




Cómo elegir el mejor modelo de embeddings para RAG en 2026: 10 modelos comparados
TL;DR: Probamos 10 modelos de embeddings en cuatro escenarios de producción que los benchmarks públicos pasan por alto: recuperación cross-modal, recuperación cross-lingual, recuperación de información clave y compresión de dimensiones. Ningún modelo gana en todo. Gemini Embedding 2 es el mejor todoterreno. Qwen3-VL-2B de código abierto supera a las API de código cerrado en tareas cross-modal. Si necesitas comprimir dimensiones para ahorrar almacenamiento, elige Voyage Multimodal 3.5 o Jina Embeddings v4.
Por qué MTEB no es suficiente para elegir un modelo de embeddings
La mayoría de los prototipos de RAG comienzan con text-embedding-3-small de OpenAI. Es barato, fácil de integrar y, para la recuperación de texto en inglés, funciona lo suficientemente bien. Pero el RAG en producción lo supera rápidamente. Tu pipeline empieza a incorporar imágenes, PDF, documentos multilingües, y un modelo de embeddings solo de texto deja de ser suficiente.
El leaderboard de MTEB te dice que hay mejores opciones. ¿El problema? MTEB solo evalúa la recuperación de texto en un único idioma. No cubre la recuperación cross-modal (consultas de texto contra colecciones de imágenes), la búsqueda cross-lingual (una consulta en chino que encuentra un documento en inglés), la precisión en documentos largos ni cuánta calidad pierdes cuando truncas las dimensiones de embeddings para ahorrar almacenamiento en tu base de datos vectorial.
Entonces, ¿qué modelo de embeddings deberías usar? Depende de tus tipos de datos, tus idiomas, la longitud de tus documentos y si necesitas compresión de dimensiones. Creamos un benchmark llamado CCKM y probamos 10 modelos lanzados entre 2025 y 2026 exactamente en esas dimensiones.
¿Qué es el benchmark CCKM?
CCKM (Cross-modal, Cross-lingual, Key information, MRL) evalúa cuatro capacidades que los benchmarks estándar pasan por alto:
| Dimensión | Qué evalúa | Por qué importa |
|---|---|---|
| Recuperación cross-modal | Emparejar descripciones de texto con la imagen correcta cuando hay distractores casi idénticos presentes | Los pipelines de RAG multimodal necesitan embeddings de texto e imagen en el mismo espacio vectorial |
| Recuperación cross-lingual | Encontrar el documento correcto en inglés a partir de una consulta en chino, y viceversa | Las bases de conocimiento en producción suelen ser multilingües |
| Recuperación de información clave | Localizar un dato específico oculto en un documento de 4K–32K caracteres (aguja en un pajar) | Los sistemas RAG procesan con frecuencia documentos largos como contratos y artículos de investigación |
| Compresión de dimensiones MRL | Medir cuánta calidad pierde el modelo cuando truncas embeddings a 256 dimensiones | Menos dimensiones = menor coste de almacenamiento en tu base de datos vectorial, pero ¿a qué coste de calidad? |
MTEB no cubre nada de esto. MMEB añade multimodalidad, pero omite negativos difíciles, por lo que los modelos obtienen puntuaciones altas sin demostrar que manejan distinciones sutiles. CCKM está diseñado para cubrir lo que ellos pasan por alto.
¿Qué modelos de embeddings probamos? Gemini Embedding 2, Jina Embeddings v4 y más
Probamos 10 modelos que cubren tanto servicios API como opciones de código abierto, además de CLIP ViT-L-14 como línea base de 2021.
| Modelo | Fuente | Parámetros | Dimensiones | Modalidad | Rasgo clave |
|---|---|---|---|---|---|
| Gemini Embedding 2 | No divulgado | 3072 | Texto / imagen / video / audio / PDF | Todas las modalidades, cobertura más amplia | |
| Jina Embeddings v4 | Jina AI | 3.8B | 2048 | Texto / imagen / PDF | MRL + adaptadores LoRA |
| Voyage Multimodal 3.5 | Voyage AI (MongoDB) | No divulgado | 1024 | Texto / imagen / video | Equilibrado entre tareas |
| Qwen3-VL-Embedding-2B | Alibaba Qwen | 2B | 2048 | Texto / imagen / video | Código abierto, multimodal ligero |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | Texto / imagen | Arquitectura CLIP modernizada |
| Cohere Embed v4 | Cohere | No divulgado | Fijo | Texto | Recuperación empresarial |
| OpenAI text-embedding-3-large | OpenAI | No divulgado | 3072 | Texto | El más utilizado |
| BGE-M3 | BAAI | 568M | 1024 | Texto | Código abierto, más de 100 idiomas |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | Texto | Ligero, centrado en inglés |
| nomic-embed-text | Nomic AI | 137M | 768 | Texto | Ultraligero |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | Texto / imagen | Línea base |
Recuperación multimodal: ¿qué modelos gestionan la búsqueda de texto a imagen?
Si tu canalización RAG gestiona imágenes junto con texto, el modelo de embeddings necesita ubicar ambas modalidades en el mismo espacio vectorial. Piensa en la búsqueda de imágenes en comercio electrónico, bases de conocimiento mixtas de imagen y texto, o cualquier sistema en el que una consulta de texto necesite encontrar la imagen correcta.
Método
Tomamos 200 pares imagen-texto de COCO val2017. Para cada imagen, GPT-4o-mini generó una descripción detallada. Luego escribimos 3 negativos difíciles por imagen: descripciones que difieren de la correcta en solo uno o dos detalles. El modelo tiene que encontrar la coincidencia correcta en un conjunto de 200 imágenes y 600 distractores.
Un ejemplo del conjunto de datos:
 Maletas vintage de cuero marrón con pegatinas de viaje, incluidas California y Cuba, colocadas sobre un portaequipajes metálico contra un cielo azul — utilizadas como imagen de prueba en el benchmark de recuperación multimodal
Maletas vintage de cuero marrón con pegatinas de viaje, incluidas California y Cuba, colocadas sobre un portaequipajes metálico contra un cielo azul — utilizadas como imagen de prueba en el benchmark de recuperación multimodal
Descripción correcta: "La imagen muestra maletas vintage de cuero marrón con varias pegatinas de viaje, incluidas 'California', 'Cuba' y 'New York', colocadas sobre un portaequipajes metálico contra un cielo azul despejado."
Negativo difícil: La misma frase, pero "California" se convierte en "Florida" y "cielo azul" se convierte en "cielo nublado." El modelo tiene que entender realmente los detalles de la imagen para distinguirlos.
