




Erste Schritte mit PyMilvus
Milvus, eine Open-Source-Vektordatenbank, in Kombination mit PyMilvus – ihrem Python-SDK – ist ein leistungsstarkes Tool für die Verarbeitung großer Datensätze sowie die Durchführung fortgeschrittener Berechnungen und Suchen.
Dieses Tutorial führt Sie durch die Installation und Einrichtung einer Entwicklungsumgebung für die Verwendung von Milvus und PyMilvus. Anschließend gehen Sie Beispielcode zur Analyse von Audiodateien, zum Speichern ihrer Daten in Milvus und zur anschließenden Verwendung dieser Daten zum Vergleichen von Audiobeispielen auf Ähnlichkeiten durch. Legen wir los.
Was ist Milvus?
Milvus ist eine Open-Source-Vektordatenbank, die Vektorähnlichkeitssuche und Analysen im Billionenmaßstab verarbeitet. Sie ist eine leistungsstarke und effiziente Plattform zur Verwaltung und Suche von unstrukturierten Daten mithilfe von Einbettungsvektoren, einer zunehmend wichtigen Fähigkeit in Machine Learning, Computer Vision, Empfehlungssystemen und anderen Bereichen der künstlichen Intelligenz (KI).
Im Kern nutzt Milvus das Konzept von Einbettungen, bei dem Datenpunkte als hochdimensionale Vektoren dargestellt werden. Diese Vektoren können die Ähnlichkeit zwischen Datenpunkten basierend auf ihren semantischen oder visuellen Merkmalen erfassen. Milvus ermöglicht die Speicherung, Indizierung und den Abruf dieser Vektoren, sodass Benutzer schnelle Ähnlichkeitssuchen über riesige Datensätze hinweg durchführen können.
Mit seiner verteilten Architektur und Unterstützung für GPU-Beschleunigung kann Milvus große Mengen an Vektordaten effizient verarbeiten und Suchergebnisse in Echtzeit liefern. Darüber hinaus bietet es eine Reihe von Indizierungsalgorithmen, die für verschiedene Anwendungsfälle optimiert sind, einschließlich Approximate-Nearest-Neighbor-(ANN)-Suche-Algorithmen, um Genauigkeit und Effizienz auszubalancieren.
Milvus unterstützt verschiedene Programmiersprachen und stellt benutzerfreundliche APIs bereit, wodurch es für Entwickler und Forscher zugänglich ist. Darüber hinaus lässt es sich gut in beliebte Machine-Learning-Frameworks und Datenverarbeitungstools integrieren und ermöglicht so eine nahtlose Integration in bestehende Workflows.
Was ist PyMilvus?
PyMilvus ist das Python-SDK für Milvus. Es wurde entwickelt, um Python-Entwicklern eine einfache und effiziente Interaktion mit Milvus zu ermöglichen und Aufgaben wie Datenverwaltung, Durchführung von Vektorähnlichkeitssuchen, Aufbau von Indizes und mehr zu erleichtern.
Mit PyMilvus nutzen Entwickler die volle Leistung von Milvus in ihren Python-Anwendungen, ohne sich um die Feinheiten der zugrunde liegenden Datenbankoperationen kümmern zu müssen. Es abstrahiert viele der Komplexitäten bei der Arbeit mit Milvus und bietet eine einfache, benutzerfreundliche API, die sich nahtlos in bestehende Python-Workflows integriert.
Einrichtung für das Tutorial
Die Befehlszeilenbeispiele in diesem Beitrag stammen aus Linux, sollten sich aber leicht auf macOS oder Windows mit dem Windows Subsystem for Linux (WSL) übertragen lassen. Sie benötigen ein System mit Docker oder Docker Desktop, Python 3.10+ und git.
Milvus-Bootcamp-Repository
Wir verwenden für dieses Tutorial Code aus dem Milvus Bootcamp-Repository auf Github. Beginnen Sie damit, das Repo auf Ihr lokales System zu klonen.
[egoebelbecker@ares bootcamp]$ git clone https://github.com/milvus-io/bootcamp.git
Cloning into 'bootcamp'...
remote: Enumerating objects: 61861, done.
remote: Counting objects: 100% (4488/4488), done.
remote: Compressing objects: 100% (1628/1628), done.
remote: Total 61861 (delta 2983), reused 4180 (delta 2791), pack-reused 57373
Receiving objects: 100% (61861/61861), 166.78 MiB | 4.91 MiB/s, done.
