




Analyse des compétences Zilliz : comment les agents d’IA maîtrisent les bases de données vectorielles
À l’origine par ShugeX, praticien indépendant en AI-ops et contributeur actif de la communauté Milvus. Traduit et republié avec autorisation.
Imaginez que vous utilisez Claude Code pour créer une application RAG avec Milvus. Chaque étape — créer une collection, définir un schéma, insérer des vecteurs, exécuter une recherche hybride — vous oblige à feuilleter la documentation pymilvus pour trouver la bonne API, puis à revenir dans l’éditeur pour l’intégrer. Et si vous êtes sur Zilliz Cloud, vous passez aussi au navigateur pour vous connecter à la console afin de gérer les clusters, la surveillance et la configuration des sauvegardes. L’environnement de développement et l’environnement d’exploitation sont deux mondes différents.
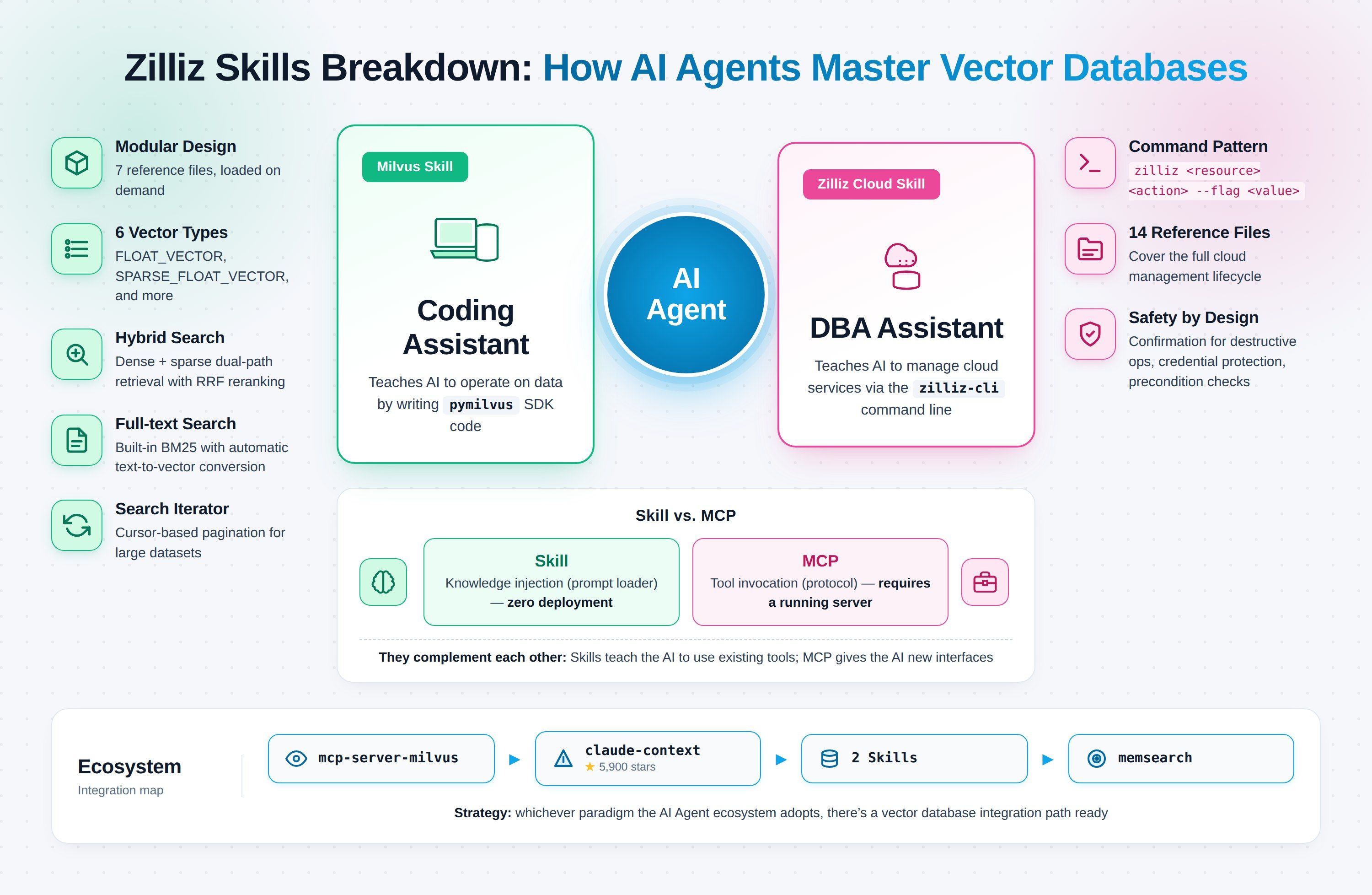
Les deux Claude Code Skills récents de Zilliz ciblent précisément ce point de rupture. Milvus Skill apprend à l’agent à exploiter la base de données vectorielle via le SDK Python. Zilliz Cloud Skill apprend à l’agent à gérer tout ce qui relève du cloud via zilliz-cli. Chaque Skill prend en charge un domaine ; ensemble, ils transforment le développement et l’exploitation en une seule session Claude Code continue.
Après avoir lu le code source des deux Skills de bout en bout, j’ai trouvé beaucoup d’éléments qui méritent d’être analysés — conception modulaire, modèles de sécurité, et la place de Skill aux côtés de MCP. Cet article les passe en revue un par un.
Ce que font respectivement Milvus Skill et Zilliz Cloud Skill
Les deux Skills ne sont pas deux versions d’une même chose. Ils ciblent deux échecs de justesse différents.
