




Por qué creamos Vector Lakebase: replanteando la arquitectura de datos no estructurados para la IA
Recientemente, lanzamos Zilliz Vector Lakebase, la próxima evolución de Zilliz Cloud: de un sistema puro de base de datos vectorial a una base de datos unificada, nativa de lake, para cargas de trabajo de IA. El anuncio despertó mucho interés. También hizo surgir casi de inmediato preguntas sobre hacia dónde se dirigía Zilliz.
¿Zilliz se estaba alejando de las bases de datos vectoriales? O, dicho más directamente: ¿las bases de datos vectoriales ya se están volviendo obsoletas?
Entiendo por qué surgieron estas preguntas. Durante años, Zilliz ha sido conocida por construir sistemas de bases de datos vectoriales listos para producción (Milvus de código abierto y Zilliz Cloud totalmente gestionado). Así que cuando empezamos a hablar de evolucionar hacia una base de datos nativa de lake para la IA, algunas personas se preguntaron naturalmente si esto significaba un cambio de dirección.
La respuesta corta es NO. Absolutamente NO. En todo caso, Vector Lakebase es nuestra respuesta a lo que ocurre después de que las bases de datos vectoriales tienen éxito.
Durante los últimos años, las bases de datos vectoriales se han convertido en una de las capas de infraestructura fundamentales del stack de IA. La adopción ha crecido más rápido de lo que podríamos haber imaginado cuando empezamos Milvus hace casi una década. La categoría es real, y la necesidad de recuperación semántica no hace más que volverse más importante.
Pero también nos ha quedado clara otra cosa: la recuperación vectorial ya no es todo el problema.
A medida que los sistemas de IA pasan de asistentes estáticos a agentes que se ejecutan continuamente, las empresas piden algo más amplio a su infraestructura de datos no estructurados. No solo quieren un sistema que pueda recuperar información. Quieren un sistema que pueda mejorar los datos, reorganizarlos, analizarlos, refinarlos y devolver esas mejoras a producción. Eso cambia la arquitectura.
Ese cambio me recuerda a un ciclo anterior en la historia de la infraestructura: la evolución de las bases de datos durante la era de internet móvil. Los detalles son diferentes, pero el patrón resulta familiar. Un nuevo tipo de aplicación crea un nuevo tipo de presión sobre los datos. La primera generación de infraestructura resuelve el problema inmediato de servicio. Luego, a medida que los datos crecen, la arquitectura tiene que expandirse.
Creo que las bases de datos vectoriales están entrando ahora en esa siguiente etapa.
Internet móvil ya pasó una vez por este ciclo
Alrededor de 2010, a medida que las aplicaciones móviles explotaban, MongoDB se convirtió en uno de los productos de infraestructura definitorios de ese periodo.
La razón era sencilla. Las aplicaciones móviles generaban enormes cantidades de datos semiestructurados: eventos de usuario, actividad social, telemetría de dispositivos, señales de comportamiento, logs de producto. Nada de esto encajaba limpiamente en los patrones de bases de datos relacionales que la mayoría de los equipos utilizaba en ese momento. Los equipos de producto lanzaban rápido, los esquemas cambiaban constantemente y el primer problema era simplemente aceptar los datos sin ralentizar la aplicación. MongoDB resolvió muy bien ese problema inmediato: ingerir los datos primero. La estructura y el análisis podían venir después.

Varios años después, la industria empezó a plantear una pregunta diferente. Una vez que todos estos datos existían, ¿cómo podían las empresas usarlos realmente? Ese cambio ayudó a impulsar el auge de los data warehouses modernos, como Snowflake y Redshift. El foco pasó del almacenamiento operativo al insight analítico. Las empresas querían informes de BI, cohortes de usuarios, atribución, forecasting y análisis de crecimiento. Los datos dejaron de ser solo un subproducto operativo y se convirtieron en un activo de negocio.
Entonces apareció otro cuello de botella.
La división entre sistemas transaccionales y sistemas analíticos se volvió cada vez más dolorosa. Los pipelines de datos entre entornos OLTP y OLAP eran frágiles, caros y agotadores desde el punto de vista operativo. Los mismos datasets se copiaban repetidamente entre sistemas, a menudo con retrasos de sincronización e inconsistencias sutiles.
Ese fue el entorno que dio origen a la arquitectura Lakehouse. Databricks, Iceberg, Hudi y sistemas relacionados convergieron todos en torno a la misma idea básica: una única copia lógica de los datos debería admitir múltiples modelos de computación sin requerir movimientos interminables entre sistemas.
En retrospectiva, la progresión parece casi inevitable. Pero en ese momento, nada de eso era obvio. El auge de MongoDB no predijo Snowflake. Snowflake no predijo el Lakehouse. Cada transición surgió porque la generación anterior de infraestructura tuvo éxito a escala y luego expuso una nueva clase de restricciones.
Ese patrón importa porque la infraestructura de IA cada vez más parece estar siguiendo un camino similar.
La recuperación resolvió el primer problema, no el definitivo
Cuando los modelos de lenguaje grandes irrumpieron en la adopción generalizada en 2023, las bases de datos vectoriales se convirtieron en una de las primeras categorías de infraestructura destacadas. La razón era práctica. Los sistemas RAG necesitaban una forma nativa de almacenar embeddings y realizar recuperación semántica. La mayoría de las bases de datos tradicionales no fueron diseñadas para búsqueda vectorial de alta dimensionalidad, índices ANN, recuperación híbrida y filtrado de baja latencia a escala.
En muchos sentidos, las bases de datos vectoriales resolvieron el mismo tipo de problema que MongoDB resolvió antes. Un nuevo patrón de aplicación creó una nueva abstracción de datos, y los desarrolladores necesitaban infraestructura que pudiera admitirla. Esta vez, la abstracción era la representación semántica: embeddings generados a partir de datos no estructurados por modelos neuronales.
Esa primera fase de adopción ocurrió muy rápido. Pero solo unos años después, las preguntas que escuchamos de los clientes se han vuelto mucho más complejas. Ya no preguntan solo cómo recuperar vectores de manera eficiente. Preguntan:
- ¿Cómo deduplicamos y refinamos continuamente los datos de entrenamiento?
- ¿Cómo analizamos miles de millones de embeddings para clustering y problemas de calidad?
- ¿Cómo identificamos deriva, sesgo o redundancia en conjuntos de datos multimodales?
- ¿Cómo rastreamos y optimizamos historiales de ejecución de agentes?
- ¿Cómo reprocesamos y mejoramos los datos a medida que los modelos evolucionan?
- ¿Cómo buscamos datos fríos sin mantener todo el cómputo en funcionamiento todo el tiempo?
- ¿Cómo usamos datos que ya residen en Iceberg, Lance, Parquet y almacenamiento de objetos para múltiples cargas de trabajo de IA?
Estos ya no son problemas puramente de recuperación. Requieren procesamiento offline a gran escala, flujos de trabajo iterativos de descubrimiento, gobernanza de datos, exploración analítica y bucles de retroalimentación continuos entre sistemas online y computación offline. Cada vez más, notamos algo importante entre los equipos avanzados de IA: el cuello de botella ya no era solo la capacidad del modelo. Era la velocidad de iteración.
Una experiencia lo hizo dolorosamente obvio. Vimos equipos intentando reprocesar grandes conjuntos de datos vectoriales: reagrupar embeddings, eliminar duplicación, regenerar índices, volver a generar embeddings de corpus completos. En algunos casos, simplemente mover mil millones de vectores de un sistema a otro podía llevar días. No horas. Días.
Mientras tanto, los ciclos de iteración dentro de los equipos líderes de IA se están moviendo en la dirección opuesta. Los investigadores quieren experimentar continuamente. Los ingenieros de datos están bajo presión para limpiar, evaluar y actualizar conjuntos de datos más rápido. Los modelos mejoran. Los modelos de embeddings cambian. Los agentes crean nuevas trazas todos los días. Pero la pila de infraestructura debajo de ellos no fue diseñada para bucles de refinamiento continuo sobre datos no estructurados.
Ese fue el punto en el que empezamos a pensar que la industria estaba encuadrando el problema de forma demasiado estrecha.
La infraestructura de datos no estructurados no es meramente una capa de recuperación. Se está convirtiendo en un sistema operativo continuo.
De sistemas de recuperación a sistemas continuos: CS/CD
Internamente, empezamos a describir esta arquitectura como un bucle continuo entre serving y discovery. Con el tiempo, empezamos a llamarlo CS/CD: Continuous Serving and Continuous Discovery.
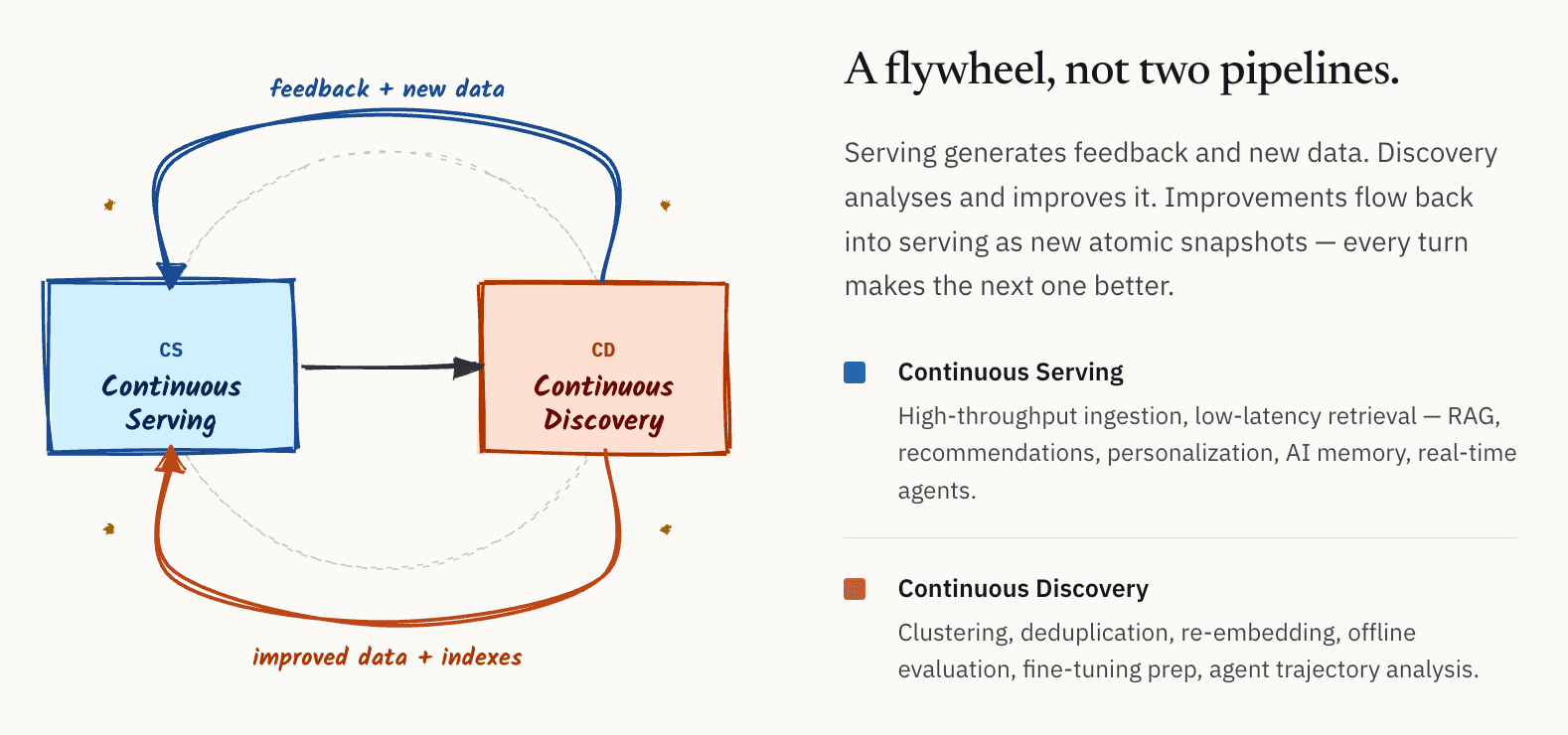
La idea es conceptualmente simple.
- Por un lado, está la capa de servicio: ingesta de alto rendimiento, recuperación de baja latencia para sistemas RAG en línea, sistemas de recomendación, personalización, memoria de IA y agentes en tiempo real.
- Por otro lado, está la capa de descubrimiento: clustering, deduplicación, re-embedding, evaluación offline, análisis de calidad, preparación para el ajuste fino de modelos y análisis de trayectorias de agentes.
El punto importante es que estos no son flujos de trabajo independientes. Forman un volante de inercia. Los sistemas de servicio generan continuamente feedback y nuevos datos. Los sistemas de descubrimiento analizan y mejoran esos datos. Las mejoras resultantes, incluidas mejores embeddings, conjuntos de datos más limpios, índices mejorados y metadatos refinados, luego vuelven a fluir hacia la capa de servicio.
