




Wie DiDi Food die Lebensmittelsuche in ganz Lateinamerika mit Milvus transformierte

19% Reduzierung
bei No-Result-Abfragen, die durch die semantische Vektorsuche von Milvus erzielt wurden
4% Steigerung
In-Cart-Conversions durch Milvus-gestütztes semantisches Produkt-Matching
15 % der Abfragen
profitieren Sie jetzt von der Vektorsuche, die die traditionelle Textsuche ergänzt
Vektorabruf im Subsekundenbereich
mit Milvus IVF_FLAT-Indizierung und Inner-Product-Ähnlichkeit
Über DiDi Food
DiDi, ein weltweit führender Anbieter im Bereich Ride-Hailing mit über 800 Millionen Nutzern weltweit, startete DiDi Food—seinen Lebensmittellieferdienst—in 12 großen Städten in Lateinamerika, darunter Mexiko, Kolumbien und Costa Rica. Durch die Nutzung seines bestehenden Logistiknetzwerks und seiner Echtzeit-Optimierungsfähigkeiten erzielte das Unternehmen ein bemerkenswertes Wachstum: 2 Millionen monatlich aktive Nutzer, 500.000 tägliche Bestellungen und über 120 Millionen US-Dollar GMV im ersten Quartal 2025—all das innerhalb von nur sechs Monaten.
Die Plattform liefert frische Lebensmittel und Haushaltswaren in 30–45 Minuten, wobei Partnergeschäfte jeweils bis zu 30 Millionen SKUs anbieten. Mit Aktivitäten in unterschiedlichen Märkten, mehrsprachigen Interaktionen, dynamischer Preisgestaltung und Echtzeit-Bestandsverwaltung baute DiDi Food eine beeindruckende Geschäftsgrundlage auf. Doch mit zunehmender Skalierung wuchs auch die Komplexität, Millionen von Kunden dabei zu helfen, genau das zu finden, was sie in riesigen Produktkatalogen benötigten. An diesem Punkt transformierte die Milvus-Vektordatenbank ihre Suchfunktionen und ermöglichte semantisches Verständnis, das sprachübergreifend funktioniert und mit der realen Unordnung umgeht, wie Menschen tatsächlich suchen.
Die Suchherausforderung: Wenn keywordbasiertes Elasticsearch an seine Grenzen stößt
Das Engineering-Team von DiDi sah sich mit den Einschränkungen konfrontiert, die ihre keywordbasierte Elasticsearch-Datenbank beeinträchtigten. Einfache Rechtschreibfehler, Code-Switching oder unkonventionelle Beschreibungen führten häufig zu leeren Ergebnisseiten und erzeugten Reibung im Einkaufserlebnis.
Hohe „Keine Ergebnisse“-Raten: Der verborgene Umsatzverlust
DiDi Food stand vor einem kritischen Problem: Zu viele Kundensuchen lieferten null Ergebnisse, was zu abgebrochenen Einkaufssitzungen und entgangenem Umsatz führte. Reale Beispiele aus den Suchdaten von DiDi zeigten drei Hauptursachen für diese Fehlschläge.
Tippfehler und Rechtschreibfehler waren die häufigsten Verursacher. Nutzer tippten „Genjibr“, wenn sie nach „Jengibre“ (Ingwer) suchten, „hedaho“ statt „HELADO“ (Eiscreme) oder „Kellongs“ für „Kelloggs“. Ihre bestehenden keywordbasierten Suchsysteme, betrieben mit Elasticsearch, konnten diese kleinen, aber entscheidenden Rechtschreiblücken nicht überbrücken.
Artefakte von Eingabemethoden schufen eine weitere Barriere. Mobile Tastaturen und verschiedene Eingabesysteme erzeugten ungewöhnliche Unicode-Varianten wie „𝑤𝑖𝑛𝑒“ statt „wine“, „𝑏𝑎𝑛𝑎𝑛𝑎“ für „banana“ oder „𝑐ℎ𝑜𝑐𝑜𝑙𝑎𝑡𝑒𝑠“ für „chocolates“. Diese technischen Kodierungsprobleme verhinderten, dass Kunden Produkte finden konnten, die eindeutig auf Lager waren.
Gemischtsprachige Suchanfragen stellten die größte Herausforderung in lateinamerikanischen Märkten dar. Kunden suchten ganz natürlich nach „apple juice orgánico“ oder „leche sin lactosa“ und kombinierten dabei englische und spanische Begriffe. Regionale Unterschiede verschärften dies noch—dasselbe Produkt konnte in Mexiko, Kolumbien und Costa Rica unterschiedliche Namen haben.
Jede fehlgeschlagene Suche bedeutete einen frustrierten Kunden und direkten Umsatzverlust. Für eine Plattform, die 500.000 tägliche Bestellungen verarbeitet, kann selbst ein kleiner Prozentsatz an Suchanfragen ohne Ergebnis erhebliche geschäftliche Auswirkungen haben.
Skalierbarkeit und mehrsprachige Komplexität
Neben einzelnen Suchfehlern stand DiDi vor systemischen Herausforderungen, die seine Skalierungsfähigkeit bedrohten. Die textuelle Indexierung von zig Millionen unterschiedlicher SKU-Namen ließ die Speicherkosten ansteigen und verschlechterte die Abfrageleistung, während sich der Produktkatalog über mehrere Länder hinweg erweiterte.
Die mehrsprachige Komplexität ging tiefer als gemischtsprachige Suchanfragen. Der Betrieb in Mexiko, Kolumbien, Costa Rica und anderen lateinamerikanischen Märkten bedeutete, dass dasselbe Produkt in jeder Region völlig unterschiedliche Namen haben konnte. „Palta“ in einigen Ländern, „aguacate“ in anderen—beides bezeichnet Avocado. Traditionelle keywordbasierte Systeme, betrieben mit Elasticsearch, erforderten die Pflege separater Indizes für jede regionale Variante, was die Speicheranforderungen vervielfachte und die Wartung verkomplizierte.
Kulturelle und sprachliche Nuancen schufen zusätzliche Barrieren. Lokaler Slang, Variationen von Markennamen und sogar unterschiedliche Maßsysteme (metrisch vs. imperial) trugen alle zu Suchfehlern bei. Ein schlüsselwortbasierter Ansatz würde erfordern, Tausende regionaler Varianten manuell zuzuordnen—eine unmögliche Aufgabe in DiDis Größenordnung.
DiDis Engineering-Team benötigte dringend eine Lösung, die diese Herausforderungen überwinden und die Absicht hinter Nutzeranfragen verstehen konnte, unabhängig von Sprache, Region oder davon, wie Kundinnen und Kunden ihre Bedürfnisse ausdrückten.
Die Lösung: Aufbau einer semantischen Suchmaschine mit Milvus
Das von Elasticsearch betriebene System hat Schwierigkeiten mit Sprachvielfalt und variabler Nutzereingabe, weil es Wörter als diskrete Tokens statt als bedeutungsvolle Konzepte behandelt. Vektordatenbanken können jedoch die semantische Bedeutung und Absicht von Nutzeranfragen durch Vektor-Embeddings verstehen und genauere sowie relevantere Ergebnisse zurückgeben, unabhängig von Sprache oder Rechtschreibfehlern.
DiDis Engineering-Team beschloss, eine semantische Suchmaschine aufzubauen, indem es mehrsprachige Embedding-Modelle und eine Vektordatenbank nutzte. Das Embedding-Modell wandelt sowohl Produktnamen und -beschreibungen als auch Nutzeranfragen in Vektor-Embeddings um, die ihre semantische Bedeutung in einem hochdimensionalen Raum darstellen, während die Vektordatenbank diese Embeddings speichert und semantische Suche durchführt, indem sie die Distanzen zwischen Anfragevektoren und Produktvektoren berechnet.
Nach sorgfältiger Evaluierung wählten sie jina-embeddings-v3 als ihr primäres Embedding-Modell, weil es Text aus verschiedenen Sprachen in denselben hochdimensionalen mathematischen Raum abbildet. Das bedeutet, dass Anfragen nach "苹果" (Chinesisch), "apple" (Englisch) oder "manzana" (Spanisch) nahezu identische Vektoren ergeben, wodurch präzises sprachübergreifendes Matching ohne komplexe Übersetzungssysteme ermöglicht wird. Selbst falsch geschriebene oder phonetisch ähnliche Eingaben erzeugen Vektoren, die nahe bei den korrekten Begriffen liegen.
DiDi wählte Milvus als ihre Vektordatenbank aufgrund seiner Open-Source-Reife, der Fähigkeit, horizontal auf Milliarden von Vektoren zu skalieren, Millisekunden-Latenz, bewährten Hochdurchsatzarchitektur und umfangreichen Funktionspalette.
Datenarchitektur und Optimierungsstrategie
Um latenzarme Vektorabfragen über 30 Millionen SKUs hinweg zu unterstützen und gleichzeitig Zuordnungen auf Filialebene beizubehalten, implementierten DiDis Ingenieurinnen und Ingenieure mehrere wichtige Optimierungen.
Anstatt einzelne Vektoren für jede SKU-Filial-Kombination zu speichern, führten sie identische Artikelnamen zu einzelnen Vektoreinträgen zusammen, wobei die entsprechenden Filial-IDs in Arrays gespeichert wurden. Dieser Ansatz reduzierte ihre Vektorbibliothek von 30 Millionen Einträgen auf 200.000 eindeutige Vektoren, wodurch der Speicherverbrauch drastisch gesenkt wurde, während die vollständige Produktabdeckung erhalten blieb.
Das Team wählte eine
IVF_FLAT-Indexkonfiguration in Milvus und priorisierte Suchgenauigkeit gegenüber Kompressionskomplexität. Wenn Nutzerinnen und Nutzer das System abfragen, gibt Milvus die top-k ähnlichsten Vektoren aus dem aggregierten Index zurück, gefolgt von einem schnellen Filial-ID-Filter, um Artikel zu isolieren, die am aktuellen Standort der Käuferin oder des Käufers verfügbar sind.Für die Datenaktualität führte DiDi einen nächtlichen T+1-Aktualisierungszyklus ein. Neue und aktualisierte SKUs werden täglich gebündelt, mithilfe von GPU-Clustern erneut eingebettet und zur Aktualisierung der Milvus-Collection übertragen. Diese Strategie bringt Datenaktualität und Recheneffizienz über ihren riesigen Produktkatalog hinweg ins Gleichgewicht.
Milvus-Schemadesign
Das Collection-Schema spiegelt DiDis spezifische Anforderungen an die Lebensmittelsuche wider und bringt Flexibilität und Leistung in Einklang:
item_name = FieldSchema(
name="item_name",
dtype=DataType.VARCHAR,
is_primary=True,
max_length=1000
)
vector = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
shop_info = FieldSchema(
name='shop_info',
dtype=DataType.ARRAY,
element_type=DataType.INT64,
max_capacity=4096)
schema = CollectionSchema(
fields=[item_name, vector, shop_info],
description="embedding using jina-embeddings-v3",
enable_dynamic_field=True
)
prop = {"shards_num": 1}
try:
collection = Collection(name=collection_name, schema=schema, using='default', properties=prop,
dimension=1024)
except CollectionNotExistException:
return False
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024},
}
collection.create_index(field_name="vector", index_params=index_params)
utility.index_building_progress(collection_name)
return collection
GPU-beschleunigte Embedding-Generierung
Die anfängliche CPU-basierte Embedding-Generierung mit dem Modell jina-embeddings-v3 führte zu einer inakzeptablen Latenz von 5 Sekunden pro Datensatz. Um Echtzeit-Performance zu erreichen, stellte DiDi GPU-Instanzen auf seiner Luban-Plattform bereit und reduzierte die Embedding-Zeit auf etwa 50 Millisekunden pro Abfrage:
from transformers import AutoModel
jina_model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
jina_model.to("cuda")
def get_jina_embedding(item_name):
vec = []
try:
vec = jina_model.encode(item_name, task="text-matching")
except Exception as e:
print(e)
return vec
Hybrid-Search-Pipeline-Architektur
Anstatt ihre bestehende Infrastruktur vollständig zu ersetzen, implementierte DiDi Milvus als intelligente Ergänzung zu ihrem etablierten Elasticsearch-System. Das Dual-Pipeline-Design ermöglicht es Elasticsearch, standardmäßige Keyword-Abfragen zu verarbeiten, während Milvus semantisches Verständnis für komplexe Fälle bietet.
Der Suchablauf erfolgt in den folgenden Schritten:
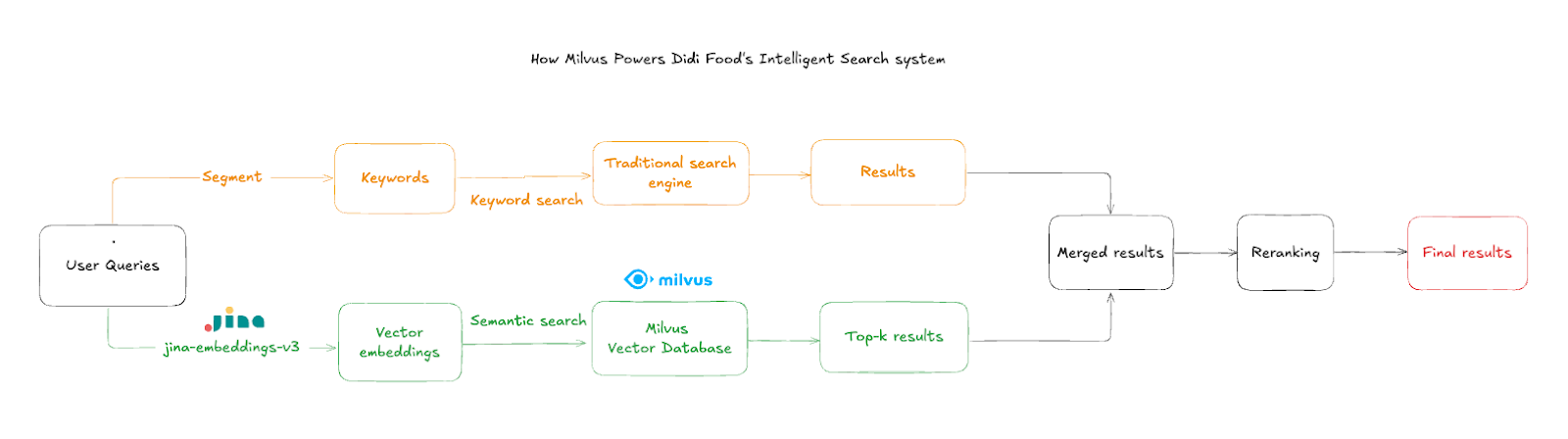
Eingabe der Nutzerabfrage: Kunden geben Produktnamen oder Beschreibungen ein, häufig mit Tippfehlern oder gemischten Sprachen
Text-Embedding: Das System verwendet
jina-embeddings-v3, um Eingaben innerhalb von ~50 ms in hochdimensionale semantische Vektoren umzuwandelnÄhnlichkeitssuche: Milvus fragt die aggregierten Produktvektoren ab, um die nächsten semantischen Treffer zu finden
Filtern nach Filiale: Ergebnisse werden nach Filial-ID gefiltert, um sicherzustellen, dass nur vorrätige Artikel in der aktuellen Filiale angezeigt werden
Zusammenführen der Ergebnisse: Vektorergebnisse werden mit Elasticsearch-Ergebnissen kombiniert, wenn die traditionelle Suche unbefriedigende Ergebnisse liefert, und bieten so ein reichhaltigeres, vollständigeres Sucherlebnis
Entscheidend für das Nutzererlebnis ist das Filtern auf Filialebene, das sicherstellt, dass die Ergebnisse zum aktuellen Standortkontext des Käufers gehören. Das System nutzt intelligente Ergebnisaggregation – wenn Elasticsearch unbefriedigende Ergebnisse liefert, ergänzen die semantisch relevanten Artikel von Milvus die Antwort.
Performance-Ergebnisse und Auswirkungen in der Praxis
Die Milvus-Implementierung von DiDi erzielte konkrete Verbesserungen bei wichtigen Geschäftskennzahlen.
Das System erreichte eine Reduzierung der Abfragen ohne Ergebnis um 19 %, was bedeutet, dass fast jede fünfte zuvor fehlgeschlagene Suche nun relevante Produkte zurückgibt und damit direkt verlorene Umsatzchancen zurückgewinnt. Für eine Plattform, die täglich 500.000 Bestellungen verarbeitet, stellt diese Rückgewinnungsrate einen erheblichen geschäftlichen Wert dar.
Die Vektorsuche wird bei 15 % aller Suchanfragen ausgelöst und ergänzt die traditionelle Textsuche genau dann, wenn semantisches Verständnis einen Mehrwert bietet, ohne die zentrale Abfrage-Pipeline zu überlasten. Besonders bedeutsam ist, dass Nutzer, denen per Vektor abgerufene Artikel angezeigt werden, einen Anstieg der Warenkorb-Hinzufügungs-Conversions um 4 % zeigen, was belegt, dass eine verbesserte Suchrelevanz zu messbarem Kaufverhalten führt.
Das System verarbeitet nun Suchanfragen in mehreren Sprachen, darunter Englisch, Spanisch, Chinesisch, Koreanisch und Japanisch, mit besonders bemerkenswerten Genauigkeitsverbesserungen für Spanisch, was für DiDis Marktpräsenz in Lateinamerika entscheidend ist. Leistungstests für Mehrsprachigkeit zeigten die Stärke semantischen Verständnisses: Suchen nach "Liquid Foundation" funktionieren gleichermaßen gut, unabhängig davon, ob Nutzer den englischen Begriff, das chinesische "液体妆前乳" oder das spanische "Base de maquillaje líquida" eingeben. Das System überbrückt Sprachlücken, an denen traditionelle Keyword-Ansätze vollständig scheitern würden.
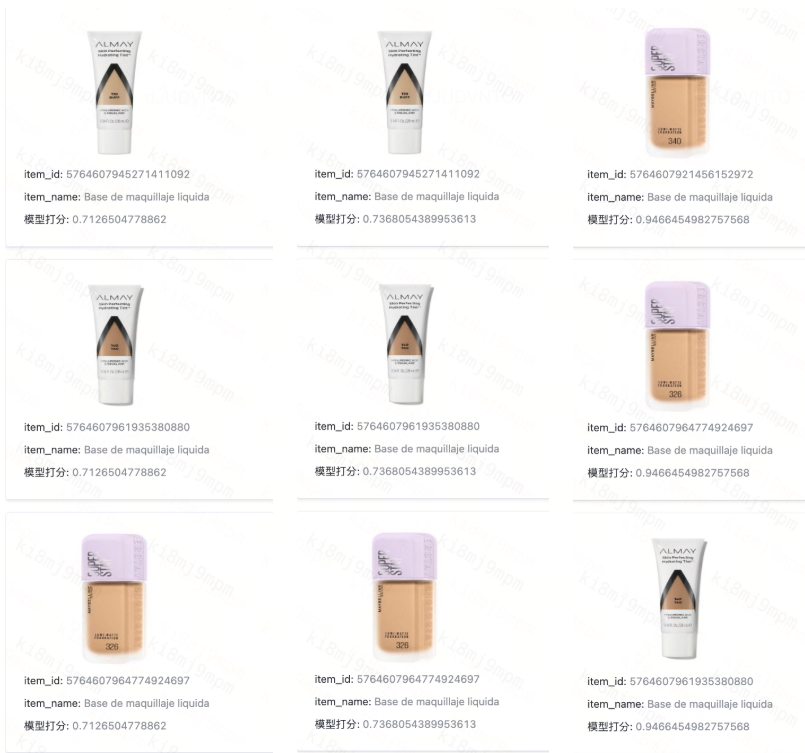
Abbildung: Suchen nach "Liquid Foundation" funktionieren gleichermaßen gut, unabhängig davon, ob Nutzer den englischen Begriff, das chinesische "液体妆前乳" oder das spanische "Base de maquillaje líquida" eingeben.
Komplexe Produktanfragen demonstrieren das kontextuelle Verständnis der Vektorsuche. Wenn Nutzer nach "Redac PalancaPara WC Blanca" (einem weißen Toilettenspülhebel) suchen, ordnet das Vektorsystem die Anfrage trotz der zusammengesetzten technischen Terminologie präzise zu, während die traditionelle Suche die mehrwortige Produktbeschreibung nicht parsen kann.
Diese Verbesserungen führen zu einem reibungsloseren Einkaufserlebnis, höherer Kundenzufriedenheit und einem klaren Wettbewerbsvorteil im E-Commerce-Markt für frische Lebensmittel.
Zukünftige Roadmap: Suchfunktionen der nächsten Generation
Aufbauend auf dieser soliden Grundlage arbeiten DiDi und Milvus an mehreren fortschrittlichen Funktionen für die nächste Entwicklungsphase.
Die Echtzeit-Katalogsynchronisierung wird die Latenz zwischen Bestandsänderungen und durchsuchbaren Daten durch Streaming-Updates reduzieren und so sicherstellen, dass Nutzer niemals Produkte sehen, die tatsächlich nicht verfügbar sind. Die Integration von Verhaltenssignalen wird Vektorähnlichkeit mit Nutzerhistorie, Präferenzen und Kontextsignalen zusammenführen, um hyperpersonalisierte Empfehlungen zu liefern, die sich im Laufe der Zeit verbessern.
Fortschrittliche hybride Suche und Reranking stellen vielleicht die spannendste Entwicklung dar. Dieses System wird Geschäftskennzahlen, darunter Preis, Bewertungen, Werbeaktionen und Lagerbestände, mit semantischer Relevanz verbinden, um für jeden einzelnen Käufer wirklich optimale Empfehlungen anzuzeigen.
Erweiterte Mehrsprachigkeitsunterstützung wird die Sprachabdeckung ausweiten und den Umgang mit regionalen Dialekten verbessern, während DiDi neue Märkte erschließt. Dynamische Embedding-Optimierung wird kontinuierliche Lernmechanismen implementieren, um die Embedding-Qualität auf Basis tatsächlicher Nutzerinteraktionsmuster zu verbessern und dadurch ein Suchsystem zu schaffen, das mit der Nutzung zunehmend intelligenter wird.
Durch kontinuierliche Innovation definiert DiDi das Sucherlebnis für Lebensmitteleinkäufe neu und stellt sicher, dass jeder Käufer jedes Mal genau das findet, was er braucht.
Fazit
DiDi Foods Weg mit Milvus zeigt, dass semantische Suche mehr ist als ein technisches Upgrade — sie ist eine grundlegende Neugestaltung der Art und Weise, wie Nutzer mit großen Produktkatalogen interagieren. Durch die Kombination aus durchdachter Datenarchitektur, geeigneten Technologieentscheidungen und konsequentem Fokus auf die Nutzererfahrung haben sie ein Suchsystem geschaffen, das Absichten über Sprachen und Kulturen hinweg wirklich versteht.
Die Ergebnisse bestätigen diesen Ansatz: weniger frustrierte Nutzer, mehr erfolgreiche Käufe und ein Einkaufserlebnis, das unabhängig davon funktioniert, wie Kunden ihre Bedürfnisse ausdrücken. Für DiDis 2 Millionen monatliche Nutzer bedeutet dies, zuverlässig zu finden, was sie brauchen, wann sie es brauchen, und in der Sprache, die sich für sie am natürlichsten anfühlt.
Diese Erfolgsgeschichte zeigt, was möglich wird, wenn innovative Unternehmen semantisches Verständnis in großem Maßstab nutzen. Während DiDi seine Expansion in Lateinamerika weiter vorantreibt, bietet seine von Milvus unterstützte Sucharchitektur eine robuste Grundlage für kontinuierliche Innovation und Nutzerzufriedenheit. Die Technologie funktioniert, die Geschäftsergebnisse sind eindeutig, und die Verbesserung der Nutzererfahrung ist greifbar – genau das, was großartige Ingenieurskunst leisten sollte.
- Über DiDi Food
- Die Suchherausforderung: Wenn keywordbasiertes Elasticsearch an seine Grenzen stößt
- Die Lösung: Aufbau einer semantischen Suchmaschine mit Milvus
- Performance-Ergebnisse und Auswirkungen in der Praxis
- Zukünftige Roadmap: Suchfunktionen der nächsten Generation
- Fazit
Inhalte
Anwendungsfall
Branche
Elektronischer Geschäftsverkehr
Verwendete Technologie