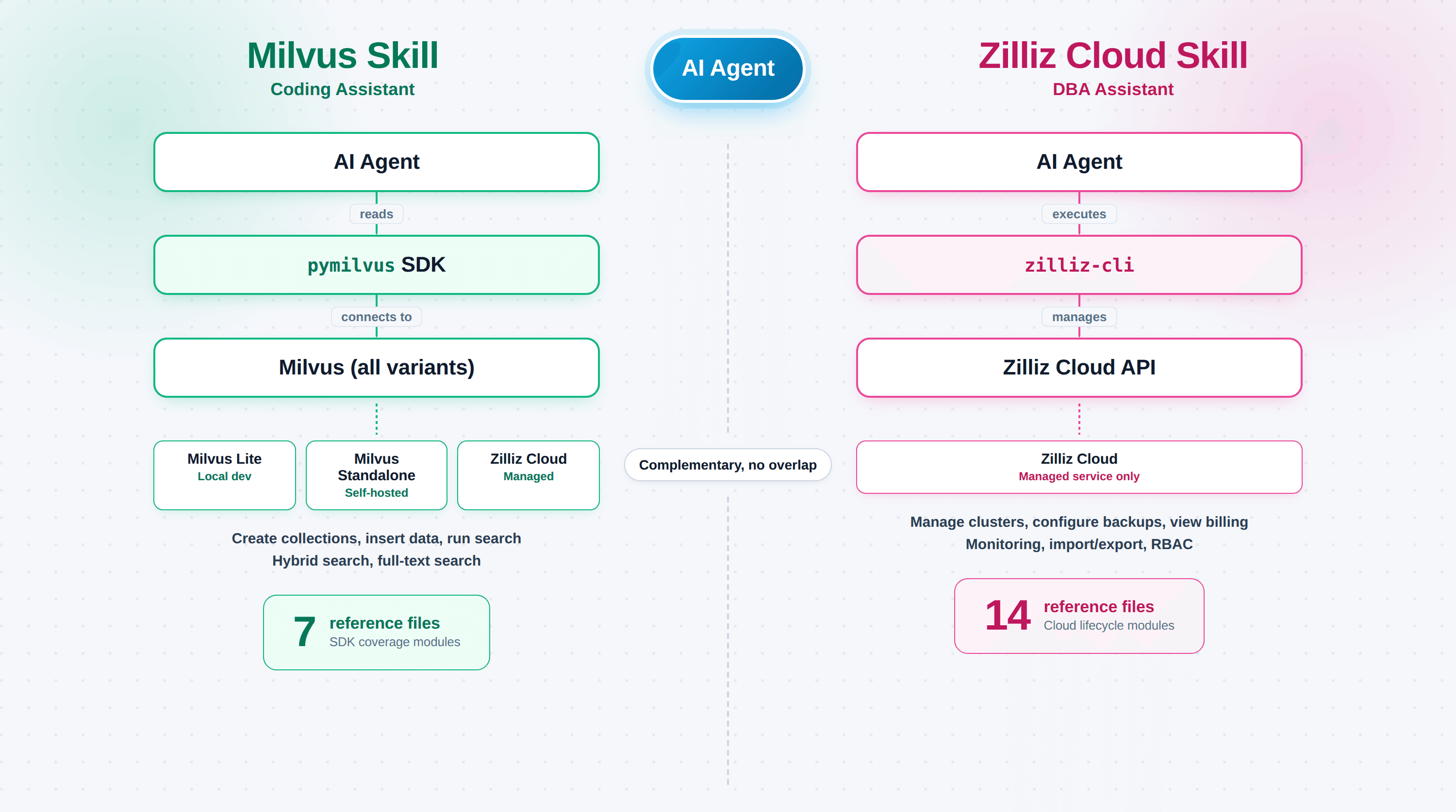
Milvus Skill (zilliztech/milvus-skill) apprend à l’agent pymilvus, le SDK Python permettant de se connecter, de créer des collections, d’insérer des vecteurs et d’exécuter des recherches. C’est un assistant de codage, et il fonctionne avec n’importe quel déploiement Milvus : Milvus Lite, Standalone/Cluster auto-hébergé ou Zilliz Cloud. L’échec qu’il corrige : du code pymilvus qui compile mais ne fait pas ce que vous avez demandé, parce que l’agent a utilisé une forme d’API obsolète.
Zilliz Cloud Skill (zilliztech/zilliz-skill) apprend à l’agent zilliz-cli, l’outil en ligne de commande qui couvre les clusters, les sauvegardes, la surveillance et la facturation. C’est un assistant DBA, et il ne fonctionne qu’avec Zilliz Cloud (Milvus auto-hébergé n’a pas de plan de contrôle). L’échec qu’il corrige : des commandes hallucinées contre un système de production en direct, où un mauvais zilliz cluster delete coûte plus cher qu’une erreur de compilation.