Cada iteración debería mejorar la siguiente. Al menos en teoría.
En la práctica, la mayoría de las organizaciones todavía no pueden operar este bucle de manera eficiente porque la infraestructura subyacente sigue fragmentada.
Hoy, si un equipo quiere realizar procesamiento offline a gran escala sobre datos vectoriales de producción, el flujo de trabajo típico sigue siendo dolorosamente manual. Primero, los datos deben exportarse desde la base de datos vectorial a un lago o entorno batch. Normalmente, los índices no se pueden reutilizar. Los pipelines de sincronización se vuelven frágiles. Las actualizaciones incrementales son difíciles. Los resultados procesados finalmente deben reimportarse al sistema de servicio, a menudo sin ninguna garantía de consistencia atómica entre los nuevos datos y los nuevos índices.
El resultado es un flujo de trabajo lento, frágil y costoso. Y debido a que es tan costoso de mantener, muchas organizaciones simplemente evitan hacer descubrimiento continuo. Los datos permanecen ahí, recuperables pero en gran medida inexplorados.
Esto nos recordó cada vez más a la brecha histórica entre los sistemas OLTP y OLAP, excepto que ahora la fragmentación está entre la recuperación semántica en línea y el procesamiento offline de datos no estructurados.
Por qué las arquitecturas existentes finalmente alcanzan sus límites
Algo de lo que nos convencimos cada vez más es que ninguno de los dos lados del stack de infraestructura actual está equivocado.
Las bases de datos vectoriales y los sistemas Lakehouse resuelven ambos problemas importantes. El problema es que cada arquitectura se optimizó en torno a solo una mitad de la carga de trabajo emergente.
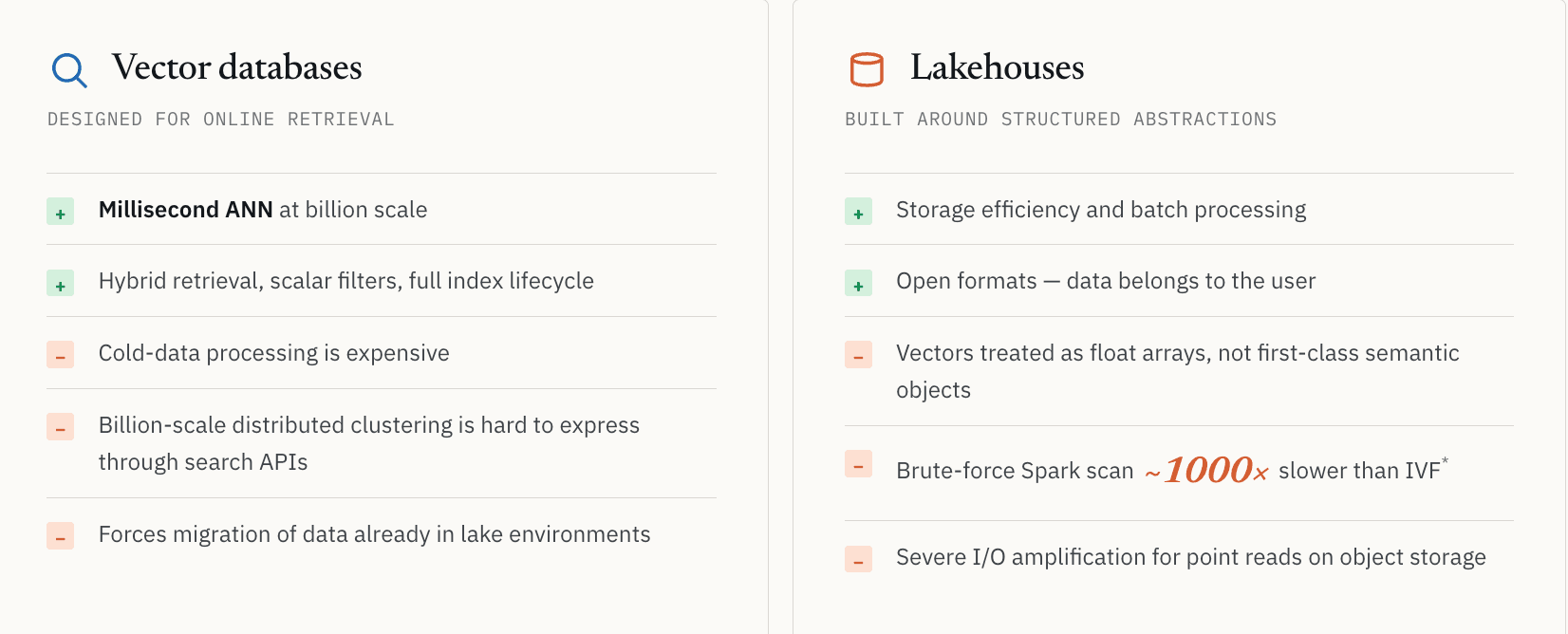
Las bases de datos vectoriales fueron diseñadas principalmente para la recuperación en línea.
Tomemos como ejemplo el proyecto open-source Milvus. Resuelve extremadamente bien la búsqueda vectorial a escala. Pero cuando las cargas de trabajo van más allá del servicio y entran en el descubrimiento a gran escala, aparecen límites arquitectónicos naturales.
El procesamiento de datos fríos se vuelve costoso. El clustering distribuido a escala de miles de millones es difícil de expresar mediante APIs de búsqueda en línea. Muchos sistemas asumen que los datos deben permanecer cargados en la infraestructura en línea para seguir siendo consultables. Las empresas que ya almacenan conjuntos masivos de datos no estructurados en entornos de lago enfrentan costos de migración y fragmentación de la gobernanza cuando se les pide mover todo a un sistema de recuperación dedicado.
Estos no son bugs de implementación. Son consecuencias de optimizar para una recuperación en línea de baja latencia.
Los Lakehouses resuelven la eficiencia de almacenamiento y el procesamiento batch, pero fueron diseñados en torno a abstracciones de datos estructurados
El enfoque opuesto, partir del lado del Lakehouse, introduce un conjunto diferente de tradeoffs.
Los Lakehouses resuelven elegantemente la eficiencia de almacenamiento y el procesamiento batch. Pero fueron diseñados en torno a abstracciones de datos estructurados. En la mayoría de las arquitecturas de lago, los vectores todavía se tratan como largos arrays de floats en lugar de objetos semánticos de primera clase. Los formatos de archivo como Parquet no fueron diseñados en torno a índices ANN, índices invertidos o rutas de recuperación semántica de baja latencia.
