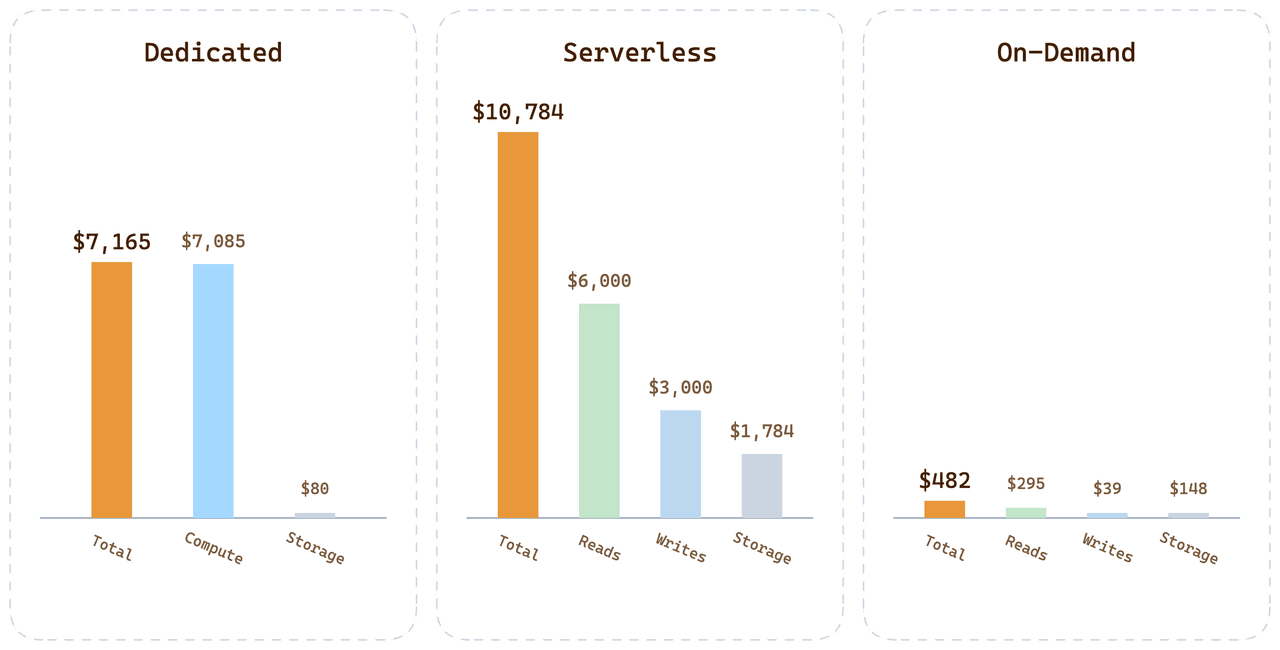
Pour la même charge de travail client sur les trois options :
| Option | Facture mensuelle | Où va l’argent |
|---|---|---|
| Dedicated (24 CU Tiered) | $7,165 | 99,6 % du calcul payé mais inactif |
| Serverless | $10,784 | Prime de requête + $1,700 de stockage + $3,000 d’écritures |
| On-Demand | < $500 | Calcul à la minute + stockage au tarif Dedicated |
Pour cette charge de travail, On-Demand revient à moins de 1/20 de la facture Serverless. L’écart n’est pas une astuce tarifaire ; c’est la conséquence directe de l’attribution des coûts à la consommation réelle, au lieu d’amortir la variance des autres utilisateurs dans chaque prix unitaire.
Quand On-Demand n’est pas le bon outil
On-Demand n’est pas un remplacement universel de Dedicated ou Serverless. Les mêmes choix de conception qui le rendent économique pour les charges de travail sporadiques et en rafales en font une mauvaise option pour d’autres. Le graphique ci-dessous trace le coût mensuel en fonction de la pression des requêtes pour la charge de travail de ce client sur les trois options.
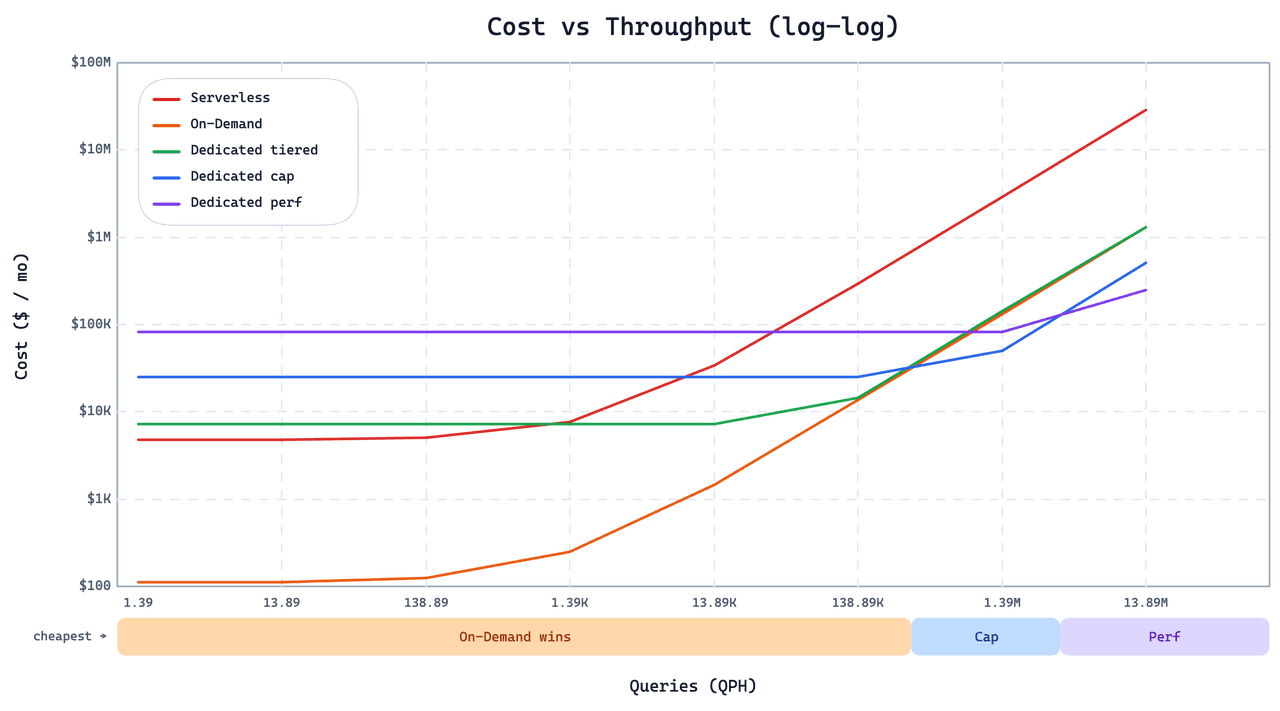
En dessous du point de croisement, On-Demand est nettement moins cher. Une fois que le QPS atteint les dizaines, les instances Cap ou Perf Dedicated deviennent à la fois moins chères et plus rapides. Deux décisions de conception expliquent ce point de croisement :
Pas d’index graphe. Pour limiter le coût de chargement des requêtes à froid, On-Demand utilise IVF au lieu d’index graphes. Les index graphes offrent un QPS en régime stable plus élevé à grande échelle, mais leur coût de chargement à froid est élevé. Au-delà de quelques dizaines de QPS, l’avantage en régime stable l’emporte nettement. Pour un service à QPS élevé, utilisez Dedicated.
Latence de queue plus élevée sur les requêtes à froid. On-Demand ne précharge pas les données, donc une requête à froid paie une récupération supplémentaire avant de pouvoir s’exécuter. Les requêtes chaudes sont rapides ; les requêtes à froid sont nettement plus lentes, et la distribution de la latence de queue est plus large que sur Dedicated ou Serverless. Si votre application ne peut pas tolérer des réponses occasionnelles de l’ordre de la seconde (ou pire, de la minute), On-Demand n’est pas adapté. Pour ces charges de travail, Smart Autoscaling on Dedicated réduit la capacité inactive sans sacrifier la latence à chaud.
Là où On-Demand est le bon outil : accès parcimonieux, itération analytique et exploration par lots sur de grands jeux de données — des charges de travail où une forte concurrence et une cohérence stricte de la latence ne sont pas les exigences principales.
Où cela s’inscrit dans Zilliz Vector Lakebase