En une phrase :
- Milvus Skill → l’agent écrit du code qui exploite les données
- Zilliz Cloud Skill → l’agent exécute des commandes qui gèrent les services
| Dimension | Milvus Skill | Zilliz Cloud Skill |
|---|---|---|
| Interface | Python (pymilvus) | CLI (zilliz-cli) |
| Rôle | Assistant de codage | Assistant DBA |
| Fonctionne avec | Tous les déploiements Milvus + Zilliz Cloud | Zilliz Cloud uniquement |
| Fichiers | 7 modules de référence | 14 sous-skills |
| Cible de justesse | API SDK obsolètes | Commandes ops insuffisamment documentées |
| Tâche typique | Créer une collection, insérer, rechercher | Provisionner un cluster, configurer une sauvegarde, vérifier la facturation |
Milvus Skill : apprendre à l’agent à écrire du pymilvus fiable
Le dossier references/ de Milvus Skill contient sept fichiers, chacun correspondant à un domaine de capacité pymilvus indépendant. Lorsque l’agent traite une tâche spécifique, il charge uniquement le fichier pertinent plutôt que de déverser toute la documentation dans le contexte :
| Fichier | Couvre |
|---|---|
collection.md | Types de données, définitions de champs, opérations sur les collections |
vector.md | CRUD vectoriel, recherche hybride, recherche plein texte, itérateurs |
index.md | Types d’index, types de métriques, gestion des index |
partition.md | Gestion des partitions |
database.md | Gestion des bases de données |
user-role.md | RBAC |
patterns.md | Modèles courants (RAG, recherche hybride, etc.) |
Vous construisez un schéma ? L’agent récupère collection.md. Vous lancez une recherche ? Il récupère vector.md. Le reste reste à l’écart. Les fenêtres de contexte sont finies ; le chargement à la demande est préférable au déversement de tout le contenu.
Types de données pris en charge : plus riches que vous ne l’imaginez
En parcourant rapidement collection.md, Milvus prend en charge plus de types de vecteurs que la plupart des développeurs ne le pensent :
- Scalaires :
BOOL,INT8/16/32/64,FLOAT,DOUBLE,VARCHAR,JSON,ARRAY - Vecteurs :
FLOAT_VECTOR— flottant 32 bits, la valeur par défautFLOAT16_VECTOR— demi-précision, économise de la mémoireBFLOAT16_VECTOR— BF16, courant dans les pipelines de deep learningBINARY_VECTOR— binaireSPARSE_FLOAT_VECTOR— creux, pour la recherche en texte intégralINT8_VECTOR— quantifié, compression supplémentaire
Recherche hybride : la fonctionnalité la plus remarquable couverte par ces Skills
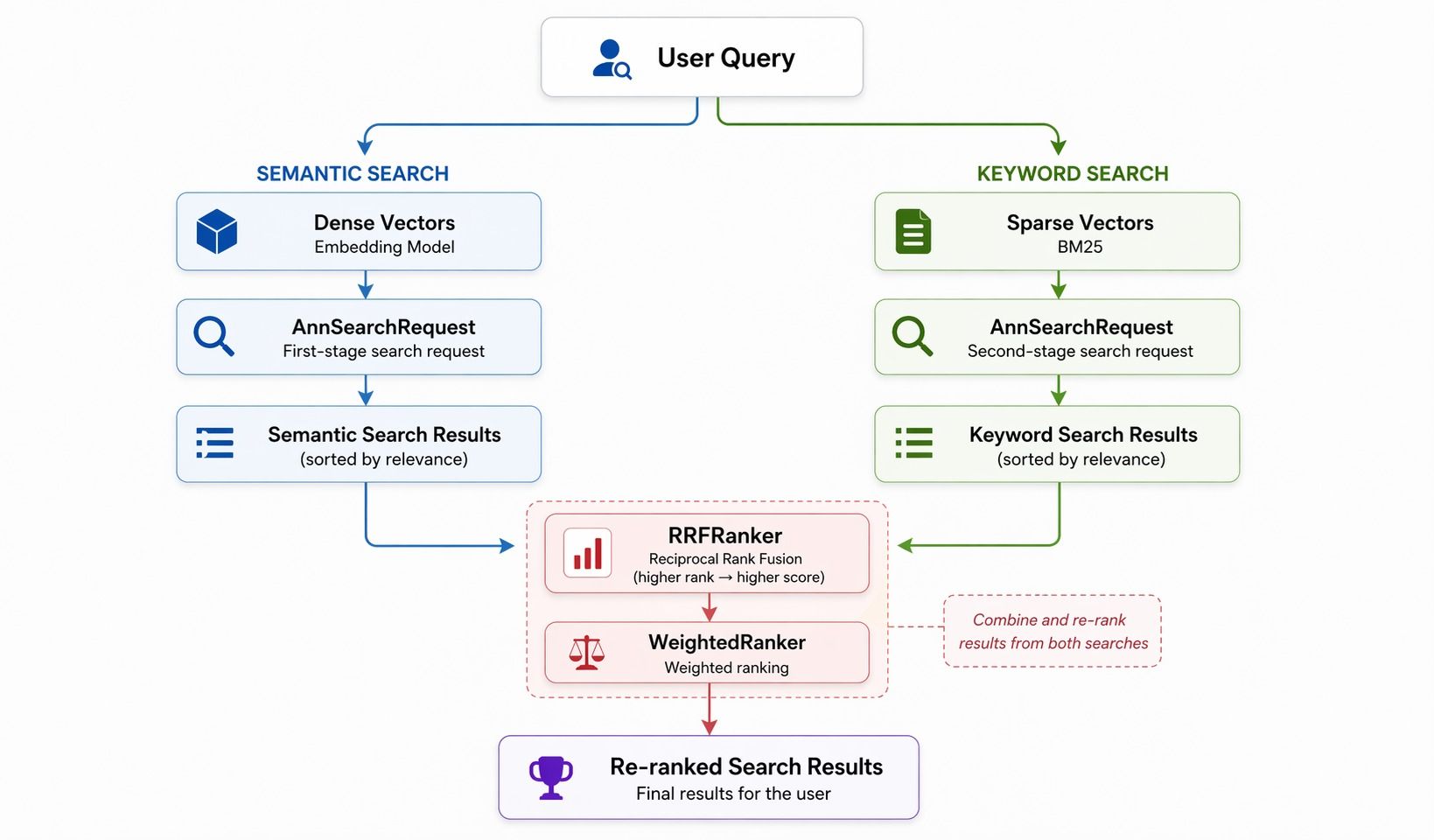
patterns.md documente quatre modèles courants. La recherche hybride est celle qui comporte le plus d’éléments. La recherche par vecteur dense (sémantique) et la recherche par vecteur creux (mot-clé) s’exécutent en parallèle, puis RRF (Reciprocal Rank Fusion) ou un classement pondéré fusionne les deux listes.
