




Erschließen Sie fortschrittliche Empfehlungsmaschinen mit der neuen Range Search von Milvus
Einführung
Bei der Ähnlichkeitssuche benötigen Entwickler häufig Unterstützung bei Einschränkungen, insbesondere wenn es darum geht, die Qualität und Vielfalt von Suchergebnissen auszubalancieren. Hier kommt die neue Funktion von Milvus ins Spiel: Range Search. Dieser Beitrag erläutert, was Range Search ist, wann sie gegenüber der traditionellen Top-K Search verwendet werden sollte, und geht auf ihre technische Architektur sowie eine Nutzungsanleitung ein.
Was ist Range Search?
Range Search in Milvus bietet eine granulare Kontrolle über die Vektorähnlichkeit in Suchergebnissen, indem Sie einen Distanzbereich für relevante Vektoren festlegen können. Diese Funktion behebt die Einschränkungen traditioneller KNN-Suchen in Empfehlungssystemen, bei denen Ergebnisse im Vergleich zu Ihren Erwartungen entweder zu ähnlich oder zu vielfältig sein können.
Wann sollte man Range Search statt Top-K Search wählen?
Die traditionelle KNN-Suche hat zwei grundlegende Schwächen:
Unausgewogene Empfehlungen: Sie kann Elemente empfehlen, die zu ähnlich sind, was die Empfehlungsqualität beeinträchtigt. Beispielsweise könnte ein Sportnachrichten-Aggregator einem Nutzer am Ende mehrere Artikel über dasselbe Fußballspiel empfehlen, nur weil er einen Artikel über das Spiel gelesen hat. Dies könnte vielfältige Inhalte verdrängen, wodurch die Empfehlungen repetitiv und weniger ansprechend wirken.
Systembeschränkungen: Der Top-K-Parameter ist auf 16.384 begrenzt, was Probleme bei groß angelegten Datenabfragen und der Ressourcennutzung verursacht. Stellen Sie sich ein Szenario vor, in dem Sie einen Datensatz mit Millionen von Produkten abfragen. Das Top-K-Limit von 16.384 bedeutet, dass Ihnen möglicherweise Tausende relevanter Produkte entgehen, die für den Nutzer interessant sein könnten, während gleichzeitig Ihre Systemressourcen belastet werden, da das System versucht, dieses große Datenvolumen zu verarbeiten und zu übertragen.
Range Search löst diese Probleme. Sie ermöglicht eine ausgewogene Ergebnismenge, indem Sie einen Distanzbereich für die Vektorähnlichkeit definieren können. Das Hinzufügen von Parametern wie radius und dem optionalen range_filter bietet eine differenziertere Kontrolle und macht eine Filterung nach der Abfrage überflüssig. Diese differenzierte Kontrolle macht Range Search ideal für Anwendungen, die eine präzise Steuerung der Suchergebnisse erfordern.
Technische Details hinter Range Search
Nachdem wir untersucht haben, was Range Search ist und wann sie eingesetzt werden sollte, tauchen wir nun in ihre Architektur und Algorithmen ein. Diese Betrachtung liefert wichtige Einblicke in ihre Stärken, Einschränkungen und die Integration mit Drittanbieterbibliotheken.
Der Ablauf von Range Search baut auf dem bestehenden Search-Ablauf auf und verwendet die meisten Datenpfade auf den höheren Ebenen wieder. Nachfolgend finden Sie einen Überblick über die Schritte, die ausgeführt werden, wenn eine Suchanfrage empfangen wird:
SDK verarbeitet Suchanfrage: Das SDK empfängt eine Suchanfrage eines Benutzers, die Parameter wie radius und range_filter enthält.
Proxy generiert SearchTask: Nach Empfang der Suchanfrage erstellt der Proxy eine SearchTask und übergibt sie an den Query Node.
Querynode zu Segcore: Der Query Node ruft die Search-Schnittstelle in Segcore über einen cgo-Aufruf auf.
Segcore-Parsing: Segcore analysiert die Parameter in search_param. Wenn ein radius-Parameter vorhanden ist, ruft es knowhere::RangeSearch auf.
Knowhere und Drittanbieterbibliotheken: Knowhere (die zentrale Vektor-Ausführungs-Engine von Milvus) leitet den Aufruf anschließend basierend auf dem Indextyp an die range_search-Funktion der entsprechenden Drittanbieterbibliothek weiter.
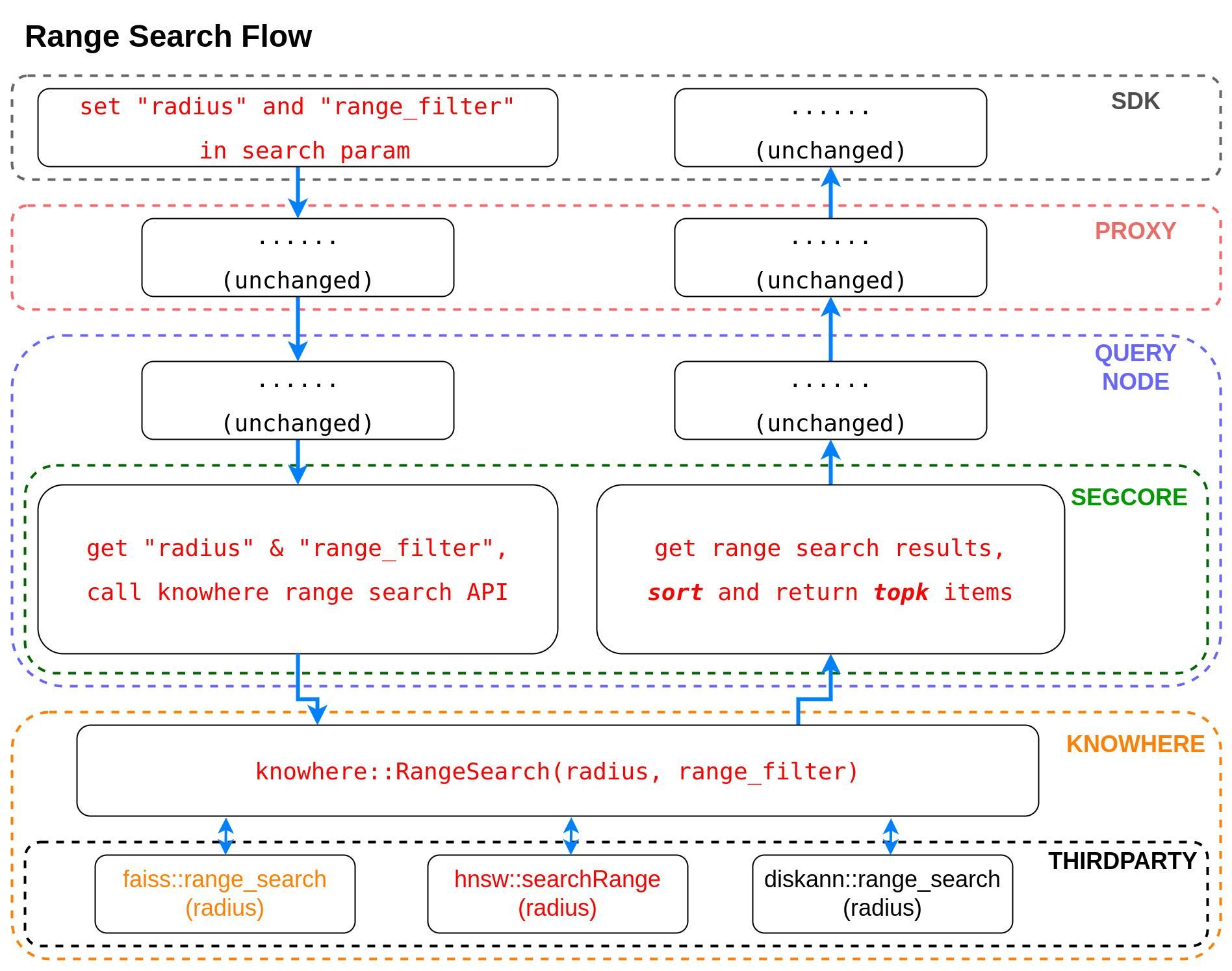
Alle von uns unterstützten Indizes von Drittanbieterbibliotheken sind so konfiguriert, dass sie eine einseitige Range Search durchführen. „Einseitig“ bedeutet, dass sie nur einen einzigen Parameter „radius“ akzeptieren und alle unsortierten Ergebnisse innerhalb dieses Radius zurückgeben. Die folgende Tabelle zeigt die Range-Search-Strategien für verschiedene Indextypen.
| Indextyp | Suchstrategie |
|---|---|
| IDMAP / BIN_IDMAP | Brute-Force-Suche |
| IVF_xxx / SCANN / BIN_IVF_xxx (aktualisiert) | Beginnen Sie die Suche mit dem Bucket, der dem Mittelpunkt am nächsten liegt. Beenden Sie die Suche, wenn eine der folgenden Bedingungen erfüllt ist: 1. Alle Buckets wurden durchsucht 2. In einem Bucket werden keine Vektoren gefunden, die die Bedingung erfüllen. |
| HNSW (selbst entwickelt) | Beginnen Sie die Suche in der obersten Schicht und identifizieren Sie den Vektor, der dem Ziel am nächsten liegt, und fahren Sie dann mit der nächsttieferen Schicht fort. Setzen Sie diesen Prozess Schicht für Schicht fort, bis der nächste Nachbar in der untersten (1.) Schicht erreicht ist. Führen Sie von dort aus eine Breitensuche (Breadth-First Search, BFS) aus, beginnend bei diesem nächsten Nachbarn und fortgesetzt, bis alle besuchten Punkte und ihre ausgehenden Nachbarn außerhalb des gewünschten Bereichs liegen. |
| DISKANN | Beginnen Sie mit l_search = min_l_search. Setzen Sie für jede Iteration l_search = 2 * l_search. Beenden Sie die Suche, wenn eine der folgenden Bedingungen erfüllt ist: 1. Die Anzahl der in einer Iteration zurückgegebenen Ergebnisse ist kleiner als l_search / 2 2. l_search > max_l_search. |
Sowohl die Metriktypen HAMMING als auch JACCARD bieten vollständige Unterstützung für die Bereichssuche für binäre Datentypen. Die Metriktypen SUBSTRUCTURE/SUPERSTRUCTURE sind jedoch nicht mit der Bereichssuche kompatibel, da ihre Semantik auf einem Wahr/Falsch-Wertesystem basiert. Bei Indizes vom Typ Float sind diejenigen, die die Metriken L2, IP und COSINE verwenden, vollständig mit der Bereichssuche kompatibel.
Die folgende Tabelle beschreibt die detaillierten Index- und Metriktypen, die mit der Bereichssuche kompatibel sind.
| L2 | IP | COSINE | HAMMING | JACCARD | SUBSTRUCTURE | SUPERSTRUCTURE | |
|---|---|---|---|---|---|---|---|
| BIN_IDMAP | √ | √ | |||||
| BIN_IVF_FLAT | √ | √ | |||||
| IDMAP | √ | √ | √ | ||||
| IVF_FLAT | √ | √ | √ | ||||
| IVF_PQ | √ | √ | √ | ||||
| IVF_SQ8 | √ | √ | √ | ||||
| HNSW | √ | √ | √ | √ | √ | ||
| SCANN | √ | √ | √ | ||||
| DISKANN | √ | √ | √ |
So verwenden Sie Range Search in Milvus
Um Range Search in Milvus zu verwenden, müssen Sie die Suchparameter in Ihrer Suchanfrage ändern. Hier ist eine Schritt-für-Schritt-Anleitung, einschließlich eines Beispiel-Python-Code-Snippets:
Voraussetzungen
Stellen Sie sicher, dass Milvus installiert ist und ausgeführt wird.
Stellen Sie sicher, dass Sie eine Collection erstellt und indexiert haben.
Wichtige Range-Search-Parameter
radius: Dies ist ein obligatorischer Parameter, der bestimmt, ob die Suchanfrage eine Bereichssuche oder eine reguläre Suche durchführt.
range_filter: Dies ist ein optionaler Parameter. Wenn er angegeben wird, wird eine sekundäre Filterung der Ergebnisse durchgeführt. Wenn er nicht angegeben wird, gibt die Funktion die Ergebnisse direkt zurück.
Durch die Konfiguration dieser beiden Parameter können Sie das Verhalten Ihrer Range-Search-Abfragen für unterschiedliche Anwendungsanforderungen feinabstimmen. Schauen wir uns vor diesem Hintergrund etwas Beispielcode an, der Ihnen den Einstieg erleichtert.
default_index = {
"index_type": "HNSW",
"metric_type": "L2",
"params": {"M":48,"efConstruction":500}
}
collection.create_index("float_vector", default_index)
search_params = {
"metric_type": "L2",
"limit": TOPK,
"params": {"ef":32,"range_filter":1.0,"radius":2.0}
}
res = collection.search(vectors[:nq], "float_vector", search_params, limit)
Überlegungen zu Metriken
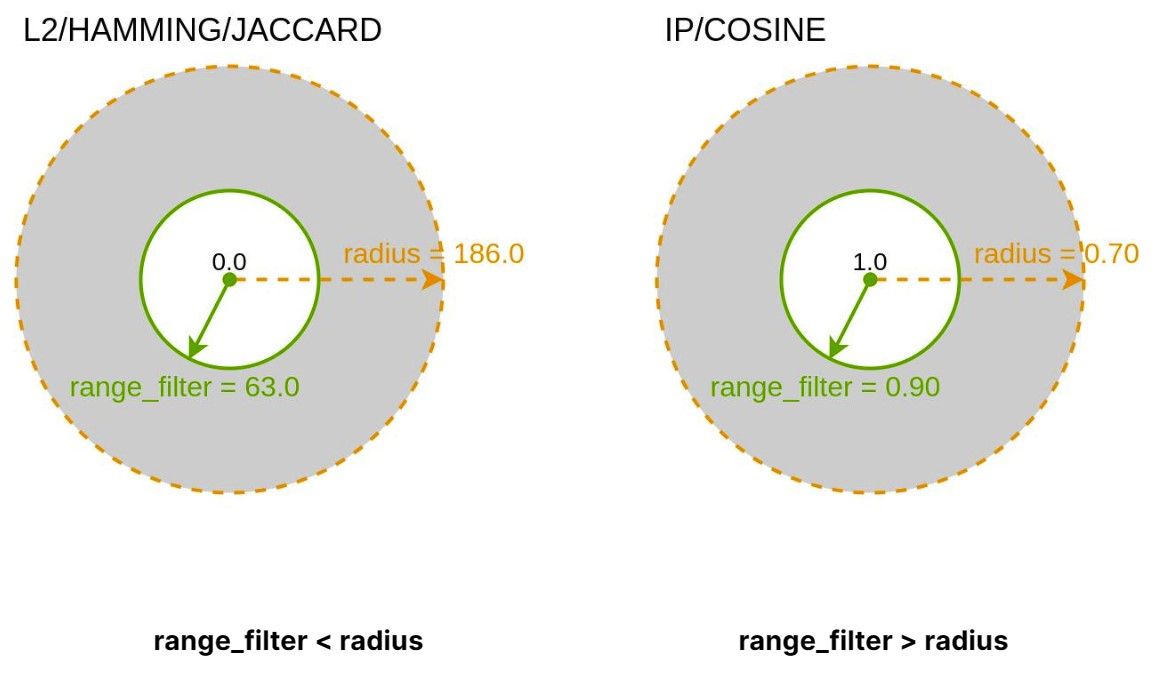
Nachdem Sie nun verstanden haben, wie Range Search verwendet wird, ist es wichtig, die Auswirkungen von Metriktypen auf Ihre Abfragen zu berücksichtigen. Je nach gewähltem Metriktyp sollten Sie den Radius überprüfen, wie wir in der folgenden Tabelle vorschlagen.
| Metriktyp | Radius | Ähnlich | Nicht ähnlich |
|---|---|---|---|
| L2 | [0.0, inf] | 0.0 | inf |
| IP | [-inf, inf] | inf | -inf |
| COSINE | [-1.0, 1.0] | 1.0 | -1.0 |
| HAMMING | [0, n] | 0 | n |
| JACCARD | [0.0, 1.0] | 0.0 | 1.0 |
Zusätzlich sollte range_filter diesen Regeln folgen:
Für L2/Hamming/Jaccard, range_filter < radius
Für IP/Cosine, range_filter > radius
Fazit
Range Search in Milvus ist nicht auf Empfehlungsmaschinen beschränkt; es hat breitere Anwendungen in Bereichen wie Content-Matching, Anomalieerkennung und NLP-Suchaufgaben. Durch die Nutzung von Parametern wie radius und range_filter können Sie Ihre Abfragen präzise auf diese vielfältigen Anwendungsfälle zuschneiden.
Bereit, die Kontrolle über Ihre Suchanfragen zu übernehmen? Range Search ist jetzt als öffentliche Vorschau auf Zilliz Cloud verfügbar. Führen Sie ein Upgrade auf die Zilliz Cloud-Betaversion durch oder laden Sie Milvus 2.3.x herunter, um es auszuprobieren. Ihre Erkenntnisse sind entscheidend für die kontinuierliche Verbesserung. Wenn Sie also auf Probleme stoßen oder Vorschläge haben, sind wir ganz Ohr. Lassen Sie uns Range Search gemeinsam verbessern.

Weiterlesen

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.