




Multimodale RAG vor Ort mit CLIP und Llama3
Mit der kürzlichen Veröffentlichung von GPT-4o und Gemini war Multimodal in letzter Zeit ein heißes Thema. Ein weiteres Thema, das im letzten Jahr ganz oben auf der Liste stand, ist Retrieval Augmented Generation (RAG), das sich jedoch hauptsächlich auf Text konzentrierte. Dieses Tutorial wird Ihnen zeigen, wie Sie ein multimodales RAG-System aufbauen können.
Bei der Verwendung von Multimodal RAG müssen Sie nicht nur Text verwenden; Sie können verschiedene Arten von Daten wie Bilder, Audio, Videos und natürlich Text verwenden. Es ist auch möglich, verschiedene Arten von Daten zurückzugeben; nur weil Sie Text als Eingabe für Ihr RAG-System verwenden, bedeutet das nicht, dass Sie auch Text als Ausgabe zurückgeben müssen. Das werden wir im Laufe dieses Tutorials zeigen.
Voraussetzungen
Bevor Sie mit der Einrichtung der verschiedenen Komponenten unseres Tutorials beginnen, stellen Sie sicher, dass Ihr System über die folgenden Voraussetzungen verfügt:
Docker & Docker-Compose - Stellen Sie sicher, dass Docker und Docker-Compose auf Ihrem System installiert sind.
Milvus Standalone - Für unsere Zwecke werden wir das effiziente Milvus Standalone verwenden, das einfach über Docker Compose verwaltet werden kann; lesen Sie unsere Dokumentation für die Installation Anleitung