Trois briques de base :
AnnSearchRequest— une par branche de rechercheRRFRanker/WeightedRanker— stratégie de fusionSPARSE_FLOAT_VECTOR— le champ de vecteur creux
RRF est simple : pour chaque résultat, score = 1/rang, additionné entre les branches. Les éléments les mieux classés l’emportent. WeightedRanker est une somme pondérée par branche. Le Skill explicite tout cela, de sorte que l’agent génère du code de recherche hybride utilisable sans que le développeur lise l’article sur RRF.
Recherche en texte intégral BM25 intégrée de Milvus
Milvus Skill encode également : la recherche en texte intégral Sparse-BM25 intégrée de Milvus 2.5. Combiné à Function et FunctionType.BM25, Milvus convertit le texte brut en vecteurs creux en interne, évitant les modèles d’embedding externes et les pipelines TF-IDF manuels.
Avant la 2.5, la recherche en texte intégral signifiait qu’il fallait gérer un tokenizer, calculer TF-IDF à la main et générer soi-même le vecteur creux. Désormais, vous dites à l’agent ce que vous voulez, et le Skill le guide pour générer la collection avec Function BM25 correctement câblée.
Itérateurs de recherche : pagination pour les collections de millions de lignes
vector.md couvre également search_iterator et query_iterator, une pagination de type curseur pour les collections de millions ou de milliards de lignes. Un simple search renvoie un ensemble de résultats de taille fixe. Les itérateurs parcourent les pages sans pertes ni doublons, ce dont l’énumération complète a besoin.
Zilliz Cloud Skill : apprendre à l’agent à être votre DBA Cloud
Le rôle de Zilliz Cloud Skill est différent de celui de Milvus Skill. Au lieu d’écrire du Python, l’agent compose des invocations CLI contre un plan de contrôle en direct — et comme une mauvaise commande peut effacer la production, le Skill encapsule ces invocations dans des règles de sécurité.
Mode commande : comment l’agent compose les invocations CLI
Le Skill encode une forme de commande cohérente :
zilliz <resource> <action> --flag <value>
Exemples :
zilliz cluster list— répertorier tous les clusterszilliz collection create --name my_collection— créer une collectionzilliz backup create --name daily-backup— créer une sauvegarde
Trois formats de sortie : json (lisible par machine), table (convivial pour l’humain), text (brut). L’agent choisit celui qui convient.
14 sous-skills couvrant tout le cycle de vie Cloud
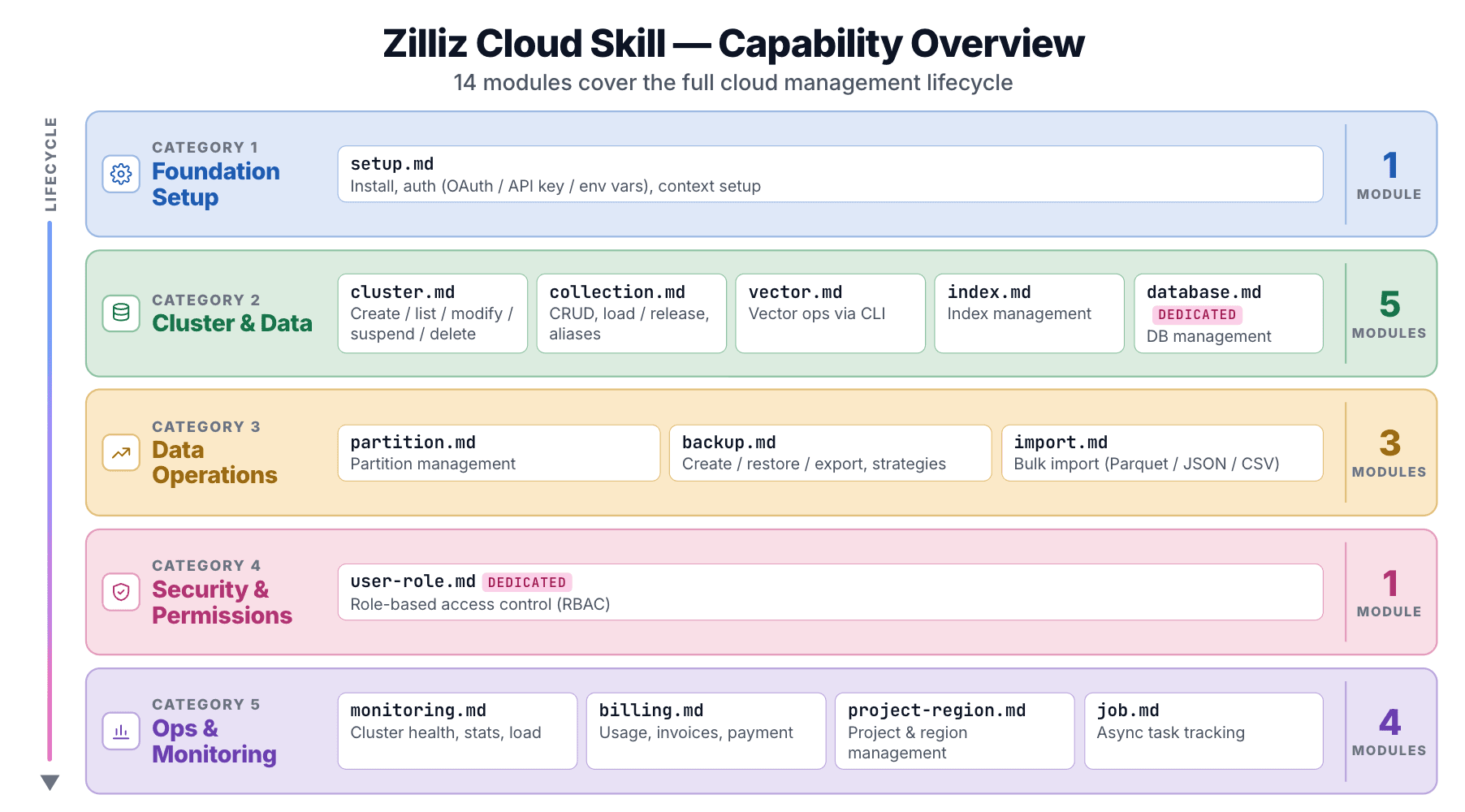
Le repo zilliz-plugin fournit 14 sous-skills, chacun sous skills/<name>/SKILL.md :
| Module | Couvre |
|---|---|
setup | Installation, auth (OAuth / clé API / variable d'env), configuration du contexte |
cluster | Créer, lister, modifier, suspendre, reprendre, supprimer |
collection | CRUD de collections, chargement/libération, alias |
vector | Opérations vectorielles via CLI |
index | Gestion des index |
database | Gestion des bases de données (Dedicated uniquement) |
