




Chain of Thought Prompting: Guiar a la IA para que piense paso a paso
Chain of Thought Prompting: Guiar a la IA para que piense paso a paso
¿Qué es el estímulo en cadena?
La cadena de pensamiento (CoT) es una técnica de [ingeniería de instrucciones](https://zilliz.com/glossary/prompt-as-code-(prompt-engineering)) que ayuda a los grandes modelos lingüísticos (LLM) a dividir los problemas complejos en pasos más pequeños y sencillos. En lugar de dar una respuesta directa, el modelo recorre una secuencia de pensamientos o razonamientos, como si una persona resolviera un problema paso a paso.
¿Cómo funciona el estímulo de la cadena de pensamiento?
El estímulo de la cadena de pensamiento funciona guiando a los modelos de inteligencia artificial (https://zilliz.com/glossary/foundation-models) para que aborden problemas complejos paso a paso. Este método se basa en el razonamiento secuencial: cada paso se basa en el anterior. Por ejemplo, supongamos que al modelo se le plantea un problema matemático difícil. En lugar de intentar dar la respuesta final de inmediato, primero realiza pequeños cálculos o pasos lógicos que conducen a un resultado final más preciso. Este proceso de descomposición del problema ayuda al modelo a obtener la respuesta correcta y a comprender cómo ha llegado a ella, lo que mejora la calidad general de la respuesta.
Ejemplo práctico: Antes y después de la estimulación de la cadena de pensamiento
Veamos cómo funciona CoT a través de un ejemplo práctico. Las dos indicaciones muestran cómo la cadena de pensamiento afecta a la respuesta del modelo de IA.
1. Pregunta antes de CoT
Clasifique las siguientes opiniones de los usuarios como "Positivas", "Negativas" o "Neutras":_.
El producto llegó tarde, pero funciona bien.
El servicio y la calidad son fantásticos.
No me gustó el color, pero la atención al cliente fue muy útil.
Experiencia terrible. No lo recomendaría.
Está bien, hace el trabajo".
Response:
Pregunta sin COT.png](https://assets.zilliz.com/answer_with_prompt_before_COT_d2ba394661.png)
Figura: Pregunta sin CoT
**Análisis
En la solicitud ingenua, el modelo proporciona un resultado básico en el que cada opinión se clasifica simplemente sin explicar cómo se ha llegado a cada decisión. No muestra al usuario el razonamiento que hay detrás de la categorización ni proporciona información sobre qué palabras o frases específicas se consideraron positivas o negativas. El resultado es correcto, pero carece de profundidad y transparencia.
2. Preguntar después de CoT
- Clasifique las siguientes opiniones de los usuarios como "Positivas", "Negativas" o "Neutras". Para cada opinión, siga estos pasos
Lea atentamente la opinión.
- Identifique las palabras o frases positivas.
- Identifique las palabras o frases negativas.
- _Evalúe el sentimiento general basándose en los elementos positivos y negativos.
- Asignar la categoría adecuada.
En la salida, presente toda la información en una tabla.
Proceder con cada revisión:_
El producto llegó tarde pero funciona bien.
El servicio y la calidad son fantásticos.
No me gustó el color, pero la atención al cliente fue muy útil.
Experiencia terrible. No lo recomendaría.
Está bien, hace el trabajo.