Puntuación:
- Generar embeddings para todas las imágenes y todos los textos (200 descripciones correctas + 600 negativos difíciles).
- Texto a imagen (t2i): Cada descripción busca entre 200 imágenes la coincidencia más cercana. Suma un punto si el resultado principal es correcto.
- Imagen a texto (i2t): Cada imagen busca entre los 800 textos la coincidencia más cercana. Suma un punto solo si el resultado principal es la descripción correcta, no un negativo difícil.
- Puntuación final: hard_avg_R@1 = (precisión t2i + precisión i2t) / 2
Resultados
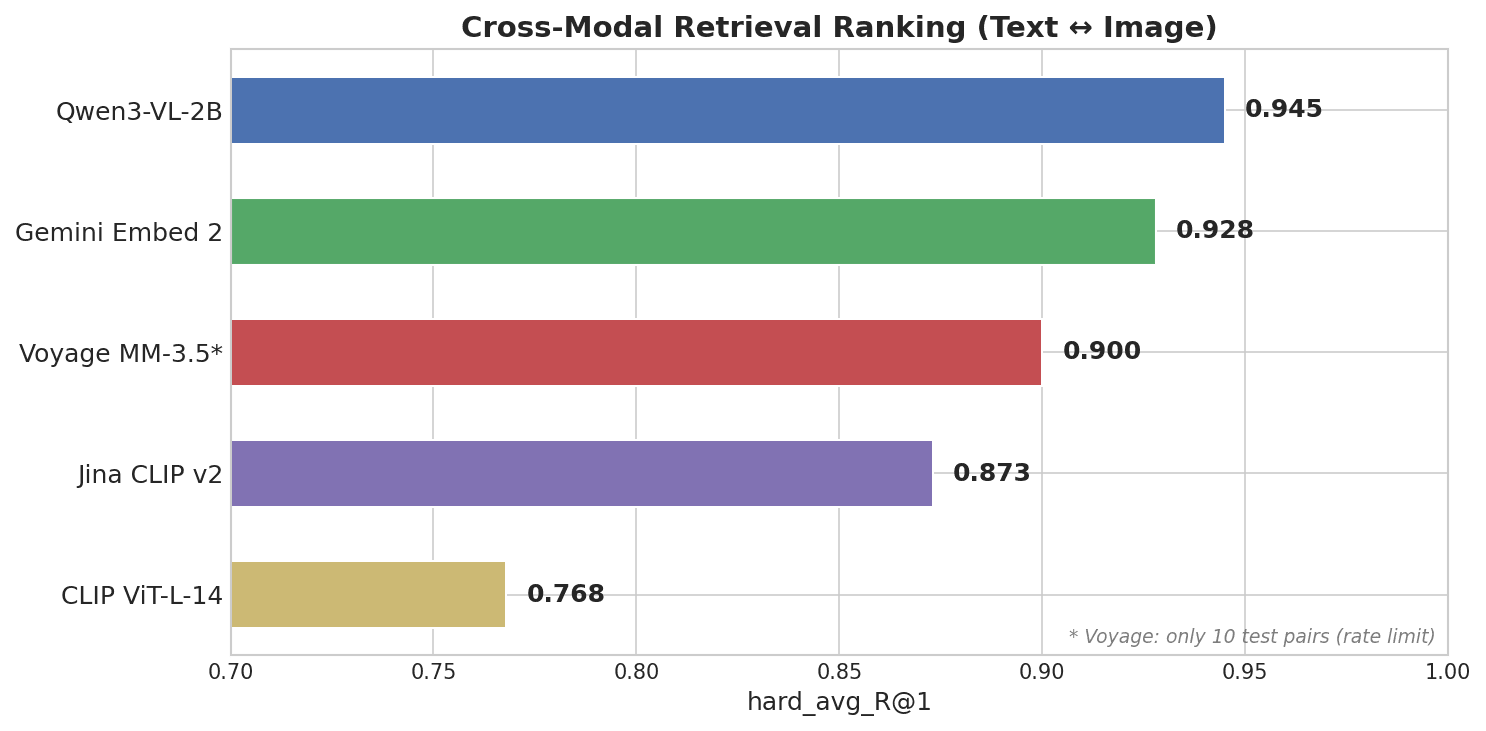 Gráfico de barras horizontal que muestra la clasificación de recuperación multimodal: Qwen3-VL-2B lidera con 0.945, seguido de Gemini Embed 2 con 0.928, Voyage MM-3.5 con 0.900, Jina CLIP v2 con 0.873 y CLIP ViT-L-14 con 0.768
Gráfico de barras horizontal que muestra la clasificación de recuperación multimodal: Qwen3-VL-2B lidera con 0.945, seguido de Gemini Embed 2 con 0.928, Voyage MM-3.5 con 0.900, Jina CLIP v2 con 0.873 y CLIP ViT-L-14 con 0.768
Qwen3-VL-2B, un modelo de código abierto de 2B parámetros del equipo Qwen de Alibaba, quedó en primer lugar, por delante de todas las API de código cerrado.
La brecha de modalidad explica la mayor parte de la diferencia. Los modelos de embeddings mapean texto e imágenes en el mismo espacio vectorial, pero en la práctica las dos modalidades tienden a agruparse en regiones diferentes. La brecha de modalidad mide la distancia L2 entre esos dos grupos. Menor brecha = recuperación multimodal más fácil.