partition | Gestion des partitions |
user-role | RBAC (Dedicated uniquement) |
backup | Créer, restaurer, exporter, politiques de sauvegarde |
import | Import en masse depuis le stockage cloud (Parquet / JSON / CSV) |
billing | Utilisation, factures, moyens de paiement |
monitoring | État du cluster, statistiques, états de chargement |
project-region | Gestion des projets et des régions |
job | Suivi des tâches asynchrones |
Lancement d’un cluster, configuration de la rétention des sauvegardes, vérification d’une facture : 14 modules couvrent toutes les opérations de la console Zilliz Cloud.
La prise en compte des niveaux est intégrée. database et user-role sont signalés comme Dedicated uniquement. Le Skill sait que les niveaux Free, Serverless et Dedicated ont des capacités différentes, donc l’agent ne tentera pas d’opérations qu’un niveau de cluster ne peut pas prendre en charge.
Trois règles de sécurité, une dans chaque module
La conception de sécurité de Zilliz Cloud Skill va plusieurs couches plus loin que celle de Milvus Skill. Trois règles fondamentales apparaissent dans les fichiers SKILL.md individuels :
- Les opérations destructrices exigent une confirmation explicite de l’utilisateur. Les consignes du module cluster indiquent : "Before deleting a cluster, always confirm with the user — this is irreversible." Chaque opération destructrice (collections, sauvegardes, bases de données, utilisateurs) porte la même instruction.
- Les commandes sensibles s’exécutent dans le terminal propre à l’utilisateur. Le module
setupest explicite : "Login commands (zilliz login, zilliz configure) require an interactive terminal and CANNOT run inside Claude Code. Always instruct the user to run these in their own terminal." Les identifiants ne transitent pas par l’agent. - Les identifiants ne sont jamais exposés. L’authentification passe par le flux navigateur OAuth, une clé API depuis la console, ou une variable d’env
ZILLIZ_API_KEY. Le Skill n’affiche jamais de secrets.
Ces règles semblent élémentaires, mais un agent disposant d’identifiants Cloud et sans couche de confirmation pourrait interpréter « nettoyer les clusters de test » et supprimer la production. Le Skill comble cette faille au niveau des instructions, avant qu’une commande destructrice n’atteigne l’API.
Le sas de prérequis : trois vérifications avant l’exécution de toute commande
Chaque sous-skill exécute une vérification en trois étapes, définie dans skills/setup/SKILL.md :
zilliz-cliinstallé ? Sinon, l’installer.- Utilisateur connecté ? Sinon, le rediriger vers l’authentification.
- Contexte de cluster défini ? Sinon, demander une sélection.
Ce sas garantit que l’environnement est prêt avant le lancement de toute commande, ce qui est plus fiable que de lancer à l’aveugle puis de déboguer les erreurs ensuite.
Pourquoi s’agit-il de Zilliz Skills, et pas seulement de MCP ?
