




Wir stellen Loon vor: Eine neue Storage Engine für Vektordaten, die sich ständig verändern
Wichtigste Erkenntnisse
Dies ist ein langer, tiefgehender technischer Einblick, daher hier die wichtigsten Punkte, bevor wir in die Details einsteigen.
- KI-Datensätze sind keine statischen Tabellen. Dieselben Zeilen ändern sich immer wieder, wenn Teams Embedding-Modelle ersetzen, Sparse-Vektoren hinzufügen, Beschriftungen überarbeiten, Labels nachträglich auffüllen, Indizes neu erstellen und Offline-Analysen ausführen.
- Herkömmliche Speicherlayouts scheitern auf drei Arten: Lange Vektorspalten machen Backfills teuer, ein einziges Dateiformat kann sowohl Scans als auch Punktabfragen nicht gut bedienen, und private Datenbankspeicherung zwingt externe Pipelines dazu, zusätzliche Kopien der Wahrheit zu erstellen.
- Loon ist die neue Storage Engine für Milvus und Zilliz Vector Lakebase. Sie basiert auf hybriden Dateiformaten, Zeilen-ID-Ausrichtung und einem Manifest, das den versionierten Zustand des Datensatzes definiert.
- Das Ziel ist, einem einzelnen Vektordatensatz zu ermöglichen, Online-Suche, Offline-Analyse, Backfills, Kompaktierung und externe Compute-Workloads zu unterstützen, ohne Daten ständig zu kopieren, neu zu schreiben oder erneut zu importieren.
Einführung
Eine Zeit lang gab es ein Argument gegen Vektordatenbanken, das vernünftig klang.
Traditionelle Datenbanken speichern bereits Ganzzahlen, Strings, JSON, Blobs und Indizes. Warum also nicht einen _vector_ -Typ hinzufügen, daneben einen ANN-Index erstellen und die Sache damit erledigen?
Für frühe semantische Suche funktioniert das gut genug. Eine Vektorspalte plus ein Index kann eine Demo, eine kleine RAG-Anwendung oder eine interne Suchfunktion unterstützen. Das Problem zeigt sich später, wenn sich der Datensatz weniger wie eine Tabelle und mehr wie ein KI-Datensystem verhält.
Ein produktiver Vektordatensatz hat Zeilen, Primärschlüssel, skalare Felder und abfragbare Spalten. In diesem Sinne sieht er wie eine Datenbanktabelle aus. Aber er hat auch die Größenordnung und Workflow-Form eines Data Lake. Er kann Hunderte Millionen Datensätze enthalten. Er wird wiederholt von Spark, Ray, DuckDB, Trainingspipelines, Evaluierungsjobs und Datenqualitätssystemen gelesen und neu geschrieben.
Er ist außerdem auf Objektspeicher angewiesen. Die Quellobjekte sind häufig Videos, Bilder, PDFs, Audiodateien oder Webdokumente, die in S3, GCS, OSS oder einem anderen Objektspeicher verbleiben. Die Datenbank speichert Referenzen, Metadaten, abgeleitete Features und Indizes. Dann fügt sie Dinge hinzu, für deren Verwaltung als First-Class-Objekte traditionelle Speichermodelle nicht entwickelt wurden: Dense Embeddings, Sparse-Vektoren, Beschriftungen, Vektorindizes, Textindizes, Löschprotokolle, Statistiken, Modellversionen, Parser-Versionen, externe Blob-Referenzen und die Versionsbeziehungen zwischen all diesen Dingen.
Genau dort beginnt „einfach eine Vektorspalte hinzufügen“ zu scheitern. Die Frage ist nicht, ob eine Datenbank Vektorbytes speichern kann. Viele Systeme können das. Die schwierigere Frage ist, ob das Speichermodell damit umgehen kann, wie sich Vektordaten verändern, wie sie abgefragt werden und wie sie im gesamten KI-Datenstack geteilt werden.
Deshalb haben wir Loon entwickelt, die neue Storage Engine für Milvus und Zilliz Vector Lakebase (die nächste Entwicklungsstufe von Zilliz Cloud).
Loon ist auf drei Ideen ausgelegt:
- Verwende unterschiedliche physische Formate für unterschiedliche Arten von Spalten.
- Richte diese Spalten über einen gemeinsamen Zeilen-ID-Raum aus.
- Verwende ein Manifest, um den versionierten Zustand des Datensatzes zu definieren.
Um zu verstehen, warum diese Bausteine wichtig sind, beginnen wir mit einem typischen multimodalen Workflow.
Ein Vektordatensatz ist nie wirklich fertig.
Stellen Sie sich ein KI-Team vor, das einen Videodatensatz für multimodales Training erstellt.
Ein langes Video wird in den Objektspeicher hochgeladen. Eine Pipeline schneidet es anhand von Szenenwechseln, Schnittgrenzen oder Zeitfenstern in Clips. Clips, die zu lang oder zu kurz, verschwommen, dupliziert oder von geringer Qualität sind, werden herausgefiltert. Die verbleibenden Clips werden von einem Ästhetikmodell bewertet, von einem anderen Modell beschriftet, von einem Vision-Language-Modell eingebettet und in einer Vektordatenbank für Suche, Deduplizierung und Filterung von Trainingsdaten gespeichert.
Auf hoher Ebene sieht der Workflow einfach aus:
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
Doch der Datensatz liegt nicht von Anfang an vollständig vor.
- In der ersten Woche darf die Tabelle nur
clip_id,video_id,start_offsetunddurationenthalten. - In der zweiten Woche fügt das Team
aesthetic_scorehinzu. - In der dritten Woche läuft ein Captioning-Modell, und jeder Clip erhält eine
caption. - In der vierten Woche geht das erste Embedding-Modell online, und jeder Clip erhält ein 768-dimensionales CLIP-Embedding.
- Einen Monat später wechselt das Team die Modelle und füllt
embedding_v2nach, nun mit 1024 Dimensionen. - Zwei Monate später wird hybride Suche zur Anforderung, also fügt das Team eine Sparse-Vector-Spalte hinzu.
- Drei Monate später werden Captions menschlich überprüft und müssen direkt korrigiert werden.
Der Datensatz wurde nie abgeschlossen. Er sammelte fortlaufend neue Interpretationen derselben zugrunde liegenden Zeilen an.
Das ist einer der zentralen Unterschiede zwischen Vektordaten und traditionellen Geschäftsdaten. Dieselbe Zeile wird immer wieder neu verarbeitet. Und Skalierung macht daraus statt einer Unannehmlichkeit ein Speicherproblem: Multimodale Datensätze umfassen oft nicht Millionen von Datensätzen, sondern Hunderte Millionen oder Milliarden. LAION-5B ist eine nützliche Referenz für die Form — Milliarden von Bild-Text-Paaren, jeweils mit Metadaten, Captions und Embeddings. Der schwierige Teil ist also nicht das erste Einfügen. Der schwierige Teil ist alles, was passiert, nachdem sich der Datensatz zu entwickeln beginnt. Diese Entwicklung legt drei Probleme offen.
Das erste Problem: lange Spalten machen Write Amplification teuer
Spaltenorientierte Formate wie Parquet eignen sich hervorragend für viele analytische Workloads. Sie funktionieren gut, wenn Schemata relativ stabil sind, Daten häufiger gelesen als neu geschrieben werden, Scans nur eine Teilmenge von Spalten berühren und Kompression wichtig ist. Das ist die Welt, für die viele analytische Formate optimiert wurden.
Vektorzeilen sind viel breiter als analytische Zeilen
TPC-H lineitem ist eine gute Basislinie. Es hat 16 Spalten: Integer-Schlüssel, Dezimalwerte, Datumsangaben, kurze Strings und ein kleines Kommentarfeld. Eine unkomprimierte Zeile umfasst ungefähr 150 Bytes. Nach der Kompression kann sie deutlich kleiner sein. Mit einer 64-MB-Row-Group kann ein Speichersystem Hunderttausende Zeilen in eine Gruppe packen.
Vektordatensätze sehen nicht so aus.
Ein LAION-artiger Bild-Text-Datensatz entspricht viel eher dem, was viele KI-Pipelines heute erzeugen. Jede Zeile enthält weiterhin gewöhnliche Metadaten: eine URL, eine Caption, Breite, Höhe, Qualitätsbewertungen, Labels und so weiter. Doch sobald das Embedding hinzugefügt wird, ändert sich die physische Form der Zeile.
Ein 768-dimensionaler CLIP-Vektor benötigt etwa 1,5 KB in fp16 oder 3 KB in fp32. Diese eine Spalte kann deutlich größer sein als eine gesamte TPC-H-lineitem-Zeile.
Und 768 Dimensionen sind nach heutigen Maßstäben weder ungewöhnlich noch groß. Ein 1024- oder 2048-dimensionales Embedding ist in multimodalen Pipelines üblich. OpenAI’s text-embedding-3-large geht bis zu 3072 Dimensionen, was etwa 12 KB pro Vektor in fp32 entspricht.
