




Métriques de similarité pour la recherche vectorielle
Métriques de similarité vectorielle pour la recherche - Zilliz Blog
On ne peut pas comparer des pommes et des oranges. Ou le pouvez-vous ? Les bases de données vectorielles comme Milvus vous permettent de comparer n'importe quelle donnée que vous pouvez vectoriser. Vous pouvez même le faire directement dans votre Jupyter Notebook. Mais comment fonctionne la recherche de similarité vectorielle ?
La recherche vectorielle comporte deux éléments conceptuels essentiels : les index et les mesures de distance. Parmi les index vectoriels les plus répandus, citons HNSW, IVF et ScaNN. Il existe trois principales mesures de distance : L2 ou distance euclidienne, la similarité en cosinus et le produit intérieur. La distance de Manhattan calcule la distance entre les points en additionnant les différences absolues dans chaque dimension et est avantageuse dans les scénarios où la sensibilité aux valeurs aberrantes doit être minimisée. D'autres mesures pour les vecteurs binaires incluent la distance de Hamming et l'indice de Jaccard.
Dans cet article, nous aborderons les points suivants
Les métriques de similarité vectorielle
L2 ou Euclidean
Comment fonctionne la distance L2 ?
Quand utiliser la distance euclidienne ?
Similitude du cosinus
Comment fonctionne la similitude du cosinus ?
Quand utiliser la similitude des cosinus ?
Produit intérieur
Comment fonctionne le produit intérieur ?
Quand utiliser Inner Product ?
Autres mesures intéressantes de similarité vectorielle ou de distance
Distance de Hamming
Indice de Jaccard
Résumé des métriques de recherche de similarité vectorielle
Les vecteurs peuvent être représentés sous forme de listes de nombres ou sous forme d'une orientation et d'une magnitude. Pour faciliter la compréhension, vous pouvez imaginer les vecteurs comme des segments de ligne pointant dans des directions spécifiques dans l'espace.
La métrique L2 ou euclidienne** est la métrique de l'"hypoténuse" de deux vecteurs. Elle mesure l'ampleur de la distance entre les extrémités des lignes de vos vecteurs.
La similitude du cosinus** est l'angle entre vos lignes à l'endroit où elles se rencontrent.
Le produit intérieur** est la "projection" d'un vecteur sur l'autre. Intuitivement, il mesure à la fois la distance et l'angle entre les vecteurs.
La mesure de distance la plus intuitive est la distance L2 ou distance euclidienne. Nous pouvons l'imaginer comme la quantité d'espace entre deux objets. Par exemple, la distance entre votre écran et votre visage.
Nous avons donc imaginé le fonctionnement de la distance L2 dans l'espace ; comment fonctionne-t-elle en mathématiques ? Commençons par imaginer les deux vecteurs sous la forme d'une liste de nombres. Alignez les listes l'une sur l'autre et faites une soustraction vers le bas. Ensuite, élevez tous les résultats au carré et additionnez-les. Enfin, prenez une racine carrée.
Milvus saute la racine carrée parce que l'ordre de classement avec racine carrée et sans racine carrée est le même. Ainsi, nous pouvons sauter une opération et obtenir le même résultat, ce qui réduit la latence et le coût et augmente le débit. Voici un exemple du fonctionnement de la distance euclidienne ou L2.
d(Reine, Roi) = √ (0.3-0.5)2 + (0.9-0.7)2
= √(0.2)2 + (0.2)2
= √0.04 + 0.04
= √0.08 ≅ 0.28
L'une des principales raisons d'utiliser la [distance] euclidienne est que vos vecteurs](https://zilliz.com/glossary/vector-distance) ont des amplitudes différentes. Ce qui vous intéresse avant tout, c'est la distance spatiale ou sémantique entre vos mots.
Nous utilisons le terme "similarité cosinus" ou "distance cosinus" pour désigner la différence entre l'orientation de deux vecteurs. Par exemple, jusqu'où vous tourneriez-vous pour faire face à la porte d'entrée ?
Fait amusant et applicable : bien que les termes "similarité" et "distance" aient des significations différentes, l'ajout du cosinus devant les deux termes leur donne presque la même signification ! Voilà un autre exemple de [similarité sémantique] (https://zilliz.com/glossary/semantic-similarity) en jeu.
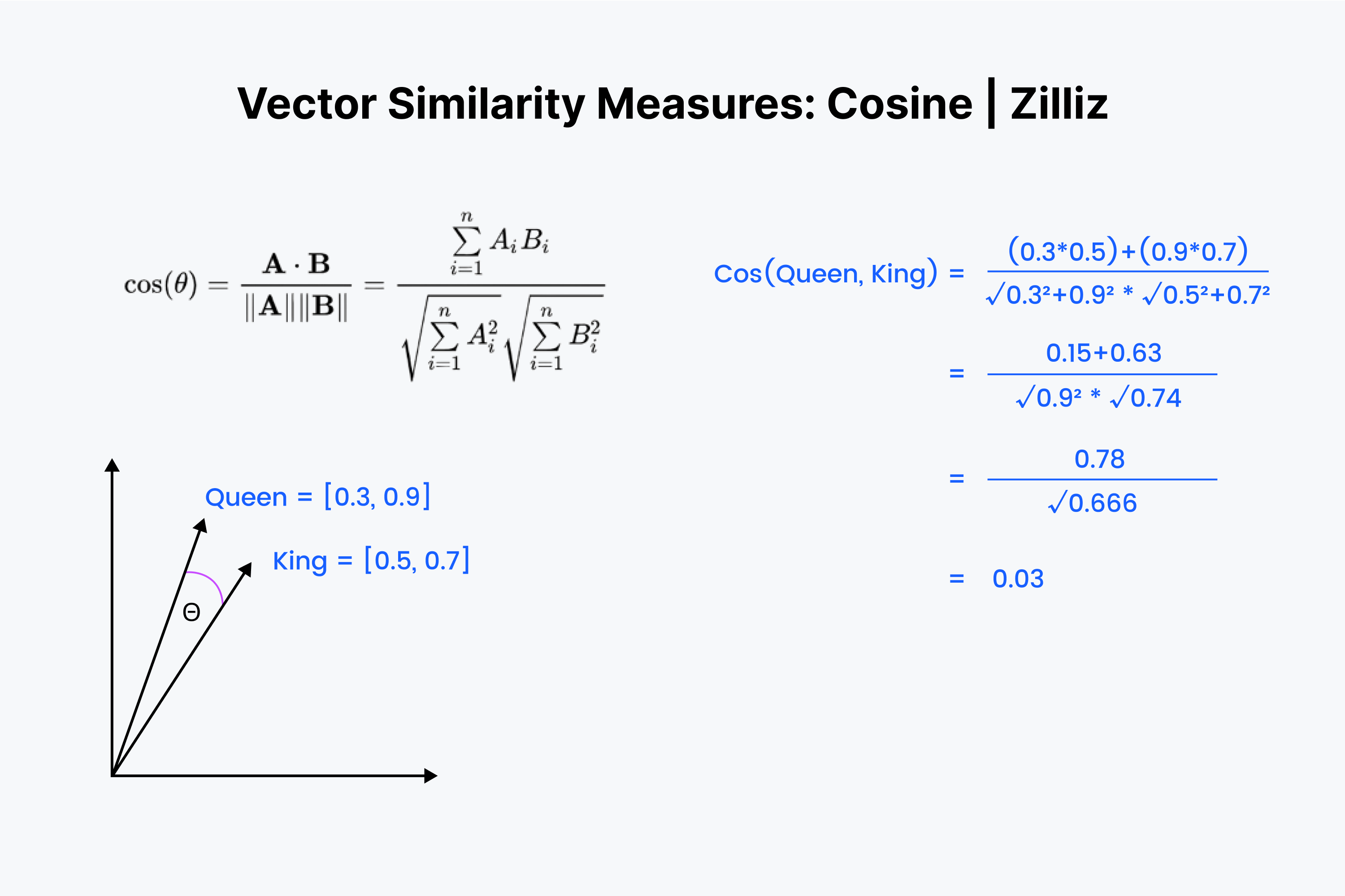
Nous savons donc que la similarité en cosinus mesure l'angle entre deux vecteurs. Une fois de plus, nous imaginons nos vecteurs sous la forme d'une liste de nombres. Le processus est cependant un peu plus complexe cette fois-ci.
Nous commençons par aligner les vecteurs les uns sur les autres. Commencez par multiplier les nombres vers le bas, puis additionnez tous les résultats. Enregistrez maintenant ce nombre ; appelez-le "x". Ensuite, nous devons élever chaque nombre au carré et additionner les nombres de chaque vecteur. Imaginez que vous mettiez chaque nombre au carré horizontalement et que vous les additionniez pour les deux vecteurs.
Prenez la racine carrée des deux sommes, multipliez-les et appelez ce résultat "y". La valeur de notre distance en cosinus est égale à "x" divisé par "y".
La similarité en cosinus est principalement utilisée dans les [applications NLP] (https://zilliz.com/learn/top-5-nlp-applications). La principale mesure de la similarité en cosinus est la différence d'orientation sémantique. Si vous travaillez avec des vecteurs normalisés, la similarité en cosinus est équivalente au produit intérieur.
Le produit intérieur est la projection d'un vecteur sur l'autre. La valeur du produit intérieur est la longueur du vecteur étiré. Plus l'angle entre les deux vecteurs est grand, plus le produit intérieur est petit. Il augmente également avec la longueur du vecteur le plus petit. Nous utilisons donc le produit intérieur lorsque nous nous intéressons à l'orientation et à la distance. Par exemple, vous devez parcourir une distance droite à travers les murs jusqu'à votre réfrigérateur.
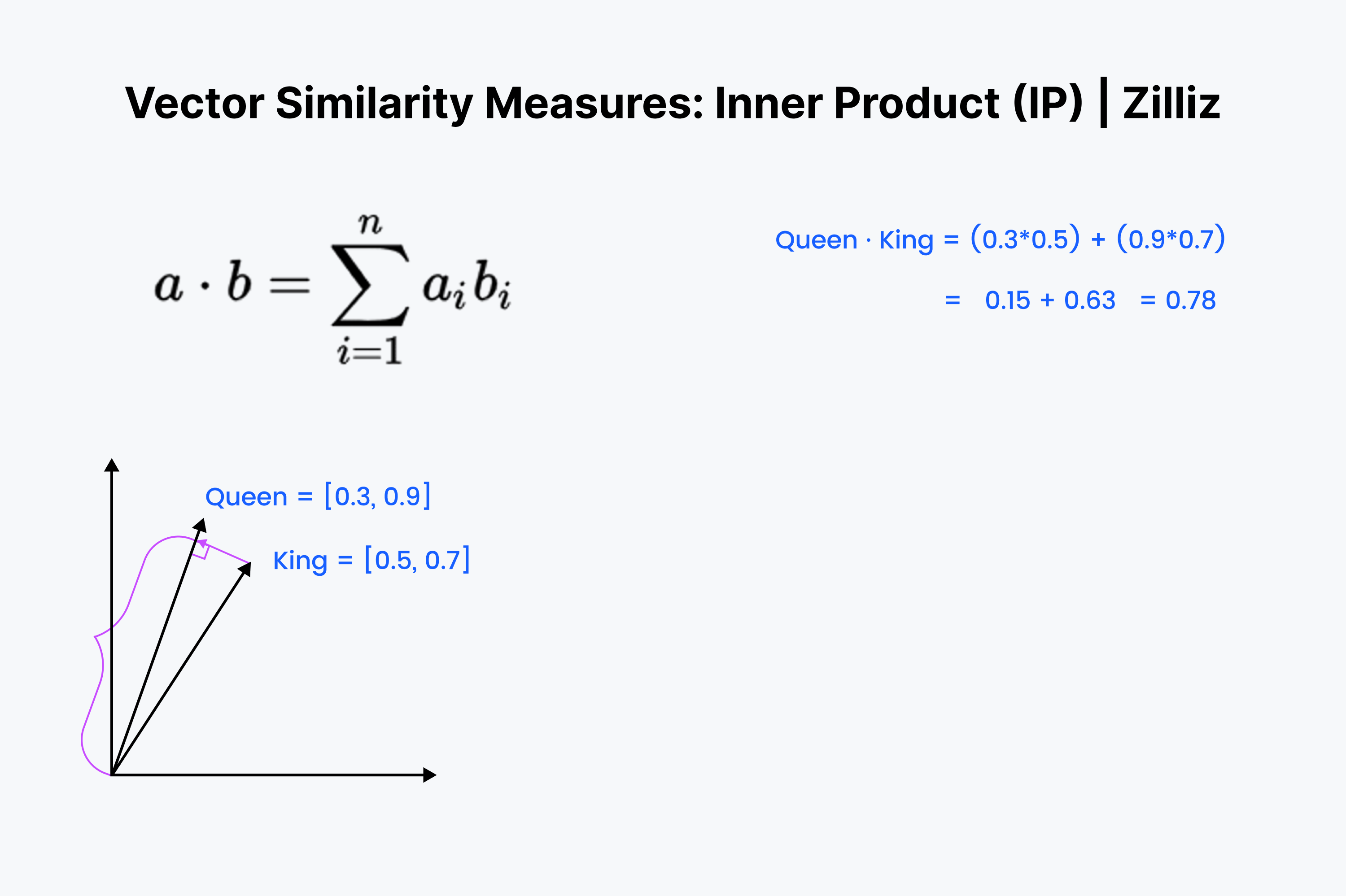
Le produit intérieur devrait vous sembler familier. C'est juste le premier ⅓ du calcul du cosinus. Alignez ces vecteurs dans votre esprit et descendez dans la rangée, en multipliant vers le bas. Ensuite, faites la somme. Cela mesure la distance en ligne droite entre vous et le dim sum le plus proche.
Le produit intérieur est un croisement entre la distance euclidienne et la similarité en cosinus. Lorsqu'il s'agit d'ensembles de données normalisés, il est identique à la similarité cosinusoïdale, de sorte que le produit intérieur convient aussi bien aux ensembles de données normalisés que non normalisés. C'est une option plus rapide que la similarité cosinusoïdale et plus flexible.
Il convient de garder à l'esprit que le produit intérieur ne suit pas l'inégalité triangulaire. Les grandes longueurs (grandes amplitudes) sont prioritaires. Cela signifie que nous devons être prudents lorsque nous utilisons le produit intérieur avec [Inverted File Index] (https://zilliz.com/learn/vector-index) ou un index de graphe comme [HNSW] (https://zilliz.com/learn/hierarchical-navigable-small-worlds-HNSW).
Les trois mesures vectorielles mentionnées ci-dessus sont les plus utiles en ce qui concerne les [vector embeddings] (https://zilliz.com/glossary/vector-embeddings). Cependant, ce ne sont pas les seules façons de mesurer la distance entre deux vecteurs. Voici deux autres façons de mesurer la distance ou la similarité entre vecteurs.
 Groupe 13401.png
Groupe 13401.png
La distance de Hamming peut être appliquée à des vecteurs ou à des chaînes de caractères. Pour notre cas d'utilisation, nous nous en tiendrons aux vecteurs. La distance de Hamming mesure la "différence" entre les entrées de deux vecteurs. Par exemple, "1011" et "0111" ont une distance de Hamming de 2.
En termes d'intégration vectorielle, la distance de Hamming n'a de sens que pour les vecteurs binaires. Les [Float vector embeddings] (https://youtube.com/shorts/d_XNrd8PrTc?feature=share), les sorties de l'avant-dernière couche des réseaux neuronaux, sont constitués de nombres à virgule flottante compris entre 0 et 1. Voici quelques exemples : [0.24, 0.111, 0.21, 0.51235] et [0.33, 0.664, 0.125152, 0.1].
Comme vous pouvez le constater, la distance de Hamming entre deux intégrations vectorielles sera presque toujours égale à la longueur du vecteur lui-même. Il y a tout simplement trop de possibilités pour chaque valeur. C'est pourquoi la distance de Hamming ne peut être appliquée qu'à des vecteurs binaires ou peu denses. Le type de vecteurs produits par un processus tel que TF-IDF, BM25 ou SPLADE.
La distance de Hamming permet de mesurer la différence de formulation entre deux textes, la différence d'orthographe entre deux mots ou la différence entre deux vecteurs binaires. Mais elle n'est pas bonne pour mesurer la différence entre des encastrements vectoriels.
Voici un fait amusant. La distance de Hamming équivaut à la somme des résultats d'une opération XOR sur deux vecteurs.
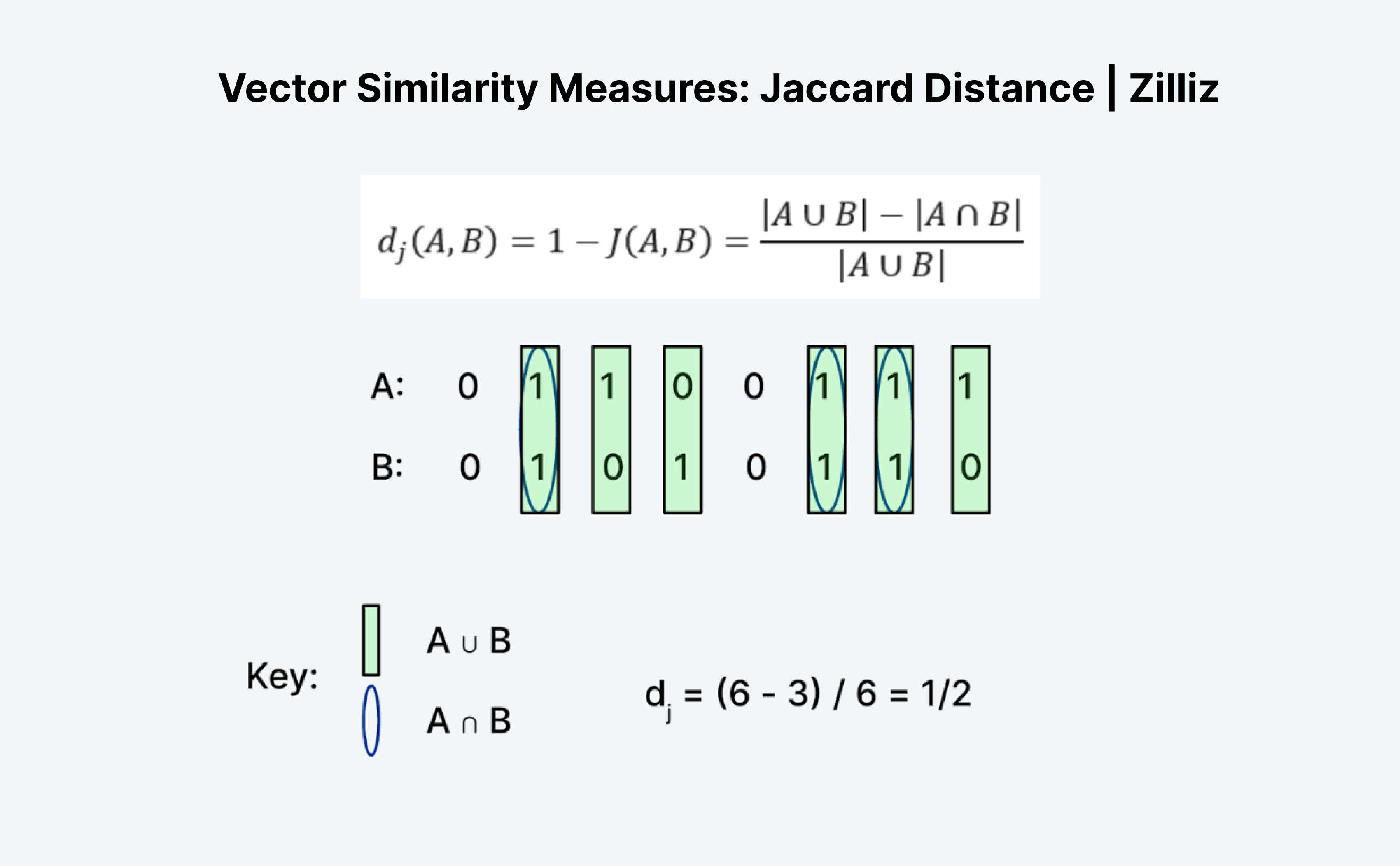
La distance de Jaccard est une autre façon de mesurer la similarité ou la distance de deux vecteurs. Ce qui est intéressant avec Jaccard, c'est qu'il existe à la fois un indice de Jaccard et une distance de Jaccard. La distance de Jaccard est égale à 1 moins l'indice de Jaccard, la mesure de distance mise en œuvre par Milvus.
Le calcul de la distance ou de l'indice de Jaccard est une tâche intéressante parce qu'elle n'a pas vraiment de sens à première vue. Comme la distance de Hamming, Jaccard ne fonctionne que sur des données binaires. La formation traditionnelle des "unions" et des "intersections" me semble déroutante. La façon dont j'y pense est celle de la logique. C'est essentiellement A "OU" B moins A "ET" B divisé par A "OU" B.
Comme le montre l'image ci-dessus, nous comptons le nombre d'entrées où A ou B vaut 1 comme l'"union" et où A et B valent tous deux 1 comme l'"intersection". L'indice de Jaccard pour A (01100111) et B (01010110) est donc de ½. Dans ce cas, la distance de Jaccard, 1 moins l'indice de Jaccard, est également ½.
Dans ce billet, nous avons appris à connaître les trois métriques de recherche de similarité vectorielle les plus utiles : La distance L2 (également connue sous le nom d'Euclide), la distance en cosinus et le produit intérieur. Chacune de ces mesures a des utilisations différentes. La distance euclidienne est utilisée lorsque nous nous intéressons à la différence de magnitude. Le cosinus est utilisé lorsque l'on s'intéresse à la différence d'orientation. Le produit intérieur est utilisé lorsque l'on s'intéresse à la différence de magnitude et d'orientation.
Regardez ces vidéos pour en savoir plus sur les métriques de similarité vectorielle ou [lire la documentation] (https://milvus.io/docs/search.md) pour savoir comment configurer ces métriques dans Milvus.
Introduction aux métriques de similarité
Les métriques de similarité sont un outil crucial dans diverses tâches d'analyse de données et d'apprentissage automatique. Elles nous permettent de comparer et d'évaluer la similarité entre différents éléments de données, facilitant ainsi des applications telles que le regroupement, la classification et les recommandations. Avec les nombreuses mesures de similarité disponibles, chacune avec ses forces et ses faiblesses, le choix de la bonne mesure pour une tâche spécifique peut s'avérer difficile. Dans cette section, nous présenterons le concept de métriques de similarité, leur importance, et nous donnerons un aperçu des métriques les plus couramment utilisées.
Similitude cosinusienne
La similarité cosinus est une mesure de similarité très répandue qui mesure le cosinus de l'angle entre deux vecteurs. Elle est couramment utilisée dans les tâches de traitement du langage naturel et de [recherche d'informations] (https://zilliz.com/learn/what-is-information-retrieval). La mesure de similarité en cosinus est particulièrement utile lorsqu'il s'agit de données à haute dimension, car elle est efficace sur le plan informatique et peut traiter des données éparses. La similarité en cosinus entre deux vecteurs peut être calculée en utilisant le produit en points des vecteurs divisé par le produit de leurs magnitudes.
Distance euclidienne
La distance euclidienne, également connue sous le nom de distance en ligne droite, est une mesure de distance très répandue qui mesure la distance entre deux points dans un espace à n dimensions. Elle est calculée comme la racine carrée de la somme des carrés des différences entre les éléments correspondants des deux vecteurs. La distance euclidienne est couramment utilisée dans diverses applications, notamment le regroupement, la classification et l'analyse de régression. Toutefois, elle peut être sensible aux valeurs aberrantes et ne pas être efficace avec des données de haute dimension.
Choisir la bonne métrique de similarité
Le choix de la bonne métrique de similarité dépend de plusieurs facteurs, notamment du type de données, des objectifs de l'analyse et de la relation entre les variables. Par exemple, la similarité en cosinus convient aux données de haute dimension et aux tâches de traitement du langage naturel, tandis que la distance euclidienne est couramment utilisée pour les tâches de regroupement et de classification. La distance de Manhattan, également connue sous le nom de distance L1, convient aux données comportant des valeurs aberrantes, tandis que la distance de Hamming est utilisée pour les données binaires. Il est essentiel de comprendre les caractéristiques et les limites de chaque mesure de similarité afin de choisir la plus appropriée pour une tâche spécifique.
Applications dans le monde réel
Les métriques de similarité ont de nombreuses applications dans le monde réel, dans divers domaines, notamment :
Traitement du langage naturel : La similarité cosinus est largement utilisée dans la classification des textes, l'analyse des sentiments et les tâches de recherche d'informations.
Systèmes de recommandation : Les mesures de similarité, telles que la similarité cosinus et la distance euclidienne, sont utilisées pour recommander des produits ou des services en fonction du comportement et des préférences de l'utilisateur.
Analyse d'images et de vidéos : Les mesures de similarité, telles que la distance euclidienne et la distance de Manhattan, sont utilisées dans la classification d'images et de vidéos, la [détection d'objets] (https://zilliz.com/learn/what-is-object-detection) et les tâches de suivi.
Regroupement et classification : Les mesures de similarité, telles que la distance euclidienne et la similarité en cosinus, sont utilisées dans les tâches de regroupement et de classification pour regrouper les points de données similaires.
En conclusion, les mesures de similarité sont un outil crucial dans diverses tâches d'analyse de données et d'apprentissage automatique. Il est essentiel de comprendre les caractéristiques et les limites de chaque métrique de similarité pour choisir celle qui convient le mieux à une tâche spécifique. En sélectionnant la bonne métrique de similarité, nous pouvons améliorer la précision et la pertinence de nos résultats, ce qui permet de prendre de meilleures décisions et d'obtenir de meilleures informations.

Continuer à lire

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.