Respuesta:
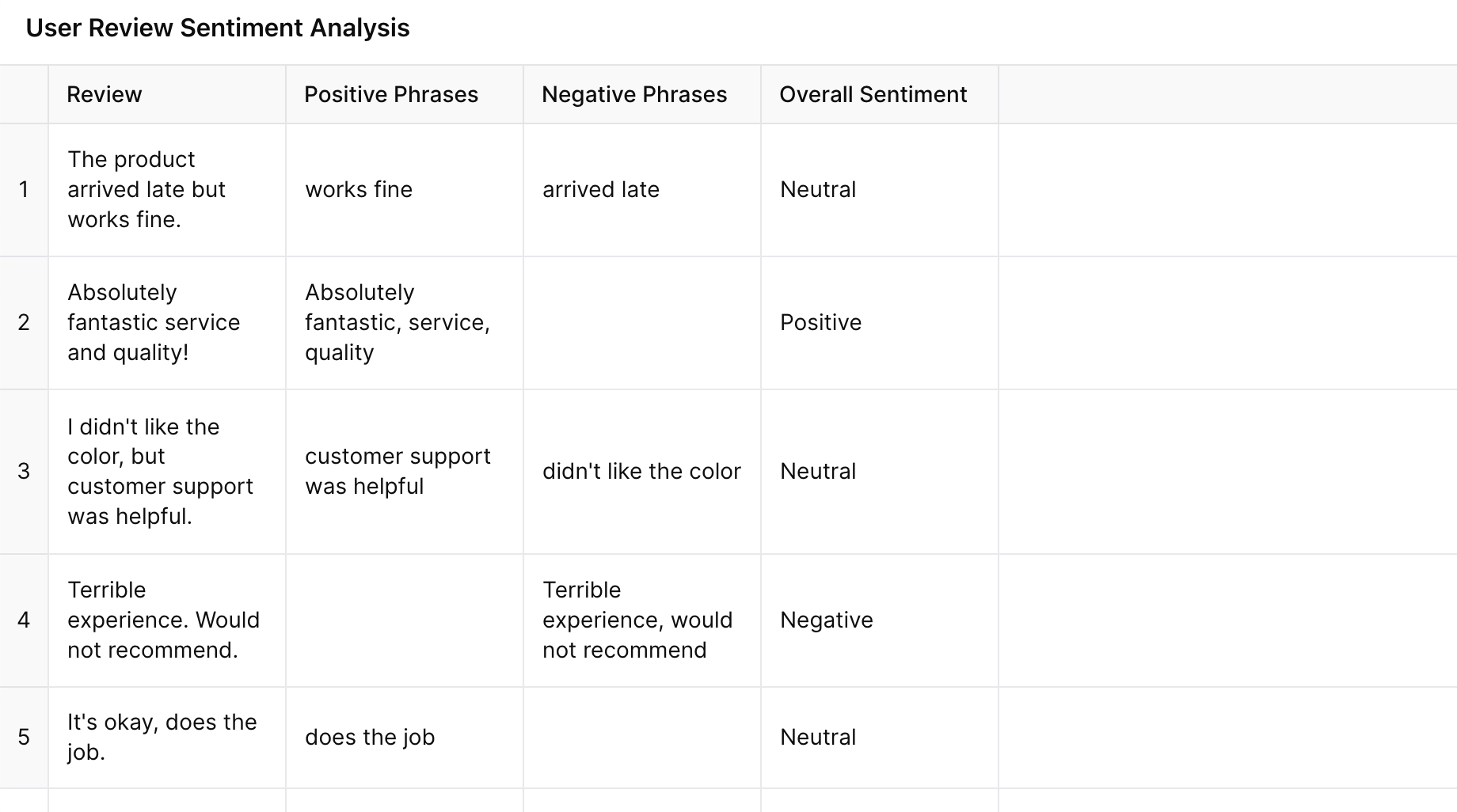{kind=link}
Figura: Preguntar con CoT
**Análisis
El modelo explica su razonamiento identificando frases positivas y negativas en cada reseña, lo que permite al usuario comprender claramente la decisión.
Se genera una tabla en la que no solo se enumera la categoría final, sino que también se muestran las frases de sentimiento clave de cada reseña, lo que hace que el resultado sea más estructurado y transparente.
Variantes de la cadena de pensamiento con ejemplos de sugerencias
A continuación se presentan diferentes tipos de estímulos de la cadena de pensamiento con ejemplos prácticos de estímulos para cada uno de ellos:
1. 1. Estimulación estándar de la cadena de pensamiento
Este tipo de cadena de pensamientos pide al modelo que piense paso a paso en cada parte del problema.
**Ejemplo
Un tren que circula a 100 km/h debe recorrer 180 km. ¿Cuánto tardará en completar el trayecto? Vayamos paso a paso._
Respuesta Modelo Esperada:
"El tren viaja a 100 km/h".
"La distancia a recorrer es de 180 millas".
"Para hallar el tiempo, tenemos que dividir la distancia por la velocidad: 180 ÷ 60 = 3".
"Por lo tanto, tardaremos 3 horas en llegar al destino".