Lo vimos directamente con un cliente farmacéutico que realizaba búsquedas de similitud molecular. Un escaneo Spark de fuerza bruta sobre datos del lake era aproximadamente 1000 veces más lento que la recuperación vectorial indexada mediante búsqueda basada en IVF. El número exacto depende de la distribución de los datos, los parámetros del índice y el hardware, pero la lección es constante: sin el índice adecuado, muchas cargas de trabajo semánticas no son económicamente viables.
También existe un problema de almacenamiento más básico. El almacenamiento de objetos puede introducir una amplificación de E/S severa para cargas de trabajo orientadas a la recuperación. La búsqueda semántica a menudo encuentra un pequeño número de IDs, pero la aplicación aún necesita los registros completos detrás de esos IDs. Con los formatos columnares tradicionales, recuperar unos pocos registros pequeños puede requerir leer grandes bloques de almacenamiento. Eso está bien para los escaneos. Es una mala opción para el servicio de baja latencia.
Con el tiempo, nuestra conclusión se volvió difícil de evitar: la industria no debería tener que elegir entre bases de datos vectoriales y arquitecturas lake. Necesita una arquitectura donde la recuperación y el descubrimiento a gran escala sean partes nativas del mismo sistema operativo.
Qué entendemos por Vector Lakebase
Esa comprensión nos llevó hacia lo que ahora llamamos Vector Lakebase. La idea central no es “una base de datos vectorial más un data lake”. Creo que ese enfoque pasa por alto el punto arquitectónico más profundo.
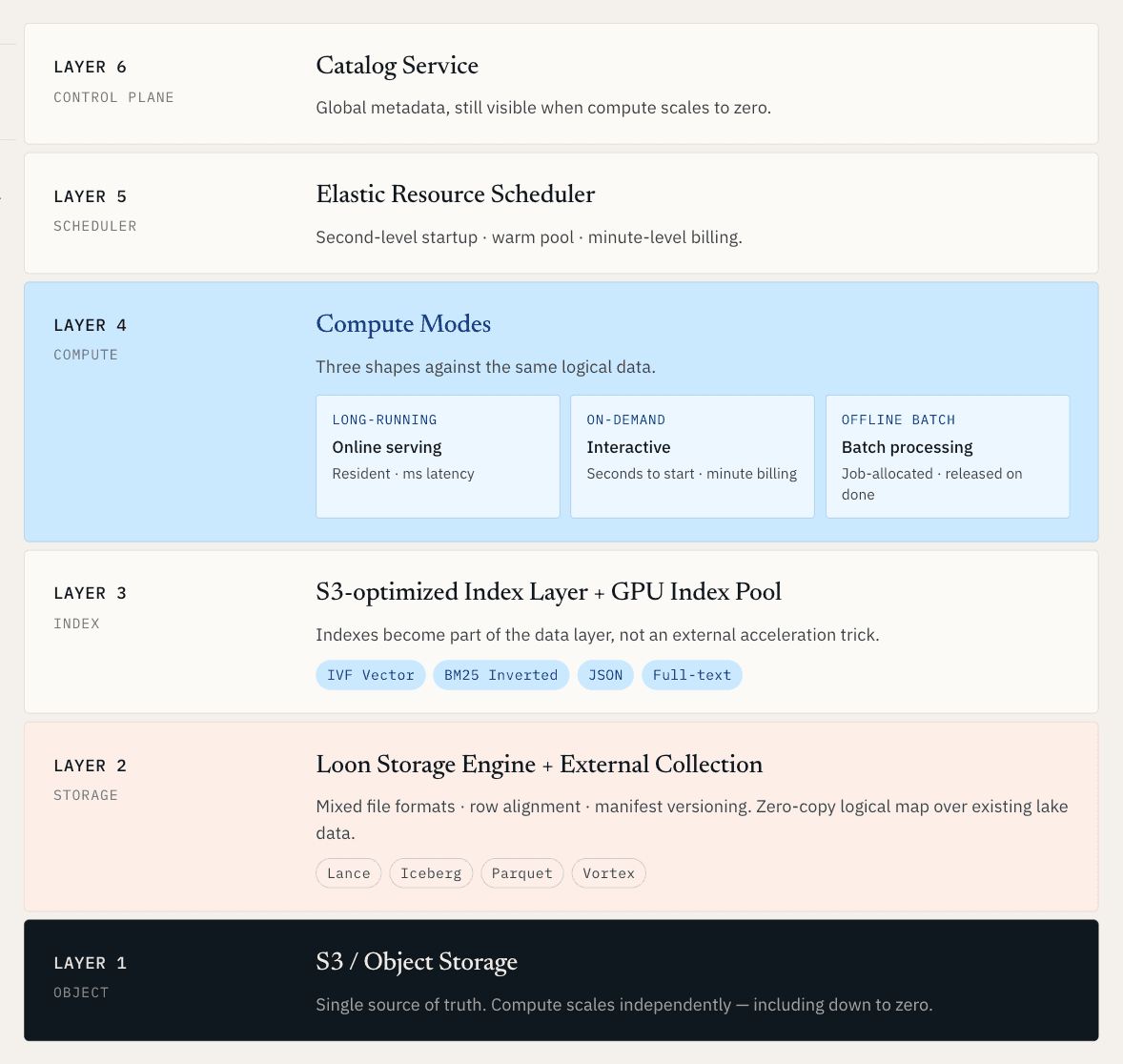
El objetivo es crear una capa operativa unificada para datos no estructurados, una en la que el servicio en línea, el descubrimiento sin conexión y el cómputo elástico operen todos sobre la misma base lógica de datos.
Para los datos sin procesar, eso significa que vectores, documentos, metadatos, registros e índices se gestionan juntos en almacenamiento nativo del lake. Para los datos que ya residen en Iceberg, Lance, Parquet o almacenamiento de objetos, significa que el sistema puede mapear e indexar esos datos sin obligar a una migración completa.
Una vez que se parte de ese requisito, la arquitectura tiene que resolver varios problemas difíciles a la vez. El cómputo debe escalar independientemente del almacenamiento. Los índices deben convertirse en parte de la capa de datos, no en un truco de aceleración externo. Los datos nuevos y los índices nuevos deben publicarse juntos como instantáneas consistentes. Y los datos existentes del lake deben poder buscarse sin crear otra copia.
Esas ideas suenan simples. Hacer que funcionen preservando al mismo tiempo el rendimiento que la gente espera de una base de datos vectorial es la parte difícil. Ahí es donde las decisiones de ingeniería de nivel inferior comienzan a importar.
El coste de separar almacenamiento y cómputo y cómo lo abordamos
La separación entre almacenamiento y cómputo es necesaria para el ciclo CS/CD, pero no es gratuita.
Arranque en frío lento
Si el cómputo puede escalar hasta cero, la primera consulta en un flujo de trabajo bajo demanda o sin conexión puede encontrarse con datos completamente fríos. El nodo no tiene índice local, ni caché precalentada, ni datos residentes. Todo tiene que venir del almacenamiento de objetos.
Para conjuntos de datos pequeños, eso es manejable. Para grandes cargas de trabajo vectoriales, rápidamente se vuelve inaceptable. Consideremos mil millones de vectores de 768 dimensiones. Un índice HNSW convencional puede rondar los 340 GB. Descargar ese índice completo desde S3 puede tardar más de cuatro minutos. Nadie quiere esperar cuatro minutos antes de que pueda comenzar una búsqueda.
Nuestra respuesta es hacer que la ruta fría sea mucho más pequeña. Usando cuantización de 1+3 bits al estilo RaBitQ, podemos comprimir ese índice de aproximadamente 340 GB a unos 13 GB. La búsqueda se ejecuta en dos etapas. La primera etapa usa una representación de 1 bit para el filtrado aproximado, con una recuperación de aproximadamente el 85 al 90 por ciento mientras reduce el tamaño de los datos a alrededor de una treintava parte del original. La segunda etapa usa la representación de 1+3 bits para reordenar y refinar los resultados hasta alrededor del 95 por ciento de recuperación. Eso reduce el arranque en frío de minutos a aproximadamente 5 a 10 segundos.
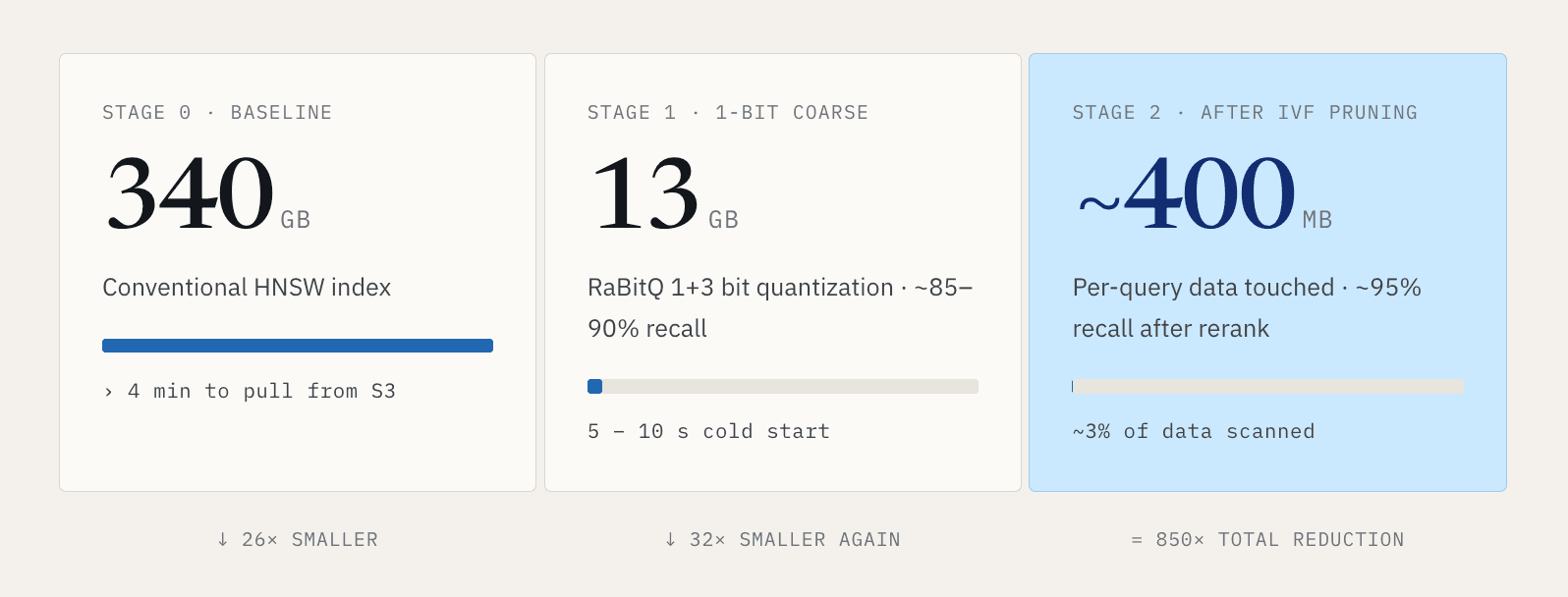
Luego usamos clustering IVF para reducir la cantidad de datos tocados por consulta. En una configuración representativa, cada consulta escanea alrededor del 3 por ciento de los datos. La ruta se convierte en: 340 GB de índice convencional, comprimidos a 13 GB, con una sola consulta tocando aproximadamente 400 MB después de la poda.
Esta es la diferencia entre la búsqueda vectorial elástica como idea y la búsqueda vectorial elástica como un sistema utilizable.
Amplificación de E/S
El arranque en frío es solo un lado del problema. El otro lado es el acceso a registros.
La búsqueda vectorial devuelve IDs. Pero las aplicaciones necesitan registros completos: fragmentos de texto, metadatos, punteros a documentos, permisos, marcas de tiempo, atributos de imagen u otros campos. En un diseño estándar de Parquet, una pequeña lectura puntual puede obligar al sistema a descargar un gran grupo de filas. Una consulta puede necesitar solo unos pocos kilobytes de datos útiles, pero terminar extrayendo decenas de megabytes del almacenamiento de objetos. Reducir los grupos de filas ayuda a las lecturas puntuales, pero perjudica la compresión y la eficiencia del escaneo.
Por eso creamos Loon, el motor de almacenamiento reconstruido detrás de Zilliz Vector Lakebase.
Loon utiliza formatos de archivo mixtos, alineación de filas y versionado basado en manifiestos. Los campos escalares pueden usar diseños columnares que siguen siendo eficientes para el filtrado y los escaneos. Los campos vectoriales y los datos con muchas consultas puntuales pueden usar diseños más adecuados para la recuperación de baja latencia. Los grupos de columnas alinean los IDs de fila para que el sistema pueda obtener los campos que necesita sin arrastrar grandes bloques no relacionados por la red.
Por debajo, Loon utiliza Vortex, un formato de archivo de código abierto bajo la Linux Foundation. Vortex admite diseños flexibles y codificaciones anidadas, incluidas consultas puntuales sin descomprimir grandes bloques irrelevantes.
En una prueba interna con 3 millones de filas, vectores de 128 dimensiones, almacenamiento S3 y 256 lectores concurrentes, las lecturas puntuales de Parquet descargaron alrededor de 9,4 MB por lectura. Vortex descargó alrededor de 0,07 MB. Eso supone una reducción de 135x en los datos descargados. El rendimiento de escaneo completo también fue mayor en esa configuración.
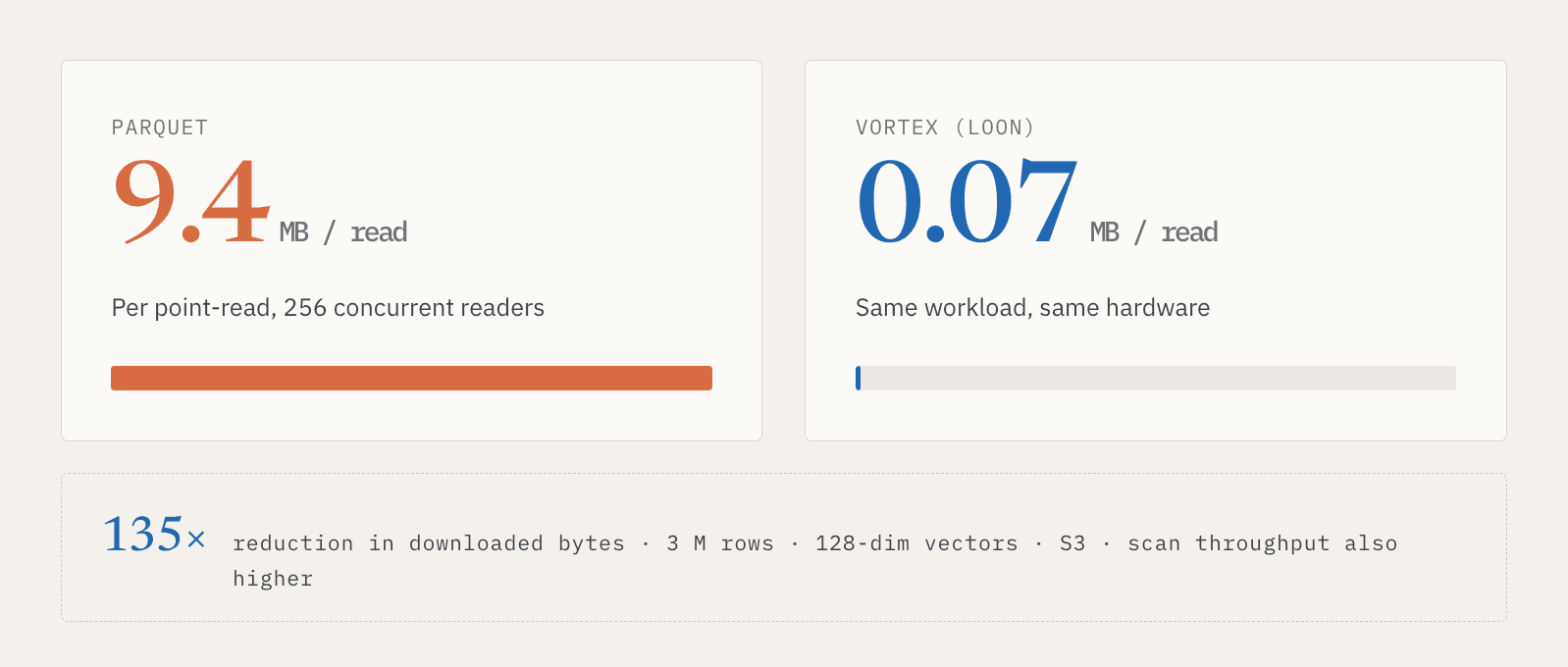
La cuestión no es solo que un formato sea más rápido para un benchmark. La cuestión es que el servicio y el descubrimiento necesitan diferentes patrones de acceso sobre los mismos datos lógicos. Los sistemas en línea necesitan lecturas puntuales rápidas. Los sistemas por lotes necesitan escaneos eficientes. Una Vector Lakebase tiene que admitir ambos sin obligar a los usuarios a mantener dos copias de los datos.
Vector Lakebase: una base de datos, múltiples modos de cómputo
Una vez que la capa de datos es compartida, el cómputo no puede ser de talla única.
Las diferentes cargas de trabajo de IA tienen formas muy distintas. Algunas necesitan baja latencia predecible durante todo el día. Algunas necesitan una sesión de búsqueda interactiva durante diez minutos. Algunas necesitan un gran trabajo por lotes que se ejecuta durante la noche y luego desaparece.
Por eso Zilliz Vector Lakebase admite tres modos de cómputo.
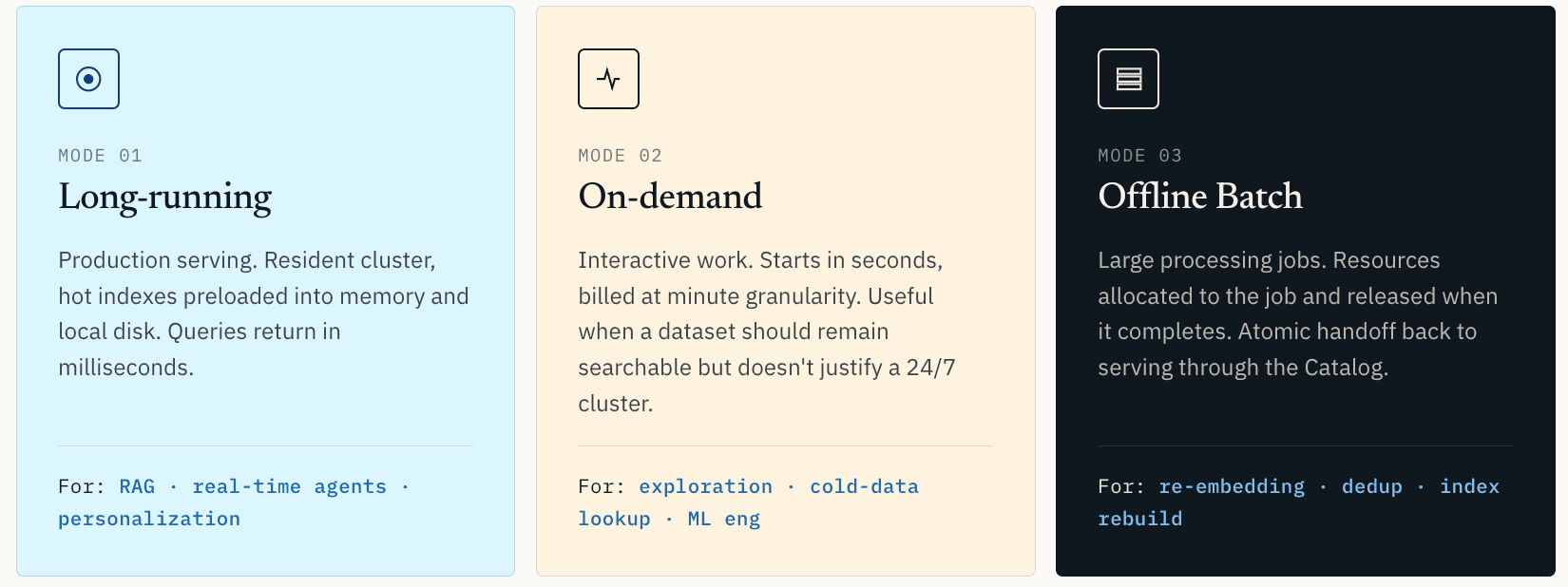
- El cómputo de larga duración es para el servicio en producción. El clúster permanece residente. Los índices y datos calientes se precargan en memoria y disco local. Las consultas se devuelven en milisegundos. Este es el modo adecuado para RAG en producción, recomendación en tiempo real, personalización, agentes en línea y cualquier carga de trabajo donde la latencia forme parte de la experiencia del usuario.
- El cómputo bajo demanda es para el trabajo interactivo. Se inicia en segundos y se factura con granularidad a nivel de minuto. Esto es útil para la exploración de similitud, inspección de anomalías, recuperación de datos fríos o flujos de trabajo de ingeniería de ML donde el conjunto de datos debe seguir siendo consultable pero no justifica un clúster 24/7.
- El cómputo Offline Batch es para grandes trabajos de procesamiento: clustering vectorial, deduplicación de datos de entrenamiento, re-embedding completo, reconstrucción de índices y escaneos de calidad de datos. Los recursos se asignan al trabajo y se liberan cuando el trabajo se completa.
La transferencia de vuelta al serving ocurre a través del Catálogo como una nueva instantánea. El serving sigue leyendo la instantánea antigua hasta que los nuevos datos e índices están listos. Entonces la nueva versión se vuelve visible de forma atómica. Ese cambio atómico importa. El descubrimiento solo es útil si las mejoras pueden volver a producción sin exponer índices a medio construir o datos inconsistentes.
 architecture.png
architecture.png
Un ejemplo de cliente muestra por qué importa la distinción. Un cliente de conducción autónoma tenía mil millones de vectores de 768 dimensiones, pero solo necesitaba unos 20 minutos de tiempo de consulta online al día. Ejecutar la carga de trabajo como un clúster de larga duración costaba aproximadamente $7,000 al mes. Pasarla al modo bajo demanda redujo el costo mensual a alrededor de $500. El mismo cliente tenía un flujo de trabajo de deduplicación que antes dedicaba unas 70 horas a realizar búsquedas ANN una por una. Replantearlo como un trabajo por lotes offline redujo el tiempo de cómputo a unas 10 horas en la misma clase de recursos.

La lección no es que un modo de cómputo sea mejor que otro. La lección es que las cargas de trabajo de datos de IA no tienen una sola forma, y la arquitectura no debería obligarlas a tenerla.
La planificación de recursos se convierte en parte de Vector Lakebase
Los tres modos de cómputo solo funcionan si la planificación de recursos es tan elástica como el propio cómputo.
Los planificadores de bases de datos tradicionales suelen asumir un conjunto fijo de máquinas. Dados estos nodos, el sistema decide dónde colocar los datos y cómo equilibrar las cargas. Ese modelo funciona bien cuando la carga de trabajo es estable. Encaja mal con cargas de trabajo de IA que aparecen en ráfagas: una sesión de búsqueda bajo demanda, una breve inspección de datos fríos, un trabajo nocturno de deduplicación y luego horas sin actividad.
En ese mundo, la mejor pregunta no es solo dónde deberían ejecutarse los datos. Es si el cómputo debería estar ejecutándose en absoluto.
Por eso Vector Lakebase tiene que planificar datos y recursos conjuntamente. En la práctica, eso significa mantener un Warm Pool de nodos preparados, adjuntar datos rápidamente cuando llega trabajo, mantener los recursos calientes brevemente después de la solicitud y liberarlos cuando ya no son útiles.
También cambia la economía. Esto no es lo mismo que la tarificación serverless por solicitud, y no es lo mismo que la capacidad mensual dedicada. Para muchas cargas de trabajo de datos de IA, el uso a nivel de minutos es la unidad más natural: pagar por el cómputo mientras el ciclo se ejecuta y luego dejar que desaparezca.
Detrás de esto hay un cambio arquitectónico más amplio: pasar de un plano de control que gestiona un kernel mayormente estático a un kernel que entiende los recursos, el estado de la caché, las instantáneas y el costo. Eso merece su propia publicación. Para este artículo, el punto importante es más simple: sin este modelo de recursos, Long-running, On-demand y Offline Batch serían tres opciones de despliegue separadas, no tres partes del mismo sistema de datos elástico.
External Collection: encontrar los datos donde ya viven
Hay una realidad más para la que tuvimos que diseñar.
La mayoría de las empresas ya tienen grandes cantidades de datos no estructurados en entornos lake: tablas Lance, tablas Iceberg, conjuntos de datos Parquet y directorios de almacenamiento de objetos. Pedirles que muevan todo a un nuevo sistema antes de poder usarlo no es realista.
Por eso construimos External Collection dentro de Zilliz Vector Lakebase. External Collection no es solo un mapeo zero-copy. Construye una capa de indexación independiente sobre los datos externos. Los datos originales permanecen donde están y siguen gobernados por la plataforma existente del cliente, mientras Zilliz construye y gestiona los índices vectoriales, índices invertidos e índices JSON necesarios para que esos datos sean buscables a través de la misma ruta de recuperación que los datos nativos.
Nuestro principio interno se volvió simple: One Data. One Index. Sin almacenamiento duplicado. Sin pipelines de doble escritura. Sin rutas de descubrimiento fragmentadas.
Esto significa que el bucle CS/CD puede abarcar más que los datos ya importados en una base de datos vectorial. Puede incluir los activos de datos no estructurados que las empresas ya tienen en sus lagos.