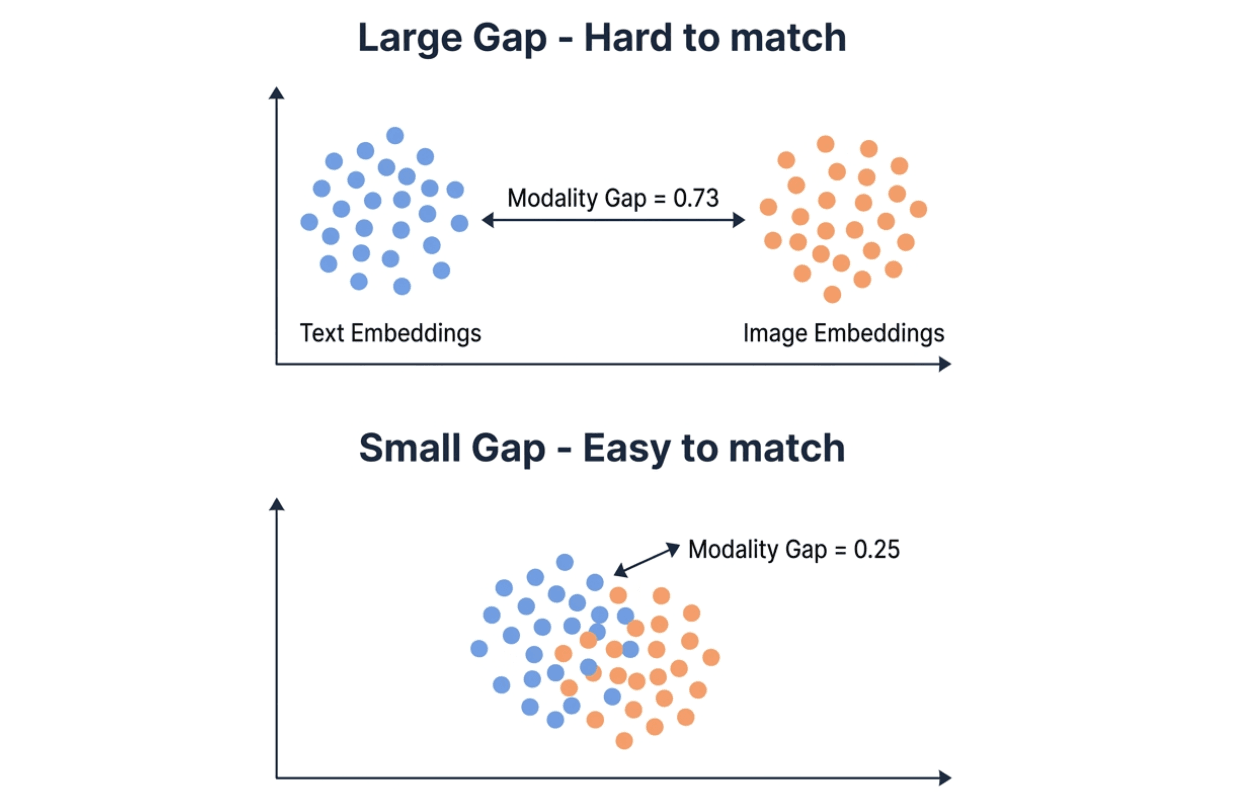 Visualización que compara una gran brecha de modalidad (0.73, clústeres de embeddings de texto e imagen muy separados) frente a una pequeña brecha de modalidad (0.25, clústeres superpuestos) — una brecha menor facilita la coincidencia multimodal
Visualización que compara una gran brecha de modalidad (0.73, clústeres de embeddings de texto e imagen muy separados) frente a una pequeña brecha de modalidad (0.25, clústeres superpuestos) — una brecha menor facilita la coincidencia multimodal
| Modelo | Puntuación (R@1) | Brecha de modalidad | Parámetros |
|---|---|---|---|
| Qwen3-VL-2B | 0.945 | 0.25 | 2B (open-source) |
| Gemini Embedding 2 | 0.928 | 0.73 | Desconocido (cerrado) |
| Voyage Multimodal 3.5 | 0.900 | 0.59 | Desconocido (cerrado) |
| Jina CLIP v2 | 0.873 | 0.87 | ~1B |
| CLIP ViT-L-14 | 0.768 | 0.83 | 428M |
La brecha de modalidad de Qwen es 0.25 — aproximadamente un tercio del 0.73 de Gemini. En una base de datos vectorial como Milvus, una pequeña brecha de modalidad significa que puedes almacenar embeddings de texto e imagen en la misma colección y buscar en ambos directamente. Una brecha grande puede hacer que la búsqueda por similitud multimodal sea menos fiable, y puede que necesites un paso de reordenamiento para compensarlo.
Recuperación interlingüística: ¿Qué modelos alinean el significado entre idiomas?
Las bases de conocimiento multilingües son comunes en producción. Un usuario hace una pregunta en chino, pero la respuesta está en un documento en inglés — o al revés. El modelo de embeddings necesita alinear el significado entre idiomas, no solo dentro de uno.
Método
Construimos 166 pares de oraciones paralelas en chino e inglés en tres niveles de dificultad:
 Niveles de dificultad interlingüística: el nivel fácil mapea traducciones literales como 我爱你 a I love you; el nivel medio mapea oraciones parafraseadas como 这道菜太咸了 a This dish is too salty con negativos difíciles; el nivel difícil mapea modismos chinos como 画蛇添足 a gilding the lily con negativos difíciles semánticamente diferentes
Niveles de dificultad interlingüística: el nivel fácil mapea traducciones literales como 我爱你 a I love you; el nivel medio mapea oraciones parafraseadas como 这道菜太咸了 a This dish is too salty con negativos difíciles; el nivel difícil mapea modismos chinos como 画蛇添足 a gilding the lily con negativos difíciles semánticamente diferentes
Cada idioma también recibe 152 distractores negativos difíciles.
Puntuación:
- Generar embeddings para todo el texto chino (166 correctos + 152 distractores) y todo el texto inglés (166 correctos + 152 distractores).
- Chino → Inglés: Cada oración china busca entre 318 textos en inglés su traducción correcta.
- Inglés → Chino: Lo mismo a la inversa.
- Puntuación final: hard_avg_R@1 = (precisión zh→en + precisión en→zh) / 2
Resultados
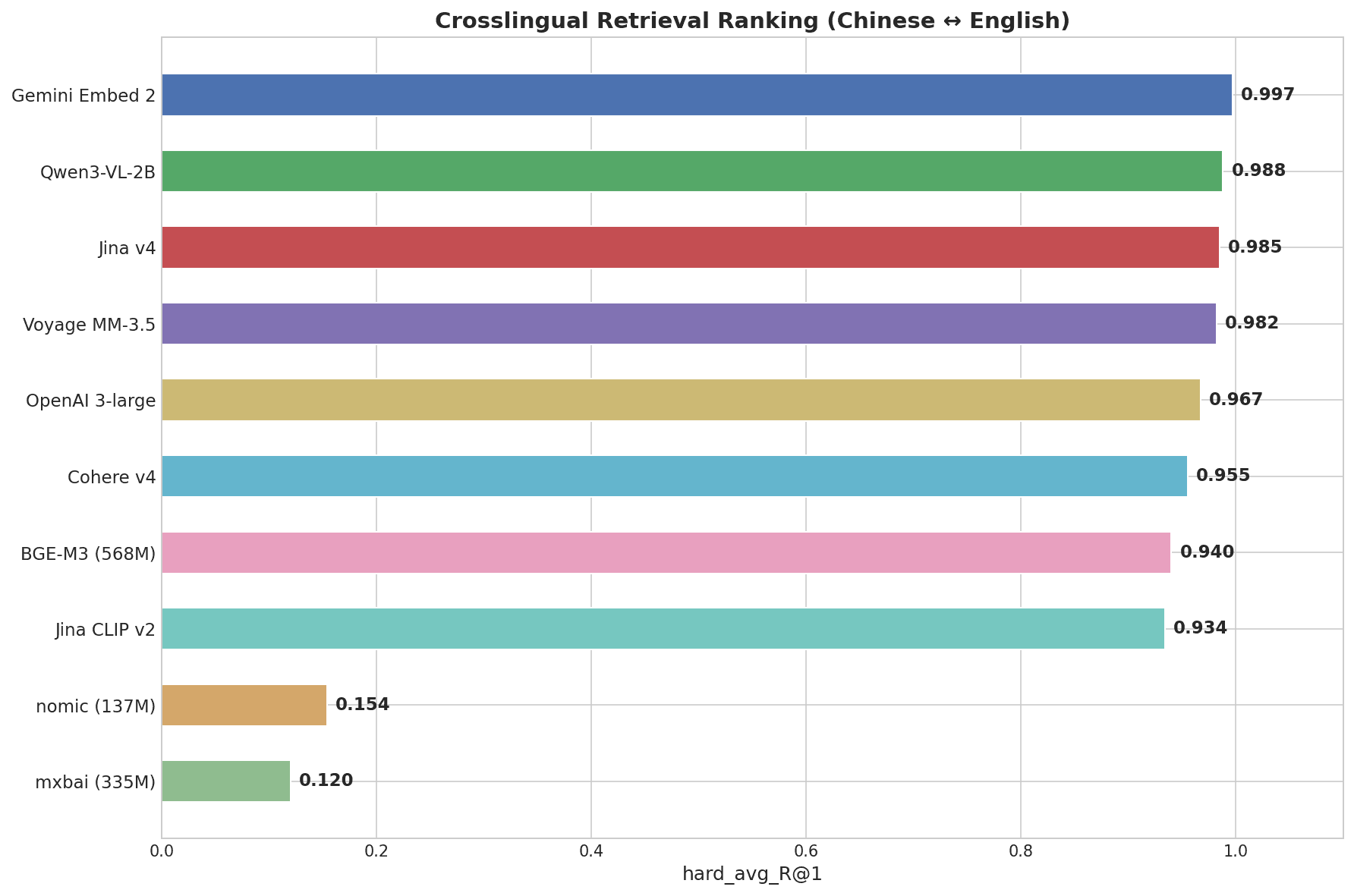 Gráfico de barras horizontal que muestra el ranking de recuperación interlingüística: Gemini Embed 2 lidera con 0.997, seguido por Qwen3-VL-2B con 0.988, Jina v4 con 0.985, Voyage MM-3.5 con 0.982, hasta mxbai con 0.120
Gráfico de barras horizontal que muestra el ranking de recuperación interlingüística: Gemini Embed 2 lidera con 0.997, seguido por Qwen3-VL-2B con 0.988, Jina v4 con 0.985, Voyage MM-3.5 con 0.982, hasta mxbai con 0.120
Gemini Embedding 2 obtuvo 0.997 — la puntuación más alta de todos los modelos probados. Fue el único modelo en obtener un 1.000 perfecto en el nivel difícil, donde pares como "画蛇添足" → "gilding the lily" requieren una comprensión semántica genuina entre idiomas, no coincidencia de patrones.
| Modelo | Puntuación (R@1) | Fácil | Medio | Difícil (modismos) |
|---|---|---|---|---|
| Gemini Embedding 2 | 0.997 | 1.000 | 1.000 | 1.000 |
| Qwen3-VL-2B | 0.988 | 1.000 | 1.000 | 0.969 |
| Jina Embeddings v4 | 0.985 | 1.000 | 1.000 | 0.969 |
| Voyage Multimodal 3.5 | 0.982 | 1.000 | 1.000 | 0.938 |
| OpenAI 3-large | 0.967 | 1.000 | 1.000 | 0.906 |
| Cohere Embed v4 | 0.955 | 1.000 | 0.980 | 0.875 |
| BGE-M3 (568M) | 0.940 | 1.000 | 0.960 | 0.844 |
| nomic-embed-text (137M) | 0.154 | 0.300 | 0.120 | 0.031 |
| mxbai-embed-large (335M) | 0.120 | 0.220 | 0.080 | 0.031 |
Los 7 mejores modelos superan todos el 0.93 en la puntuación general — la verdadera diferenciación ocurre en el nivel difícil (modismos chinos). nomic-embed-text y mxbai-embed-large, ambos modelos ligeros centrados en inglés, obtienen puntuaciones cercanas a cero en tareas interlingüísticas.
Recuperación de información clave: ¿Pueden los modelos encontrar una aguja en un documento de 32K tokens?
Los sistemas RAG suelen procesar documentos extensos: contratos legales, artículos de investigación, informes internos que contienen datos no estructurados. La pregunta es si un modelo de embeddings todavía puede encontrar un hecho específico enterrado entre miles de caracteres de texto circundante.
Método
Tomamos artículos de Wikipedia de distintas longitudes (de 4K a 32K caracteres) como el pajar e insertamos un único hecho fabricado — la aguja — en diferentes posiciones: inicio, 25%, 50%, 75% y final. El modelo debe determinar, basándose en un embedding de consulta, qué versión del documento contiene la aguja.
Ejemplo:
- Aguja: "The Meridian Corporation reported quarterly revenue of $847.3 million in Q3 2025."
- Consulta: "What was Meridian Corporation's quarterly revenue?"
- Pajar: Un artículo de Wikipedia de 32.000 caracteres sobre la fotosíntesis, con la aguja oculta en algún lugar dentro.
Puntuación:
- Generar embeddings para la consulta, el documento con la aguja y el documento sin ella.
- Si la consulta es más similar al documento que contiene la aguja, contarlo como un acierto.
- Promediar la precisión en todas las longitudes de documento y posiciones de la aguja.
- Métricas finales: overall_accuracy y degradation_rate (cuánto cae la precisión del documento más corto al más largo).
Resultados
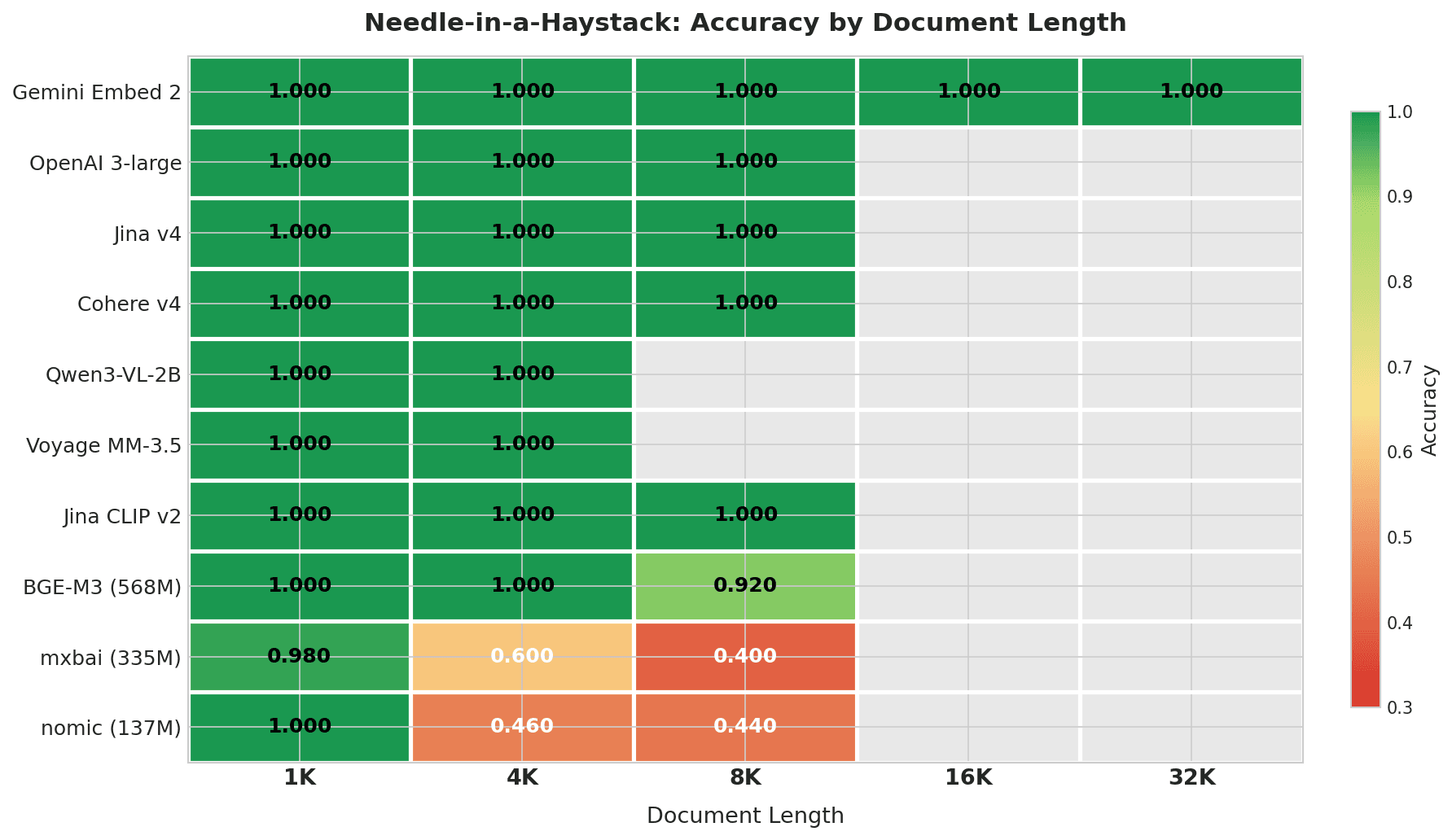 Mapa de calor que muestra la precisión de Needle-in-a-Haystack por longitud de documento: Gemini Embed 2 obtiene 1.000 en todas las longitudes hasta 32K; los 7 modelos principales puntúan perfectamente dentro de sus ventanas de contexto; mxbai y nomic se degradan bruscamente a partir de 4K
Mapa de calor que muestra la precisión de Needle-in-a-Haystack por longitud de documento: Gemini Embed 2 obtiene 1.000 en todas las longitudes hasta 32K; los 7 modelos principales puntúan perfectamente dentro de sus ventanas de contexto; mxbai y nomic se degradan bruscamente a partir de 4K
Gemini Embedding 2 es el único modelo probado en todo el rango de 4K–32K, y obtuvo una puntuación perfecta en cada longitud. Ningún otro modelo en esta prueba tiene una ventana de contexto que alcance 32K.
| Modelo | 1K | 4K | 8K | 16K | 32K | General | Degradación |
|---|---|---|---|---|---|---|---|
| Gemini Embedding 2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0% |
| OpenAI 3-large | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Jina Embeddings v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Cohere Embed v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Qwen3-VL-2B | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Voyage Multimodal 3.5 | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Jina CLIP v2 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| BGE-M3 (568M) | 1.000 | 1.000 | 0.920 | — | — | 0.973 | 8% |
| mxbai-embed-large (335M) | 0.980 | 0.600 | 0.400 | — | — | 0.660 | 58% |
| nomic-embed-text (137M) | 1.000 | 0.460 | 0.440 | — | — | 0.633 | 56% |
"—" significa que la longitud del documento supera la ventana de contexto del modelo.
Los 7 modelos principales puntúan perfectamente dentro de sus ventanas de contexto. BGE-M3 empieza a fallar a 8K (0.920). Los modelos ligeros (mxbai y nomic) caen a 0.4–0.6 con solo 4K caracteres, aproximadamente 1.000 tokens. En el caso de mxbai, esta caída refleja en parte que su ventana de contexto de 512 tokens trunca la mayor parte del documento.
Compresión de dimensiones MRL: ¿Cuánta calidad se pierde con 256 dimensiones?
Matryoshka Representation Learning (MRL) es una técnica de entrenamiento que hace que las primeras N dimensiones de un vector sean significativas por sí solas. Toma un vector de 3072 dimensiones, trúncalo a 256, y aún conserva la mayor parte de su calidad semántica. Menos dimensiones significan menores costes de almacenamiento y memoria en tu base de datos vectorial: pasar de 3072 a 256 dimensiones supone una reducción de almacenamiento de 12x.
 Ilustración que muestra el truncamiento de dimensiones MRL: 3072 dimensiones con calidad completa, 1024 al 95%, 512 al 90%, 256 al 85%, con ahorros de almacenamiento de 12x a 256 dimensiones
Ilustración que muestra el truncamiento de dimensiones MRL: 3072 dimensiones con calidad completa, 1024 al 95%, 512 al 90%, 256 al 85%, con ahorros de almacenamiento de 12x a 256 dimensiones
Método
Usamos 150 pares de oraciones del benchmark STS-B, cada uno con una puntuación de similitud anotada por humanos (0–5). Para cada modelo, generamos embeddings a dimensiones completas y luego los truncamos a 1024, 512 y 256.
 Ejemplos de datos STS-B que muestran pares de oraciones con puntuaciones de similitud humana: A girl is styling her hair frente a A girl is brushing her hair puntúa 2.5; A group of men play soccer on the beach frente a A group of boys are playing soccer on the beach puntúa 3.6
Ejemplos de datos STS-B que muestran pares de oraciones con puntuaciones de similitud humana: A girl is styling her hair frente a A girl is brushing her hair puntúa 2.5; A group of men play soccer on the beach frente a A group of boys are playing soccer on the beach puntúa 3.6
Puntuación:
- En cada nivel de dimensión, calcula la similitud coseno entre los embeddings de cada par de oraciones.
- Compara la clasificación de similitud del modelo con la clasificación humana usando ρ de Spearman (correlación de rangos).
¿Qué es ρ de Spearman? Mide qué tan bien coinciden dos clasificaciones. Si los humanos clasifican el par A como el más similar, B en segundo lugar, C como el menos similar — y las similitudes coseno del modelo producen el mismo orden A > B > C — entonces ρ se acerca a 1.0. Un ρ de 1.0 significa concordancia perfecta. Un ρ de 0 significa que no hay correlación.
Métricas finales: spearman_rho (cuanto más alto, mejor) y min_viable_dim (la dimensión más pequeña donde la calidad se mantiene dentro del 5% del rendimiento de dimensión completa).
Resultados
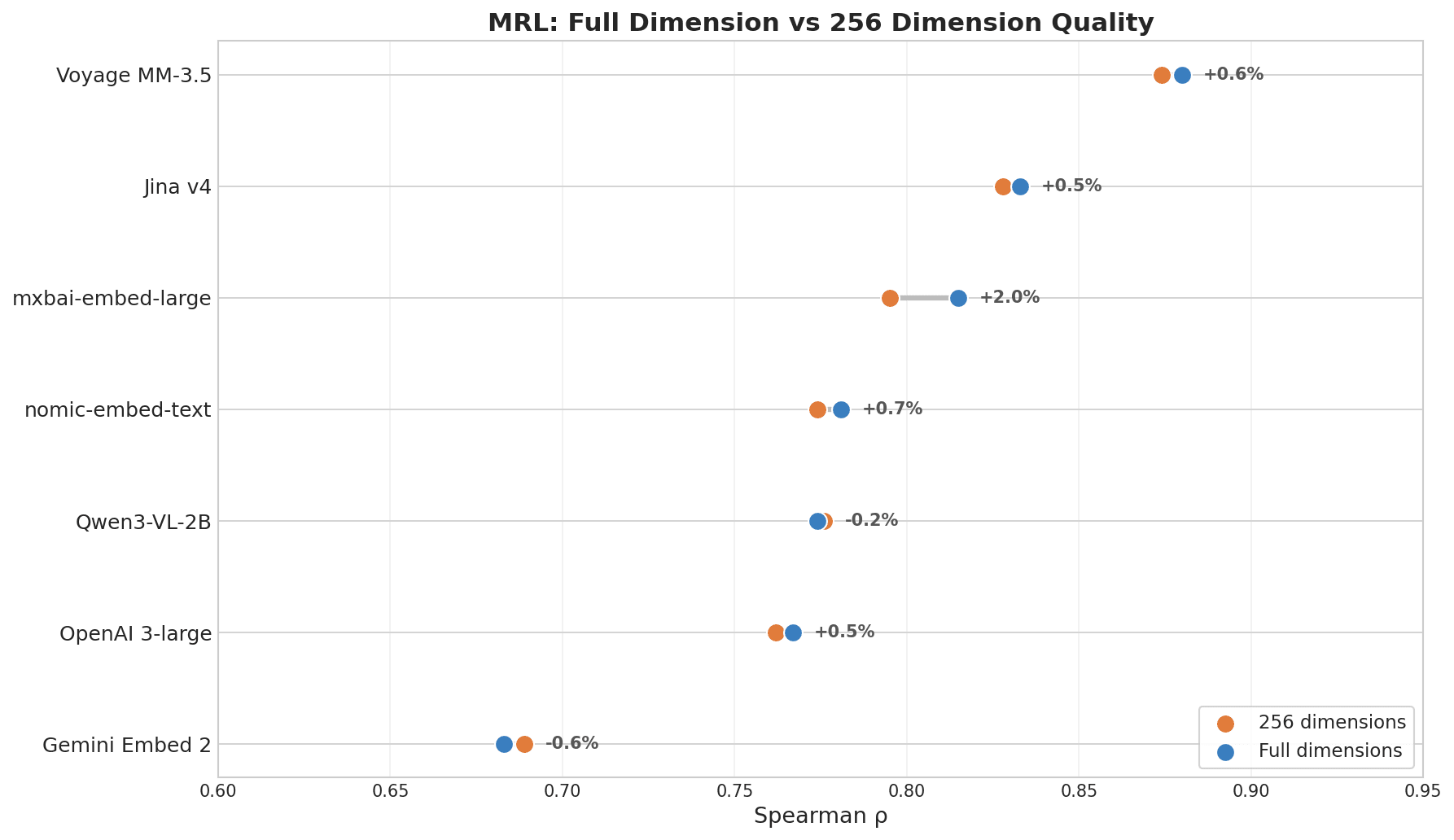 Gráfico de puntos que muestra MRL Full Dimension frente a 256 Dimension Quality: Voyage MM-3.5 lidera con un cambio de +0.6%, Jina v4 +0.5%, mientras que Gemini Embed 2 muestra -0.6% en la parte inferior
Gráfico de puntos que muestra MRL Full Dimension frente a 256 Dimension Quality: Voyage MM-3.5 lidera con un cambio de +0.6%, Jina v4 +0.5%, mientras que Gemini Embed 2 muestra -0.6% en la parte inferior
Si estás planeando reducir los costos de almacenamiento en Milvus u otra base de datos vectorial truncando dimensiones, este resultado importa.
| Modelo | ρ (dim completa) | ρ (256 dim) | Decaimiento |
|---|---|---|---|
| Voyage Multimodal 3.5 | 0.880 | 0.874 | 0.7% |
| Jina Embeddings v4 | 0.833 | 0.828 | 0.6% |
| mxbai-embed-large (335M) | 0.815 | 0.795 | 2.5% |
| nomic-embed-text (137M) | 0.781 | 0.774 | 0.8% |
| OpenAI 3-large | 0.767 | 0.762 | 0.6% |
| Gemini Embedding 2 | 0.683 | 0.689 | -0.8% |
Voyage y Jina v4 lideran porque ambos fueron entrenados explícitamente con MRL como objetivo. La compresión de dimensiones tiene poco que ver con el tamaño del modelo: si el modelo fue entrenado para ello es lo que importa.
Una nota sobre la puntuación de Gemini: la clasificación MRL refleja qué tan bien un modelo preserva la calidad después del truncamiento, no qué tan buena es su recuperación en dimensión completa. La recuperación en dimensión completa de Gemini es sólida: los resultados multilingües y de información clave ya lo demostraron. Simplemente no fue optimizado para reducirse. Si no necesitas compresión de dimensiones, esta métrica no aplica para ti.
¿Qué modelo de embedding deberías usar?
Ningún modelo gana en todo. Aquí está la tabla de puntuación completa:
| Modelo | Parámetros | Multimodal | Multilingüe | Info clave | ρ MRL |
|---|---|---|---|---|---|
| Gemini Embedding 2 | No divulgado | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage Multimodal 3.5 | No divulgado | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina Embeddings v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| OpenAI 3-large | No divulgado | — | 0.967 | 1.000 | 0.760 |
| Cohere Embed v4 | No divulgado | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
"—" significa que el modelo no admite esa modalidad o capacidad. CLIP es una línea base de 2021 como referencia.
Esto es lo que destaca:
- Multimodal: Qwen3-VL-2B (0.945) primero, Gemini (0.928) segundo, Voyage (0.900) tercero. Un modelo open-source de 2B superó a todas las API de código cerrado. El factor decisivo fue la brecha de modalidad, no el número de parámetros.
- Multilingüe: Gemini (0.997) lidera — el único modelo en lograr una puntuación perfecta en alineación a nivel de modismos. Los 8 modelos principales superan 0.93. Los modelos ligeros solo en inglés puntúan cerca de cero.
- Información clave: Las API y los grandes modelos open-source puntúan perfectamente hasta 8K. Los modelos por debajo de 335M empiezan a degradarse en 4K. Gemini es el único modelo que maneja 32K con una puntuación perfecta.
- Compresión de dimensiones MRL: Voyage (0.880) y Jina v4 (0.833) lideran, perdiendo menos del 1% a 256 dimensiones. Gemini (0.668) queda en último lugar — fuerte en dimensión completa, no optimizado para truncamiento.
Cómo elegir: Un diagrama de flujo de decisión
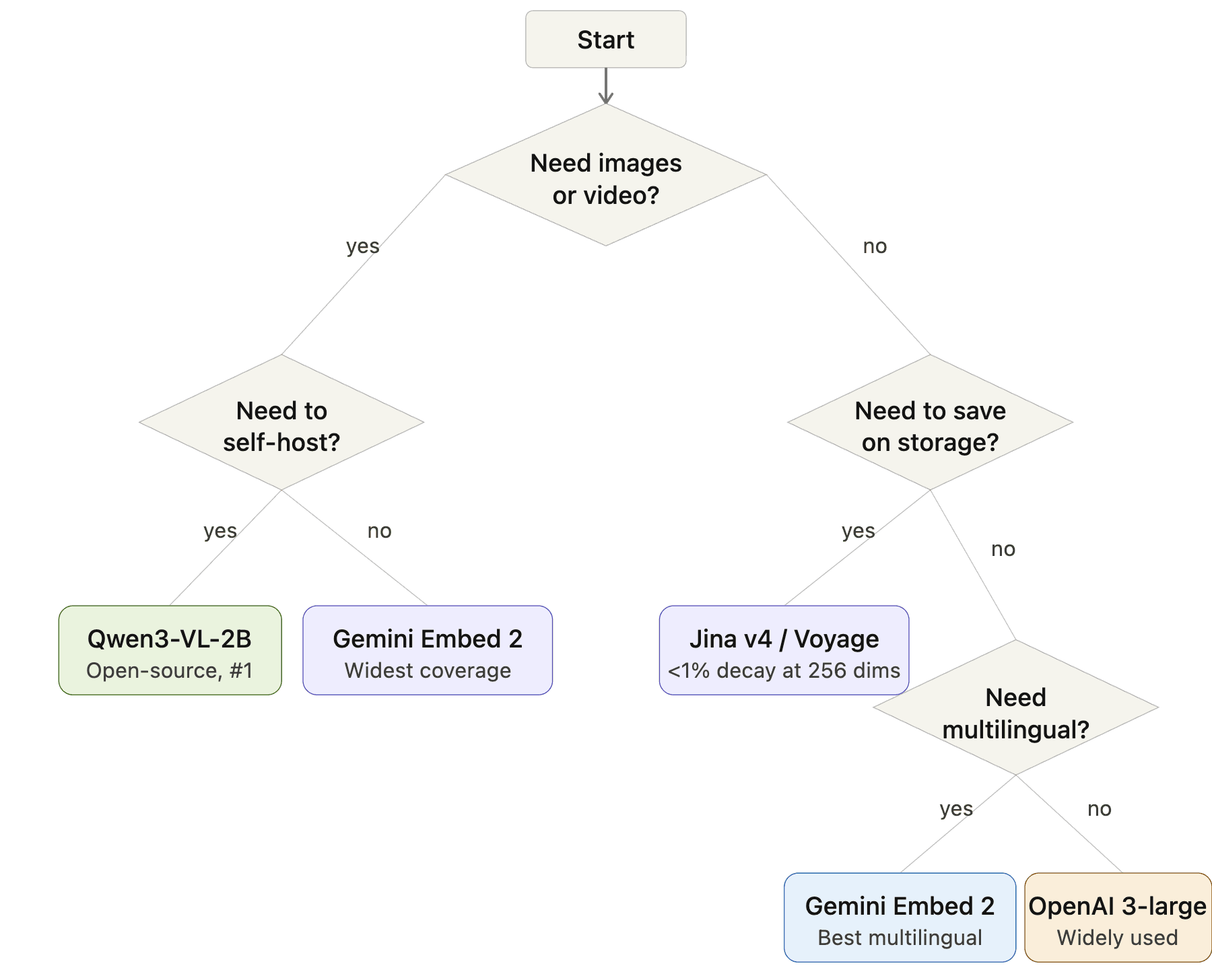 Diagrama de flujo para la selección de modelos de embedding: Inicio → ¿Necesitas imágenes o video? → Sí: ¿Necesitas autoalojarlo? → Sí: Qwen3-VL-2B, No: Gemini Embedding 2. Sin imágenes → ¿Necesitas ahorrar almacenamiento? → Sí: Jina v4 o Voyage, No: ¿Necesitas multilingüe? → Sí: Gemini Embedding 2, No: OpenAI 3-large
Diagrama de flujo para la selección de modelos de embedding: Inicio → ¿Necesitas imágenes o video? → Sí: ¿Necesitas autoalojarlo? → Sí: Qwen3-VL-2B, No: Gemini Embedding 2. Sin imágenes → ¿Necesitas ahorrar almacenamiento? → Sí: Jina v4 o Voyage, No: ¿Necesitas multilingüe? → Sí: Gemini Embedding 2, No: OpenAI 3-large
El mejor todoterreno: Gemini Embedding 2
En conjunto, Gemini Embedding 2 es el modelo más sólido en general en este benchmark.
Fortalezas: Primero en multilingüe (0.997) y recuperación de información clave (1.000 en todas las longitudes hasta 32K). Segundo en multimodal (0.928). La cobertura de modalidades más amplia — cinco modalidades (texto, imagen, video, audio, PDF), mientras que la mayoría de los modelos llegan como máximo a tres.
Debilidades: Último en compresión MRL (ρ = 0.668). Superado en multimodal por el open-source Qwen3-VL-2B.
Si no necesitas compresión de dimensiones, Gemini no tiene un competidor real en la combinación de recuperación multilingüe + documentos largos. Pero para precisión multimodal u optimización de almacenamiento, los modelos especializados funcionan mejor.
Limitaciones
- No incluimos todos los modelos que vale la pena considerar — NV-Embed-v2 de NVIDIA y v5-text de Jina estaban en la lista, pero no entraron en esta ronda.
- Nos centramos en modalidades de texto e imagen; embeddings de video, audio y PDF (a pesar de que algunos modelos afirman soportarlos) no fueron cubiertos.
- La recuperación de código y otros escenarios específicos de dominio quedaron fuera del alcance.
- Los tamaños de muestra fueron relativamente pequeños, por lo que las diferencias estrechas en la clasificación entre modelos pueden caer dentro del ruido estadístico.
Los resultados de este artículo quedarán obsoletos en un año. Nuevos modelos se lanzan constantemente, y la tabla de clasificación se reordena con cada lanzamiento. La inversión más duradera es construir tu propio pipeline de evaluación — define tus tipos de datos, tus patrones de consulta, las longitudes de tus documentos, y somete los nuevos modelos a tus propias pruebas cuando aparezcan. Vale la pena monitorear benchmarks públicos como MTEB, MMTEB y MMEB, pero la decisión final siempre debería venir de tus propios datos.
Nuestro código de benchmark es open-source en GitHub — haz un fork y adáptalo a tu caso de uso.
Una vez que hayas elegido tu modelo de embedding, necesitas un lugar donde almacenar y buscar esos vectores a escala. Milvus es la base de datos vectorial open-source más adoptada del mundo, con 43K+ estrellas en GitHub, creada exactamente para esto — soporta dimensiones truncadas con MRL, colecciones multimodales mixtas, búsqueda híbrida que combina vectores densos y dispersos, y escala desde un portátil hasta miles de millones de vectores.
- Comienza con la guía de inicio rápido de Milvus, o instala con
pip install pymilvus. - Únete al Slack de Milvus o al Discord de Milvus para hacer preguntas sobre la integración de modelos de embeddings, estrategias de indexación vectorial o escalado en producción.
- Reserva una sesión gratuita de Milvus Office Hours para revisar tu arquitectura RAG: podemos ayudarte con la selección de modelos, el diseño del esquema de colecciones y la optimización del rendimiento.
- Si prefieres evitar el trabajo de infraestructura, Zilliz Cloud (Milvus gestionado) ofrece un nivel gratuito para empezar.
Algunas preguntas que surgen cuando los ingenieros eligen un modelo de embeddings para RAG en producción:
P: ¿Debería usar un modelo de embeddings multimodal aunque ahora mismo solo tenga datos de texto?
Depende de tu hoja de ruta. Si es probable que tu pipeline añada imágenes, PDFs u otras modalidades en los próximos 6–12 meses, empezar con un modelo multimodal como Gemini Embedding 2 o Voyage Multimodal 3.5 evita una migración dolorosa más adelante: no tendrás que volver a generar embeddings para todo tu conjunto de datos. Si tienes claro que será solo texto en el futuro previsible, un modelo centrado en texto como OpenAI 3-large o Cohere Embed v4 te dará una mejor relación precio/rendimiento.
P: ¿Cuánto almacenamiento ahorra realmente la compresión de dimensiones MRL en una base de datos vectorial?
Pasar de 3072 dimensiones a 256 dimensiones supone una reducción de 12x en el almacenamiento por vector. Para una colección de Milvus con 100 millones de vectores en float32, eso equivale aproximadamente a 1.14 TB → 95 GB. La clave es que no todos los modelos manejan bien el truncamiento: Voyage Multimodal 3.5 y Jina Embeddings v4 pierden menos del 1% de calidad a 256 dimensiones, mientras que otros se degradan significativamente.
P: ¿Es Qwen3-VL-2B realmente mejor que Gemini Embedding 2 para la búsqueda cross-modal?
En nuestro benchmark, sí: Qwen3-VL-2B obtuvo 0.945 frente a los 0.928 de Gemini en recuperación cross-modal difícil con distractores casi idénticos. La razón principal es la brecha de modalidad mucho menor de Qwen (0.25 frente a 0.73), lo que significa que los embeddings de texto e imagen se agrupan más cerca en el espacio vectorial. Dicho esto, Gemini cubre cinco modalidades mientras que Qwen cubre tres, así que si necesitas embeddings de audio o PDF, Gemini es la única opción.
P: ¿Puedo usar estos modelos de embeddings directamente con Milvus?
Sí. Todos estos modelos generan vectores float estándar, que puedes insertar en Milvus y buscar con similitud coseno, distancia L2 o producto interno. PyMilvus funciona con cualquier modelo de embeddings: genera tus vectores con el SDK del modelo y luego almacénalos y búscalos en Milvus. Para vectores truncados con MRL, simplemente configura la dimensión de la colección en tu objetivo (p. ej., 256) al crear la colección.

Sigue leyendo

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.