




Milvus sur les GPU avec NVIDIA RAPIDS cuVS
Introduction
La performance en production est un facteur critique dans le succès de notre application d'IA. Plus vite nous pouvons renvoyer les résultats à l'utilisateur, mieux c'est. Cette urgence entraîne le besoin d'optimisation.
Prenons un exemple concret : l'application [Retrieval Augmented Generation] (https://zilliz.com/learn/Retrieval-Augmented-Generation) (RAG). Dans un système RAG, la recherche vectorielle est le moteur qui alimente l'expérience de l'utilisateur, en fournissant des résultats pertinents basés sur ses requêtes. Cependant, nous ne sommes que trop conscients que la recherche vectorielle est une tâche gourmande en ressources. Plus nous stockons de données, plus le calcul est coûteux et prend du temps.
Une solution doit être trouvée pour optimiser les performances de nos applications d'intelligence artificielle dans de tels cas. Lors d'une récente présentation au Unstructured Data Meetup organisé par Zilliz, Corey Nolet, ingénieur principal chez NVIDIA, a présenté les dernières avancées de NVIDIA pour résoudre ce problème, que nous allons explorer dans cet article. Vous pouvez également consulter l'intervention de [Corey] sur YouTube](https://youtu.be/pBaq3CcZOFc?t=1548).
Plus précisément, nous nous concentrerons sur cuVS, une bibliothèque développée par NVIDIA qui contient plusieurs algorithmes liés à la recherche vectorielle et qui exploite la puissance d'accélération des GPU. Nous verrons comment cette bibliothèque peut améliorer les performances des opérations de recherche vectorielle et optimiser les coûts opérationnels globaux. Alors, sans plus attendre, plongeons dans le vif du sujet !
La recherche vectorielle et le rôle de la base de données vectorielle dans celle-ci
La recherche vectorielle est une méthode de [recherche d'informations] (https://zilliz.com/learn/what-is-information-retrieval) dans laquelle la requête de l'utilisateur et les documents recherchés sont représentés sous forme de vecteurs. Pour effectuer une recherche vectorielle, nous devons transformer notre requête et nos documents (qui peuvent être des images, des textes, etc.) en vecteurs.
Un vecteur a une dimension spécifique, qui dépend de la méthode utilisée pour le générer. Par exemple, si nous utilisons un modèle HuggingFace appelé all-MiniLM-L6-v2 pour transformer notre requête en vecteur, nous obtiendrons un vecteur d'une dimension de 384. Les vecteurs portent la signification sémantique des données ou des documents qu'ils représentent. Par conséquent, si deux données sont similaires, leurs vecteurs correspondants sont positionnés à proximité l'un de l'autre dans l'espace vectoriel.
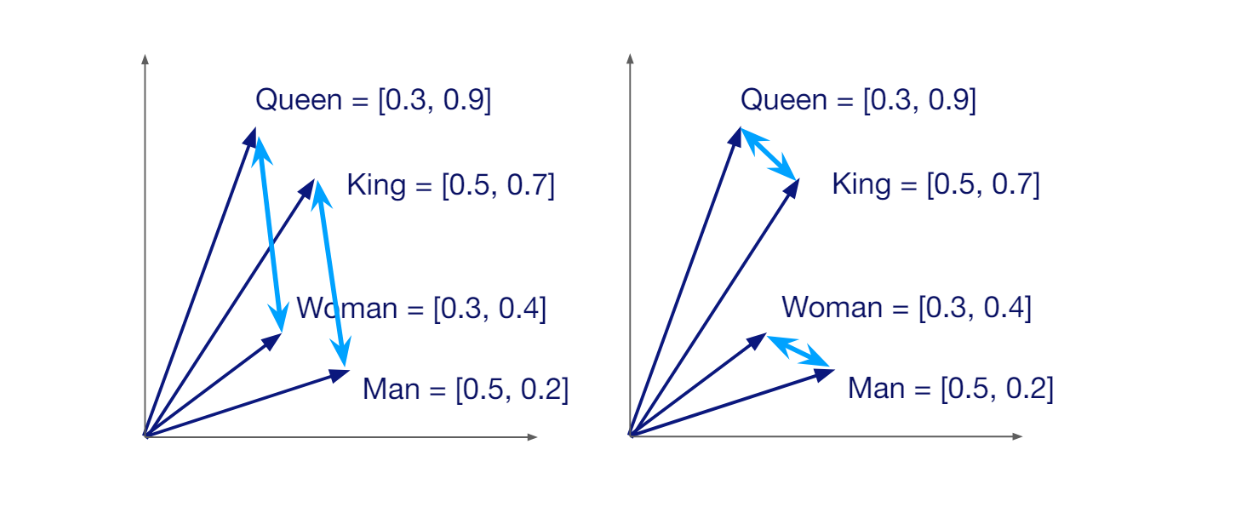 Similitude sémantique entre vecteurs dans un espace vectoriel..png
Similitude sémantique entre vecteurs dans un espace vectoriel..png
Similitude sémantique entre vecteurs dans un espace vectoriel.
Le fait que chaque vecteur porte la signification sémantique des données qu'il représente nous permet de calculer la similarité entre n'importe quelle paire aléatoire de vecteurs. S'ils sont similaires, le score de similarité sera élevé, et vice versa. L'objectif principal de la recherche vectorielle est de trouver les vecteurs les plus similaires au vecteur de notre requête.
La mise en œuvre de la recherche vectorielle est relativement simple lorsqu'il s'agit de quelques documents. Toutefois, la complexité augmente lorsque le nombre de documents est plus élevé et qu'il faut stocker davantage de vecteurs. Plus il y a de vecteurs, plus il faut de temps pour effectuer une recherche vectorielle. En outre, le coût opérationnel augmente considérablement à mesure que nous stockons davantage de vecteurs dans la mémoire locale. Nous avons donc besoin d'une solution évolutive, et c'est là que les [bases de données vectorielles] (https://zilliz.com/learn/what-is-vector-database) entrent en jeu.
Les bases de données vectorielles offrent une solution efficace, rapide et évolutive pour le stockage d'une vaste collection de vecteurs. Elles offrent des méthodes d'indexation avancées pour une récupération plus rapide lors des opérations de recherche de vecteurs, ainsi qu'une intégration facile avec les cadres d'IA les plus courants afin de simplifier le processus de développement de nos applications d'IA. Dans les bases de données vectorielles telles que Milvus et Zilliz Cloud (Milvus géré), nous pouvons également stocker les métadonnées des vecteurs et effectuer des processus de filtrage avancés pendant les opérations de recherche.
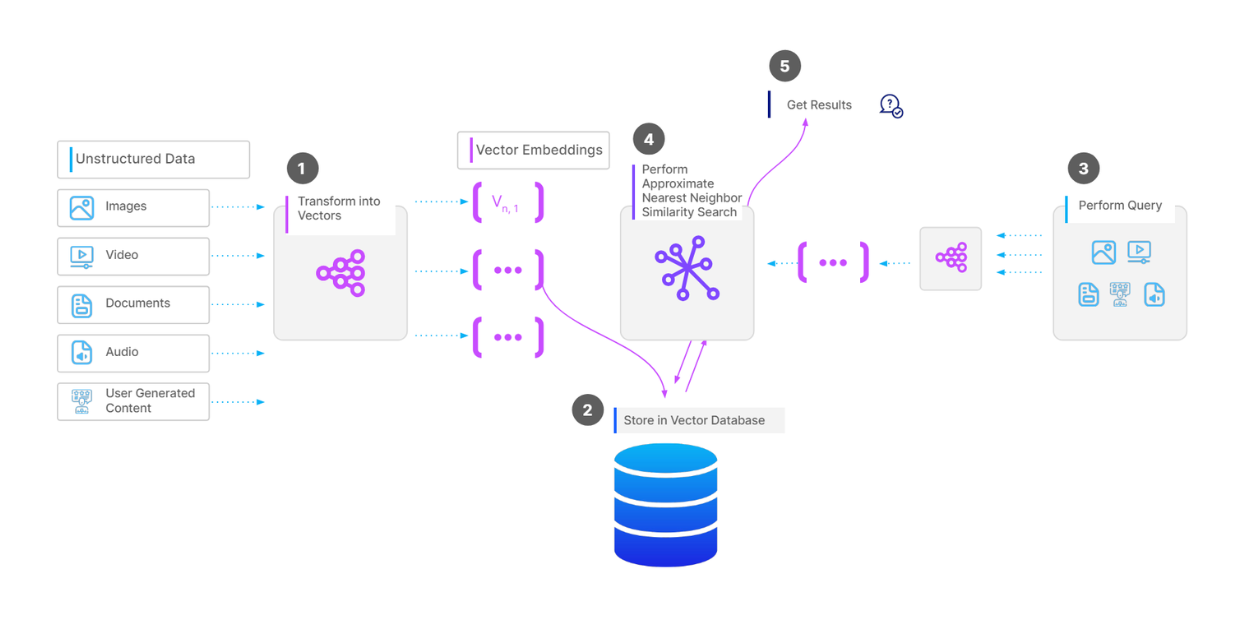 Flux de travail complet d'une opération de recherche de vecteurs..png
Flux de travail complet d'une opération de recherche de vecteurs..png
Flux de travail complet d'une opération de recherche vectorielle.png
Pour stocker une collection de vecteurs dans une base de données vectorielles comme Milvus, la première étape consiste à effectuer un prétraitement des données, en fonction de leur type. Par exemple, si nos données sont une collection de documents, nous pouvons diviser le texte de chaque document en morceaux. Ensuite, nous transformons chaque morceau en vecteur à l'aide d'un [modèle d'intégration] (https://zilliz.com/ai-models) de notre choix. Ensuite, nous intégrons tous les vecteurs dans notre base de données vectorielle et nous construisons un index sur ces vecteurs pour une récupération plus rapide lors des opérations de recherche vectorielle.
Lorsque nous avons une requête et que nous voulons effectuer une opération de recherche vectorielle, nous transformons la requête en un vecteur en utilisant le même modèle d'intégration que précédemment, puis nous calculons sa similarité avec les vecteurs de la base de données. Enfin, les vecteurs les plus similaires nous sont renvoyés.
Opération de recherche vectorielle sur l'unité centrale
Les opérations de recherche vectorielle nécessitent des calculs intensifs, et le coût de calcul augmente à mesure que l'on stocke davantage de vecteurs dans une base de données vectorielles. Plusieurs facteurs affectent directement le coût de calcul, tels que la construction de l'index, le nombre total de vecteurs, la dimensionnalité des vecteurs et la qualité souhaitée des résultats de la recherche.
Les CPU sont les unités de traitement couramment utilisées pour les opérations de recherche vectorielle en raison de leur rentabilité et de leur facilité d'intégration avec d'autres composants dans les applications d'intelligence artificielle. De nombreux algorithmes de recherche vectorielle sont entièrement optimisés pour les CPU, le [Hierarchical Navigable Small World] (https://zilliz.com/learn/hierarchical-navigable-small-worlds-HNSW) (HNSW) étant le plus populaire.
À la base, le HNSW combine les concepts de skip lists et de Navigable Small World (NSW). Dans un algorithme NSW, le graphe est construit en commençant par mélanger aléatoirement nos points de données. Ensuite, les points de données sont insérés un par un, chaque point étant relié à ses voisins les plus proches par un nombre prédéfini d'arêtes.
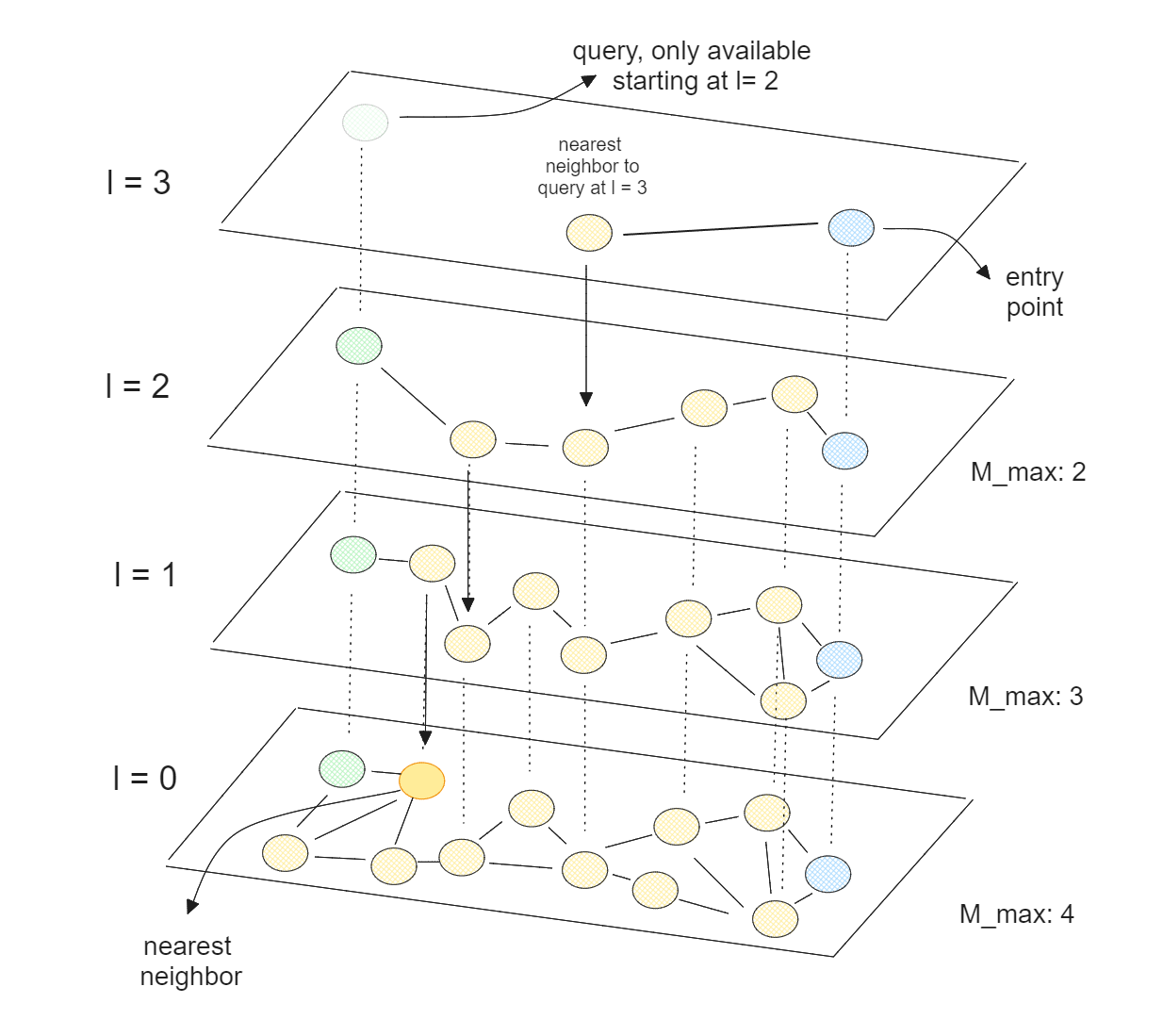 Recherche vectorielle utilisant HNSW..png
Recherche vectorielle utilisant HNSW..png
Recherche vectorielle à l'aide de HNSW._
HNSW est un NSW multicouche, où la couche la plus basse contient tous les points de données, et la couche la plus haute ne contient qu'un petit sous-ensemble de nos points de données. Cela signifie que plus la couche est haute, plus nous sautons de points de données, ce qui correspond à la théorie des listes à sauter.
Avec HNSW, nous disposons d'un graphe où la plupart des nœuds peuvent être atteints à partir de n'importe quel autre nœud grâce à un petit nombre d'itérations. Cette propriété permet à HNSW de naviguer efficacement dans le graphe pour trouver les voisins les plus proches. Comme HNSW est optimisé pour les CPU, nous pouvons également paralléliser son exécution sur plusieurs cœurs de CPU afin d'accélérer encore le processus de recherche vectorielle.
Cependant, le temps de calcul de HNSW continue de diminuer au fur et à mesure que nous stockons davantage de données dans la base de données vectorielle. La situation peut même empirer si la dimensionnalité de nos vecteurs est très élevée. Nous avons donc besoin d'une autre solution pour les cas où nous disposons d'un grand nombre de vecteurs à haute dimensionnalité.
Opération de recherche vectorielle sur GPU
Une solution pour améliorer les performances de la recherche vectorielle en présence d'un grand nombre de vecteurs de haute dimension consiste à utiliser un GPU. Pour ce faire, nous pouvons utiliser la bibliothèque RAPIDS cuVS de NVIDIA, qui contient plusieurs implémentations de recherche vectorielle optimisées pour les GPU. Elle simplifie l'utilisation des GPU à la fois pour les opérations de recherche vectorielle et pour la construction d'index.
cuVS propose plusieurs algorithmes de recherche du plus proche voisin parmi lesquels on peut choisir :
Brute-force : Une recherche exhaustive des plus proches voisins où la requête est comparée à chaque vecteur dans la base de données.
IVF-Flat : Un algorithme d'approximation du plus proche voisin (ANN) qui divise les vecteurs de la base de données en plusieurs partitions ne se recoupant pas. La requête n'est alors comparée qu'aux vecteurs des mêmes partitions (et éventuellement des partitions voisines).
IVF-PQ : Une version quantifiée d'IVF-Flat qui réduit l'empreinte mémoire des vecteurs stockés dans la base de données.
CAGRA : Un algorithme natif du GPU similaire à HNSW.
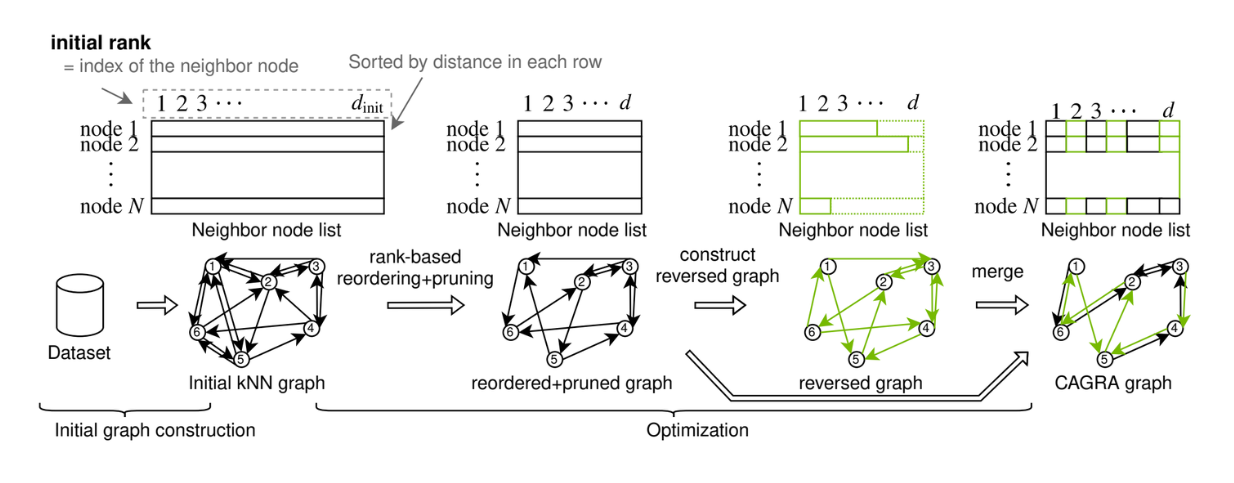 CAGRA graph construction. .png
CAGRA graph construction. .png
CAGRA graph construction. Source.
Parmi ces algorithmes de plus proche voisin, nous nous concentrerons sur CAGRA.
CAGRA est un algorithme basé sur les graphes introduit par NVIDIA pour une recherche rapide et efficace du plus proche voisin, en tirant parti de la puissance de traitement parallèle des GPU.
Le graphe de CAGRA peut être construit à l'aide de la méthode IVF-PQ ou de la méthode NN-DESCENT :
Méthode IVF-PQ : Elle utilise un index pour créer un graphe initial peu gourmand en mémoire en connectant chaque point à de nombreux voisins.
Méthode NN-DESCENT** : Utilise un processus itératif pour construire un graphe en étendant et en affinant les connexions entre les points.
Par rapport à HNSW, les méthodes de construction de graphe de CAGRA sont plus faciles à paralléliser et contiennent moins d'interactions de données entre les tâches, ce qui améliore considérablement le temps de construction du graphe ou de l'index. Si vous souhaitez en savoir plus en détail sur CAGRA, consultez son document officiel ou l'article sur CAGRA.
CAGRA a établi une performance de pointe dans les opérations de recherche vectorielle. Pour le démontrer, nous allons comparer ses performances à celles de HNSW dans la section suivante.
Comparaison des performances de CAGRA et de HNSW
Les performances de la recherche vectorielle sont cruciales pour deux opérations : la construction de l'index et la recherche elle-même. Nous allons comparer les performances de CAGRA et de HNSW dans ces deux opérations.
Commençons par la construction de l'index.
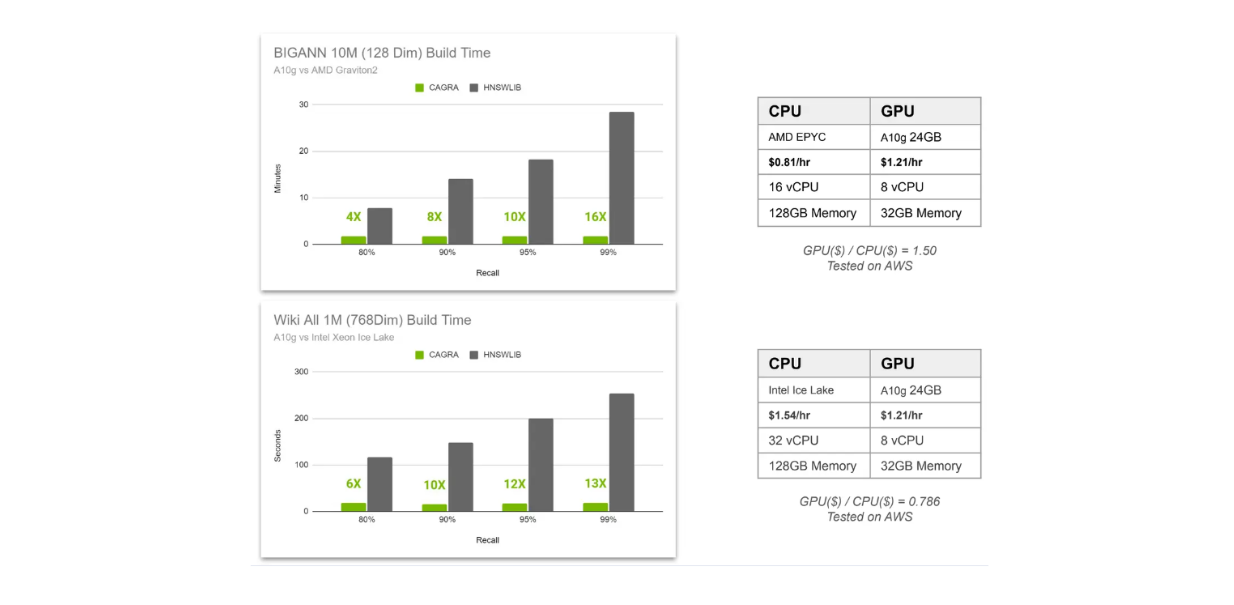 Comparaison du temps de construction d'un index entre CAGRA et HNSW..png
Comparaison du temps de construction d'un index entre CAGRA et HNSW..png
Comparaison du temps de construction de l'indice CAGRA vs HNSW.png]()
Dans la visualisation ci-dessus, nous comparons le temps de construction d'index de CAGRA et de HNSW dans deux scénarios différents. Premièrement, nous avons 10 millions de vecteurs à 128 dimensions stockés dans une base de données vectorielle, et deuxièmement, nous avons 1 million de vecteurs à 768 dimensions. Le premier scénario utilise AMD Graviton2 comme CPU pour HNSW et A10G GPU pour CAGRA, tandis que le second scénario utilise Intel Xeon Ice Lake comme CPU pour HNSW et A10G GPU pour CAGRA.
Nous comparons le temps de construction de l'index pour quatre valeurs de rappel différentes, allant de 80 % à 99 %. Comme vous le savez peut-être déjà, plus le rappel est élevé, plus le calcul nécessaire est intensif.
En effet, dans une recherche vectorielle basée sur un graphe, nous pouvons affiner deux facteurs : le nombre de voisins pris en compte pour trouver le voisin le plus proche à chaque couche, et le nombre de voisins les plus proches à considérer comme point d'entrée dans chaque couche. Plus le rappel est élevé, plus le nombre de voisins pris en compte est important, ce qui se traduit par une plus grande précision de la recherche, mais aussi par un coût de calcul plus élevé.
La visualisation ci-dessus montre qu'il est plus intéressant d'utiliser le GPU lorsque l'on souhaite obtenir des résultats avec un rappel élevé. De plus, l'accélération due à l'utilisation du GPU augmente à mesure que nous augmentons le nombre de vecteurs à haute dimension stockés dans notre base de données vectorielle.
Comparons ensuite les performances de HNSW et de CAGRA à l'aide de deux mesures courantes dans la recherche vectorielle :
Throughput : le nombre de requêtes qui peuvent être effectuées dans un intervalle de temps spécifique.
La latence** : le temps nécessaire à l'algorithme pour effectuer une requête.
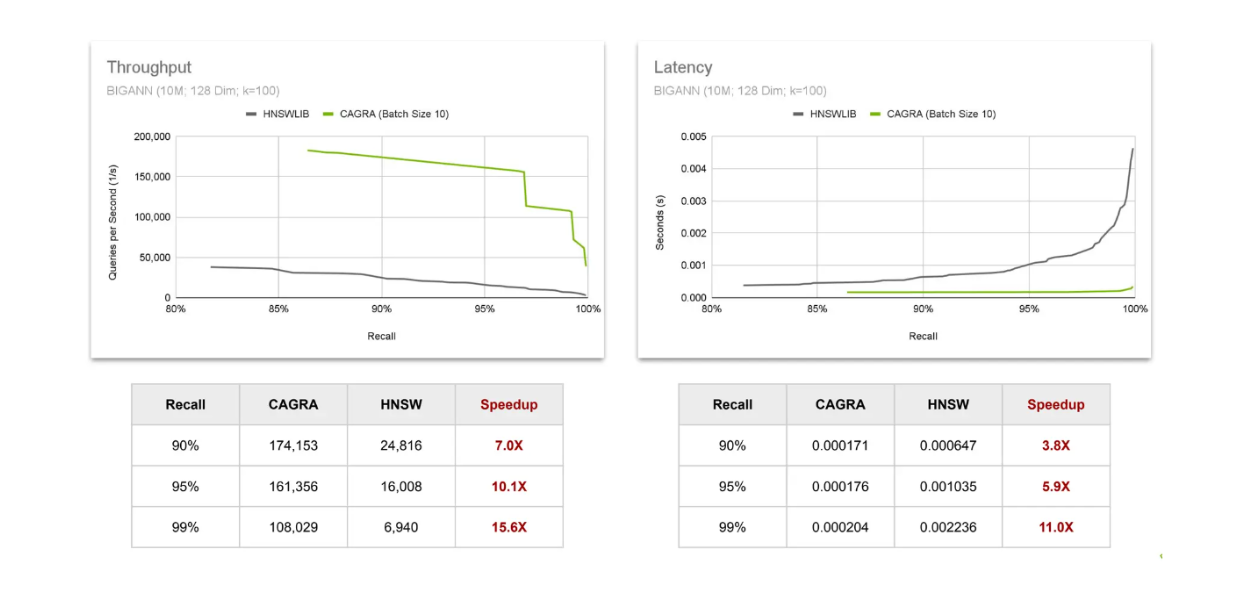 Comparaisons du débit et de la latence entre CAGRA et HNSW..png
Comparaisons du débit et de la latence entre CAGRA et HNSW..png
Comparaisons de débit et de latence CAGRA vs HNSW.png
Pour évaluer le débit, nous observons le nombre de requêtes qui peuvent être effectuées en une seconde. Les résultats montrent que l'accélération de l'utilisation de CAGRA sur GPU augmente à mesure que nous demandons des résultats avec des valeurs de rappel plus élevées. La même tendance est observée pour la latence, où la vitesse augmente avec la valeur de rappel. Cela confirme que la valeur de l'utilisation du GPU augmente au fur et à mesure que nous recherchons des résultats plus précis à partir de la recherche vectorielle.
Cependant, il arrive que nous souhaitions utiliser le CPU pour la recherche vectorielle en raison de sa simplicité et de sa facilité d'intégration avec d'autres composants de notre application d'IA. Dans ce cas, l'implémentation des algorithmes de plus proches voisins avec le CAGRA est toujours utile car nous pouvons effectuer la recherche vectorielle à la fois sur le GPU et sur le CPU par la suite.
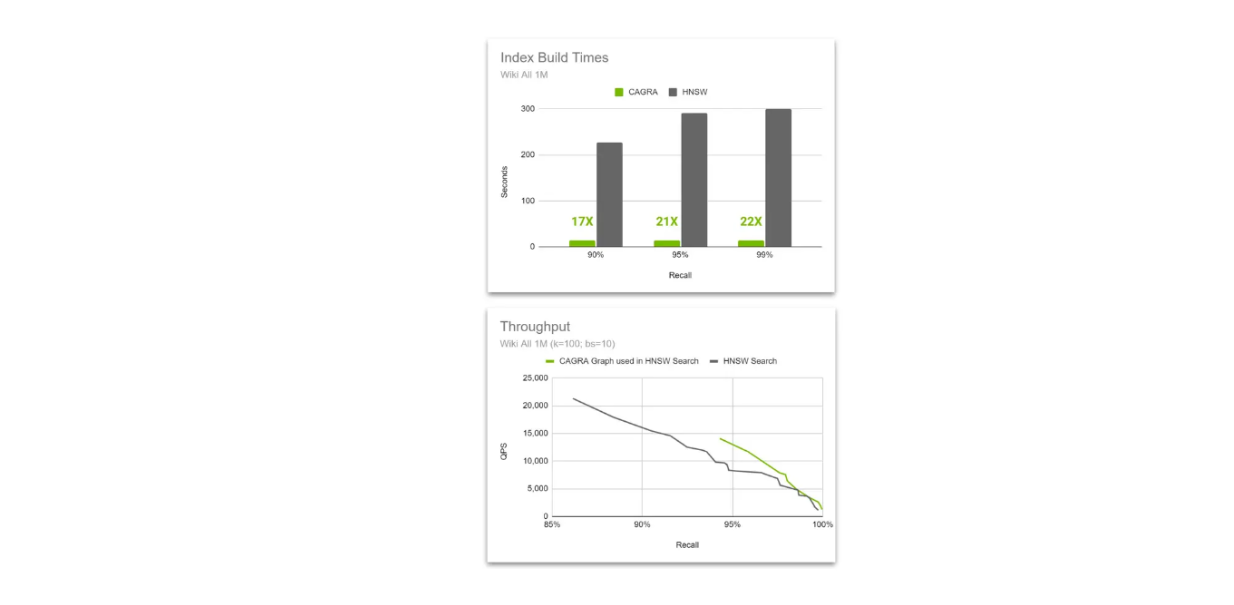 Comparaison du débit entre le graphe HNSW natif et le graphe CAGRA utilisé dans la recherche HNSW..png
Comparaison du débit entre le graphe HNSW natif et le graphe CAGRA utilisé dans la recherche HNSW..png
Comparaison du débit entre le graphe HNSW natif et le graphe CAGRA utilisé dans la recherche HNSW.
L'idée est d'utiliser la puissance d'accélération de CAGRA et du GPU pendant la construction de l'index, puis de passer à HNSW pendant la recherche vectorielle. Cette méthode est possible car l'algorithme HNSW peut effectuer une recherche en utilisant un graphe construit par CAGRA, et ses performances sont encore meilleures que celles du graphe construit avec HNSW lorsque la dimension du vecteur augmente.
CAGRA propose également une méthode de quantification appelée CAGRA-Q pour comprimer davantage la mémoire des vecteurs stockés. Cette méthode est particulièrement utile pour rendre l'allocation de la mémoire plus efficace et nous permet de stocker les vecteurs quantifiés sur une mémoire plus petite afin de les retrouver plus rapidement.
Supposons que nous ayons une mémoire de périphérique dont la taille est inférieure à celle de la mémoire hôte. Les premiers benchmarks de performance de NVIDIA ont montré que les vecteurs quantifiés stockés dans la mémoire de l'appareil avec le graphique stocké dans la mémoire hôte auront des performances similaires à celles des vecteurs originaux non quantifiés et du graphique stocké dans la mémoire de l'appareil à des taux de rappel plus élevés.
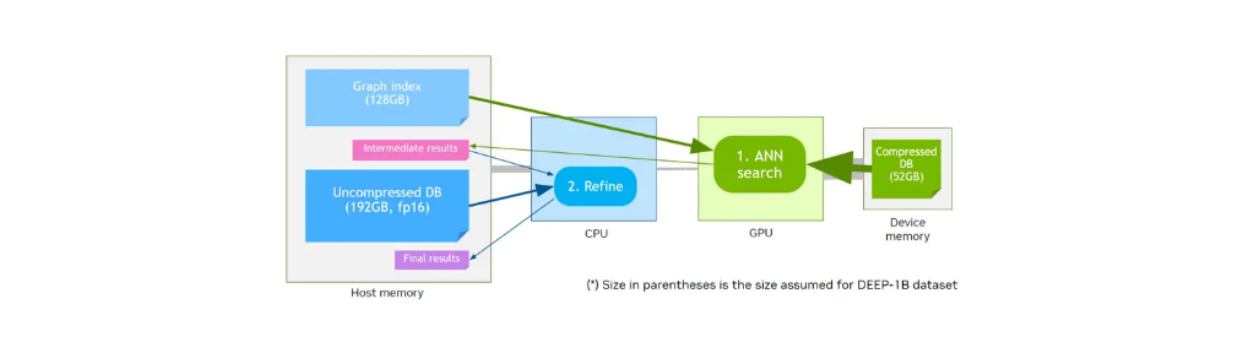 Flux de travail de la recherche vectorielle en utilisant la mémoire de l'appareil et CAGRA-Q..png
Flux de travail de la recherche vectorielle en utilisant la mémoire de l'appareil et CAGRA-Q..png
Flux de travail de la recherche vectorielle en utilisant la mémoire de l'appareil et CAGRA-Q..png]()
Milvus sur le GPU avec CuVS
Milvus supporte l'intégration avec la bibliothèque cuVS, nous permettant de combiner Milvus avec CAGRA pour construire des applications d'IA. L'architecture de Milvus consiste en plusieurs nœuds, tels que les nœuds d'index, les nœuds de requête et les nœuds de données. cuVS optimise la performance de Milvus en accélérant les processus au sein des nœuds de requête et des nœuds d'index.
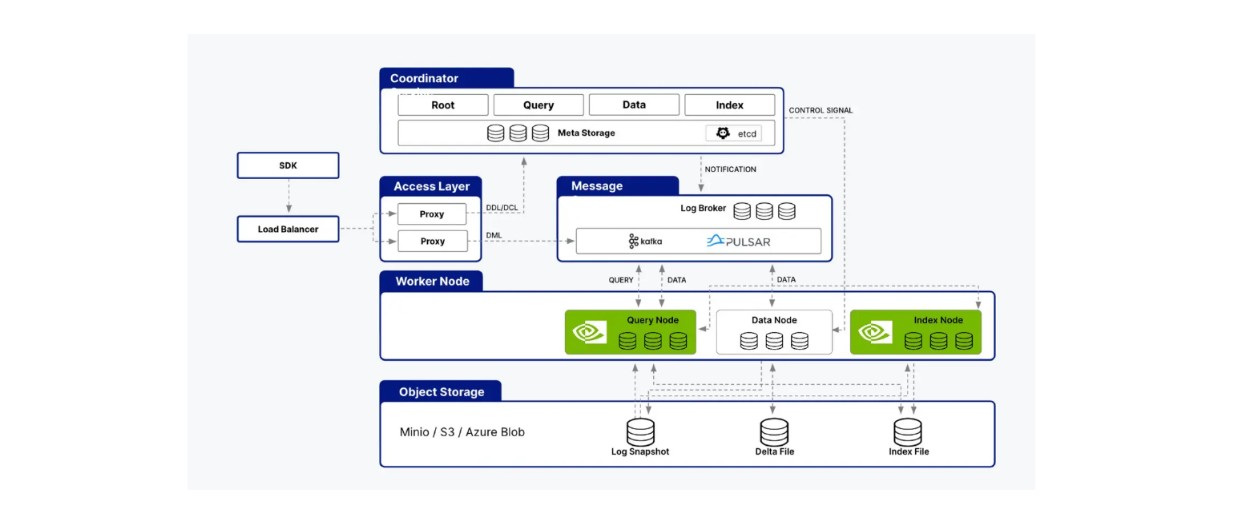 cuVS supporte les noeuds de requête et d'index de l'architecture Milvus..png
cuVS supporte les noeuds de requête et d'index de l'architecture Milvus..png
cuVS supporte à la fois les nœuds de requête et d'indexation de l'architecture Milvus.
Comme vous le savez peut-être déjà, les nœuds d'index sont responsables de la construction de l'index, tandis que les nœuds de requête traitent les requêtes des utilisateurs, effectuent des recherches vectorielles et renvoient les résultats à l'utilisateur. Nous avons vu comment CAGRA améliore tous ces aspects par rapport aux algorithmes CPU natifs comme HNSW dans la section précédente.
Examinons maintenant les performances de la construction d'index avec cuVS et Milvus sur site. Plus précisément, nous allons examiner le temps de construction de l'index en utilisant CAGRA et IVF-PQ pour différents nombres de vecteurs : 10, 20, 40 et 80 millions.
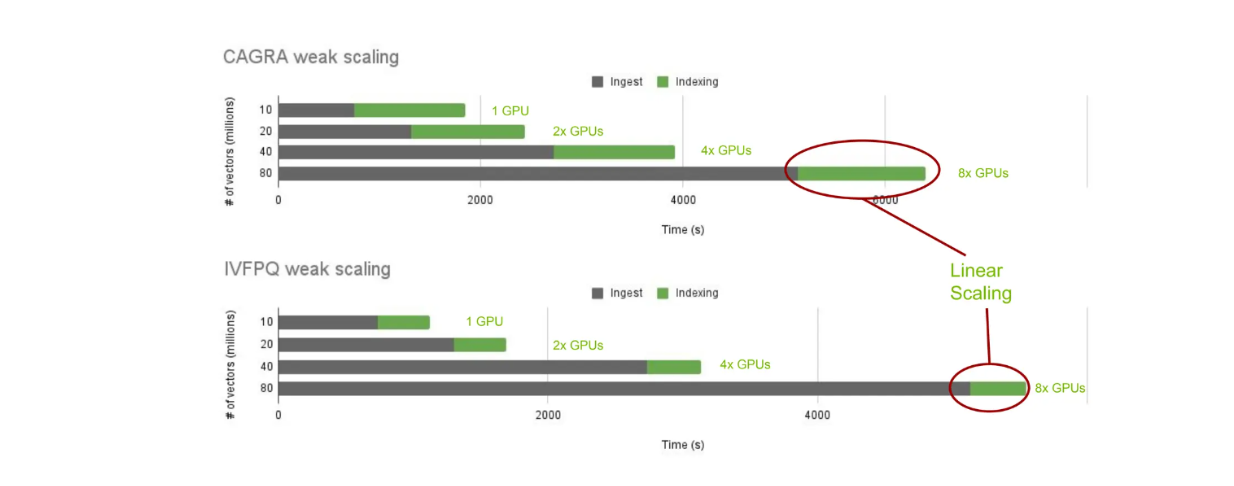 cuVS scaling of index building time across different nearest neighbors algorithms..png
cuVS scaling of index building time across different nearest neighbors algorithms..png
L'échelle de la durée de construction de l'index entre les différents algorithmes de voisinage le plus proche.
Comme prévu, le temps d'ingestion augmente avec le nombre de vecteurs stockés. Cependant, le temps de construction de l'index reste constant lorsque nous ajoutons linéairement plus de GPU en fonction du nombre de vecteurs stockés. Cela nous permet de mettre à l'échelle et de comparer le temps de construction de l'index entre différents algorithmes de plus proche voisin avec cuVS.
Nous savons que les GPU offrent des opérations de calcul plus rapides que les CPU. Cependant, le coût opérationnel de l'utilisation des GPU est également plus élevé. Par conséquent, nous devons comparer le rapport coût-performance de l'utilisation des GPU et des CPU avec Milvus, comme le montre la figure ci-dessous.
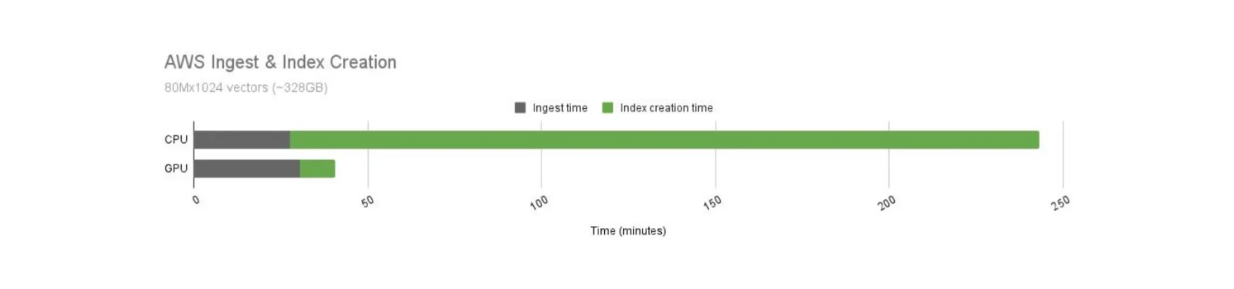 Comparaison du temps de construction de l'index Milvus entre GPU et CPU..png
Comparaison du temps de construction de l'index Milvus entre GPU et CPU..png
Comparaison du temps de construction de l'index de Milvus entre le GPU et le CPU.
Le temps de construction de l'index à l'aide des GPU est nettement plus rapide que celui des CPU. Dans ce cas d'utilisation, Milvus accéléré par le GPU offre une vitesse 21x supérieure à celle de son homologue CPU. Cependant, le coût opérationnel des GPU est également plus élevé que celui des CPU. Le GPU coûte 16,29 dollars par heure, tandis que le CPU coûte 9,68 dollars par heure.
Lorsque nous normalisons le rapport coût-performance des GPU et des CPU, l'utilisation des GPU pour la construction d'index donne toujours de meilleurs résultats. À coût égal, le temps de construction de l'index est 12,5 fois plus rapide avec les GPU.
Dans un autre test de référence, nous avons construit un index pour 635 millions de vecteurs à 1024 dimensions. En utilisant 8 GPU DGX H100, le temps de construction de l'index avec la méthode IVF-PQ est d'environ 56 minutes. En revanche, l'utilisation d'un processeur pour effectuer la même tâche prendrait environ 6,22 jours.
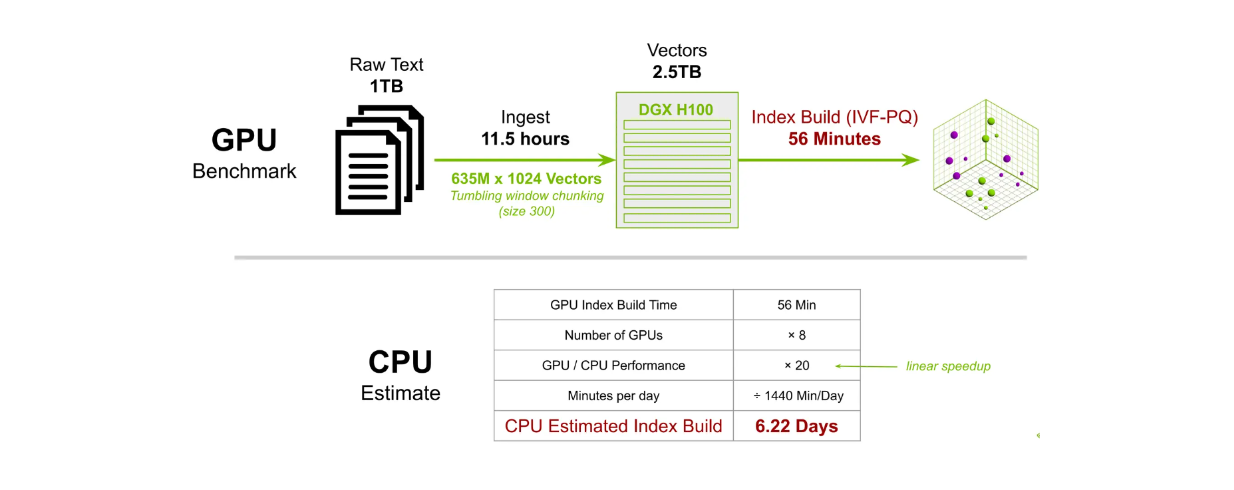 Comparaison du temps de construction de l'index Milvus à grande échelle entre GPU et CPU..png
Comparaison du temps de construction de l'index Milvus à grande échelle entre GPU et CPU..png
Comparaison du temps de construction de l'index de Milvus à grande échelle entre le GPU et le CPU.
Conclusion
Les progrès de la recherche vectorielle accélérée par le GPU grâce à la bibliothèque cuVS et à l'algorithme CAGRA de NVIDIA sont très utiles pour optimiser les performances des applications d'IA en production. Plus précisément, les GPU offrent des améliorations significatives par rapport aux CPU dans les cas impliquant des valeurs de rappel élevées, une dimensionnalité vectorielle élevée et un grand nombre de vecteurs.
Grâce aux capacités d'intégration de Milvus, nous pouvons désormais facilement incorporer cuVS dans notre base de données vectorielles Milvus. Bien que les GPU aient des coûts opérationnels plus élevés que les CPU, le rapport performance-coût favorise encore souvent les GPU dans les applications à grande échelle, comme le démontrent les benchmarks ci-dessus. Si vous souhaitez en savoir plus sur cuVS, vous pouvez vous référer à la [documentation complète] (https://rapids.ai/cuvs/) fournie par l'équipe NVIDIA.
Ressources complémentaires
Qu'est-ce que RAG ? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Qu'est-ce qu'une base de données vectorielle et comment fonctionne-t-elle ?](https://zilliz.com/learn/what-is-vector-database)
[Comment améliorer les performances de votre pipeline RAG] (https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
Recherche vectorielle efficace dans RecSys avec Milvus et NVIDIA Merlin
Continuer à lire

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.