




¿Qué es una Vector Lakebase?
TL;DR
- Un Vector Lakebase es una arquitectura de datos unificada y nativa del lago para IA que combina serving de nivel de base de datos vectorial con almacenamiento abierto en lago, índices reutilizables a nivel de lago y una capa semántica compartida.
- Permite que los mismos datos no estructurados impulsen el serving en línea (RAG, agentes, búsqueda semántica) y el descubrimiento offline (clustering, deduplicación, re-embedding, gobernanza), sin copiar datos entre sistemas.
- Zilliz Vector Lakebase es una implementación de esta arquitectura: una evolución de Zilliz Cloud desde una base de datos vectorial gestionada hacia una plataforma de datos de IA unificada.
¿Qué es un Vector Lakebase?
Un Vector Lakebase es una arquitectura de datos unificada y nativa del lago para IA. Combina serving de nivel de base de datos vectorial, almacenamiento abierto en lago, índices reutilizables a nivel de lago y una capa semántica compartida, para que los mismos datos no estructurados puedan admitir aplicaciones de IA en línea, descubrimiento interactivo y analítica offline, sin copiarlos entre sistemas. Responde una pregunta diferente a la recuperación por sí sola: ¿qué ocurre cuando los equipos de IA en producción necesitan los mismos datos para recuperación, descubrimiento, analítica, gobernanza, retroalimentación y mejora continua?
Se entiende mejor como una expansión de la base de datos vectorial, no como un reemplazo de ella. La búsqueda vectorial sigue siendo la ruta de serving de baja latencia; un Vector Lakebase sitúa esa ruta dentro de una base más amplia que también puede almacenar, indexar, gobernar y mejorar continuamente los datos a su alrededor.
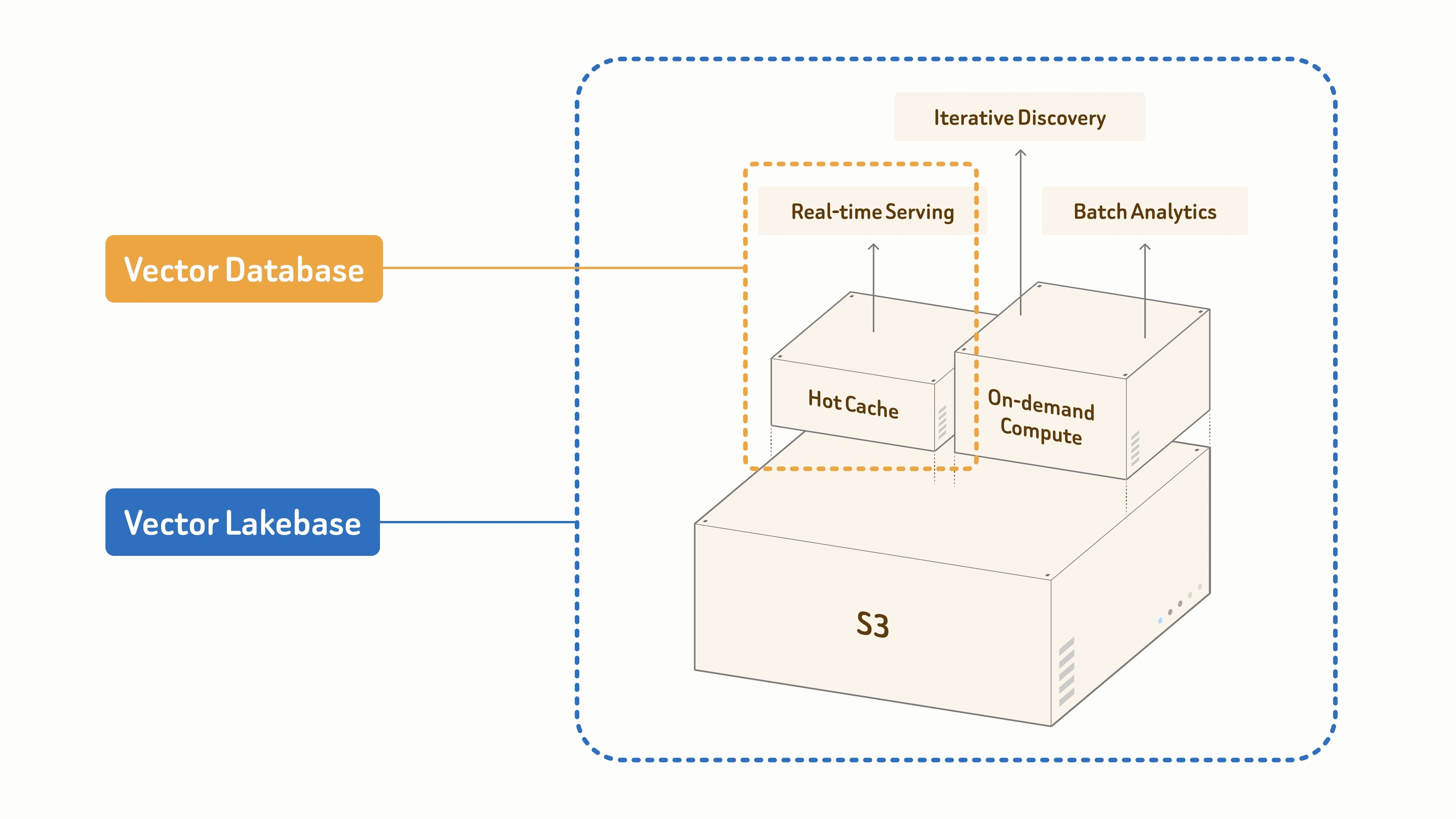
Por qué las cargas de trabajo modernas de IA necesitan un Vector Lakebase
Las bases de datos vectoriales resolvieron el primer problema de datos de la IA moderna: la recuperación semántica rápida a escala, que impulsa RAG, agentes y búsqueda semántica. Ese problema sigue siendo importante, más que nunca, a medida que los sistemas de IA se expanden.
Pero los equipos de IA en producción necesitan cada vez más que la recuperación a partir de los mismos datos: deduplicación y clustering para conjuntos de entrenamiento, detección de anomalías y deriva, re-embedding a medida que cambian los modelos, gobernanza y linaje, y retroalimentación del comportamiento en producción.
La mayoría de los stacks gestionan estos flujos de trabajo como sistemas separados: un lago de datos para archivos sin procesar, una base de datos vectorial para recuperación en línea, pipelines por lotes para preprocesamiento y trabajos separados para embeddings e índices. Los datos se copian entre ellos, los índices se reconstruyen, y el serving en línea y el descubrimiento offline se desincronizan.
Un Vector Lakebase elimina esa fragmentación al proporcionar una única base lógica de datos para serving y descubrimiento. Mantiene la ruta de recuperación de baja latencia para la que están diseñadas las bases de datos vectoriales, pero la conecta con una base nativa del lago donde los datos, vectores, índices, metadatos y contexto semántico pueden almacenarse, gobernarse, versionarse, reutilizarse y mejorarse con el tiempo. El objetivo no es reemplazar la base de datos vectorial con el lago; es integrar la búsqueda vectorial, el contexto semántico y el procesamiento de datos no estructurados en una sola arquitectura. (Para el contexto de la industria y la ingeniería detrás de este cambio, consulta Why We Built Vector Lakebase.)
Principios centrales de diseño de Vector Lakebase: One Data, One Index, One Semantic Layer
Una arquitectura Vector Lakebase se basa en tres principios: One Data, One Index y One Semantic Layer. Describen dónde reside el sistema de registro, cómo se gestionan los índices y cómo se organiza el significado.

One Data: el lago como base de datos compartida
One Data significa que el almacenamiento abierto en lago se convierte en la base compartida para los datos no estructurados de IA. Los archivos sin procesar, los datos limpios, los vectores, los campos escalares, los metadatos, los artefactos de índice, las etiquetas semánticas, el linaje y los resultados del procesamiento offline residen todos dentro de una única base lógica de datos.
En esta arquitectura, la base de datos vectorial no es un nuevo silo de datos. Se convierte en parte de la ruta de servicio de baja latencia. Los datos autorizados siguen siendo nativos del lake, mientras que los sistemas en línea almacenan en caché los datos e índices más activos cuando es necesario. Esto reduce el almacenamiento duplicado, la gobernanza y la migración entre sistemas, y permite que los mismos datos respalden aplicaciones en línea, procesamiento sin conexión, entrenamiento de modelos, evaluación y gobernanza.
Por ejemplo, un documento utilizado en un sistema RAG también puede formar parte de un trabajo de agrupación sin conexión, un flujo de trabajo de exploración de datos de entrenamiento, una revisión de cumplimiento y un futuro proceso de re-embedding. En una arquitectura fragmentada, cada flujo de trabajo crea su propia copia o representación derivada. En un Vector Lakebase, esos flujos de trabajo operan sobre la misma base lógica de datos.