Resolving deltas: 100% (28214/28214), done.
Virtuelle Python-Umgebung
Erstellen Sie als Nächstes eine virtuelle Umgebung, um Ihren Code auszuführen. Sie können sie in dem Verzeichnis ablegen, in das Sie das Bootcamp-Repo geklont haben. Aktivieren Sie die Umgebung, nachdem Sie sie erstellt haben.
[egoebelbecker@ares bootcamp]$ cd bootcamp
[egoebelbecker@ares bootcamp]$ git checkout archive20230625
[egoebelbecker@ares bootcamp]$ python3 -m venv ./venv
[egoebelbecker@ares bootcamp]$ source venv/bin/activate
(venv) [egoebelbecker@ares bootcamp]$
Python-Abhängigkeiten installieren
Jetzt ist es an der Zeit, unser Projekt einzurichten.
Wir werden das Beispiel Audio Similarity Search verwenden. Es nutzt einen öffentlich verfügbaren Satz von Audiodateien, um zu demonstrieren, wie Sie Milvus verwenden können, um Ähnlichkeiten zwischen verschiedenen Samples zu erkennen.
Wechseln Sie in das Unterverzeichnis des Projekts und sehen Sie sich die mit dem Code bereitgestellte Datei requirements.txt an.
(venv) [egoebelbecker@ares bootcamp]$ cd solutions/audio/audio_similarity_search/
(venv) [egoebelbecker@ares audio_similarity_search]$ cat requirements.txt
pymilvus
redis
librosa
numpy
panns_inference
torch
diskcache
gdown
Dies sind die Python-Bibliotheken, die zum Ausführen des Projekts benötigt werden. Verwenden Sie pip, um sie zu installieren. Fügen Sie anschließend Jupyter hinzu, damit wir das Notebook ausführen können.
(venv) [egoebelbecker@ares audio_similarity_search]$ pip install -r requirements.txt
(Lots of output)
(venv) [egoebelbecker@ares audio_similarity_search]$ pip install jupyter
(More output)
Redis starten
Starten Sie nun einen Redis-Docker-Container.
docker run --name redis -d -p 6379:6379 redis
Milvus Lite installieren und starten
Schließlich benötigen Sie einen Milvus-Server. Der einfachste Weg, mit Milvus loszulegen, ist Milvus Lite, das in Python läuft. Installieren Sie die milvus-Pakete.
(venv) [egoebelbecker@ares audio_similarity_search]$ pip install milvus
(Lots of output)
(venv) [egoebelbecker@ares audio_similarity_search]$ milvus-server
__ _________ _ ____ ______
/ |/ / _/ /| | / / / / / __/
/ /|_/ // // /_| |/ / /_/ /\ \
/_/ /_/___/____/___/\____/___/ {Lite}
Welcome to use Milvus!
Version: v2.2.8-lite
Process: 275118
Started: 2023-05-25 12:41:47
Config: /home/egoebelbecker/.milvus.io/milvus-server/2.2.8/configs/milvus.yaml
Logs: /home/egoebelbecker/.milvus.io/milvus-server/2.2.8/logs
Ctrl+C to exit ...
PyMilvus-Projekt
Nachdem nun eine Umgebung eingerichtet ist, können Sie das Tutorial ausführen.
Jupyter starten
Starten Sie Jupyter aus Ihrer virtuellen Umgebung.
(venv) [egoebelbecker@ares audio_similarity_search]$ python -m jupyter notebook --notebook-dir=`pwd`
_ _ _ _
| | | |_ __ __| |__ _| |_ ___
| |_| | '_ \/ _` / _` | _/ -_)
\___/| .__/\__,_\__,_|\__\___|
|_|
Read the migration plan to Notebook 7 to learn about the new features and the actions to take if you are using extensions.
https://jupyter-notebook.readthedocs.io/en/latest/migrate_to_notebook7.html
(More output)
Dadurch wird die Jupyter-Dateiseite in Ihrem Standardbrowser geöffnet.
 Navigieren Sie zum Verzeichnis
Navigieren Sie zum Verzeichnis solutions/audio/audio_similarity_search.
Öffnen Sie das Notebook audio_similarity_search.
Mit Redis und Milvus verbinden
Sie haben die anfängliche Einrichtung bereits durchgeführt, scrollen Sie also direkt nach unten zum Abschnitt Code Overview. Der Code beginnt mit dem Importieren von Bibliotheken für Redis und Milvus.
In der zweiten Zeile sehen Sie die Klassen, die Sie benötigen, um eine Verbindung zu Milvus herzustellen, eine Collection zu erstellen sowie Daten hinzuzufügen und daraus abzurufen.
import redis
from pymilvus import connections, DataType, FieldSchema, CollectionSchema, Collection, utility
connections.connect(host = '127.0.0.1', port = 19530)
red = redis.Redis(host = '127.0.0.1', port=6379, db=0)
Dann stellt der Code eine Verbindung zu den beiden Servern her. Führen Sie diesen Block aus. Jetzt ist es an der Zeit, eine Milvus-Collection zu erstellen, um Informationen zu jeder Audiodatei zu speichern.
import time
red.flushdb()
time.sleep(.1)
collection_name = "audio_test_collection"
if utility.has_collection(collection_name):
print("Dropping existing collection...")
collection = Collection(name=collection_name)
collection.drop()
#if not utility.has_collection(collection_name):
field1 = FieldSchema(name="id", dtype=DataType.INT64, description="int64", is_primary=True,auto_id=True)
field2 = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, description="float vector", dim=2048, is_primary=False)
schema = CollectionSchema(fields=[ field1,field2], description="collection description")
collection = Collection(name=collection_name, schema=schema)
print("Created new collection with name: " + collection_name)
Eine Milvus Collection erstellen
Dieser Schritt erstellt eine Collection namens audio_test_collection mit zwei Feldern:
- id - ein ganzzahliges Identifikationsfeld
- embedding - ein Vektor aus 2048 Gleitkommazahlen, um Daten über die Audiodateien zu speichern
Führen Sie diesen Block aus, und Sie sehen diese Meldung:
Dropping existing collection...
Created new collection with name: audio_test_collection
Fügen Sie als Nächstes Ihrer neuen Collection einen Index hinzu:
if utility.has_collection(collection_name):
collection = Collection(name = collection_name)
default_index = {"index_type": "IVF_SQ8", "metric_type": "L2", "params": {"nlist": 16384}}
status = collection.create_index(field_name = "embedding", index_params = default_index)
if not status.code:
print("Successfully create index in collection:{} with param:{}".format(collection_name, default_index))
Führen Sie diesen Block aus:
Successfully create index in collection:audio_test_collection with param:{'index_type': 'IVF_SQ8', 'metric_type': 'L2', 'params': {'nlist': 16384}}
Audiodaten speichern
Milvus ist jetzt bereit, die Audiodaten zu speichern. Lassen Sie uns den nächsten Codeblock aufschlüsseln und genau ansehen.
import os
import librosa
import gdown
import zipfile
import numpy as np
from panns_inference import SoundEventDetection, labels, AudioTagging
data_dir = './example_audio'
at = AudioTagging(checkpoint_path=None, device='cpu')
def download_audio_data():
url = 'https://drive.google.com/uc?id=1bKu21JWBfcZBuEuzFEvPoAX6PmRrgnUp'
gdown.download(url)
with zipfile.ZipFile('example_audio.zip', 'r') as zip_ref:
zip_ref.extractall(data_dir)
Dieser Abschnitt importiert Bibliotheken zur Verarbeitung der Dateien. Dann erstellt er ein AudioTagging-Objekt aus der Panns Inference library.
Dies ist eine Python-Schnittstelle zu den Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition (PANNs).
Die AudioTagging-Klasse erstellt für jede Audiodatei einen Satz von Datenpunkten, ähnlich wie hier:
Speech: 0.893
Telephone bell ringing: 0.754
Inside, small room: 0.235
Telephone: 0.183
Music: 0.092
Ringtone: 0.047
Inside, large room or hall: 0.028
Alarm: 0.014
Animal: 0.009
Vehicle: 0.008
embedding: (2048,)
Als Nächstes folgt der Code zum Herunterladen der Dateien, Analysieren dieser Dateien und Einfügen der Daten in Milvus sowie der Dateiinformationen in Redis:
def embed_and_save(path, at):
audio, _ = librosa.core.load(path, sr=32000, mono=True)
audio = audio[None, :]
try:
_, embedding = at.inference(audio)
embedding = embedding/np.linalg.norm(embedding)
embedding = embedding.tolist()[0]
mr = collection.insert([[embedding]])
ids = mr.primary_keys
collection.load()
red.set(str(ids[0]), path)
except Exception as e:
print("failed: " + path + "; error {}".format(e))
Dieser Codeblock fügt alles zusammen:
print("Starting Insert")
download_audio_data()
for subdir, dirs, files in os.walk(data_dir):
for file in files:
path = os.path.join(subdir, file)
embed_and_save(path, at)
print("Insert Done")
Führen Sie den Code aus:
Checkpoint path: /home/egoebelbecker/panns_data/Cnn14_mAP=0.431.pth
Using CPU.
Starting Insert
Wird heruntergeladen...
Von: [https://drive.google.com/uc?id=1bKu21JWBfcZBuEuzFEvPoAX6PmRrgnUp](https://drive.google.com/uc?id=1bKu21JWBfcZBuEuzFEvPoAX6PmRrgnUp)
Nach: /home/egoebelbecker/src/bootcamp/solutions/audio/audio_similarity_search/example_audio.zip
100%|█████████████████████████████████████████████████████████████████████████████████████████| 474k/474k [00:00<00:00, 8.87MB/s]
Einfügen abgeschlossen
Nach Ähnlichkeiten suchen
Um die Datenbank zu durchsuchen, müssen Sie dieselbe Analyse für die Dateien durchführen, die Sie abgleichen möchten. Hier ist Code, um dies für eine zufällig ausgewählte Menge von Datei-IDs zu tun.
```python
def get_embed(paths, at):
embedding_list = []
for x in paths:
audio, _ = librosa.core.load(x, sr=32000, mono=True)
audio = audio[None, :]
try:
_, embedding = at.inference(audio)
embedding = embedding/np.linalg.norm(embedding)
embedding_list.append(embedding)
except:
print("Embedding Failed: " + x)
return np.array(embedding_list, dtype=np.float32).squeeze()
random_ids = [int(red.randomkey()) for x in range(2)]
search_clips = [x.decode("utf-8") for x in red.mget(random_ids)]
embeddings = get_embed(search_clips, at)
print(embeddings.shape)
Führen Sie diesen Block aus, um zwei Dateien auszuwählen und die Analyse durchzuführen. Jetzt ist es an der Zeit, eine Suche in Milvus durchzuführen. Dieser Code zeigt die Suchergebnisse in Audioplayern an:
import IPython.display as ipd
def show_results(query, results, distances):
print("Query: ")
ipd.display(ipd.Audio(query))
print("Results: ")
for x in range(len(results)):
print("Distance: " + str(distances[x]))
ipd.display(ipd.Audio(results[x]))
print("-"*50)
Als Nächstes nimmt das Programm das oben erstellte Array embeddings und konvertiert es in eine Liste. Dann erstellt es unsere Suchparameter. Wir suchen nach zwei ähnlichen Klängen und verwenden nprobe für die Kriterien. Dies entspricht dem Indextyp, den Sie oben verwendet haben.
embeddings_list = embeddings.tolist()
search_params = {"metric_type": "L2", "params": {"nprobe": 16}}
Zum Schluss folgt hier die Suche.
try:
start = time.time()
results = collection.search(embeddings_list, anns_field="embedding", param=search_params, limit=3)
end = time.time() - start
print("Search took a total of: ", end)
for x in range(len(results)):
query_file = search_clips[x]
result_files = [red.get(y.id).decode('utf-8') for y in results[x]]
distances = [y.distance for y in results[x]]
show_results(query_file, result_files, distances)
except Exception as e:
print("Failed to search vectors in Milvus: {}".format(e))
Führen Sie es aus, und Sie sehen die zufällig ausgewählten Dateien sowie zwei Suchergebnisse mit ihrer Entfernung vom Original.
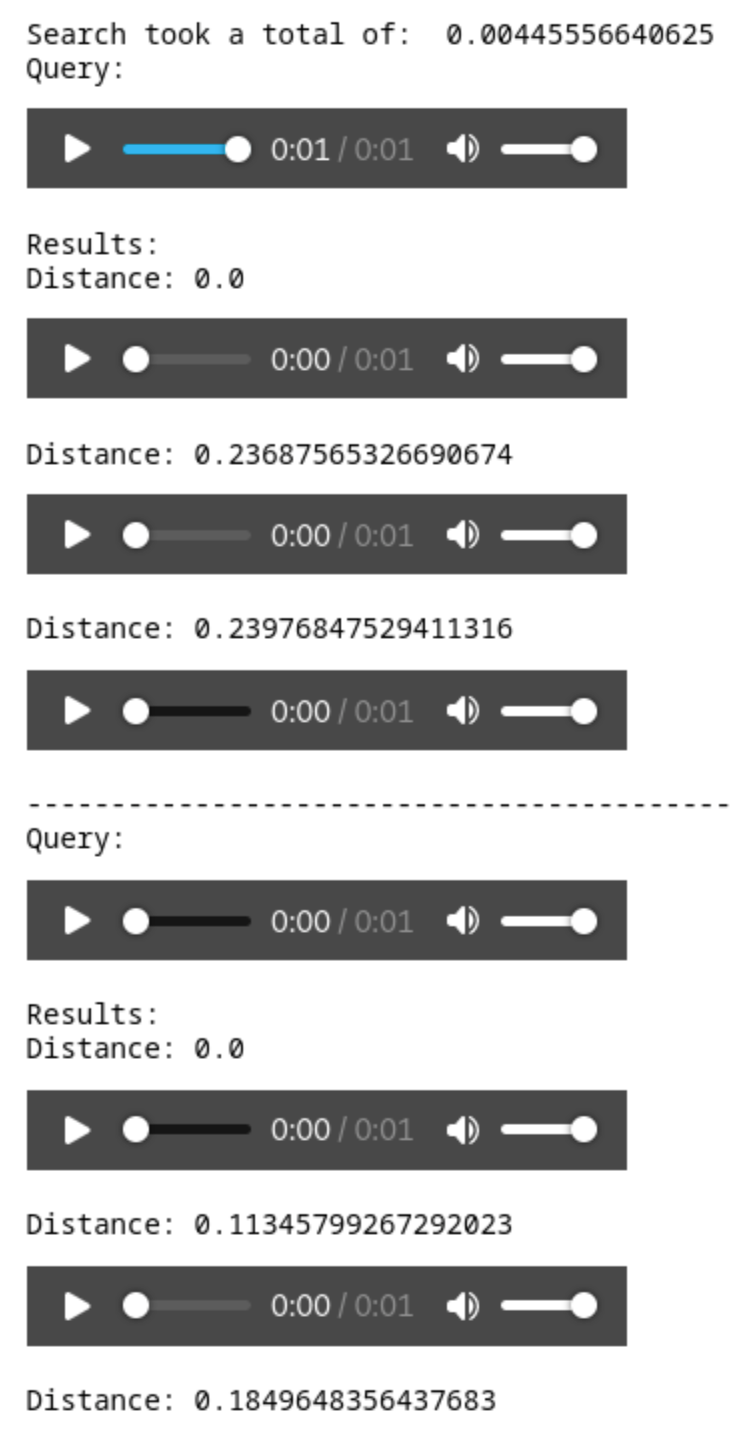
Hören Sie sich jede Datei an, und Sie hören die exakte Übereinstimmung und ihren nächsten Nachbarn.
Zusammenfassung
In diesem Beitrag haben Sie gelernt, wie Sie eine Python-Umgebung für die Arbeit mit Milvus erstellen. Nachdem Sie einen Server und das PyMilvus SDK eingerichtet hatten, haben Sie ein Beispiel-Tutorial aus dem Milvus Bootcamp-Repository ausgeführt. Sie haben Code gesehen, um eine Collection zu erstellen, sie zu indexieren, Daten zu speichern und eine einfache Suche durchzuführen.
Nachdem Sie nun gesehen haben, wie einfach der Einstieg in Milvus ist, fahren Sie mit den Bootcamp-Projekten fort und sehen Sie, wie Sie Milvus nutzen können, um Ihre Projekte zu verbessern.
Dieser Beitrag wurde von Eric Goebelbecker geschrieben. Eric arbeitet seit 25 Jahren auf den Finanzmärkten in New York City und entwickelt Infrastruktur für Marktdaten und Netzwerke für das Financial Information Exchange (FIX)-Protokoll. Er spricht gerne darüber, was Teams effektiv (oder nicht so effektiv!) macht.

Weiterlesen

How to Improve Retrieval Quality for Japanese Text with Sudachi, Milvus/Zilliz, and AWS Bedrock
Learn how Sudachi normalization and Milvus/Zilliz hybrid search improve Japanese RAG accuracy with BM25 + vector fusion, AWS Bedrock embeddings, and practical code examples.

Zilliz Named "Highest Performer" and "Easiest to Use" in G2's Summer 2025 Grid® Report for Vector Databases
Zilliz shines in G2's Summer 2025 Grid® Report as both "Highest Performer" and "Easiest to Use," solving the performance-usability dilemma.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.