Le cas client présenté dans cet article est une partie d’un schéma plus large : le même jeu de données, consulté à des cadences différentes par différentes charges de travail, n’est dimensionné correctement que lorsque chaque charge de travail obtient la forme de calcul dont elle a réellement besoin. On-Demand est l’une de ces formes de calcul. Zilliz Vector Lakebase est l’architecture qui rend le reste possible.
Un Vector Lakebase est une plateforme de données native lake pour les charges de travail IA. Les données résident sur S3, les index sont découplés du calcul, et différentes formes de calcul s’attachent à la même collection via un accès sans copie. Il traite trois modes de charge de travail comme des capacités de premier ordre — récupération en temps réel, découverte itérative et analytique par lots — chacun étant servi par la forme de calcul adaptée à son modèle d’accès. La recherche vectorielle a toujours été une charge de travail de premier ordre sur Zilliz Cloud ; avec le lancement de Vector Lakebase, les formes de calcul pour la découverte itérative et l’analytique par lots la rejoignent sur la même fondation de données.
On-Demand est la forme de calcul conçue pour les charges de travail analytiques et irrégulières. Les quatre autres capacités couvrent le reste des modes :
- Tiered Serving Solutions pour la récupération en temps réel — Performance-Optimized (1000+ QPS, latence en ms à un seul chiffre, entièrement en mémoire), Capacity-Optimized (100–500 QPS avec une latence inférieure à 100 ms sur mémoire + NVMe local), et Tiered-Storage (10–50 QPS avec une latence d’environ 100 ms sur mémoire, NVMe et stockage objet). Différents points sur la courbe performance/coût, même mode de service.
- External Data Lake Search pour indexer et rechercher des données déjà présentes dans Lance, Iceberg ou d’autres formats lake — sans les copier dans un magasin séparé.
- Full-Spectrum Search pour les vecteurs, le texte, JSON et les données géospatiales sur un même plan de requête, avec récupération hybride, filtrage et reranking sur un modèle de données en table large.
- Unified Lake-Native Storage construit sur Vortex, un format colonnaire ouvert de nouvelle génération avec des lectures aléatoires plus rapides que Lance ou Parquet, ainsi qu’une flexibilité de format par colonne.
Zilliz Vector Lakebase est désormais en aperçu public sur Zilliz Cloud. Pour l’architecture complète et le reste des capacités, le Vector Lakebase deep-dive est la lecture de référence.
Pour essayer On-Demand sur votre propre charge de travail, inscrivez-vous sur Zilliz Cloud et lancez un cluster On-Demand depuis la console ou la CLI. Si les chiffres de cet article correspondent à quelque chose que vous exécutez, l’équipe Zilliz se fera un plaisir d’examiner votre charge de travail avec vous avant que vous ne construisiez.

Continuer à lire

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.