One Index: los índices se convierten en activos a nivel de lake
One Index significa que los índices no quedan bloqueados dentro de un único motor de servicio en línea. Se convierten en activos de datos que pueden crearse, versionarse, reutilizarse y servirse en diferentes modos de cómputo. Esto es importante porque los índices son costosos y operativamente importantes: codifican cómo un sistema recupera y organiza los datos. Si cada flujo de trabajo tiene que construir su propio índice, los equipos desperdician cómputo, crean comportamientos de recuperación inconsistentes y dificultan la gobernanza.
En un Vector Lakebase, un índice lógico puede asignarse a diferentes formas de servicio según el patrón de acceso y el coste. Los índices activos admiten recuperación en línea a nivel de milisegundos; los datos tibios se sirven mediante caché o almacenamiento por niveles; los datos fríos permanecen en el lake para exploración, gobernanza y análisis sin conexión. El mismo linaje de índice puede respaldar el servicio RAG, la búsqueda semántica, la memoria de agentes, la exploración de datos y el procesamiento por lotes, lo que permite a los equipos elegir el perfil adecuado de latencia y coste sin romper el modelo de datos.
One Semantic Layer: el significado se convierte en una capa compartida del sistema
One Semantic Layer significa que el sistema gestiona más que embeddings. Un embedding es solo una representación del activo subyacente. Una base de datos útil para IA también necesita entidades, etiquetas, resúmenes, temas, fragmentos de contexto, información de origen, versiones de modelos, políticas de acceso, linaje y señales de retroalimentación. Esta capa semántica permite a los equipos organizar datos no estructurados por significado, en lugar de solo por ruta de archivo, tabla, bucket o colección.
Un sistema RAG puede recuperar contexto confiable desde la capa semántica. Un agente de IA puede comprender tareas anteriores, memorias y resultados de llamadas a herramientas. Un flujo de trabajo de datos de entrenamiento puede descubrir brechas de cobertura, duplicados, valores atípicos y sesgos. Un sistema de gobernanza puede rastrear una respuesta, característica o muestra hasta los datos de origen y la versión del modelo que la produjo.
La capa semántica también es el centro del volante de datos: las aplicaciones en línea generan consultas, clics, citas, correcciones y retroalimentación; el descubrimiento sin conexión convierte esas señales en mejores metadatos, conjuntos de datos más limpios, índices mejorados y contexto más sólido; y esas mejoras vuelven al servicio. Ese bucle es donde un Vector Lakebase se convierte en algo más que almacenamiento más recuperación.
Cómo funciona Vector Lakebase: el volante CS/CD, en cuatro etapas
Un Vector Lakebase funciona como un bucle continuo entre servicio y descubrimiento; llamamos a esto CS/CD (Continuous Serving and Continuous Discovery). El servicio genera retroalimentación y nuevos datos, el descubrimiento los convierte en datos más limpios y mejores índices, y esas mejoras vuelven al servicio.
Operativamente, el mismo bucle atraviesa cuatro etapas: ingestión de datos, vectorización y enriquecimiento, servicio de consultas y procesamiento sin conexión.
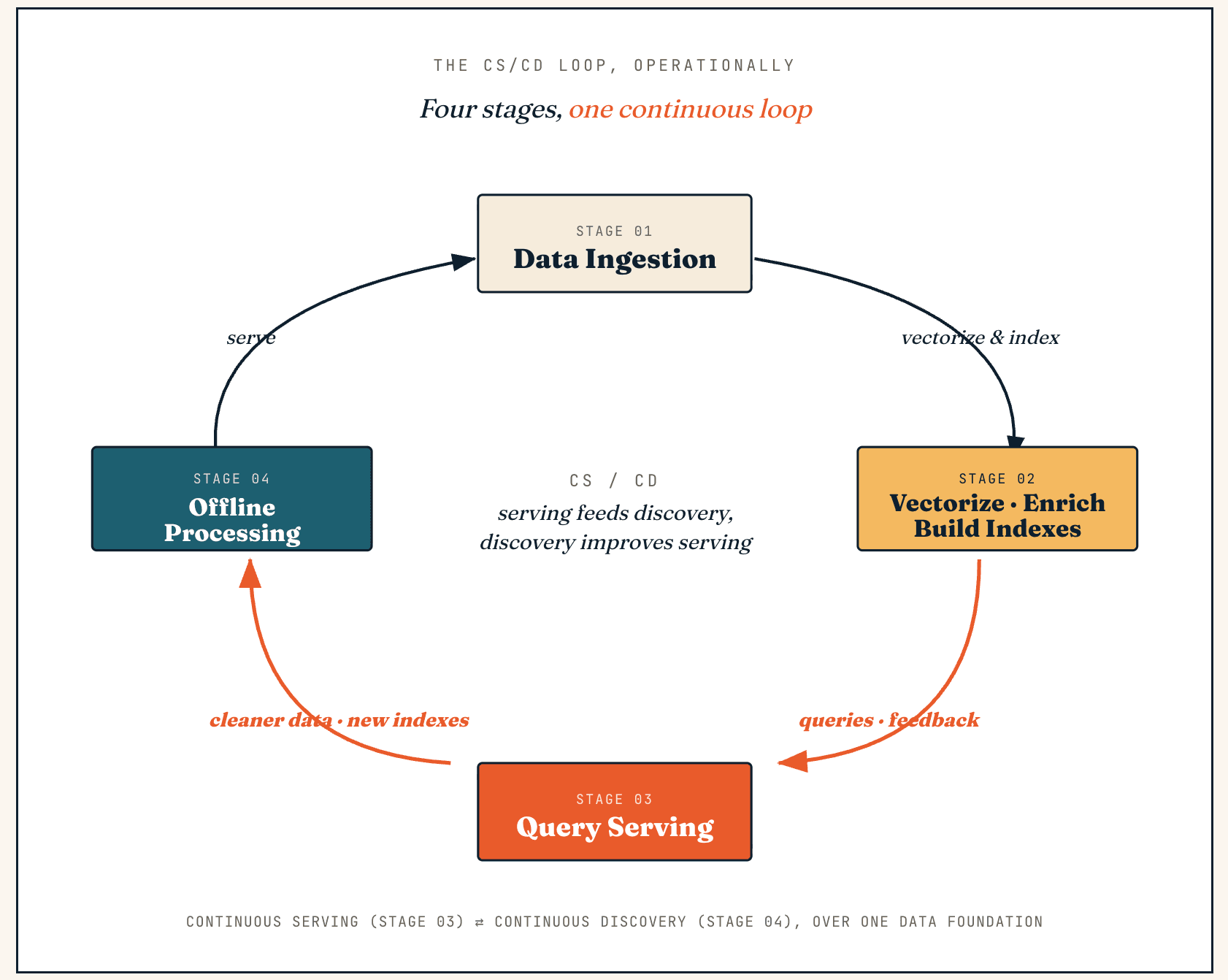
Ingestión de datos
Los datos pueden ingresar al sistema a través de una API de base de datos vectorial, una canalización de documentos, almacenamiento de objetos o un formato open lake existente. Los datos pueden incluir documentos, vectores, campos escalares, metadatos empresariales, imágenes, audio, video, código, registros, conversaciones, tickets de soporte o trazas de agentes.
A medida que crecen los datos no estructurados, la ingesta también debe admitir limpieza, normalización, control de acceso, seguimiento de fuentes y linaje. El sistema necesita saber no solo qué son los datos, sino de dónde provienen, qué modelo los procesó, quién puede acceder a ellos y cómo se pueden usar. Esto es especialmente importante para la IA empresarial. Un sistema RAG o un agente no puede tratar cada fragmento de datos recuperado como igualmente confiable. El contexto necesita conocimiento de la fuente, conocimiento de los permisos, actualidad y, a veces, reglas de gobernanza específicas del negocio.
Vectorización, enriquecimiento y construcción de índices
Después de la ingesta, el sistema genera representaciones vectoriales utilizando modelos de embeddings y trabajos de procesamiento de datos. También enriquece los datos con metadatos — entidades, etiquetas, resúmenes, temas, información de origen, permisos, marcas de tiempo y versiones de modelos. Luego construye estructuras de consulta sobre los datos del lake: índices vectoriales, índices de palabras clave, índices de texto completo, índices JSON, índices escalares y otras estructuras necesarias para la recuperación híbrida.
Arquitectónicamente, este es el punto clave: los índices no están vinculados a ningún motor de serving único. Se pueden versionar, publicar, reutilizar y rastrear hasta la instantánea de datos a partir de la cual se construyeron, lo que convierte la gestión del ciclo de vida de los índices en parte de la base de datos, no en un detalle de implementación oculto dentro de una aplicación.
Serving de consultas
Una Vector Lakebase proporciona rutas de recuperación para RAG, búsqueda agéntica, búsqueda semántica, recuperación multimodal, memoria de IA, recomendación y otras cargas de trabajo de aplicaciones de IA. La ruta de consulta puede usar una base de datos vectorial o una capa de caché para datos calientes que necesitan baja latencia, y acceder a datos e índices nativos del lake para cargas de trabajo más frías o menos frecuentes.
Una consulta puede combinar búsqueda vectorial, búsqueda por palabras clave, búsqueda de texto completo, filtrado de metadatos, predicados escalares, permisos y ranking híbrido, porque la recuperación de IA en producción rara vez se basa solo en la similitud vectorial. Un buen resultado a menudo depende de la relevancia semántica, la actualidad, los derechos de acceso, la calidad de la fuente, los metadatos de negocio y la intención del usuario.
Procesamiento offline
El procesamiento offline incluye clustering, deduplicación, detección de anomalías, análisis de calidad de datos, exploración de datos de entrenamiento, evolución de esquemas, re-embedding, evaluación y reconstrucción de índices. Estos flujos de trabajo se ejecutan sobre grandes lotes de datos y no siempre requieren latencia de milisegundos, pero necesitan acceso a los mismos vectores, metadatos, índices y contexto semántico utilizados por las aplicaciones online.
Su salida se escribe de nuevo en el lake, el sistema de índices y la capa semántica — conjuntos de datos más limpios, mejores etiquetas, fragmentos de contexto mejorados, nuevas versiones de índices o señales de feedback actualizadas — y se publica como una instantánea atómica para que producción nunca lea índices a medio construir. Este es el ciclo operativo central: el serving genera feedback, el descubrimiento mejora los datos y los datos mejorados vuelven al serving.
Tres formas de carga de trabajo para Vector Lakebases
Las cargas de trabajo de datos de IA no tienen una sola forma. Algunas necesitan serving a nivel de milisegundos durante todo el día. Algunas necesitan una búsqueda interactiva para una breve sesión de análisis. Algunas necesitan grandes trabajos de procesamiento offline que se ejecutan, publican resultados y desaparecen. Un único modelo de almacenamiento online siempre activo no puede cubrir eficientemente todos estos casos.
Una base de datos vectorial tradicional está optimizada principalmente para la primera forma de carga de trabajo. Una Vector Lakebase está diseñada para las tres sobre un conjunto de datos lógico único.
En Zilliz Vector Lakebase, estas cargas de trabajo se asignan a tres modos de cómputo — long-running (residente, serving en milisegundos), on-demand (interactivo, facturado por minuto, el puente entre serving y descubrimiento), y offline batch (grandes trabajos que liberan su cómputo al finalizar).
| Tipo de carga de trabajo | Ejemplos típicos | Patrón de cómputo |
|---|---|---|
| Servicio en tiempo real | RAG en producción, memoria de agentes, búsqueda semántica, recomendación, personalización, búsqueda de IA | Clústeres de servicio de larga duración con índices activos, cachés templadas y latencia predecible |
| Descubrimiento interactivo | Análisis de comentarios, inspección de trazas de agentes, búsqueda de anomalías, recuperación de datos fríos, exploración semántica | Cómputo bajo demanda que se inicia cuando se necesita y libera recursos cuando termina la sesión |
| Analítica por lotes | Deduplicación de corpus, agrupamiento, re-incrustación completa, preparación de datos de entrenamiento, reconstrucción de índices | Cómputo por lotes para trabajos grandes que se ejecutan, publican resultados y desaparecen |
Casos de uso comunes de Vector Lakebases
Como una Vector Lakebase unifica el servicio y el descubrimiento sobre una única base, sus casos de uso se dividen en dos grupos.
 图片12
图片12
Casos de uso de recuperación (compartidos con una base de datos vectorial, ahora sobre una base gobernada):
- RAG — documentos, bases de conocimiento, código y registros como contexto consultable, mantenido actualizado, con permisos y reindexable a medida que cambian los modelos.
- Memoria de agentes de IA y uso de herramientas — almacenar y recuperar memoria de agentes, luego analizarla sin conexión y retroalimentar los hallazgos.
- Búsqueda agentica y multimodal — búsqueda vectorial, por palabras clave, de texto completo y de metadatos en texto, imágenes, audio, video y entidades.
- Sistemas de recomendación y más.
Casos de uso del ciclo de vida de los datos (más allá de lo que cubre una base de datos vectorial por sí sola):
- Ingeniería de características y contexto — derivar entidades, resúmenes, temas, etiquetas y clústeres, almacenados junto a los datos de los que provinieron.
- Exploración de datos de entrenamiento — agrupar muestras, encontrar casi duplicados, inspeccionar valores atípicos y rastrear ejemplos hasta su origen.
- Preprocesamiento de datos no estructurados — deduplicación, detección de anomalías, enriquecimiento y filtrado de calidad, escritos de vuelta en el lago.
Cómo se relaciona una Vector Lakebase con las bases de datos vectoriales y las Lakebases
Una Vector Lakebase está relacionada con dos arquitecturas: bases de datos vectoriales y Lakebase. No reemplaza a ninguna de ellas. La tabla siguiente ofrece una vista rápida; las secciones posteriores explican cada relación.
| Base de datos vectorial | Vector Lakebase | Lakebase | |
|---|---|---|---|
| Datos principales | Incrustaciones vectoriales + datos no estructurados asociados | Datos no estructurados y multimodales, además de todo el ciclo de vida a su alrededor | Datos de aplicaciones estructurados / transaccionales |
| Tarea principal | Recuperación semántica de baja latencia | Unificar el servicio en línea y el descubrimiento sin conexión sobre una sola base | Llevar capacidades de base de datos (OLTP) al almacenamiento abierto en lago |
| Índices | Creados y mantenidos dentro del motor de servicio | Activos a nivel de lago: creados, versionados, reutilizados en distintos modos de cómputo | Índices de tabla / SQL |
| Cómputo | Servicio siempre activo | De larga duración + bajo demanda + por lotes sin conexión | Transaccional |
| Almacenamiento de registro | A menudo acoplado al motor | Almacenamiento abierto en lago | Almacenamiento abierto en lago |
| Mejor opción | Búsqueda vectorial rápida para aplicaciones en línea | Servir y mejorar continuamente datos no estructurados a escala | Datos de aplicaciones transaccionales en el lago |
| Relación con vector lakebase | Se convierte en el motor de servicio dentro de una Vector Lakebase | - | La contraparte de datos estructurados de la misma idea nativa del lago |
Vector Lakebase frente a bases de datos vectoriales
Una Vector Lakebase no reemplaza a las bases de datos vectoriales. Si una organización solo necesita búsqueda vectorial de baja latencia para una sola aplicación, una base de datos vectorial puede ser suficiente: sigue siendo el sistema adecuado para la recuperación en producción cuando importan la latencia, la escala, el filtrado y la fiabilidad operativa. Milvus, por ejemplo, está diseñado para este tipo de búsqueda vectorial en producción.
El cálculo cambia cuando una organización necesita reutilizar los mismos datos no estructurados, incrustaciones, índices y contexto semántico en muchos equipos, modelos, aplicaciones y flujos de trabajo de procesamiento.
En ese mundo, la base de datos vectorial no debería ser el único lugar donde viven los datos y los índices; se convierte en el motor de servicio dentro de una arquitectura más amplia de datos no estructurados. Su función se vuelve más específica y más importante: proporciona la ruta de servicio que necesitan las aplicaciones de IA, mientras que Vector Lakebase proporciona la base de datos más amplia alrededor de esa ruta. El resultado no es menos búsqueda vectorial; es búsqueda vectorial conectada al ciclo de vida completo de los datos no estructurados.
Si solo necesito una base de datos vectorial, ¿Vector Lakebase sigue siendo una buena opción?
Ese es un punto de partida perfectamente válido, porque la base de datos vectorial ya forma parte de un Vector Lakebase. Puedes usar la capa de clúster de servicio exactamente como una base de datos vectorial independiente (búsqueda ANN de baja latencia, búsqueda híbrida, filtrado de metadatos, recuperación de texto completo, filtrado JSON, gestión de índices, fiabilidad en producción) y no tocar nunca el descubrimiento interactivo ni la analítica por lotes el primer día. La diferencia es que no quedas atrapado en una arquitectura solo de recuperación: si la carga de trabajo se expande más adelante hacia la búsqueda de datos fríos, la deduplicación a gran escala, la regenaración de embeddings, la preparación de datos de entrenamiento o la gobernanza semántica, la arquitectura más amplia ya está en su lugar: sin reconstrucciones, sin datos duplicados.