2. Prompting de cadena de pensamiento de pocos disparos
En una CoT de pocos intentos, el modelo recibe algunos ejemplos antes de que se le pida que resuelva un nuevo problema.
Prompt Ejemplo:
He aquí un ejemplo: ¿Cuál es su velocidad si un coche recorre 100 millas en 2 horas? La velocidad es 100 ÷ 2 = 50 millas por hora. He aquí otro ejemplo: Si un avión recorre 600 millas en 3 horas, la velocidad es 600 ÷ 3 = 200 millas por hora. Ahora, siguiendo los mismos pasos, si un ciclista recorre 90 millas en 3 horas, ¿cuál es su velocidad?"_.
Respuesta Modelo Esperada:
"La distancia es de 90 millas y el tiempo es de 3 horas".
"Para hallar la velocidad, dividimos 90 entre 3".
"90 ÷ 3 = 30 millas por hora".
3. Cadena de pensamiento autoconsistente
El modelo genera múltiples vías de razonamiento y elige la respuesta más coherente.
**Ejemplo
Si una persona compra 6 manzanas por 12 ¤, ¿cuánto cuesta cada manzana? Intentemos resolver este problema de diferentes maneras y comparemos las respuestas". Respuesta Modelo Esperada:
Ruta 1:
- "El coste total es de $12, y hay 6 manzanas".
- "$12 ÷ 6 = $2 por manzana". Camino 2:
- "Si 6 manzanas cuestan $12, entonces cada manzana cuesta $2 porque $12 dividido entre 6 es igual a $2". Respuesta final: "Ambos métodos conducen al mismo resultado, por lo que el coste por manzana es $2".
4. Cadena de pensamiento interactiva
El modelo pide aclaraciones o información extra cuando es necesario en esta variante. **Ejemplo Tienes un total de 50 dólares y quieres comprar unos libros. Cada libro cuesta 7 dólares. ¿Cuántos libros puedes comprar y cuánto dinero te sobrará? Por favor, pregunta si necesitas más información antes de resolver". Respuesta Modelo Esperada: 1. "¿Hay impuestos incluidos en el precio del libro, o son sólo $7 por libro?". (Si el usuario confirma que son $7 por libro sin impuestos)$7 por libro sin impuestos)$7 por libro sin impuestos)$7 por libro sin impuestos. 2. "Muy bien, sin impuestos, $50 dividido por $7 da aproximadamente 7 libros. Ya que 7 × 7 es igual a 49". 3. "Te quedará $1 después de comprar 7 libros".
5. Cadena de pensamiento multiagente
En este caso, múltiples agentes de IA trabajan juntos para resolver el problema abordando diferentes partes. **Ejemplo Hay 45 alumnos y 9 profesores que van de viaje. Si en cada autobús caben 15 personas, ¿cuántos autobuses se necesitan? Hagamos que un agente calcule el número total de personas, otro agente calcule la división y un tercero verifique la solución". Respuesta esperada del modelo: Agente 1: "El número total de personas es 45 alumnos + 9 profesores = 54 personas". Agente 2: "Dividimos 54 personas entre 15 por autobús: 54 ÷ 15 = 3,6, lo que significa que necesitamos 4 autobuses". Agente 3: "El número total de personas y el cálculo son correctos". Necesitamos 4 autobuses".
6. Cadena de pensamiento recursiva
El modelo comprueba su propio razonamiento y revisa los pasos si es necesario. Ejemplo: "_Con $120 en la mano, gastas $45 en comestibles, $30 en gasolina y $20 en entretenimiento. ¿Cuánto dinero te queda? Comprueba tus cálculos sobre la marcha". Respuesta esperada del modelo:
- "Empezando con $120".
- "$120 - $45 = $75."
- "$75 - $30 = $45."
- "$45 - $20 = $25."
- "Comprobación: $120 - $45 = $75, luego $75 - $30 = $45, y finalmente $45 - $20 = $25. La respuesta es 25$".