Qué define a la primera generación de Vector Lakebase
Estas ideas no son solo arquitectura sobre el papel. Ya las estamos lanzando en Zilliz Vector Lakebase, y el proceso de construirlo ha hecho que nuestra visión de la categoría sea mucho más concreta.
Una Vector Lakebase de primera generación tiene que hacer bien varias cosas al mismo tiempo.

- Primero, separación de almacenamiento y cómputo con almacenamiento en caché de múltiples capas. Los datos residen en almacenamiento de objetos, y el cómputo puede escalar de forma independiente, incluso hasta cero. Pero la separación por sí sola no basta. La búsqueda vectorial en línea todavía necesita memoria, disco local, nodos calientes y ejecución consciente de la caché para mantener las consultas activas rápidas a nivel de ms.
- Segundo, gestión unificada para datos no estructurados multimodales. El sistema debe gestionar no solo vectores, sino también documentos fuente, imágenes, audio, video, embeddings, metadatos escalares, permisos e índices. Un sistema que solo almacena vectores es un servicio de índices, no una base de datos.
- Tercero, capacidades nativas de base de datos vectorial. Búsqueda ANN en milisegundos, gestión del ciclo de vida de índices, búsqueda híbrida, filtrado escalar, recuperación de texto completo, filtrado JSON y múltiples métricas de similitud deben estar integrados. Conectar un Lakehouse a una base de datos vectorial externa no elimina la fragmentación. Solo crea otro pipeline.
- Cuarto, múltiples modos de cómputo. El servicio en línea, la interacción bajo demanda y el procesamiento por lotes offline necesitan operar sobre los mismos datos lógicos. El cómputo bajo demanda es especialmente importante porque se convierte en el puente entre el servicio en producción y el procesamiento offline a gran escala.
- Quinto, formatos abiertos y sin migración forzada. La capa de almacenamiento debe ser legible por motores externos como Spark, Ray y Daft. Las tablas Iceberg, los conjuntos de datos Lance y los archivos Parquet existentes deben poder unirse al sistema sin copias innecesarias. Los datos pertenecen al usuario, no al motor.
- Sexto, los recursos deben seguir a los datos. El cómputo puede desaparecer cuando no se necesita, mientras que los metadatos permanecen visibles y consultables. Una solicitud puede traer de vuelta los recursos en segundos. Los tenants inactivos no deberían pagar por cómputo dedicado que no están utilizando. Esto no es solo autoescalado; requiere que el motor tome decisiones de recursos junto con decisiones de datos.
Estas son nuestras creencias actuales, no la última palabra. Seguiremos revisándolas a medida que el sistema madure. Pero una presión parece poco probable que cambie: los datos no estructurados seguirán creciendo, mientras que los presupuestos de infraestructura no crecerán al mismo ritmo. Eso significa que los sistemas de IA deben volverse más iterativos, más eficientes y más continuamente adaptativos.
Las bases de datos vectoriales no están desapareciendo
Entonces, volviendo a la pregunta original: ¿significa esto que las bases de datos vectoriales van a desaparecer? En absoluto.
En todo caso, la recuperación semántica se vuelve más importante en esta arquitectura. Pero su rol cambia.
Las bases de datos vectoriales se convierten en el motor de servicio dentro de un sistema de datos no estructurados más amplio, de forma muy similar a como las bases de datos transaccionales siguieron siendo esenciales dentro de la era más amplia del Lakehouse. Los sistemas OLTP no fueron reemplazados por los Lakehouses. Se convirtieron en una capa dentro de una pila de arquitectura más amplia. Creo que las bases de datos vectoriales están atravesando ahora la misma transición.
El cambio más amplio que está ocurriendo bajo la infraestructura de IA no se trata simplemente de recuperación. Se trata de construir bucles operativos continuos alrededor de los propios datos no estructurados. El servicio genera retroalimentación. El descubrimiento mejora la calidad de los datos. Esas mejoras vuelven a producción. Cada vuelta del bucle mejora el sistema.
Todo lo demás, incluidos los formatos de almacenamiento, las jerarquías de caché, los sistemas de indexación, los modelos de cómputo elástico y la programación de recursos, existe para hacer que ese volante sea económicamente viable a escala.
Todavía no sabemos exactamente en qué se convertirá Vector Lakebase en los próximos cinco años. Cuando empezamos Milvus hace casi una década, tampoco podríamos haber predicho adónde llevarían las propias bases de datos vectoriales.
Pero una cosa parece clara ahora. Los datos no estructurados seguirán creciendo. Los modelos seguirán cambiando. Los agentes generarán más trazas, retroalimentación y estado. Los equipos necesitarán mejorar sus datos más rápido sin permitir que el costo de infraestructura crezca sin límite.
Los sistemas que tengan éxito serán aquellos que hagan que el servicio continuo y el descubrimiento continuo se sientan como parte de la misma máquina. Esa es la dirección hacia la que estamos construyendo.
Zilliz Vector Lakebase está disponible en vista previa pública
Hemos lanzado la vista previa pública de Zilliz Vector Lakebase — una evolución importante de Zilliz Cloud, de una base de datos vectorial gestionada a una plataforma unificada de datos semánticos, que combina el servicio vectorial de baja latencia con la apertura, escalabilidad y economía de un lago de datos.
Capacidades principales de Zilliz Vector Lakebase:
- Servicio por niveles optimizado para diferentes compensaciones entre rendimiento en tiempo real y costo
- Búsqueda bajo demanda para cargas de trabajo a gran escala o exploratorias sin cómputo siempre activo
- Búsqueda en lago de datos externo — indexa y busca directamente sobre tus datos existentes en el lago
- Búsqueda de espectro completo en vectores, texto, JSON y datos geoespaciales con recuperación híbrida y reranking
- Almacenamiento unificado nativo de lago basado en Vortex, un formato abierto con lecturas aleatorias más rápidas y más baratas que Lance o Parquet
Si tu stack actual divide el servicio y el descubrimiento en sistemas separados, puede que valga la pena echar un vistazo a Vector Lakebase. Pruébalo en Zilliz Cloud — los nuevos registros con correo electrónico de trabajo reciben $100 en créditos gratis — o habla con nosotros sobre tu caso de uso.
Nota: Las cifras de rendimiento y costo de este artículo provienen de resultados de VectorDB Benchmark de código abierto, pruebas internas y escenarios de clientes anonimizados. Los resultados reales varían según la escala de los datos, la distribución, los parámetros de índice, la forma de la carga de trabajo y la configuración de recursos.

Sigue leyendo

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.