




Wie Tokopedia mit Milvus ein 10-fach besseres Sucherlebnis erreicht hat
10x klüger
Sucherfahrung
Verbessert
Benutzererfahrung
Erweitert
Skalierbarkeit und Zuverlässigkeit
Our search system has been much more intelligent, stable, and reliable using Milvus.
Rahul Yadav
Über Tokopedia
[Tokopedia] (https://www.tokopedia.com/) ist die größte E-Commerce-Plattform Indonesiens mit unglaublichen 90 Millionen monatlich aktiven Nutzern und einem beeindruckenden Netzwerk von 8,6 Millionen Händlern. Mit einer Reichweite von 98 % der indonesischen Verwaltungsregionen ist Tokopedia zur ersten Adresse für Online-Shopping in Indonesien geworden.
Tokopedia hat erkannt, dass der Wert seines umfangreichen Produktkatalogs darin liegt, dass Käufer mühelos Produkte entdecken können, die auf ihre Vorlieben zugeschnitten sind. Um die Relevanz der Suchergebnisse zu verbessern, hat Tokopedia eine [Ähnlichkeitssuche] (https://zilliz.com/learn/vector-similarity-search) eingeführt.
Wenn der Nutzer auf die Seite mit den Suchergebnissen auf seinem mobilen Gerät navigiert, wird er eine diskrete Schaltfläche "..." sehen. Wenn der Nutzer auf diese Schaltfläche klickt, kann er auf ein Menü zugreifen, das ihm die Möglichkeit bietet, Produkte zu erkunden, die dem von ihm betrachteten Produkt sehr ähnlich sind.
Herausforderungen bei der stichwortbasierten Suche
In der Vergangenheit nutzte die Tokopedia-Suche [Elasticsearch] (https://zilliz.com/blog/elasticsearch-cloud-vs-zilliz) als primäre Engine für die Produktsuche und das Ranking. Jede Suchanfrage löste eine Anfrage an Elasticsearch aus, das die Produkte auf der Grundlage des Suchbegriffs des Benutzers ordnete. Elasticsearch speichert die Schlüsselwörter als Sequenzen von numerischen Werten, die ASCII- oder UTF-Codes für einzelne Buchstaben darstellen. Es erstellt einen invertierten Index zur schnellen Identifizierung von Dokumenten, die Wörter aus der Suchanfrage des Nutzers enthalten, und ermittelt anschließend die besten Übereinstimmungen mithilfe einer Reihe von Bewertungsalgorithmen.
Diese Bewertungsalgorithmen berücksichtigen jedoch in der Regel nicht die Semantik der gesuchten Schlüsselwörter. Stattdessen konzentrieren sie sich auf Faktoren wie die Häufigkeit des Auftretens der Wörter in den Dokumenten, die Nähe der Wörter zueinander und andere statistische Informationen. Obwohl Menschen die Bedeutung hinter der ASCII-Darstellung von Wörtern verstehen können, benötigen Computer einen zuverlässigen Algorithmus, um die Semantik von ASCII-kodierten Wörtern zu vergleichen.
Vektorielle Darstellung
Eine der Lösungen, die das Tokopedia-Team für dieses Problem fand, war die Schaffung einer neuen Art der Darstellung von Schlüsselwörtern, die die Buchstaben eines Wortes zeigt und Informationen über seine Bedeutung liefert. Zum Beispiel könnten sie die häufig verwendeten Wörter mit dem Suchbegriff kodieren, um einen wahrscheinlichen Kontext zu liefern. Von dort aus können sie annehmen, dass ähnliche Kontexte auf ähnliche Konzepte hindeuten, und sie mit Hilfe mathematischer Techniken vergleichen. Es ist sogar möglich, ganze Sätze auf der Grundlage ihrer Bedeutung zu kodieren.
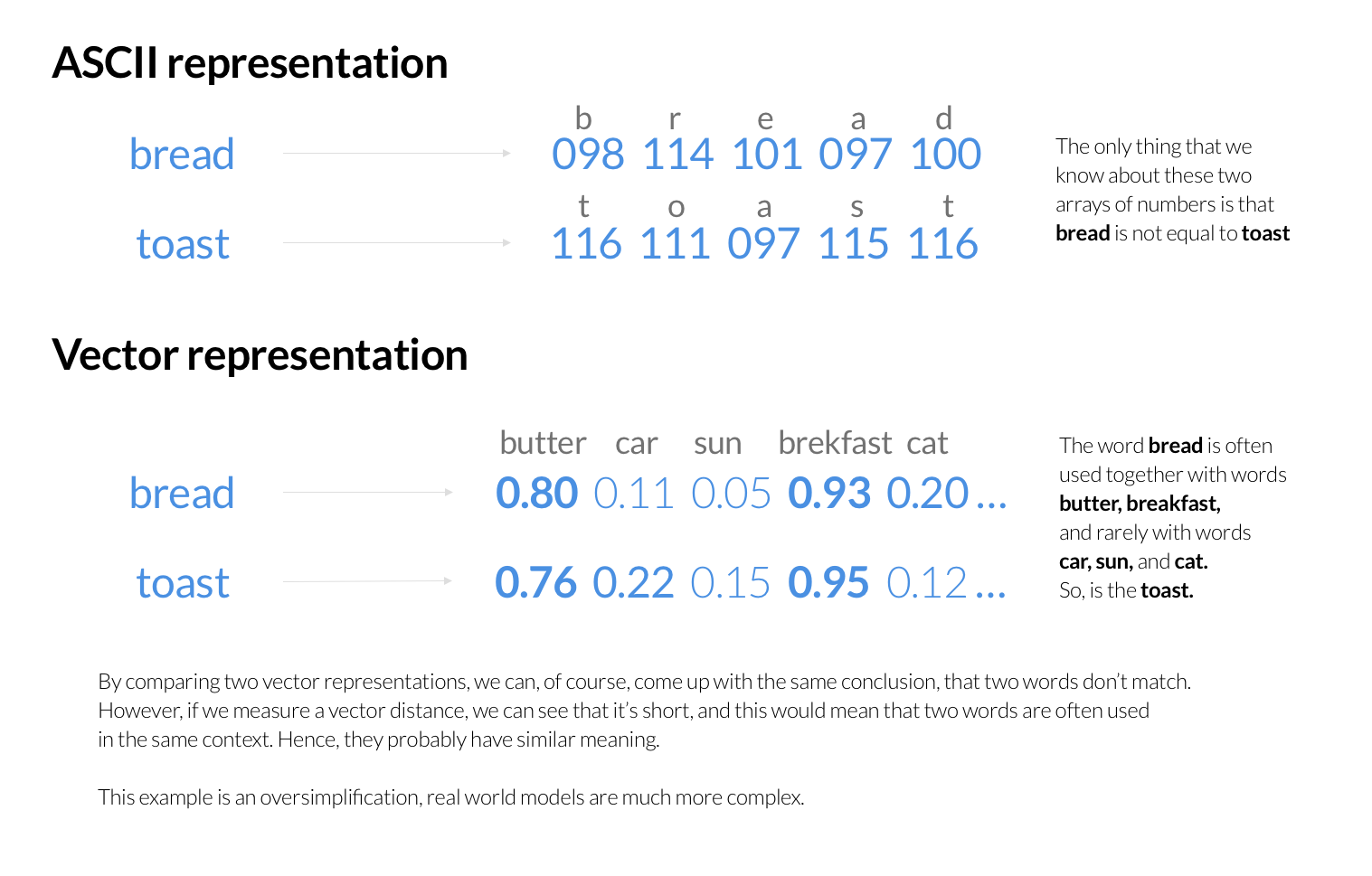
Auswahl von Milvus als Suchmaschine für Vektorähnlichkeit
Da Tokopedia nun über Merkmalsvektoren verfügt, besteht die verbleibende Herausforderung darin, effizient Vektoren aus dem umfangreichen Datensatz abzurufen, die dem Zielvektor genau entsprechen. Bei der Untersuchung von Vektorsuchmaschinen haben wir Proof-of-Concept (POC)-Evaluierungen mit mehreren auf GitHub verfügbaren Vektorsuchstacks durchgeführt, darunter FAISS, Vearch und Milvus.
Basierend auf unseren Lasttestergebnissen tendieren wir zu Milvus. Im Vergleich zu Milvus arbeitet FAISS eher als zugrundeliegende Bibliothek und ist folglich weniger benutzerfreundlich. Als wir uns näher mit Milvus befassten, entschieden wir uns aus den folgenden Gründen für Milvus:
- Milvus erwies sich als bemerkenswert benutzerfreundlich. Sie fanden heraus, dass man nur sein Docker-Image ziehen und die Parameter an seine spezifischen Anwendungsfälle anpassen muss.
- Milvus bietet ein breiteres Spektrum an unterstützten Indizes**. Neben FAISS, HSNW, DISK_ANN und ScaNN stehen 11 Indizes zur Auswahl.
- Milvus bietet eine umfassende Dokumentation zur Unterstützung der Benutzer bei der Implementierung.
Kurz gesagt, Milvus ist benutzerfreundlich, mit einer klaren Dokumentation und zuverlässigem Community-Support für alle Probleme, die auftreten können.
Milvus in Produktion
Nach der Implementierung von Milvus als Feature-Vektor-Suchmaschine nutzten sie es für ihren Anzeigenservice, um Schlüsselwörter mit niedriger Füllrate mit solchen mit hoher Füllrate abzugleichen. Es wurde ein eigenständiger Knoten in einer Entwicklungsumgebung (DEV) konfiguriert und ausgeführt, der reibungslos funktionierte und eine beeindruckende 10-fach höhere Click-Through-Rate (CTR) und Conversion-Rate (CVR) lieferte.
Es ergab sich jedoch ein potenzielles Problem. Wenn ein einzelner Knoten ausfiel, war der gesamte Dienst nicht mehr zugänglich. Daher wechselte das Tokopedia-Team zu einer HA-Implementierung von Milvus.
Milvus bietet zwei Werkzeuge: Mishards, eine Cluster-Sharding-Middleware, und Milvus-Helm für eine rationalisierte Konfiguration. Bei Tokopedia werden Ansible-Playbooks für die Einrichtung der Infrastruktur verwendet, was sie dazu veranlasst, ein Playbook zur Orchestrierung der Infrastruktur zu erstellen. Das folgende Diagramm zeigt, wie Mishards funktioniert.
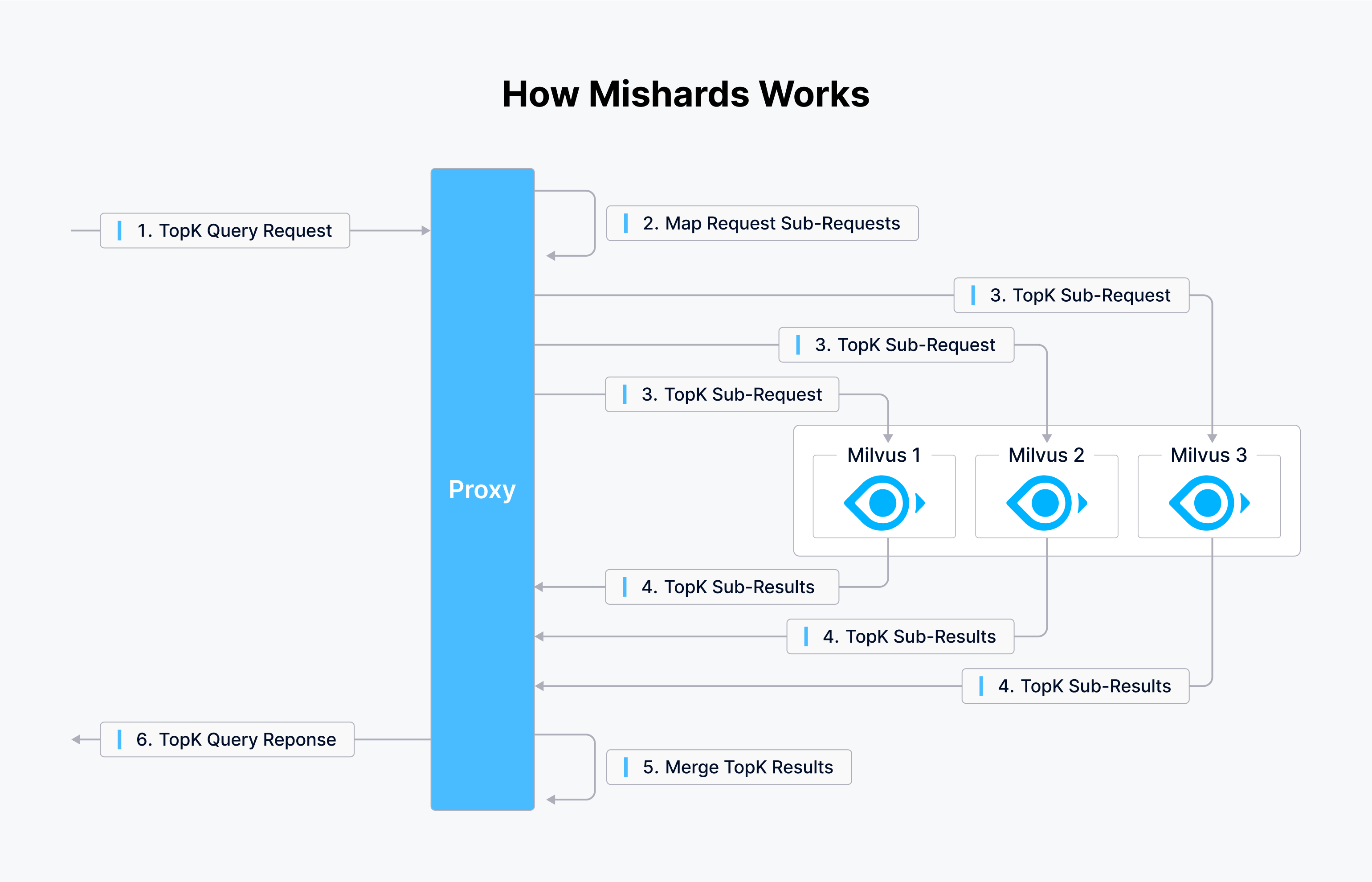
Mishards erleichtert den nahtlosen Fluss von Anfragen vom Upstream zum Downstream, indem es die Upstream-Anfragen in Untermodule aufteilt, Ergebnisse von Unterdiensten sammelt und diese Ergebnisse anschließend an die Upstream-Quelle zurückliefert.
Die Architektur der auf Mishards basierenden Clusterlösung ist im Folgenden dargestellt.
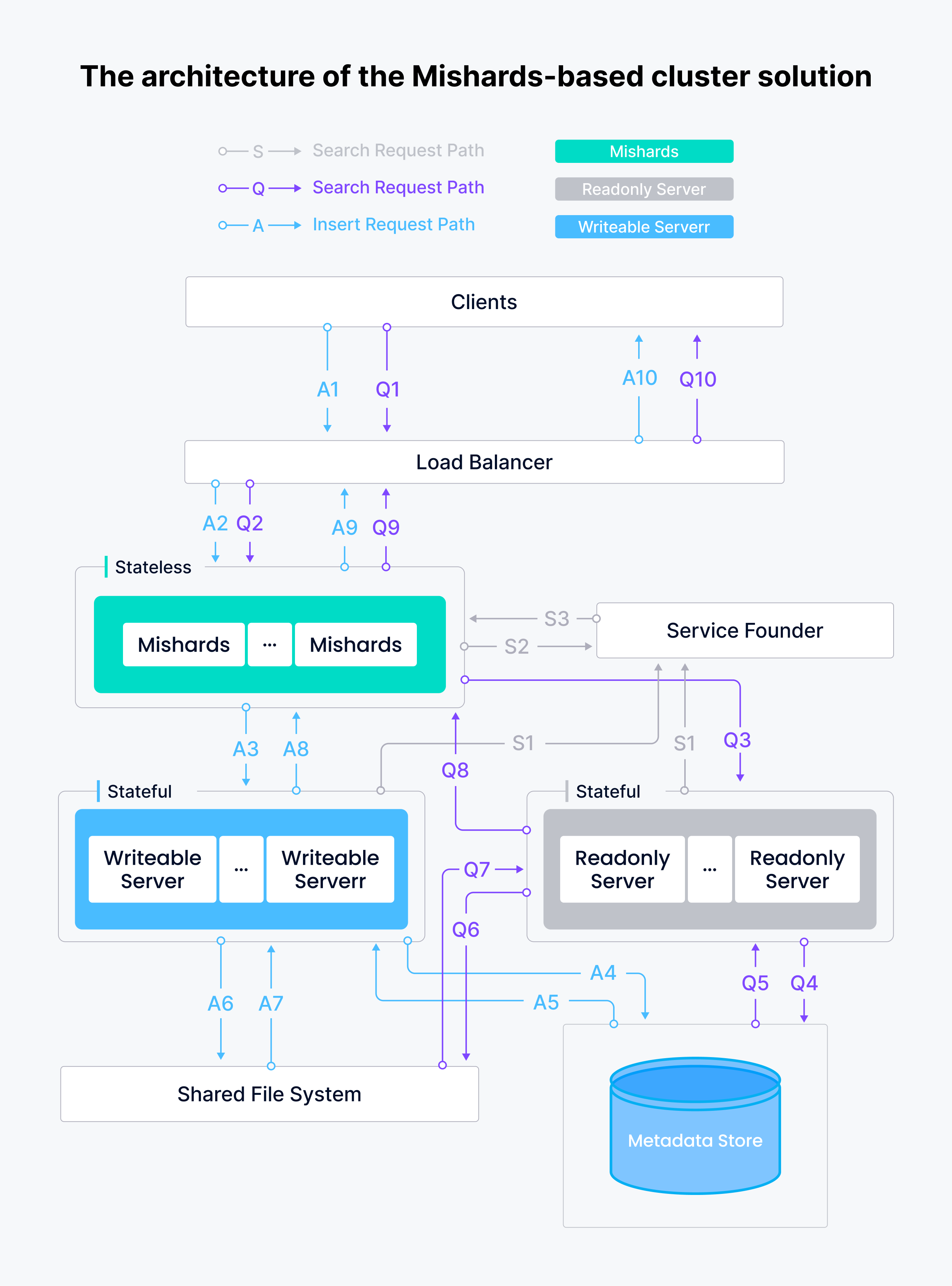
Das System des semantischen Suchdienstes Tokopedia umfasst einen beschreibbaren Knoten, zwei Nur-Lese-Knoten und eine Mishards-Middleware-Instanz, die alle mit Milvus Ansible in GCP bereitgestellt werden. Das System ist deutlich intelligenter, stabiler und zuverlässiger geworden.
Wie beschleunigt die Vektorindizierung die Ähnlichkeitssuche?
Die effiziente Abfrage großer Vektordatensätze in Ähnlichkeitssuchmaschinen erfordert eine angemessene Indizierung. Dieser Prozess organisiert die Daten und beschleunigt den Suchprozess, so dass er für die Bearbeitung von Datensätzen mit Millionen, Milliarden oder sogar Billionen von Vektoren unerlässlich ist. Nach der Indizierung eines riesigen Vektordatensatzes können Abfragen auf Cluster oder Teilmengen von Daten gelenkt werden, die mit hoher Wahrscheinlichkeit Vektoren enthalten, die der Eingabeanfrage ähnlich sind. Dieser Ansatz kann jedoch zu Lasten der Genauigkeit gehen, um schnellere Abfragen bei großen Vektordaten zu erreichen.
Zum besseren Verständnis kann man sich die Indizierung wie die alphabetische Sortierung von Wörtern in einem Wörterbuch vorstellen. Wenn Sie ein Stichwort nachschlagen, können Sie schnell zu einem Abschnitt navigieren, der nur Wörter mit demselben Anfangsbuchstaben enthält, was die Suche nach der Definition des eingegebenen Wortes erheblich beschleunigt.
Zusammenfassung
Tokopedias Streben nach einer überragenden Suchfunktionalität führte sie zu Milvus, einem Wendepunkt in der semantischen Suche. Mit Milvus haben sie die Macht der Vektordarstellung erschlossen und ein 10-mal intelligenteres Suchsystem entwickelt, das die Benutzerfreundlichkeit dramatisch verbessert hat. Der Suchdienst ist außerdem hochverfügbar und gewährleistet einen nahtlosen Betrieb. Diese Reise mit Milvus hat die Suche von Tokopedia verändert und verspricht eine Zukunft mit personalisierten und aussagekräftigen Suchergebnissen. Mit Milvus revolutioniert Tokopedia den elektronischen Handel in Indonesien und darüber hinaus.
*Dieser Beitrag wurde von Rahul Yadav, einem Software-Ingenieur bei Tokopedia, geschrieben. Er wurde bearbeitet und hier mit Erlaubnis wieder veröffentlicht. *