Ollama-Installieren Sie Ollama auf Ihrem System. Dies ermöglicht uns die Verwendung von Llama3 auf unserem Laptop. Besuchen Sie die Website für die neueste Installationsanleitung.
OpenAI CLIP
Die Kernidee hinter dem CLIP (Contrastive Language-Image Pretraining) Modell ist es, die Verbindung zwischen einem Bild und einem Text zu verstehen. Es ist ein grundlegendes KI-Modell, das auf Text-Bild-Paaren trainiert wird. Es lernt dann, einen Punkt im Vektorraum sowohl für Text als auch für Bilder zu erstellen. In diesem Raum befinden sich ähnliche Textbeschreibungen in der Nähe von relevanten Bildern und umgekehrt.
CLIP kann für verschiedene Anwendungen eingesetzt werden, darunter:
Bildsuche: Stellen Sie sich vor, Sie suchen nach Bildern anhand einer Textbeschreibung oder finden die perfekte Bildunterschrift zu einem Bild.
Multimodales Lernen: Die Stärke von CLIP bei der Verknüpfung von Text und Bildern macht es zu einem perfekten Baustein für Systeme wie multimodales RAG, die mit Informationen in verschiedenen Formaten umgehen.
Dies ermöglicht es unserem RAG-System, Anfragen zu verstehen und zu beantworten, die sowohl Text als auch Bilder beinhalten können.
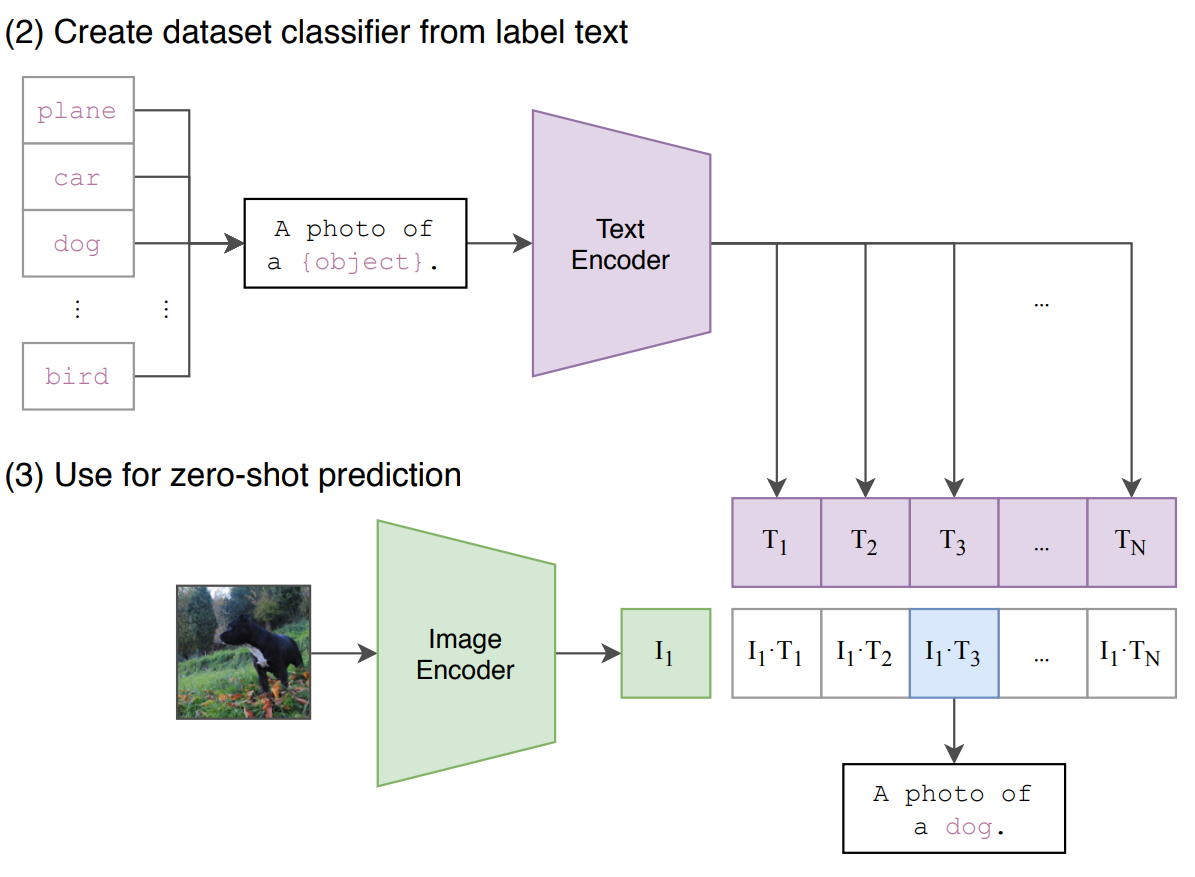 Abb1: Architektur von OpenAI CLIP
Abb1: Architektur von OpenAI CLIP
Multimodale Einbettungen
Was sind Einbettungen? Einfacher ausgedrückt, sind Einbettungen komprimierte Darstellungen von Daten. CLIP nimmt ein Bild oder einen Text als Eingabe und wandelt ihn in einen numerischen Code um, der seine wichtigsten Merkmale erfasst.
Das Schöne an CLIP ist, dass es sowohl für Text als auch für Bilder funktioniert. Sie können ein Bild eingeben, und es wird eine Einbettung erzeugt, die den visuellen Inhalt erfasst. Sie können aber auch einen Text eingeben, und CLIP erzeugt eine Einbettung, die die Bedeutung des Textes wiedergibt.
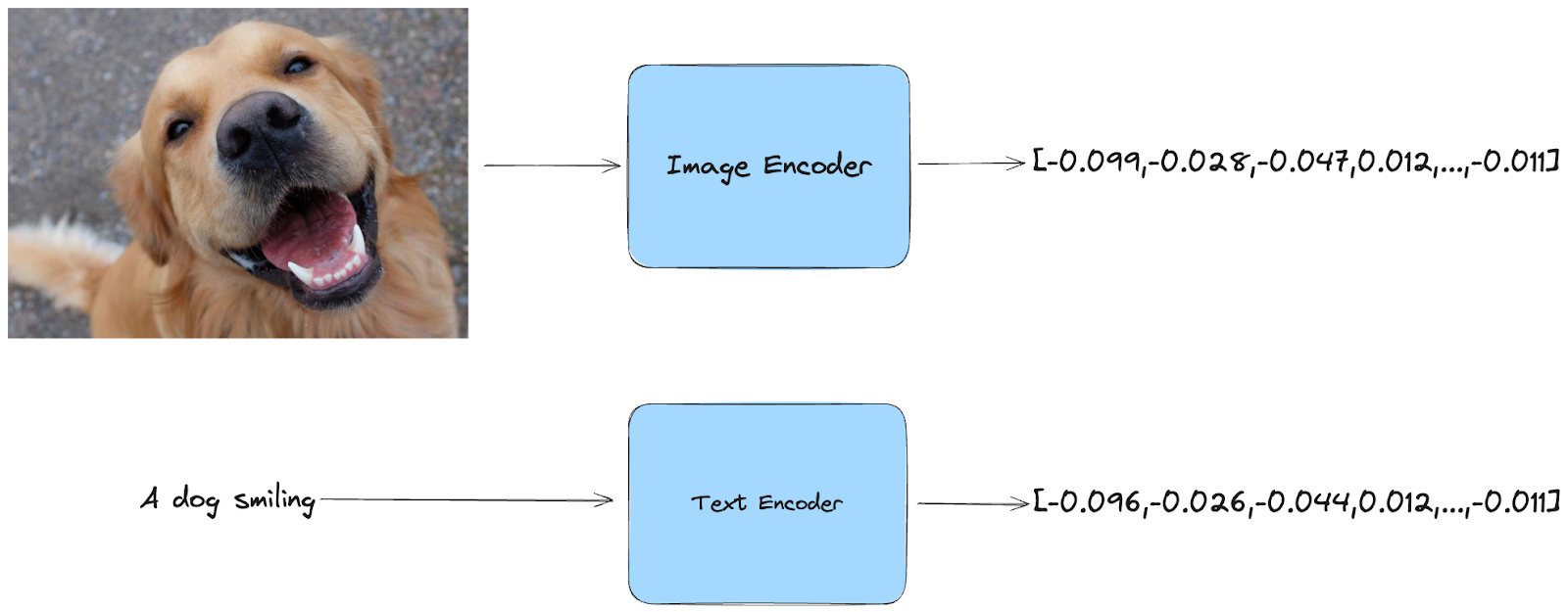 Multimodale Einbettungen
Multimodale Einbettungen
Stellt man sich eine Projektion in den Vektorraum vor, so liegen Einbettungen mit ähnlichen Bedeutungen nahe beieinander. Zum Beispiel liegen der Text "Ein Hund mit einem Lächeln" und das Bild eines Hundes, der zu lächeln scheint, nahe beieinander.
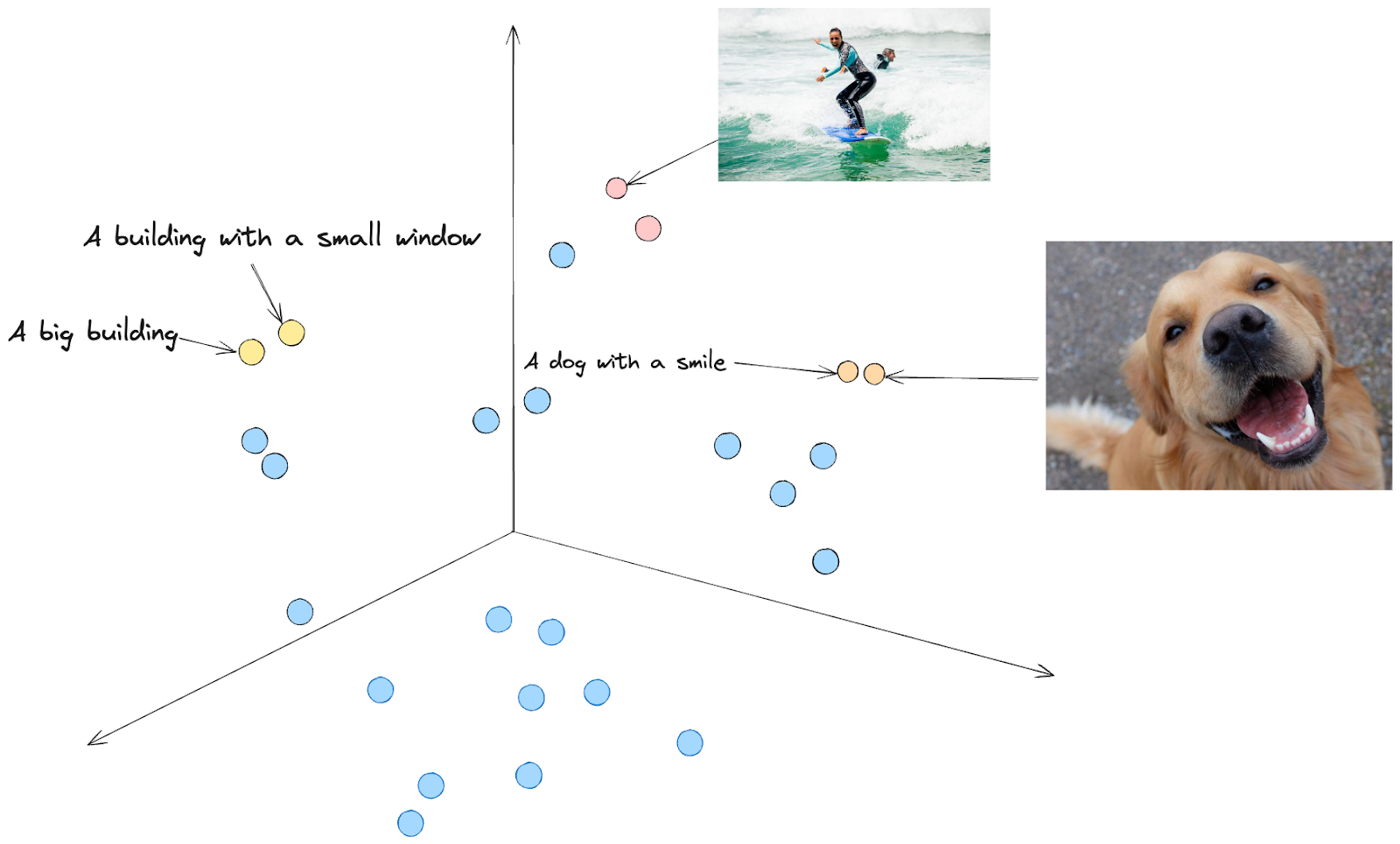 Abb2. Darstellung im Vektorraum
Abb2. Darstellung im Vektorraum
Aufbau einer multimodalen RAG
Wir verwenden Daten aus Wikipedia, laden die Textdaten herunter, die mit dem Thema verbunden sind, über das wir mehr erfahren wollen, und machen das Gleiche mit Bildern.
Wir werden Embeddings mit dem CLIP-Modell "ViT-B/32" erzeugen und Llama3 als LLM verwenden.
Wir speichern die Einbettungen in Milvus, das für die Verwaltung umfangreicher Einbettungen konzipiert ist, damit wir eine schnelle und effiziente Suche durchführen können.
LlamaIndex wird als Query Engine in Kombination mit Milvus als Vektorspeicher verwendet.
Der gesamte Code ist ziemlich lang, da wir Wikipedia durchsuchen, den Text und die Bilder verarbeiten und dann eine RAG-Anwendung erstellen müssen. Er ist jedoch vollständig auf Github verfügbar, also sollten Sie ihn sich unbedingt ansehen!
Sobald Sie es zum Laufen gebracht haben, sollten Sie in der Lage sein, ähnliche Abfragen wie die folgenden durchzuführen:
# https://en.wikipedia.org/wiki/Helsinki
query2 = "Was sind einige der beliebtesten Touristenattraktionen in Helsinki?"
# Bildabfrageergebnisse generieren
image_query(abfrage2)
# Generierung von Textabfrageergebnissen
text_retrieval_results = text_query_engine.query(query2)
print("Textabfrageergebnisse: \n" + str(text_retrieval_results))
Die Ausgabe sollte in etwa so aussehen
Zu den beliebten Touristenattraktionen in Helsinki gehören Suomenlinna (Sveaborg), eine Festungsinsel mit reicher Geschichte, und der Zoo Korkeasaari, der auf einer der Hauptinseln Helsinkis liegt. Darüber hinaus verfügt die Stadt über zahlreiche Naturschutzgebiete, darunter Vanhankaupunginselkä, das größte Naturschutzgebiet Helsinkis.

Und damit haben Sie eine multimodale RAG-Anwendung, die entweder Bilder oder Text verarbeiten kann und auch Bilder oder Text zurückgeben kann.
Sie können auf den Code auf Github zugreifen, Fragen auf unserem Discord stellen und uns einen Stern auf Github geben.

Weiterlesen

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.