Der Vergleich ist deutlich:
| Datensatzform | Ungefähre Zeilengröße | Dominierendes Feld |
|---|---|---|
| TPC-H lineitem | ~150 Bytes unkomprimiert | Skalare und kurze Strings |
| LAION-artige Zeile mit 768-dim fp16-Vektor | ~1,5 KB+ | Embedding |
| LAION-artige Zeile mit 768-dim fp32-Vektor | ~3 KB+ | Embedding |
| Zeile mit 3072-dim fp32-Vektor | ~12 KB+ allein für den Vektor | Embedding |
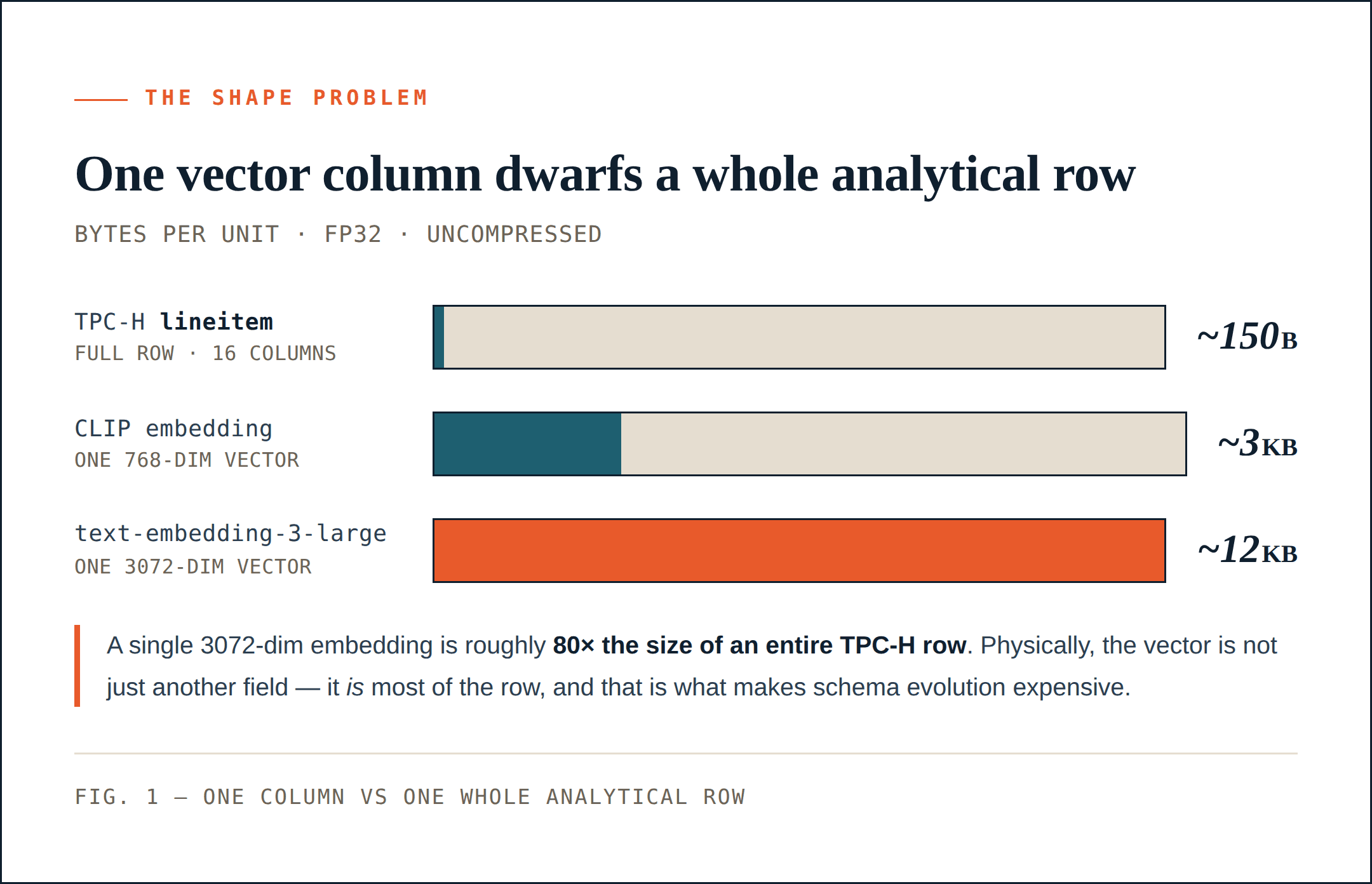
In vielen KI-Datensätzen ist die Vektorspalte nicht einfach ein weiteres Feld. Physisch ist sie der größte Teil der Zeile. Das verändert die Kosten der Schemaentwicklung.
Das Hinzufügen einer einzigen Vektorspalte kann Hunderte Gigabyte bedeuten
Angenommen, ein Datensatz enthält 100 Millionen Videoclips. Das Hinzufügen einer neuen 1024-dimensionalen fp32-Embedding-Spalte bedeutet, ungefähr 400 GB roher Vektordaten zu schreiben. Das umfasst keine Statistiken, Indizes, Metadatenaktualisierungen, Object-Storage-Overhead, Validierung oder Integration in den Serving-Pfad.

Wenn das Team jeden Monat eine oder zwei vektorähnliche Spalten hinzufügt, wie embedding_v2, sparse_vector oder Rerank-Features, wird Schema-Evolution zu einer wiederkehrenden Data-Engineering-Aufgabe, die in Hunderten von Gigabyte oder Terabyte gemessen wird.
Kleine logische Aktualisierungen können große physische Neuschreibungen auslösen
Aktualisierungen sind genauso wichtig.
In spaltenorientierten Systemen werden alte Daten normalerweise nicht direkt vor Ort aktualisiert. Ein Löschprotokoll zeichnet auf, was sich geändert hat, und die Kompaktierung schreibt später aktive Zeilen in neue Dateien um. Dieses Modell ist handhabbar, wenn Zeilen klein sind.
Bei Vektordaten kann eine kleine logische Aktualisierung eine große physische Neuschreibung auslösen.
Ein menschlicher Review-Job korrigiert möglicherweise nur ein paar Hundert Byte in einer Bildunterschrift. Wenn jedoch die Bildunterschrift, der dichte Vektor, der Sparse Vector und andere abgeleitete Features denselben physischen Datei-Lebenszyklus teilen, kann das System am Ende auch die Vektoren neu schreiben. Die logische Änderung ist klein. Der physische I/O kann enorm sein.
Das ist das Problem der Schreibverstärkung in der Vektorspeicherung. Der teure Teil besteht nicht nur darin, dass Vektoren groß sind. Er besteht darin, dass große abgeleitete Felder und kleine veränderliche Felder oft durch ein Speicherlayout miteinander verknüpft werden, das sie als eine Einheit behandelt.
Für AI-Datasets ist Backfill eine Routine-Workload
Bei traditionellen analytischen Tabellen tritt Schema-Evolution möglicherweise nur gelegentlich auf. Bei AI-Datasets ist sie Routine. Caption-Modelle werden aktualisiert. Embedding-Modelle werden ersetzt. Sparse Vectors werden später hinzugefügt. Rerank-Features kommen hinzu. Menschliche Labels werden korrigiert. Governance-Tags werden per Backfill ergänzt. Indizes werden neu aufgebaut.
Diese Operationen sind keine einfachen Appends. Sie ändern oder erweitern häufig bestehende Zeilen.
Deshalb kann Vektorspeicherung nicht nur auf Scan-Durchsatz optimieren. Sie muss auch Backfills und partielle Aktualisierungen günstiger machen.
Das zweite Problem: dieselben Daten müssen Scans und Point Reads unterstützen
Nachdem die Daten geschrieben wurden, teilt sich der Lesepfad auf. Dasselbe Vektor-Dataset hat typischerweise zwei unterschiedliche Zugriffsmuster: analytisches Scannen und Point Reads.

Analytische Workloads wollen breite, komprimierte Scans
Eine Pipeline kann Filter ausführen wie:
WHERE aesthetic_score > 0.8 AND duration > 5
Oder sie kann Offline-Analysen, vollständige Embedding-Evaluierungen, BM25-Statistiken, Bitmap-Erstellung, Datenqualitätsprüfungen, Zählungen und Group-bys ausführen.
Dieses Muster liest viele Zeilen, aber nur wenige Spalten. Es bevorzugt sequenziellen I/O, größere Row Groups, Kompression, Column Pruning, Batch-Decoding und vektorisierte Ausführung.
Große Row Groups helfen hier. Sie ermöglichen es einer einzelnen I/O-Anfrage, eine große Menge nützlicher Daten abzurufen, verbessern die Kompressionseffizienz und stellen der Ausführungs-Engine genügend zusammenhängende Daten bereit, um Overhead zu amortisieren. Wenn mehrere Spalten gemeinsam gelesen werden, hilft ihre Organisation für Scan-Durchsatz auch dabei, Cache Misses während der vektorisierten Ausführung zu reduzieren.
Parquet ist auf diesem Pfad stark.
ANN-Ergebnisse benötigen schmale Lookups auf Zeilenebene
Nachdem die ANN-Suche Kandidaten-Zeilen-IDs zurückgegeben hat, muss das System häufig Felder abrufen wie:
caption
embedding
rerank feature
video_uri
metadata
Dieses Muster liest weniger Zeilen, oft Hunderte oder Tausende, benötigt aber präzisen Zugriff per Zeilen-ID. Es möchte eine bestimmte Zeile und Spalte lokalisieren, nur den erforderlichen Bytebereich abrufen und vermeiden, eine ganze Row Group zu laden, nur um ein paar Datensätze abzurufen.
Point Lookup hat fast die entgegengesetzte Präferenz zum Scannen. Er will eine kleinere Lesegranularität. Idealerweise kann die Speicherschicht das relevante Segment oder den relevanten Bytebereich per Zeilen-ID finden, nur diesen Bereich lesen und nur die Daten dekodieren, die für das Ergebnis benötigt werden.
Auch die Kompression hat einen anderen Trade-off. Für Scans lohnt sich stärkere Kompression oft, weil das System viele Daten liest und I/O spart. Für Point Lookup kann Kompression zur Belastung werden, wenn das Abrufen einer einzelnen Zeile das Dekodieren eines viel größeren komprimierten Blocks erfordert.
Ein Layout kann nicht für beide Pfade optimieren
Dies ist der zentrale Konflikt. Skalare Filterung und Analysen benötigen breite, komprimierte, scan-freundliche Layouts. Vector Lookup benötigt schmale, präzise, zeilenadressierbare Layouts.
Ein einziges Dateiformat kann beides bis zu einem gewissen Grad unterstützen, aber es kann nicht gleichzeitig für beides optimal sein.
Wenn alle Spalten in Parquet liegen, sind skalare Scans komfortabel. Aber ANN Lookup nach dem Recall wird schwieriger. Das System benötigt möglicherweise nur ein paar hundert Vektoren, Captions oder Metadatensätze, während die Speicherschicht möglicherweise große Row Groups lesen muss, die größtenteils irrelevante Zeilen enthalten.
Auf einer lokalen SSD können Cache und mmap einen Teil dieser Kosten verbergen. Sobald die Daten in Object Storage gespeichert sind, werden die Kosten sichtbarer. Jeder Cache Miss kann zu einem entfernten Range Read werden. Wenn Kandidatenzeilen über viele Row Groups verstreut sind, kann eine einzelne Abfrage mehrere Reads auslösen, wobei jeder mehr Daten lädt, als die Abfrage benötigt. In einem schlecht angelegten Layout kann das Abrufen von 1.000 Kandidatenzeilen leicht zu Dutzenden oder Hunderten von Megabyte unnötigem I/O führen, in Extremfällen sogar zu deutlich mehr.
Kleinere Row Groups helfen beim Point Lookup, schaden aber Scans. Zu viele kleine Fragmente reduzieren die Kompressionseffizienz, erhöhen den Metadaten-Overhead und unterbrechen die langen sequenziellen Reads, auf die analytische Engines angewiesen sind.
Das Problem besteht also nicht darin, eine einzige magische Row-Group-Größe zu finden. Das Problem ist, dass derselbe Datensatz dazu gebracht werden soll, sich wie zwei verschiedene Speichersysteme zu verhalten.
Hybrid Search zwingt beide Pfade in eine Abfrage
Hybrid Search macht den Konflikt schwerer zu ignorieren. Eine einzelne Abfrage kann zunächst skalare Filter anwenden:
aesthetic_score > 0.8 AND duration > 5
Dann führt sie ANN Search aus.
Dann ruft sie Caption, Vektor und Metadaten per Row ID ab.
Für den Benutzer ist dies eine Suchanfrage. Für die Speicherschicht ist es sowohl ein analytischer Scan als auch ein latenzarmer Random Lookup.
Deshalb braucht Vector Storage mehr als eine bessere Parquet-Einstellung. Es braucht eine Möglichkeit, verschiedene Spalten entsprechend ihrer tatsächlichen Leseweise zu platzieren.
Das dritte Problem: Der Datensatz lebt nicht innerhalb einer einzigen Engine
Die ersten beiden Probleme treten innerhalb der Datenbank auf. Das dritte entsteht an der Grenze zwischen Systemen.

AI-Datenpipelines erstrecken sich über viele Systeme
Im Video-Workflow passiert nur sehr wenig innerhalb der Vector Database selbst.
Die Rohvideos liegen in Object Storage. Clip-Erzeugung kann in Spark oder Ray laufen. Aesthetic Scoring kann in einem GPU-Service laufen. Captioning kann in einer LLM-Inference-Pipeline laufen. Embeddings können von einem anderen GPU-Job erzeugt werden. Sparse Vectors können aus einem SPLADE-Service stammen. Offline Evaluation, Trainingsdaten-Filterung, Human Review und Governance-Jobs können alle anderswo laufen.
Die Vector Database bedient die Online-Suche, aber der Datensatz wird von vielen Systemen erzeugt, korrigiert, evaluiert und erweitert.
Private Speicherformate erzeugen mehrere Kopien der Wahrheit
Wenn die Datenbank ein privates physisches Format verwendet, das nur sie lesen und schreiben kann, benötigt jeder externe Job einen Export, eine Konvertierung, eine Kopie und einen Import. Dieselbe Collection kann in der Datenbank, in einem temporären Spark-Verzeichnis, in einem Evaluation Output und in einem lokalen Backfill-Verzeichnis existieren. Dann lautet die eigentliche Frage:
- Welche Kopie ist die Source of Truth?
- Welche enthält das Caption-Modell vom letzten Monat?
- Welche Zeilen wurden bereits durch Human Review korrigiert?
- Welche Sparse-Vector-Spalte wurde von welchem Modell erzeugt?
- Welcher Vector Index ist nach dem Backfill noch gültig?
- Auf welches ursprüngliche Videoobjekt verweist diese Zeile?
In kleinem Maßstab können Teams manchmal mit Namenskonventionen und manuellen Prüfungen überleben. Bei Hunderten von Millionen Zeilen und Terabytes an Embeddings wird dies zu einem Konsistenzproblem.
Vector Datasets benötigen einen gemeinsamen versionierten Zustand
Lakehouse-Systeme haben eine Version dieses Problems für strukturierte Daten gelöst. Iceberg, Delta Lake und Hudi drehen sich nicht nur um das Speichern von Dateien. Ihr zentraler Beitrag besteht darin, mehreren Engines zu ermöglichen, sich rund um denselben Tabellenzustand zu koordinieren.
Vektordatenbanken benötigen nun eine ähnliche Fähigkeit, aber der Zustand ist komplexer. Er muss nicht nur Tabellendateien und Partitionen umfassen, sondern auch Vektorindizes, Textindizes, Sparse-Features, Löschprotokolle, Statistiken, Zeilen-ID-Bereiche und Verweise auf externe Blobs.
Die Frage lautet nicht einfach: „Kann Spark Milvus-Dateien lesen?“
Die Frage lautet: Wenn Spark eine Sparse-Vektorspalte nachbefüllt, woher weiß Milvus, zu welcher Version diese Spalte gehört, welche Zeilen sie abdeckt, welches Modell sie erzeugt hat und wann Online-Abfragen sie sicher verwenden können?
Die Antwort muss im Speichermodell liegen.
Warum Patches nicht ausreichen
Es ist verlockend, dies als drei separate technische Probleme zu betrachten.
- Schreibverstärkung? Batching hinzufügen.
- Punktlesevorgänge? Einen Cache hinzufügen.
- Externe Systeme? Export- und Import-Tools hinzufügen.
Diese Patches können helfen, aber sie lösen nicht das zugrunde liegende Problem: Ein Vektordatensatz ist physisch heterogen.

Im Videobeispiel sind clip_id, video_id, duration und aesthetic_score kurze skalare Felder. Sie sind nützlich für Filterung und Analyse.
captionist Text. Er kann für BM25, Prüfung, Korrektur und Nachbefüllung verwendet werden.embeddingist ein langer, dichter Vektor. Er wird für ANN-Recall und später für Lookup auf Zeilenebene oder Reranking verwendet.embedding_v2ist die Ausgabe eines neuen Modells, die oft lange nach dem Einfügen der ursprünglichen Daten nachbefüllt wird.sparse_vectorunterstützt hybride Suche und hat ein eigenes Zugriffsmuster.- Das Rohvideo sollte im Object Storage verbleiben. Die Datenbank sollte einen Verweis, eine Prüfsumme, einen MIME-Typ, eine Parser-Version und eine Beziehung auf Zeilenebene speichern.
- Vektorindizes, Textindizes, Statistiken und Löschprotokolle sind abgeleitete Objekte mit eigener Versionssemantik.
Diese Objekte teilen sich eine logische Zeile, sollten aber nicht alle dasselbe physische Layout oder denselben Lebenszyklus teilen.
- Wenn sie in ein gewöhnliches Tabellenlayout gezwungen werden, werden Updates teuer.
- Wenn sie in ein einziges spaltenorientiertes Dateiformat gezwungen werden, werden Punktlesevorgänge teuer.
- Wenn sie als voneinander unabhängige Objektdateien behandelt werden, wird das Versionsmanagement fragil.
Das Speichermodell muss also von der Tatsache ausgehen, dass der Datensatz heterogen ist.
Daraus ergeben sich drei Designanforderungen:
- Erstens sollten verschiedene Spaltengruppen in unterschiedlichen physischen Formaten gespeichert werden.
- Zweitens benötigen diese Spaltengruppen einen gemeinsamen Zeilen-ID-Raum, damit sie sich weiterhin wie eine einzige logische Tabelle verhalten können.
- Drittens benötigt der Datensatz ein versioniertes Manifest, das deklariert, welche Dateien, Indizes, Protokolle, Statistiken und Objektverweise zur aktuellen Ansicht gehören.
Das ist das Design hinter Loon, unserer neuen Speicher-Engine hinter Milvus und Zilliz Cloud.
Loon: eine Speicher-Engine hinter Milvus und Zilliz Cloud für sich weiterentwickelnde Vektordatensätze
Um all die oben genannten Probleme zu lösen, haben wir Loon entwickelt, die neue Speicher-Engine für Milvus und Zilliz Vector Lakebase (die nächste Evolutionsstufe von Zilliz Cloud), entwickelt für sich weiterentwickelnde Vektordatensätze.
Der Name folgt der Vogelbenennungstradition von Zilliz. Ein Loon ist ein Tauchvogel, der auf Seen lebt, was gut zum Ziel des Systems passt: Eine Vektordatenbank sollte nicht jedes Mal einen ganzen Datensee verschieben, scannen oder neu schreiben müssen, wenn sie eine Abfrage ausführt, eine Spalte nachbefüllt oder einen Index erstellt. Sie sollte zuerst die aktuelle Datensatzversion verstehen, einschließlich ihrer Spalten, Indizes, Statistiken, Löschprotokolle und Objektverweise, und dann nur den Teil lesen, den sie tatsächlich benötigt.
Hybride Dateiformate, Zeilen-ID-Ausrichtung und Manifest sind keine drei separaten Funktionen. Sie ergeben sich aus derselben Designannahme: Ein Vektordatensatz ist von Natur aus heterogen.
Drei Bausteine, ein Speichermodell
Hybride Dateiformate erkennen an, dass unterschiedliche Spalten unterschiedliche Zugriffsmuster haben. Skalare Felder eignen sich gut für Scans und Filter. Vektorfelder benötigen effiziente Lookups auf Zeilenebene. Rohobjekte wie Videos, PDFs, Bilder und Audiodateien gehören in den Objektspeicher, nicht in Datenbankdatendateien.
Die Row-ID-Ausrichtung erkennt an, dass diese Spalten physisch getrennt sein können, aber dennoch dieselben logischen Zeilen beschreiben. Eine Bildunterschrift, ein Embedding, ein Sparse-Vektor und eine Video-URI können sich in verschiedenen Dateien und Formaten befinden, müssen aber dennoch als ein einziges Ergebnis wieder zusammengeführt werden.
Das Manifest erkennt an, dass der Datensatz nicht einmal geschrieben und dann unverändert gelassen wird. Er wird von mehreren Systemen, über mehrere Versionen hinweg und für mehrere Aufgaben geändert. Indizes, Statistiken, Löschprotokolle, externe Objektreferenzen und Spaltengruppen müssen alle in derselben versionierten Ansicht erscheinen.
Deshalb ist Loon nicht nur ein schnelleres Vektordateiformat. Ein schnelleres Format hilft beim Point-Lookup, löst aber weder Schemaentwicklung noch die Koordination mehrerer Engines. Die Row-ID-Ausrichtung lässt aufgeteilte Spalten wie eine einzelne Tabelle wirken, gibt aber nicht an, welche Dateien zur aktuellen Version gehören. Ein Manifest kann einen Datensatzstatus beschreiben, aber ohne Spaltengruppen und Row-ID-Ausrichtung kann es unterschiedliche physische Layouts innerhalb einer logischen Sammlung nicht sauber darstellen.
Das Speichermodell braucht alle drei: unterschiedliche Formate für unterschiedliche Spaltengruppen, einen gemeinsamen Row-ID-Raum zur Rekonstruktion von Zeilen und ein versioniertes Manifest, das jedem Leser und Schreiber mitteilt, was der Datensatz aktuell ist.
Wo Loon in Milvus und Zilliz Vector Lakebase passt
In Milvus ersetzt es die alte Segment-Binlog-Speicherschicht durch ein Modell, das auf Manifest-, ColumnGroup-, Dateiformat- und Dateisystemabstraktionen aufbaut. In Zilliz Vector Lakebase (der nächsten Entwicklung von Zilliz Cloud), gilt dieselbe Richtung für die Vector-Lakebase-Architektur: den Serving-Pfad der Vektordatenbank schnell halten und gleichzeitig die zugrunde liegenden Daten leichter weiterentwickelbar, analysierbar und mit externen Systemen koordinierbar machen.
Die übergeordneten Milvus-Komponenten behalten weiterhin ihre vertrauten Rollen. Proxy übernimmt das Routing. QueryCoord und DataCoord übernehmen die Planung. IndexNode baut Indizes. Die anwendungsseitigen APIs für Collections, Inserts, Suchen und hybride Suchen müssen Manifest-Dateien oder ColumnGroups nicht offenlegen.
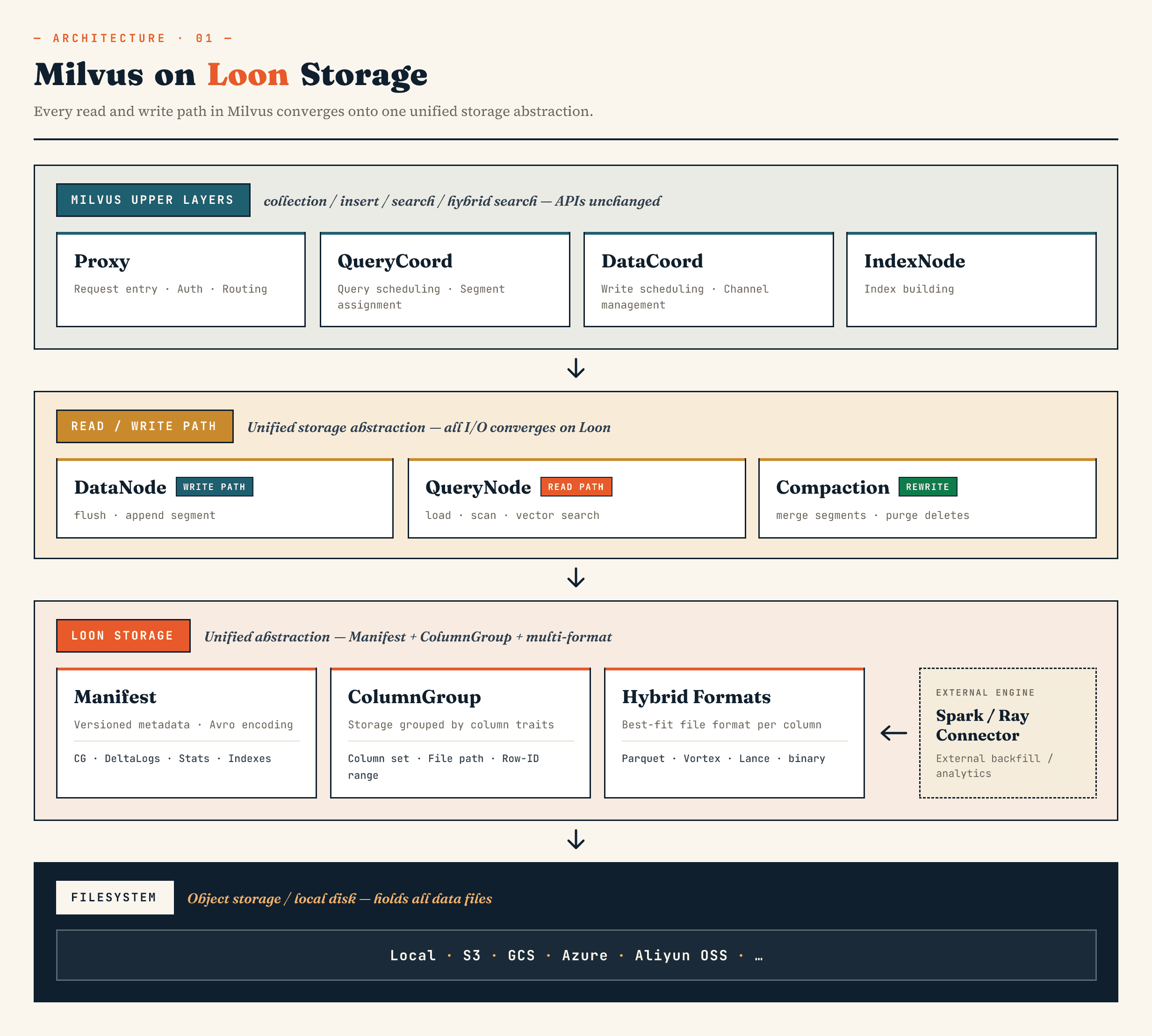
Die Änderung liegt darunter.
DataNode, QueryNode, segcore, Kompaktierung und externe Konnektoren können über dieselbe Speicherabstraktion arbeiten. Das ist wichtig, weil der Datensatz nicht mehr nur von der Datenbank geschrieben und gelesen wird. Er kann von externen Rechensystemen erweitert und gleichzeitig von der Online-Suche konsumiert werden.
Auf hoher Ebene sehen die Schichten so aus:
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
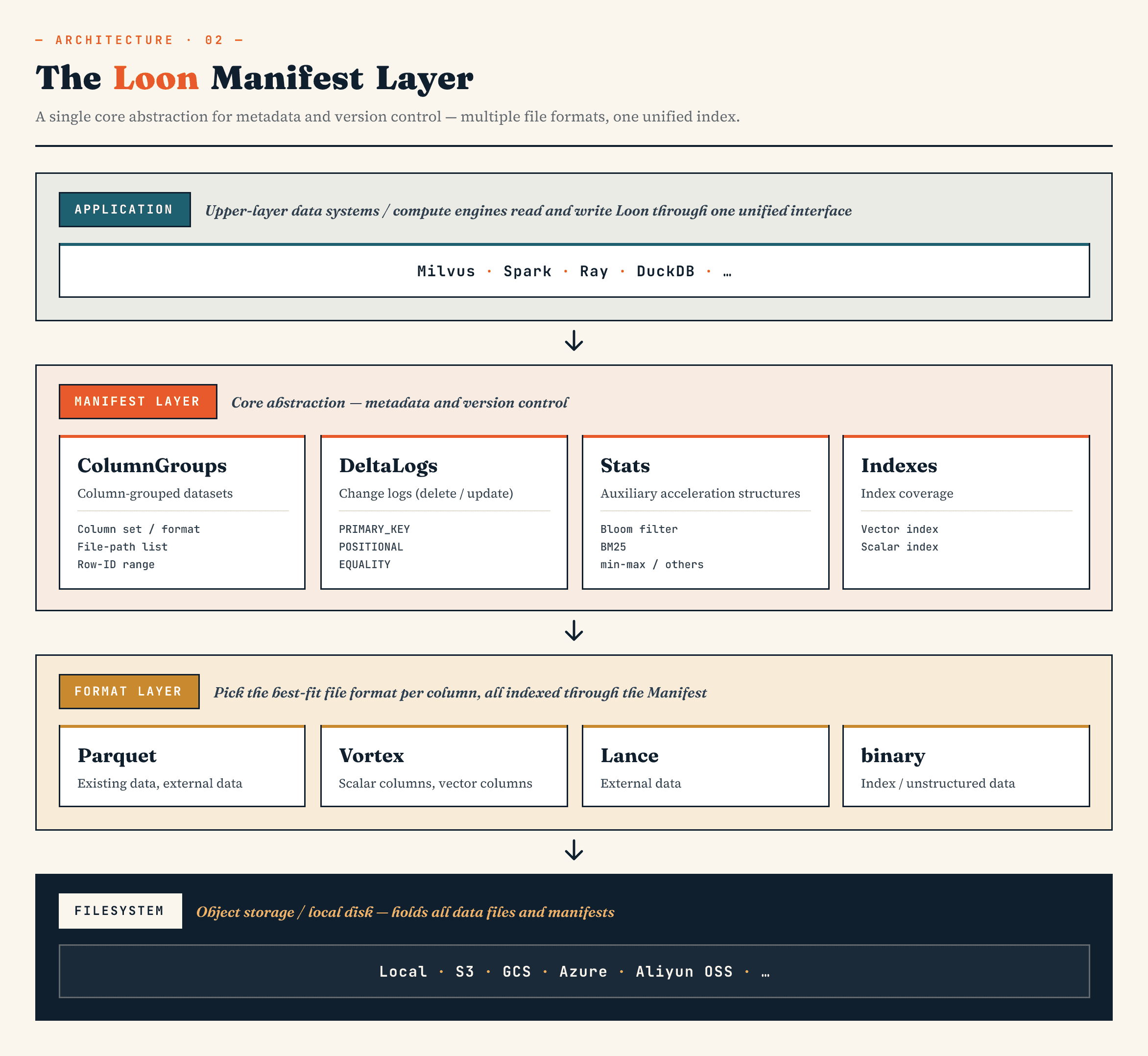
Das Manifest beschreibt den versionierten Zustand des Datensatzes. ColumnGroups ordnen eine logische Collection physischen Spaltengruppen zu. Die Dateiformatschicht lässt jede ColumnGroup ein geeignetes Format wählen. Die Dateisystemabstraktion funktioniert über Objektspeicher und lokalen Speicher hinweg.
Der wichtige Punkt ist, dass hybride Dateiformate, Row-ID-Ausrichtung und Manifest keine separaten Features sind. Zusammen definieren sie das Speichermodell.
Mit diesem Modell können wir die drei Designentscheidungen nacheinander betrachten: wie Loon unterschiedliche ColumnGroups speichert, wie es sie wieder zu Zeilen ausrichtet und wie das Manifest diese Dateien in einen versionierten Datensatz verwandelt.
Design 1: das richtige Dateiformat für die richtige Spaltengruppe verwenden
Unterschiedliche Spalten haben unterschiedliche Zugriffsmuster. Sie sollten nicht in dasselbe Dateiformat gezwungen werden.
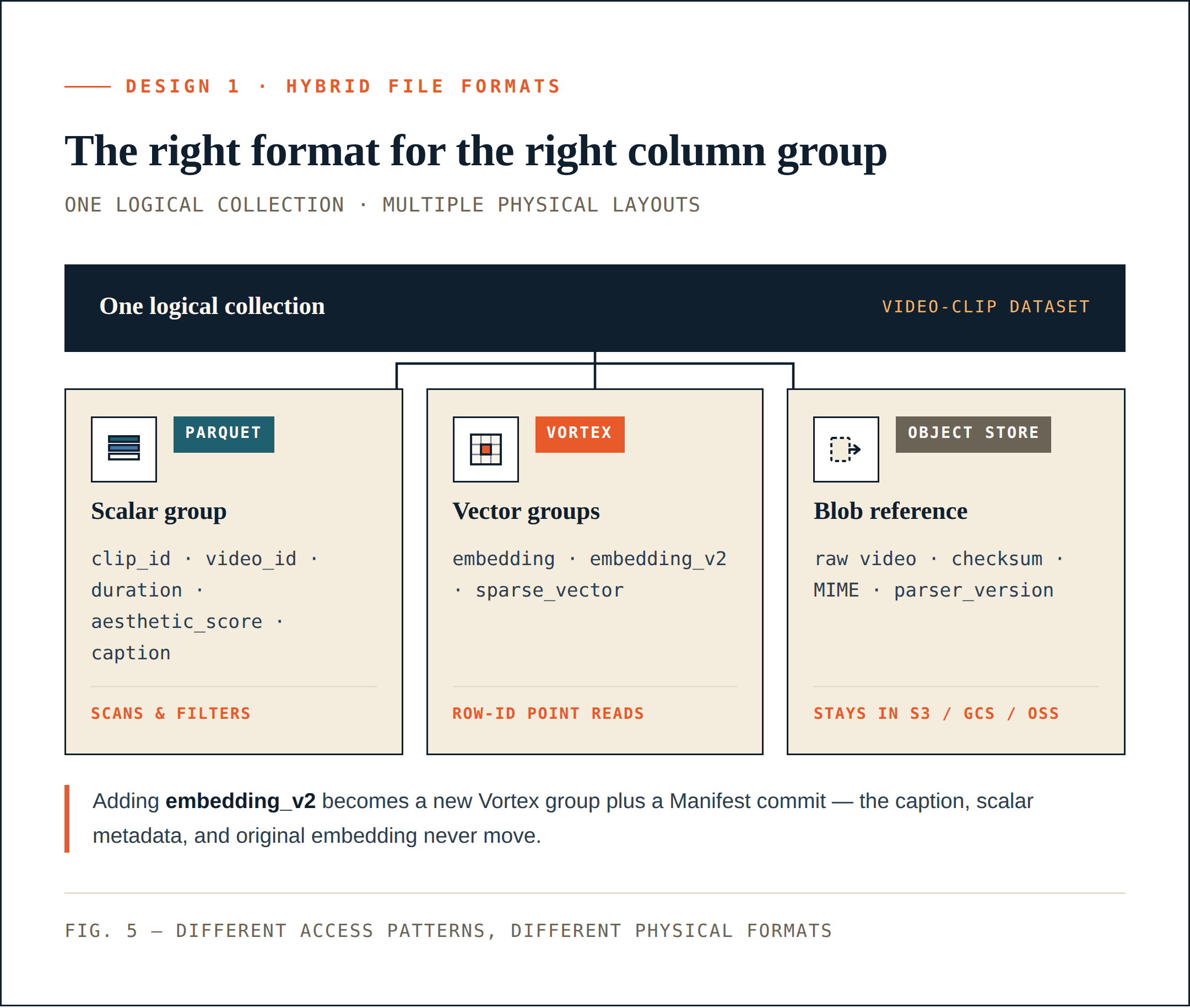
Loon trennt eine logische Sammlung in ColumnGroups.
- Skalare Felder, Filterfelder, Geschäftsschlüssel und statistische Felder werden häufig gescannt, gefiltert, aggregiert oder für die Abfrageplanung verwendet. Sie profitieren von Komprimierung, Spalten-Pruning und Ökosystem-Kompatibilität. Parquet eignet sich gut für diese Spalten.
- Dense Vektoren, Sparse Vektoren und Rerank-Features werden häufig nach dem ANN-Recall anhand der Zeilen-ID gelesen. Sie benötigen zufälligen Zugriff mit niedriger Latenz, präzise Byte-Range-Reads und selektives Decoding. Ein segmentorientiertes Layout eignet sich besser. Loon verwendet Vortex in diese Richtung.
- Rohobjekte wie Videos, PDFs, Bilder und Audiodateien sollten nicht in die Datendateien der Vektordatenbank eingebettet werden. Sie sollten im Object Storage verbleiben. Die Datenbank speichert Referenzen, Prüfsummen, MIME-Typen, Parser-Versionen und Beziehungen auf Zeilenebene.
Für das Videobeispiel könnte ein physisches Layout so aussehen:
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
Für die Anwendung ist dies weiterhin eine Sammlung. Für die Speicherschicht verwenden verschiedene Teile dieser Sammlung unterschiedliche physische Formate. Dies reduziert direkt unnötige Neuschreibvorgänge. Das Hinzufügen von embedding_v2 kann zu einer neuen Vektor-ColumnGroup plus einem Manifest-Commit werden. Es erfordert kein Neuschreiben der Caption-Spalte, der skalaren Metadaten oder der bestehenden Embedding-Spalte.
Dieselbe Idee gilt für Sparse Vektoren, Rerank-Features oder andere abgeleitete Felder. Wenn eine neue Spalte physisch unabhängig sein und über die Zeilen-ID ausgerichtet werden kann, muss sie keine nicht verwandten Spalten durch denselben Rewrite-Pfad ziehen.
Loon passt auch die Verwendung von Dateiformaten an.
Für Parquet sind Standardeinstellungen nicht immer ideal für vektorlastige Daten. Eine 64-MB-Row-Group kann für Point Lookups zu groß sein, da ein kleiner zufälliger Lesevorgang deutlich mehr Daten abrufen kann als nötig. Loon verkleinert Row-Groups in relevanten Pfaden auf 1 MB und deaktiviert Encodings, wie etwa Dictionary Encoding auf Vektorspalten, wenn sie bei zufällig wirkenden Vektordaten nicht helfen.
Für Vortex ist die wichtigere Arbeit das Layout. Loon verwendet ein Layout, das Scan-Effizienz und Point Lookup ausbalanciert. Innerhalb einer Row-Group können Segmente verwandter Spalten nah beieinander platziert werden, um Scans zu unterstützen. Zur Durchführung von Operationen ermöglichen Sub-Segment-Reads dem System, nur die relevanten Bytes abzurufen, anstatt ein gesamtes Segment zu laden.
Loon unterstützt außerdem eine read-only Lance-Integration, sodass bestehende Lance-Datasets als ColumnGroups eingebunden werden können, wenn Kompatibilität wichtig ist.
Was der Benchmark zeigt
In einem lokalen Test mit einer einzelnen Datei mit 40.000 Zeilen und dem Schema {id: int64, name: utf8, value: float64, vector: list<float32>[128]} zeigte Vortex diese Ergebnisse gegenüber Parquet mit 1-MB-Row-Groups:
| Operation | Vortex | Parquet | Unterschied |
|---|---|---|---|
| Take, K=1000 zufällige Zeilen | 5,8 ms | 144 ms | 25x schneller |
| Vollständiger Vektorspalten-Scan | 21 ms | 142 ms | 6,76x schneller |
| Dateigröße, ~21 MB Rohdaten | 6,62 MB | 7,16 MB | 7% kleiner |
Das take-Ergebnis entsteht durch die Reduzierung der Menge irrelevanter Daten, die gelesen und decodiert werden müssen. Das Scan-Ergebnis entsteht durch Komprimierungs- und Implementierungsentscheidungen.
Diese Zahlen sollten an ihre Testumgebung gebunden bleiben: 8 vCPU Ubuntu 22.04 KVM, lokales Dateisystem, eine Datei, 40.000 Zeilen, 1-MB-Row-Groups und das oben genannte Schema. Bei Object Storage kann Netzwerk-I/O dominieren, sodass die Reduzierung der Read Amplification noch wichtiger sein kann. Die tatsächlichen Ergebnisse hängen von der Dataset-Form, dem Verhalten des Object Storage, dem Cache-Zustand und dem Abfragemuster ab.
Der umfassendere Punkt ist nicht, dass jede Spalte Vortex verwenden sollte.
Der Punkt ist, dass Vektordatasets eine Dateiformatwahl auf ColumnGroup-Ebene benötigen.

Design 2: Physische Dateien über Zeilen-IDs ausrichten
Hybride Dateiformate lösen ein Problem: Unterschiedliche Spalten können nun in den Formaten gespeichert werden, die am besten zu ihnen passen.
Doch dadurch entsteht ein zweites Problem. Wenn skalare Felder in Parquet liegen, Vektoren in Vortex und Rohobjekte im Objektspeicher, wie behandelt das System sie dann weiterhin als eine Sammlung?
Loon löst dies durch Zeilen-ID-Ausrichtung.
Zeilen-ID ist das Koordinatensystem der Speicherschicht
Jede physische ColumnGroupFile zeichnet den Dateipfad und den von ihr abgedeckten Zeilen-ID-Bereich auf:
path
start_index
end_index
Verschiedene ColumnGroups können denselben Zeilen-ID-Raum abdecken, selbst wenn sie in unterschiedlichen Dateien und Formaten liegen.
Für Zeilen-ID 12345 können die skalaren Metadaten in einer Parquet-ColumnGroup liegen, das Embedding in einer Vortex-ColumnGroup und das Rohvideo durch eine Objektspeicher-Referenz dargestellt werden. Logisch gesehen sind sie dennoch eine Zeile. Dies gibt der Speicherschicht ein stabiles Koordinatensystem.
Die Zeilen-ID ist nicht der fachliche Primärschlüssel. Sie ist das Koordinatensystem der Speicherschicht, das es Loon ermöglicht, eine Sammlung physisch aufzuteilen, ohne die Fähigkeit zu verlieren, sie logisch zu rekonstruieren.
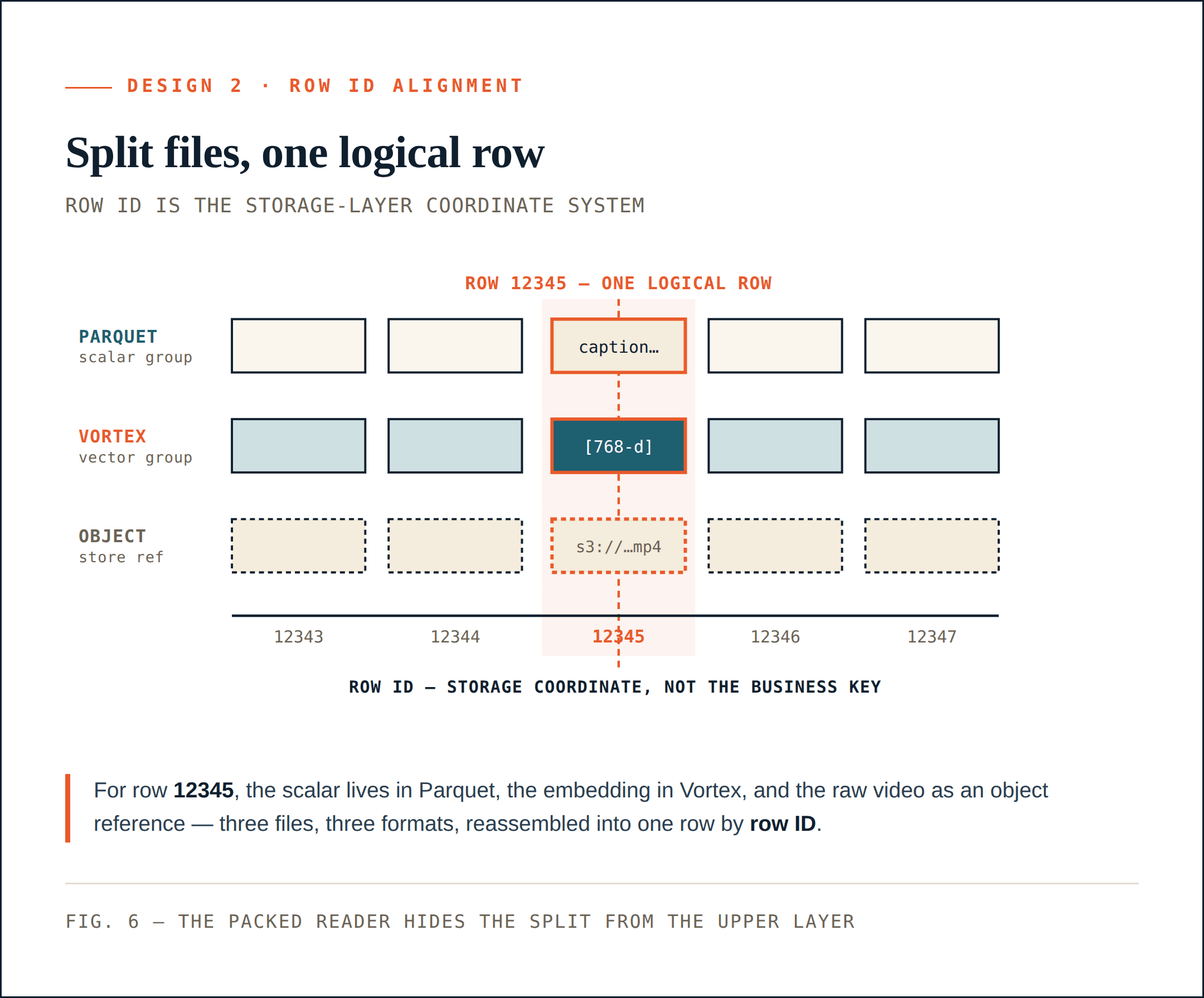
Neue Spalten müssen alte Spalten nicht neu schreiben
Das Hinzufügen von embedding_v2 erfordert kein Neuschreiben der ursprünglichen Caption, Metadaten oder embedding_v1-ColumnGroups. Loon kann eine neue Vektor-ColumnGroup schreiben, den von ihr abgedeckten Zeilen-ID-Bereich aufzeichnen und diese Änderung über das Manifest committen.
Dasselbe gilt für sparse Vektoren, Rerank-Features oder andere abgeleitete Felder, die später hinzukommen.
Solange die neue ColumnGroup den richtigen Zeilen-ID-Bereich abdeckt, kann sie derselben logischen Sammlung beitreten, ohne zu erzwingen, dass nicht verwandte Daten verschoben werden.
Löschungen und Kompaktierung können gezielter erfolgen
Die Zeilen-ID-Ausrichtung hilft auch bei Löschungen.
Eine Löschung kann zunächst über ein Delete-Log ausgedrückt werden. Die Zeile wird auf der logischen Ebene unsichtbar, während die physische Bereinigung bis zur Kompaktierung verzögert wird. Wenn die Kompaktierung schließlich läuft, muss sie nicht immer jede ColumnGroup neu schreiben, die mit den betroffenen Zeilen verknüpft ist. Sie kann sich auf die ColumnGroups konzentrieren, die bereinigt werden müssen.
Das ist wichtig, weil nicht jede Spalte dasselbe Kostenprofil hat. Das Neuschreiben einer kurzen skalaren ColumnGroup unterscheidet sich stark vom Neuschreiben hunderter Gigabyte dichter Vektoren.
Hybride Suche kann nur die Spalten abrufen, die sie benötigt
Die Zeilen-ID-Ausrichtung macht auch die hybride Suche auf Basis hybrider Dateiformate praktikabel.
Nachdem die ANN-Suche Kandidaten-Zeilen-IDs zurückgegeben hat, kann das System nur die Felder abrufen, die für das endgültige Ergebnis benötigt werden: Captions, Metadaten, Vektoren, Rerank-Features oder Objektreferenzen.
Zum Beispiel kann eine Abfrage Folgendes benötigen:
caption
embedding
video_uri
Diese Felder können in verschiedenen ColumnGroups liegen. Loon kann die relevanten Dateien anhand des Zeilen-ID-Bereichs lokalisieren, die erforderlichen Byte-Bereiche lesen und das Ergebnis zusammensetzen.
Ohne Zeilen-ID-Ausrichtung wären hybride Formate lediglich separate Dateien, die nebeneinander liegen. Mit Zeilen-ID-Ausrichtung verhalten sie sich wie eine einzige logische Sammlung.
Packed Reader verbirgt die Aufteilung vor der oberen Schicht
Die Laufzeitkomponente, die dies nutzbar macht, ist der Packed Reader.
Die obere Schicht sieht einen einheitlichen Arrow RecordBatch-Stream. Darunter können Daten aus mehreren ColumnGroups in unterschiedlichen Dateiformaten stammen. Der Packed Reader verbirgt diese Unterschiede, richtet Daten anhand von Zeilen-ID-Bereichen aus und plant Multi-File-I/O mit kontrollierter Speichernutzung.
Er unterstützt außerdem direktes take per Zeilen-ID. Bei einer gegebenen Menge von Zeilen-IDs lokalisiert er die relevanten ColumnGroupFiles, führt Range Reads aus und gibt die angeforderten Felder zurück.
Für den Video-Workflow kann eine ANN-Abfrage caption, embedding und video_uri benötigen. Der Packed Reader kann die skalare ColumnGroup und die Vektor-ColumnGroup abrufen, ohne nicht verwandte Spalten zu berühren.
Das ist der Unterschied zwischen „separaten Dateien“ und „einer Tabelle mit mehreren physischen Layouts“.
Design 3: das Manifest zur Single Source of Truth machen
Hybride Dateiformate definieren, wie Daten physisch gespeichert werden. Die Row-ID-Ausrichtung bestimmt, wie getrennte ColumnGroups dennoch eine einzige logische Tabelle bilden. Aber das System muss weiterhin eine größere Frage beantworten: Welche Dateien, Logs, Statistiken, Indizes und Objektreferenzen gehören zur aktuellen Version des Datasets? Das ist die Aufgabe des Manifests.

Object-Storage-Verzeichnisse reichen nicht aus
Object Storage ist kein Datenbankkatalog. Ein Verzeichnis kann alte Dateien, neue Dateien, Ausgaben fehlgeschlagener Jobs, temporäre Dateien, Delete-Logs, Dateien, die noch von älteren Snapshots referenziert werden, und Dateien enthalten, die auf die Bereinigung warten. Die Tatsache, dass eine Datei existiert, bedeutet nicht, dass sie zur aktuellen Dataset-Version gehört.
Ein Loon-Dataset kann in Verzeichnissen organisiert sein wie:
_metadata/
_data/
_delta/
_stats/
_index/
Aber die Verzeichnisstruktur ist nicht die Single Source of Truth. Das Manifest ist es. Reader sollten keine Verzeichnisse auflisten und den Zustand aus beliebigen Dateien ableiten, die zufällig existieren. Sie sollten das aktuelle Manifest lesen und der versionierten Sicht folgen, die es deklariert.
Das Manifest definiert eine versionierte Sicht des Datasets
Das Manifest definiert das Dataset in einer bestimmten Version. Es zeichnet auf:
- welche ColumnGroups existieren
- welche Row-ID-Bereiche sie abdecken
- welches physische Format jede ColumnGroup verwendet
- wo die Dateien liegen
- welche Delete-Logs aktiv sind
- welche Statistiken verfügbar sind
- welche Indizes existieren
- welche externen Blobs referenziert werden
- welche Spalten und Row-Bereiche diese Stats oder Indizes abdecken
Jedes Update schreibt eine neue Manifest-Version. Ein Reader, der Version N öffnet, sieht eine stabile Sicht des Datasets in Version N. Ein Writer kann Version N+1 vorbereiten, ohne Reader zu stören, die noch Version N verwenden.
Das Manifest verfolgt mehr als Tabellendateien
In Loon wird der Manifest-Body mit Apache Avro kodiert und um vier Hauptabschnitte herum organisiert.
- ColumnGroups beschreiben die Spalten, Formate, Dateien und Row-ID-Bereiche.
- DeltaLogs beschreiben Löschungen. Unterschiedliche Löschtypen decken unterschiedliche Änderungsquellen ab, wie etwa Primary-Key-Deletes von Clients, positionale Deletes aus interner Kompaktierung oder Equality-Deletes von externen Engines.
- Stats umfassen Planungsmetadaten wie Bloom-Filter, BM25-Statistiken und Min/Max-Werte.
- Indexes beschreiben Indextyp, Parameter, abgedeckte Spalten und Row-ID-Bereiche. Dies kann Vektorindizes wie HNSW oder IVF, Textindizes, invertierte Indizes, Bitmap-Indizes und verwandte Strukturen umfassen.
Hier unterscheidet sich Loon von einem traditionellen Tabellenmanifest.
Ein Vektor-Dataset muss nicht nur Datendateien und Partitionen verfolgen. Es muss auch Vektorindizes, Textindizes, Sparse-Features, Delete-Logs, Statistiken, externe Objektreferenzen und die Row-ID-Bereiche verfolgen, die sie miteinander verbinden.
Das Manifest muss von mehr als nur der Datenbank beschreibbar sein
Der wichtigste Teil ist nicht nur, was das Manifest enthält. Es ist, wer es schreiben kann.
- Wenn nur die Datenbank das Manifest schreiben kann, bleibt es interne Metadaten. Sauberere Metadaten, aber weiterhin privat für eine Engine.
- Wenn externe Engines neue ColumnGroups, Stats und Manifest-Einträge erzeugen können, wird das Manifest zu einer Koordinationsschnittstelle.
- Ein Spark-Job kann zum Beispiel eine Sparse-Vector-Spalte nachträglich befüllen. Er schreibt eine neue ColumnGroup, zeichnet Row-Abdeckung und Statistiken auf und committet ein neues Manifest. Online-Abfragen können während des Jobs weiterhin die alte Version lesen. Sobald der Commit erfolgreich ist, wird die neue Version sichtbar.
Das ähnelt vom Grundgedanken her Iceberg und Delta Lake, aber das Objektmodell ist breiter. Ein Vektor-Dataset muss Vektorindizes, Textindizes, Sparse-Features, Delete-Logs, Stats, Blob-Referenzen und Row-ID-Bereiche verfolgen, nicht nur Tabellendateien und Partitionen.
Optimistische Commits halten Versionsaktualisierungen einfach
Jeder Commit schreibt eine neue Manifest-Version. Ein Writer kann neue Inhalte auf Basis von Version N erstellen und dann versuchen, manifest-{N+1}.avro zu schreiben. Bedingte Schreibvorgänge im Objektspeicher oder Generation-Match-Semantiken können dazu führen, dass der Commit fehlschlägt, wenn diese Version bereits existiert. Der Writer kann es dann mit der neueren Version erneut versuchen.
Dies gibt Loon optimistische Nebenläufigkeit, ohne jedes Update über einen aufwendigen, stark konsistenten Koordinationspfad erzwingen zu müssen. Ohne ein Manifest werden Multi-Format- und Multi-Engine-Speicher letztlich zu Namenskonventionen und manueller Abstimmung. Das mag für kleine Datensätze funktionieren. Für Vektordaten im TB-Maßstab funktioniert es nicht.
Das Manifest macht aus heterogenen Dateien einen Datensatz, den mehrere Systeme sicher lesen und aktualisieren können.
Was sich für Benutzer ändert, wenn Speicher versioniert wird
Für Anwendungsentwickler sollte Loon nicht zu einer neuen API-Belastung werden.
Benutzer sollten weiterhin mit vertrauten Milvus-Konzepten arbeiten: Collections, Inserts, Search und Hybrid Search. Sie sollten bei der normalen Anwendungsentwicklung nicht über Manifest-Dateien, ColumnGroups, Zeilen-ID-Bereiche oder Dateilayout nachdenken müssen.
Die Änderung liegt darunter. Der Speicher wird sich stärker bewusst, wie sich AI-Datensätze tatsächlich weiterentwickeln.
Das Hinzufügen eines neuen Embeddings sollte die alten Daten nicht verschieben
Früher erforderte das Hinzufügen von embedding_v2 zu einer bestehenden Collection oft das Exportieren von Daten, das Trainieren eines neuen Modells, das Generieren von Vektoren und anschließend das erneute Importieren oder Massenaktualisieren der Collection über das SDK. Dieser Weg verursacht viel operativen Aufwand: Versionsverfolgung, Wiederholungen fehlgeschlagener Jobs, Index-Neuaufbauten, Auswirkungen auf die Bereitstellung und Konsistenzprüfungen.
Mit Loon kann dies zu einer Schema-Evolution plus einem neuen ColumnGroup-Commit werden. Die neue Embedding-Spalte kann als eigene physische ColumnGroup geschrieben, anhand der Zeilen-ID ausgerichtet und über das Manifest sichtbar gemacht werden. Die alte Caption-Spalte, die Spalte mit skalaren Metadaten und die ursprüngliche Embedding-Spalte müssen nicht verschoben werden.
Backfills sollten keine clientseitige Update-Schleife erfordern
Viele AI-Datenaktualisierungen sind Backfills. Ein Team kann Sparse-Vektoren hinzufügen, nachdem Hybrid Search wichtig geworden ist. Es kann Rerank-Features hinzufügen, nachdem ein neues Modell trainiert wurde. Es kann Captions nach menschlicher Prüfung korrigieren. Es kann Governance-Tags nach einer Richtlinienaktualisierung hinzufügen.
In einem traditionellen Layout erfolgen diese Änderungen oft über Client-SDK-Updates oder ausschließlich datenbankbasierte Schreibpfade, selbst wenn die Daten von Spark, Ray oder einer anderen externen Engine erzeugt werden.
Mit Loon können externe Compute-Systeme neue ColumnGroups erzeugen und sie über das Manifest committen. Die Datenbank muss nicht länger der einzige Einstiegspunkt für jede Neuschreibung sein.
Offline-Analyse sollte keine weitere Kopie der Wahrheit erfordern
Früher haben Teams eine Online-Collection oft nach Parquet exportiert, um sie offline zu evaluieren oder zu analysieren. Dadurch entstehen zwei Versionen desselben Datensatzes: die Online-Collection und die Analysekopie. Sobald Captions korrigiert, Embeddings neu generiert, Löschprotokolle angewendet oder Indizes neu aufgebaut werden, muss das Team fragen, welche Kopie aktuell ist.
Mit einem Manifest-basierten Speichermodell können Analyse-Engines dieselbe versionierte Datensatzansicht lesen wie das Serving-System. Sie können nur die benötigten Spalten projizieren, nur die relevanten Zeilenbereiche scannen und gegen eine deklarierte Datensatzversion arbeiten statt gegen einen manuell exportierten Snapshot.
Löschungen und Korrekturen sollten nur das berühren, was sich geändert hat
Löschungen, Caption-Korrekturen, Label-Fixes und Governance-Updates sind in AI-Datensätzen Routine. Sie sollten nicht erzwingen, dass jede lange Vektorspalte denselben Neuschreibpfad durchläuft.
Mit Loon können Löschprotokolle zunächst als logische Löschung behandelt werden. Eine spätere Kompaktierung kann die betroffenen ColumnGroups bereinigen, ohne nicht zusammenhängende Daten neu zu schreiben. Wenn sich ein kurzes Textfeld ändert, sollte die Speicherschicht nicht Hunderte von Gigabyte dichter Vektoren neu schreiben müssen, nur weil sie dieselbe logische Zeile teilen.
Externe Engines werden Teil des Workflows, nicht ein Notausgang
Die größere Verschiebung besteht darin, dass externe Engines nicht mehr als Systeme außerhalb der Vektordatenbank behandelt werden.
Spark, Ray, Evaluierungsjobs, Labeling-Systeme und Governance-Pipelines erzeugen und verändern bereits einen Großteil der Daten. Die Speicherschicht sollte es ihnen ermöglichen, rund um eine einzige Quelle der Wahrheit zusammenzuarbeiten, anstatt ständig zu exportieren, zu kopieren und erneut zu importieren.
Genau das macht eine Version von Manifest möglich. Sie gibt Online-Serving, Offline-Analyse, Backfill-Jobs und Kompaktierung eine gemeinsame Sicht auf den Datensatz.
Das mag nach internen Speicherdetails klingen, aber es beeinflusst, wie schnell Teams an KI-Datensätzen iterieren können. Jede Modelländerung, jeder Feature-Backfill, jede Caption-Korrektur, jeder Qualitätsfilter und jeder Index-Neuaufbau hängt von derselben Frage ab: "Kann das System den Datensatz aktualisieren, ohne Daten zu verschieben, die es nicht verschieben muss? "
Das ist der praktische Wert des Speichermodells.
Loon ist in Milvus 3.0 Beta und Zilliz Vector Lakebase verfügbar
Loon ist in Milvus 3.0 beta verfügbar und ist außerdem Teil der Speicherschicht in Zilliz Vector Lakebase, der nächsten Weiterentwicklung von Zilliz Cloud. Und diese Version konzentriert sich auf drei Kernbereiche:
- Das Manifest. Das Ziel ist, dass Schreibvorgänge, Backfills, Löschungen, Statistiken und Indexaktualisierungen versionierte Datensatzansichten erzeugen, die Leser konsistent öffnen können. Für Leser bedeutet das, dass eine Abfrage eine bestimmte Manifest-Version öffnen und eine stabile Sicht auf den Datensatz sehen kann. Für Schreiber bedeutet das, dass neue Datendateien, Löschprotokolle, Statistiken oder Indexdateien zuerst vorbereitet und dann über einen versionierten Commit sichtbar gemacht werden können.
- Die ColumnGroup- und Formatunterstützung. Parquet unterstützt skalare und ökosystemfreundliche Spalten. Vortex unterstützt Zugriffsmuster mit hohem Vektoranteil. Lance kann im schreibgeschützten Modus integriert werden, um Kompatibilität mit bestehenden Lance-Datensätzen zu gewährleisten.
- Der Index on Lake. Skalare Statistiken, Filterindizes und invertierte Textindizes können an der Manifest-basierten Planung nach Zeilenbereich teilnehmen. Lake-native Vektorindizes sind komplexer. HNSW und IVF verhalten sich auf Objektspeicher unterschiedlich, und insbesondere HNSW ist empfindlich gegenüber zufälligem Zugriff und Cache-Lokalität. Es kann nicht einfach ein Layout wiederverwenden, das für eine lokale SSD entwickelt wurde, und dasselbe Ergebnis erwarten.
Es gibt noch Arbeit vor uns
- Externe Schreibpfade sind wichtig, weil Spark und Ray ColumnGroups und Manifest-Commits erzeugen können sollten, ohne jeden Backfill durch eine Client-SDK-Schleife zwingen zu müssen.
- Lakehouse-Interoperabilität ist wichtig, weil viele Teams bereits Kataloge und Abfrage-Engines wie Iceberg, Delta Lake, Trino, DuckDB und Athena verwenden. Vektordaten sollten an diesem Ökosystem teilnehmen können, ohne Suchleistung bei der Vektorsuche zu verlieren.
- Index-Layout ist wichtig, weil Graphindizes und invertierte Strukturen auf Objektspeicher unterschiedliche Zugriffsmuster haben.
- Semantik großer Objekte ist wichtig, weil Rohvideos, PDFs, Bilder und Audiodateien Referenzverwaltung, Versionierung und Löschverhalten erfordern, die mit dem abgeleiteten Vektordatensatz übereinstimmen.
Das genaue Release-Verhalten, die Standardeinstellungen und der Migrationspfad sollten den entsprechenden Milvus- und Zilliz Cloud release notes folgen. Die Speicherrichtung ist jedoch klar: Vektordatenbanken benötigen unterhalb der Serving-Schicht eine versionierte, lake-native Grundlage.
Testen Sie Loon unter Zilliz Vector Lakebase
Wenn Ihr aktueller Stack Online-Serving, Offline-Analyse, Backfills und externe Data-Lake-Workflows in verschiedene Systeme trennt, ist Zilliz Vector Lakebase einen Blick wert. Sie können es in Zilliz Cloud ausprobieren. Neue Registrierungen mit geschäftlicher E-Mail-Adresse erhalten kostenlose Credits im Wert von 100 $. Sie können auch gerne mit uns sprechen, um Ihren Anwendungsfall zu besprechen.
Sie können auch dem Milvus 3.0 release folgen, um zu sehen, wie sich Loon in der Open-Source-Engine weiterentwickelt.
Zilliz Vector Lakebase vereint:
- Mehrstufige Bereitstellung für unterschiedliche Kompromisse zwischen Echtzeit-Performance und Kosten
- On-Demand-Suche für groß angelegte oder explorative Workloads ohne ständig aktive Rechenressourcen
- Suche in externen Data Lakes, sodass Sie direkt über vorhandene Lake-Daten indexieren und suchen können
- Suche über das gesamte Spektrum hinweg – über Vektoren, Text, JSON und Geodaten, mit hybrider Abfrage und Reranking
- Einheitlicher, lake-nativer Speicher, aufgebaut auf Vortex, einem offenen Format, das für schnellere, kostengünstigere Random Reads über vektorlastige Daten entwickelt wurde
Weiterlesen

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.