




Alles, was Sie über Llama 2 wissen müssen

Alles, was Sie über Llama 2 wissen müssen
Was ist Llama 2?
Llama 2, 2023 von Meta AI vorgestellt, ist ein bedeutender Fortschritt bei großen Sprachmodellen (LLMs). Diese Modelle, Llama 2 und Llama 2-CHAT, skalieren auf bis zu 70 Milliarden Parameter und stehen für Forschungs- und kommerzielle Zwecke kostenlos zur Verfügung. Sie stellen einen Sprung nach vorn bei den Fähigkeiten der Verarbeitung natürlicher Sprache (NLP) dar, von der Texterzeugung bis zur Interpretation von Programmcode.
Aufbauend auf seinem Vorgänger LLaMa 1, der ursprünglich nur Forschungseinrichtungen unter einer nichtkommerziellen Lizenz zugänglich war, markiert Llama 2 einen wichtigen Wandel hin zur Demokratisierung des Zugangs zu modernsten KI-Technologien. Im Gegensatz zu seinem Vorgänger sind die Llama 2-Modelle „Open Source“ und damit frei für Forschung und kommerzielle Anwendungen verfügbar, was Metas Engagement widerspiegelt, ein inklusiveres und kollaborativeres generatives KI-Ökosystem zu fördern.
Die Veröffentlichung von Llama 2 bietet Zugang zu hochmodernen LLMs und geht die rechnerischen Herausforderungen an, die mit ihrer Entwicklung verbunden sind. Durch die Optimierung der Leistung, ohne die Parameteranzahl exponentiell zu erhöhen, bietet Llama 2 Modelle mit unterschiedlichen Parametergrößen von 7 Milliarden bis 70 Milliarden. Dieser strategische Ansatz ermöglicht es kleineren Organisationen und Forschungsgemeinschaften, die Leistungsfähigkeit von LLMs ohne exorbitante Rechenressourcen zu nutzen.
Darüber hinaus zeigt sich Metas Engagement für Transparenz in der Entscheidung, sowohl den Code als auch die Modellgewichte von Llama 2 zu veröffentlichen, wodurch ein besseres Verständnis und eine stärkere Zusammenarbeit innerhalb der KI-Forschungsgemeinschaft ermöglicht werden. Durch den Abbau von Einstiegshürden und die Förderung der Zugänglichkeit ebnet Llama 2 den Weg für eine inklusivere und innovativere Zukunft in der KI-Forschung und -Entwicklung.
Llama 2
Llama 2 ist eine aktualisierte Version von Llama 1, die mit einer neuen Mischung öffentlicher Daten trainiert wurde. Der vortrainierte Datensatz wurde um 40 % vergrößert, die Kontextlänge wurde verdoppelt, und das Meta-Team führte beim Aufbau von Llama 2 Grouped-Query Attention ein.
| Trainingsdaten | Parameter | Kontextlänge | Group-query attention | Token | |
| Llama 1 | Siehe Touvron et al.(2023) | 7B | 2K | - | 1.0T |
| 13B | 2K | - | 1.0T | ||
| 33B | 2K | - | 1.4T | ||
| 65B | 2K | - | 1.4T | ||
| Llama 2 | Eine neue Mischung öffentlichverfügbarer Online-Daten | 7B | 4K | - | 2.0T |
| 13B | 4K | - | 2.0T | ||
| 34B | 4K | ✓ | 2.0T | ||
| 70B | ✓ | 2.0T |
Llama 2-CHAT
Llama 2-CHAT ist eine feinabgestimmte Version von Llama 2, die das Meta-Team für Anwendungsfälle natürlicher Sprache optimiert hat. Die Varianten dieses Modells sind mit 7B, 13B und 70B Parametern verfügbar. Llama 2-Chat unterliegt denselben weithin anerkannten Einschränkungen anderer LLMs, darunter ein Ende der Wissensaktualisierungen nach dem Vortraining, das Potenzial für nicht faktenbasierte Generierung wie unqualifizierte Ratschläge und eine Neigung zu Halluzinationen.
Llama 2 Open Source
Während Meta großzügig Zugang zum Ausgangscode und zu den Modellgewichten für Llama 2-Modelle für Forschungs- und kommerzielle Zwecke bereitgestellt hat, sind Diskussionen darüber aufgekommen, ob es angemessen ist, es aufgrund bestimmter Einschränkungen in seiner Lizenzvereinbarung als "Open Source" zu bezeichnen.
Die Debatte um die Klassifizierung der Lizenzbedingungen von Llama 2 hängt von technischen und semantischen Nuancen ab. Während "Open Source" umgangssprachlich häufig verwendet wird, um jede Software mit frei zugänglichem Quellcode zu bezeichnen, hat es eine spezifische Bedeutung als formale Bezeichnung, die von der Open Source Initiative (OSI) überwacht wird. Um als "von der Open Source Initiative genehmigt" zu gelten, muss eine Softwarelizenz die zehn Kriterien erfüllen, die in der offiziellen Open Source Definition (OSD) dargelegt sind.
Daher hängt die Anwendbarkeit des Labels "Open Source" auf Llama 2-Modelle davon ab, ob seine Lizenzbedingungen mit den strengen Kriterien der OSI übereinstimmen. Diese Unterscheidung unterstreicht die Bedeutung von Klarheit und Präzision bei der Diskussion über die Zugänglichkeit und Verteilung von Softwareressourcen innerhalb der breiteren Entwicklergemeinschaft.
Llama 2 ist jedoch zwar nicht vollständig Open Source, bietet Entwicklern aber ein überzeugendes Modell mit deutlich mehr Flexibilität als die geschlossenen Modelle, die von OpenAI, Google und anderen großen Akteuren im Bereich der generativen KI entwickelt wurden.
Llama 2-Architektur
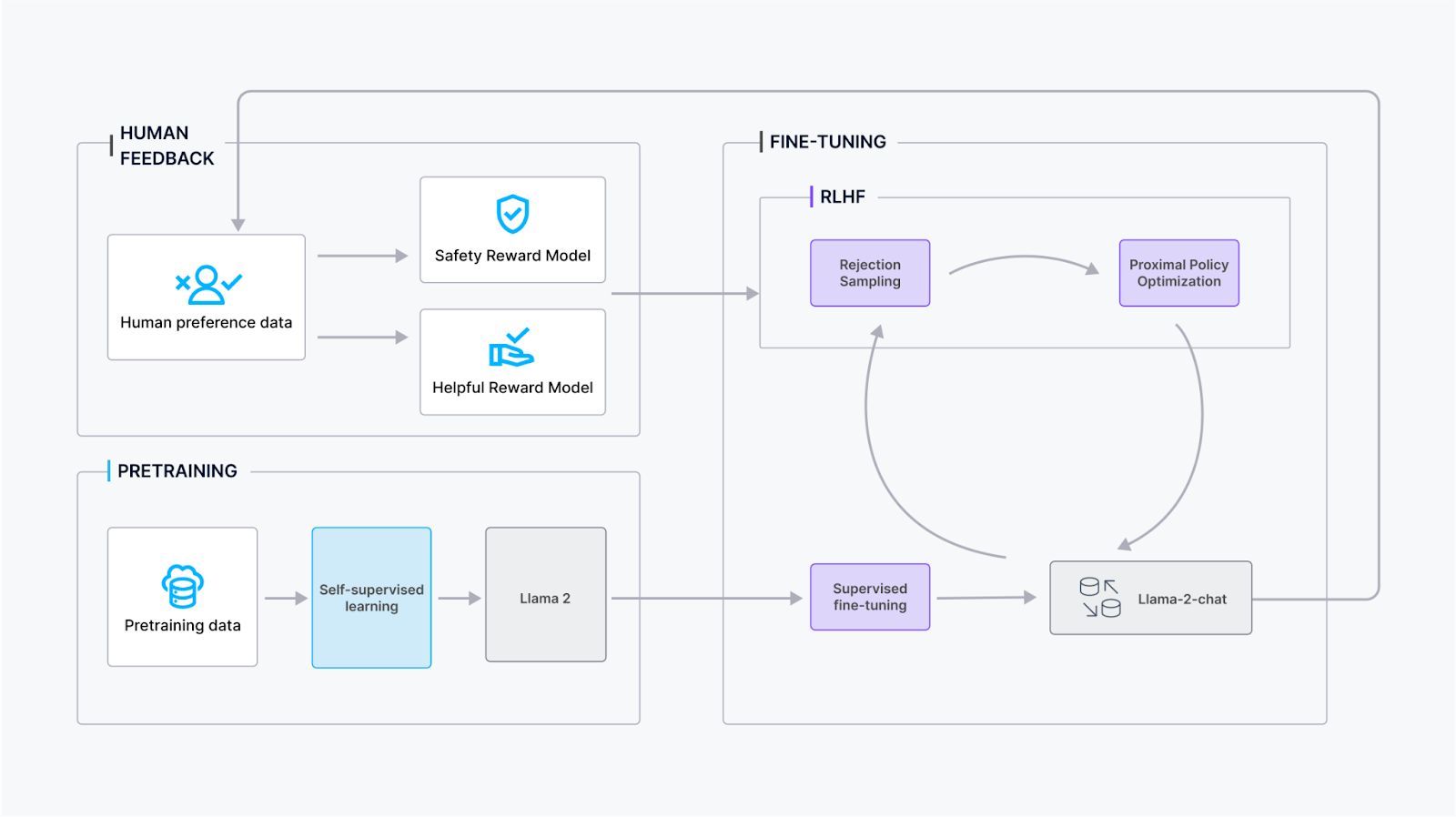
Der Trainingsprozess für Llama 2-Chat umfasst mehrere Phasen, um optimale Leistung und Verfeinerung sicherzustellen:
Vortraining: Llama 2 durchläuft ein Vortraining unter Verwendung öffentlich verfügbarer Online-Quellen, um grundlegendes Wissen und Sprachverständnis aufzubauen.
Überwachtes Fine-Tuning: Das Meta-Team erstellte eine erste Version von Llama 2-Chat durch überwachtes Fine-Tuning, bei dem das Modell aus gekennzeichneten Daten lernt, um seine Konversationsfähigkeiten zu verbessern.
Reinforcement Learning with Human Feedback (RLHF): Das Modell durchläuft eine iterative Verfeinerung mithilfe von RLHF-Methoden, hauptsächlich durch Rejection Sampling und Proximal Policy Optimization (PPO). Diese Phase beinhaltet eine kontinuierliche Interaktion mit menschlichem Feedback, um die Konversationsqualität zu verbessern.
Iterative Reward Modeling: Während der gesamten RLHF-Phase erfolgt die iterative Akkumulation von Reward-Modeling-Daten parallel zu Modellverbesserungen. Iteratives Reward Modeling stellt sicher, dass Reward-Modelle innerhalb der Verteilung bleiben, und trägt so dazu bei, die Konversationsfähigkeiten des Modells kontinuierlich zu verbessern.
Durch die Einbeziehung dieser Schritte zielt das Training von Llama 2-Chat darauf ab, eine robuste Konversationsleistung zu erreichen, während es sich an Benutzerfeedback anpasst und die Ausrichtung an Reward-Modellen beibehält.
Was ist ein Embedding im maschinellen Lernen?
Im maschinellen Lernen bezeichnet ein Embedding eine erlernte Darstellung von Objekten in einem kontinuierlichen Vektorraum, wie etwa Wörter, Bilder oder Entitäten. Diese Embeddings erfassen semantische Beziehungen und Ähnlichkeiten zwischen Objekten und machen sie dadurch besser für rechnerische Aufgaben geeignet. In der Verarbeitung natürlicher Sprache (NLP) ordnen Word Embeddings beispielsweise Wörter aus einem Vokabular dichten Vektoren in einem hochdimensionalen Raum zu, in dem ähnliche Wörter nahe beieinander liegen.
In Llama 2 spielen Embeddings eine entscheidende Rolle beim Verstehen und Generieren natürlicher Sprache. Llama 2 verwendet Embeddings, um Wörter, Phrasen oder ganze Sätze in einem kontinuierlichen Vektorraum darzustellen. Llama 2 kann Text effektiv verarbeiten und generieren, indem sprachliche Eingaben und Ausgaben eingebettet werden und dabei semantische Beziehungen und Nuancen erfasst werden.
Zum Beispiel lernt Llama 2 während des Trainingsprozesses Embeddings für Wörter und Phrasen aus dem riesigen Textkorpus, auf dem es trainiert wird. Diese Embeddings kodieren semantische Informationen über die Sprache, wodurch Llama 2 in der Lage ist, kohärente Antworten auf Anfragen oder Prompts zu verstehen und zu generieren.
Embeddings im maschinellen Lernen, einschließlich der in Llama 2 verwendeten, erleichtern die Darstellung von Sprache und anderen Daten auf strukturierte und semantisch sinnvolle Weise und ermöglichen so eine effektive Verarbeitung, ein effektives Verständnis und eine effektive Generierung natürlicher Sprache.
Wie verwendet man Llama 2?
Um Llama 2 effektiv zu nutzen, greifen Sie über die bereitgestellte Schnittstelle oder API auf das Modell zu und stellen Sie sicher, dass die erforderlichen Berechtigungen vorhanden sind. Bereiten Sie Ihre Eingabedaten vor, ob Text, Bilder oder kompatible Formate, und verarbeiten Sie sie bei Bedarf vor. Geben Sie die Aufgabe für Llama 2 an, z. B. Textgenerierung oder Zusammenfassung. Geben Sie die vorverarbeiteten Daten in Llama 2 ein, rufen Sie die Ausgabe ab und bewerten Sie deren Qualität. Experimentieren Sie mit verschiedenen Formaten und Konfigurationen, um die Ergebnisse zu optimieren. Überwachen Sie Leistungsmetriken wie Genauigkeit und Geschwindigkeit und passen Sie Strategien basierend auf Feedback an. Bleiben Sie über Verbesserungen auf dem Laufenden, um die Effektivität zu maximieren und neue Möglichkeiten für Projekte und Anwendungen zu erschließen. Sie können Llama 2 auch mit Tools wie LangChain, LlamaIndex und Semantic Kernel verwenden, wenn Sie RAG-Anwendungen erstellen.
Leistung von Llama 2
Die Gesamtleistung kann durch die Betrachtung einiger beliebter aggregierter Benchmarks beurteilt werden. Hier ist eine Ergebnistabelle zur Leistung im Vergleich zu Open-Source-basierten Modellen, wie im LLama-2-Paper angegeben:
| Modell | Größe | Code | Alltagslogisches Schließen | Weltwissen | Leseverständnis | Mathe | MMLU | BBH | AGI Eval |
| MPT | 7B | 20.5 | 57.4 | 41.0 | 57.5 | 4.9 | 26.8 | 31.0 | 23.5 |
| 30B | 28.9 | 64.9 | 50.0 | 64.7 | 9.1 | 46.9 | 38.0 | 33.8 | |
| Falcon | 7B | 5.6 | 56.1 | 42.8 | 36.0 | 4.6 | 26.2 | 28.0 | 21.2 |
| 40B | 15.2 | 69.2 | 56.7 | 65.7 | 12.6 | 55.4 | 37.1 | 37.0 | |
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 | |
| 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 | |
| 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 | |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 | |
| 33B | 27.8 | 69.9 | 58.7 | 68.0 | 24.2 | 62.6 | 44.1 | 43.4 | |
| 65B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
Sie können sehen, dass Llama 2 Llama 1 in einer Reihe von Kategorien wie MMLU und BBH übertrifft und sogar im Vergleich zum Falcon-Modell gut abschneidet.
Llama 2 vs GPT 4
Das Llama-2-Paper behandelt auch einige Vergleiche mit Llama 2 und GPT 4 sowie einigen anderen, wie unten gezeigt:
| Benchmark (Shots) | GPT-3.5 | GPT-4 | PaLM | PaLM-2-L | Llama 2 |
| MMLU (5-Shot) | 70.0 | 86.4 | 69.3 | 78.3 | 68.9 |
| TriviaQA (1-Shot) | — | — | 81.4 | 86.1 | 85.3 |
| Natural Questions (1-Shot) | — | — | 29.3 | 37.5 | 33.0 |
| GSM8K (8-Shot) | 57.1 | 92.0 | 56.5 | 80.7 | 56.8 |
| HumanEval (0-Shot) | 48.1 | 67.0 | 26.2 | — | 29.9 |
| BIG-Bench Hard (3-Shot) | — | — | 52.3 | 65.7 | 51.2 |
- MMLU (5-Shot): Dem Modell werden 5 Passagen oder Beispiele gegeben, um eine Antwort zu generieren.
- TriviaQA (1-Shot): Ein Datensatz, bei dem dem Modell ein einzelner Kontext oder eine einzelne Frage bereitgestellt wird, bevor es eine Antwort generiert.
- Natural Questions (1-Shot): Ein weiterer Datensatz, bei dem dem Modell eine Frage als Eingabe gegeben wird.
- GSM8K (8-Shot): Ein Datensatz, bei dem dem Modell 8 Passagen oder Beispiele gegeben werden, um Fragen zu beantworten oder Aufgaben auszuführen.
- HumanEval (0-Shot): Ein Datensatz oder Evaluationssetting, bei dem das Modell anhand von Aufgaben oder Fragen bewertet wird, auf die es nicht explizit trainiert wurde, daher „0-Shot“.
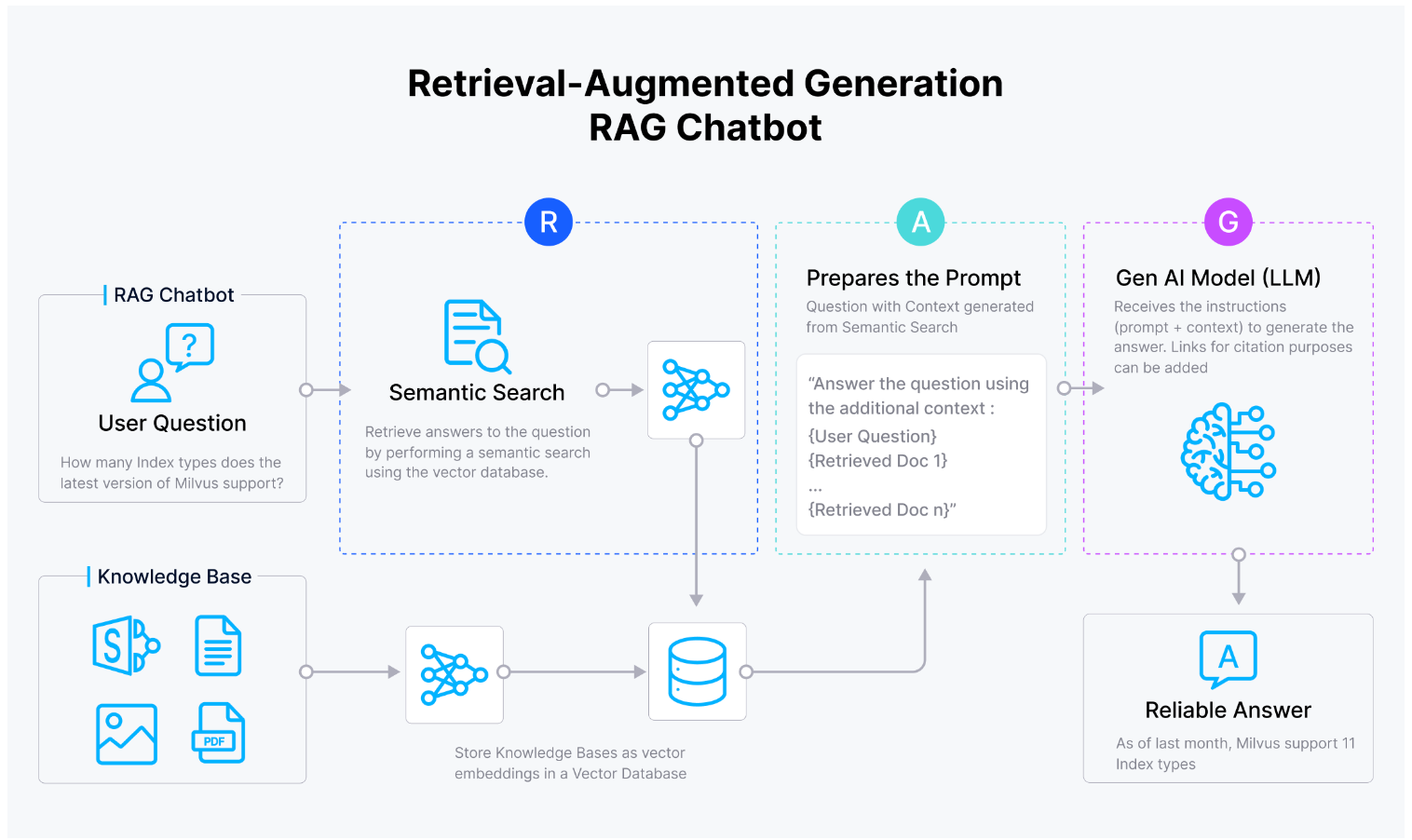
Funktioniert Zilliz mit Llama 2?