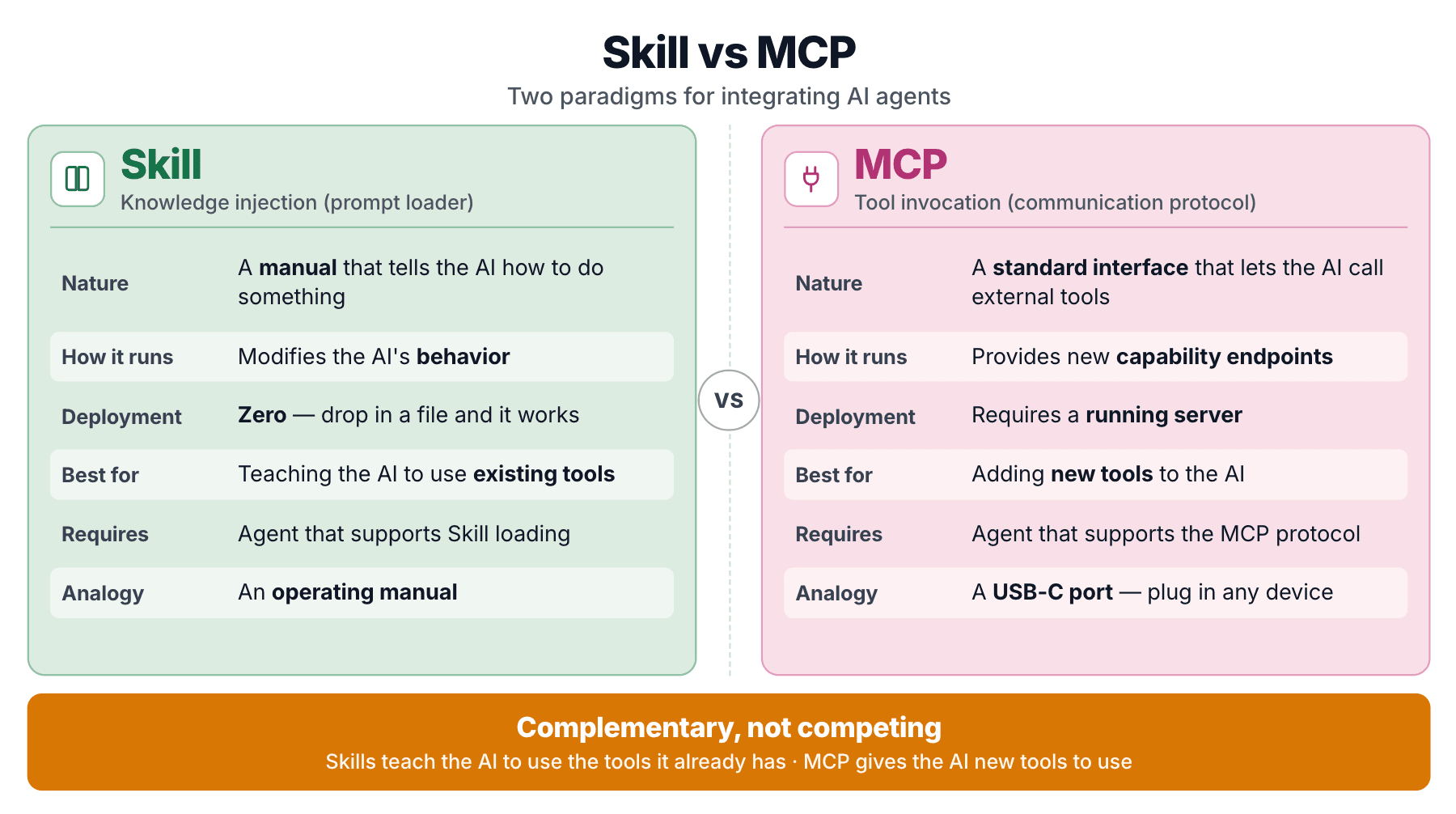
Zilliz propose les deux parce qu’ils résolvent des problèmes différents. Un Skill injecte des connaissances que l’agent consulte lorsqu’il écrit du code. Un serveur MCP expose des points de terminaison appelables que l’agent peut invoquer. mcp-server-milvus est le bras MCP ; Milvus Skill est le bras connaissance. Ils se superposent plutôt qu’ils ne se concurrencent.
Skill est un chargeur de prompts
Le Skill minimal est un dossier et un SKILL.md :
my-skill/
├── SKILL.md # instructions + metadata
├── references/ # reference docs (optional)
├── scripts/ # executable scripts (optional)
└── assets/ # templates, resources (optional)
SKILL.md est un manuel d’instructions. Il indique à l’agent comment traiter une tâche donnée. Pas de code exécutable, pas de processus serveur. Juste des connaissances structurées injectées dans le contexte du modèle à la demande.
Un Skill est un chargeur de prompts. Des connaissances de domaine empaquetées sous forme de prompt structuré, chargées dynamiquement.
MCP est un protocole d’outils
MCP (Model Context Protocol) prend une forme différente. C’est un protocole standardisé qui permet à un agent d’appeler des outils externes via une interface uniforme. mcp-server-milvus est un serveur MCP qui expose des points de terminaison d’outils comme milvus_text_search, milvus_create_collection, et ainsi de suite.
MCP a été décrit comme « le port USB-C pour les agents IA ». Il résout le problème de standardisation de l’interface des outils.
Zilliz Skill vs zilliz MCP
| Dimension | Skill | MCP |
|---|---|---|
| Essence | Injection de connaissances (prompt) | Invocation d’outil (protocole) |
| Ce qu’il fait | Modifie la manière dont l’agent se comporte | Donne à l’agent une nouvelle capacité |
| Coût de déploiement | Déposer des fichiers, terminé | Processus serveur requis |
| Convient à | Apprendre à l’agent à utiliser des outils qu’il possède déjà | Donner à l’agent des outils qu’il n’a pas |
| Dépendance | L’agent prend en charge le chargement des Skills | L’agent prend en charge MCP |
La distinction déterminante : Milvus Skill apprend à l’agent à utiliser pymilvus. pymilvus existe déjà. Le Skill n’ajoute pas de capacité. Il corrige l’exactitude pour une capacité que l’agent possède déjà. MCP, en revanche, donne à l’agent des points de terminaison appelables qu’il ne pourrait pas atteindre autrement.
Un Skill est le manuel d’utilisation d’une machine que vous possédez déjà. MCP est une télécommande qui fait bouger une nouvelle machine. Zilliz l’a dit directement dans "Is MCP Dead? MCP vs CLI vs Agent Skills Compared" : les deux modèles persistent.
Cela dit, les Skills gagnent rapidement du terrain. Les annuaires communautaires estiment le nombre à plus de 700 000 packages dans les registres, ClawHub à lui seul répertoriant plus de 5 700 skills. Un projet de packages de skills sur GitHub a obtenu 6 600 étoiles en cinq jours en avril 2026.
Scénarios concrets : comment les développeurs les utilisent réellement
Scénario 1 : créer une application RAG
Vous créez une application RAG. Avec Milvus Skill installé, vous dites :
"Crée une collection de récupération de documents : vecteurs de dimension 768, recherche plein texte BM25, champs pour title, body et embedding."
L’agent extrait collection.md et patterns.md et écrit :
from pymilvus import MilvusClient, DataType, Function, FunctionType
client = MilvusClient(uri="<URI>", token="<TOKEN>")
schema = client.create_schema(auto_id=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("title", DataType.VARCHAR, max_length=512)
schema.add_field("body", DataType.VARCHAR, max_length=4096, enable_analyzer=True)
schema.add_field("embedding", DataType.FLOAT_VECTOR, dim=768)
schema.add_field("body_sparse", DataType.SPARSE_FLOAT_VECTOR)
# Wire BM25 full-text search
schema.add_function(Function(
name="body_bm25",
input_field_names=["body"],
output_field_names=["body_sparse"],
function_type=FunctionType.BM25,
))
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", index_type="AUTOINDEX", metric_type="COSINE")
index_params.add_index(field_name="body_sparse", index_type="AUTOINDEX", metric_type="BM25")
client.create_collection("documents", schema=schema, index_params=index_params)
enable_analyzer=True, le câblage de la Function BM25, la combinaison AUTOINDEX avec la métrique BM25 : aucune de ces choses ne doit être laissée aux suppositions de l’agent. Le Skill les encode.
Scénario 2 : gérer un cluster Zilliz Cloud
"Crée un cluster Serverless dans us-east-1, puis crée une collection avec des vecteurs de dimension 768."
L’agent exécute la vérification des prérequis, puis lance les commandes CLI dans l’ordre. Ou :
"Montre-moi l’état et l’utilisation des ressources de tous mes clusters."
L’agent exécute zilliz cluster list et les commandes zilliz monitoring correspondantes, puis résume. Les identifiants ne quittent jamais votre terminal.
Scénario 3 : sauvegardes et migration de données
"Configure une politique de sauvegarde quotidienne pour la production, conserve 7 jours."
backup.md documente la syntaxe complète de la politique. L’agent configure la politique directement.
"Exporte la collection orders du cluster de test vers S3."
import.md couvre l’importation et l’exportation en masse depuis le stockage cloud, y compris les formats pris en charge (Parquet, JSON, CSV).
Scénario 4 : Passer à la recherche hybride
"Améliore ma recherche en hybride dense + sparse avec RRF."
L’agent récupère les notes de vector.md sur AnnSearchRequest et RRFRanker et écrit le code de recherche hybride. Vous n’avez pas besoin d’étudier les paramètres RRF.
La stack d’agents de Zilliz : où s’inscrivent les deux Skills
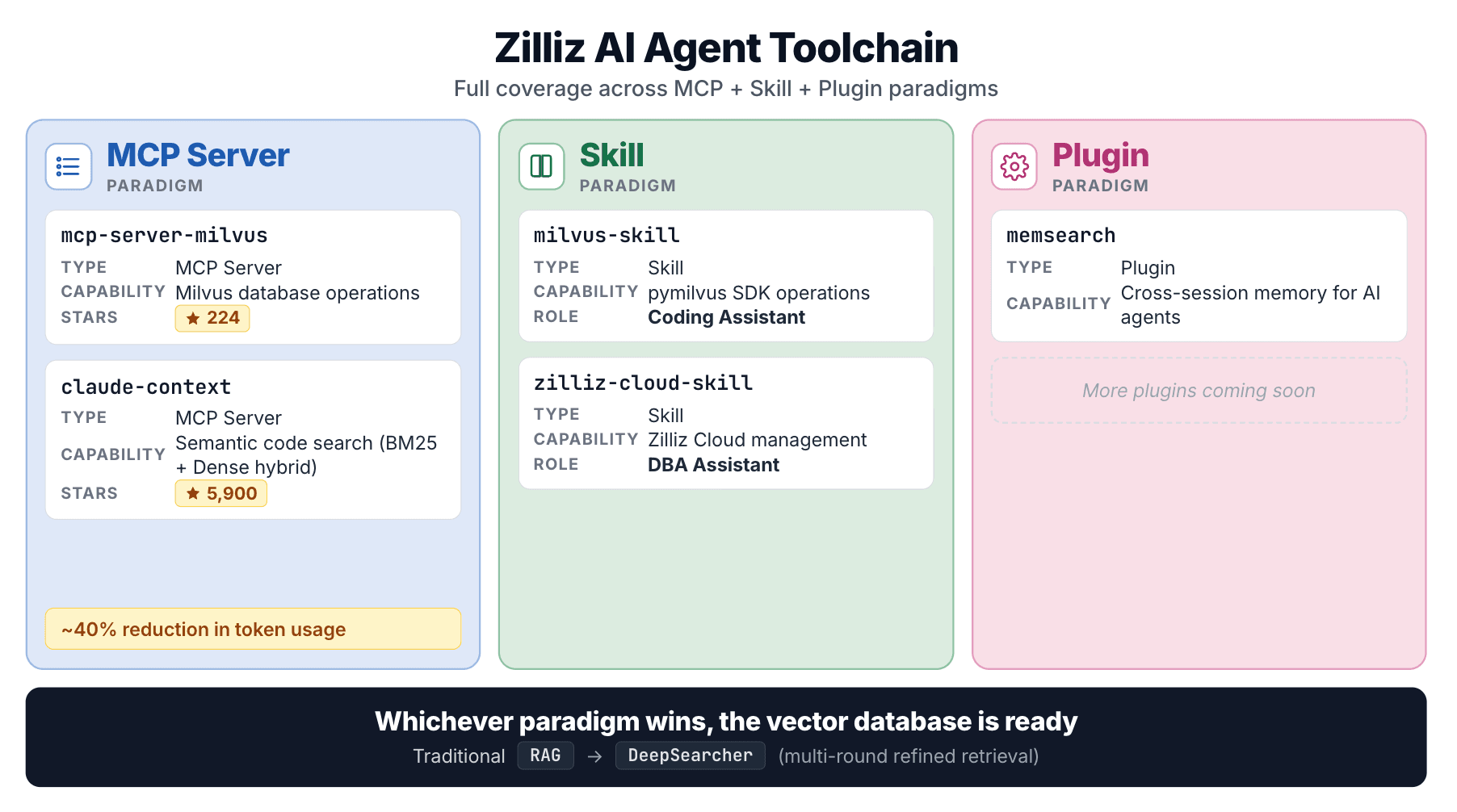
Ces deux Skills s’inscrivent dans un effort plus large de Zilliz couvrant chaque modèle d’intégration d’agents :
| Projet | Type | Couvre |
|---|---|---|
| mcp-server-milvus | Serveur MCP | Opérations de base de données Milvus |
| claude-context | Serveur MCP | Recherche sémantique dans le code |
| milvus-skill | Skill | SDK pymilvus |
| zilliz-skill | Skill | Gestion de Zilliz Cloud |
| DeepSearcher | Framework d’agent | RAG agentique en plusieurs étapes |
claude-context se démarque. Il indexe une base de code dans une base de données vectorielle, récupère le code pertinent à la demande avec une recherche hybride (BM25 + dense), et rapporte une réduction d’environ 40 % des tokens à qualité de récupération équivalente.
De MCP aux Skills, en passant par la recherche de code et les frameworks d’agents, la stratégie de Zilliz est cohérente : quel que soit le modèle d’intégration d’agents qui l’emporte, une base de données vectorielle doit disposer d’un point d’entrée de premier plan. Les deux Skills constituent l’entrée de Zilliz dans cette voie.
Conclusion
Milvus Skill et Zilliz Cloud Skill reposent sur quatre choix de conception communs :
- Les deux Skills ont des rôles clairs et non chevauchants. Milvus Skill gère la couche de codage SDK ; Zilliz Cloud Skill gère la couche d’opérations CLI. Ensemble, ils couvrent tout le cycle de vie d’une base de données vectorielle sans se marcher sur les pieds.
- Le chargement modulaire des connaissances garde le contexte léger. Répartir les connaissances sur 7 et 14 fichiers de référence permet à l’agent de ne récupérer que le fichier correspondant à la tâche en cours, plutôt que d’inonder la fenêtre de contexte avec toute la documentation.
- Zilliz Cloud Skill intègre la sécurité dans la couche d’instructions. La confirmation des opérations destructrices, la protection des identifiants et les vérifications des prérequis montrent que l’équipe a soigneusement réfléchi à ce qu’un agent disposant de clés Cloud peut faire sur une base de données en production.
- Zilliz se couvre sur plusieurs paradigmes, sans choisir de gagnant. En publiant à la fois des implémentations MCP et Skill, Zilliz est couvert quelle que soit la direction que prendra l’écosystème d’intégration des agents.
Si vous construisez des agents avec une base de données vectorielle, installez les deux Skills la prochaine fois que vous lancerez une application RAG ou gérerez un cluster.
Démarrer
Installez les deux Skills dans votre prochaine session Claude Code :
- Milvus Skill — exactitude de pymilvus. Fonctionne avec Milvus Lite, Standalone/Cluster auto-hébergé et Zilliz Cloud.
- Zilliz Cloud Skill — gestion de cluster en direct via
zilliz-cli. Installez le CLI en parallèle.
Si vous n’avez pas encore de cluster, inscrivez-vous à Zilliz Cloud (les nouveaux comptes avec e-mail professionnel reçoivent des crédits gratuits) ou connectez-vous, puis collez le Skill dans Claude Code, et l’agent s’occupe du reste.
Lectures complémentaires
- "Le MCP est-il mort ?" — la façon dont Zilliz situe les CLI et les Skills aux côtés du MCP.
- Milvus SDK Code Helper — pendant MCP de Milvus Skill, même problème de pymilvus obsolète sous un autre angle.
claude-context— recherche sémantique dans la base de code signalant une réduction d’environ 40 % des tokens.- Documentation Milvus et Zilliz Cloud pour l’ensemble de la gamme de produits.
Continuer à lire

How to Install and Run OpenClaw (Previously Clawdbot/Moltbot) on Mac
Turn your Mac into an AI gateway for WhatsApp, Telegram, Discord, iMessage, and more — in under 5 minutes.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.