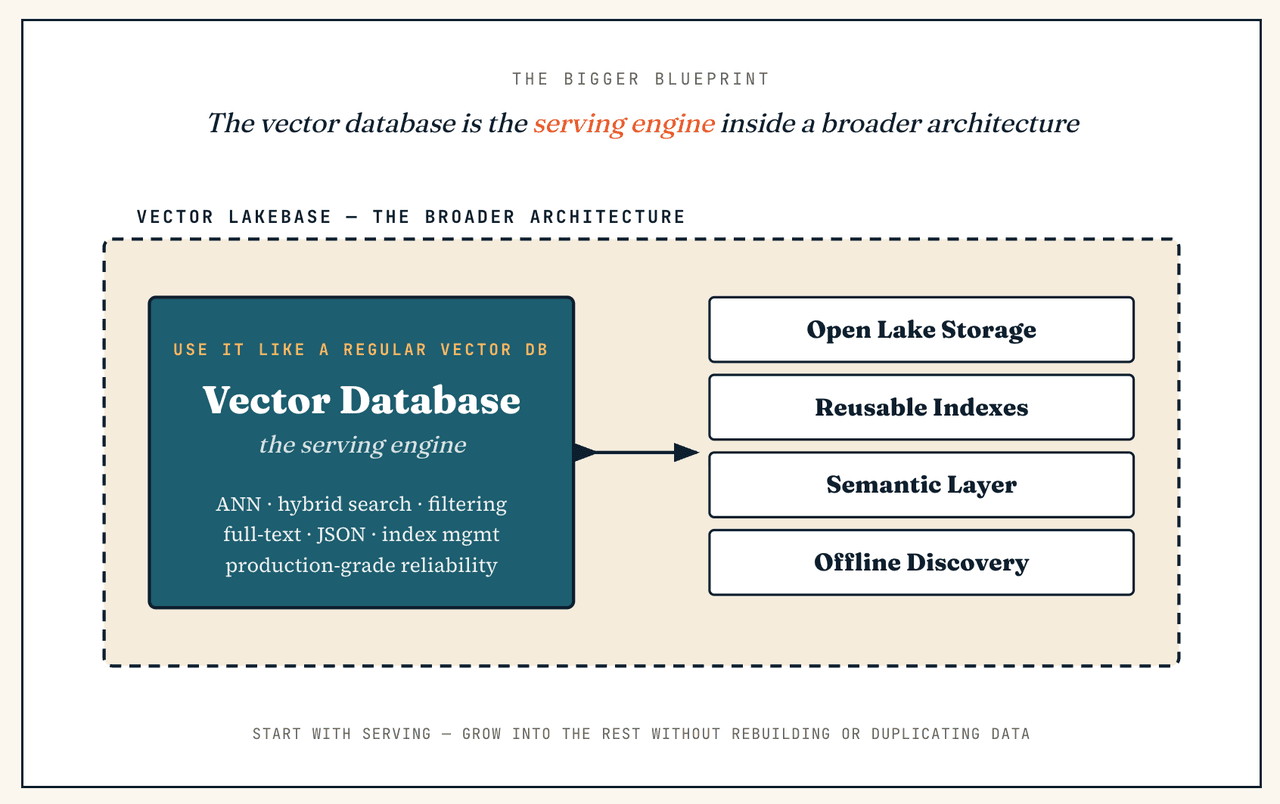
Vector Lakebase vs. Lakebase
Un Vector Lakebase está relacionado con un Lakebase, pero no es simplemente "Lakebase más vectores."

Una arquitectura de estilo Lakebase aporta capacidades similares a las de una base de datos al almacenamiento abierto en lago para datos de aplicaciones estructurados: registros estructurados, transacciones, esquemas, cómputo elástico y gobernanza unificada, consultados mediante campos y relaciones conocidos.
Un Vector Lakebase aborda un centro de gravedad diferente: datos no estructurados y multimodales para IA. El problema no es cómo almacenar el estado de la aplicación en un lago; es cómo gestionar representaciones semánticas, índices vectoriales, metadatos, contexto, feedback y flujos de trabajo de descubrimiento offline sobre datos no estructurados, lo que requiere interpretación semántica, recuperación, refinamiento y feedback en lugar de búsquedas sobre campos conocidos. Se describe mejor no como un reemplazo del Lakebase, sino como la idea de Lakebase extendida a la era de los vectores, los índices y el contexto semántico.
| Dimensión | Lakebase | Vector Lakebase |
|---|---|---|
| Datos primarios | Datos de aplicaciones estructurados, registros transaccionales, estado de la aplicación | Documentos, imágenes, audio, vídeo, logs, código, conversaciones, vectores, metadatos y contexto semántico |
| Abstracciones principales | Tablas, transacciones, esquemas, ramas, clones | Vectores, índices, fragmentos, entidades, etiquetas, resúmenes, permisos, feedback y relaciones semánticas |
| Cargas de trabajo principales | Lecturas y escrituras de aplicaciones, transacciones, analítica en tiempo real | RAG, memoria de agentes, búsqueda agéntica, recuperación multimodal, descubrimiento, ingeniería de contexto, flujos de trabajo de datos de entrenamiento |
| Modelo de consulta | SQL, consultas transaccionales, consultas analíticas | Búsqueda vectorial, búsqueda híbrida, búsqueda de texto completo, filtrado JSON, recuperación multimodal, descubrimiento semántico |
| Modelo semántico | Significado de negocio expresado principalmente mediante el esquema | Significado expresado mediante embeddings, metadatos, entidades, resúmenes, versiones de modelos, linaje y feedback |
| Valor para IA | Aporta capacidades similares a las de una base de datos al almacenamiento abierto en lago | Aporta contexto de IA, indexación vectorial, recuperación semántica y descubrimiento offline a datos no estructurados nativos del lago |
Lo que no es un Vector Lakebase
Como Vector Lakebase es un nuevo patrón de arquitectura, vale la pena dejar claro lo que no es.
- No es solo un lago de datos con embeddings almacenados en una columna. Almacenar embeddings en una tabla de lago conserva los vectores, pero no proporciona nada de la indexación, el serving, los metadatos semánticos, la recuperación híbrida, el bucle de retroalimentación ni la ruta de recuperación de baja latencia que necesitan los sistemas de IA en producción. Los vectores son útiles cuando se pueden buscar, gobernar, versionar, filtrar, conectar con los datos de origen y mejorar con el tiempo, no simplemente almacenar.
- No es solo una base de datos vectorial conectada a almacenamiento de objetos. Poner almacenamiento de objetos detrás de una base de datos vectorial puede reducir el costo de almacenamiento, pero no aborda la reutilización de índices, el descubrimiento offline, la gobernanza, el versionado ni la coherencia entre los datos procesados y los servidos. Lo difícil no es dónde viven los bytes; es cómo los datos, los índices, los metadatos, las señales semánticas y los modos de cómputo funcionan juntos como un único sistema operativo.
- No es un sistema de analítica offline. El descubrimiento offline es solo un lado de la arquitectura. Un Vector Lakebase también sirve tráfico de producción, admite rutas de recuperación activas, gestiona índices, aplica control de acceso y devuelve contexto relevante a aplicaciones y agentes. La cuestión no es elegir entre serving y analítica, sino conectarlos.
- No es un alejamiento de las bases de datos vectoriales. Este puede ser el punto más importante que hemos mencionado repetidamente. Vector Lakebase no hace que las bases de datos vectoriales sean menos relevantes. Les da una arquitectura más amplia en la que operar.
Zilliz Vector Lakebase está disponible en vista previa pública
Hemos lanzado la vista previa pública de Zilliz Vector Lakebase, una evolución importante de Zilliz Cloud de una base de datos vectorial gestionada pura a una plataforma unificada de datos semánticos que combina el serving vectorial de baja latencia con la apertura, escalabilidad y economía de un lago de datos.
Capacidades principales de Zilliz Vector Lakebase:
- Serving por niveles optimizado para diferentes compromisos de rendimiento-costo en tiempo real
- Búsqueda bajo demanda para cargas de trabajo a gran escala o exploratorias sin cómputo siempre activo
- Búsqueda en lago de datos externo: indexa y busca directamente sobre tus datos de lago existentes
- Búsqueda de IA de espectro completo en vectores, texto, JSON y datos geoespaciales con recuperación híbrida y reranking
- Almacenamiento unificado nativo de lago basado en Vortex, un formato abierto con lecturas aleatorias más rápidas y económicas que Lance o Parquet
Si tu stack actual separa el serving y el descubrimiento en sistemas distintos, puede que valga la pena echarle un vistazo a Vector Lakebase. Pruébalo en Zilliz Cloud: los nuevos registros con correo electrónico de trabajo reciben $100 en créditos gratis, o habla con nosotros sobre tu caso de uso.
Más información sobre Vector Lakebases
- De Vector Database a Vector Lakebase
- Pasamos 8 años haciendo que la búsqueda vectorial fuera más rápida. Luego la IA cambió el modelo de cómputo
- Por qué creamos Vector Lakebase: repensar la arquitectura de datos no estructurados para la IA
- Vector Lakebase: pon fin al silo de datos de IA
- Zilliz Cloud On-Demand Compute: paga solo por lo que usas
- La búsqueda vectorial de Notion es excelente. Su próximo problema es más difícil.
Sigue leyendo

How to Choose the Best Embedding Model for RAG in 2026: 10 Models Benchmarked
We benchmarked 10 embedding models on cross-modal, cross-lingual, long-document, and dimension compression tasks. See which one fits your RAG pipeline.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.