Der häufigste Anwendungsfall für Zilliz Cloud in Verbindung mit Llama 2 ist die Entwicklung von Retrieval Augmented Generation-Anwendungen (RAG). RAG-Anwendungen nutzen die Fähigkeiten von großen Sprachmodellen (LLMs) wie Llama 2, die auf riesigen Datensätzen trainiert werden, aber grundsätzlich innerhalb der Grenzen endlicher Daten arbeiten. Für sich genommen neigt Llama 2 dazu, Antworten zu „halluzinieren“ und Antworten zu generieren, selbst wenn möglicherweise nicht genügend Kontext oder genaue Informationen vorhanden sind. RAG ist eine Möglichkeit, diese Halluzination anzugehen.
Die Kombination aus Zilliz Cloud und Llama 2 ermöglicht es Nutzern, fortschrittliche Fähigkeiten zum Sprachverständnis und zur Sprachgenerierung nahtlos mit effizienten und skalierbaren vektorbasierten Retrieval-Systemen zu integrieren, die von Zilliz Cloud bereitgestellt werden. Durch die Nutzung der Stärken beider Plattformen können Entwickler anspruchsvolle Anwendungen erstellen, die bei Aufgaben überzeugen, die umfassende Sprachverarbeitung, Informationsabruf und Generierungsfunktionen erfordern.
Wichtige Ressourcen
- Was ist Llama 2?
- Llama 2-Architektur
- Was ist ein Embedding im maschinellen Lernen?
- Wie verwendet man Llama 2?
- Leistung von Llama 2
- Llama 2 vs GPT 4
- Funktioniert Zilliz mit Llama 2?
- Wichtige Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren