




Retos de infraestructura en la ampliación de GAR con modelos de IA personalizados
Los sistemas de Generación Aumentada de Recuperación (RAG) han mejorado significativamente las aplicaciones de IA al proporcionar respuestas más precisas y contextualmente relevantes. Sin embargo, la ampliación y el despliegue de estos sistemas en producción han planteado retos considerables a medida que se vuelven más sofisticados e incorporan modelos de IA personalizados.
Durante un reciente Unstructured Data Meetup organizado por Zilliz, Chaoyu Yang, fundador y CEO de BentoML, compartió su visión sobre los obstáculos de infraestructura a la hora de escalar sistemas RAG con modelos de IA personalizados y destacó cómo herramientas como BentoML podrían simplificar el despliegue y la gestión de estos componentes. Este post recapitulará los puntos clave de Chaoyu Yang y explorará patrones avanzados de inferencia y técnicas de optimización. Estas estrategias le ayudarán a construir sistemas RAG que no sólo son potentes, sino también eficientes y rentables.
Vea la repetición de la charla de Chaoyu en Youtube
Cómo RAG potencia las aplicaciones de IA
Los sistemas RAG (Retrieval Augmented Generation) han surgido para abordar el problema de las alucinaciones en las aplicaciones GenAI. Al integrar las capacidades de recuperación de similitud vectorial de bases de datos vectoriales como Milvus y Zilliz Cloud con el poder generativo de grandes modelos lingüísticos (LLMs), los sistemas RAG permiten a los modelos de IA producir respuestas que son:
Más precisas
Contextualmente relevantes
Increíblemente informativo
Sin alucinaciones
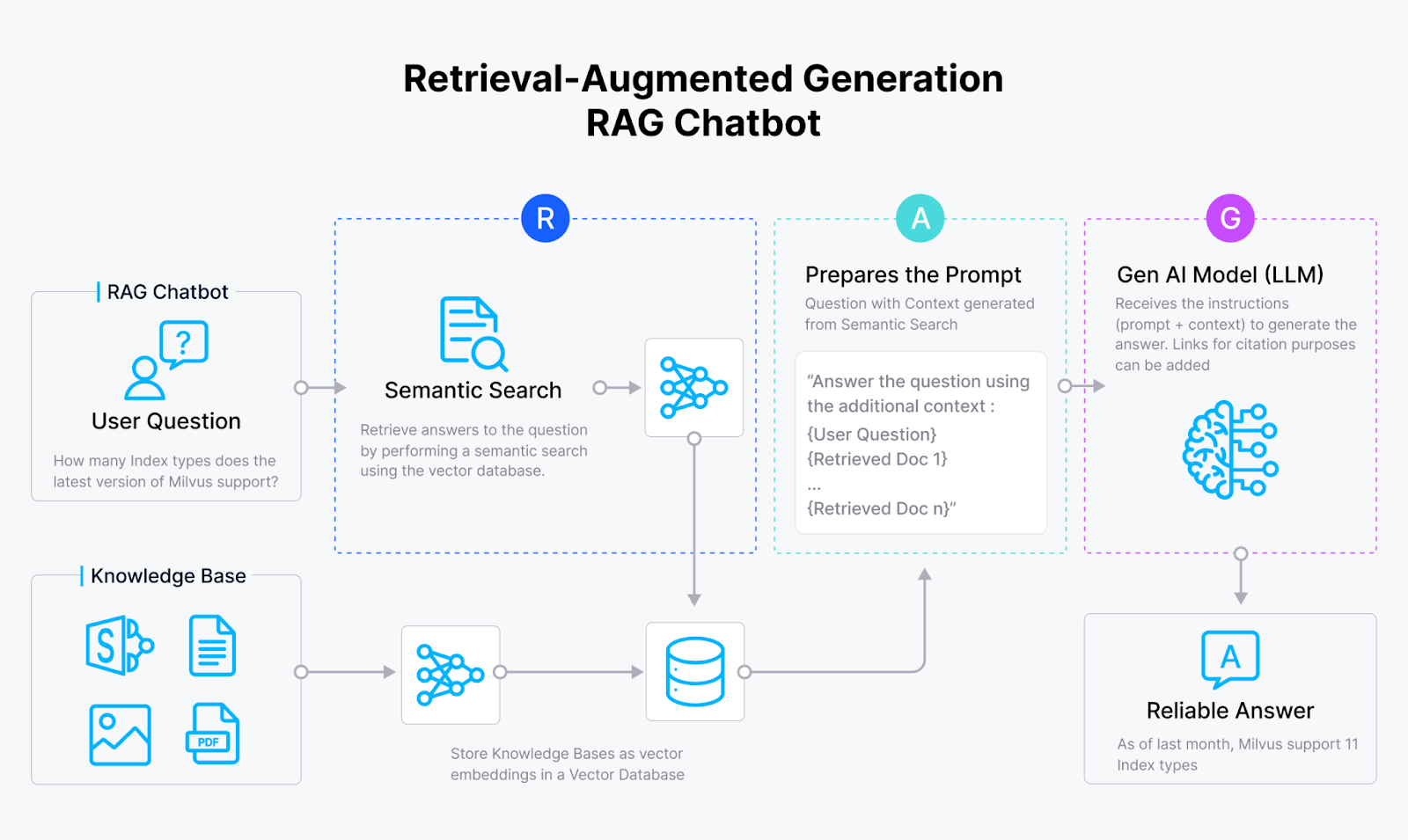
Cómo funciona un chatbot RAG_
Estos sistemas tienen el potencial de transformar una amplia gama de dominios, entre ellos:
Respuesta a preguntas
Resumen de documentos
Generación de contenidos personalizados
Y mucho más.
Los sistemas RAG logran este objetivo aprovechando el vasto conocimiento oculto en fuentes externas, ¡como un bibliotecario de IA!
Desafíos en el despliegue de sistemas GAR en producción
Los sistemas RAG tienen sus propios retos que superar antes de que puedan salvar el día en entornos de producción. Uno de los mayores obstáculos es garantizar un rendimiento de recuperación de primera categoría, lo que implica:
Optimizar la recuperación:** Asegurarse de que se recupera toda la información relevante.
Optimizar la precisión: minimizar la cantidad de información irrelevante.
Para hacer las cosas más interesantes, los sistemas RAG a menudo tienen que tratar con fuentes de datos complejas y no estructuradas. Imagínese un PDF con más diseños, tablas e imágenes que un cómic. Este problema requiere técnicas muy sofisticadas de tratamiento y comprensión de documentos.
Otro reto al que se enfrentan los sistemas GAR es generar respuestas precisas, contextualmente apropiadas y alineadas con la intención del usuario. Es como escribir una historia coherente utilizando sólo fragmentos de diferentes libros.
Además, también es crucial garantizar la seguridad y fiabilidad del contenido generado, sobre todo cuando hay mucho en juego. No queremos que nuestros sistemas de inteligencia artificial se vuelvan locos y difundan información errónea.
Los modelos personalizados de inteligencia artificial son el compañero de confianza en esta historia. Al ajustar y adaptar los modelos de IA a dominios y conjuntos de datos específicos, los desarrolladores pueden dotar a sus sistemas RAG de los superpoderes que necesitan para hacer frente a estos retos.
Aprovechamiento de los modelos de IA personalizados para un mayor rendimiento de la GAR
Para liberar todo el potencial de los sistemas RAG, es crucial aprovechar los modelos de IA personalizados adaptados a nuestro caso de uso específico. Afinando y optimizando estos modelos, podemos aumentar significativamente su rendimiento. Exploremos algunas áreas clave en las que los modelos de IA personalizados pueden tener un impacto significativo.
Modelos de incrustación de texto: La base del éxito de RAG
Los modelos de incrustación de texto predeterminados, como "text-embedding-ada-002", a menudo se quedan cortos a la hora de captar los matices de nuestro dominio específico. Este modelo ocupa el puesto 57 en la tabla de clasificación de MTEB, lo que indica que hay mucho margen de mejora.
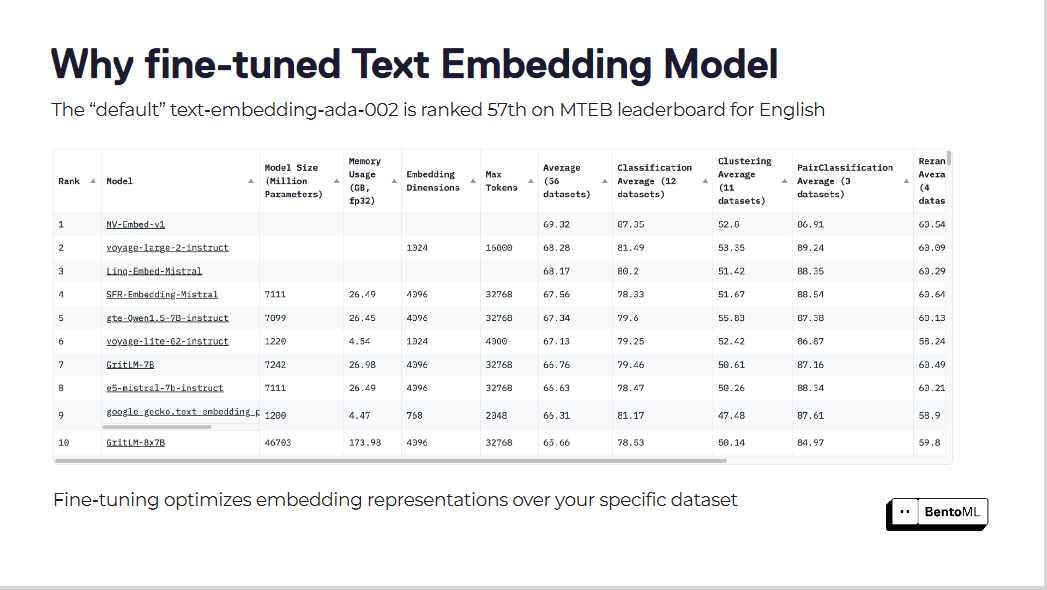
El ajuste fino optimiza las representaciones de incrustación en su conjunto de datos específico
El ajuste fino de estos modelos de incrustación puede dar lugar a notables mejoras en las puntuaciones de recuperación. Gracias a la optimización de los modelos de incrustación para sus conjuntos de datos específicos, los sistemas RAG han obtenido mejoras sustanciales en el rendimiento.
Hosting Our LLMs: Tomar el control
Los LLM propietarios ofrecen comodidad, pero no siempre se ajustan a nuestras necesidades o limitaciones. Los LLM de código abierto nos permiten personalizar y adaptar los modelos a nuestras necesidades. A la hora de alojar nuestros LLM, debemos tener en cuenta los siguientes factores clave:
Seguridad y privacidad de los datos
Latencia y rendimiento
Capacidades específicas necesarias
Coste y escalabilidad
Mantenimiento y asistencia
Procesamiento y comprensión de documentos: Extracción de información de datos no estructurados
Los sistemas GAR a menudo necesitan procesar y comprender documentos complejos y no estructurados, como PDF, imágenes, etc. La integración de varios modelos y técnicas puede ayudar a extraer información valiosa. Por ejemplo, podemos llevar a cabo:
Análisis del diseño con LayoutLM
Detección de tablas con Table Transformers TATR
OCR con EasyOCR o Tesseract
Control de calidad visual de documentos con LayoutLM v3 o Donut
El ajuste de estos modelos a sus tipos de documentos específicos puede mejorar enormemente su rendimiento.
Técnicas avanzadas para mejorar la precisión de la recuperación
Para mejorar aún más la precisión de la recuperación, podemos considerar la aplicación de las siguientes técnicas:
Context-aware chunking y global concept-aware chunking: Estos métodos ayudan a identificar la información más relevante para la recuperación teniendo en cuenta el contexto y los conceptos generales de los documentos.
Extracción de metadatos:** La extracción de metadatos de los documentos puede proporcionar un contexto adicional para mejorar la recuperación y la síntesis de respuestas.
Modelos de reclasificación: el perfeccionamiento de los modelos de reclasificación en conjuntos de datos personalizados puede mejorar el rendimiento entre un 10 y un 30% con respecto a los modelos genéricos.
Al aprovechar los modelos de IA personalizados en estas áreas clave, podemos mejorar significativamente el rendimiento de nuestro sistema RAG.
Sin embargo, desplegar y servir estos modelos de forma eficiente conlleva sus propios retos. En la siguiente sección, discutiremos algunos desafíos de infraestructura para escalar RAG con modelos personalizados.
Desafíos de infraestructura en el escalamiento de RAG con modelos personalizados
A medida que los sistemas RAG se vuelven más complejos e incorporan múltiples modelos personalizados, las demandas de recursos computacionales y la necesidad de un despliegue y una gestión eficientes aumentan significativamente. El escalado de los sistemas de Generación Aumentada de Recuperación (RAG) con modelos de IA personalizados se convierte en un requisito urgente, pero conlleva un conjunto único de retos de infraestructura.
Servicio eficiente de API de inferencia de modelos personalizados
Uno de los principales retos es el servicio eficiente de API de inferencia de modelos personalizados. Los sistemas RAG a menudo requieren la integración de múltiples modelos, como:
Modelos de incrustación de texto
Grandes modelos lingüísticos (LLM)
Modelos de tratamiento de documentos
Cada modelo puede tener diferentes requisitos computacionales y características de rendimiento. Desplegar estos modelos como API de inferencia que puedan gestionar solicitudes en tiempo real y escalar con la demanda es complejo.
Para hacer frente a este reto, es esencial contar con una infraestructura robusta y escalable para servir APIs de inferencia de modelos. Esta infraestructura debe ser capaz de gestionar los requisitos específicos de cada modelo, como la asignación de GPU, la gestión de memoria y las restricciones de latencia. Las tecnologías de contenedores como Docker pueden ayudar a encapsular las dependencias de los modelos y proporcionar un entorno de ejecución coherente en diferentes sistemas.
Mecanismos de escalado eficientes
Sin embargo, no basta con contenerizar los modelos. La infraestructura también debe soportar mecanismos de escalado eficientes para manejar cargas de trabajo variables. Este requisito incluye el escalado automático del número de instancias del modelo en función del tráfico de solicitudes entrantes, garantizando una utilización óptima de los recursos y minimizando los tiempos de respuesta.
Optimización del servicio de modelos
Otro reto fundamental es optimizar el servicio de modelos en términos de rendimiento y rentabilidad. Los modelos de IA personalizados, especialmente los modelos lingüísticos de gran tamaño, pueden ser costosos desde el punto de vista computacional. Las estrategias de despliegue ingenuas pueden conducir a una utilización de recursos subóptima y a un aumento de los costes. Técnicas como el procesamiento dinámico por lotes, en el que se agrupan varias solicitudes para aprovechar el paralelismo de las GPU, pueden mejorar significativamente el rendimiento y reducir los tiempos de respuesta.
Además de la dosificación dinámica, pueden aplicarse otras técnicas de optimización, como la cuantización, la poda y la destilación de modelos, para reducir la huella de memoria y los requisitos computacionales de los modelos personalizados. Sin embargo, la aplicación de estas optimizaciones requiere una cuidadosa consideración de las compensaciones entre el rendimiento del modelo y la eficiencia de los recursos.
Asignación eficiente de recursos y autoescalado
La asignación eficiente de recursos y el autoescalado son también aspectos críticos del escalado de sistemas RAG con modelos personalizados. La infraestructura debe ser capaz de asignar recursos de forma dinámica en función de los requisitos de carga de trabajo de cada modelo. Este enfoque implica monitorizar métricas clave como la utilización de la GPU, el uso de la memoria y la latencia de las peticiones para tomar decisiones de escalado con conocimiento de causa. Los mecanismos de escalado automático deben ser capaces de gestionar picos repentinos de tráfico y escalar los recursos en consecuencia para mantener un rendimiento óptimo.
Composición y orquestación de múltiples modelos
Además, la infraestructura debe soportar la composición y orquestación de múltiples modelos dentro de un sistema RAG. Los sistemas GAR a menudo implican complejas canalizaciones en las que la salida de un modelo sirve como entrada de otro. La infraestructura debe proporcionar herramientas y marcos para definir y gestionar estos conductos, garantizando un flujo de datos sin fisuras y una ejecución eficiente.
Supervisión y observabilidad
La monitorización y la observabilidad son cruciales para mantener la salud y el rendimiento de los sistemas RAG con modelos personalizados. La infraestructura debe proporcionar capacidades de supervisión completas para realizar un seguimiento de las métricas clave, los registros y las trazas de todos los componentes del sistema. Esto permite detectar y diagnosticar rápidamente los problemas y optimizar y ajustar el sistema en función de los datos de rendimiento del mundo real.
Integración y despliegue continuos (CI/CD)
Por último, la infraestructura debe soportar la integración y el despliegue continuos (CI/CD) de los modelos personalizados. A medida que se actualizan y perfeccionan los modelos, debe establecerse un proceso racionalizado para desplegar nuevas versiones sin interrumpir el sistema general. Esto requiere mecanismos sólidos de versionado, pruebas y reversión para garantizar la estabilidad y fiabilidad del sistema GAR.
Para hacer frente a estos retos de infraestructura se requiere una combinación de herramientas, marcos de trabajo y buenas prácticas. En la siguiente sección, exploraremos cómo BentoML, una plataforma para servir y desplegar modelos de aprendizaje automático, puede ayudar a abordar estos retos y simplificar el escalado de los sistemas RAG con modelos de IA personalizados.
Creación de API de inferencia para modelos personalizados con BentoML
BentoML simplifica el proceso de creación y despliegue de API de inferencia para modelos personalizados en sistemas RAG. Proporciona una transición fluida desde el desarrollo del modelo hasta las API listas para producción, lo que permite una iteración más rápida y una integración más sencilla con los sistemas existentes. Veamos cómo puede ayudarnos a superar los retos de infraestructura para escalar RAG.
Del script de inferencia al punto final de servicio
Con sólo unas pocas líneas de código, puede convertir fácilmente su script de inferencia en un punto final de servicio utilizando BentoML. Veamos un ejemplo de creación de un servicio BentoML para un modelo de incrustación de texto ajustado:
importar antorcha
from transformadores_de_sentencia import transformador_de_sentencia, modelos
clase SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/mi-modelo-afinado",
device="cuda"
)
def encode(
self,
sentencias: t.Lista[str],
) -> np.ndarray:
return self.model.encode(frases)
Este fragmento de código define la clase SentenceTransformers para encapsular el modelo de incrustación y sus métodos asociados. Dentro del método __init__` ``, el modelo SentenceTransformer`` se inicializa con un modelo ajustado y se configura para ejecutarse en el dispositivo "cuda". El método `` encode `` toma una lista de sentencias como entrada y devuelve sus incrustaciones como un array NumPy.
Para convertir esto en un servicio BentoML, puedes añadir los decoradores @bentoml.service` `` y @bentoml.api` ``:
importar bentoml
@bentoml.service
clase SentenceTransformers:
def __init__(self):
self.model = SentenceTransformer(
"bentoml/mi-modelo-afinado",
device="cuda"
)
@bentoml.api
def encode(
self,
sentencias: t.Lista[str],
) -> np.ndarray:
return self.model.encode(sentencias)
Para servir el modelo, puedes usar la CLI de BentoML:
bentoml servir .
Este comando inicia el servidor BentoML y sirve el modelo definido en el directorio actual. La salida CLI muestra que el servicio está a la escucha en [http://localhost:3000](http://localhost:3000).
A continuación, puede realizar peticiones al modelo servido utilizando el cliente BentoML:
importar bentoml
con bentoml.SyncHTTPClient("http://localhost:3000") como cliente:
result: np.NDArray = client.encode(
sentences=["frase de entrada de ejemplo"],
)
Optimizaciones del servicio
BentoML proporciona varias optimizaciones de servicio listas para usar. Una de las más potentes es el procesamiento dinámico por lotes. Añadiendo el parámetro ``` batchable=True` `` a la definición de la API, BentoML agrupa automáticamente las peticiones entrantes, optimizando la utilización de la GPU y mejorando el rendimiento del servicio del modelo.
@bentoml.api(batchable=True)
def encode(self, sentencias: t.List[str]) -> np.ndarray:
return self.model.encode(sentencias)
Los lotes dinámicos forman lotes pequeños de forma inteligente agrupando las peticiones entrantes, dividiendo los lotes grandes y ajustando automáticamente el tamaño del lote. Esta optimización puede acelerar hasta tres veces el tiempo de respuesta y mejorar en un 200% el rendimiento del servicio de incrustación.
Infraestructura de despliegue y servicio
BentoML ofrece una infraestructura de despliegue y servicio flexible y escalable. Admite varias opciones de despliegue, incluida la contenedorización con Docker y la orquestación con Kubernetes. Puede especificar fácilmente los requisitos de recursos, como el número y el tipo de GPU, y configurar los ajustes de tráfico como la concurrencia y las colas externas.
importar bentoml
@bentoml.service(
recursos={
"gpu" 1,
"gpu_type": "nvidia-tesla-t4",
},
traffic={
"concurrency": 512,
"cola_externa": True
}
)
clase SentenceTransformers:
def __init__(self):
...
@bentoml.api(batchable=True)
def encode(
...
):
...
Las capacidades de escalado elástico y micromezcla adaptativa de BentoML garantizan una utilización óptima de los recursos y un escalado automático en función del tráfico entrante. También proporciona un panel de control de despliegue fácil de usar que ofrece información sobre la tasa de solicitudes, el tiempo de respuesta y la utilización de recursos. A continuación veremos cómo escalar la inferencia LLM con BentoML.
Escalado de servicios de inferencia LLM con BentoML
BentoML proporciona características y optimizaciones completas para ayudarle a escalar sus servicios de inferencia LLM de forma eficiente.
Estrategias de autoescalado
El autoescalado garantiza que sus servicios de inferencia LLM puedan manejar cargas de trabajo variables y mantener un rendimiento óptimo. Sin embargo, es posible que las métricas de autoescalado tradicionales, como la utilización de la GPU y las consultas por segundo (QPS), no reflejen con precisión el número de réplicas deseado para los servicios LLM.
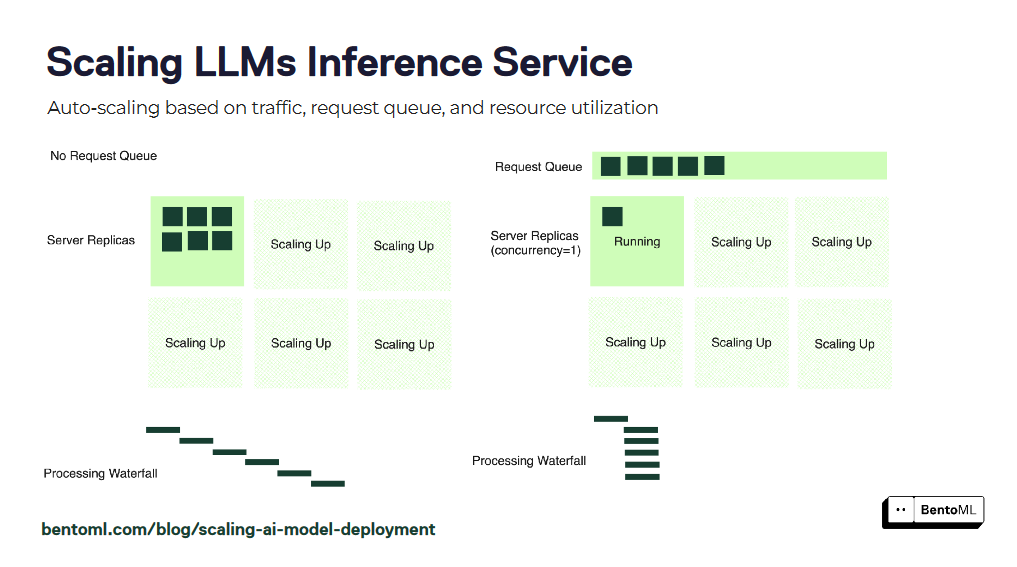
BentoML introduce el autoescalado basado en concurrencia, un enfoque más efectivo para escalar servicios de inferencia LLM. El autoescalado basado en concurrencia considera el número de peticiones concurrentes que cada réplica del modelo puede manejar, proporcionando una representación más precisa de la capacidad del servicio.
Optimización del arranque en frío
Los arranques en frío pueden suponer un reto importante a la hora de escalar servicios de inferencia LLM, especialmente con grandes imágenes contenedoras y archivos modelo. BentoML ofrece varias técnicas de optimización para mitigar la latencia del arranque en frío.
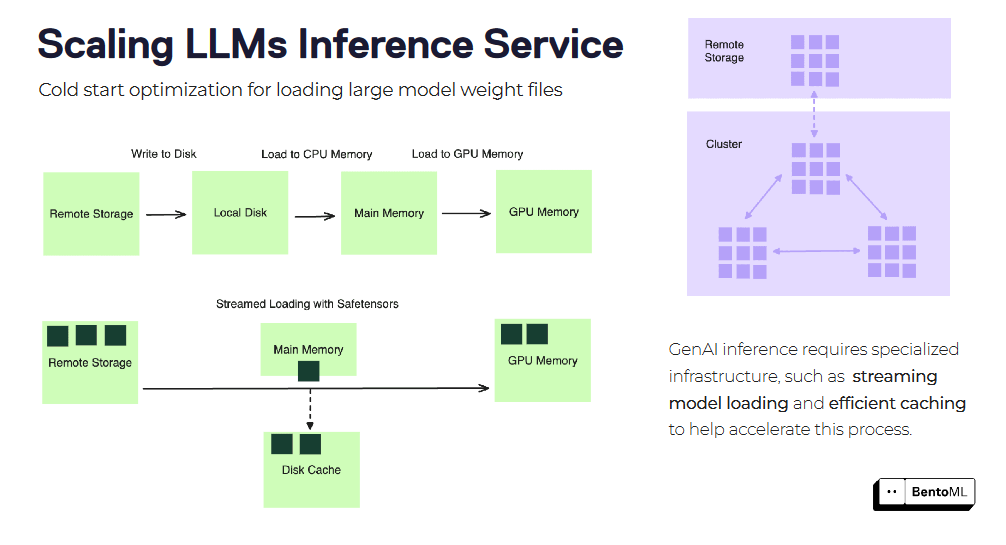
Una de estas técnicas es la carga en flujo de imágenes contenedoras. En lugar de descargar toda la imagen del contenedor antes de iniciar el servicio, BentoML puede cargar la imagen en streaming, obteniendo sólo los archivos necesarios bajo demanda. Esto puede reducir significativamente el tiempo de arranque de nuevas réplicas.
Otra optimización es la carga y almacenamiento en caché de archivos de peso del modelo. BentoML puede almacenar en caché los pesos del modelo cargado en todas las réplicas, reduciendo el tiempo necesario para cargar el modelo para cada nueva solicitud. Esto es especialmente beneficioso para modelos lingüísticos grandes con archivos de pesos extensos.
Aprovechando las estrategias de autoescalado de BentoML y las optimizaciones de arranque en frío, puede escalar eficazmente sus servicios de inferencia LLM para manejar las demandas de su sistema RAG. BentoML elimina las complejidades de la gestión de infraestructuras, lo que le permite centrarse en el desarrollo y la iteración de sus modelos al tiempo que garantiza un rendimiento y una escalabilidad óptimos.
Patrones avanzados de inferencia para sistemas GAR
Los sistemas RAG suelen requerir patrones de inferencia avanzados para gestionar flujos de trabajo complejos y optimizar el rendimiento. BentoML proporciona un marco flexible y extensible para soportar estos patrones, permitiendo la creación de sofisticados sistemas RAG con facilidad.
Los canales de procesamiento de documentos se pueden crear combinando varios modelos y pasos de procesamiento, como el análisis de diseño, la extracción de tablas y el OCR.
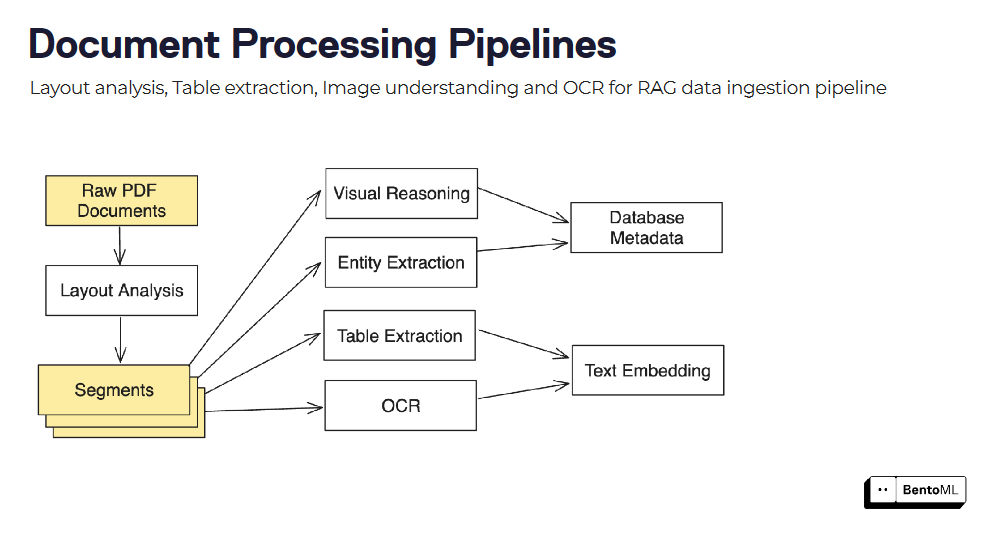
La interfaz de inferencia asíncrona de BentoML gestiona eficazmente las tareas de larga duración, mientras que su soporte de inferencia por lotes permite procesar grandes conjuntos de datos aprovechando el paralelismo y las optimizaciones.
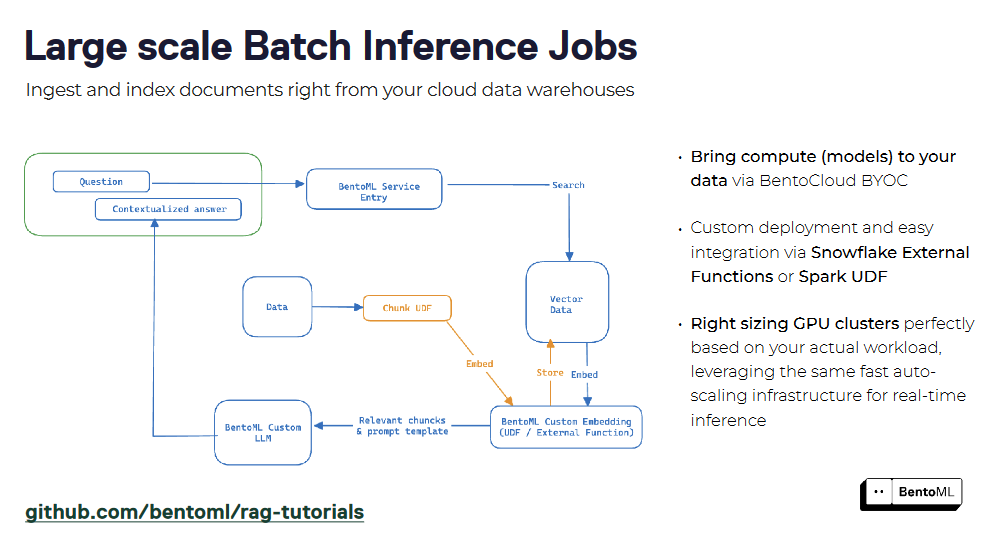
Los sistemas RAG pueden empaquetarse como un servicio utilizando BentoML, creando una interfaz unificada para la consulta y la interacción. Al encapsular componentes recuperadores y generadores, se puede desplegar un servicio RAG fácilmente e integrarlo con otras aplicaciones. La compatibilidad de BentoML con la contenedorización y la orquestación simplifica el escalado y la gestión de los servicios RAG en entornos de producción.
Estos patrones de inferencia avanzados muestran la flexibilidad y extensibilidad de BentoML en la construcción de servicios RAG potentes y eficientes que manejan diversas tareas y cargas de trabajo.
Aparte de la infraestructura para servir LLMs, también necesitamos una base de datos vectorial robusta para almacenar nuestras incrustaciones vectoriales y realizar una búsqueda de similitud. Aquí es donde nos ayuda la base de datos vectorial Milvus. En la siguiente sección, veremos cómo construir una aplicación RAG sencilla utilizando BentoML y Milvus.
Integración de BentoML y la base de datos vectorial Milvus
Milvus es una base de datos vectorial de código abierto diseñada para la búsqueda de similitudes de alto rendimiento y es un componente de infraestructura fundamental para construir Retrieval Augmented Generation (RAG).
Milvus se ha integrado con BentoML, facilitando la creación de aplicaciones RAG escalables. Esta sección le guiará a través de la construcción de una aplicación RAG con BentoML y la base de datos vectorial Milvus. En este ejemplo, utilizaremos Milvus Lite, la versión ligera de Milvus, para la creación rápida de prototipos.
El conjunto de datos que utilizamos puede encontrarse aquí: City data.
Paso 1: Configurar el entorno
En primer lugar, instale las bibliotecas necesarias como se muestra a continuación:
# Instalar las librerías necesarias
pip install -U pymilvus bentoml
Paso 2: Prepare sus datos
Vamos a descargar y procesar los Datos de la ciudad.
importar os
importar requests
importar urllib.request
# Configurar la fuente de datos
repo = "ytang07/bento_octo_milvus_RAG"
directory = "data"
save_dir = "./datos_ciudad"
api_url = f "https://api.github.com/repos/{repo}/contents/{directory}"
# Descargar archivos de GitHub
response = requests.get(api_url)
datos = response.json()
if not os.path.exists(guardar_dir):
os.makedirs(save_dir)
para item en datos:
if item["type"] == "file":
URL_archivo = elemento["URL_descarga"].
ruta_archivo = os.path.join(directorio_guardado, elemento["nombre"])
urllib.request.urlretrieve(url_archivo, ruta_archivo)
# Procesar los datos descargados
def chunk_text(nombre_archivo):
with open(nombre_archivo, "r") as f:
text = f.read()
frases = text.split("\n")
return [s for s in frases if len(s) > 7]
ciudades = os.listdir("datos_ciudad")
trozos_ciudad = []
for ciudad in ciudades:
chunked = chunk_text(f "datos_ciudad/{ciudad}")
city_chunks.append({
"nombre_ciudad": ciudad.split(".")[0],
"chunks": chunked
})
Paso 3: Configurar clientes BentoML
Ahora configuraremos los clientes BentoML tanto para el modelo de incrustación como para el LLM como se muestra a continuación.
importar bentoml
# Configurar endpoints y token API
EMBEDDING_ENDPOINT = "TU_EMBEDDING_MODEL_ENDPOINT"
LLM_ENDPOINT = "TU_LLM_ENDPOINT"
API_TOKEN = "TU_API_TOKEN"
# Inicializar clientes BentoML
embedding_client = bentoml.SyncHTTPClient(EMBEDDING_ENDPOINT, token=API_TOKEN)
llm_client = bentoml.SyncHTTPClient(LLM_ENDPOINT, token=API_TOKEN)
Sustituya los puntos finales y el token por los puntos finales y el token de API de su despliegue BentoML. Estos clientes nos permitirán generar incrustaciones y utilizar el modelo de lenguaje para la generación de texto.
Paso 4: Generar incrustaciones.
Antes de generar incrustaciones, vamos a crear una función de incrustación como se muestra a continuación:
Crear función de incrustación
def obtener_incrustaciones(textos):
# Maneja grandes lotes de textos
si len(textos) > 25:
splits = [textos[x : x + 25] for x in range(0, len(textos), 25)]
incrustaciones = []
para split en splits:
embedding_split = embedding_client.encode(sentences=split)
embeddings += embedding_split
devolver incrustaciones
# Manejar lotes pequeños directamente
return embedding_client.encode(sentencias=textos)
Esta función maneja lotes para grandes conjuntos de textos, ya que el modelo de incrustación puede tener limitaciones de tamaño de entrada.
**Genera incrustaciones para todos los trozos.
entradas = []
for ciudad_dict in trozos_ciudad:
# Obtener incrustaciones para los trozos de texto de cada ciudad
embedding_list = get_embeddings(ciudad_dict["trozos"])
# Crear entradas con incrustaciones y metadatos
para i, incrustación en enumerar(lista_incrustación):
entrada = {
"incrustación": incrustación
"frase": ciudad_dict["trozos"][i],
"ciudad": city_dict["nombre_ciudad"],
}
entries.append(entrada)
Aquí estamos creando una lista de entradas, cada una de las cuales contiene la incrustación, la frase original y el nombre de la ciudad. Esta estructura será útil cuando inserte datos en Milvus.
Paso 5: Configurar Milvus
Ahora inicializaremos una base de datos vectorial utilizando Milvus para añadir las incrustaciones.
Inicializar cliente Milvus y crear esquema
from pymilvus import MilvusClient, DataType
COLLECTION_NAME = "Bento_Milvus_RAG"
DIMENSION = 384 # Debe coincidir con la dimensión de salida de su modelo de incrustación
# Inicializar el cliente Milvus
milvus_client = MilvusClient("milvus_demo.db")
# Crear esquema
schema = MilvusClient.create_schema(auto_id=True, enable_dynamic_field=True)
schema.add_field("id", DataType.INT64, is_primary=True)
schema.add_field("incrustación", DataType.FLOAT_VECTOR, dim=DIMENSION)
Aquí estamos utilizando Milvus lite, que está incrustado en la aplicación. El esquema define nuestra estructura de datos en Milvus, incluyendo un ID autogenerado y el vector de incrustación.
Preparar los parámetros del índice y crear una colección
# Preparar los parámetros del índice
index_params = milvus_client.prepare_index_params()
index_params.add_index(
nombre_campo="incrustación",
index_type="AUTOINDEX",
metric_type="COSINE",
)
# Crear o recrear colección
if milvus_client.has_collection(nombre_coleccion=NOMBRE_COLECCION):
milvus_client.drop_collection(nombre_coleccion=NOMBRE_COLECCION)
milvus_client.crear_colección(
nombre_colección=nombre_colección, esquema=esquema, parámetros_índice=parámetros_índice
)
Estamos utilizando AUTOINDEX, que selecciona automáticamente el mejor tipo de índice en función de los datos. Se utiliza Coseno de similitud como métrica de distancia para las comparaciones de vectores.
Insertar datos en Milvus
Ahora, insertaremos los datos en Milvus como se muestra a continuación
# Insertar datos preprocesados en Milvus
milvus_client.insert(nombre_coleccion=nombre_coleccion, datos=entradas)
Este paso inserta todos nuestros datos preprocesados (incrustaciones y metadatos) en la colección Milvus.
Paso 6: Implementar RAG
Para implementar RAG eficientemente, crearemos tres funciones para generar la respuesta RAG, recuperar el contexto relevante de la colección, y generar la respuesta como se muestra a continuación:
Crear una función para que el LLM genere respuestas
def generar_rag_respuesta(pregunta, contexto):
# Preparar la pregunta para el LLM
prompt = (
f "Eres un asistente útil. Responde a la pregunta del usuario basándote sólo en el contexto: {contexto}. \n"
f "La pregunta del usuario es {pregunta}"
)
# Generar respuesta utilizando el LLM
results = llm_client.generate(max_tokens=1024, prompt=prompt)
return "".join(resultados)
Esta función construye un prompt utilizando el contexto recuperado y la pregunta del usuario y luego utiliza el LLM para generar una respuesta.
Crear una función para recuperar el contexto relevante
def recuperar_contexto(pregunta):
# Generar incrustaciones para la pregunta
embeddings = get_embeddings([pregunta])
# Buscar vectores similares en Milvus
res = milvus_client.search(
nombre_colección=nombre_colección,
data=embeddings,
anns_field="incrustación",
limit=5,
output_fields=["frase"],
)
# Extraer y combinar las frases relevantes
sentences = [hit["entidad"]["frase"] for hits in res for hit in hits]
return ". ".join(sentencias)
Esta función incorpora la pregunta del usuario, busca vectores similares en Milvus y recupera los trozos de texto correspondientes para contextualizarlos.
Combina las funciones anteriores para crear la tubería RAG.
def pregunta_pregunta(pregunta):
# Recupera el contexto relevante
context = recuperar_contexto(pregunta)
# Generar respuesta basada en el contexto y la pregunta
return generar_respuesta(pregunta, contexto)
Esta función enlaza todo, creando nuestra tubería RAG.
Paso 7: Usar tu sistema RAG
Ahora podemos utilizar nuestro sistema RAG para responder a las preguntas como se muestra a continuación:
# Ejemplo de uso
question = "¿En qué estado se encuentra Cambridge?"
answer = pregunta(pregunta)
print(f "Pregunta: {pregunta}")
print(f "Respuesta: {respuesta}")
Este ejemplo muestra cómo utilizar el sistema RAG para responder a una pregunta concreta sobre una ciudad.
Notas importantes:
Antes de ejecutar este código, asegúrese de que sus modelos de incrustación y de lenguaje grande están correctamente desplegados en BentoML.
La dimensión de sus incrustaciones (384 en este ejemplo) debe coincidir con la salida de su modelo de incrustación.
Esta configuración utiliza Milvus Lite, que es adecuado para conjuntos de datos más pequeños. Considere el uso de un despliegue completo de Milvus en Docker o K8s para aplicaciones a mayor escala.
La eficacia del sistema RAG depende de la calidad y la cobertura de sus datos iniciales de la ciudad. Asegúrese de que su conjunto de datos es completo y preciso para obtener los mejores resultados.
Esta integración de BentoML y Milvus crea un potente sistema GAR capaz de responder a preguntas basadas en la información de la ciudad proporcionada. Puede ampliar este sistema añadiendo más datos o ajustándolo para casos de uso específicos.
Conclusión
Construir y escalar sistemas Retrieval Augmented Generation (RAG) con modelos de IA personalizados presenta retos únicos. Los desarrolladores pueden crear sistemas RAG de alto rendimiento y escalabilidad aprovechando la potencia de los modelos personalizados, optimizando la infraestructura de despliegue y servicio, y adoptando patrones de inferencia avanzados.
BentoML es una herramienta valiosa en este viaje. Simplifica el proceso de creación y despliegue de API de inferencia, optimiza el rendimiento del servicio y permite un escalado perfecto.
Al integrar BentoML con la base de datos vectorial Milvus, las organizaciones pueden crear sistemas RAG más potentes y escalables. Esta combinación permite una recuperación eficiente de la información relevante y la generación de respuestas conscientes del contexto, abriendo posibilidades para aplicaciones avanzadas de IA en diversos dominios e industrias.
Para más información sobre BentoML y RAG, consulte los siguientes recursos
RAG sin OpenAI: BentoML, OctoAI y Milvus - blog de Zilliz](https://zilliz.com/blog/rag-without-open-ai-bentoml-octoai-milvus)
Cómo mejorar el rendimiento de su canalización RAG - blog de Zilliz](https://zilliz.com/learn/how-to-enhance-the-performance-of-your-rag-pipeline)
Dominar los retos LLM: una exploración de RAG - Zilliz blog](https://zilliz.com/learn/RAG-handbook)
Ingesting Chaos: Los MLOps detrás del manejo fiable de datos no estructurados a escala para RAG (milvus.io)](https://milvus.io/blog/Ingesting-Chaos-MLOps-Behind-Handling-Unstructured-Data-Reliably-at-Scale-for-RAG.md)
Por qué Milvus facilita, acelera y rentabiliza la creación de RAG - Zilliz blog](https://zilliz.com/blog/why-milvus-makes-building-rag-easier-faster-cost-efficient)
Sigue leyendo

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.