




Batch Processing verstehen: Ein Leitfaden für Einsteiger
Batch Processing verstehen: Ein Leitfaden für Einsteiger
Haben Sie sich jemals gefragt, wie Systeme mit großen Datenmengen umgehen, ohne dabei überfordert zu werden? Eine gängige Methode zur Verwaltung dieser großen Datenmengen ist die Stapelverarbeitung. Bei dieser Methode wird eine riesige Datenmenge in kleinere Teile zerlegt, damit sie leichter zu handhaben ist. Anstatt zu versuchen, alles gleichzeitig zu erledigen, ermöglicht die Stapelverarbeitung es den Systemen, Aufgaben Schritt für Schritt zu bearbeiten, so dass die Dinge reibungslos ablaufen.
Lassen Sie uns die Stapelverarbeitung näher erläutern.
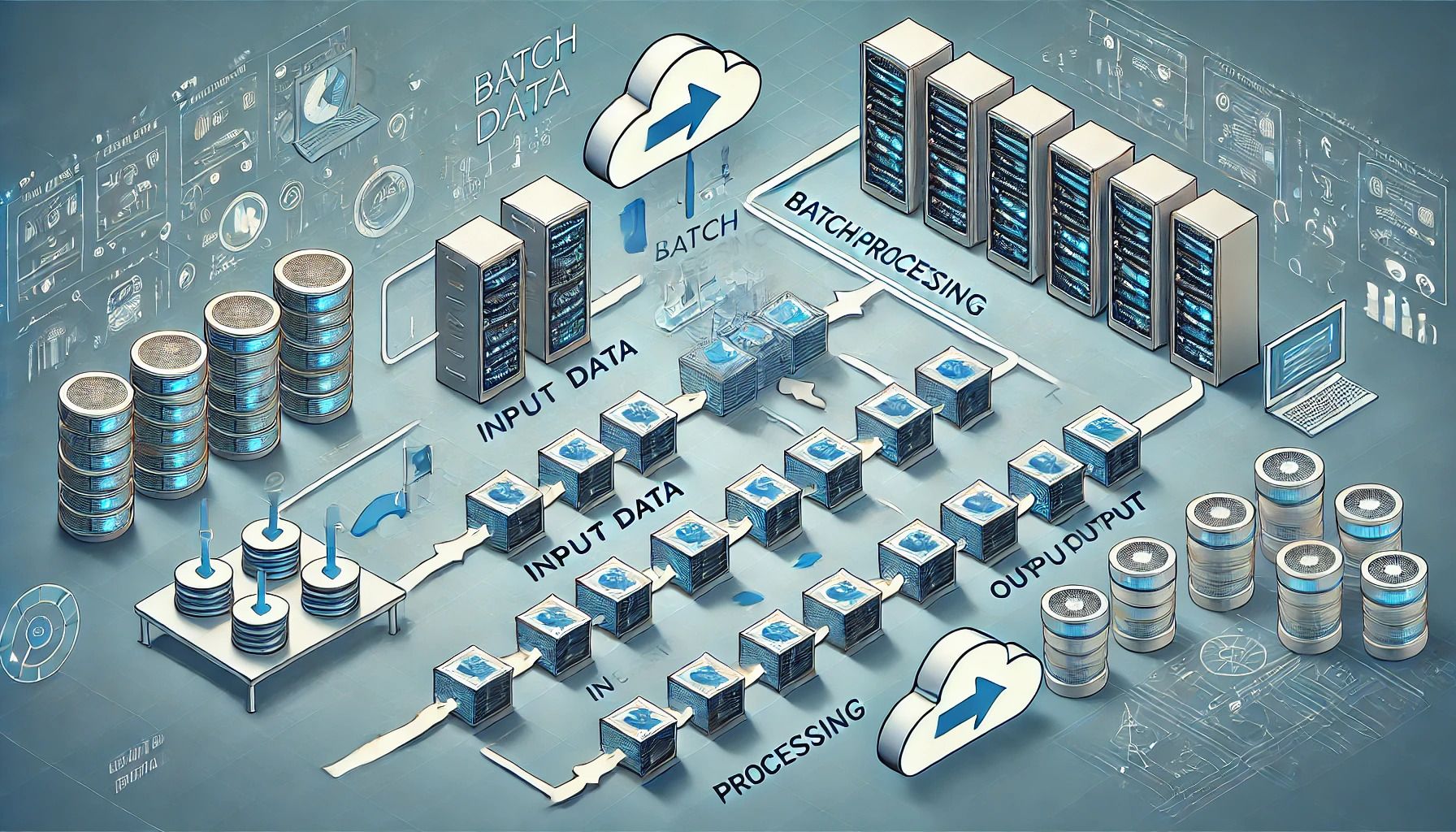 Abbildung 1: Stapelverarbeitung
Abbildung 1: Stapelverarbeitung
Was ist Stapelverarbeitung?