Cuándo utilizar el estímulo de la cadena de pensamiento
El estímulo de la cadena de pensamiento es adecuado para tareas que requieren razonamiento en varios pasos, pensamiento lógico o análisis minucioso. A continuación se describen algunas situaciones en las que puede resultar útil:
**Cuando la tarea implica múltiples operaciones o cálculos, CoT guía al modelo a través de cada paso. Por ejemplo, resolver problemas de palabras o aritmética compleja requiere descomponer la información en trozos más pequeños y manejables antes de realizar los cálculos.
Razonamiento lógico y deducción: CoT es ideal para tareas en las que el modelo necesita analizar la información paso a paso, ya sea tomando una decisión basada en varios factores o resolviendo un rompecabezas que implique pasos lógicos.
**Tareas como cuadrar un presupuesto, seguir una receta o resolver un problema técnico suelen requerir varios pasos. CoT ayuda al modelo a seguir estos pasos en el orden correcto.
Respuesta a preguntas complejas: CoT puede guiar al modelo a través del razonamiento necesario para dar una respuesta más precisa y detallada cuando se le plantean preguntas complejas de ciencia, derecho o filosofía. En lugar de adivinar, analiza los hechos y la lógica necesarios para formar una respuesta sólida.
Mejorar aún más el estímulo de la cadena de pensamiento
Para mejorar aún más la eficacia del indicador, se pueden combinar otras técnicas para gestionar el razonamiento. Por ejemplo:
Proporcionar instrucciones claras y estructuradas: La calidad de las instrucciones influye significativamente en el razonamiento. Las instrucciones deben estar diseñadas para mejorar el CoT y dividir los problemas en pasos lógicos. Cuanto más estructurada y detallada sea la instrucción, mejor seguirá el modelo el proceso de razonamiento.
- Combinar el CoT con el aprendizaje de pocos ejemplos: El aprendizaje de pocos ejemplos, en el que el modelo da algunos ejemplos de razonamiento a través de problemas, puede mejorar el CoT. Mostrando al modelo varios casos similares en los que se utilizó el razonamiento paso a paso, puede entender mejor cómo abordar nuevas tareas.
**Una forma de mejorar la CoT es pedir al modelo que compruebe su propio razonamiento. Después de generar una respuesta, se puede pedir al modelo que revise sus pasos para ver si tienen sentido. Esto ayuda a detectar errores lógicos o lagunas antes de dar la respuesta final.
**La autoconsistencia es un método en el que el modelo genera múltiples rutas de razonamiento y las compara para ver si conducen a la misma conclusión. Si varios caminos coinciden, es más probable que el modelo haya llegado a la respuesta correcta. Por ejemplo, se puede pedir al modelo que resuelva un problema de dos maneras diferentes y seleccionar la respuesta más coherente entre los distintos enfoques.
Limitaciones de la estimulación de la cadena de pensamiento
Aunque el estímulo de la cadena de pensamiento es un método potente para mejorar el razonamiento de la IA, tiene algunas limitaciones que pueden afectar a su eficacia en determinados escenarios.
**1. CoT depende de que el modelo siga un proceso lógico paso a paso. Sin embargo, si el modelo comete un error en un paso, ese error puede trasladarse a la respuesta final.
2. Sobrecarga de tiempo y recursos: CoT requiere más recursos computacionales porque el modelo tiene que pensar en cada paso en lugar de proporcionar una respuesta directa. Esto puede hacer que el proceso sea más lento y requiera más recursos, especialmente en el caso de problemas complejos o de varios pasos. En situaciones en las que la velocidad es una prioridad, CoT puede no ser ideal.
4. Dependencia de instrucciones bien diseñadas: La eficacia de CoT depende en gran medida de la calidad de las instrucciones proporcionadas. Si las instrucciones no son claras o no están bien estructuradas, el modelo puede tener dificultades para razonar el problema. La elaboración de estas instrucciones requiere esfuerzo y experiencia.
5. Generalización limitada a tareas desconocidas: CoT es muy eficaz para tareas que ha visto antes o que se parecen mucho a tareas anteriores. Sin embargo, cuando se le presentan problemas o tareas desconocidas fuera de sus datos de entrenamiento, el modelo puede tener dificultades para aplicar CoT con eficacia, ya que se basa en patrones de razonamiento aprendidos.
**6. Con el tiempo, un modelo entrenado para usar CoT podría volverse demasiado dependiente de instrucciones específicas, limitando la flexibilidad. El modelo Overfitting podría esperar que los problemas se presentaran siempre en un formato determinado, lo que dificultaría su adaptación a tareas nuevas o redactadas de forma diferente.
Casos reales de uso de las instrucciones de cadena de pensamiento
El guiado por la cadena de pensamiento tiene una amplia gama de aplicaciones prácticas en diversos campos. He aquí algunos casos reales en los que CoT puede resultar muy beneficioso:
1. ### 1. Resolución de problemas matemáticos
CoT es extremadamente útil en la educación matemática y en las plataformas de tutoría. Los estudiantes pueden entender el proceso descomponiendo los problemas matemáticos en pasos más pequeños y lógicos, en lugar de limitarse a obtener la respuesta final. También es útil para cálculos avanzados en áreas como álgebra, cálculo y estadística.
2. Razonamiento jurídico y análisis de contratos
En los sistemas jurídicos, el CdT ayuda a los sistemas de IA a evaluar los documentos legales, analizar las cláusulas y generar asesoramiento jurídico repasando sistemáticamente cada punto de un contrato o caso. También puede explicar paso a paso el razonamiento jurídico que hace que la IA sea más transparente y digna de confianza en los procesos jurídicos.
3. Atención al cliente y resolución de problemas
CoT ayuda a los chatbots o sistemas de soporte impulsados por IA a guiar a los usuarios a través de procesos de resolución de problemas paso a paso. Esto es útil para cuestiones técnicas, en las que el usuario debe seguir instrucciones o pasos de diagnóstico para resolver un problema.
4. Diagnóstico médico y apoyo a la toma de decisiones
El CdT puede ayudar a los médicos o profesionales sanitarios a analizar los síntomas, los resultados de las pruebas y el historial médico para sugerir posibles diagnósticos o tratamientos, explicando cómo se llega a cada conclusión.
5. Respuesta a preguntas complejas
CoT es muy eficaz para responder a preguntas complejas que requieren algo más que la simple obtención de un dato. Para preguntas en campos como la historia, la ciencia o el derecho, CoT puede ayudar a los sistemas de IA a proporcionar respuestas detalladas y en varios pasos que expliquen el razonamiento de la respuesta.
6. Estrategia de juego y resolución de puzles
En los juegos, las estrategias se generan considerando múltiples pasos en una secuencia. CoT descompone las estrategias complejas en escenarios de juego o de resolución de puzles en movimientos más pequeños y meditados que permiten tomar mejores decisiones y jugar mejor a juegos como el ajedrez, el Go o los juegos basados en puzles.
¿Cómo puede Milvus aumentar la eficacia de las instrucciones de la cadena de pensamiento?
Milvus, una base de datos vectorial de código abierto desarrollada por Zilliz, está diseñada para almacenar y recuperar de forma eficiente datos no estructurados como imágenes, texto y vídeo. Mientras que Chain-of-Thought se centra en mejorar la capacidad de razonamiento de los modelos de IA, Milvus mejora la forma en que estos modelos gestionan y procesan los datos vectoriales a gran escala.
- **CoT depende de que los modelos de IA tengan acceso a información relevante para el razonamiento paso a paso. Milvus es un backend eficiente, que almacena grandes cantidades de datos vectoriales (como incrustaciones de texto) y proporciona una rápida recuperación. Esto permite a los modelos de IA acceder a los datos que necesitan en cada paso del proceso de razonamiento sin retrasos.
Soporte de aplicaciones a gran escala: En muchos casos del mundo real, los mensajes CoT requieren el manejo de grandes conjuntos de datos para el razonamiento en varios pasos. En muchos casos del mundo real, Milvus permite a los modelos de IA trabajar con grandes conjuntos de datos sin comprometer la velocidad ni el rendimiento.
Búsquedas de similitud optimizadas: Milvus está diseñado para [búsquedas semánticas] (https://zilliz.com/glossary/semantic-search) y [búsquedas de similitud] (https://zilliz.com/learn/vector-similarity-search) rápidas, lo que mejora el CoT al permitir que la IA acceda rápidamente a datos semánticamente relacionados. Esto acelera el proceso de razonamiento, ya que el modelo puede extraer información relevante con mayor precisión y eficacia al resolver problemas de varios pasos.
