




Présentation des fonctions et de l’inférence de modèles sur Zilliz Cloud : embedding automatique et reranking avec des modèles hébergés
Les pipelines de recherche IA construits sur des bases de données vectorielles vous obligent généralement à générer vous-même les embeddings, à les insérer dans la base de données vectorielle pour la récupération par similarité, à intégrer chaque requête de la même manière et à ajouter un service de reranking séparé si vous voulez une meilleure qualité de résultats. Cela fonctionne, mais cela signifie davantage de code de liaison et davantage d’endroits où les choses peuvent diverger.
Aujourd’hui, nous annonçons Functions and Inference Services sur Zilliz Cloud — désormais en Public Preview pour les modèles tiers et en Private Preview pour les modèles hébergés par Zilliz. Vous pouvez insérer du texte brut et effectuer des recherches en langage naturel. Zilliz Cloud gère ensuite automatiquement la génération d’embeddings, le stockage vectoriel et le reranking des résultats.
Que sont Functions and Inference Services sur Zilliz Cloud ?
Une Function Function est une opération déclarative attachée à une collection qui indique à Zilliz Cloud comment traiter vos données. Au lieu d’envoyer des vecteurs, il vous suffit désormais d’envoyer du texte brut. Au lieu d’intégrer les requêtes côté client, vous envoyez directement des requêtes textuelles. Zilliz Cloud s’occupe ensuite du reste.
Les Functions se répartissent en deux catégories :
- Les Pre-search Functions s’exécutent au moment de l’ingestion et de la requête, en convertissant le texte en représentations interrogeables. Cela inclut BM25 pour la recherche plein texte par mots-clés (aucun modèle requis) et les approches basées sur des modèles qui produisent des embeddings denses pour la recherche sémantique.
- Les Post-search Functions s’exécutent après la récupération, l’affinement et le réordonnancement des résultats. Cela inclut les rankers hybrides qui fusionnent plusieurs ensembles de résultats, les rankers basés sur des règles pour la logique métier, et les rankers basés sur des modèles qui évaluent la pertinence entre les requêtes et les documents.
Le schéma suivant fournit une abstraction du fonctionnement des Functions dans le workflow de recherche.
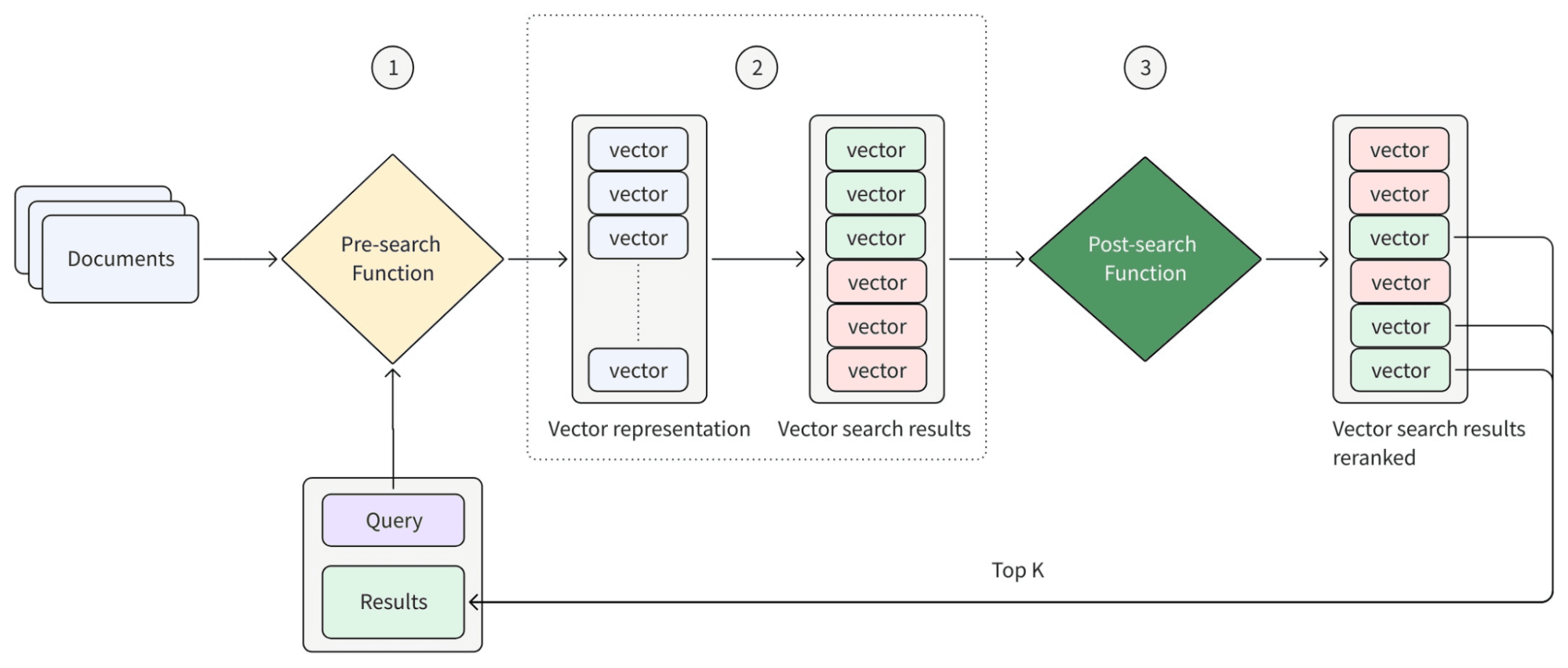
Les Inference Services alimentent les Functions basées sur des modèles. Lorsqu’une Function doit générer un embedding ou évaluer une paire requête-document, elle appelle un modèle provenant de l’une des deux sources suivantes :
| Source | Fonctionnement |
|---|---|
| Fournisseurs tiers (OpenAI, Voyage AI, Cohere) | Vous fournissez votre clé API. Zilliz Cloud gère l’intégration. |
| Modèles hébergés par Zilliz | Instances de modèles entièrement gérées sur l’infrastructure GPU de Zilliz. Vos données ne quittent jamais la plateforme. |
La distinction la plus simple : les Functions définissent ce qui arrive à vos données. Les Inference Services définissent quel modèle effectue le travail.
Pourquoi déplacer l’embedding et le reranking dans Zilliz Cloud ?
Si vous appelez une API d’embedding et insérez des vecteurs dans Zilliz Cloud aujourd’hui, cela fonctionne déjà. Mais à mesure que les applications passent à l’échelle, plusieurs points de friction apparaissent.
La cohérence des modèles devient votre problème
Votre chemin d’ingestion et votre chemin de requête doivent utiliser exactement le même modèle. S’ils divergent — par exemple, si un déploiement met à jour un côté mais pas l’autre — la qualité de recherche se dégrade silencieusement. Avec Functions, la collection possède la configuration du modèle. L’ingestion et la requête sont garanties de correspondre.
Le reranking est ignoré parce qu’il génère trop de friction
Le reranking basé sur des modèles améliore significativement la qualité des résultats, en particulier pour la recherche hybride. Mais ajouter un autre appel de service après chaque requête — avec sa propre clé API, son budget de latence et sa gestion des échecs — représente suffisamment de friction pour que de nombreuses équipes livrent sans l’utiliser. Lorsque le reranking est une Function intégrée, cette friction disparaît.
Les identifiants se dispersent entre les services
Chaque service qui écrit ou recherche des données a besoin de la clé API de votre fournisseur d’embeddings. Avec Functions, les identifiants résident dans Model Provider Integration de Zilliz Cloud — un seul endroit pour gérer, un seul endroit pour faire tourner les clés, aucun secret dans le code applicatif.
Les données quittent votre réseau à chaque appel d’inférence
Pour les équipes ayant des exigences de confidentialité ou de conformité, envoyer du texte brut à une API externe à chaque insertion et requête est une véritable préoccupation. Les Hosted Models gardent tout — données, inférence, stockage, recherche — au sein du réseau privé de Zilliz.
Ce qui est disponible en aperçu public
Fonctions d’embedding basées sur des modèles
Associez un modèle d’embedding à une collection. À partir de ce moment :
- Insérez du texte brut via Insert, Upsert ou Import — Zilliz Cloud génère et stocke automatiquement les embeddings vectoriels denses.
- Recherchez avec du texte — le système encode votre requête avec le même modèle et exécute une recherche ANN.
Pas de code d’embedding côté client. Pas de souci de cohérence du modèle. Votre application fonctionne simplement avec du texte.
Fonctions de reranking basées sur des modèles
Sélectionnez un modèle de reranking et appliquez-le comme étape post-recherche intégrée. C’est particulièrement puissant pour la recherche hybride, où vous combinez la recherche sémantique et par mots-clés dans un seul ensemble de résultats.
Les rerankers basés sur des modèles vont au-delà de la similarité vectorielle — ils lisent le contenu de chaque candidat et évaluent dans quelle mesure il répond réellement à la requête. C’est la différence entre « ces vecteurs sont proches » et « ce document répond à la question ».
Fournisseurs pris en charge
| Fournisseur | Embedding | Reranking |
|---|---|---|
| OpenAI | Oui | -- |
| Voyage AI | Oui | Oui |
| Cohere | Oui | Oui |
Intégration des fournisseurs de modèles
Enregistrez une seule fois vos identifiants API tiers dans la console Zilliz Cloud via Model Provider Integration. Les collections référencent l’intégration par ID — aucune clé dans le code. Faites tourner les identifiants à un seul endroit ; chaque collection utilisant cette intégration récupère automatiquement la modification.
Ce qui est en aperçu privé : Hosted Models
Pour les équipes pour lesquelles la latence, le coût ou la résidence des données est une priorité, les Hosted Models exécutent des instances de modèles entièrement gérées sur l’infrastructure GPU de Zilliz. La différence architecturale : au lieu d’envoyer les données à une API externe, le modèle s’exécute juste à côté de vos données.
Le diagramme suivant montre les procédures d’utilisation des modèles hébergés.
| Avantage | Ce que cela signifie |
|---|---|
| Aucun frais de transfert de données | L’inférence se fait au sein du réseau Zilliz |
| Latence réduite | Aucun aller-retour externe pour l’embedding ou le reranking |
| Confidentialité renforcée | Le texte brut ne quitte jamais l’environnement Zilliz |
| Ressources dédiées | Aucun problème de performance lié aux voisins bruyants |
Modèles disponibles
| Catégorie | Modèles |
|---|---|
| Embedding | Qwen3-Embedding (0.6B, 4B, 8B), série BAAI BGE (small, base, large — EN & ZH) |
| Reranking | Qwen3-Reranker (0.6B, 4B, 8B), BAAI BGE Reranker (base, large) |
| Semantic Highlighter | zilliz/semantic-highlight-bilingual-v1 — met en évidence les segments de texte pertinents dans les résultats |
Les Hosted Models sont disponibles sur demande. Contactez l’équipe Zilliz pour obtenir l’accès.
Aperçu complet des fonctionnalités de Functions et d’inférence
Fonctions de pré-recherche
| Fonction | Description | Statut |
|---|---|---|
| BM25 | Embeddings clairsemés pour la recherche par mots-clés en texte intégral — aucun modèle requis | GA |
| Model-Based Embedding (3rd-party) | Embeddings denses via OpenAI, Voyage AI, Cohere | Public Preview |
| Model-Based Embedding (Hosted) | Embeddings denses via Qwen3, BGE hébergés par Zilliz | Private Preview |
Fonctions post-recherche
| Fonction | Description | Statut |
|---|---|---|
| Hybrid Rankers | Fusionner les résultats de plusieurs stratégies de récupération (p. ex., sémantique + mots-clés) | GA |
| Rule-Based Rankers | Appliquer une logique métier — récence, popularité, scores personnalisés | GA |
| Model-Based Rankers (3rd-party) | Reranking sémantique via Voyage AI, Cohere | Public Preview |
| Model-Based Rankers (Hosted) | Reranking sémantique via Qwen3, BGE hébergés par Zilliz | Private Preview |
BM25, les rankers hybrides et les rankers basés sur des règles sont généralement disponibles. La version d’aujourd’hui ajoute une intelligence alimentée par des modèles pour l’embedding et le ranking — ainsi que l’infrastructure permettant d’exécuter ces modèles via des API tierces ou directement sur Zilliz Cloud.
Comment démarrer avec Zilliz Cloud Functions
Public Preview (disponible maintenant) :
- Inscrivez-vous ou connectez-vous à Zilliz Cloud — les nouveaux comptes enregistrés avec une adresse e-mail professionnelle reçoivent 100 $ de crédits gratuits
- Configurez une Model Provider Integration dans la console
- Créez une collection avec une fonction d’embedding
- Insérez du texte brut et effectuez une recherche avec du texte — c’est tout
Private Preview (sur demande) :
Contactez-nous pour essayer Hosted Models avec inférence dédiée.
Documentation complète : Guide des fonctions et de l’inférence de modèles
Questions fréquentes
Quelques questions qui reviennent au sujet de l’embedding, du reranking et de l’inférence gérée pour la recherche vectorielle :
Une base de données vectorielle peut-elle générer des embeddings automatiquement ?
Oui. Avec Zilliz Cloud Functions, vous associez un modèle d’embedding à une collection et insérez du texte brut — la base de données génère et stocke les embeddings vectoriels denses pour vous. Les requêtes fonctionnent de la même manière : envoyez une requête textuelle, et le système l’embarque avec le même modèle avant d’exécuter la recherche ANN. Cela élimine le code d’embedding côté client et garantit la cohérence du modèle entre l’ingestion et la recherche.
Qu’est-ce que le reranking basé sur un modèle, et comment améliore-t-il la recherche vectorielle ?
Le reranking basé sur un modèle est une étape post-récupération où un modèle de langage évalue dans quelle mesure chaque document candidat répond réellement à la requête — plutôt que de s’appuyer uniquement sur les scores de similarité vectorielle. Il est particulièrement efficace pour les pipelines de recherche hybride qui combinent récupération par mots-clés et récupération sémantique. Sur Zilliz Cloud, vous pouvez appliquer le reranking basé sur un modèle en tant que Function intégrée à l’aide de fournisseurs comme Voyage AI ou Cohere, ou via Zilliz Hosted Models.
Quelle est la différence entre les modèles d’embedding hébergés et tiers ?
Les modèles tiers (OpenAI, Voyage AI, Cohere) s’exécutent sur l’infrastructure du fournisseur — vous fournissez une clé API et payez à l’appel. Les Hosted Models s’exécutent sur l’infrastructure GPU gérée par Zilliz, de sorte que vos données ne quittent jamais la plateforme. Les Hosted Models offrent une latence plus faible, zéro frais de transfert de données et un calcul dédié sans problèmes de voisins bruyants. Le compromis : le paiement à l’appel de tiers peut être moins cher à faible volume, tandis que les instances hébergées sont plus rentables à grande échelle.
Comment combiner la recherche par mots-clés et la recherche sémantique dans une seule requête ?
Sur Zilliz Cloud, vous pouvez associer à la même collection à la fois une Function BM25 (pour la recherche par mots-clés via des embeddings creux) et une Function d’embedding basée sur un modèle (pour la recherche sémantique via des embeddings denses). Au moment de la requête, un ranker hybride ou un reranker basé sur un modèle fusionne les résultats en une seule liste classée. La collection gère ensemble les embeddings creux, les embeddings denses et le reranking — aucune orchestration externe n’est nécessaire.

Continuer à lire

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.