Stapelverarbeitung ist eine Technik, bei der mehrere Aufgaben oder Aktivitäten gemeinsam in einer Gruppe oder einem "Stapel" erledigt werden, anstatt sie einzeln zu bearbeiten. Dieser Ansatz wird häufig in der Computer- und Datenverarbeitung angewandt, insbesondere bei der Verarbeitung großer Datenmengen. Im Gegensatz zur Echtzeitverarbeitung wird bei der Stapelverarbeitung die Arbeit über einen bestimmten Zeitraum angesammelt und zu einem bestimmten Zeitpunkt auf einmal verarbeitet. Diese Methode kann für Aktivitäten nützlich sein, die kein regelmäßiges Feedback oder irgendeine Form der unmittelbaren Interaktivität erfordern.
Die Stapelverarbeitung wird normalerweise angewendet, wenn Prozesse oder Aktivitäten mehrere Iterationen erfordern. Sie wird zum Beispiel in der Gehaltsabrechnung verwendet, wo alle organisatorischen Daten der Mitarbeiter zu einem bestimmten Zeitpunkt auf einmal erfasst werden, anstatt die Daten jedes einzelnen Mitarbeiters während seiner Arbeitszeit zu bearbeiten. Diese Methode optimiert sowohl den Zeitaufwand als auch die Ressourcen, da das System den gesamten Stapel auf einmal verarbeiten kann, was eine größere Effizienz und Verbesserungen bei der gesamten Datenverarbeitung ermöglicht.
Wie funktioniert die Stapelverarbeitung?
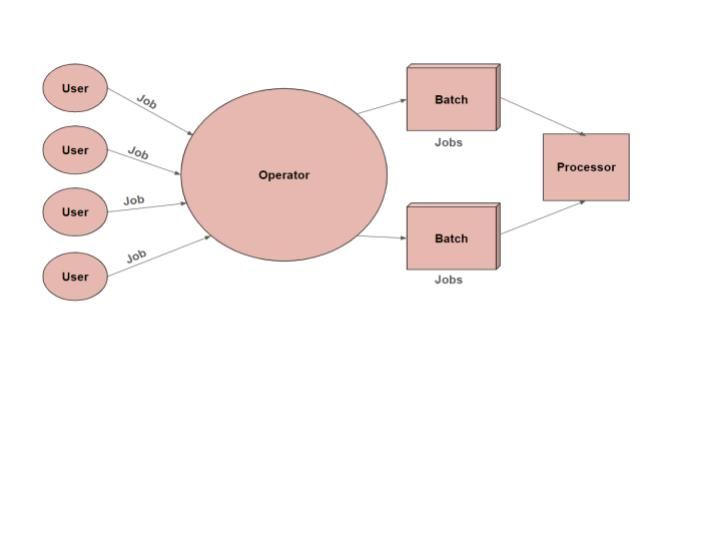 Abbildung 2: Funktionsweise der Stapelverarbeitung
Abbildung 2: Funktionsweise der Stapelverarbeitung
Der Prozess der Stapelverarbeitung läuft im Allgemeinen in folgenden Schritten ab:
Daten sammeln
Zunächst werden die Daten aus verschiedenen Quellen wie Datenbanken, externen Dateien oder anderen Systemen gesammelt. Nach dem Sammeln werden die Daten in Stapeln organisiert, um verwandte Informationen zusammenzufassen. Diese Organisation erleichtert die nächsten Schritte, insbesondere bei der Arbeit mit großen Datenmengen.