Conclusión
En resumen, Chain-of-Thought Prompting ayuda a los modelos de IA a abordar problemas complejos dividiéndolos en pasos lógicos, lo que mejora la precisión y la claridad. Milvus mejora este proceso permitiendo un acceso rápido a grandes cantidades de datos no estructurados para que la IA pueda extraer información relevante a medida que avanza en cada paso. CoT y Milvus ofrecen soluciones prácticas para gestionar tareas complejas en campos como la investigación, la atención al cliente y el análisis financiero, haciendo que la IA sea más eficaz y fiable en aplicaciones del mundo real.
Preguntas frecuentes sobre el estímulo de la cadena de pensamiento
**¿Cómo mejora el razonamiento basado en la cadena de pensamiento?
El estímulo de la cadena de pensamiento mejora el razonamiento de la IA guiando al modelo paso a paso a través de los problemas. Este método anima al modelo a dividir las tareas complejas en partes más pequeñas y manejables, reduciendo los errores y mejorando la precisión.
¿Cuándo se debe utilizar el estímulo de cadena de pensamiento?
CoT se utiliza mejor en tareas que requieren un razonamiento de varios pasos, un análisis lógico profundo o la resolución de problemas complejos. Algunos ejemplos son los problemas matemáticos, las deducciones lógicas, la resolución de problemas técnicos y los procesos polifacéticos de toma de decisiones.
- ¿Cuáles son las principales ventajas de la estimulación de la cadena de pensamiento?
Las principales ventajas de CoT son una mayor precisión, un mejor manejo de los problemas complejos, una reducción de los errores, una mayor transparencia del modelo y un enfoque estructurado que hace que el razonamiento de la IA sea más comprensible y fiable.
¿Cómo mejora Milvus la eficacia de la inducción de la cadena de pensamiento?
Milvus mejora el guiado de la cadena de pensamiento almacenando y recuperando eficazmente datos no estructurados a gran escala, como texto e imágenes. Permite a los modelos de IA acceder rápidamente a los datos relevantes en cada etapa del razonamiento para un rendimiento rápido y sin problemas en tareas complejas de varios pasos.
¿En qué se diferencia el estímulo de la cadena de pensamiento de las respuestas tradicionales de la IA?
Las respuestas tradicionales de la IA suelen intentar dar una respuesta directa sin detallar el proceso de razonamiento. En cambio, las preguntas de cadena de pensamiento guían al modelo para que explique su razonamiento paso a paso, ofrecen transparencia y siguen una progresión lógica hacia la solución.
Recursos relacionados
[2201.11903] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Introducción a la ingeniería de instrucciones](https://zilliz.com/glossary/prompt-as-code-(prompt-engineering))
Generación de instrucciones de texto a imagen basadas en LLM con Milvus](https://zilliz.com/blog/llm-powered-text-to-image-prompt-generation-with-milvus)
Prompting en LangChain](https://zilliz.com/blog/prompting-langchain)
Encadenamiento de instrucciones](https://zilliz.com/glossary/prompt-chaining)
Todo lo que necesitas saber sobre el aprendizaje de tiro cero](https://zilliz.com/learn/what-is-zero-shot-learning)
ChatGPT+ Base de datos vectorial + prompt-as-code - La pila CVP](https://zilliz.com/blog/ChatGPT-VectorDB-Prompt-as-code)
Exploración de agentes basados en LLM en la era de la IA](https://zilliz.com/blog/explore-llm-driven-agents-in-age-of-AI)
- ¿Qué es el estímulo en cadena?
- ¿Cómo funciona el estímulo de la cadena de pensamiento?
- Variantes de la cadena de pensamiento con ejemplos de sugerencias
- Cuándo utilizar el estímulo de la cadena de pensamiento
- Mejorar aún más el estímulo de la cadena de pensamiento
- Limitaciones de la estimulación de la cadena de pensamiento
- Casos reales de uso de las instrucciones de cadena de pensamiento
- ¿Cómo puede Milvus aumentar la eficacia de las instrucciones de la cadena de pensamiento?
- Conclusión
- Preguntas frecuentes sobre el estímulo de la cadena de pensamiento
- Recursos relacionados
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis