




Wie Biomap die Entdeckung in den Biowissenschaften im großen Maßstab mit KI-gestützter Vektorsuche mithilfe von Milvus transformiert
22× schneller
Protein-Suchen mit verkürzten Abfragezeiten von 10–20 Minuten auf unter eine Minute.
50 Mrd.+
Sequence Scale wurde von Hunderten Millionen auf Zehnmilliarden biologischer Sequenzen erweitert.
Echtzeit-Erkennung
Antworten im Subsekundenbereich für komplexe biologische Abfragen in RAG-Workflows.
Cross-modale Integration
Proteine, DNA, RNA, Text und zelluläre Daten in einem einzigen durchsuchbaren Framework vereinheitlicht.
Milvus has become the bridge that connects our multi-modal foundation models with real-world applications. It's not just about performance – it's about enabling entirely new approaches to biological discovery that were previously impossible.
Xiaoming Zhang
Über Biomap
Biomap ist ein führendes Life-Sciences-KI-Unternehmen, das sich auf den Aufbau von KI-Modellen konzentriert, die Entdeckungen in der Arzneimittelentwicklung, synthetischen Biologie und medizinischen Forschung beschleunigen. Im Zentrum seiner Plattform steht xTrimo, eine Familie groß angelegter Foundation Models, die speziell für die Biologie entwickelt wurden. Mit einer Skalierung auf bis zu 210 Milliarden Parameter vereint xTrimo Proteine, DNA, RNA, Zellen, Moleküle und wissenschaftliche Texte in einem einzigen Framework und liefert Vorhersagen und Erkenntnisse, mit denen traditionelle Methoden nicht mithalten können.
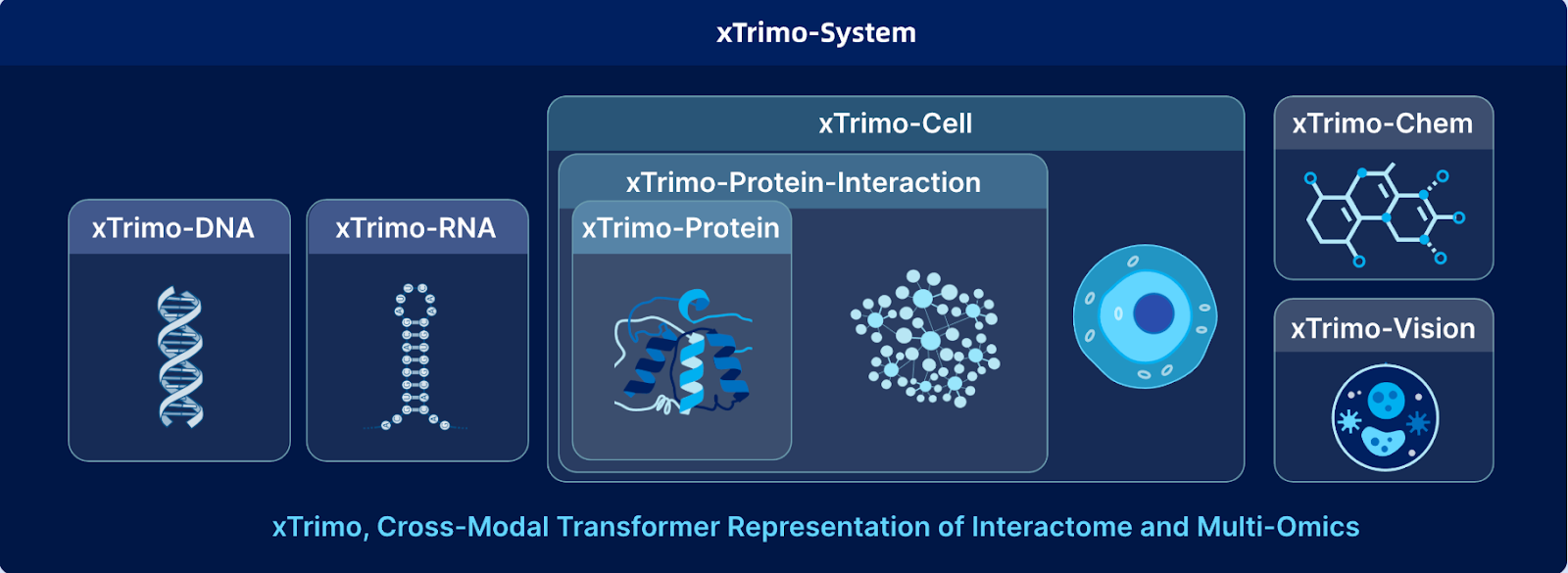
Um diese Fähigkeit zu erreichen, mussten technische Hürden überwunden werden, darunter verrauschte biologische Daten, äußerst vielfältige Formate und die Notwendigkeit, Milliarden von Sequenzen in Echtzeit zu durchsuchen. Biomap begegnete diesen Herausforderungen durch die Entwicklung maßgeschneiderter Embedding-Modelle für biologische Entitäten und den Einsatz fortschrittlicher Dateninfrastruktur, wie etwa der Milvus Vector Database, um eine schnelle und präzise Abfrage in großem Maßstab zu ermöglichen. Auf dieser Grundlage können Forschende nun Durchbrüche in verschiedenen Bereichen beschleunigen, darunter Immunologie, Neurologie, Onkologie und die Behandlung seltener Krankheiten.
Technische Hürden bei der Skalierung biologischer KI
Als Biomap seine KI-Fähigkeiten ausbaute, stieß das Team auf mehrere Engpässe, die traditionelle Tools nicht überwinden konnten.
1. Langsame Proteinsuche
Biomaps Pipeline zur Vorhersage von Proteinstrukturen stützte sich zuvor auf Multiple Sequence Alignment (MSA), das 10–20 Minuten benötigte, um ein einzelnes Ergebnis zurückzugeben. Während dies für Forschung in kleinem Maßstab akzeptabel war, war diese Verzögerung für Produktions-Workloads unpraktikabel, insbesondere bei der Skalierung auf Hunderte Millionen — oder sogar Milliarden — von Sequenzen.
2. Komplexität multimodaler Daten
Biologische Daten liegen naturgemäß in vielen Formen vor — Proteine, DNA, RNA, zelluläre Bildgebung und sogar Text. Traditionelle Suchmethoden waren nicht in der Lage, diese Modalitäten effektiv zu überbrücken, wodurch die Art von modalitätsübergreifenden Erkenntnissen fehlte, die für das Verständnis komplexer biologischer Systeme entscheidend sind.
3. Dilemma zwischen Geschwindigkeit und Genauigkeit
In der biomedizinischen Forschung können kleine Fehler schwerwiegende Folgen haben. Biomaps RAG-basierter Discovery Assistant benötigte sowohl Abfrageantworten im Subsekundenbereich für Interaktivität als auch Genauigkeit auf Forschungsniveau für wissenschaftliche Zuverlässigkeit. Die meisten Lösungen erzwangen jedoch einen Kompromiss zwischen Geschwindigkeit und Präzision.
4. Spezialisierte Datenanforderungen
Biologische Daten weisen einzigartige Eigenschaften auf, die maßgeschneiderte Indexierungsstrategien, domänenspezifische Embedding-Modelle und eine auf wissenschaftliche Workloads abgestimmte Optimierung erfordern — Fähigkeiten, die Standardlösungen nicht bieten konnten.
5. Vielfältige Leistungsanforderungen
Verschiedene Anwendungsfälle von Biomap hatten sehr unterschiedliche Anforderungen: Konversationsassistenten benötigten sofortige Antworten, die Proteinvorhersage konnte Minuten pro Abfrage tolerieren, erforderte jedoch effiziente Stapelverarbeitung, und das Training von Foundation Models verlangte Datenpipelines mit hohem Durchsatz. Die Verwaltung dieser unterschiedlichen Anforderungen innerhalb einer einzigen einheitlichen Infrastruktur erwies sich als besonders herausfordernd.
Warum Biomap Milvus zur Unterstützung biologischer KI in großem Maßstab wählte
Biomap erkannte schnell, dass die Skalierung seiner KI-Workloads eine speziell entwickelte Vektorsuchplattform erfordern würde. Das Team wandte sich zunächst an Faiss, eine beliebte Vektorsuchbibliothek, für Proofs of Concept in kleinem Maßstab. Während Faiss in frühen Experimenten gut abschnitt, versagte es bei Produktions-Workloads und konnte die Anforderungen an Skalierbarkeit, Zuverlässigkeit und Flexibilität realer Life-Sciences-Anwendungen nicht erfüllen. Nach dem Testen mehrerer Alternativen stellte das Team fest, dass Milvus aufgrund der folgenden Faktoren die einzige Lösung war, die alle Anforderungen erfüllte:
Open-Source-Flexibilität: Daten aus den Lebenswissenschaften sind hochspezialisiert und erfordern oft benutzerdefinierte Indizierung und Algorithmen, die auf biologische Anwendungsfälle zugeschnitten sind. Das Open-Source-Design von Milvus gab Biomap die Freiheit, das System ohne Einschränkungen anzupassen und zu erweitern. Wie Xiaoming Zhang, VP of Technology bei Biomap, erklärte: „Wenn es nicht Open Source ist, gibt es wahrscheinlich keinen Spielraum für solche Anpassungen, was nicht zu unseren Szenarien passt.“
Produktionsreife Stabilität: Für Produktionsbereitstellungen benötigte Biomap eine ausgereifte Plattform, die von einer aktiven Nutzerbasis unterstützt wird, insbesondere unter Biotech-Unternehmen im Enterprise-Bereich. Mit einer nachgewiesenen Erfolgsbilanz in verschiedenen Branchen und einer starken Community-Akzeptanz unter Biotech-Unternehmen bot Milvus die Zuverlässigkeit und Ökosystem-Unterstützung, die Biomap benötigte.
Umfassender Funktionsumfang: Milvus unterstützt eine breite Palette von Indextypen und hybride Suchfunktionen, wodurch die Optimierung von Suchen über Proteine, DNA, RNA, Text und andere Modalitäten hinweg ermöglicht wird – alles innerhalb eines einzigen Systems.
Leistung im großen Maßstab: Von interaktiven Assistenten bis hin zu groß angelegten Proteinsuchen benötigte Biomap eine Infrastruktur, die sowohl Abfragen im Subsekundenbereich als auch massive Batch-Jobs bewältigen konnte. Die horizontal skalierbare Architektur von Milvus stellte eine konsistente Leistung über Workloads hinweg sicher, unabhängig von deren Größe und Umfang.
Community und Partnerschaft: Das Biomap-Team schätzte außerdem die aktive Open-Source-Community von Milvus und das langfristige Partnerschaftspotenzial mit Zilliz, dem Unternehmen hinter Milvus.
Diese Kombination aus technischer Tiefe, Ökosystem-Reife und zukunftsorientierter Unterstützung machte Milvus zur klaren Wahl für die Produktionsinfrastruktur von Biomap.
Wie Biomap Milvus nutzt, um seine biologischen KI-Dienste zu betreiben
Biomap setzte Milvus in drei kritischen Anwendungsfällen ein, von denen jeder eine einzigartige wissenschaftliche Herausforderung adressiert und die zusammen das Rückgrat ihrer biologischen KI-Plattform bilden.
KI-Discovery-Assistent (RAG)
Im Zentrum der Forschungs-Workflows von Biomap steht ein Discovery-Assistent, der von fortschrittlicher Retrieval-Augmented Generation (RAG) angetrieben wird. Der auf LangGraph zur Orchestrierung aufgebaute Assistent zieht Daten aus umfangreichen Sammlungen wissenschaftlicher Literatur, Patenten und spezialisierten biologischen Datenbanken. Solche Daten, die reich an Formeln, Proteinstrukturen und domänenspezifischer Notation sind, werden anschließend in Vektor-Embeddings umgewandelt und in Milvus gespeichert.
Milvus führt hybride Vektor- und Volltextsuchen durch, um die genauesten Ergebnisse für Abfragen innerhalb von Sekundenbruchteilen zu liefern. Dies ermöglicht es Forschern, spezialisiertes biologisches Wissen zu durchsuchen und präzise Antworten in Echtzeit zu erhalten, anstatt Stunden damit zu verbringen, die Literatur zu durchforsten.
Proteinstrukturvorhersage im großen Maßstab
Biomap hat auch die traditionelle Protein-Suchpipeline neu erfunden, indem langsame Methoden des Multiple Sequence Alignment (MSA) durch Vektorsuche ersetzt wurden. Ihre proprietären Protein-Foundation-Models erzeugen hochdimensionale Embeddings, die in Milvus gespeichert und abgefragt werden. Diese neue Architektur erweiterte ihren Suchumfang von Hunderten Millionen auf mehr als 5 Milliarden Proteinsequenzen und ermöglichte Entdeckungen, die zuvor unerreichbar waren. Auch die Leistung verbesserte sich drastisch: Abfragen, die früher 10–20 Minuten dauerten, werden nun in weniger als einer Minute abgeschlossen, mit höherer Genauigkeit dank KI-gesteuerter Ähnlichkeitsmetriken.
Cross-modale Stichprobengenerierung für das Modelltraining
Um die Entwicklung multimodaler Foundation-Models voranzutreiben, verlässt sich Biomap auf Milvus, um Daten über biologische Modalitäten hinweg zu verbinden. Forscher können beispielsweise Zellbilder abrufen, die mit bestimmten Proteinsequenzen verknüpft sind, oder Daten auf molekularer und zellulärer Ebene in einem einheitlichen Vektorraum ausrichten. Diese Fähigkeit unterstützt anspruchsvolle Datenaugmentation und die Entdeckung cross-modaler Assoziationen und beschleunigt das Training von Modellen, die Text-, Sequenz- und Bilddaten miteinander verbinden.
Zusammengenommen zeigen diese Anwendungen, wie Milvus Biomap dabei unterstützt, Skalierbarkeit, Genauigkeit und Geschwindigkeit über verschiedene Bereiche hinweg zu vereinen – von der täglichen Entdeckung bis hin zum Training modernster biologischer Modelle.
Einfluss von Milvus auf Biomaps Plattform
Durch die Einführung von Milvus erzielte Biomap Ergebnisse, die mit herkömmlicher Infrastruktur nicht möglich gewesen wären, und veränderte sowohl die Geschwindigkeit als auch den Umfang ihrer Forschung.
Schnellere Suchen im Milliardenmaßstab
Die leistungsstarke Indexierungs-Engine von Milvus ermöglichte eine 22-fache Beschleunigung bei der Suche nach Proteinsequenzen. Abfragen, die früher 10–20 Minuten dauerten, liefern nun in unter einer Minute Ergebnisse, selbst bei Größenordnungen von 50 Milliarden Sequenzen. Dies entspricht einer mehr als 10-fachen Steigerung der Skalierung – von Hunderten Millionen auf Dutzende Milliarden biologischer Sequenzen – ohne Einbußen bei Genauigkeit oder Zuverlässigkeit.
Intelligentere biologische Entdeckung
Milvus hat auch verändert, wie Biomap an die Entdeckung selbst herangeht. Da die Suchqualität direkt mit der Leistung ihrer Foundation Models verknüpft ist, führen Verbesserungen der Modellgenauigkeit unmittelbar zu besseren Retrieval-Ergebnissen. Dadurch entsteht ein positiver Kreislauf: Mit der Weiterentwicklung der Modelle wird die von Milvus unterstützte Suchmaschine präziser und erschließt wissenschaftliche Erkenntnisse, die statische, alignmentbasierte Methoden niemals erreichen könnten.
Modalitätsübergreifende Durchbrüche
Mit Milvus kann Biomap nun Daten auf molekularer und zellulärer Ebene innerhalb desselben Vektorraums verbinden. Diese „Abflachung“ von Skalierungsunterschieden ermöglicht nahtlose modalitätsübergreifende Suchen und unterstützt das Training ihrer multimodalen Foundation Models der nächsten Generation. Es ist ein grundlegender Schritt hin zu ihrer langfristigen Vision, einen umfassenden KI-Simulator für die Biologie zu entwickeln.
Eine skalierbare Plattform für die Life Sciences
Letztendlich stellt Milvus Biomap die Infrastruktur bereit, um über die interne Forschung hinaus in breitere Anwendungen der Life Sciences zu expandieren. Dieselbe Plattform unterstützt nun maßgeschneiderte Wissensdatenbanken und intelligente Agenten für Pharmaunternehmen, Krankenhäuser und Unternehmen der synthetischen Biologie – und erweitert so die Vorteile schneller, skalierbarer biologischer KI auf das gesamte Ökosystem.
Ausblick
Biomaps Erfolg mit Milvus hat die Grundlage für eine Expansion im gesamten Life-Sciences-Ökosystem geschaffen. Das Team erweitert seine Plattform nun, um eine Vielzahl von Stakeholdern zu bedienen, darunter Pharmaunternehmen, die die Wirkstoffforschung beschleunigen, medizinische Einrichtungen, die die klinische Forschung vorantreiben, Unternehmen der synthetischen Biologie, die das Organismendesign optimieren, und Agrarbiotech-Unternehmen, die genetische Verbesserungen bei Nutzpflanzen vorantreiben. Jeder neue Anwendungsfall baut auf derselben Kerninfrastruktur auf – der Vektorsuche mit Milvus –, die komplexe biologische Daten in großem Maßstab zugänglich und nutzbar macht.
Wie Xiaoming anmerkte: „Milvus ist zur einzigen technischen Wahl für Vektordatenbanken bei unserer bevorstehenden Geschäftsausweitung in der Life-Sciences-Branche geworden.“
Diese Partnerschaft geht über die technische Integration hinaus. Sie schafft eine Grundlage dafür, wie biologische Entdeckung in Zukunft durchgeführt wird: schneller, präziser und in der Lage, Modalitäten zu überspannen, die einst isoliert waren. Während Biomap weiterhin seine Vision eines „KI-Simulators für das Leben“ verfolgt, stellt Zilliz die Vektordatenbank-Infrastruktur bereit, die diese Ambition in die Realität umsetzt und Durchbrüche ermöglicht, die sowohl Wissenschaft als auch Industrie transformieren könnten.
- Über Biomap
- Technische Hürden bei der Skalierung biologischer KI
- Warum Biomap Milvus zur Unterstützung biologischer KI in großem Maßstab wählte
- Wie Biomap Milvus nutzt, um seine biologischen KI-Dienste zu betreiben
- Einfluss von Milvus auf Biomaps Plattform
- Ausblick
Inhalte
Anwendungsfall
Branche
Biowissenschaften
Milvus has become the only technical choice for vector databases in our upcoming business expansion across the life sciences industry.
Xiaoming Zhang