




Choisir le bon modèle d'intégration pour vos données
Qu'est-ce qu'un modèle d'intégration ?
Les modèles d'intégration sont des modèles d'apprentissage automatique qui transforment les données non structurées (texte, images, audio, etc.) en vecteurs de taille fixe, également connus sous le nom d'intégrations vectorielles (intégration éparse, dense, binaire, etc.). Ces vecteurs capturent la signification sémantique des données non structurées, ce qui facilite l'exécution de diverses tâches telles que la recherche de similitudes, le traitement du langage naturel (NLP), la vision par ordinateur, le regroupement, la classification, etc.
Il existe différents types de modèles d'intégration, notamment les intégrations de mots, les intégrations de phrases, les intégrations d'images, les intégrations multimodales et bien d'autres encore.
Encastrements de mots : Représentation des mots sous forme de [vecteurs denses] (https://zilliz.com/learn/sparse-and-dense-embeddings). Les exemples incluent Word2Vec, GloVe et FastText.
Sentence Embeddings : Représentent des phrases ou des paragraphes entiers. Exemples : Universal Sentence Encoder (USE) et [Sentence-BERT] (https://zilliz.com/learn/Sentence-Transformers-for-Long-Form-Text).
Image Embeddings : Représentation d'images sous forme de vecteurs. Les exemples incluent des modèles tels que ResNet et CLIP.
Multimodal Embeddings : Combine différents types de données (par exemple, du texte et des images) dans un seul espace d'intégration. CLIP de l'OpenAI en est un exemple notable.
Modèles d'intégration et génération augmentée de recherche (RAG)
Retrieval Augmented Generation (RAG) est un modèle d'IA générative dans lequel vous pouvez utiliser vos données pour augmenter la connaissance du modèle générateur LLM (tel que ChatGPT). Cette approche est une solution parfaite pour résoudre les problèmes d'hallucinations gênantes des LLM. Elle peut également vous aider à tirer parti de vos données privées ou spécifiques à un domaine pour créer des applications d'IA générative sans vous soucier des problèmes de sécurité des données.
RAG se compose de deux modèles différents, les [modèles d'intégration] (https://zilliz.com/ai-models) et les [grands modèles de langage] (https://zilliz.com/glossary/large-language-models-(llms)) (LLM), qui sont tous deux utilisés en mode d'inférence. Ce blog explique comment choisir le meilleur modèle d'intégration et où le trouver en fonction du type de données et éventuellement de la langue ou du domaine de spécialité, tel que le droit.
Comment choisir le meilleur modèle d'intégration pour vos données
Pour choisir le bon modèle d'intégration pour vos données, vous devez comprendre votre cas d'utilisation spécifique, le type de données dont vous disposez et les exigences de performance de votre application.
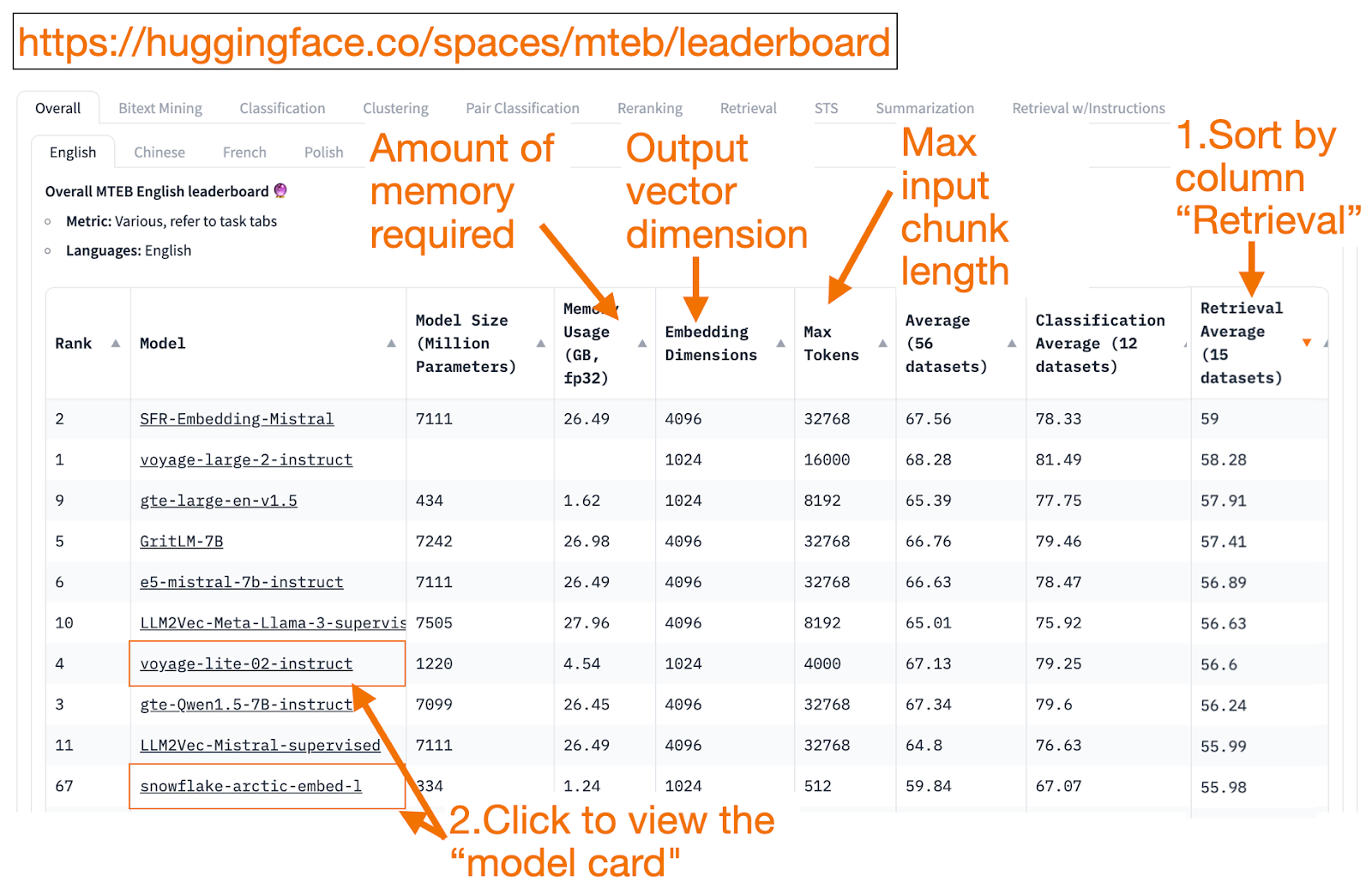
Données textuelles : MTEB Tableau de bord
Le classement HuggingFace MTEB est un guichet unique pour trouver des modèles d'intégration de texte ! Pour chaque modèle d'intégration, vous pouvez voir sa performance moyenne dans l'ensemble des tâches.
Une bonne façon de commencer est de trier en descendant par la colonne "Retrieval Average " puisqu'il s'agit de la tâche la plus liée à la recherche vectorielle. Ensuite, recherchez le modèle le plus petit (Go de mémoire).
- La dimension d'intégration est la longueur du vecteur, c'est-à-dire la partie y de f(x)=y, que le modèle produira.
Max tokens est la longueur du morceau de texte en entrée, c'est-à-dire la partie x dans f(x)=y, que vous pouvez entrer dans le modèle.
En plus de la tâche d'extraction, vous pouvez également filtrer par :
Langue: français, anglais, chinois ou polonais. Par exemple, tâche=recherche et Langue=chinois.
- Par exemple, task=retrieval and Language=law, pour des modèles affinés sur des textes juridiques.
Malheureusement, comme les données d'entraînement n'ont été rendues publiques que récemment, certaines entrées de MTEB sont des [modèles surajustés] (https://linkedin.com/pulse/what-overfitting-underfitting-he-hao), qui se classent de manière trompeuse à un niveau plus élevé que celui qu'ils obtiendraient en réalité sur vos données. Ce [blog de HuggingFace] (https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices) contient des conseils pour décider si vous faites confiance au classement d'un modèle. Cliquez sur le lien du modèle (appelé "carte du modèle").
Cherchez des blogs et des articles** qui expliquent comment le modèle a été entraîné et évalué. Examinez attentivement les langues, les données et les tâches sur lesquelles le modèle a été entraîné. Recherchez également des modèles créés par des entreprises réputées. Par exemple, sur la carte de modèle voyage-lite-02-instruct, vous remarquerez que d'autres modèles de production VoyageAI sont listés, mais pas celui-ci. C'est un indice ! Ce modèle est un modèle de vanité (vanity overfit). **Ne l'utilisez pas !
Dans la capture d'écran ci-dessous, j'essaierais la nouvelle entrée de Snowflake, "snowflake-arctic-embed-1" parce qu'elle est bien classée, assez petite pour fonctionner sur mon ordinateur portable, et que la carte de modèle contient des liens vers un blog et un document.
Sceenshot of Snowflake on MTEB Leaderboard
Une fois que vous avez choisi votre modèle d'intégration, l'avantage des modèles HuggingFace est que vous pouvez changer de modèle en modifiant **model_name** dans le code !
import torch
from sentence_transformers import SentenceTransformer
# Initialiser les paramètres de torch
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Charge le modèle à partir de huggingface.
model_name = "WhereIsAI/UAE-Large-V1" # Changez simplement le model_name pour utiliser un autre modèle !
encoder = SentenceTransformer(model_name, device=DEVICE)
# Obtenir les paramètres du modèle et les sauvegarder pour plus tard.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Imprimer les paramètres du modèle.
print(f "nom_du_modèle : {nom_du_modèle}")
print(f "EMBEDDING_DIM : {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH : {MAX_SEQ_LENGTH_IN_TOKENS}")

Données d'image : ResNet50
Il arrive que vous souhaitiez rechercher des images similaires à une image d'entrée. Peut-être cherchez-vous d'autres images de chats Scottish Fold ? Dans ce cas, vous téléchargez votre image préférée d'un chat Scottish Fold et demandez au moteur de recherche de trouver des images similaires !
ResNet50 est un modèle Convolutional Neural Network (CNN) populaire, formé à l'origine en 2015 par Microsoft sur les données ImageNet.
De même, pour la recherche vidéo inversée, ResNet50 peut toujours intégrer des vidéos. Ensuite, une recherche inversée de similarité d'images est effectuée sur la base de données de photos vidéo. La vidéo la plus proche (à l'exclusion de l'entrée) est renvoyée à l'utilisateur en tant que vidéo la plus similaire.
Données sonores : PANNs
Tout comme pour la recherche inversée d'images à partir d'une image d'entrée, il est possible d'inverser la recherche d'un clip audio à partir d'un extrait sonore d'entrée.
Les PANNs (Pretrained Audio Neural Networks) sont des modèles d'intégration populaires pour cette tâche, car ils sont préformés sur des ensembles de données audio à grande échelle et sont efficaces pour des tâches telles que la classification et l'étiquetage audio.
Données multimodales d'images et de textes : SigLIP ou Unum
Au cours des dernières années, des modèles d'intégration ont vu le jour, entraînés sur un mélange de [données non structurées] (https://zilliz.com/glossary/unstructured-data) : Texte, Image, Audio ou Vidéo. Ces modèles d'intégration capturent la [sémantique] (https://zilliz.com/glossary/semantic-search) de plusieurs types de données non structurées à la fois dans le même espace vectoriel.
Les modèles d'intégration multimodale permettent d'utiliser du texte pour rechercher des images, de générer des descriptions textuelles d'images ou d'inverser la recherche d'images à partir d'une image d'entrée.
CLIP (Contrastive Language-Image Pretraining) d'OpenAI en 2021 était le modèle d'intégration standard. Cependant, les praticiens ont trouvé qu'il était difficile à utiliser parce qu'il devait être affiné. En 2024, SigLIP, ou sigmoïdal-CLIP de Google, semble être un CLIP amélioré, avec des rapports de bons résultats en utilisant des invites zero-shot.
Les variantes de petits modèles de LLM sont de plus en plus populaires. Au lieu de nécessiter un grand cluster de cloud computing, elles peuvent fonctionner sur des ordinateurs portables (comme mon Apple M2 avec seulement 16 Go de RAM). Les petits modèles utilisent moins de mémoire, ce qui signifie qu'ils ont une latence plus faible et peuvent potentiellement fonctionner plus rapidement que les grands modèles. [Unum] (https://github.com/unum-cloud/uform?tab=readme-ov-file#uform) propose de petits modèles d'intégration multimodaux.
Données multimodales textuelles et/ou sonores et/ou vidéo
La plupart des systèmes RAG multimodaux texte-son utilisent un LLM génératif multimodal pour convertir d'abord le son en texte. Une fois les paires son-texte créées, le texte est intégré dans des vecteurs et vous pouvez utiliser votre RAG pour récupérer le texte de la manière habituelle. Pour la dernière étape, le texte est reconverti en son pour terminer la boucle texte-son ou vice-versa.
Whisper d'OpenAI peut transcrire la parole en texte.
Text-to-speech (TTS) d'OpenAI peut également convertir du texte en audio parlé.
Les systèmes multimodaux de conversion texte-vidéo utilisent une approche similaire pour convertir les vidéos en texte, intégrer le texte, effectuer des recherches dans le texte et renvoyer des vidéos comme résultats de recherche.
Sora d'OpenAI peut convertir du texte en vidéo. Comme pour Dall-e, vous fournissez un texte et le LLM génère une vidéo. Sora peut également générer des vidéos à partir d'images fixes ou d'autres vidéos.
Résumé
Ce blog a abordé certains modèles d'intégration populaires utilisés dans les [applications RAG] (https://zilliz.com/learn/Retrieval-Augmented-Generation).
Ressources complémentaires
[Qu'est-ce que le RAG ?] (https://zilliz.com/learn/Retrieval-Augmented-Generation)
Modèles d'IA les plus performants pour vos applications GenAI | Zilliz
Références
Classement de la MTEB, papier, Github : https://huggingface.co/spaces/mteb/leaderboard
Meilleures pratiques MTEB pour éviter de choisir un modèle surajouté : https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Recherche d'images similaires : https://milvus.io/docs/image_similarity_search.md
Recherche d'image à vidéo : https://milvus.io/docs/video_similarity_search.md
Recherche de sons similaires : https://milvus.io/docs/audio_similarity_search.md
Recherche texte-image : https://milvus.io/docs/text_image_search.md
2024 SigLIP (sigmoïd loss CLIP) paper : https://arxiv.org/pdf/2401.06167v1
Modèles d'intégration multimodale de poche d'Unum : https://github.com/unum-cloud/uform

{kind=link}
Continuer à lire

Zilliz Cloud Now Available in AWS Europe (Ireland)
Zilliz Cloud launches in AWS eu-west-1 (Ireland) — bringing low-latency vector search, EU data residency, and full GDPR-ready infrastructure to European AI teams. Now live across 30 regions on five cloud providers.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.