




Wie plant Milvus Abfrageaufgaben
In diesem Artikel besprechen wir, wie Milvus Abfrageaufgaben plant. Außerdem sprechen wir über Probleme, Lösungen und zukünftige Ausrichtungen für die Implementierung der Milvus-Planung.
Hintergrund
Aus Managing Data in Massive-Scale Vector Search Engine wissen wir, dass die Vektorähnlichkeitssuche durch den Abstand zwischen zwei Vektoren in einem hochdimensionalen Raum implementiert wird. Das Ziel der Vektorsuche ist es, K Vektoren zu finden, die dem Zielvektor am nächsten sind.
Es gibt viele Möglichkeiten, den Vektorabstand zu messen, zum Beispiel den euklidischen Abstand:
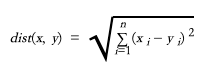 Euklidischer Abstand.
Euklidischer Abstand.
wobei x und y zwei Vektoren sind. n ist die Dimension der Vektoren.
Um die K nächsten Vektoren in einem Datensatz zu finden, muss der euklidische Abstand zwischen dem Zielvektor und allen zu durchsuchenden Vektoren im Datensatz berechnet werden. Anschließend werden die Vektoren nach Abstand sortiert, um die K nächsten Vektoren zu erhalten. Der Rechenaufwand ist direkt proportional zur Größe des Datensatzes. Je größer der Datensatz, desto mehr Rechenaufwand erfordert eine Abfrage. Eine GPU, die auf Grafikverarbeitung spezialisiert ist, verfügt zufällig über viele Kerne, um die erforderliche Rechenleistung bereitzustellen. Daher wird bei der Implementierung von Milvus auch die Unterstützung mehrerer GPUs berücksichtigt.
Grundlegende Konzepte
Datenblock(TableFile)
Um die Unterstützung für die Suche in Daten im großen Maßstab zu verbessern, haben wir die Datenspeicherung von Milvus optimiert. Milvus teilt die Daten in einer Tabelle nach Größe in mehrere Datenblöcke auf. Während der Vektorsuche durchsucht Milvus Vektoren in jedem Datenblock und führt die Ergebnisse zusammen. Ein Vektorsuchvorgang besteht aus N unabhängigen Vektorsuchvorgängen (N ist die Anzahl der Datenblöcke) und N-1 Ergebniszusammenführungsvorgängen.
Aufgabenwarteschlange(TaskTable)
Jede Resource verfügt über ein Aufgabenarray, das Aufgaben aufzeichnet, die zur Resource gehören. Jede Aufgabe hat verschiedene Zustände, darunter Start, Loading, Loaded, Executing und Executed. Der Loader und der Executor in einem Rechengerät teilen sich dieselbe Aufgabenwarteschlange.
Abfrageplanung
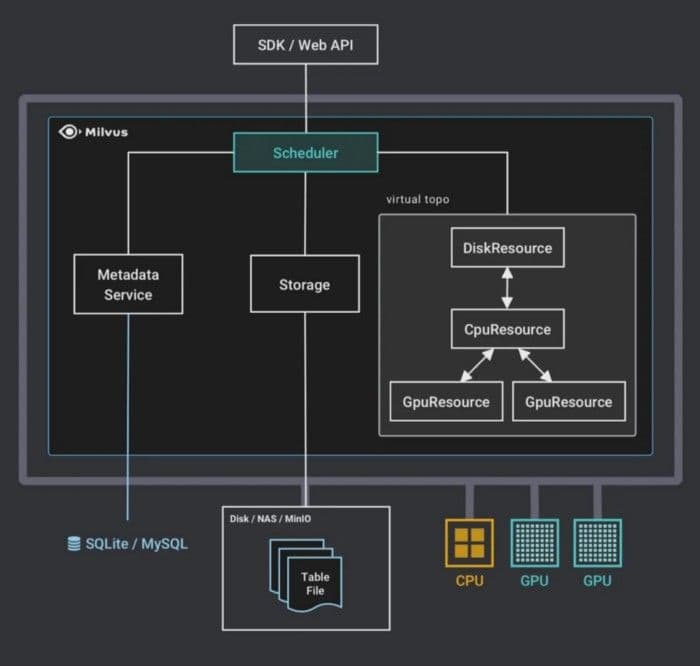 Abfrageplanung.
Abfrageplanung.
- Wenn der Milvus-Server startet, startet Milvus die entsprechende GpuResource über die
gpu_resource_config-Parameter in der Konfigurationsdateiserver_config.yaml. DiskResource und CpuResource können weiterhin nicht inserver_config.yamlbearbeitet werden. GpuResource ist die Kombination aussearch_resourcesundbuild_index_resourcesund wird im folgenden Beispiel als{gpu0, gpu1}bezeichnet:
 Beispielcode.
Beispielcode.
 Beispiel.
Beispiel.
- Milvus empfängt eine Anfrage. Tabellenmetadaten werden in einer externen Datenbank gespeichert, die für Einzelhost-Betrieb SQLite oder MySQl und für verteilten Betrieb MySQL ist. Nach dem Empfang einer Suchanfrage validiert Milvus, ob die Tabelle existiert und die Dimension konsistent ist. Anschließend liest Milvus die TableFile-Liste der Tabelle.
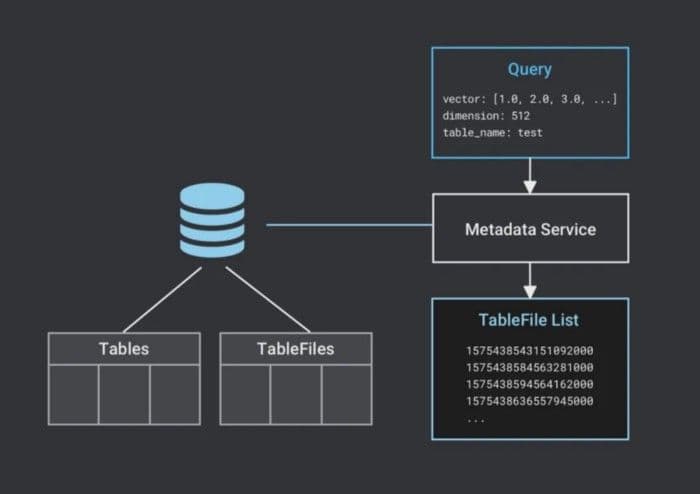 Milvus liest die TableFile-Liste.
Milvus liest die TableFile-Liste.
- Milvus erstellt eine SearchTask. Da die Berechnung jeder TableFile unabhängig durchgeführt wird, erstellt Milvus für jede TableFile eine SearchTask. Als Grundeinheit der Aufgabenplanung enthält eine SearchTask die Zielvektoren, Suchparameter und die Dateinamen von TableFile.
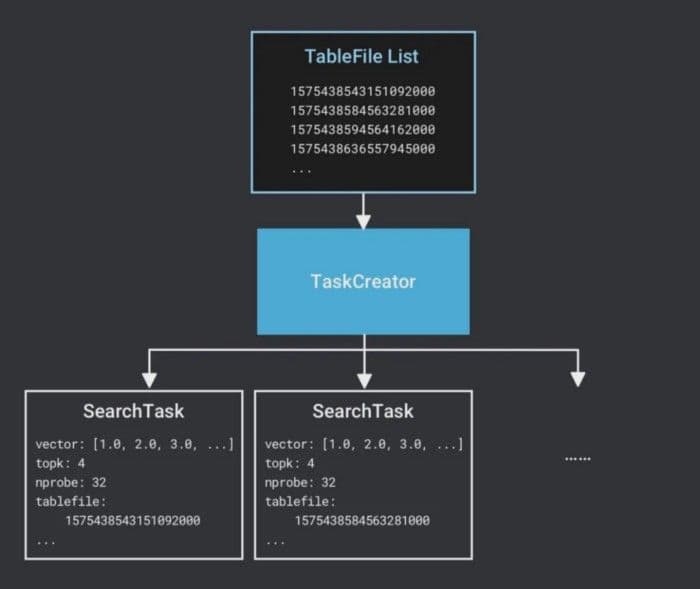 Tabellendateilisten-Aufgabenersteller.
Tabellendateilisten-Aufgabenersteller.
- Milvus wählt ein Rechengerät aus. Das Gerät, auf dem eine SearchTask die Berechnung ausführt, hängt von der geschätzten Abschlusszeit für jedes Gerät ab. Die geschätzte Abschlusszeit gibt das geschätzte Intervall zwischen der aktuellen Zeit und dem geschätzten Zeitpunkt an, zu dem die Berechnung abgeschlossen ist.
Wenn beispielsweise ein Datenblock einer SearchTask in den CPU-Speicher geladen wird, wartet die nächste SearchTask in der CPU-Berechnungsaufgaben-Warteschlange und die GPU-Berechnungsaufgaben-Warteschlange ist inaktiv. Die geschätzte Abschlusszeit für die CPU entspricht der Summe der geschätzten Zeitkosten der vorherigen SearchTask und der aktuellen SearchTask. Die geschätzte Abschlusszeit für eine GPU entspricht der Summe der Zeit, die benötigt wird, um Datenblöcke auf die GPU zu laden, und der geschätzten Zeitkosten der aktuellen SearchTask. Die geschätzte Abschlusszeit für eine SearchTask in einer Resource entspricht der durchschnittlichen Ausführungszeit aller SearchTasks in der Resource. Milvus wählt dann ein Gerät mit der geringsten geschätzten Abschlusszeit und weist die SearchTask diesem Gerät zu.
Hier nehmen wir an, dass die geschätzte Abschlusszeit für GPU1 kürzer ist.
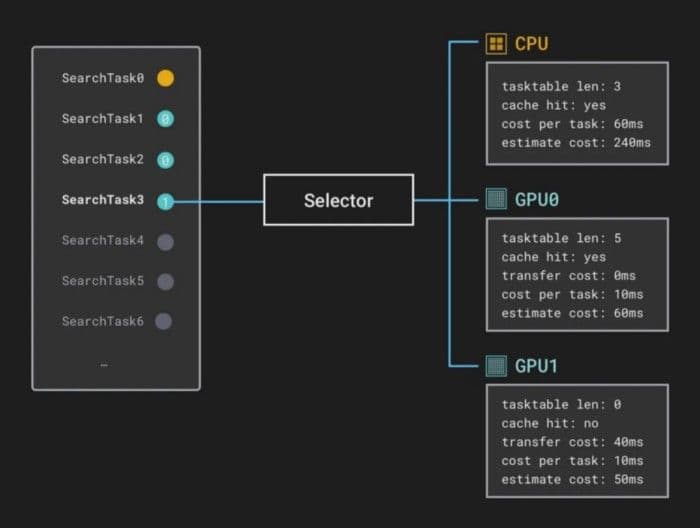 Kürzere geschätzte Abschlusszeit für GPU1.
Kürzere geschätzte Abschlusszeit für GPU1.
Milvus fügt die SearchTask zur Aufgabenwarteschlange von DiskResource hinzu.
Milvus verschiebt die SearchTask in die Aufgabenwarteschlange von CpuResource. Der Lade-Thread in CpuResource lädt jede Aufgabe sequenziell aus der Aufgabenwarteschlange. CpuResource liest die entsprechenden Datenblöcke in den CPU-Speicher.
Milvus verschiebt die SearchTask zu GpuResource. Der Lade-Thread in GpuResource kopiert Daten aus dem CPU-Speicher in den GPU-Speicher. GpuResource liest die entsprechenden Datenblöcke in den GPU-Speicher.
Milvus führt die SearchTask in GpuResource aus. Da das Ergebnis einer SearchTask relativ klein ist, wird das Ergebnis direkt in den CPU-Speicher zurückgegeben.
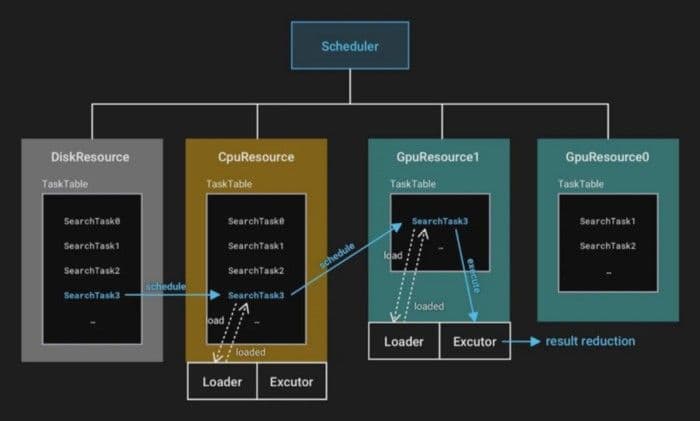 Scheduler.
Scheduler.
- Milvus führt das Ergebnis der SearchTask mit dem gesamten Suchergebnis zusammen.
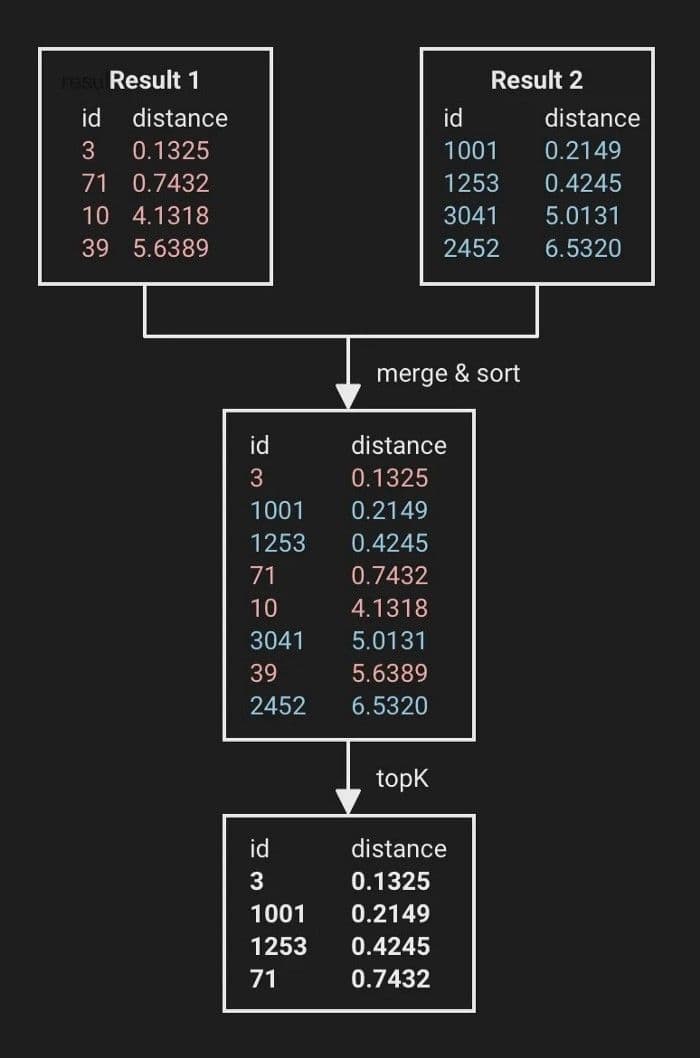 Milvus führt Suchaufgabenergebnisse zusammen.
Milvus führt Suchaufgabenergebnisse zusammen.
Nachdem alle SearchTasks abgeschlossen sind, gibt Milvus das gesamte Suchergebnis an den Client zurück.
Indexerstellung
Die Indexerstellung ist im Grunde identisch mit dem Suchprozess, jedoch ohne den Zusammenführungsprozess. Wir werden darauf nicht im Detail eingehen.
Leistungsoptimierung
Cache
Wie bereits erwähnt, müssen Datenblöcke vor der Berechnung auf die entsprechenden Speichergeräte wie CPU-Speicher oder GPU-Speicher geladen werden. Um wiederholtes Laden von Daten zu vermeiden, führt Milvus einen LRU-Cache (Least Recently Used) ein. Wenn der Cache voll ist, verdrängen neue Datenblöcke alte Datenblöcke. Sie können die Cache-Größe über die Konfigurationsdatei basierend auf der aktuellen Speichergröße anpassen. Ein großer Cache zum Speichern von Suchdaten wird empfohlen, um die Datenladezeit effektiv zu verkürzen und die Suchleistung zu verbessern.
Überlappung von Datenladen und Berechnung
Der Cache kann unseren Bedarf an besserer Suchleistung nicht erfüllen. Daten müssen neu geladen werden, wenn der Speicher nicht ausreicht oder die Größe des Datensatzes zu groß ist. Wir müssen die Auswirkung des Datenladens auf die Suchleistung verringern. Das Laden von Daten, sei es von der Festplatte in den CPU-Speicher oder vom CPU-Speicher in den GPU-Speicher, gehört zu den IO-Operationen und erfordert kaum Rechenarbeit von Prozessoren. Daher ziehen wir in Betracht, Datenladen und Berechnung parallel durchzuführen, um Ressourcen besser zu nutzen.
Wir teilen die Berechnung auf einem Datenblock in 3 Phasen (Laden von der Festplatte in den CPU-Speicher, CPU-Berechnung, Ergebniszusammenführung) oder 4 Phasen (Laden von der Festplatte in den CPU-Speicher, Laden vom CPU-Speicher in den GPU-Speicher, GPU-Berechnung und Ergebnisabruf sowie Ergebniszusammenführung) auf. Nehmen wir die 3-stufige Berechnung als Beispiel: Wir können 3 Threads starten, die für die 3 Phasen verantwortlich sind und als Instruction Pipelining fungieren. Da die Ergebnismengen meist klein sind, nimmt die Ergebniszusammenführung nicht viel Zeit in Anspruch. In einigen Fällen kann die Überlappung von Datenladen und Berechnung die Suchzeit um 1/2 reduzieren.
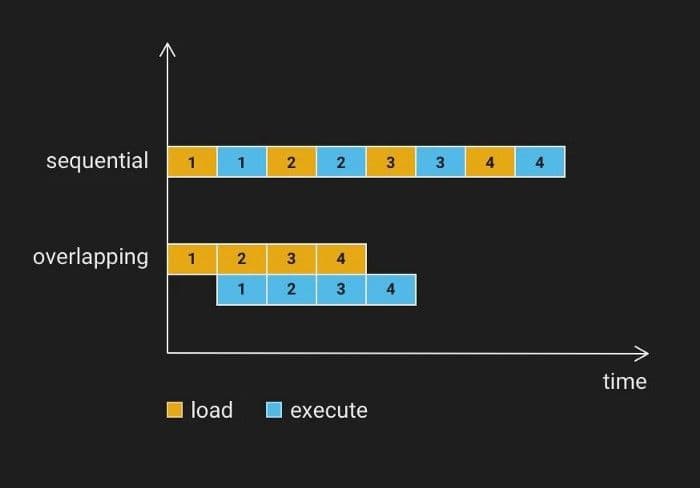 Sequenzielles überlappendes Laden in Milvus.
Sequenzielles überlappendes Laden in Milvus.
Probleme und Lösungen
Unterschiedliche Übertragungsgeschwindigkeiten
Zuvor verwendete Milvus die Round-Robin-Strategie für die Task-Planung auf mehreren GPUs. Diese Strategie funktionierte auf unserem Server mit 4 GPUs perfekt, und die Suchleistung war 4-mal besser. Bei unseren Hosts mit 2 GPUs war die Leistung jedoch nicht 2-mal besser. Wir führten einige Experimente durch und stellten fest, dass die Datenkopiergeschwindigkeit für eine GPU 11 GB/s betrug. Bei einer anderen GPU betrug sie jedoch 3 GB/s. Nach Durchsicht der Mainboard-Dokumentation bestätigten wir, dass das Mainboard über PCIe x16 mit einer GPU und über PCIe x4 mit einer anderen GPU verbunden war. Das heißt, diese GPUs haben unterschiedliche Kopiergeschwindigkeiten. Später fügten wir die Kopierzeit hinzu, um das optimale Gerät für jede SearchTask zu bestimmen.
Zukünftige Arbeiten
Hardwareumgebung mit erhöhter Komplexität
Unter realen Bedingungen kann die Hardwareumgebung komplizierter sein. Für Hardwareumgebungen mit mehreren CPUs, Speicher mit NUMA-Architektur, NVLink und NVSwitch bietet die Kommunikation über CPUs/GPUs hinweg viele Optimierungsmöglichkeiten.
Abfrageoptimierung
Während der Experimente entdeckten wir einige Möglichkeiten zur Leistungsverbesserung. Wenn der Server beispielsweise mehrere Abfragen für dieselbe Tabelle erhält, können die Abfragen unter bestimmten Bedingungen zusammengeführt werden. Durch die Nutzung von Datenlokalität können wir die Leistung verbessern. Diese Optimierungen werden in unserer zukünftigen Entwicklung umgesetzt. Jetzt wissen wir bereits, wie Abfragen für das Szenario mit einem einzelnen Host und mehreren GPUs geplant und ausgeführt werden. In den kommenden Artikeln werden wir weiterhin weitere interne Mechanismen von Milvus vorstellen.
Weiterlesen

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.