Daten vorbereiten
Nach der Erfassung müssen die Daten aufbereitet werden. Dieser Schritt umfasst die Bereinigung von Fehlern oder Unstimmigkeiten, die Überprüfung der Daten auf ihre Richtigkeit und die Sicherstellung einer einheitlichen Formatierung der Daten. Eine ordnungsgemäße Aufbereitung ist wichtig, da sie gewährleistet, dass die Daten für eine reibungslose Verarbeitung bereit sind.
Daten in Stapeln verarbeiten
Sobald die Daten fertig sind, werden sie in Stapeln verarbeitet. Jeder Stapel enthält einen kleineren Teil der Gesamtdaten. Aufgaben wie Berechnungen, Sortierung und Filterung werden auf jeden Stapel angewandt, was die effiziente Verwaltung großer Datenmengen erleichtert.
Fehlerbehandlung
Während der Verarbeitung können aufgrund von Datenproblemen oder Systemausfällen Fehler auftreten. Wenn das passiert, fängt das System diese Fehler ab, protokolliert sie und benachrichtigt die Administratoren. Manchmal versucht das System, den Stapel erneut zu verarbeiten, um einen reibungslosen Ablauf zu gewährleisten.
Ergebnisse generieren
Nach jeder Stapelverarbeitung werden Ergebnisse generiert. Dabei kann es sich um Berichte, Aktualisierungen von Datenbanken oder zusammengefasste Informationen handeln. Die verarbeiteten Daten können auch für spätere Analysen gespeichert oder mit anderen Systemen geteilt werden, damit keine wertvollen Erkenntnisse verloren gehen.
Nachbearbeitung und Bereinigung
Sobald alle Stapel verarbeitet sind, werden abschließende Aufgaben wie die Erstellung von Berichten oder die Archivierung der Daten durchgeführt. Alle temporären Dateien, die während der Verarbeitung erstellt wurden, werden bereinigt, um Systemressourcen freizugeben und die Umgebung effizient zu halten.
Aufgaben planen
Batch-Prozesse werden häufig so geplant, dass sie außerhalb der Hauptgeschäftszeiten ablaufen, um die Auswirkungen auf andere Anwendungen oder Benutzer zu minimieren. Die Systeme können effizient arbeiten, ohne den regulären Betrieb zu beeinträchtigen, wenn die Aufgaben in ruhigeren Zeiten geplant werden.
Vergleich mit Stream Processing und Echtzeitverarbeitung
Die Stapelverarbeitung ist eine Methode zur Bearbeitung großer Mengen von Aufgaben in Gruppen und unterscheidet sich erheblich von der Strom- und Echtzeitverarbeitung. Hier ist ein ausführlicher Vergleich:
Stapelverarbeitung vs. Stream-Verarbeitung
Stapelverarbeitung und Datenstromverarbeitung sind beides wichtige Methoden für die Datenverwaltung, die sich jeweils für unterschiedliche Anforderungen eignen. Der Hauptunterschied liegt in der Art und Weise, wie die Daten verarbeitet werden. Bei der Stapelverarbeitung werden große Datenmengen in geplanten Intervallen verarbeitet, was sie für Aufgaben geeignet macht, die keine sofortigen Ergebnisse erfordern. Im Gegensatz dazu werden bei der Stromverarbeitung die Daten kontinuierlich verarbeitet, sobald sie eintreffen, so dass Antworten in Echtzeit möglich sind. **Die Stapelverarbeitung ist ideal für Szenarien, in denen Geschwindigkeit keine Priorität hat, während die Stromverarbeitung für Anwendungen, die schnelle, Echtzeiterkenntnisse erfordern, unerlässlich ist.
 Abbildung 3: Visueller Vergleich von Stapel- und Datenstromverarbeitung
Abbildung 3: Visueller Vergleich von Stapel- und Datenstromverarbeitung
Batch-Verarbeitung vs. Echtzeit-Verarbeitung
Echtzeitverarbeitung und Stapelverarbeitung sind für unterschiedliche betriebliche Anforderungen geeignet. Die Echtzeitverarbeitung verarbeitet Daten sofort, wenn sie eintreffen, und eignet sich daher perfekt für Anwendungen, die ein sofortiges Feedback benötigen, wie z. B. die Live-Überwachung oder die Transaktionsverarbeitung. Dieser Ansatz erfordert fortschrittliche Systeme zur Verwaltung des konstanten Datenflusses.
Bei der Stapelverarbeitung hingegen werden die Daten im Laufe der Zeit gesammelt und in großen Gruppen in geplanten Intervallen verarbeitet. Sie ist ideal für Aufgaben, die keine sofortigen Ergebnisse erfordern, wie z. B. die Erstellung von Berichten oder die Verarbeitung großer Datenimporte, und ist oft effizienter für die [Verwaltung großer Datenmengen] (https://zilliz.com/blog/zilliz-makes-real-time-ai-a-reality-with-confluent).
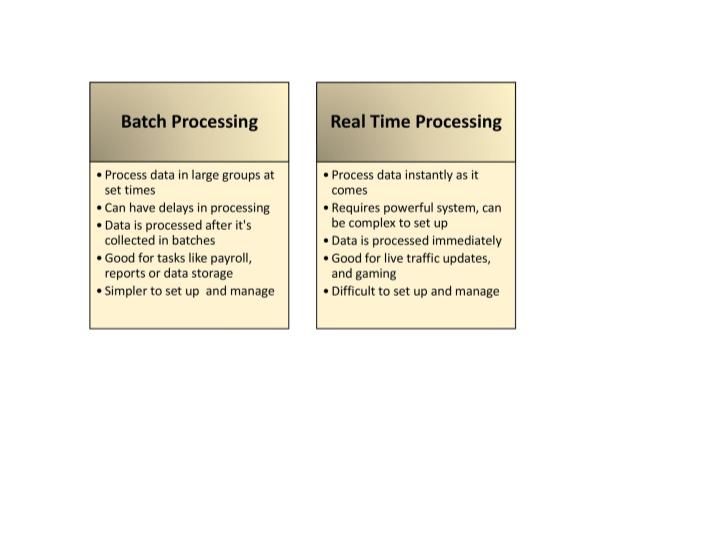 Abbildung 4: Visueller Vergleich von Batch- und Echtzeitverarbeitung
Abbildung 4: Visueller Vergleich von Batch- und Echtzeitverarbeitung
Vorteile der Stapelverarbeitung
Die Stapelverarbeitung bietet mehrere Vorteile, wie z. B. die effiziente Handhabung großer Datenmengen und die optimierte Nutzung von Ressourcen. In der folgenden Liste sind die wichtigsten Vorteile aufgeführt:
Effizienter Umgang mit großen Datenmengen: Die Stapelverarbeitung kann große Datenmengen effizient verarbeiten und ist daher ideal für Aufgaben wie die Erstellung von Berichten oder die Verarbeitung von Massendatenaktualisierungen.
Ressourcenoptimierung: Die Stapelverarbeitung ermöglicht die Planung von Aufgaben außerhalb der Stoßzeiten, wodurch die Systemressourcen optimiert und die Auswirkungen auf die Leistung in Zeiten hoher Nachfrage minimiert werden.
Kosteneffizienz: Da die Stapelverarbeitung Daten in großen Mengen verarbeitet, kann sie bei umfangreichen Operationen kosteneffizienter sein und den Bedarf an kontinuierlicher Systemeinbindung verringern.
Einfachheit: Die Batch-Verarbeitung ist in der Regel einfacher zu verwalten als Echtzeitsysteme, da sie nicht die komplexe Infrastruktur erfordert, die für die Verarbeitung eines kontinuierlichen Datenflusses notwendig ist.
Herausforderungen der Stapelverarbeitung
In der folgenden Liste werden die wichtigsten Herausforderungen im Zusammenhang mit der Stapelverarbeitung aufgeführt:
Verzögerung der Ergebnisse: Die Ergebnisse stehen erst nach der Verarbeitung des gesamten Stapels zur Verfügung, was ein Nachteil für Anwendungen sein kann, die sofortiges Feedback oder Informationen in Echtzeit benötigen.
Komplexe Fehlerbehandlung: Fehler bei der Stapelverarbeitung können schwieriger zu erkennen und zu korrigieren sein, da sie möglicherweise erst nach der Verarbeitung des Stapels sichtbar werden und große Datenmengen betreffen können.
Skalierbarkeitsprobleme: Wenn die Datenmengen wachsen, können auch die Größe der Stapel und die Verarbeitungszeiten zunehmen, was zu Skalierbarkeitsproblemen und längeren Verarbeitungszeiten führt.
Anwendungsfälle der Stapelverarbeitung
Die Stapelverarbeitung wird häufig in Szenarien eingesetzt, in denen die effiziente Verwaltung großer Datenmengen entscheidend ist. Hier sind ein paar gängige Beispiele:
Monatliche Finanzberichte: Erstellung detaillierter Finanzberichte am Ende eines jeden Monats durch Aggregation und Analyse von Daten aus verschiedenen Quellen. Auf diese Weise lässt sich der Finanzstatus des Unternehmens über einen bestimmten Zeitraum zusammenfassen.
Lohn- und Gehaltsabrechnungen: Berechnung von Gehältern, Leistungen und Abzügen für einen ganzen Lohnzeitraum, in der Regel zweiwöchentlich oder monatlich.
Tagesabschlusstransaktionen: Aktualisierung der Kontostände und Erstellung von Zusammenfassungen durch Verarbeitung aller Transaktionen des Tages in Banksystemen oder Einzelhandelsumgebungen.
System-Backups: Durchführung regelmäßiger Backups ganzer Datenbanken oder Dateisysteme, um sicherzustellen, dass die Daten sicher gespeichert sind und bei Bedarf wiederhergestellt werden können.
Kundenfakturierung: Erstellen und Versenden von Rechnungen an mehrere Kunden gleichzeitig, oft in großen Mengen, um die Abrechnungszyklen effizienter zu gestalten.
FAQs zur Stapelverarbeitung
Was ist Stapelverarbeitung und wie funktioniert sie?Bei der Stapelverarbeitung werden Daten in verschiedenen Abständen gesammelt und in großen Gruppen oder "Stapeln" verarbeitet. Dies ist ideal für Aufgaben, die nicht unbedingt zeitkritisch sind, wie z. B. die Erstellung von Berichten, die monatlich erstellt werden, oder Datenimporte, deren Verarbeitung Zeit in Anspruch nimmt. Bei der Stapelverarbeitung werden bestimmte Intervalle festgelegt, in denen große Datenmengen systematisch verarbeitet werden, ohne dass ein ständiges menschliches Eingreifen erforderlich ist. Diese Methode ist besonders wertvoll, um den Umgang mit großen Datenmengen effizient zu optimieren.
Wie unterscheidet sich die Stapelverarbeitung von der Echtzeitverarbeitung?Bei der Stapelverarbeitung werden große Datenmengen zu bestimmten Zeitpunkten verarbeitet. Die Ergebnisse liegen also erst vor, wenn alle Stapel verarbeitet wurden. Bei der Echtzeitverarbeitung hingegen werden die Daten laufend verarbeitet und können sofort beantwortet werden. Die Echtzeitverarbeitung eignet sich daher eher für autonome Anwendungen, bei denen sofortige Antworten erforderlich sind, wie z. B. bei einem Überwachungssystem oder der Online-Transaktionsverarbeitung. Echtzeitsysteme können Daten in Echtzeit verarbeiten und ermöglichen eine Echtzeitausgabe mit angemessenem und unmittelbarem Feedback.
Was sind typische Anwendungsfälle für die Stapelverarbeitung?Die Stapelverarbeitung wird in der Regel für Tätigkeiten wie die Erstellung von Monats-, Wochen- oder Tagesberichten, die Vorbereitung von Mitarbeiterschecks, den Abschluss von Konten usw. verwendet. Sie wird auch bei der Erstellung von Systemsicherungen und der Verarbeitung großer Datenmengen eingesetzt, indem sie in großen Stapeln und nicht kontinuierlich verarbeitet wird.
Kann die Stapelverarbeitung automatisiert werden, und wenn ja, wie?Die Stapelverarbeitung kann durch den Einsatz verschiedener Tools und Software automatisiert werden. Teil- und Stapelverarbeitungsaufträge können mit Hilfe von Automatisierungswerkzeugen und Planungsskripten automatisiert werden, die so programmiert werden können, dass Stapelverarbeitungsaufträge häufig zu vorher festgelegten Zeiten ausgeführt werden, ohne dass der Benutzer eingreifen muss. Die Handhabung und Verarbeitung von Stapelverarbeitungsaufgaben wird einfacher, wenn bestimmte Aufgaben kodiert und automatisiert werden, da sie dann leichter zum gewünschten Zeitpunkt und in der richtigen Weise erledigt werden können. Dies ist besonders nützlich in Szenarien, in denen eine manuelle Bearbeitung unpraktisch wäre, wie z. B. bei der Verarbeitung großer Datenmengen.
Was sind Beispiele für die Stapelverarbeitung?Die Stapelverarbeitung wird in verschiedenen Branchen häufig zur Rationalisierung von Aufgaben und zur Steigerung der Effizienz eingesetzt. So nutzen beispielsweise Kreditkartenunternehmen die Stapelverarbeitung, indem sie für ihre Kunden eine einzige monatliche Rechnung erstellen, in der alle Transaktionen des betreffenden Zeitraums zusammengefasst sind. Anstatt für jede Transaktion eine eigene Rechnung zu schreiben, erhalten die Kunden eine einzige Rechnung, die alle notwendigen Informationen für den gesamten Monat enthält. Die Fertigungsindustrie ist ein weiteres Beispiel für die Verwendung der Stapelverarbeitung bei der Massenproduktion, bei der große Mengen ähnlicher Artikel in einem einzigen Durchgang hergestellt werden.
*# Weitere Ressourcen
Was sind Vektordatenbanken und wie funktionieren sie? ](https://zilliz.com/learn/what-is-vector-database)
Was sind große Sprachmodelle (LLMs)](https://zilliz.com/glossary/large-language-models-(llms))?
Die Wahl zwischen relationalen und Vektor-Datenbanken](https://zilliz.com/blog/relational-databases-vs-vector-databases)
Ressourcen über KI, ML und Vektordatenbanken](https://zilliz.com/learn)
- Was ist Stapelverarbeitung?
- Wie funktioniert die Stapelverarbeitung?
- Vergleich mit Stream Processing und Echtzeitverarbeitung
- Vorteile der Stapelverarbeitung
- Herausforderungen der Stapelverarbeitung
- Anwendungsfälle der Stapelverarbeitung
- FAQs zur Stapelverarbeitung
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren